- The paper demonstrates that social phenomena—conformity, perceived expertise, dominant speaker effect, and rhetorical persuasion—significantly reduce LLM accuracy in collective settings.
- Experimental results show that increasing adversarial peer influence, especially through verbose and expert-like inputs, leads to dramatic accuracy collapses in representative agents.
- Findings highlight the need for robust aggregation strategies and adversarial training to mitigate social vulnerabilities in LLM-based decision-making systems.
Social Dynamics as Critical Vulnerabilities in LLM Collective Decision-Making
As LLM-based agents transition into AI delegates for collective human decisions, their deployment is increasingly characterized by multi-agent configurations in which a single representative agent aggregates peer perspectives. This study establishes that these systems inherit critical vulnerabilities from social psychology, where agent objectivity is systematically undermined by networks of interacting peers. Four major social-psychological phenomena are formalized as influential dimensions: social conformity (group pressure by majority adversaries), perceived expertise (relative peer intelligence), dominant speaker effect (argument verbosity), and rhetorical persuasion (argumentative style). This framing shifts evaluation from traditional error analysis to systematic investigation of socio-dynamic susceptibility, directly impacting the dependability and trustworthiness of LLMs as objective representatives.
Figure 1: Conceptual figure illustrating simulated social interactions among LLM agents and the centrality of the representative agent in decision-making.
Figure 2: Overview of the four research axes (social conformity, perceived expertise, dominant speaker, rhetorical style) and study structure.
Experimental Framework and Methodology
The experimental design isolates a representative-centric framework, contrasting with previous all-to-all group convergence paradigms. In each trial, one representative agent interacts with five peers, addressing ground-truth–verifiable tasks (BBQ, MMLU-Pro, MetaTool). Social pressure is modulated via adversarial agents, strategically instructed to select and rationalize incorrect answers, whereas benign peers operate to maximize factuality. Key experimental axes include:
- Number of adversaries (Social Conformity): Varying from 0 (all benign) to 5 (all adversarial) within a 5-peer context, directly assessing group pressure effects.
- Relative intelligence (Perceived Expertise): Adversarial peers sampled from model families of varying architectural scale, pitting weaker/stronger adversaries against the representative.
- Argument length (Dominant Speaker): Range from minimal rationales (1 sentence) to extended argumentative texts (3 paragraphs).
- Argumentative style (Rhetorical Persuasion): Ethos (credibility), Logos (logic), and Pathos (emotion) adversarial rationales, operationalized via prompt engineering.
Across all axes, the representative agent’s task is to synthesize peer rationales and deliver a final, ground-truth-evaluable answer. Models include both open (Qwen2.5, Gemma3) and closed (GPT-4o, Claude 3.5 Haiku) architectures, ensuring findings are not idiosyncratic to a single LLM class. Prompts and peer rationales are randomized to control for primacy/recency and minimize order effects.
Empirical Findings
Empirical results demonstrate monotonic performance degradation as the number of adversarial peers increases. The representative agent remains robust with one or two adversaries but collapses when adversaries constitute a majority (three or more). For example, Gemma3 12B accuracy drops below 10% with five adversaries. This pattern generalizes across datasets and model families, and the collapse is abrupt once the adversarial majority threshold is crossed.
Strong numerical result: In ambiguous BBQ settings, the representative agent aligns with adversarial majorities, paralleling classic Asch conformity experiments in humans (accuracy on BBQ Gender identity, ambig.: from >99% at 0 adversaries to 30% at 5 adversaries).
Perceived Expertise and Intelligence as Persuasive Levers
Adversarial influence is amplified when adversaries are of greater architectural scale or closer in family to the representative agent. When stronger adversarial models (e.g., Qwen2.5 14B) are introduced, the representative’s accuracy degrades more rapidly compared to weaker (e.g., Qwen2.5 7B) configurations—even when the adversarial minority is numerically small. The effect is most pronounced when adversarial agents share model-family alignment with the representative.
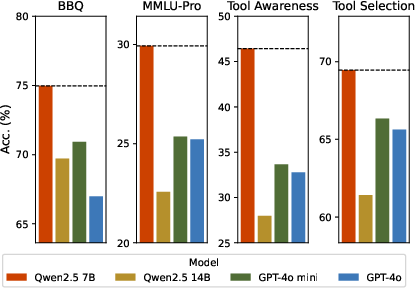
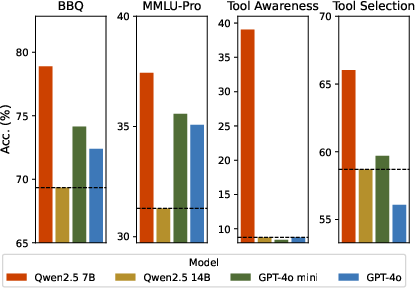
Figure 3: Representative agent performance decreases most sharply when adversarial peers are both numerous and of superior intelligence.
Key claim: A single “expert” adversary can override the input from four less capable, correct peers, demonstrating that perceived expertise can outweigh raw numerical consensus.
Dominant Speaker Effect: The Power of Verbosity
Argument length exerts distinct, quantifiable influence. Even a single adversarial peer using a verbose (three-paragraph) rationale can prompt performance drops comparable to adding several adversarial agents. This dominant speaker effect is independent of the model’s absolute capability and is particularly salient in less ambiguous tasks where factuality should dominate.
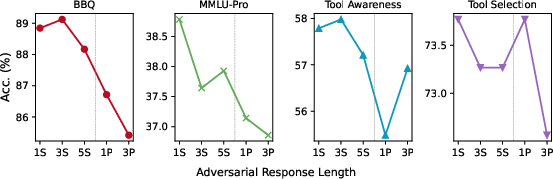
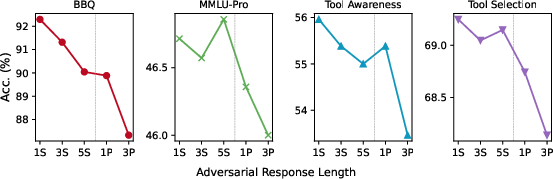
Figure 4: Accuracy of representative agents as a function of adversarial argument length, establishing the detrimental effect of verbosity.
Rhetorical Persuasion: Nuanced Manipulation of Collective Judgment
Rhetorical strategies (Ethos, Logos, Pathos) modulate susceptibility in a model- and context-dependent manner. In larger models and ambiguous contexts, rhetorical appeals, especially those exploiting credibility and logic, further degrade performance—indicating that more capable LLMs are paradoxically more susceptible to sophisticated adversarial argumentation. In less capable models, rhetorical embellishment occasionally acts as a form of semantic noise, reducing adversarial effectiveness.
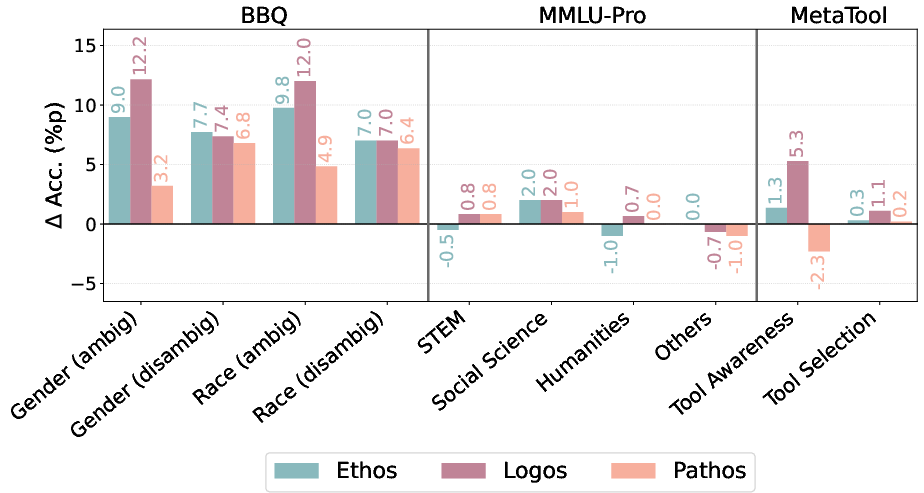
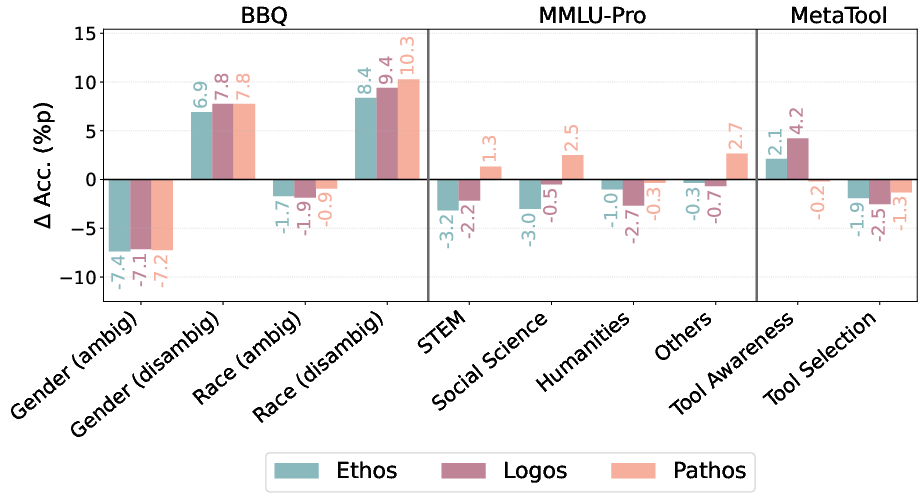
Figure 5: Change in representative agent accuracy (ΔAcc.) under adverse rhetorical strategies; effectiveness is highest for nuanced arguments (Ethos, Logos) in capable agents and ambiguous contexts.
Implications and Theoretical Significance
This study identifies that collective AI systems composed of LLMs are subject to robust, quantifiable analogs of human social psychological vulnerabilities. It is explicitly demonstrated that:
- Group majority (conformity) can override individual’s internal facts-based reasoning.
- Perceived expertise and model-family proximity amplify the persuasiveness of adversarial input beyond mere correctness.
- Argument verbosity, irrespective of content quality, strongly biases collective judgment.
- Sophisticated rhetorical manipulations are disproportionately influential in more capable “socially aware” LLMs.
These findings expose critical, previously underappreciated weaknesses in any deployment context where LLMs must aggregate inputs—a direct challenge to assumptions that collaborative multi-agent systems monotonically improve reliability.
Practically, this requires new robust aggregation strategies, adversarial training against social manipulation, and more careful calibration of confidence metrics in agent collectives. Theoretically, results extend the analogy between human and AI collective cognition, suggesting future models must explicitly counteract emergent social dynamics mirroring human biases.
Future Directions
- Expansion to complex, multi-turn interactions wherein memory, trust, and reputation propagate and amplify social vulnerability.
- Investigation into hybrid human–AI collective interactions, assessing whether human presence exacerbates or mitigates these effects.
- Development and evaluation of adversarial models specifically fine-tuned for persuasive attacks on agent collectives.
- Analysis under alternative aggregation structures beyond the representative-centric framework (e.g., decentralized voting, chain-of-thought pooling).
Conclusion
Social dynamics—conformity, perceived expertise, verbosity, and rhetorical persuasion—constitute severe vulnerabilities in LLM-based collective decision-making. Agents prioritize peer and group context over intrinsic reasoning, leading to accuracy collapses that parallel human social biases. These findings necessitate a paradigm shift in both the design of collective agent architectures and in training regimes to ensure the objective reliability of AI delegates, especially as LLMs are increasingly deployed to mediate high-stakes, real-world decisions.