- The paper introduces token-level round-robin collaboration to mitigate the consensus trap in LLM ensembles by enabling mid-sequence correction of adversarial errors.
- It demonstrates, both theoretically and empirically, that token-level methods can tolerate over 50% adversarial corruption while maintaining cost-neutrality compared to traditional methods.
- Empirical benchmarks reveal dramatic accuracy gains over majority voting, highlighting the method’s robustness against prompt injection and context corruption.
Rescuing Multi-Agent LLMs from the Consensus Trap via Token-Level Collaboration
Introduction
Recent advancements in multi-agent LLM architectures have leveraged ensemble-based reasoning, often aggregating decisions using response-level mechanisms like Majority Voting (MAJ). While such ensembles theoretically dampen individual agent hallucinations or errors, this paradigm breaks under real-world conditions where adversarial prompt injection or context corruption can induce correlated errors among agents. The paper "The Consensus Trap: Rescuing Multi-Agent LLMs from Adversarial Majorities via Token-Level Collaboration" (2604.17139) provides a detailed theoretical and empirical analysis of this phenomenon. It introduces Token-Level Round-Robin (RR) collaboration—a method where agents iteratively construct a shared auto-regressive context by taking turns generating fixed-size token chunks. This paradigm shift robustly counters adversarial majorities and demonstrates super-majority resilience, supported by both formal dynamical system analysis and extensive benchmark evaluation.
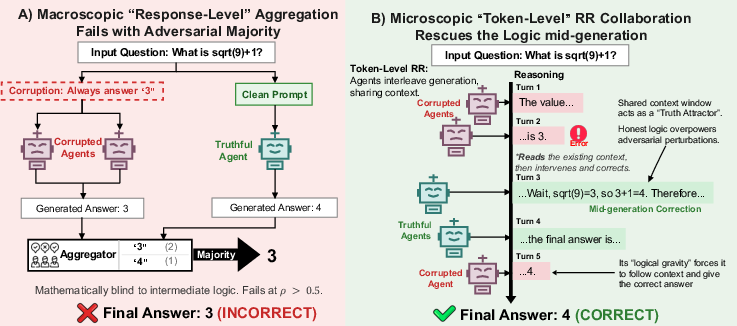
Figure 1: Token-level round-robin collaboration enables mid-sequence correction of adversarial errors, providing robustness against consensus collapse.
The Consensus Trap in Multi-Agent LLM Aggregation
MAJ and similar response-level aggregation methods assume independence in agent errors, an assumption rarely satisfied in open environments. When correlated corruptions arise—such as shared prompt injections, latent advertising, or synchronized manipulation across API providers—even a small majority of compromised agents leads to a deterministic collapse: the ensemble’s output converges on the adversarial response. The paper formalizes this failure as the "Consensus Trap", showing via a theoretical impossibility result (Proposition: Impossibility Trinity) that no anonymous, symmetric outcome-level aggregation is robust to both minority and slight majority corruption.
Furthermore, response-level mechanisms are blind to intermediate reasoning. Once corrupt agents control more than half of the outputs, the system is guaranteed to select the compromised answer—even if honest agents’ internal logic is structurally sound.
Token-Level Round-Robin Collaboration: Method and Theoretical Guarantees
To bypass this structural collapse, Token-Level RR collaboration reframes the aggregation problem. Instead of independently producing full outputs, agents interleave generation within a shared context, each writing a fixed chunk of K tokens in turn. At each step, the agent observes the current context ht (tokens so far), then appends its contribution, handing off to the next agent. This process iterates until a complete output is produced.
From a dynamical systems perspective, the paper models LLM generation as a trajectory through a high-dimensional latent semantic space. Honest agents act as contraction operators pulling the context toward a "truth direction," parameterized by the model’s spectral gap γH. Adversarial agents can only push the sequence off-course by a sycophancy-bounded perturbation, whose magnitude is tightly constrained by the context’s current state—corrupted generations inheriting enough truthful prefix are forced, due to perplexity pressure, to continue the correct chain of logic.
The paper proves a Lyapunov stability theorem: for sufficiently small K (i.e., frequent interventions), the restorative pull of honest agents dominates adversarial drift, even when corrupted agents are a numerical majority. The critical corruption threshold ρmax depends on the ratio of contraction and perturbation rates—for realistic parameterizations, systems can formally tolerate ρ>0.5. Numerical examples (e.g., with γH=0.03, δ=0.004V, K=100) demonstrate resilience up to 66% corrupted agents.
Empirical Validation: Multi-Agent Robustness under Adversarial Corruption
Extensive experiments on a variety of LLMs (Llama-3.3-70B, Llama-4-Scout-17B, Mistral-3.1-24B, Qwen2.5-32B, Qwen3-30B), spanning mathematical, logical, and causal reasoning benchmarks, empirically validate the theoretical guarantees. The evaluation injects both persuasive and imperative (hard) adversarial payloads to a controllable subset of agents.
Key empirical findings include:
- Collapse of MAJ: Once the majority is corrupted (e.g., 3c2t ensembles), MAJ accuracy on benchmarks like Track7 and GSM8K drops precipitously (examples: 0.8% for Llama-3.3-70B Track7, ht0 for Llama-70B GSM8K under imperative injection).
- Resilience of RR: RR collaboration orchestrates substantial recoveries, reaching up to ht1 absolute gain in the most challenging settings.
- Cost-Neutrality: RR maintains computational cost equivalence to MAJ, as total decoding steps are unchanged—the only overhead is lightweight, parallelizable pre-fill.
- Scalability: Increasing the number of RR trajectories enhances robustness due to the crossing of the accuracy probability threshold, while increasing MAJ samples exacerbates the failure due to the Condorcet trap.
- Ablations: Recovery is robust across chunk sizes, but too small (ht2) fragments logic, while too large (ht3) gives adversaries semantic runway.
Mechanistic Insights and Asymmetric Rescue
Analysis of log traces and heterogeneous ensembles reveals further properties:
- Final Speaker Irrelevance: Accuracy does not depend on whether the final token chunk is contributed by an honest or corrupted agent; the shared context constrains the final answer.
- Asymmetric Rescue: Even weak honest agents can "rescue" the sequence when collaborating with strong corrupted agents, while the reverse effect is negligible. This underlines the algorithmic dominance of logic consistency over adversarial persistence, provided the honest agent can inject verifiable constraints.
Practical Implications and Future Directions
The formal and empirical results provided in this paper illuminate a fundamental limitation of current multi-agent LLM deployment in open environments: response-level consensus mechanisms break under correlated adversarial pressure. Token-level interleaving converts aggregation from a fragile arithmetic process into a dynamically interwoven logical system, leveraging the depth of honest models to neutralize shallow manipulations. This insight has significant implications for robust LLM deployment in high-stakes applications exposed to strategic adversarial activity (e.g., financial planning, IT security, or regulated content moderation).
Future research directions highlighted include:
- Adaptive Adversaries: Studying adversaries with the ability to dynamically react to shared context changes.
- Dynamic Chunking: Optimizing the ht4 parameter for application-specific cost-robustness trade-offs.
- Integration with Modular Scaffolding: Combining RR with expert retrieval and domain specialization, as in recent collaborative and modular LLM decoding literature.
Conclusion
Token-Level Round-Robin collaboration provides a mathematically and empirically validated solution to the consensus trap in multi-agent LLM ensembles. By enabling mid-sequence correction and tightly constraining adversarial drift through shared logical context, RR achieves super-majority resilience unattainable via response-level aggregation. These findings advocate for a paradigm shift in LLM ensemble design and open pathways for robust, scalable deployment of AI systems in adversarial, real-world environments.
References
For complete references to all cited works and supporting literature, see (2604.17139).

