- The paper demonstrates that JEPA alignment is essential for stabilizing gate training and preventing predictor collapse in conditional depth routing.
- The paper reveals that removing util/rank auxiliary losses yields improved language model performance while reducing computational costs by approximately 30–39%.
- The paper highlights that top‑k routing mechanisms neutralize absolute score differences, underscoring the need for on‑policy utility calibration in adaptive computation.
Empirical Analysis of Auxiliary Losses in Conditional Depth Routing
Overview
This essay provides a detailed technical analysis of "Revisiting Auxiliary Losses for Conditional Depth Routing: An Empirical Study" (2604.17228), which examines the interplay between predictive and explicit score-supervision auxiliary losses during gate (controller) training for conditional depth execution in Transformer-based LLMs. The core experimental findings arise from a systematic ablation study comparing two gate architectures—the standard MLP gate and a JEPA-guided gate—under a spectrum of auxiliary loss configurations within a 157M parameter, controller-only training regime.
Conditional Depth Routing and Gate Training Challenges
Conditional depth execution frameworks aim to reduce computational cost by dynamically routing a subset of tokens through a lightweight, low-rank (cheap) FFN, while select tokens take the full path at each controlled layer. Despite the apparent computational benefits, stable and efficient training of the token-wise gate (controller)—which determines this routing—remains challenging. The gate must propagate its decisions across many layers before their impact is reflected in the language modeling loss, resulting in noisy gradients and slow convergence.
Auxiliary losses have been widely adopted to stabilize these training dynamics, drawing from both predictive models (e.g., JEPA-inspired architectures) and explicit score supervision using counterfactual oracle-derived labels (utility/rank losses). However, the literature has not systematically explored how combinations of these auxiliaries interact, especially regarding their compatibility and cumulative impact.
Experimental Design
Architectures
- MLP Gate (G1): A two-layer MLP maps the current hidden state directly to a utility score, which is then used for top-k routing.
- JEPA-Guided Gate (G3): Incorporates a JEPA-inspired predictor which, conditioned on contextual embedding and an action (full or cheap), generates low-dimensional outcome summaries. These drive a decision head to produce routing utility scores. A fixed target projection head enforces alignment, ensuring discriminability between the predicted outcomes of "full" and "cheap" actions.
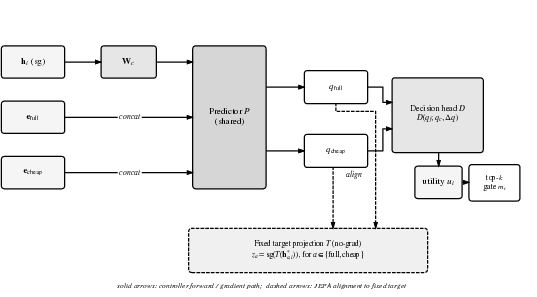
Figure 1: Architecture of the JEPA-guided gate (G3) showing context projection, action conditioning, predictive alignment, and routing decision flow.
Utility Labeling and Oracle Bias
Explicit score supervision leverages utility labels that measure the downstream cross-entropy reduction resulting from executing "full" versus "cheap" at a given layer, assuming all subsequent layers execute full for both branches (the "subsequent-all-full" counterfactual). This oracular teacher provides deterministic, tractable, token-wise signal but introduces a distributional mismatch: the student (actual execution) only routes a fraction ρ of subsequent tokens through the full path, violating the oracle's off-policy assumptions.
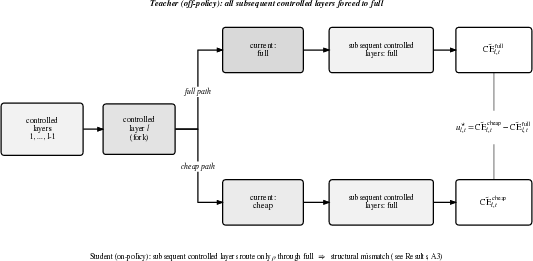
Figure 2: Counterfactual fork for utility label computation, contrasting the student's on-policy execution with the oracle's all-subsequent-full assumption.
Training Protocols and Metrics
All experiments use controller-only training with the full Transformer backbone frozen, thereby isolating the effects of auxiliary losses and gate architectures. Key metrics include validation lm_loss (both cumulative and endpoint), threshold-hitting steps, and diagnostic measures such as gradient norms and predictor collapse indicators.
Empirical Results and Key Findings
JEPA Alignment is Necessary but Not Sufficient
The JEPA-guided gate (G3) yields improved early-to-mid training dynamics relative to the basic MLP gate (G1) under the "standard recipe" (i.e., when predictive and util/rank auxiliary losses are both active). Benefits manifest in lower average validation lm_loss, faster threshold hitting, and orders-of-magnitude lower controller gradient norms.
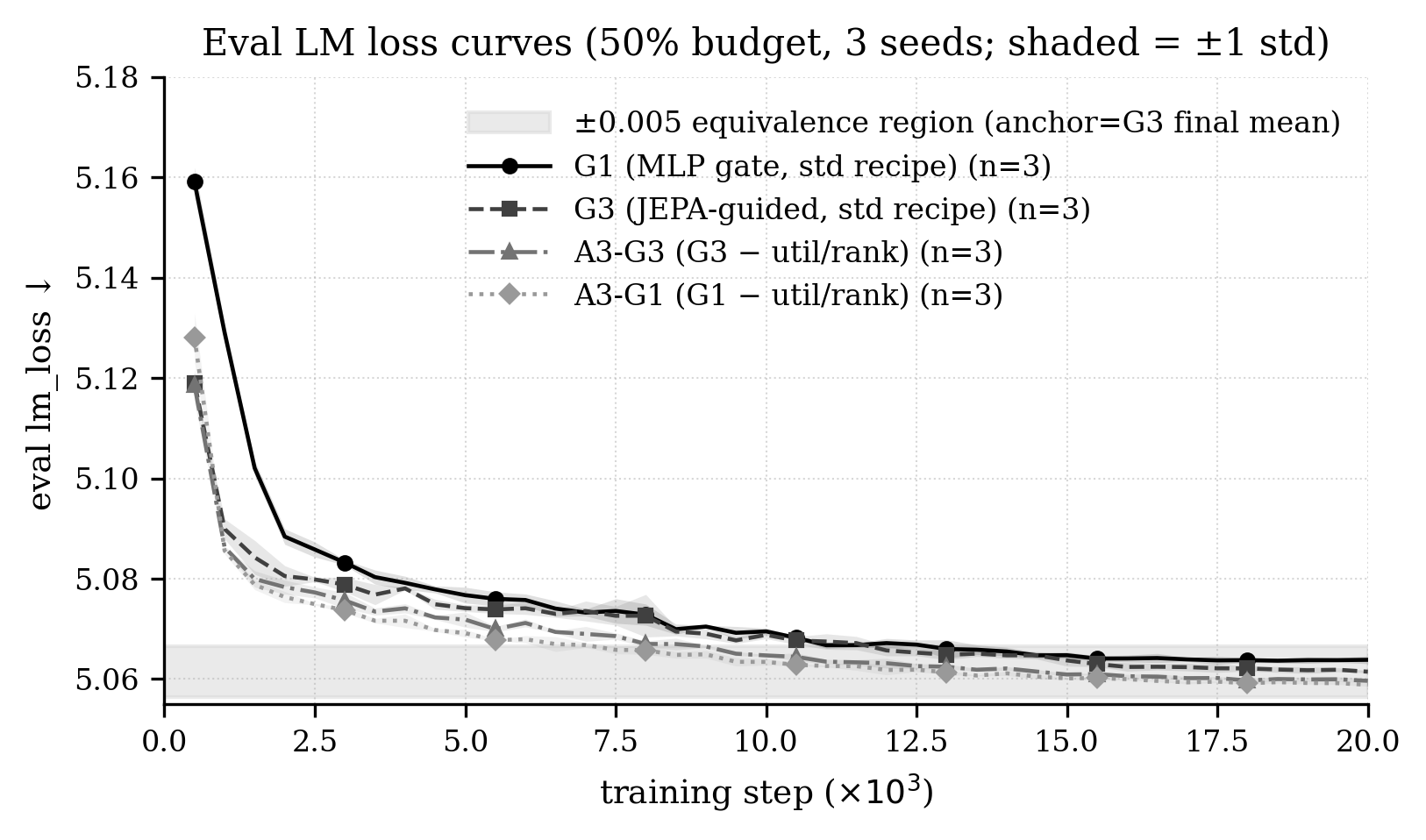
Figure 3: Validation lm_loss learning curves demonstrate G3's early-phase superiority over G1 with all auxiliaries present. Removal of util/rank brings G1 and G3 into statistical equivalence.
However, ablation demonstrates that direct JEPA alignment supervision is essential: its removal leads to severe predictor collapse (action-conditional outputs become degenerate), evidenced by sharp diagnostic drops in output ℓ2 separation and near-zero utility variance. The precise weighting of the JEPA alignment loss, however, is not critical within a broad range.
Net-Negative Impact of Oracle Util/Rank Auxiliary
A central and contradictory finding is that removing both util/rank auxiliary losses consistently improves language modeling performance for both gate architectures. Moreover, the advantage conferred by the JEPA-guided architecture in the presence of oracle supervision disappears; G1 and G3 become statistically indistinguishable on all reported metrics. Endpoint lm_loss differentials fall well within a preset 0.005 reference margin, indicating practical equivalence.
This result exposes the structural flaw in the "subsequent-all-full" oracle: by being off-policy relative to the actual routed execution, utility labels systematically understate the cost of "cheap" path decisions, exerting a misaligned optimization pressure on the gate outputs. The top-k routing mechanism, being permutation-invariant to absolute utility scale, further limits any score anchoring benefit, underscoring a fundamental disconnect between oracle-based calibration and effective routing.
In addition, ablation of util/rank reduces the training compute proxy (FFN-equivalent FLOPs) by ∼30\%, with measured wall-clock savings of ∼39\%, without incurring any inference-time penalty.
Diagnostics of Gradient Norms and Score Calibration
Controller gradient norms follow a clear stratification: standard G1 exhibits high norms; G3's architectural regularization suppresses norms by ∼10×; and util/rank removal collapses all configurations to much lower, "cleaner" optimization.
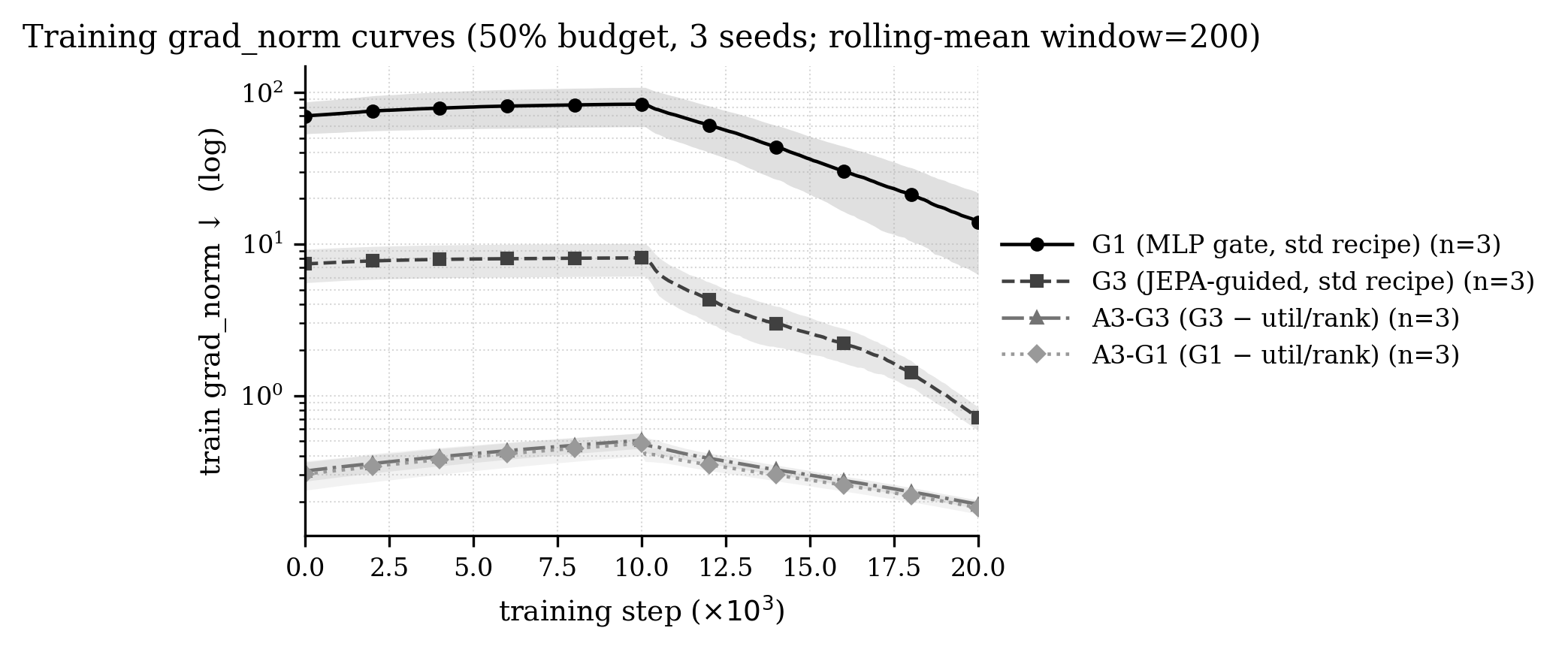
Figure 4: Gradient norm trajectories illustrating optimization stabilization with JEPA-guided gating and further reduction with util/rank removal.
The study also isolates score calibration effects: although absolute score levels (mean gate probabilities) can diverge widely—depending on seed and architecture—across G1 and G3, the hard top-k constraint ensures exact adherence to prescribed full-path ratios, nullifying absolute score scale as a routing determinant.
Discussion and Implications
Separating the Roles of Auxiliary Losses
The empirical results delineate two orthogonal auxiliary loss roles:
- Feature Shaping (JEPA alignment): Ensures action-conditional latent outputs remain informative and discriminable, with direct collapse supervision. This is required for the integrity of a JEPA-style architecture.
- Score Anchoring (util/rank): Attempts to anchor utility scores to explicit, counterfactual oracle signals. In the regime studied, this not only fails to help but actively degrades language modeling due to distribution mismatch.
The implication is that feature-shaping auxiliaries like JEPA alignment are critical for architectural soundness, but score-anchoring auxiliaries can backfire if not precisely aligned with the actual routing policy's execution distribution.
Relation to Conditional Routing and MoE Literature
These findings align with cautionary themes in MoE routing work, where load-balancing and z-losses are often benign, but explicit router supervision (policy teachers) risk introducing adversarial gradients if not carefully harmonized with student execution. The detrimental effect of off-policy oracle labeling echoes classic covariate-shift pathology in imitation learning (cf. DAgger, scheduled sampling).
Recommendations for Practice
For controlled regimes matching the experimental setup (controller-only training, moderate scale), the results strongly support omitting utility/rank auxiliary losses. Predictive alignment used in JEPA-style gates suffices for non-collapse, and stacking explicit policy supervision can be counterproductive. Whether this conclusion holds at larger scales, with different data realities, or in backbone-tuned settings requires additional study.
Open Problems and Future Directions
Multiple uncontrolled variables remain. Critical next steps include:
- Sweeping util/rank weighting to separate inherent harm from overstrength.
- Employing on-policy (trajectory-matched) utility labeling to test whether net-negative effects persist.
- Scaling experiments to joint backbone-and-controller training regimes.
- Extending diagnostic evaluation to downstream tasks.
- Further architectural cross-ablations, especially to disentangle the independent roles of semantic pairing and util/rank interaction.
Conclusion
This study provides empirical grounding that, within the specific tested regime, explicit oracle-style utility/rank auxiliary losses in conditional depth gate training can have net-negative effects on LLM performance, mainly due to structural teacher-student mismatch. JEPA-aligned feature shaping is necessary for sophisticated gate architectures, but does not confer direct LM gains without score-anchoring auxiliaries. These observations underscore the need for more nuanced auxiliary loss design in conditional computation, with strong consideration for alignment between supervision and on-policy execution statistics. The findings chart a disciplinary path away from one-size-fits-all auxiliary stacking, towards differentiated and closely monitored auxiliary integration in adaptive computation.
References:
- "Revisiting Auxiliary Losses for Conditional Depth Routing: An Empirical Study" (2604.17228)