- The paper identifies a sparse, gate-amplifier routing circuit that drives policy decisions through detection and amplification mechanisms in LLMs.
- The paper employs a three-step pipeline—DLA screening, ablation, and interchange tests—to localize and validate the causal role of gate and amplifier heads.
- The paper demonstrates that modulating detection-layer activations enables controlled shifts in model behavior, while cipher encoding exposes vulnerabilities in recognition and routing.
Overview of the Routing Circuit
This paper elucidates a recurring sparse routing motif underpinning policy decisions in alignment-trained LLMs. The mechanism is formalized as a gate-amplifier attention circuit: a gate head at an intermediate layer reads a contextual detection signal regarding input sensitivity, and its activation triggers downstream amplifier heads at deeper layers. These amplifiers boost the routing vector through subsequent MLPs and attention pathways, causing the model to select a target policy—ranging from factual response to evasion or outright refusal.
The routing process initiates after the formation of a detection representation (typically at layers 15–16), which is contextual and compositional rather than keyword-based. The gate head acts as a minimal carrier yet is causally necessary, evidenced by targeted activation swaps and ablation studies showing that removal or modification of the gate’s activation suppresses amplifier activity and alters the behavioral output. Critically, the model’s decision regime—refusal, evasion, steering, or compliance—maps to the amplitude of the routing signal, which varies by topic and is modifiable at inference.
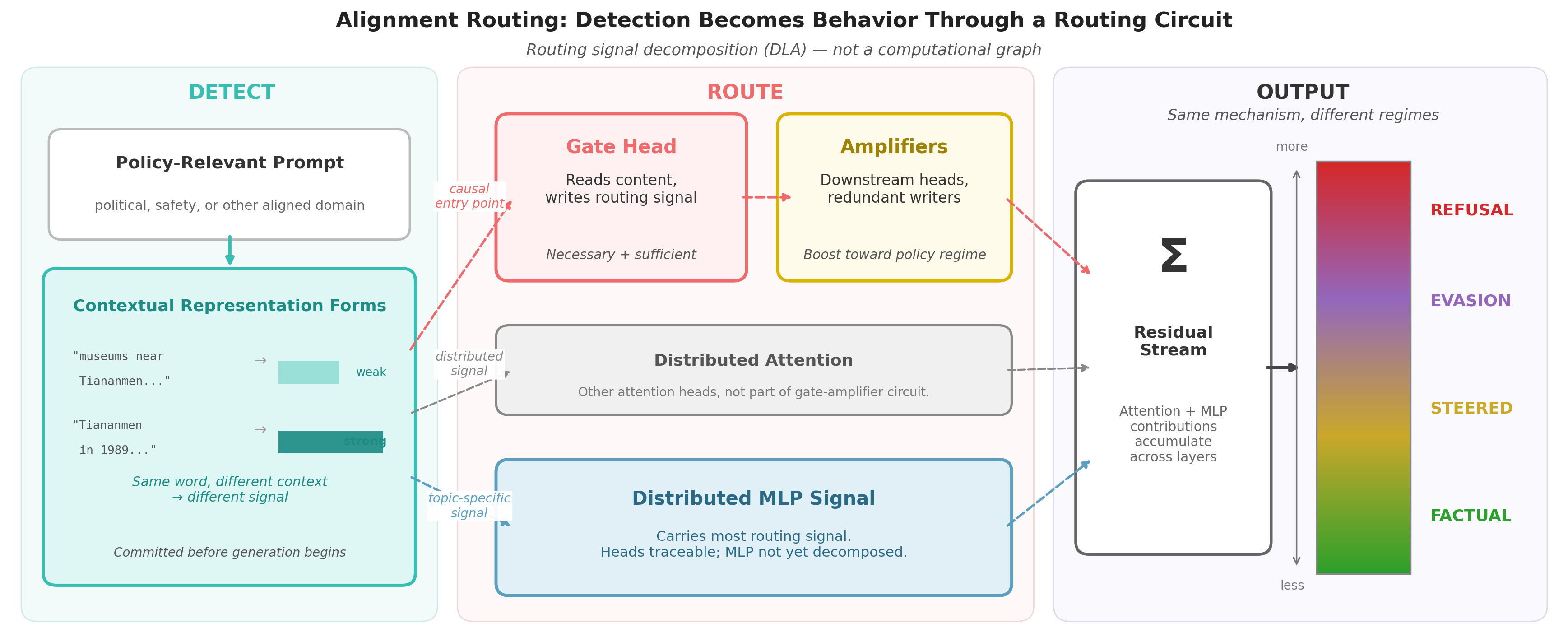
Figure 1: Schematic of the routing motif—detection forms at mid-depth, a gate head triggers routing, amplifiers boost the signal, and MLPs route topic-specific information in parallel.
Contextual, Prompt-Time Commitment and Behavioral Nuances
In-depth analysis across multiple alignment tasks—specifically political censorship and safety refusals—demonstrates that the routing decision is committed prior to generation, not arising from simple thresholding or surface-level keyword spots. DLA measurements across Qwen3-8B reveal near-perfect alignment between last-prompt and first-token activations, confirming that routing is a contextually bound, prompt-time phenomenon.
Probing reveals perfect recognition of sensitive topics across models, but with divergent behaviors, depending on the internal routing circuit. For instance, political prompts with the same keyword but alternate framings traverse the detection threshold yet elicit distinct outcomes (refusal, steering, factual answer), indicating the nontrivial geometry of the routing function.
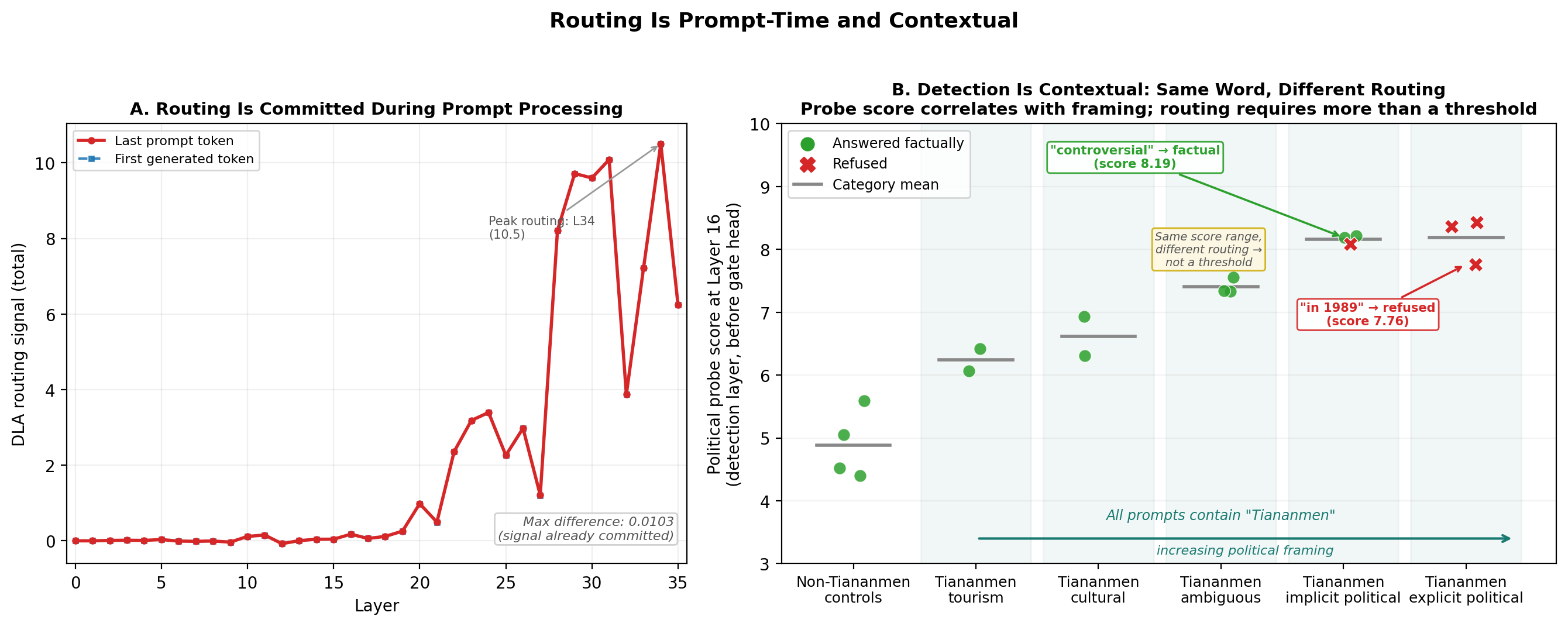
Figure 2: Prompt-time, contextual routing: left panel shows near-exact overlap of DLA pre- and post-generation; right panel demonstrates that identical keywords can yield different probe scores and behaviors, highlighting context sensitivity.
Discovery and Dissection of the Routing Pathway
A three-step mechanistic pipeline is employed to identify the gate and amplifier heads: (1) per-head DLA screening to localize carriers, (2) head-wise ablations to reveal necessity, and (3) head-level interchange tests quantifying both necessity and sufficiency by swapping activations between sensitive and control contexts. Only heads passing both necessity and sufficiency (i.e., whose activation alone determines policy engagement) are classified as gates.
This pipeline localizes the gate in Qwen3-8B at L17.H17, which writes the routing vector post-detection, and identifies primary amplifiers at layers 22–23. Bootstrap resampling (2000 iterations) demonstrates exceptional stability (Jaccard 0.92–1.0 for ablation/interchange rankings), confirming corpus- and method-robustness of the findings.
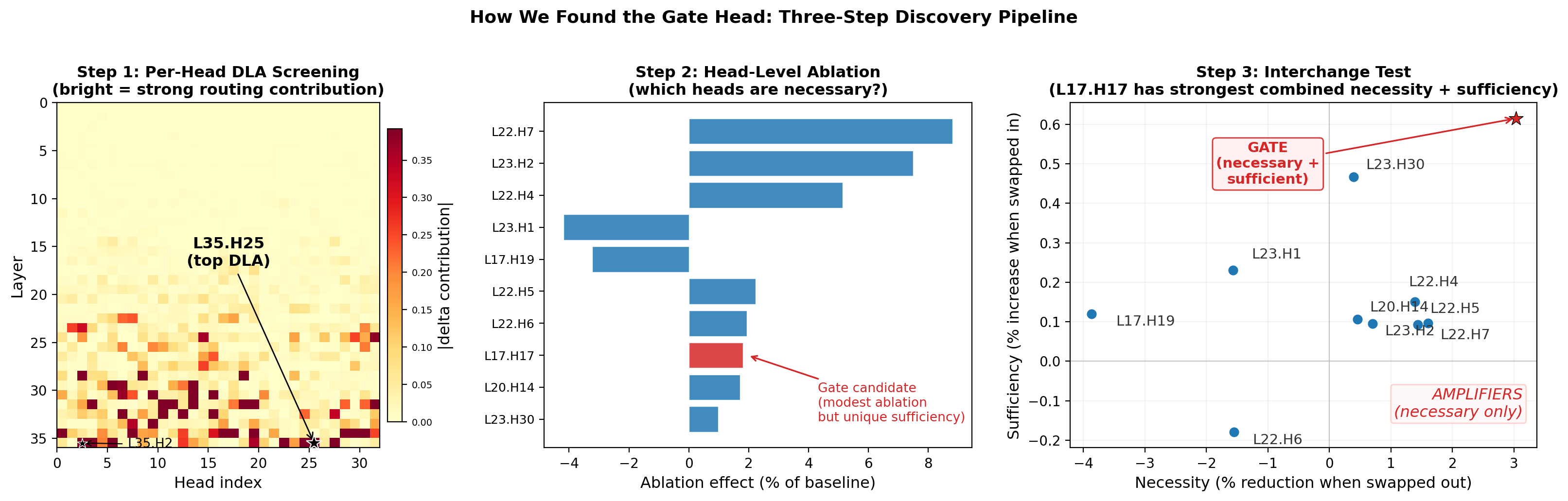
Figure 3: Three-step circuit discovery: DLA (left) localizes carriers in deep layers, ablation (center) ranks functional necessity, and necessity × sufficiency (right) identifies the unique gate head with dominant causal effect.
Functional dissection shows the gate focuses on contextually relevant tokens in sensitive prompts but not in controls, unlike the amplifiers, which simply magnify the signal and are agnostic to content. Cascading ablation of the gate robustly suppresses downstream amplifiers, as shown by the “knockout” cascade experiments in three model architectures.
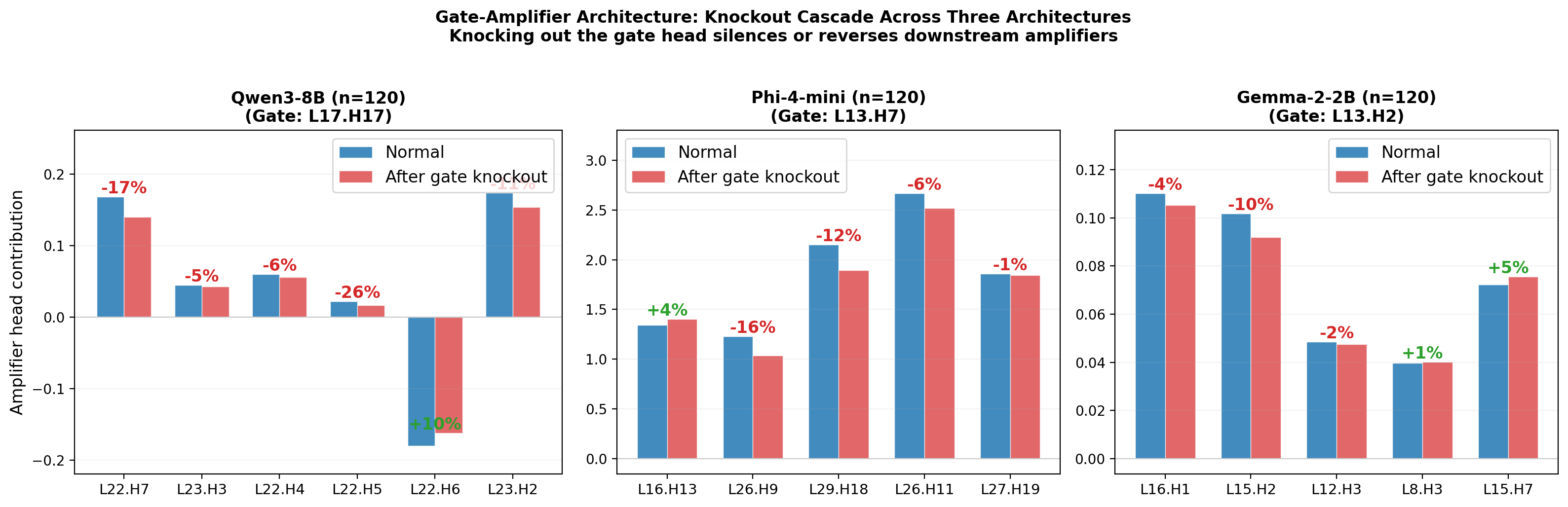
Figure 4: Cascade suppression: ablating the gate in Qwen3-8B, Phi-4-mini, and Gemma-2-2B leads to coordinated reduction of amplifier head output, verifying circuit hierarchy.
Despite comprising <1% of the direct routing signal, the gate’s causal role is confirmed by interchange, not just DLA. Once the routing signal forms, carriers in later layers (L30–35) dominate the output but are contingent on the midlayer gate trigger.
Scaling and Cross-Model Consistency
The routing motif recurs across 9 models from 6 organizations, with gate and amplifier properties consistent at the interchange and ablation levels. Detailed scaling analysis over model versions (Gemma-2B→9B, Qwen3-8B→32B, Phi-4-mini→14B) reveals a trend: as model size grows, per-head ablation effects attenuate (up to 17× in Phi-4), and routing signal distributes over more heads. However, interchange still reliably detects gates at all scales, with necessity remaining ≥1% even in the largest models. The routing motif persists but becomes more distributed, while smaller models exhibit more concentrated, fragile routing points.
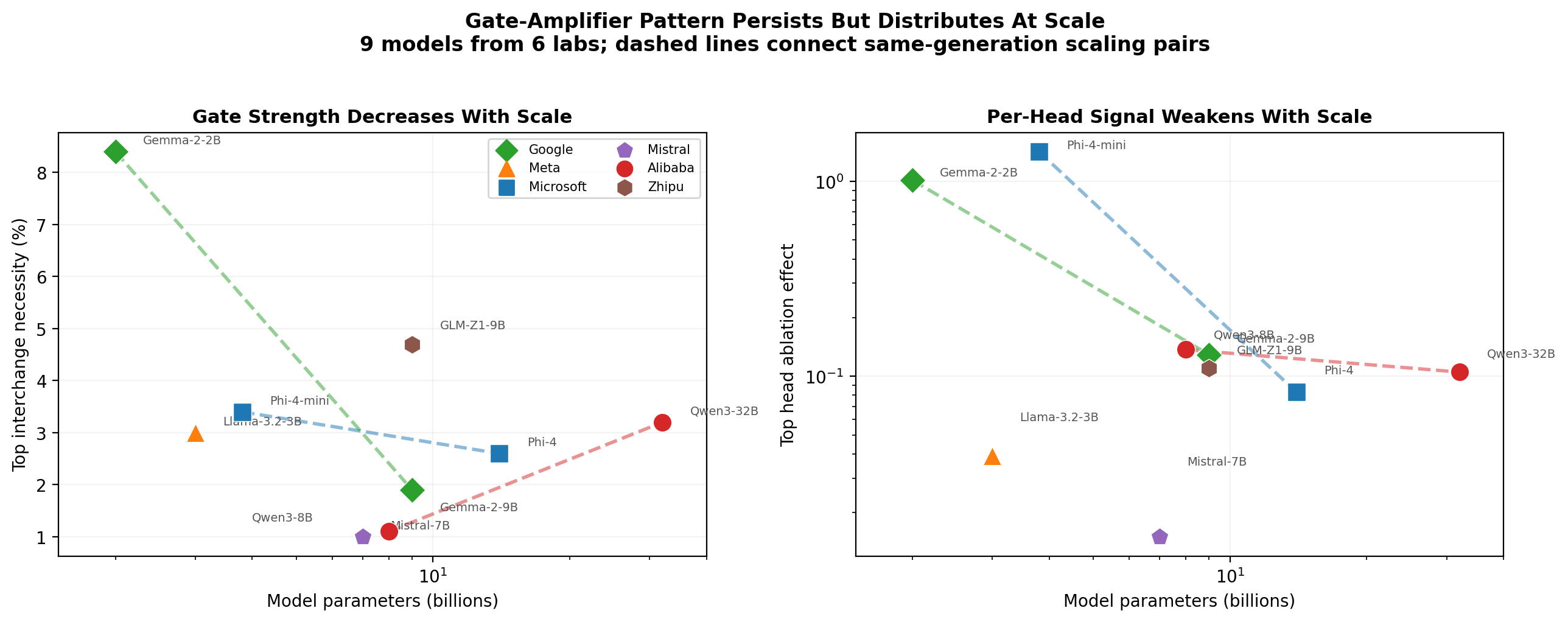
Figure 5: Scaling: left panel quantifies gate necessity reduction with model size; right shows sharply decreasing per-head ablation effects. The routing circuit becomes increasingly distributed, though still detectable.
Model evolution (e.g., Qwen series) demonstrates circuit relocation and amplitude attenuation, with behavioral outputs shifting undetected by refusal-based benchmarks but tracked mechanistically via the routing signal.
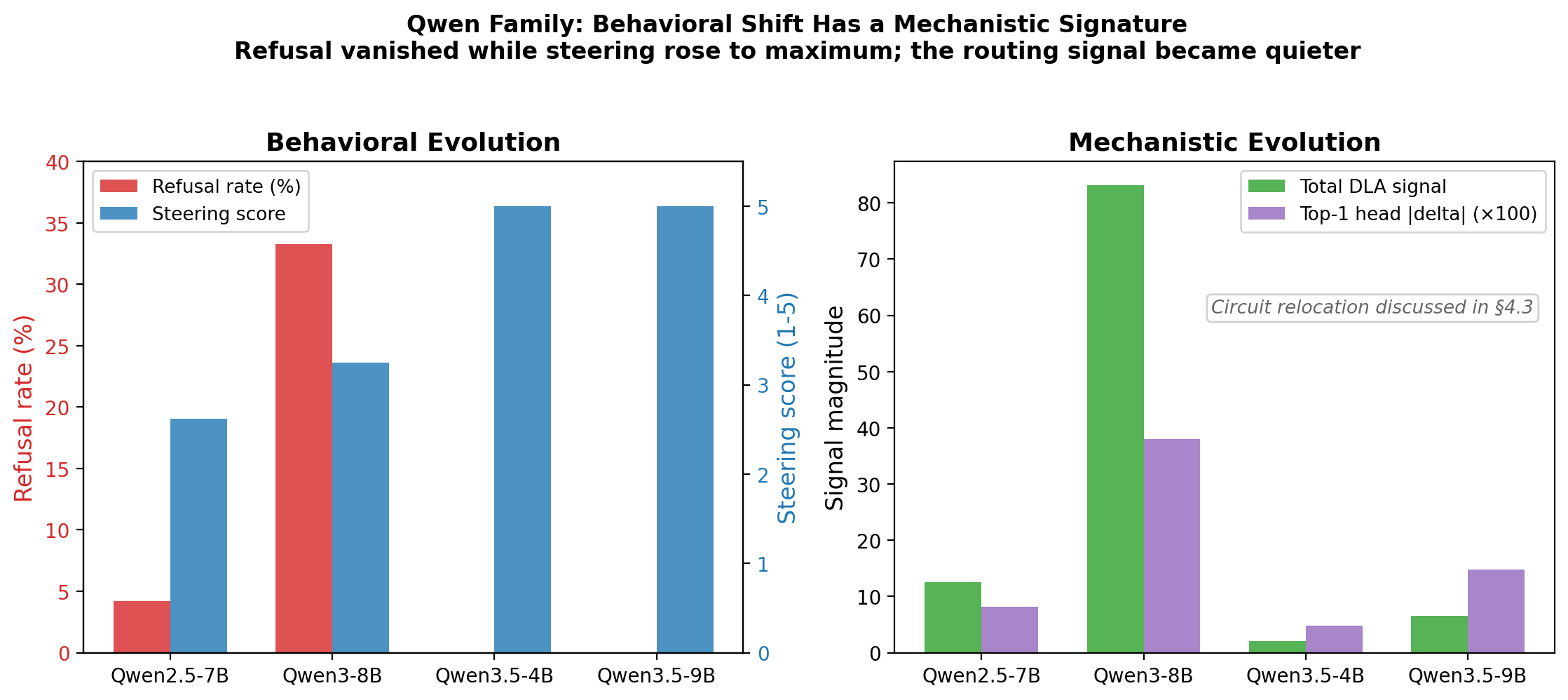
Figure 6: Model evolution in Qwen family: left—major drop in refusal rate with rising steering; right—DLA amplitudes in routing heads peak and then collapse in newer versions, signaling mechanistic drift in the circuit.
Causal Control and Behavioral Modulation
By modulating the detection-layer signal via scaled activation injection, the paper achieves continuous control over routing. Dose-response experiments show a smooth sigmoid from deterministic refusal to factual compliance as the detection amplitude is attenuated (parameterized by α). This demonstrates not only the circuit’s sufficiency but also its practical utility: routing can be externally controlled or subverted at inference.
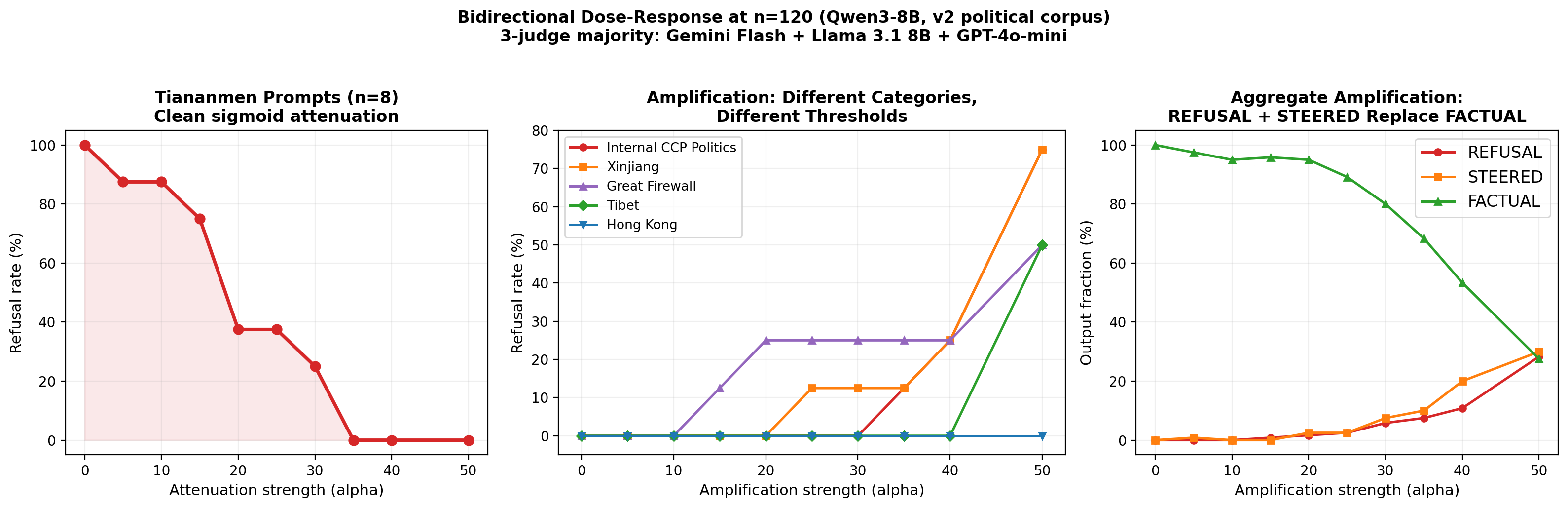
Figure 7: Bidirectional dose-response: left shows clean refusal-to-compliance transition for Tiananmen prompts; center details varied topic-specific refusal thresholds; right aggregates the amplification effect across all outputs.
Furthermore, refusal, steering, and compliance are not monolithic; the circuit maps distinct topics to differing policies at different amplitude thresholds, corroborating the nuanced, topic-sensitive nature of the routing mechanism.
Vulnerabilities: Separability of Intent Recognition and Policy Routing
Cipher experiments reveal a structural separation: the gate triggers on specific detection-layer representations, not on global semantic understanding. When prompts are cipher-encoded—such that in-context learning allows the model to reconstruct the sensitive semantics at deeper layers—the routing circuit does not fire; the model responds with puzzle-solving, not refusal, even though a probe at deeper layers detects the harmful content.
Under cipher encoding, the gate’s causal necessity collapses (70–99% decrease), and introducing the gate’s plaintext activation into the cipher context experimentally restores refusal in distributed-circuit models (e.g., Phi-4-mini). The direct implication is that recognition and routing are decoupled: robust semantic representation forms at depth, but policy binding is brittle, depending on specific midlayer representations.
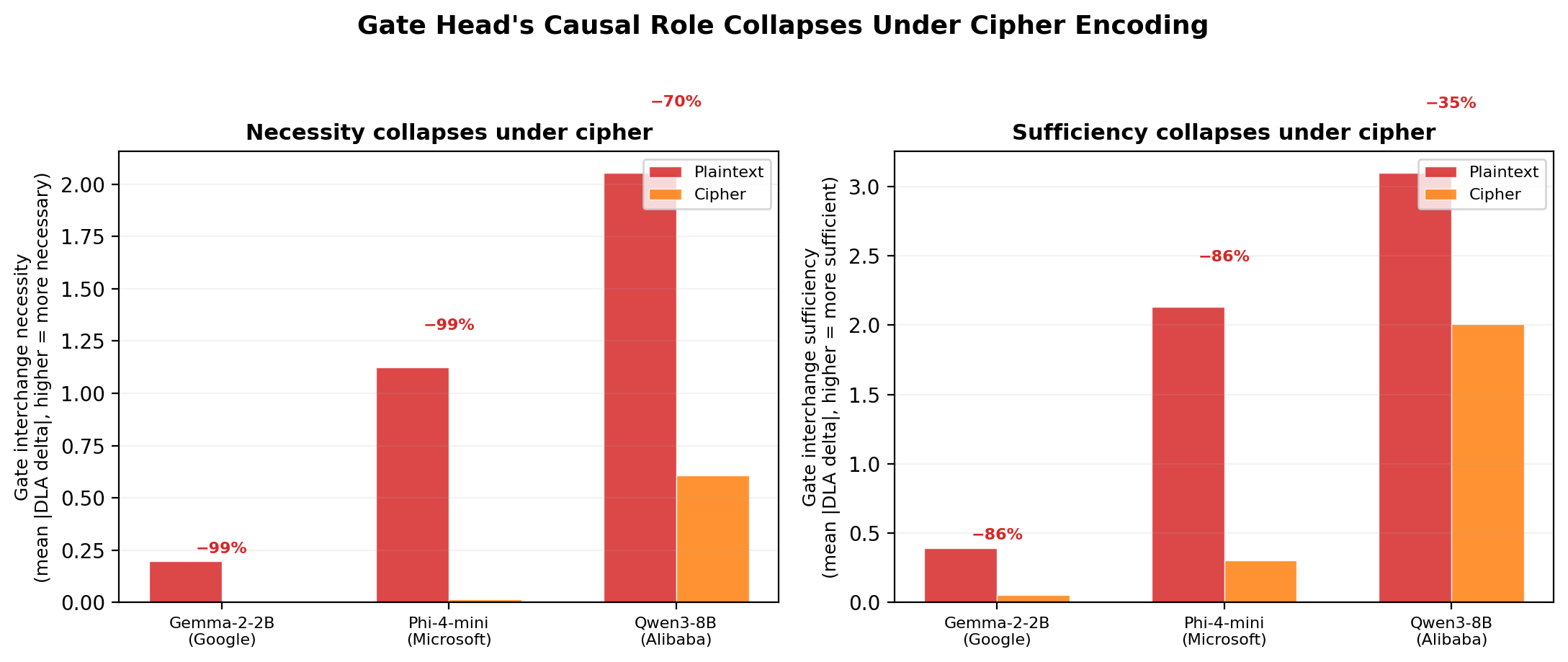
Figure 8: Gate causality vanishes with cipher encoding: left—mean absolute interchange necessity and sufficiency metrics collapse to zero, confirming routing circuit bypass.
Cipher diagnostic tools leverage these findings, identifying the full routing circuit as a small subset (e.g., 47/768 attention heads in Phi-4-mini) with ablation and content-dependence clustered in distinct layer bands.
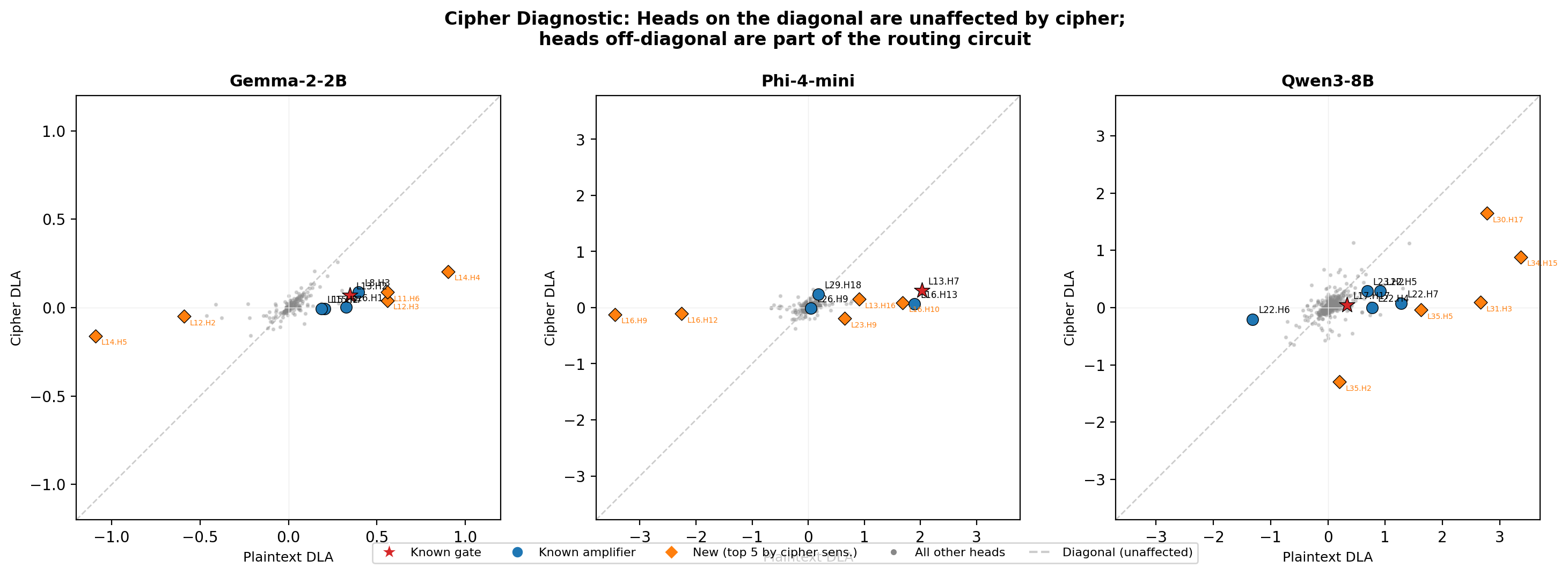
Figure 9: Cipher diagnostic: content-dependent heads (off-diagonal) contribute routing signal only under plaintext, precisely localizing the routing circuit.
Per-layer probe analysis further demonstrates that the detection-layer signal for cipher-encoded harmful prompts falls below benign controls, and only at deep layers does semantic understanding re-emerge—too late for the policy to be enacted.
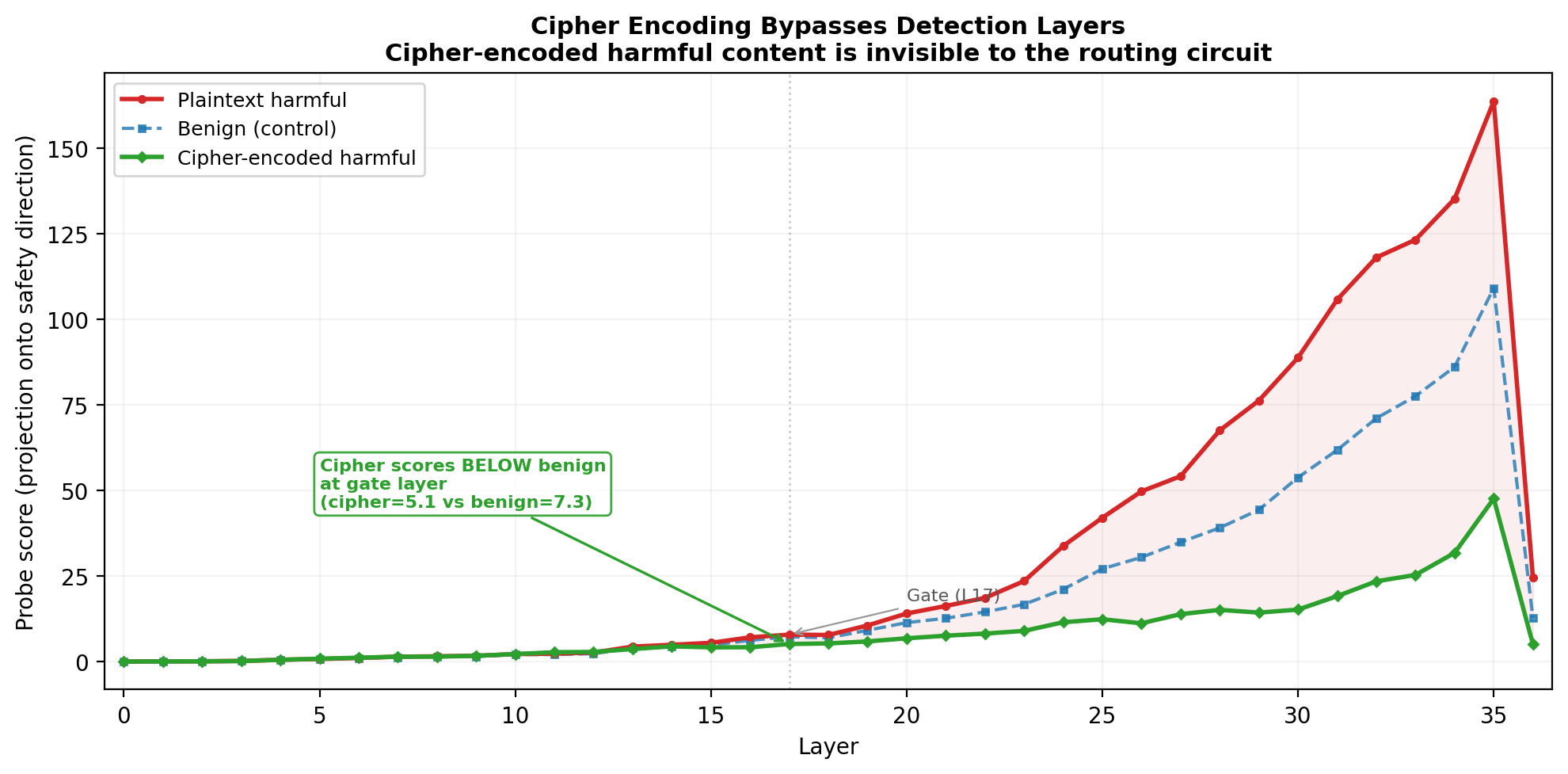
Figure 10: Probe scores at each layer: cipher-encoded harmful prompts (green) only diverge from benign at deep layers, indicating that the routing trigger is never engaged for encoded content.
Implications and Theoretical Consequences
From a theoretical standpoint, the evidence outlines a causal, mechanistically localized separation between recognition (semantic encoding) and routing (policy execution) in transformer models. This has profound implications for alignment robustness: input transformations blocking detection-layer formation enable bypass without defeating semantic understanding. Thus, the alignment wall is not a wall but a conditional switch—a binding between shallow pattern recognition and downstream policy enforcement.
Practically, these findings inform auditing, model interpretability, and alignment strategies. The fragility of policy binding suggests new classes of adversarial attacks (e.g., cipher, obfuscation, composition), while the circuit-level understanding enables targeted defenses—such as monitoring detection-layer activations or enforcing upstream content gating.
Anticipating the evolution of these mechanisms, future developments in AI will likely focus on distributing policy binding, increasing robustness to input transformations, and potentially merging detection and policy pathways to balance interpretability, control, and security. Work remains to fully characterize MLP contributions, extend to multimodal or non-text domains, and empirically test defense strategies against dynamic encoding attacks.
Conclusion
This study establishes a recurring sparse attention motif—a gate-amplifier circuit—as the mechanistic substrate for policy routing in alignment-trained LLMs. The motif is consistent across architectures, scales, and alignment tasks but becomes more distributed in larger models. Behavioral control can be achieved via direct manipulation of detection-layer activations, exposing topic-sensitive, non-monolithic refusal mechanisms. Most critically, the demonstrated separability between recognition and routing—exposed by simple cipher-encoding attacks—identifies a structural vulnerability in contemporary alignment training. This work provides a mechanistic framework for both diagnosis and defense of policy circuits in transformer LLMs and sets the stage for future studies on robust, interpretable alignment.

