Learning When Not to Attend Globally
Abstract: When reading books, humans focus primarily on the current page, flipping back to recap prior context only when necessary. Similarly, we demonstrate that LLMs can learn to dynamically determine when to attend to global context. We propose All-or-Here Attention (AHA), which utilizes a binary router per attention head to dynamically toggle between full attention and local sliding window attention for each token. Our results indicate that with a window size of 256 tokens, up to 93\% of the original full attention operations can be replaced by sliding window attention without performance loss. Furthermore, by evaluating AHA across various window sizes, we identify a long-tail distribution in context dependency, where the necessity for full attention decays rapidly as the local window expands. By decoupling local processing from global access, AHA reveals that full attention is largely redundant, and that efficient inference requires only on-demand access to the global context.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper asks a simple question: Do LLMs really need to look at everything they’ve read all the time? Just like a person mainly reads the current page and only flips back when needed, the authors show that LLMs can learn to mostly focus on nearby words and only look far back when it truly matters. They introduce a method called All-or-Here Attention (AHA) that teaches models when to use full “global” attention and when a small “local window” is enough.
Key questions the paper tries to answer
The paper focuses on three easy-to-understand questions:
- Can an LLM learn to decide, on the fly, whether it needs global context or just the recent few words?
- How often does a model really need global attention if we give it a reasonably sized local window?
- Can we keep model quality the same while using global attention much less?
How the method works (in everyday language)
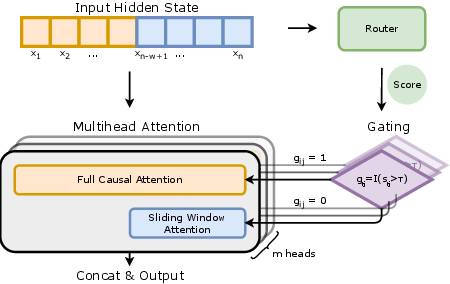
Modern LLMs use “attention” to decide which earlier words to look at when predicting the next word. Full attention looks at all previous words, which can be very expensive for long texts. AHA adds a tiny decision-maker (a “router”) that decides, for each small part of the model (each attention head) and for each word:
- “All”: Use full attention (look at the entire past).
- “Here”: Use local attention (look only at the last w words, like a sliding window).
Think of it like a light switch for each attention head at each step:
- If the switch is ON, the head can see the whole past (global).
- If the switch is OFF, the head sees only a short window (local).
To train these switches, the model:
- Learns an “importance score” between 0 and 1 for each head at each word.
- Compares the score to a threshold (like 0.5). Above it means “use global,” below it means “stay local.”
- Uses a training trick (called a straight-through estimator) that lets it learn good switch positions even though ON/OFF is a hard decision.
To encourage saving compute, the model gets a tiny “penalty” whenever it chooses global attention. You can think of this like charging a small fee for pressing the “global” button. This nudges the model to stay local unless global attention is really needed.
Finally, the authors don’t retrain a model from scratch. They take an existing model (OLMo-2, already trained) and fine-tune it with AHA added, so it works as a drop-in improvement.
Main results and why they matter
The authors test AHA on a variety of tasks (like question answering, math problems, coding, and summarizing) and try different local window sizes (w = 16, 32, 64, 128, 256). Here’s what they find:
- With a local window of 256 words, the model uses global attention only about 6–7% of the time, which means it can skip around 93% of the usual global-attention work—without losing performance. In fact, performance slightly improves on average in their tests at w = 256.
- Even with much smaller windows (like 128), the model still does very well. At w = 128, it uses global attention only about 12% of the time while matching or slightly beating the original model.
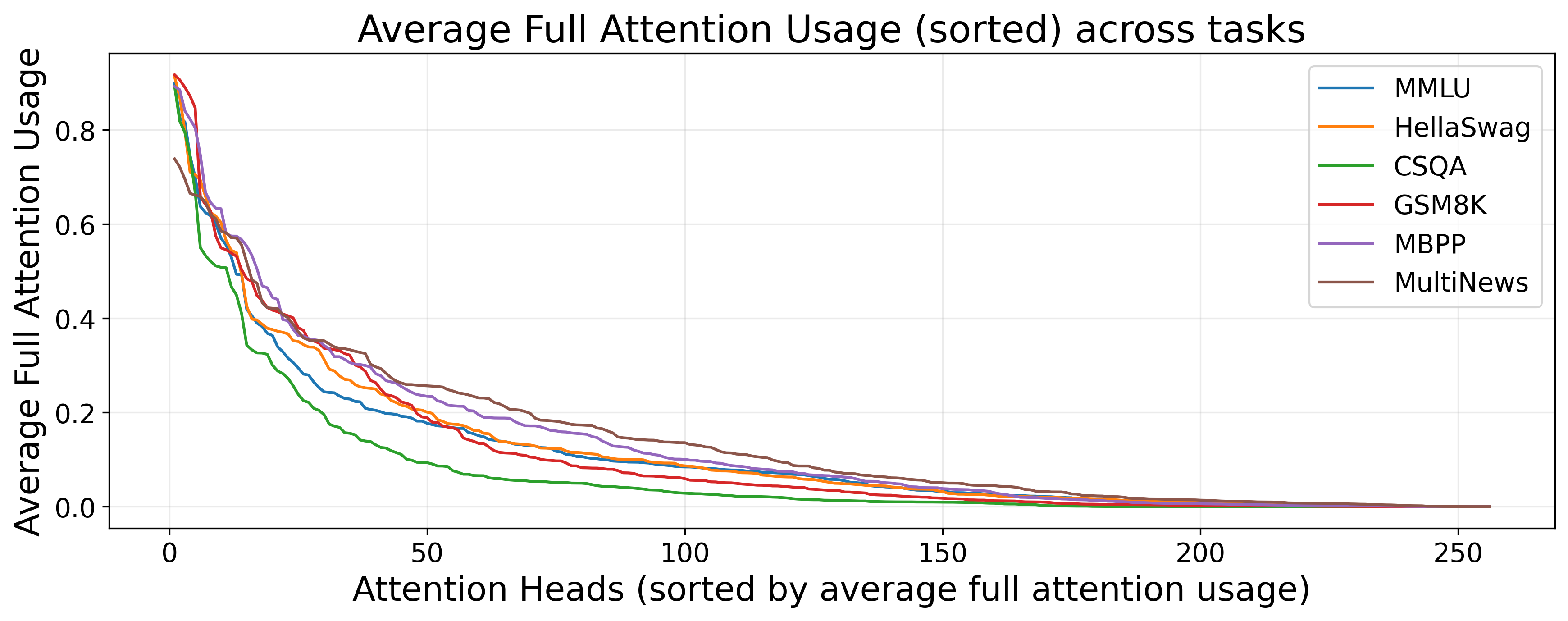
- The need for global attention drops quickly as the local window gets bigger. This is a “long-tail” pattern: most of the time, nearby context is enough; only a small number of cases truly need far-away information.
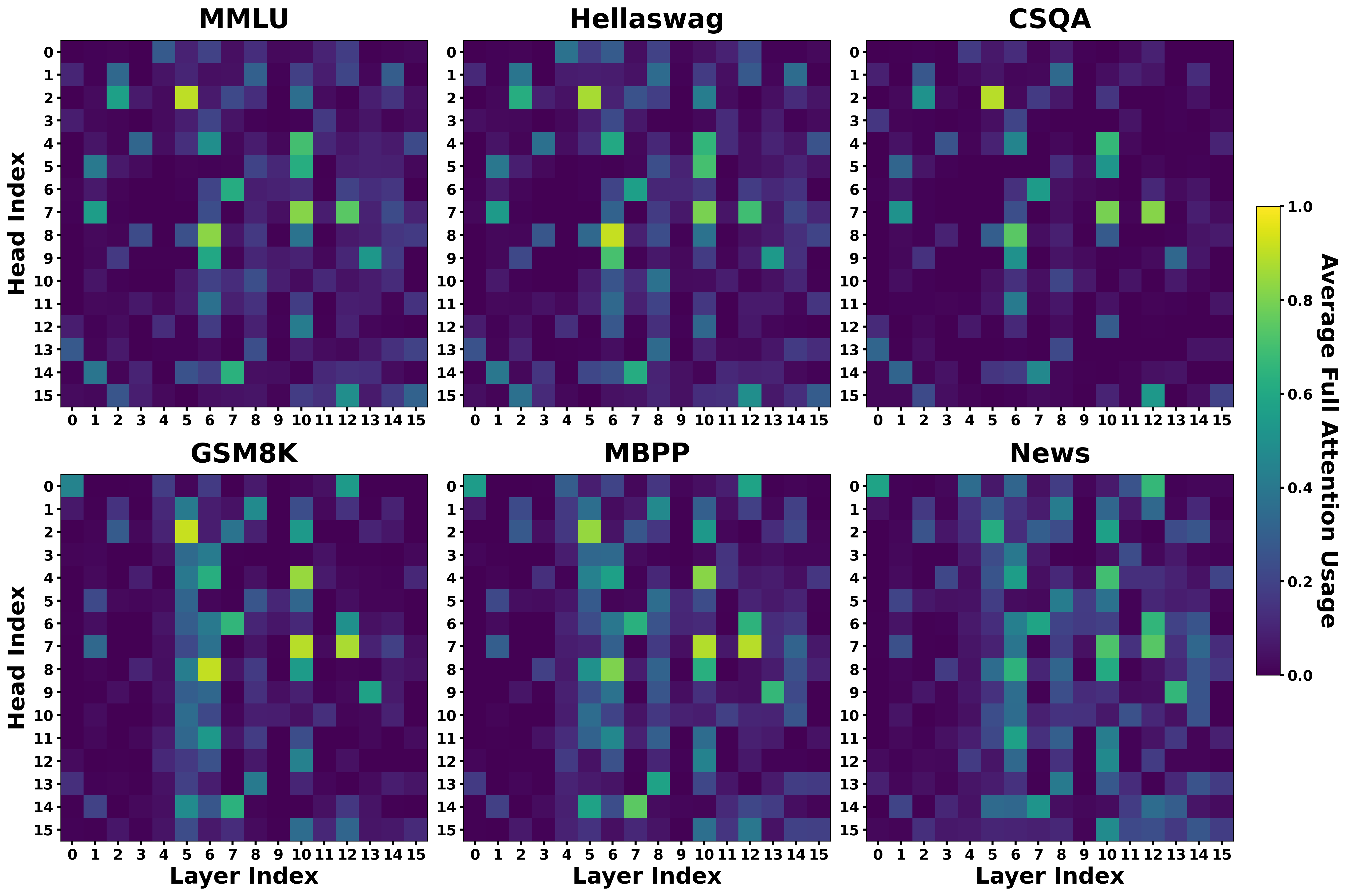
- The model learns a “division of labor” among attention heads. A few “heavy-hitter” heads do most of the global work; most heads stay local almost all the time.
- If the local window is tiny (like 16), the model smartly turns on global attention more often to compensate, and still keeps most of its performance.
Why this matters: Full attention is the most expensive part of long-context processing. AHA shows that models can keep quality while using global attention much less often. This points to big potential savings in memory and compute for long documents.
What this could mean going forward
The big idea is simple but powerful: don’t always pay the price of global attention—use it only when needed. This could make LLMs faster and cheaper on long texts, help them run better on limited hardware, and guide future designs that focus on smart, on-demand access to the full context.
There are two important caveats:
- The paper mostly analyzes how often global attention is used, not actual speedups on hardware. Getting real-world speedups will need new, efficient software kernels that handle this kind of dynamic switching.
- The experiments are on one base model (OLMo-2). Testing on more models and tasks would strengthen the claim.
Overall, AHA suggests a practical path: keep local processing as the default and “flip back” to the full context only when the model truly needs it. This could make long-context AI more efficient without sacrificing accuracy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that the paper leaves open, focusing on what is missing, uncertain, or unexplored:
- Lack of system-level evaluation: no measurements of wall-clock speedup, throughput, latency, or energy savings under realistic serving scenarios (prefill vs. decode, batch sizes, KV-cache strategies).
- Hardware/kernel readiness: no implementation or benchmark of hardware-aware kernels for dynamic per-head, per-token routing (e.g., bucketed execution, ragged tensors, CUDA kernels aligned with AHA’s heterogeneity).
- Memory management with KV caches: unclear whether KV storage can be reduced when most heads use local windows, given that any global head may still require full-prefix keys; no strategy for memory reclamation or selective KV eviction.
- Training–inference window mismatch: AHA is trained and evaluated with matched window sizes; robustness when inference window differs (smaller/larger) remains untested.
- Threshold sensitivity: fixed gating threshold (τ=0.5) is not ablated; unknown effects of τ on sparsity, accuracy, stability, and calibration across tasks and model sizes.
- Router design choices: the router is a single linear projection per layer; no exploration of alternative architectures (e.g., multi-layer MLPs, per-head routers, token-type–aware routing, curriculum routing).
- Regularization form: L1 penalty is applied to router scores (not gates); no comparison with L0-style regularizers, entropy penalties, or sparse constraints that directly operate on discrete gates.
- STE training dynamics: no analysis of gradient bias/variance introduced by the Straight-Through Estimator; no comparison to Gumbel-Softmax, REINFORCE, or relaxations with temperature annealing.
- Head-level constraints: no investigation of constraints (e.g., minimum/maximum global attention quota per layer/head) to prevent pathological collapse or overuse; no safety mechanisms for tasks requiring guaranteed global access.
- Scope granularity: binary “global vs. one local window” only; multi-choice window sizes, adaptive span distributions, or learned per-layer/per-head span catalogs are suggested but not evaluated.
- Interaction with other efficiency methods: no controlled comparisons or integrations with adaptive attention span, block-sparse patterns, MoE, Mixture-of-Depths, state-space models (e.g., Mamba), or FlashAttention variants.
- Scalability across model sizes: results are limited to a 1B model; unknown whether sparsity patterns and performance retention hold for mid- and large-scale models (7B–70B+).
- Pretraining integration: AHA is applied via SFT only; effects on pretraining objectives, perplexity, stability, and long-range representation learning are not studied.
- Task coverage for long-range dependencies: limited evaluation of extreme long-context tasks (e.g., Long Range Arena, “needle-in-a-haystack,” book-level QA, codebase-scale reasoning); unclear failure modes when deep retrieval is needed.
- Cross-domain and multilingual generalization: evaluations focus on English instruction/data; no tests across languages, domains (law, biomedical), or noisy/structured inputs (tables, code repositories).
- Robustness and safety: no analysis of adversarial prompts, prompt injection, or contexts engineered to suppress global routing decisions; no evaluation of safety/alignment impacts.
- Variance and reproducibility: single-seed, single-epoch SFT; no reporting of variance across seeds, epochs, datasets, or alternate training schedules; statistical significance of “retained performance” not established.
- Metric aggregation methodology: “Retain %” aggregates heterogeneous metrics (Acc, EM, ROUGE, Pass@1); the normalization/weighting scheme and its statistical validity are not specified.
- Token-level analysis: no fine-grained study of which token types or linguistic phenomena trigger global attention (e.g., coreference, entity linking, section transitions); no diagnostics to inform router design.
- Head specialization interpretation: observed “always-on” vs. sparse heads are not functionally characterized; unclear whether static assignment (fixed global/local heads) could match AHA while simplifying kernels.
- Cost of routing: the compute/memory overhead of routers and gate computation is not measured; net savings vs. added overhead under different batch sizes and sequence lengths are unknown.
- Impact on gradient flow and learning: with local windows, distant tokens do not receive attention gradients; implications for learning long-range dependencies (especially under pretraining) remain unexplored.
- Streaming and online settings: behavior under streaming inputs, chunked decoding, and sliding contexts is not evaluated; policies for revisiting earlier chunks when global routing is triggered are unspecified.
- Data filtering effect: samples shorter than the window were filtered to ensure sliding-window operation; how this filtering biases evaluation and real-world applicability is not analyzed.
- Failure case analysis: tasks with notable drops at small windows (e.g., CSQA, News) are not dissected; missing error analysis to identify dependency types that require global attention.
- Practical deployment heuristics: no guidance on choosing λ, τ, window sizes, or per-task configurations to balance accuracy and efficiency under production constraints.
- Combining retrieval augmentation: how AHA interacts with external memory/RAG systems (e.g., routing global attention to retrieved chunks instead of entire prefixes) is not investigated.
Practical Applications
Immediate Applications
The following applications can be deployed today, leveraging the paper’s findings that most tokens only need local context and that a simple binary router can reliably toggle between local and global attention without degrading performance at window sizes of 128–256.
- Efficient long-context inference for existing LLMs (software/cloud)
- What: Adapt decoder-only LLMs by replacing full attention modules with AHA and running a brief supervised fine-tuning on in-domain data.
- Use cases: Customer support chatbots, document summarization, code assistants, multi-step reasoning services where typical contexts exceed 1k tokens.
- Tools/products/workflows: AHA router layer for HuggingFace/Transformers; model cards that include “Average Full Attention Usage” (μf) to report efficiency; inference configs with w=128 or w=256.
- Assumptions/dependencies: Inference window size must match training; measured performance validated on OLMo-2-1B SFT; wall-clock speedups depend on attention kernels; minor integration effort to patch attention layers.
- Cost and throughput optimization for model serving (software, cloud infrastructure)
- What: Reduce average full-attention activations by 90%+ at w=256, cutting attention FLOPs and memory bandwidth per token.
- Use cases: Multi-tenant LLM APIs, call center analytics, bulk summarization pipelines, asynchronous batch processing.
- Tools/products/workflows: Gating-aware throughput dashboards; capacity planning using μf to forecast compute per token; autoscaling policies tuned to expected gating rates.
- Assumptions/dependencies: Dynamic routing can cause heterogeneous compute within a batch; gains in token throughput depend on scheduler and kernel support.
- On-device assistants and keyboards with longer contexts (consumer, mobile/IoT)
- What: Deploy AHA-enabled small LLMs on mobile/edge devices while maintaining quality with w=128–256.
- Use cases: Smart keyboards, email drafting, offline personal assistants with local document context.
- Tools/products/workflows: AHA-enabled inference builds for llama.cpp, Android NNAPI/Metal; energy-aware profiles using μf to manage battery life.
- Assumptions/dependencies: Limited memory and compute budgets; real-world speed depends on mobile kernels that handle sliding-window attention efficiently.
- RAG and context-chunking workflows that default to local (software, enterprise knowledge)
- What: Combine AHA with retrieval systems so tokens default to local window; global attention activates only when strictly needed.
- Use cases: Knowledge workers processing large corpora; helpdesk systems; long-brief generation.
- Tools/products/workflows: Chunked context windows aligned to w; routers log attention triggers to flag “global dependency” spans.
- Assumptions/dependencies: Router must be fine-tuned on the target RAG workload; retrieval cadence and chunk boundaries should align with local window size.
- Head pruning and compression guided by gating statistics (software, ML tooling)
- What: Use μf per head to identify “always-local” heads and prune or quantize them aggressively, preserving “heavy-hitter” global heads.
- Use cases: Model slimming for deployment on constrained hardware; targeted distillation.
- Tools/products/workflows: Pruning scripts using sorted μf; retraining checkpoints with pruned head sets; evaluation harness integration.
- Assumptions/dependencies: Post-pruning fine-tuning required; impact varies across tasks; careful validation needed on reasoning-heavy workloads.
- Attention observability and task profiling (academia, applied ML)
- What: Instrument models to log μf across layers/heads and quantify long-tail dependencies per task.
- Use cases: Dataset curation; discovering domain-specific long-range needs; linguistic studies of dependency lengths.
- Tools/products/workflows: Eval harness plugins; dashboards showing attention activation density by task.
- Assumptions/dependencies: Requires reproducible evaluation settings; interpreting μf across models needs consistent thresholds and windows.
- Carbon/ESG reporting for LLM inference (policy, sustainability)
- What: Use μf as a standardized, model-internal metric that correlates with attention compute to estimate carbon footprint per token.
- Use cases: ESG disclosures for AI services; procurement and energy benchmarking.
- Tools/products/workflows: Reporting templates that include μf and window size; back-of-envelope energy models tied to attention FLOPs.
- Assumptions/dependencies: Mapping μf to energy is approximate and hardware-dependent; policy adoption needs consensus.
- Real-time streaming with selective global access (media, operations)
- What: Use AHA to process long streams (meetings, transcripts) primarily with local windows, spiking to global attention when needed.
- Use cases: Live captioning, meeting summarization, customer call analysis.
- Tools/products/workflows: Sliding buffers sized to w; token-level logs identifying global-access moments for post-hoc inspection.
- Assumptions/dependencies: Performance depends on long-range salience of the stream; latency improvements hinge on kernel support.
- Safer prompting via reduced global exposure (software, security)
- What: Defaulting to local attention may limit inadvertent reliance on distant, potentially adversarial prompt segments; global retrieval becomes explicit and rare.
- Use cases: Prompt-injection-resistant assistants; content moderation aids.
- Tools/products/workflows: Router telemetry to flag unexpected global triggers; guardrails that audit global-access events.
- Assumptions/dependencies: Security gains are contingent and unproven; rigorous adversarial testing required.
Long-Term Applications
These applications will benefit from further research, scaling, kernel/hardware development, and broader ecosystem adoption to fully realize the efficiency implied by attention sparsity.
- Dynamic attention kernels and accelerators (semiconductors, systems)
- What: Hardware-aware kernels that natively support heterogeneous token-head windows and conditional execution, turning sparsity into wall-clock gains.
- Tools/products/workflows: “FlashAttention-Dynamic” variants; scheduler-friendly memory layouts; GPU warp-level compaction for variable spans.
- Assumptions/dependencies: Substantial kernel engineering; coordination with framework maintainers; careful handling of dynamic batching.
- Gating-aware serving schedulers and compilers (cloud infrastructure)
- What: Batch formation and graph compilation that group tokens requiring full attention, improving utilization; compile gating decisions into efficient execution plans.
- Tools/products/workflows: Triton/XLA passes for conditional graphs; serving routers that coalesce global-attention tokens across requests.
- Assumptions/dependencies: Accurate, low-latency gating prediction; complexity in multi-tenant environments; trade-offs with latency.
- Multi-choice routing with heterogeneous windows (software, model design)
- What: Extend binary gating to select among multiple local window sizes, optimizing compute-quality Pareto fronts task-by-task.
- Tools/products/workflows: Mixture-of-attention-spans modules; training with window curriculum; adaptive λ regularization by head/layer.
- Assumptions/dependencies: Training stability; additional hyperparameter tuning; new kernels for multi-span execution.
- Integration with Mixture-of-Experts and Mixture-of-Depth (software, model efficiency)
- What: Jointly control which experts/depth are active and how far attention reaches, yielding fine-grained conditional compute.
- Tools/products/workflows: Joint routing networks; unified schedulers that handle expert selection and attention span simultaneously.
- Assumptions/dependencies: Complex training dynamics; balancing load across experts; potential increases in engineering overhead.
- Edge robotics and autonomous systems (robotics)
- What: Real-time LLM controllers that mostly operate on local windows, escalating to global lookback for rare events or task switches.
- Tools/products/workflows: ROS integrations with gating telemetry; safety envelopes limiting global retrieval.
- Assumptions/dependencies: Deterministic latency budgets; certified kernels; extensive validation in safety-critical settings.
- Healthcare and finance document workflows at scale (healthcare, finance)
- What: Long-EHR summarization and compliance review with gated global access to reduce cost while maintaining accuracy on key dependencies.
- Tools/products/workflows: Regulated pipelines with μf reporting; audit trails for global-attention events; human-in-the-loop review of flagged spans.
- Assumptions/dependencies: Regulatory acceptance; robust evaluation on long-range clinical/legal tasks; guardrails for safety and bias.
- Standardization of “Global Attention Reliance” metrics (policy, benchmarking)
- What: Community benchmarks that report μf by task/model and tie it to cost/energy per token as part of model cards and procurement criteria.
- Tools/products/workflows: Shared datasets emphasizing long-range dependencies; governance frameworks adopting μf as a procurement KPI.
- Assumptions/dependencies: Agreement across vendors; reliable mapping from μf to cost/energy; evolving norms.
- Cross-modal conditional attention (vision, multimodal)
- What: Apply AHA-style gating to ViTs and multimodal Transformers to reduce global attention when local receptive fields suffice.
- Tools/products/workflows: Conditional patch attention; multi-scale local windows; kernels supporting variable patch spans.
- Assumptions/dependencies: Research into multimodal dependency structures; kernel support for vision attention patterns.
- Training from scratch with AHA-native architectures (model development)
- What: Pre-train foundation models with AHA to bake in conditional compute and head specialization from the outset.
- Tools/products/workflows: Pretraining curricula emphasizing local-context tasks; router regularization schedules; large-scale infrastructure.
- Assumptions/dependencies: Significant compute; exploration of scaling laws under conditional attention; generalization across domains.
- Adaptive pricing and SLAs for inference (cloud, finance/ops)
- What: Bill and guarantee performance based on measured μf, aligning cost with actual attention compute used per request.
- Tools/products/workflows: μf-based metering; SLAs that specify max global-attention share; customer-side dashboards.
- Assumptions/dependencies: Accurate real-time μf measurement; customer understanding of metrics; safeguards against gaming.
Notes on feasibility across applications:
- The model’s success hinges on task distributions where long-range dependencies are sparse; reasoning-heavy or cross-document tasks may need more frequent global attention.
- Reported results are on OLMo-2-1B SFT; generalization to larger or different architectures and training regimes requires validation.
- Real-world speedups depend on hardware kernels and serving schedulers that can exploit conditional, heterogeneous execution.
- Matching training and inference window sizes is critical; performance may degrade if these diverge.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability. "Optimization is performed using AdamW with a learning rate of , , and ,"
- All-or-Here Attention (AHA): A mechanism that uses binary routing to switch per head between full global attention and local sliding-window attention. "We propose All-or-Here Attention (AHA), which utilizes a binary router per attention head to dynamically toggle between full attention and local sliding window attention for each token."
- Attention head: One of multiple parallel attention sub-modules in a Transformer layer that processes information independently. "a binary router per attention head to dynamically toggle between full attention and local sliding window attention for each token."
- Causal attention: Attention constrained to the prefix (past tokens) to preserve autoregressive generation. "A lightweight router computes importance scores for each head, generating binary gates that dynamically toggle between full causal attention and local sliding window attention."
- Conditional computation: A design where parts of the model are activated selectively based on inputs to reduce compute. "In this section, we detail the proposed All-or-Here Attention (AHA), which introduces a conditional computation mechanism into the attention layer."
- Cross-entropy loss: A standard objective for language modeling that measures the difference between predicted and true token distributions. "where $\mathcal{L}_{\text{LM}$ is the standard cross-entropy loss for next-token prediction,"
- Decoder-only Transformer: A Transformer architecture composed solely of decoder blocks, typically used for autoregressive language modeling. "Beyond the specific modifications to the attention mechanism, our architecture strictly adheres to the standard decoder-only Transformer design~\cite{gpt,llama}."
- FlashAttention: A highly optimized attention kernel that is fast and memory-efficient with IO-awareness. "e.g., FlashAttention~\cite{flashattn}"
- Gated attention: An attention variant that uses soft gates to modulate and fuse features. "This represents a fundamental departure from methods such as gated attention~\cite{gateddeltanet, gatedattention} and hierachical attention~\cite{deepseeknsa, hierarchical,deepseekv32},"
- Indicator function: A discrete function that outputs 1 if a condition holds and 0 otherwise, used here for binary gating. "where is the indicator function, and is a pre-defined threshold."
- L1 penalty: A regularization term that encourages sparsity by penalizing the absolute values of parameters or scores. "we apply an L1 penalty to the router scores across the entire network."
- Linear attention: Attention formulations that scale linearly with sequence length, reducing quadratic complexity. "including linear attention~\cite{linearattn,mamba,gateddeltanet}, sparse attention~\cite{sparsetransformer,longformer,bigbird}, and hierarchical attention~\cite{hierarchical,deepseeknsa}."
- Long-range dependencies: Relationships between tokens that span large distances in the sequence. "global retrieval is necessary only for a sparse subset of tokens resolving long-range dependencies~\cite{dependency1,dependency2,dependency3,longformer}."
- Long-tail distribution: A distribution where most events are near the head and a few rare events form a long tail; here describing context dependency. "we identify a long-tail distribution in context dependency, where the necessity for full attention decays rapidly as the local window expands."
- Mixture-of-Depths: A conditional computation approach that dynamically selects which layers (depth) to execute. "mixture-of-depth~\cite{mod}."
- Mixture-of-Experts: A conditional model that routes inputs to a subset of expert modules to save compute and specialize behavior. "mixture-of-experts~\cite{Shazeer2017MoE}, and mixture-of-depth~\cite{mod}."
- Normalized accuracy (Acc_norm): An evaluation metric that adjusts accuracy to account for dataset biases (used in HellaSwag). "normalized accuracy (Acc_norm) for HellaSwag,"
- Regularization hyperparameter: A scalar that controls the strength of a regularization term to balance performance and sparsity. "and is a regularization hyperparameter controlling the trade-off between task accuracy and attention sparsity."
- Router: A lightweight linear module that produces importance scores to decide per-head whether to use global or local attention. "we integrate lightweight routers at each Transformer layer to generate scalar importance scores."
- Scaled dot-product attention: The standard attention computation that scales dot products of queries and keys before softmax. "The function follows the standard scaled dot-product formulation."
- Sliding window attention: Attention restricted to a fixed-size local window of recent tokens to reduce computation. "dynamically toggle between full attention (\"All\") and local sliding window attention (\"Here\") for each attention head."
- Sparse attention: Attention that limits token interactions to a subset, reducing memory and compute. "sparse attention~\cite{sparsetransformer,longformer,bigbird},"
- Straight-Through Estimator (STE): A gradient approximation technique that enables training with non-differentiable discrete decisions. "we employ the Straight-Through Estimator (STE)~\cite{ste}."
- Supervised Fine-Tuning (SFT): Post-training on labeled data to adapt a pre-trained model to downstream tasks. "A standard, fully pre-trained Transformer can be seamlessly adapted by replacing its full attention modules with AHA, followed by continued Supervised Fine-Tuning (SFT)."
- Window size: The number of recent tokens included in local attention; a key parameter controlling context range. "with a window size of 256 tokens, up to 93\% of the original full attention operations can be replaced by sliding window attention without performance loss."
Collections
Sign up for free to add this paper to one or more collections.