- The paper introduces Dr. MAMR, which redefines multi-agent LLM reasoning by countering lazy-agent behavior with novel reward restructuring.
- It integrates a Shapley-inspired causal influence model and adaptive deliberation to assign granular rewards and ensure balanced agent participation.
- Empirical tests on benchmarks like MATH500 and GSM8K show enhanced pass rates and stable multi-turn interactions compared to single-agent strategies.
Unlocking the Power of Multi-Agent LLM for Reasoning: From Lazy Agents to Deliberation
Introduction
The paper focuses on enhancing the reasoning capabilities of multi-agent systems using LLMs through a framework called ReMA, which incorporates meta-thinking and reasoning agents. A core issue identified in this framework is the emergence of lazy agents, particularly when one agent dominates the reasoning process, leading to inefficiencies. The paper proposes solutions to mitigate lazy agent behavior and optimize multi-agent collaboration for complex reasoning tasks.
Multi-Agent LLM Reasoning Framework
ReMA employs a dual-agent approach for problem-solving. The meta-thinking agent sets goals and adapts to feedback, while the reasoning agent executes step-by-step computations. The agents work sequentially on tasks, but lazy behavior can cause one to rely excessively on the other, undermining collaborative potential.
The framework is built on Multi-Turn Group Relative Preference Optimization (GRPO), enabling granular credit assignment for dialog turns. Despite these optimized mechanisms, lazy behavior persists due to inherent biases in GRPO's objective function, which favors shorter trajectories, inadvertently promoting minimal interaction between agents.
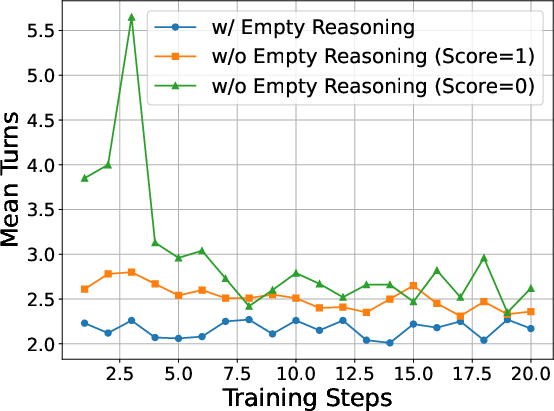
Figure 1: Mean number of turns comparing reasoning processes with and without lazy-agent behavior.
Identifying and Addressing Lazy Agents
The paper proposes Dr. MAMR, an advanced method to tackle lazy-agent issues. It includes:
- Theoretical Insights: The analysis reveals that GRPO's normalization bias incentivizes reduced turns. The paper demonstrates that unless longer rollouts are substantially more rewarding, the system favors shorter interactions, leading to superficial dialogue exchanges dominated by one agent.
- Shapley-inspired Causal Influence: ReMA's reliance on single trajectory estimation obscures turn-specific contributions. To rectify this, the authors introduce a Shapley-inspired model, which aggregates contributions across similar rollout steps, thus mitigating phrasal biases and creating robust causality estimates.
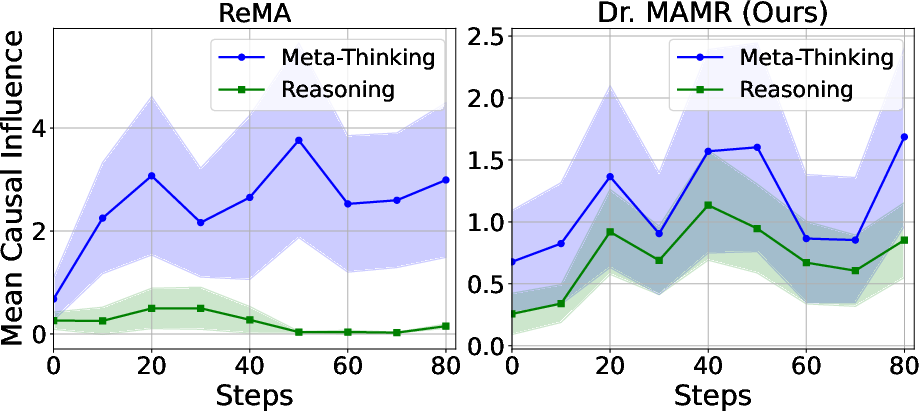
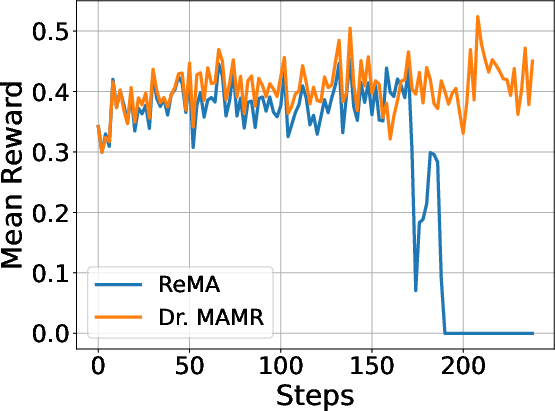
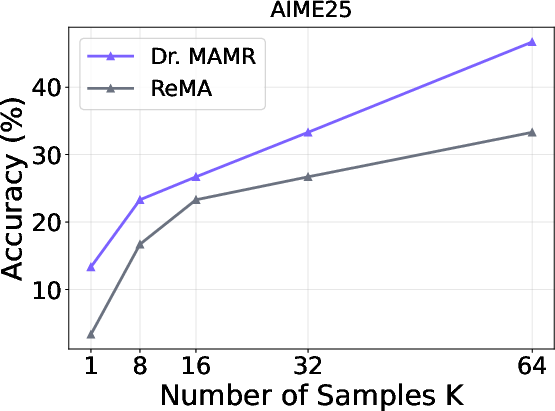
Figure 2: Causal influence across training steps.
- Adaptive Reasoning Agent Deliberation: Longer dialogues can lead agents astray due to context fragmentation. To counteract this, the reasoning agent can restart reasoning, discarding prior outputs when needed to achieve coherent problem-solving. This action is guided by a verifiable reward mechanism that assesses the agent's final probability of output correctness upon restart.
Empirical Evaluation and Results
Experiments on benchmarks like MATH500 and GSM8K demonstrate Dr. MAMR's efficacy. The multi-agent system clearly outpaces single-agent models like GRPO, showing increased pass rates and improved reasoning process stability across various tests.
The robust training curves of Dr. MAMR contrast sharply with ReMA, indicating sustained reward accumulation and stable learning, whereas ReMA frequently collapses due to reward-hacking phenomena, which are prevalent in reinforcement learning settings.
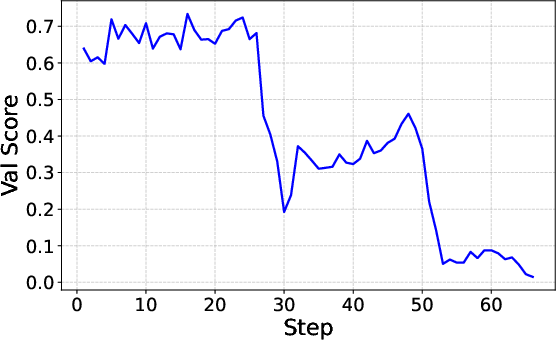
Figure 3: Training curve of ReMA with process reward assigned for each turn.
Forward-Looking Implications
Dr. MAMR enables balanced agent involvement by refining credit assignment and ensuring agents actively engage throughout problem-solving processes. The architecture vastly improves handling of complex tasks and fosters collaboration among specialized LLM agents. Future research can explore further refining causal inference and promoting synchronization in agent systems to avoid inefficiencies rooted in biased reward structures.
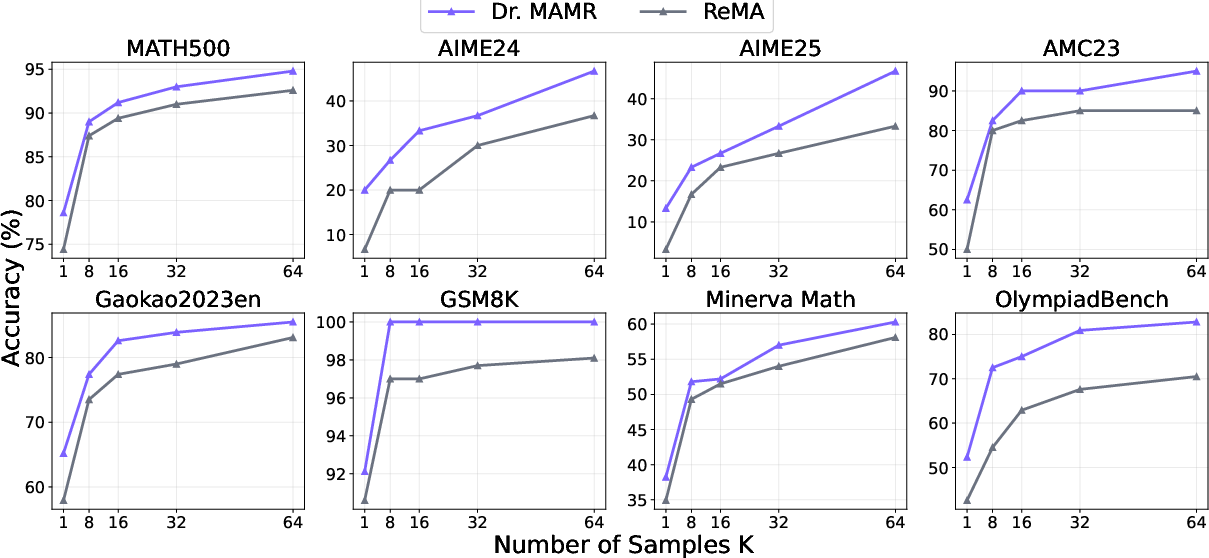
Figure 4: Pass@K performance.
Conclusion
The investigation into multi-agent LLM reasoning showcases critical improvements necessary to overcome the lazy-agent problem. Through Dr. MAMR, the paper successfully realigns GRPO's reward structure to support a cooperative agent ecosystem, unlocking the full potential of multi-agent setups in intricate reasoning scenarios. By advancing reward mechanisms and fostering active agent roles, Dr. MAMR lays a foundational pathway for future explorations into AI-driven collaborative reasoning systems.