Path-Constrained Mixture-of-Experts
Abstract: Sparse Mixture-of-Experts (MoE) architectures enable efficient scaling by activating only a subset of parameters for each input. However, conventional MoE routing selects each layer's experts independently, creating NL possible expert paths -- for N experts across L layers. This far exceeds typical training set sizes, leading to statistical inefficiency as the model may not learn meaningful structure over such a vast path space. To constrain it, we propose \pathmoe, which shares router parameters across consecutive layers. Experiments on 0.9B and 16B parameter models demonstrate consistent improvements on perplexity and downstream tasks over independent routing, while eliminating the need for auxiliary load balancing losses. Analysis reveals that tokens following the same path naturally cluster by linguistic function, with \pathmoe{} producing more concentrated groups, better cross-layer consistency, and greater robustness to routing perturbations. These results offer a new perspective for understanding MoE architectures through the lens of expert paths.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine a school where each student doesn’t go to every class, but instead visits just a few “specialist” teachers who are best for them. Mixture‑of‑Experts (MoE) models work a bit like that: for each word (token) the model reads, it sends the token to a small set of “experts” (tiny neural networks) instead of using the whole big model. This makes large models faster and cheaper.
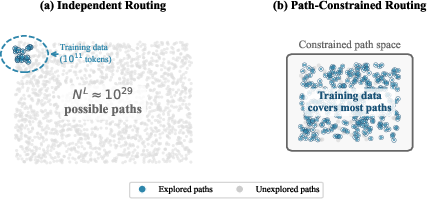
The problem is that, layer by layer, there are many possible ways (paths) a token can move through experts. If there are experts in each of layers, there are possible paths—an astronomically large number. Most of those paths never get enough practice during training, which can make learning inefficient.
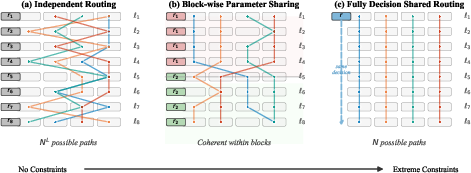
This paper proposes PathMoE: a simple change that makes the routing (the decisions about which expert to use) more consistent across nearby layers by sharing the same “decision rule” within small blocks of layers. This reduces the number of effectively used paths, helps experts specialize better, and improves performance without extra tricks.
What questions the researchers asked
- Can we make MoE models learn more efficiently by reducing the number of expert paths they use?
- Is there a simple way to coordinate expert choices across layers without making the model rigid?
- Does this “path consistency” improve language modeling quality (perplexity) and real tasks like question answering?
- Can we remove the extra “load balancing” loss (a common training add‑on) and still keep experts well used?
- Do tokens that follow the same path share meaningful patterns (like punctuation or names), and is the routing more stable?
How they approached it (in everyday terms)
Think of a tall building (the neural network) with many floors (layers). At each floor, a traffic cop (router) sends a token to one of several specialists (experts). In the usual setup, each floor’s cop works independently and may make very different choices from the floor above or below, creating countless possible routes.
PathMoE’s idea:
- Group floors into small blocks (like 4 floors per block).
- Give all floors in a block the same instructions for routing (they share the same “decision rule,” or router parameters).
- This doesn’t force exactly the same decision at each floor, but encourages similar ones because the rule is shared and the token’s representation only changes gradually between nearby floors.
Why this helps:
- Fewer “effectively used” routes mean each route gets more training practice.
- Experts see more consistent types of tokens and can specialize better.
- The model becomes easier to train and needs fewer “helper” losses.
What they measured and tested:
- Perplexity: a score of how well the model predicts the next word (lower is better).
- Accuracy on several benchmarks (e.g., ARC, BoolQ, PIQA, HellaSwag).
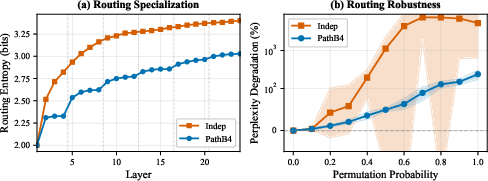
- Routing entropy: a measure of how spread‑out or concentrated the used paths are (lower means tokens stick to fewer paths).
- Routing consistency: how often consecutive layers pick the same or similar experts.
- Robustness: what happens if you scramble expert identities (a stress test).
- They compared PathMoE with the standard independent routers and other routing methods, on models with about 0.9B and 16B parameters.
What they found (main results and why they matter)
- Better performance with a simple change:
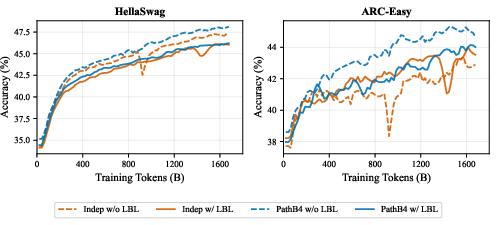
- On a 0.9B model, PathMoE variants consistently improved validation perplexity and average accuracy across 8 tasks. A 4‑layer block size (PathB4‑MoE) worked especially well.
- On a 16B model, PathMoE won on 10 out of 12 tasks, with notable gains on CommonsenseQA (+5.73%), ARC‑Easy (+5.09%), and OpenBookQA (+3.80%).
- Fewer, more useful paths:
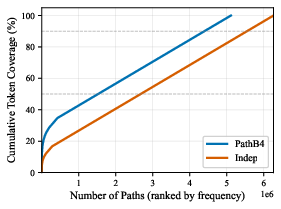
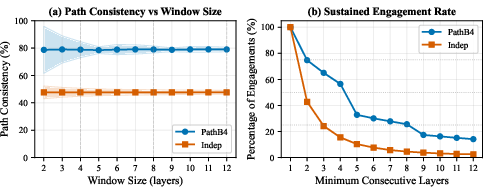
- PathMoE reduced routing entropy (about 1 bit lower in one test), meaning tokens followed fewer paths. That effectively halves the variety of paths, giving each path more training signal.
- Early in training, the model already identifies top paths. Limiting routing later to about a few hundred of these top paths barely hurts performance—showing the model naturally concentrates on a manageable set of meaningful routes.
- No need for extra balancing tricks:
- Typical MoE training uses a “load balancing” loss to keep all experts busy. PathMoE trained stably without it, avoiding extra tuning.
- More consistent and robust routing:
- Tokens tended to use similar experts across nearby layers (much higher cross‑layer consistency than the standard approach).
- Despite being more specialized, PathMoE was far more robust when the researchers randomly scrambled expert identities: performance dropped much less than with the standard method.
- Interpretable specialization:
- Tokens following the same path often shared a linguistic role: punctuation, person names, time expressions, etc. PathMoE’s paths formed clearer clusters than the standard setup, hinting at understandable “skills” emerging inside the model.
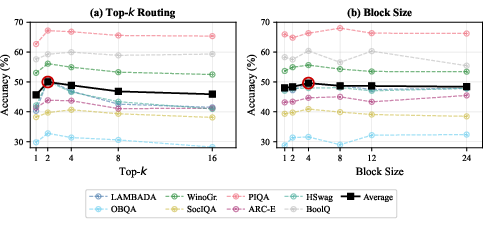
- Sweet spots for settings:
- Top‑2 routing (send a token to its two best experts) worked best overall.
- A block size of 4 layers provided the best trade‑off between flexibility and consistency.
Why this matters (implications and impact)
PathMoE shows that making expert choices more consistent across nearby layers can:
- Improve accuracy and next‑word prediction without adding complexity or cost.
- Reduce the need for extra training losses and hyperparameter tuning.
- Help experts specialize in useful, interpretable ways (easier to analyze and debug).
- Make large models more efficient by focusing on a smaller set of well‑trained paths.
- Scale to bigger models (up to 16B parameters in these tests) while maintaining benefits.
Overall, this is a simple architectural tweak that makes MoE models learn better, work more reliably, and be easier to understand—helping future LLMs be both smarter and more efficient.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. These are framed to guide actionable future research.
- Theoretical guarantees for path-space reduction:
- No formal proof bounds the reduction in effective path space under PathMoE; the entropy argument relies on a first-order Markov approximation and heuristic assumptions about residual networks.
- Analysis assumes top-1 routing for tractability, while training/evaluation use top-k; a rigorous treatment for top-k routing and weighted mixtures is missing.
- Estimation of routing entropy:
- Empirical routing entropy is computed on ~7M tokens and with approximations; there is no bias/variance analysis of the estimator, nor sensitivity studies to dataset size, domain, or top-k choice.
- The method for mapping top-k selections to a single “path” for entropy and consistency metrics is under-specified; it is unclear whether different definitions (e.g., ordered k-tuples, multiset paths) change conclusions.
- Load balancing without auxiliary losses:
- The claim that PathMoE obviates auxiliary load-balancing loss is shown on limited settings; there is no systematic study across expert counts, capacity factors, token-drop strategies, training lengths, or highly skewed data distributions.
- Quantitative characterization of expert utilization (e.g., per-expert token counts over training, tail utilization, overflow/drop rates) without LBL is absent.
- Optimal block design and placement:
- Only uniform, fixed-size blocks are considered; there is no exploration of non-uniform or learnable block boundaries, data-dependent block sizes, or adaptive/path-aware block merging/splitting.
- Interaction between block size and depth-dependent representation drift is not quantified; criteria for choosing B4 vs. B8 vs. B24 beyond empirical averages are not provided.
- Gradient interference induced by shared routers:
- Sharing router parameters across layers may create gradient conflicts between layers within a block; the paper does not analyze optimization dynamics (e.g., gradient alignment, variance) or propose mitigation (e.g., PCGrad, decoupled updates).
- Expert-choice and soft mixtures:
- Preliminary results suggest no benefit for expert-choice routing, but details (experimental setup, metrics, failure modes) are not provided; it remains open whether PathMoE variants can be effective for expert-choice or soft/continuous MoE.
- Mechanisms to induce cross-layer coordination in expert-choice or soft-gating regimes (e.g., shared priors, coupling terms) are not explored.
- Generalization across tasks and modalities:
- Evaluations cover a subset of English NLP benchmarks; there is no testing on multilingual, code/math-heavy, long-context, or instruction-following tasks where routing needs may differ.
- No results on multimodal (vision, speech-text beyond prior art) or encoder–decoder setups; it is unclear how PathMoE transfers to non-decoder architectures.
- Scaling behavior and stability at larger sizes:
- Results at 0.9B and 16B are promising, but there are no scaling-law analyses (loss vs. tokens/compute) or stability assessments at larger/trillion-parameter scales.
- Sensitivity to training budgets, curriculum, and optimizer hyperparameters at scale remains unstudied.
- Robustness beyond expert permutations:
- Robustness is only tested via random expert permutations; other perturbations (e.g., partial expert dropout, stochastic routing noise, adversarial routing, capacity overflows, hardware faults) are not evaluated.
- Distribution shift and OOD robustness of routing decisions and expert specialization are not assessed.
- Interactions with MoE design choices:
- Limited exploration of how PathMoE interacts with number of experts N, capacity factor, gate noise/temperature, and routing determinism; comprehensive ablations are missing.
- Compatibility with contemporary architectural variants (e.g., MoD/mixture-of-depths, multi-query attention, state-space models) is not examined.
- Path specialization and interpretability:
- Linguistic clustering by path is qualitatively shown (word clouds), but quantitative measures (e.g., mutual information with POS/NER tags, purity scores, stability across seeds/domains) are absent.
- Causality between path specialization and performance is not established; interventions that alter path assignments to test causal impact are not performed.
- Early-path restriction experiments:
- Restricting to top-K paths after 5k steps suggests early consolidation, but the long-term consequences (path lock-in, lost rare-skill paths, recoverability) are not studied.
- It is unclear whether early pruning biases the model against minority phenomena or harms tail capabilities.
- Scheduling and learnability of routing constraints:
- No investigation of curricula that anneal block size or gradually introduce sharing; potential benefits of staged routing constraints remain unexplored.
- Learnable, data- or layer-dependent routing constraints (e.g., gating regularizers instead of hard parameter sharing) are not evaluated.
- Compute and systems implications:
- While throughput/memory are reported for one hardware/training setup, impacts on pipeline/tensor parallelism, memory bandwidth, and router parameter sharing in distributed training are not analyzed.
- Potential inference-time benefits from path coherence (e.g., path-level caching, scheduling, or compile-time specialization) are not explored.
- Fairness, bias, and privacy implications:
- Path-level clustering around named entities and social terms may amplify biases or leak sensitive patterns; no audits or mitigation strategies are presented.
- The effect of path constraints on fairness across demographics or dialects is unknown.
- Evaluation breadth and statistical rigor:
- Task improvements are reported as averages with limited variance reporting; more rigorous statistical testing across seeds, checkpoints, and datasets would strengthen claims.
- Some tasks show mixed results; analysis of task-specific failure modes and when path constraints hurt performance is lacking.
- Expert identity alignment:
- Metrics that align experts across layers by permutation for analysis may mask instability; it is unclear how sensitive conclusions are to the alignment method and whether alignment artifacts influence reported gains.
- Router capacity and architecture:
- Routers are simple linear projections; the impact of richer router architectures (e.g., MLPs, attention, low-rank adapters on top of shared weights) within PathMoE is underexplored beyond a single LowRank baseline.
- Regularization of shared routers (e.g., orthogonality, sparsity, dropout) and their effect on specialization and stability are not studied.
- Downstream fine-tuning and transfer:
- Effects of PathMoE on instruction tuning, RLHF, or PEFT methods are untested; whether shared routers help or hinder adaptation to new tasks remains open.
- Public resources:
- No mention of releasing code, checkpoints, or analysis tools for path-level metrics; reproducibility and community validation may be hindered without these resources.
Practical Applications
Practical Applications of Path-Constrained Mixture-of-Experts (PathMoE)
Below are actionable, real-world applications enabled by the paper’s findings and innovations. Each item notes relevant sectors, potential tools/workflows, and feasibility considerations.
Immediate Applications
- Production-ready MoE training with fewer knobs
- Sectors: software/AI infrastructure, cloud
- What: Adopt block-wise shared routing (e.g., block size 4, top-2/4) to train LLMs with improved perplexity and task accuracy while removing auxiliary load-balancing loss.
- Why PathMoE enables it: Demonstrated gains at 0.9B and 16B scales; balanced utilization without auxiliary loss; no throughput/memory regressions.
- Tools/workflows:
- Add a “PathMoERouter” module to existing MoE stacks (Megatron/DeepSpeed-MoE/JAX GSPMD, TensorRT-LLM, vLLM).
- Default cookbook: top-2 routing, block size 4, remove load-balancing loss, monitor path entropy.
- Assumptions/dependencies: Requires MoE-capable infra (token dispatch/all-to-all). Gains may depend on dataset, model size, and top-k. Not shown to help expert-choice routing.
- Lower-variance, faster-to-tune LLM training
- Sectors: software/AI infrastructure, enterprise AI
- What: Reduce hyperparameter search by eliminating load-balancing loss and improving routing stability, shortening time-to-first-accurate-checkpoint.
- Why PathMoE enables it: Stable training curves without LBL; higher routing consistency and lower path entropy.
- Tools/workflows: Automated training pipelines that skip LBL sweeps; early stopping based on path entropy and path coverage curves.
- Assumptions/dependencies: Stability without LBL shown on tested datasets; verification recommended for new domains.
- Inference robustness under resource variability
- Sectors: cloud, edge AI, device OEMs
- What: Deploy MoE LLMs that are more robust to routing perturbations and potential expert index changes during upgrades or sharding adjustments.
- Why PathMoE enables it: 22.5× robustness to routing permutations reported.
- Tools/workflows: Rolling upgrades with staged expert remaps; chaos tests that permute expert indices to validate resilience.
- Assumptions/dependencies: Real-world perturbations differ from synthetic permutations; test in production-like environments.
- MoE observability and debugging via path-level analytics
- Sectors: software/AI operations (MLOps), regulated industries (finance, healthcare)
- What: Monitor routing behavior through “path entropy,” path coverage curves, and cross-layer consistency as model health indicators.
- Why PathMoE enables it: Lower path entropy and interpretable token clusters (e.g., punctuation, named entities) offer actionable telemetry.
- Tools/workflows:
- “PathProfiler” dashboards showing path frequencies, entropy over time, expert utilization per block.
- Alerts for sudden path drift indicating data distribution shifts.
- Assumptions/dependencies: Logging per-token routing may have privacy implications; aggregate or differentially private logging recommended.
- Path-informed fine-tuning and specialization
- Sectors: enterprise NLP, finance (document extraction/compliance), healthcare (clinical note processing), customer support
- What: Use path clusters to guide domain-specific fine-tuning (e.g., legal names/temporal expressions routed to specialized experts).
- Why PathMoE enables it: More coherent and consistent paths make specialization more reliable and interpretable.
- Tools/workflows:
- “PathFreezer” workflow: detect dominant paths early, optionally freeze or prioritize them during domain adaptation.
- “PathPruner” to retire rarely used paths/experts for leaner inference.
- Assumptions/dependencies: Over-restricting to few paths can harm performance (as shown by the 10-path ablation); conservative thresholds advised.
- Reduced distributed training stragglers via natural load balance
- Sectors: cloud training platforms, HPC
- What: Smoother expert utilization without explicit balancing loss reduces dispatch hotspots and stragglers across devices.
- Why PathMoE enables it: Empirically balanced routing without LBL; improved inter-layer coordination.
- Tools/workflows: Token dispatcher metrics (tokens/expert/step, queue latency) integrated with cluster autoscaling.
- Assumptions/dependencies: Actual dispatch balance still depends on batch composition and capacity factors; monitor in practice.
- On-device or constrained-environment assistants with sparse compute
- Sectors: mobile, embedded/IoT, consumer devices
- What: Use MoE’s conditional computation with PathMoE’s parameter sharing to lower memory/compute for interactive assistants (typing aid, smart home).
- Why PathMoE enables it: Active parameters per token remain small; shared routers reduce param count and improve consistency.
- Tools/workflows:
- Quantized experts with block-shared routers.
- Local fallback paths with pre-warmed experts for latency spikes.
- Assumptions/dependencies: MoE all-to-all can be challenging on-device; requires kernel support for routing and memory bandwidth planning.
- ASR and multimodal extensions (near-term)
- Sectors: speech (ASR), media, contact centers
- What: Apply block-wise shared routing to speech and multimodal transformers to improve WER/latency and stability.
- Why PathMoE enables it: Prior work shows fully-shared routers help ASR; block-sharing is a middle ground for diverse tokens/frames.
- Tools/workflows: Replace per-layer routers in ASR MoE encoders/decoders with block-shared versions; measure path entropy vs. WER.
- Assumptions/dependencies: Requires validation on target datasets and careful choice of block size per modality.
- Compliance/audit logging with interpretable routing
- Sectors: finance, healthcare, public sector
- What: Provide auditors with high-level path summaries linked to token categories (e.g., names, dates) for post-hoc analysis.
- Why PathMoE enables it: Tokens cluster by linguistic function along paths, enabling coarse-grained interpretability.
- Tools/workflows:
- “ExpertPath Auditor” that maps prompts/responses to path clusters and flags unusual routing patterns.
- Assumptions/dependencies: Interpretability is coarse and not a causal explanation; must pair with other governance tools.
- Cost and carbon reduction through fewer HPO cycles
- Sectors: enterprise AI, policy (sustainability)
- What: Reduce compute from extensive LBL hyperparameter sweeps; standardize on a small set of routing defaults.
- Why PathMoE enables it: Removes/tames a common hyperparameter (LBL weight) without hurting convergence.
- Tools/workflows: “Green HPO” policies preferring PathMoE defaults; energy dashboards showing saved GPU-hours.
- Assumptions/dependencies: Savings vary by org; requires monitoring to confirm no hidden regressions.
Long-Term Applications
- Path-aware serving compilers and hardware scheduling
- Sectors: cloud inference, chip vendors
- What: Build compilers/runtimes that exploit path coherence to prefetch experts, pin memory, and fuse per-path kernels.
- Why PathMoE enables it: Higher cross-layer path consistency and lower entropy make paths more predictable at runtime.
- Tools/products: “Path-AOT” (ahead-of-time) schedules per frequent path; cache residency policies per block.
- Assumptions/dependencies: Requires hardware/runtime support for dynamic dispatch; benefits grow with stable path distributions.
- Path-conditioned safety and governance controls
- Sectors: platform safety, policy/regulation
- What: Enforce policy by routing risky token categories (e.g., PII patterns) through safety-tuned experts/paths for additional checks.
- Why PathMoE enables it: Linguistic-function clustering along paths can be used as soft signals for risk-aware routing.
- Tools/products: Path-level guardrails and escalation (e.g., “safety path” interposer experts).
- Assumptions/dependencies: Must avoid over-reliance on path heuristics; requires rigorous red-teaming and fairness checks.
- Standardized “path metrics” in model cards and audits
- Sectors: academia, policy, open-source
- What: Include routing entropy, path coverage, and cross-layer consistency as standard interpretability and stability metrics.
- Why PathMoE enables it: Provides well-motivated, computable measures linked to performance and robustness.
- Tools/workflows: Benchmark suites and CI that track path metrics across versions; public leaderboards with path statistics.
- Assumptions/dependencies: Community consensus on definitions and measurement protocols; privacy-preserving logging.
- Continual and personalized learning via path partitioning
- Sectors: consumer AI, enterprise personalization
- What: Use path partitions (blocks of experts) for user- or task-specific adaptation, isolating updates to reduce interference.
- Why PathMoE enables it: Coherent paths create natural subspaces for modular fine-tuning.
- Tools/products: “Path adapters” or LoRA modules attached to path-specific experts; per-tenant expert groups.
- Assumptions/dependencies: Storage of multiple expert variants; careful capacity management to avoid fragmentation.
- Data-efficient training for low-resource domains/languages
- Sectors: NGOs, global development, public sector
- What: Leverage better sample efficiency (reduced effective path space) to improve performance with fewer tokens.
- Why PathMoE enables it: Empirically lower routing entropy concentrates learning signal along key paths.
- Tools/workflows: Curriculum schedules that prioritize path formation early; selective data augmentation per path.
- Assumptions/dependencies: Demonstrated on English datasets; transfer to low-resource contexts needs empirical validation.
- Compression and distillation from path concentration
- Sectors: edge AI, SaaS
- What: Distill frequent expert paths into compact submodels or merge redundant experts for smaller footprints.
- Why PathMoE enables it: Path concentration and consistent expert engagement provide clear candidates for pruning/merging.
- Tools/products: “PathDistill” (train student per top-k paths), expert merging guided by cross-layer alignment.
- Assumptions/dependencies: Must preserve accuracy; generalization might degrade if long-tail paths are pruned too aggressively.
- Multimodal and robotics policies with path-constrained gating
- Sectors: robotics, autonomous systems, media
- What: Apply path-constrained routing to policy networks where consistent processing stages (perception→reasoning→action) benefit from coherent expert paths.
- Why PathMoE enables it: Encourages cross-layer coordination without overconstraining, aligning with staged computation.
- Tools/workflows: Block-shared gates in ViTs/decision transformers; path-level latency budgeting for real-time control.
- Assumptions/dependencies: Requires domain-specific validation and safety guarantees; real-time constraints are strict.
- Federated and privacy-preserving MoE with stable routers
- Sectors: healthcare, finance, on-device learning
- What: Use stable, shared routers to reduce synchronization overhead and variance in federated settings, while keeping expert updates local.
- Why PathMoE enables it: Shared parameters per block can reduce coordination complexity across clients.
- Tools/workflows: Federated aggregation of shared router blocks; client-specific expert fine-tuning.
- Assumptions/dependencies: Communication patterns and privacy constraints must be worked out; MoE dispatch across clients is nontrivial.
- Curriculum and dataset routing informed by path structure
- Sectors: education tech, dataset curation
- What: Design curricula that expose models to data that strengthens useful paths early, then broaden; or route examples to experts aligned with their path clusters.
- Why PathMoE enables it: Early emergence of dominant paths; correlation between path concentration and performance.
- Tools/workflows: Early-epoch path mining; “path-aware” samplers that balance or emphasize certain linguistic functions.
- Assumptions/dependencies: Overemphasis risks myopic specialization; balance required to maintain generality.
- Path-aware RAG and tool use
- Sectors: enterprise search, developer tools
- What: Route retrieval tokens and reasoning tokens along different experts/paths for better latency and precision.
- Why PathMoE enables it: Clearer separation of linguistic functions along paths can align with retrieval vs. generation phases.
- Tools/workflows: Prompt analyzers that steer routing; path-conditioned tool-calling policies.
- Assumptions/dependencies: Requires tight integration with RAG pipelines; path detection must be low-latency.
Notes on feasibility and generalization:
- Applicability is strongest for token-choice MoE with top-k routing (k≈2–4) and block sizes around 4; very large or tiny blocks may underperform.
- Path interpretability is emergent and coarse-grained; it should complement (not replace) other interpretability and safety techniques.
- Logging and analysis of routing decisions must consider privacy and security; aggregate statistics or synthetic probes may be necessary.
- Gains are shown on language tasks; cross-domain use (vision, robotics, finance time series) requires empirical validation and potentially different block sizes or routing hyperparameters.
Glossary
- Auxiliary load balancing loss: An extra training objective added to encourage uniform expert utilization and prevent collapse. Example: "eliminating the need for auxiliary load balancing losses."
- Block-wise parameter sharing: Sharing the same routing parameters across a contiguous block of layers to encourage path coherence. Example: "Block-wise parameter sharing routing, dubbed PathMoE: layers within a block share router parameters."
- Categorical distribution: A discrete probability distribution over a finite set of categories (experts) used for routing decisions. Example: "E_l \mid \mathbf{x}_l \sim \text{Categorical}\left[ \mathrm{softmax}(\mathbf{W}_l \mathbf{x}_l) \right]."
- Conditional computation: Activating only a subset of model components for each input to save compute while increasing capacity. Example: "demonstrating that conditional computation could dramatically increase model capacity with modest computational overhead."
- Cross-layer coordination: Designing routing so that expert selections across layers are correlated or aligned rather than independent. Example: "These approaches improve individual routing decisions but do not address cross-layer coordination, which we show is critical for expert path efficiency."
- Expert choice routing: A routing paradigm where experts select tokens instead of routers assigning tokens to experts. Example: "proposed expert choice routing where experts select tokens;"
- Expert collapse: A failure mode where only a few experts receive most tokens, reducing specialization and utilization. Example: "To prevent expert collapse where only a few experts receive most tokens, MoE training typically adds an auxiliary loss"
- Expert path: The sequence of selected experts for a token as it passes through all MoE layers. Example: "A token's journey through an MoE network can be viewed as an expert path---a sequence of expert selections across layers (top-1 expert is used)."
- First-order Markov dependency: An approximation assuming each layer’s routing depends mainly on the previous layer’s decision. Example: "Using the chain rule of entropy, the routing entropy can be decomposed and further approximated using the first-order Markov dependency (meaningful approximation in residual networks):"
- GRU (Gated Recurrent Unit): A recurrent neural network cell used to pass routing information across layers in recurrent routing schemes. Example: "Recurrent-MoE~\cite{qiu2024layerwise} uses a shared GRU where each layer's router receives information from the previous layer's hidden state"
- Inductive bias: Architectural or algorithmic assumptions that guide learning toward certain solutions. Example: "This creates an inductive bias where the same routing function is applied to gradually-evolving token representations within each block."
- Jaccard similarity: A set-similarity metric measuring overlap between two sets, used here to quantify path consistency. Example: "Path consistency measures expert reuse: we compute the average Jaccard similarity between expert sets at consecutive layers."
- Jensen's inequality: A convexity inequality used to show increased correlation under shared routing. Example: "By Jensen's inequality, since is strictly convex and the routing probability varies across the data distribution, we get that and are correlated"
- Load balancing loss (LBL): The specific auxiliary objective encouraging balanced expert loads, often abbreviated as LBL. Example: "with and without load balancing losses (LBL)."
- Marginal distribution: The distribution of expert paths aggregated over the data, ignoring conditioning on specific inputs. Example: "The routing entropy is then defined as the Shannon entropy on this marginal distribution of expert paths over the data distribution :"
- Mixture-of-Experts (MoE): A neural architecture that routes inputs to a subset of specialized expert networks to scale capacity efficiently. Example: "Sparse Mixture-of-Experts (MoE) architectures enable efficient scaling by activating only a subset of parameters for each input."
- Mutual information: An information-theoretic measure of dependence between random variables, used to analyze inter-layer routing correlation. Example: "where is the mutual information between consecutive layers"
- Perplexity: A standard metric for language modeling that measures how well a probability model predicts a sample. Example: "best validation perplexity (12.29)"
- Residual connections: Skip connections that add a layer’s input to its output, stabilizing training and making representations evolve gradually. Example: "Since nearby layers process similar representations (thanks to residual connections), they naturally receive similar (though not identical) routing"
- Residual networks: Architectures composed of residual (skip) connections, supporting approximations like first-order Markov dependency. Example: "first-order Markov dependency (meaningful approximation in residual networks)"
- Router: The component that computes expert selection probabilities given a token representation. Example: "each MoE layer contains expert networks and a router ."
- Routing entropy: The Shannon entropy of the marginal distribution over expert paths, quantifying effective path-space size. Example: "We compute empirical routing entropy over 7M tokens for both independent routing and PathMoE () routing"
- Shannon entropy: An information-theoretic measure of uncertainty used to quantify diversity in expert path usage. Example: "The routing entropy is then defined as the Shannon entropy on this marginal distribution of expert paths over the data distribution :"
- Top-k routing: A routing strategy that selects the top-k experts by probability for each token. Example: "Classical approaches employ top- routing with load balancing constraints"
Collections
Sign up for free to add this paper to one or more collections.