The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
Abstract: The viability of chain-of-thought (CoT) monitoring hinges on models being unable to reason effectively in their latent representations. Yet little is known about the limits of such latent reasoning in LLMs. We test these limits by studying whether models can discover multi-step planning strategies without supervision on intermediate steps and execute them latently, within a single forward pass. Using graph path-finding tasks that precisely control the number of required latent planning steps, we uncover a striking limitation unresolved by massive scaling: tiny transformers trained from scratch discover strategies requiring up to three latent steps, fine-tuned GPT-4o and Qwen3-32B reach five, and GPT-5.4 attains seven under few-shot prompting. Although the maximum latent planning depth models can learn during training is five, the discovered strategy generalizes up to eight latent steps at test-time. This reveals a dissociation between the ability to discover a latent strategy under final-answer supervision alone and the ability to execute it once discovered. If similar limits hold more broadly, strategies requiring multiple coordinated latent planning steps may need to be explicitly taught or externalized, lending credence to CoT monitoring.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks a straightforward question: Can today’s AI LLMs quietly plan several steps ahead “in their heads” without writing out the steps, and if so, how many steps can they handle? The authors find a clear limit: models can plan a few steps internally, but they hit a “depth ceiling” when the plan gets too long—unless they’re allowed to write down their reasoning.
The big idea and purpose
LLMs often do better when they “show their work” using chain-of-thought (CoT) reasoning. That’s helpful for performance and for safety, because humans can read and monitor those steps. But what if a model could secretly plan many steps without writing them? Then CoT monitoring would miss what the model is really doing. This paper tests how deep that hidden planning can go.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- Can models figure out (discover) a multi-step planning strategy on their own if they only get told whether the final answer is right or wrong (no hints about the steps)?
- How many “in-your-head” steps can they actually carry out correctly in one go?
- Does making the model bigger or giving it examples help, and in what way?
How they tested it (with simple analogies)
The team used a very controlled puzzle that forces multi-step thinking:
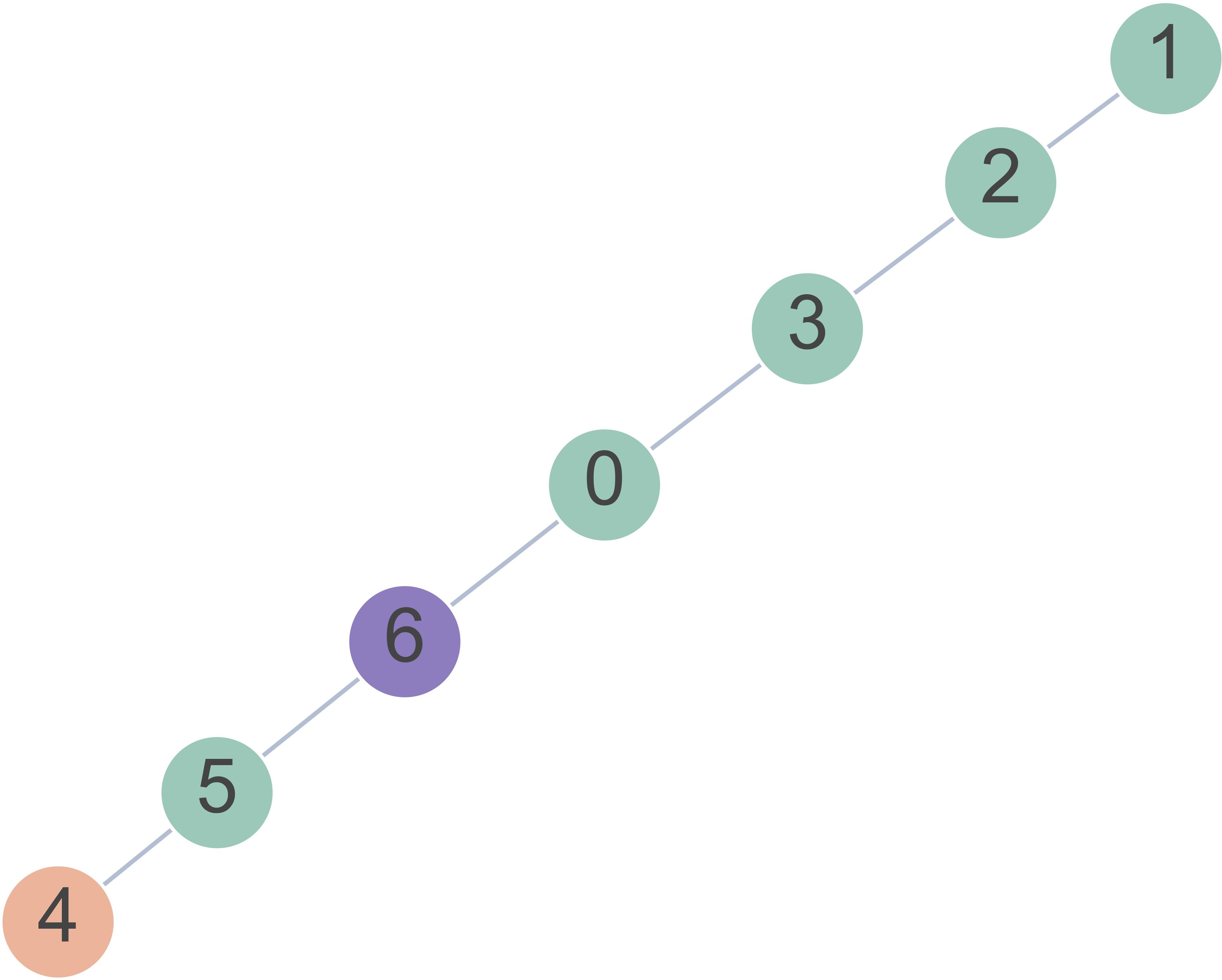
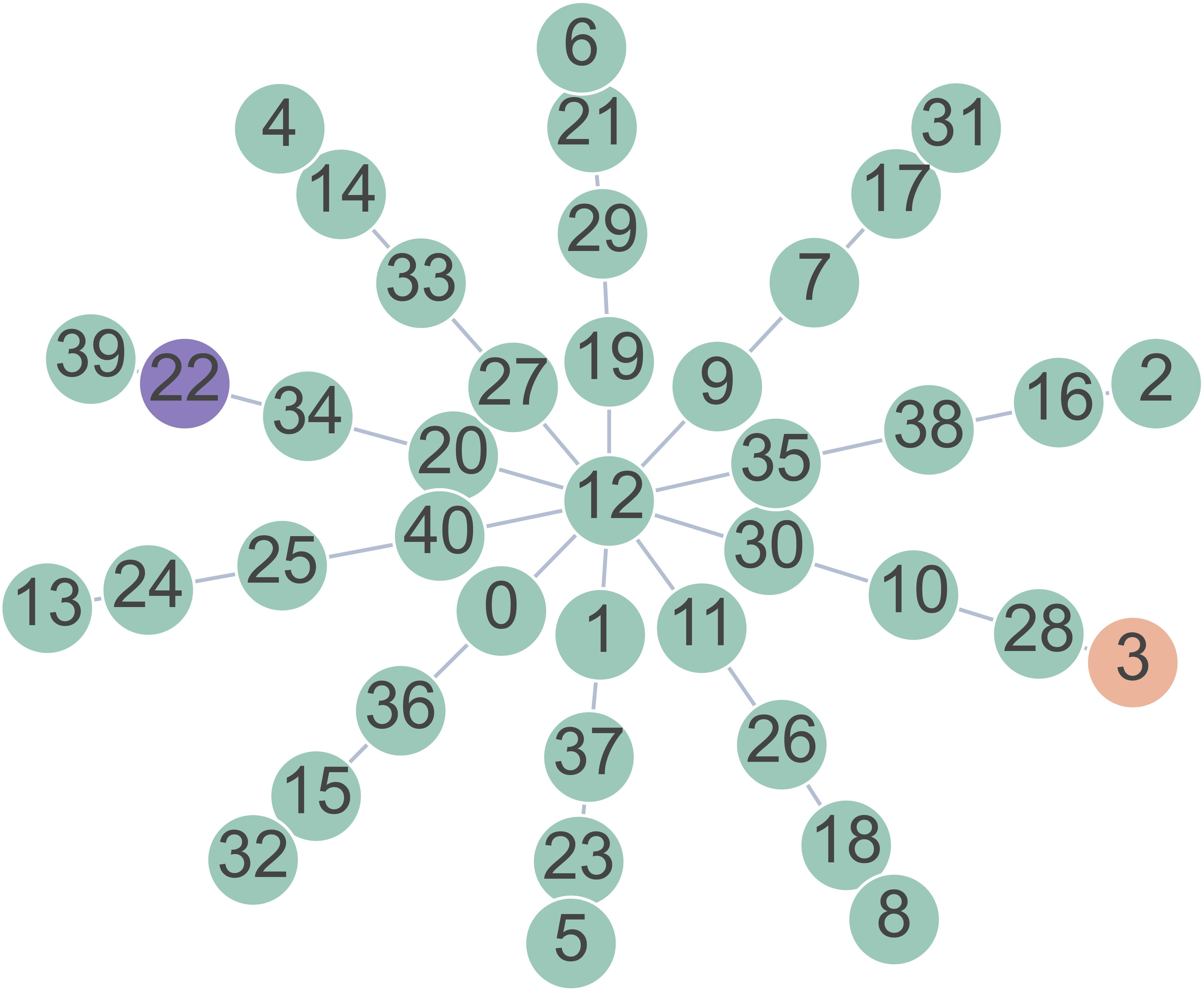
- Imagine a sun with a center and several equally long “spokes” (branches). One far end is secretly marked as the target. You start at the center and must pick the correct first step—the first node on the right spoke—to eventually reach the target.
- Because all spokes look the same, there are no shortcuts or clues. You must “plan” along the path that leads from the target back to the center.
- “Depth” means how many steps long a spoke is. “Breadth” means how many spokes there are.
They trained models only on the final answer (Which first step is correct?), with no step-by-step guidance. That means the model gets a learning signal only if it gets everything right—like being graded only on the final answer to a multi-step math problem.
They tested:
- A tiny transformer trained from scratch (no prior knowledge).
- Large pre-trained LLMs (like Qwen, GPT-4o), sometimes fine-tuned on the task, and sometimes given a few examples in the prompt (“few-shot”).
- A newer, very capable model (GPT-5.4) in few-shot mode.
They also checked what happens if models are allowed to write out a backtracking strategy (like showing their work) and then learn to compress that back into hidden reasoning.
Key terms in everyday language:
- Latent planning: the model plans internally, without writing out steps.
- Depth: how many steps ahead the plan needs.
- Breadth: how many choices you could make at each step (how many spokes).
- Few-shot prompting: giving a handful of example problems and solutions in the prompt.
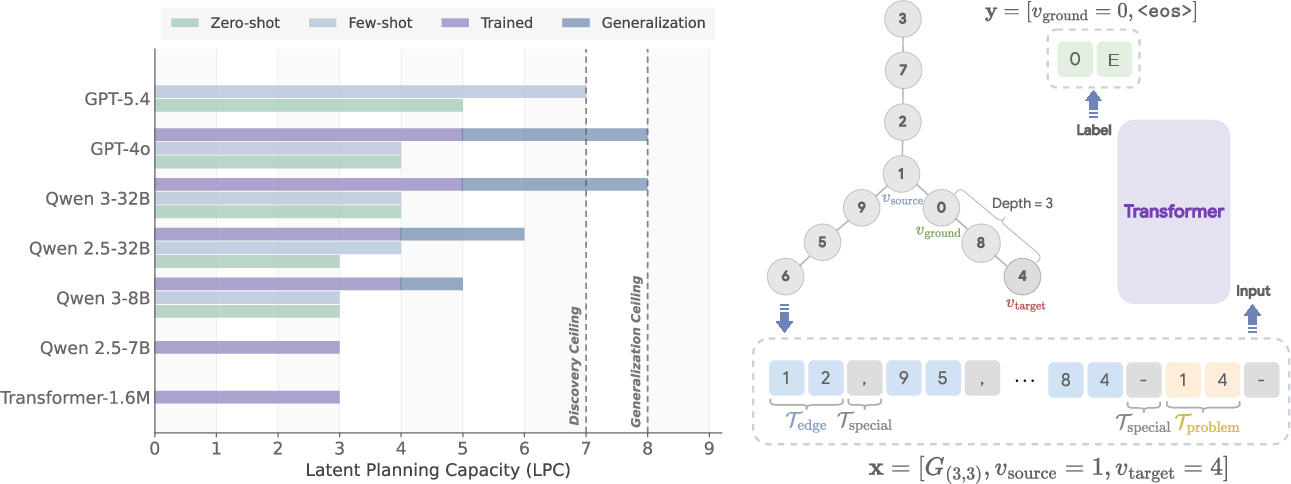
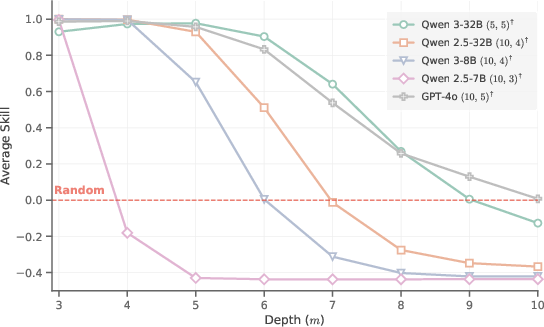
What they found (the main results)
Here are the main takeaways, written plainly:
- Models can discover only shallow hidden plans:
- A tiny transformer learned to plan up to 3 steps in its head.
- After fine-tuning, models like GPT-4o and Qwen-32B reached about 5 steps.
- GPT-5.4 reached about 7 steps with a few examples in the prompt.
- Going beyond that, discovery fails: performance collapses to guessing.
- Bigger isn’t enough for deeper planning:
- Scaling up (bigger models) helps handle more spokes (more choices)—that’s breadth.
- But it barely increases how many steps ahead they can plan without writing it out—depth stays limited.
- Discovery vs. execution:
- Models trained on 5-step problems often could generalize their learned strategy to 6–8 steps at test time.
- But when trained directly on 6–8 steps (with only final-answer feedback), they failed to discover the strategy.
- This shows a split: discovering the hidden strategy is hard; once discovered, executing it for a few more steps is easier.
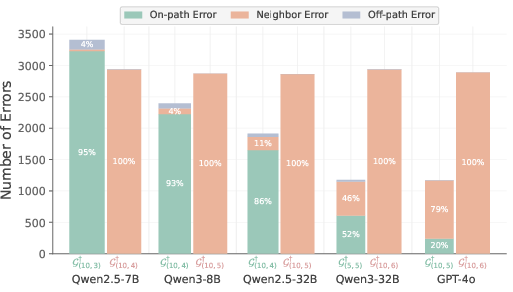
- How models seem to solve it:
- Attention patterns suggest a “backtracking” approach (mentally moving from the target back to the center).
- When pushed to longer depths, models often chose the correct spoke but made mistakes partway along it—evidence they tried the right plan but couldn’t carry it through enough steps.
- If you let them write out steps, the ceiling disappears:
- When given chain-of-thought training (explicit backtracking written out), models quickly solved very deep problems (20 steps) with little training.
- This proves the task isn’t inherently too hard—the main problem is discovering the hidden multi-step strategy from only final answers.
Why this matters
- For performance: If a task needs many coordinated steps, current models struggle to discover and carry out that plan silently. They often need to write down their reasoning to succeed.
- For safety and oversight: Because deep hidden planning is limited, requiring models to show their work (chain-of-thought) is not just helpful—it’s often necessary. That supports “CoT monitoring,” where humans review the model’s steps to understand and supervise it.
A short note on limits of the study
- The tests used “star” graphs to remove shortcuts and precisely control difficulty. Real-world problems can offer hints or patterns that might help. Still, these results show a clear lower bound: even in this clean setup, hidden multi-step planning hits a ceiling.
- The exact numbers (like 5 or 7 steps) may change with future models, but the overall pattern—discovery is hard, execution is easier, and depth beats scale—was consistent across models tested.
Bottom line
Today’s LLMs can plan a few steps ahead silently, but they hit a “depth ceiling” when the plan gets longer. Making the model bigger helps it handle more choices but doesn’t solve the depth problem. If we want models to solve deeper, multi-step problems reliably, we usually need to let them write out their reasoning—or teach those strategies explicitly. That’s good news for using chain-of-thought as both a performance booster and a safety tool.
Knowledge Gaps
Below is a single, concrete list of unresolved gaps, limitations, and open questions that future work could address:
- Generality beyond star graphs: test whether the depth ceiling persists on other topologies (e.g., balanced trees, grids/mazes, random graphs, directed/weighted graphs, graphs with cycles) where shortest-path structure and local cues differ.
- Task formulation: evaluate whether requiring the full path (not just the first hop) or alternative outputs (e.g., next-hops at multiple depths, target verification) changes discovery and execution ceilings.
- Heuristic-rich settings: introduce graphs with informative local heuristics to quantify how much heuristics reduce discovery difficulty versus genuinely deeper latent planning.
- Graph encoding choices: assess sensitivity to input format (edge lists vs adjacency matrices, edge ordering/randomization, canonicalization), tokenization schemes, and positional embeddings (RoPE/ALiBi) on discoverability.
- Architecture ablations at scale: systematically vary depth, width, number of heads, attention patterns (local/global), recurrence (e.g., Transformer-XL), memory modules, and MoE to isolate which components constrain latent planning depth.
- Inference-time recurrence without external tokens: explore mechanisms that permit latent iteration across layers or time (e.g., iterative refinement with reused hidden states) while still prohibiting externalized tokens, and measure effects on depth.
- Verification of “single forward pass” constraints: develop stronger guarantees/diagnostics that proprietary models (e.g., GPT-5.4 with “reasoning effort = none”) are not using hidden multi-pass computation.
- Mechanistic evidence for strategy: go beyond attention-based BR by applying causal interpretability (activation patching, causal scrubbing, head/neuron ablations) to confirm whether backtracking (vs forward BFS) is actually implemented.
- Failure localization: measure at which internal “step” execution breaks (e.g., identify the specific backtracking hop where errors concentrate) to pinpoint depth-dependent bottlenecks.
- Breadth vs depth disentanglement: quantify memory/representation demands of branch indexing and track how breadth-related capacity limits interact with depth-related discovery limits.
- Data scaling laws: map sample complexity vs planning depth (m) across orders of magnitude more data to test whether discovery ceilings shift with data alone and where returns diminish.
- Optimization dynamics: probe sensitivity to optimizers, schedules, label smoothing, auxiliary regularizers, and initialization; characterize metastability and run-to-run variance in the two-stage learning dynamics.
- Curriculum minimality: identify the minimal curriculum (fraction and distribution of shallow depths) required to unlock deep latent planning without explicit step supervision.
- Alternative objectives under implicit-only constraint: test auxiliary losses that do not externalize reasoning (e.g., masked edge prediction, contrastive path consistency, latent-state consistency) for improving discovery.
- RL without visible scaffold: design RL setups that enforce hidden-state-only planning (e.g., illegible intermediate tokens, auxiliary entropy minimization) and evaluate whether credit assignment improves discovery depth.
- Few-shot prompting variables: study how demonstration diversity, ordering, and depth in context affect discovery, and whether “in-context CoT but no CoT output” alters the ceiling.
- Pretraining influences: analyze whether code-heavy or algorithmic pretraining, larger token budgets, or synthetic curricula in pretraining shift discovery vs execution ceilings.
- Position of the ceiling in stronger frontier models: when fine-tuning becomes available, test whether GPT-5.x-class models surpass the seven-step few-shot ceiling and whether gains come from discovery or only execution.
- Domain transfer: probe depth ceilings in non-graph tasks with controlled latent-step counts (multi-hop QA without shortcuts, formal languages like an bn, pointer-following, parity, algorithmic string transformations, math proof subgoals).
- Multimodal latent planning: assess whether analogous depth ceilings emerge in vision-language planning tasks (e.g., instruction-following in image-based mazes) under implicit-only constraints.
- Statistical thresholds and multiple testing: evaluate robustness of LPC conclusions to different α-levels, multiple-comparison corrections, and alternative skill metrics.
- Sequence length and context effects: disentangle impacts of input length vs planning depth by fixing token budget and varying m, and test whether longer contexts or memory compression mitigate discovery limits.
- Decoding strategies: test whether sampling + self-consistency (without external CoT) improves latent planning execution vs greedy decoding, and whether it shifts the ceiling.
- Distillation and re-internalization at scale: extend ICoT-style compression to larger models and harder graphs to test whether explicit-to-implicit distillation can reliably surpass the discovery ceiling without sacrificing breadth.
- Safety implications: assess whether adversarial incentives can push models to covertly compute more steps latently despite the ceiling, and develop monitors that can detect partial latent execution plus partial externalized CoT.
Practical Applications
Summary
This paper identifies a “depth ceiling” in current LLMs’ ability to discover and execute multi-step planning strategies entirely within a single forward pass (latent reasoning) when trained only with final-answer supervision. Small transformers discover up to three latent planning steps; fine-tuned GPT-4o/Qwen3-32B reach five; GPT-5.4 achieves seven with few-shot prompting. Once a latent strategy is discovered, models can generalize it a few steps further at test time (up to eight), but they fail to discover deeper strategies under sparse supervision alone. Externalizing reasoning via chain-of-thought (CoT) immediately circumvents this bottleneck (solving 20-step cases with minimal training). The work introduces practical probes and metrics (e.g., Latent Planning Capacity, attention-based backtracking ratio) and shows scaling helps planning breadth more than depth. These findings have direct implications for how to design, deploy, train, evaluate, and regulate LLM-based systems.
Below are practical applications, grouped by deployment horizon.
Immediate Applications
The following applications can be implemented now with existing tools and workflows.
- CoT-first deployment policies for complex tasks
- Sector: software, healthcare, finance, education, policy
- Use: Default to step-by-step reasoning (CoT) or tool-based planning for tasks likely to require more than ~5–7 latent steps (e.g., long-horizon analysis, multi-stage decisions).
- Tools/workflows: CoT-enabled prompts; “explain your steps” templates; enforced rationale fields in UIs.
- Dependencies/assumptions: CoT logging is available and not deliberately suppressed; privacy/compliance processes for storing rationales.
- Depth-aware routing in agent frameworks
- Sector: software/AI agents, enterprise automation
- Use: Route tasks predicted to require deeper multi-step planning to explicit planners (e.g., programmatic search, symbolic solvers) or to CoT mode; keep shallow tasks in single-pass mode.
- Tools/workflows: Simple heuristics (task length/structure), pilot “depth” classifiers calibrated on LPC; integration with planning libraries (A*, BFS), program synthesis modules, or tool-calling workflows.
- Dependencies/assumptions: Access to tool-execution environment; latency/cost tolerance for multi-step execution.
- Adopt the paper’s metrics for evaluations
- Sector: ML evaluation, MLOps
- Use: Include Latent Planning Capacity (LPC) and empirical skill in eval dashboards; monitor planning breadth vs depth; add attention-based Backtracking Ratio (BR) probes for strategy audits.
- Tools/workflows: Internal eval suites; implement star-graph tasks across k (breadth) and m (depth); simple attention inspection for smaller models.
- Dependencies/assumptions: For proprietary LLMs, attention probes may not be available; rely on behavioral metrics and error structure instead.
- Training curricula that mix depths to bootstrap strategies
- Sector: model training/finetuning
- Use: When latent execution is desired, train on a curriculum containing shallow depths alongside deeper instances to enable discovery and subsequent generalization (as prior work suggests).
- Tools/workflows: Data schedulers; synthetic generators controlling planning depth; progressive difficulty pipelines.
- Dependencies/assumptions: Access to finetuning; compute budget; curriculum does not leak shortcuts.
- CoT-to-implicit compression for performance
- Sector: model optimization
- Use: Train with explicit backtracking CoT to teach the algorithm, then apply ICoT/implicit-CoT methods to compress parts of the reasoning back into latent space for speed.
- Tools/workflows: CoT finetuning; ICoT or distillation frameworks; regression tests on LPC.
- Dependencies/assumptions: Distillation success depends on model capacity and task structure; privacy considerations for CoT traces.
- Error analytics to diagnose “depth ceiling” failures
- Sector: MLOps, QA, research
- Use: Use on-path vs off-path error decomposition to identify when models find the right branch but fail to complete all planning steps; prioritize CoT/tooling for those cases.
- Tools/workflows: Structured error tagging; dashboards highlighting on-path error ratios as depth increases.
- Dependencies/assumptions: Task representations that support structural error labeling.
- Product design for transparency in high-stakes domains
- Sector: healthcare, finance, legal, public sector
- Use: Require structured CoT reports for differential diagnosis, risk analysis, or legal reasoning; gate single-pass outputs behind review if estimated depth is high.
- Tools/workflows: Templates (e.g., differential diagnosis schemas, investment memo outlines); reviewer workflows; red-teaming with controlled-depth tasks.
- Dependencies/assumptions: Human oversight capacity; regulatory constraints on logging and disclosure.
- Data and compute prioritization
- Sector: ML program management
- Use: Avoid spending large budgets trying to learn deep latent planning at a single fixed depth under only final-answer supervision; instead, invest in CoT training and/or curricula.
- Tools/workflows: Budget allocation policies; ablation plans that track discovery vs execution.
- Dependencies/assumptions: Organizational alignment on training goals.
- Domain-specific scaffolding for planning-heavy tasks
- Sector: robotics/operations/logistics, software engineering
- Use: Combine LLMs with explicit planners (task-and-motion planners, routing solvers) and require stepwise plans; in code assistants, enforce plan-of-action and unit-test scaffolds.
- Tools/workflows: Agent toolchains (e.g., graph search, OR solvers, simulators), test-driven development scaffolds.
- Dependencies/assumptions: Integration engineering; latency budgets.
- Benchmarking and auditing kits
- Sector: academia/industry benchmarks, safety
- Use: Release star-graph and similar structured latent-depth tasks into eval suites to detect Clever Hans shortcuts and depth ceilings; use as admission tests for new models.
- Tools/workflows: Public benchmark repos; CI hooks to prevent regressions.
- Dependencies/assumptions: Community adoption; maintenance of task generators.
Long-Term Applications
These applications require further research, scaling, or development.
- Architectures with deeper latent planning capacity
- Sector: ML research
- Use: Explore recurrence, memory-augmented transformers, neural algorithmic reasoning modules, or differentiable search components to extend latent planning depth without external tokens.
- Tools/workflows: Recurrent decoding, scratchpad memories, graph neural modules, algorithmic inductive biases.
- Dependencies/assumptions: Training stability; transfer to open-domain tasks.
- Self-discovered curricula and latent-state supervision
- Sector: ML research/training
- Use: Develop training regimes that autonomously expose intermediate planning depths or latent subgoals (e.g., next-latent-state prediction) while preserving generality.
- Tools/workflows: Unsupervised subgoal discovery, latent rollouts, contrastive objectives for multi-step consistency.
- Dependencies/assumptions: Avoiding overfitting to scaffolds; compatibility with large-scale pretraining.
- Depth-aware orchestration for autonomous agents
- Sector: software/robotics/enterprise automation
- Use: Create orchestrators that estimate required planning depth and dynamically choose between single-pass, CoT, search, or programmatic solvers; enforce autonomy gates based on depth.
- Tools/workflows: Depth estimators, policy engines, safety thresholds, fallback trees.
- Dependencies/assumptions: Reliable depth signals; acceptance of performance–latency trade-offs.
- Formal CoT monitoring standards and regulation
- Sector: policy, compliance, safety
- Use: Establish standards for logging, storing, and auditing reasoning traces; specify minimum transparency levels for high-stakes deployments; define conformance tests using LPC thresholds.
- Tools/workflows: Compliance toolkits; cryptographic signing of CoT; third-party audits.
- Dependencies/assumptions: Regulatory will; managing privacy/IP concerns.
- General-purpose planning coprocessors
- Sector: AI infrastructure, software
- Use: Develop reusable “planning coprocessors” (graph search, theorem provers, constraint solvers) that LLMs can call for deep planning—abstracted behind simple APIs.
- Tools/workflows: Service-oriented planning modules; cost-aware routers; caching of subplans.
- Dependencies/assumptions: Interoperability; monitoring of solver reliability.
- Cross-domain latent-depth benchmarks
- Sector: academia/benchmarks
- Use: Build benchmarks that precisely control multi-step depth in domains like theorem proving, code synthesis, math word problems, and robotics, to generalize LPC beyond graphs.
- Tools/workflows: Synthetic generators with guaranteed depth; evaluation harnesses for execution vs discovery.
- Dependencies/assumptions: Agreement on measurement protocols; avoiding heuristic shortcuts.
- Mechanistic interpretability of latent strategies
- Sector: interpretability research
- Use: Extend backtracking-ratio-style probes to other domains; identify circuit motifs for latent multi-step computation; develop universal “latent depth” diagnostics.
- Tools/workflows: Attention flow analyses, probing classifiers, activation patching for depth-tracking.
- Dependencies/assumptions: Access to model internals; robustness across scales.
- Adaptive compute and token budgeting
- Sector: inference systems, cloud AI
- Use: Build systems that allocate more tokens (CoT) or multiple passes when predicted depth is high; otherwise keep low-latency single-pass generation.
- Tools/workflows: Dynamic compute policies; budget-aware scheduling; early-exit criteria tied to depth estimates.
- Dependencies/assumptions: Reliable depth predictors; predictable cost-performance curves.
- High-assurance workflows for safety-critical decisions
- Sector: healthcare, finance, critical infrastructure
- Use: Design workflows that require explicit multi-step reasoning artifacts, tool-assisted plans, and human sign-off for deep-planning tasks; integrate LPC-based gating into SOPs.
- Tools/workflows: Structured decision templates; plan verifiers; audit trails.
- Dependencies/assumptions: Institutional buy-in; training of operators.
- Consumer-facing “transparent mode”
- Sector: consumer assistants, education
- Use: Offer a user-selectable mode where the assistant reveals its reasoning for complex requests and allows step-by-step verification or editing.
- Tools/workflows: UI for rationale viewing and editing; versioned plans; user education.
- Dependencies/assumptions: UX research; privacy considerations.
- Training data pipelines tuned to discovery vs execution
- Sector: ML ops
- Use: Separate phases for (1) strategy discovery with dense supervision/CoT and (2) execution generalization; schedule data to optimize both goals.
- Tools/workflows: Two-stage finetuning; automated detection of discovery failure modes; evaluation gates aligned to LPC.
- Dependencies/assumptions: Sufficient data diversity; careful avoidance of shortcut learning.
- Robustness and red-teaming against latent-only shortcuts
- Sector: safety, security
- Use: Create adversarial tests that look for shallow latent heuristics; enforce CoT monitoring where latent-only success would be risky (e.g., jailbreak defenses, deceptive planning).
- Tools/workflows: Attack suites that vary depth; detectors for hidden rationales; policy rules for mandatory transparency.
- Dependencies/assumptions: Continuous updating as models evolve.
Notes on Assumptions and Dependencies
- Generalization from star-graph findings: While the benchmark cleanly isolates planning depth, real-world tasks may contain heuristics that partially bypass deep planning. Many applications above assume the depth ceiling observed here extends (at least partially) to other domains.
- Model and API constraints: Some proprietary models do not expose attention or allow finetuning; use behavioral metrics (LPC, error structure) and orchestration instead.
- Privacy/compliance: CoT logging and storage raise privacy/IP concerns; deployments must implement appropriate governance controls.
- Cost/latency trade-offs: CoT and tool-calling increase latency and cost; depth-aware routing helps optimize these trade-offs.
- Organizational incentives: Applying curricula, CoT monitoring, and planning coprocessors requires alignment across product, engineering, and safety teams.
Glossary
- Attention heads: Parallel attention subcomponents within a transformer layer that allow multiple representation subspaces to be attended concurrently. "Increasing model depth or the number of attention heads does not overcome this limitation (see Appendix~\ref{appendix:hyperparameters})."
- Attention maps: Visualizations of attention weight patterns that reveal which tokens or graph elements a model focuses on. "We further conduct a qualitative analysis by visualizing the attention maps of the trained transformer (see Appendix~\ref{appendix:attention_visualization})."
- Autoregressive transformer: A transformer that predicts each next token conditioned on all previous tokens in the sequence. "we train an autoregressive transformer following the standard GPT-2 architecture \citep{radford2019language} from-scratch, using GELU \citep{hendrycks2016gaussian} as the activation function."
- Backtracking: A strategy that traces the path from target back to source through sequential steps. "Attention analysis on the transformer trained from scratch suggests that successful models learn a backtracking strategy that concentrates attention along the target-to-source path."
- Backtracking ratio (BR): A metric quantifying how much attention mass is allocated to edges on the true target-to-source path. "we define a backtracking ratio (BR) that measures the fraction of edge-token attention allocated to edges on the path between $v_{\mathrm{target}$ and $v_{\mathrm{source}$ (formal definitions are provided in Appendix~\ref{appendix:attention_probing})."
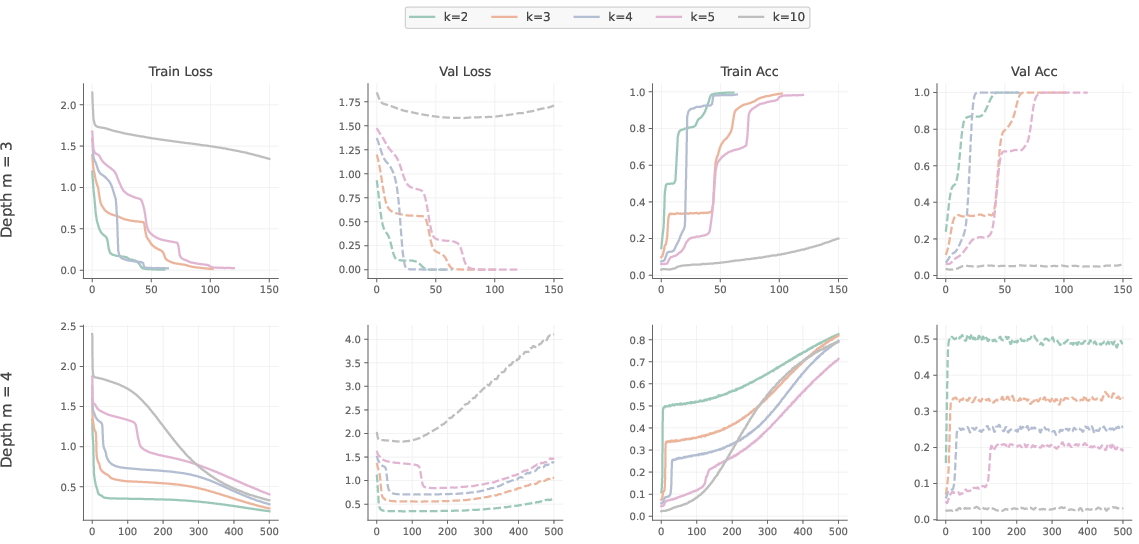
- Bootstrapping: Leveraging simpler learned behaviors to build and generalize to more complex strategies. "such curricula allow models to bootstrap simpler strategies to more complex cases."
- Breadth-first approach: A forward strategy that expands all branches level-by-level in parallel when searching a graph. "The most natural variant is a parallel breadth-first approach, in which the model simultaneously tracks all branches, advancing one depth level per computational step and checking at each level whether any branch reaches $v_{\mathrm{target}$."
- Chain-of-thought (CoT): Explicit, step-by-step intermediate reasoning produced as text tokens. "Chain-of-thought (CoT) reasoning is one of the main drivers of progress in LLMs."
- Clever Hans cheat: Exploiting superficial cues or shortcuts instead of performing the intended reasoning. "causing models to exploit superficial greedy shortcuts (the Clever Hans cheat), though their analysis does not examine shallow planning depths where success may still be possible."
- Cross-entropy loss: A standard probabilistic loss for next-token prediction that penalizes divergence from the target distribution. "All models are trained via standard next-token prediction with cross-entropy loss on the final answer, without supervision on intermediate reasoning steps (see Appendix~\ref{appendix:ntp} for details)."
- Critical threshold: The minimum empirical skill needed to statistically exceed chance performance at a given confidence level. "where $\tau_{\mathrm{crit}(k, \hat{N}, \alpha)$ denotes the minimum empirical skill required to reject random guessing"
- Depth-first variant: A search strategy that explores one branch fully before backtracking to try others. "A sequential depth-first variant, which fully traverses one branch before returning to try the next, is less plausible: it requires up to steps in the worst case"
- Distillation: Transferring behavior or representations from a teacher model into a student model by matching internal signals. "CODI \citep{hao2024training} distills hidden states from a teacher model with full CoT."
- Empirical skill: A normalized performance measure that adjusts accuracy relative to the chance baseline for a given branch factor. "we therefore first normalize accuracy into an empirical skill score , where a value of $1$ indicates perfect performance and $0$ corresponds to random guessing"
- Externalize their reasoning: Produce intermediate reasoning steps as explicit tokens rather than keeping them latent. "in a control setting where models are allowed to externalize their reasoning by training with a backtracking strategy in the chain of thought, they successfully solve graphs requiring twenty lookahead steps"
- Few-shot prompting: Providing a small number of in-context examples to guide model behavior without parameter updates. "attains seven under few-shot prompting."
- Forward pass: A single execution of a model to produce outputs without iterative internal deliberation across tokens. "execute them latently, within a single forward pass."
- GELU: Gaussian Error Linear Unit, a smooth nonlinearity used in neural network layers. "using GELU \citep{hendrycks2016gaussian} as the activation function."
- Generalization ceiling: The maximum depth beyond training at which a discovered strategy continues to work at test time. "This leads to a slightly higher
generalization ceiling' at eight steps than thediscovery ceiling' at seven steps (Figure \ref{fig:lpc_bar})." - Greedy decoding: Decoding by selecting the highest-probability token at each step without search. "under greedy decoding."
- Hidden reasoning trace: An internal chain-of-thought mode that some models can produce but which can be disabled. "To ensure a fair comparison, we disable the hidden reasoning trace of GPT-5.4 by setting the reasoning effort parameter to none"
- ICoT framework: A method for compressing explicit chain-of-thought into latent representations. "using the ICoT framework \citep{deng2023implicit,deng2024explicit}"
- Illegible intermediate tokens: Non-readable tokens inserted to stand in for hidden reasoning steps without exposing content. "inserting illegible intermediate tokens in place of explicit reasoning traces \citep{bachmann2024pitfalls}."
- Induction heads: Learned attention patterns that copy or continue patterns from earlier in the sequence. "a shortcut achievable through shallow pattern-matching mechanisms such as induction heads \citep{olsson2022context}."
- Latent planning: Multi-step planning performed within hidden representations without emitting intermediate tokens. "We study latent planning using path-finding on star graphs."
- Latent planning capacity (LPC): A binary indicator of whether performance at a given depth exceeds chance by a statistically significant margin. "we define the latent planning capacity (LPC) to capture whether a model exhibits any statistically significant evidence of planning at a given depth ."
- Latent reasoning: Reasoning carried out in a model’s internal representations rather than in explicit text. "Yet little is known about the limits of such latent reasoning in LLMs."
- Lookahead steps: The number of future steps a model must mentally simulate to plan correctly. "models can solve instances requiring many latent lookahead steps"
- Next-token prediction: Training objective where the model predicts the next token given previous tokens. "We train with next-token prediction because reinforcement learning settings typically permit reasoning to be externalized through intermediate tokens, making latent planning difficult to enforce."
- Out-of-distribution (OOD) generalization: Performance on test cases that differ from the training distribution, such as longer depths. "Out-of-distribution (OOD) generalization of latent planning across depths."
- Overfitting: Memorizing training data rather than learning a generalizable strategy. "whereas failure results in the model simply memorizing the training graphs and overfitting."
- Random baseline: The chance level of accuracy given uniform guessing over available options. "Since tasks with different branch factors yield different random baselines, raw accuracy does not allow fair comparison across configurations."
- Random guessing: Selecting answers uniformly at random, providing a chance-performance reference. "statistically distinguishable from random guessing"
- Reinforcement learning: Training paradigm where behavior is optimized via reward signals rather than supervised targets. "reinforcement learning settings typically permit reasoning to be externalized through intermediate tokens"
- Separator token: A special token used to delimit structural segments in the input encoding. "s is a separator token between edges"
- Significance level: The predefined probability threshold for rejecting a null hypothesis in statistical testing. "at significance level "
- Star graphs: Graphs with a central hub and multiple equal-length branches emanating from it. "We study latent planning using path-finding on star graphs."
- Strategy discovery depth ceiling: The maximum planning depth at which a model can learn a strategy under sparse final-answer supervision. "Strategy Discovery Depth Ceiling To efficiently identify the maximum depth at which each model can discover a planning strategy, we adopt a progressive training procedure."
- Two-stage learning process: A learning dynamic where a simple heuristic emerges first, followed by attempted acquisition of the full multi-step strategy. "the model typically exhibits a two-stage learning process."
- Zero-shot prompting: Prompting without any in-context examples. "We evaluate LLMs under zero-shot and few-shot prompting"
Collections
Sign up for free to add this paper to one or more collections.