- The paper introduces a novel metric for detecting representational collapse by measuring cosine similarity and effective rank among LLM agents.
- It develops DALC, a diversity-aware consensus protocol that uses projection methods to recalibrate agent influence and reduce token cost.
- Experimental results on GSM8K and MATH-500 demonstrate DALC’s efficiency improvements and highlight encoder sensitivity in multi-agent settings.
Representational Collapse in Multi-Agent LLM Committees: Diagnostic Measurement and Diversity-Aware Consensus
Motivation and Background
The aggregation of outputs from replicated LLM agents, differentiated by role prompts, underpins the reliability and accuracy improvements in committee-based agentic architectures. Standard approaches such as self-consistency and majority voting operate under the assumption that agent outputs are sufficiently independent and diverse, enabling error correction and complementarity. This assumption is rarely tested empirically within the context of LLM committees, especially those composed of identical models. The paper addresses this gap by introducing the phenomenon of representational collapse, quantifies it using embedding-based statistics, and proposes DALC (Diversity-Aware Latent Consensus), a protocol to leverage detected diversity at aggregation time.
Measuring Representational Collapse
Representational collapse is defined as excessive embedding similarity among chain-of-thought rationales generated by role-conditioned LLM agents. Using a frozen encoder (nomic-embed-text, 768d), embeddings from three Qwen2.5-14B agents (methodical solver, skeptical verifier, concise expert) reveal a mean pairwise cosine similarity of 0.888 and an effective rank of 2.17 (out of 3). The effective rank, computed from singular values, quantifies the intrinsic dimensionality spanned by the committee’s outputs. Results indicate that shifting role prompts produces minor surface variation in generated text but not substantial representational diversity; agents often occupy a narrow cone in embedding space. This structure undermines the independence assumption behind majority voting, risking error amplification.
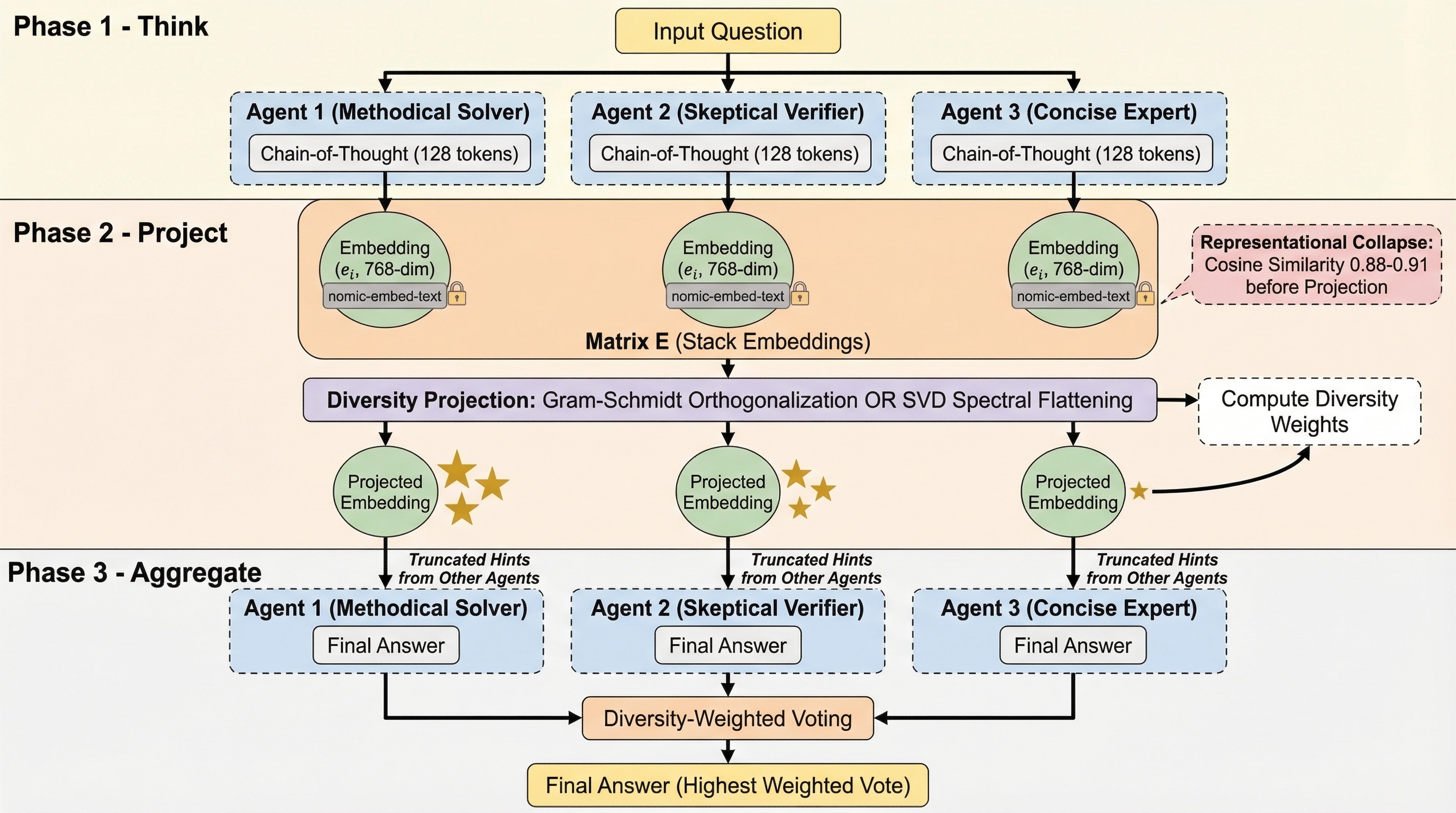
Figure 1: DALC protocol: role-conditioning, embedding and decorrelation, hint sharing, and diversity-weighted voting; pre-projection cosine similarity 0.88–0.91 highlights collapse.
The DALC Protocol: Diversity-Aware Aggregation
DALC operationalizes this diagnostic: after short chain-of-thought generation, embeddings are optionally projected to maximize orthogonality (Gram-Schmidt, SVD, or identity), and diversity-weighted voting is computed as wi∝1−sˉi, where sˉi is the agent’s mean cosine similarity to all others. Agents receive truncated hints from other agents’ rationales and produce final answers, aggregated by diversity-weighted voting. Unlike classical diversity-aware selection (MMR, DPPs), DALC retains all chains and adjusts influence post hoc, compatible with agentic deployments where generation is a sunk cost.
Experimental Evaluation
The paper benchmarks DALC against baselines on GSM8K and MATH-500 using Qwen2.5-Instruct (14B, 7B). Results on GSM8K (14B, n=100) demonstrate that DALC-Id achieves 87% accuracy at 26% lower token cost than self-consistency (SC, 84%). DALC-SVD scores 86%; DALC-GS, despite perfect orthogonalization, falls to 83%. On MATH-500, DALC variants match or slightly surpass SC (57% vs. 56%) at roughly two-thirds the token cost. These token savings (25–34%) are robust across methods and model scales.
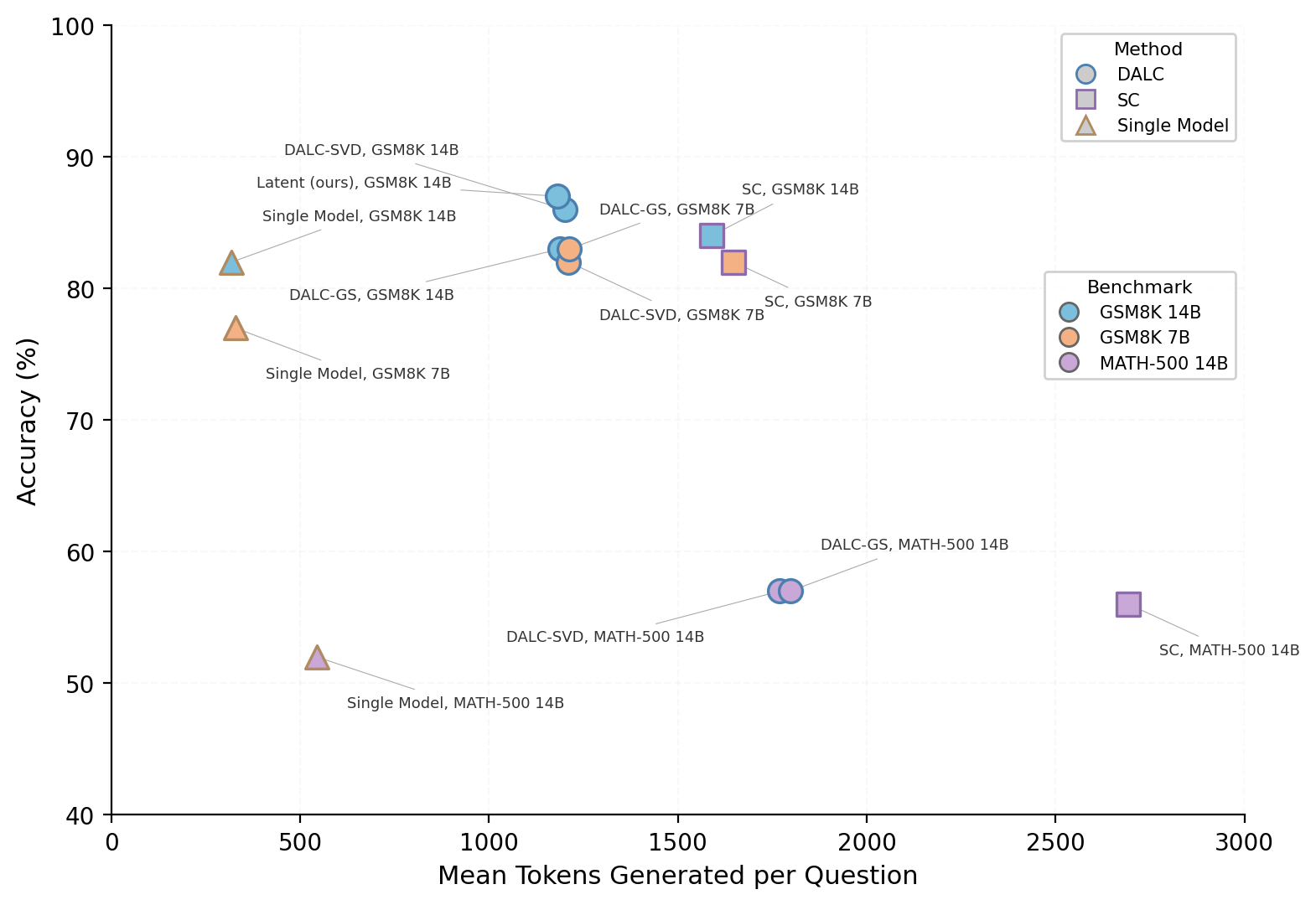
Figure 2: DALC achieves comparable or higher accuracy than self-consistency at substantially reduced token cost, across benchmarks and scales.
Collapse Severity, Downstream Impact, and Encoder Sensitivity
Collapse metrics, averaged across 100 questions, confirm high redundancy (cosine > 0.87, rank ≈2.1). SVD projection shifts metrics negligibly; hard Gram-Schmidt orthogonalization yields perfect diversity geometrically, but not in downstream accuracy—DALC-GS underperforms relative to DALC-Id and SVD, suggesting that sentence-level embeddings are a coarse proxy for reasoning diversity. Collapse worsens on MATH-500 (harder tasks), supporting the intuition that agents converge more tightly when confident alternative paths are scarce.
Encoder sensitivity is pronounced: replacing nomic-embed-text with mxbai-embed-large further raises cosine similarity (0.908) and reduces effective rank (2.09), coinciding with DALC variants losing their advantage over baselines. This indicates that embedding geometry directly governs detectable diversity, and hence, protocol effectiveness. The embedding proxy must be validated for reasoning-relevant distinctions prior to deployment.
Ablation Studies and Robustness
Three ablation studies elucidate protocol contributions:
- Run-to-run variance: Stochasticity in agent output results in 1–3 point swings between independent runs, rendering 1–5 point accuracy differences between protocols within noise.
- No-hints ablation: Diversity weighting alone explains most protocol benefits; hint sharing yields marginal additional gains.
- Encoder ablation: The latent protocol’s effectiveness collapses with an encoder that induces excessive similarity, underscoring the dependency on representation space.
Collapse measurements are stable across runs, confirming their structural significance.
Theoretical and Practical Implications
Representational collapse presents a critical bottleneck for scalable multi-agent committees. Empirically measuring embedding overlap via a pilot run provides a diagnostic to determine effective committee size: with cosine >0.88, three agents deliver the diversity of two chains, undermining the rationale for scaling up. This has direct implications for resource allocation and error resilience in agentic systems. Furthermore, unanimous agreement within a collapsed committee is not an indicator of robustness—confidence policies should be augmented with diversity diagnostics (e.g., effective rank).
The protocol and its findings challenge assumptions underlying latent communication methods, such as LatentMAS and ThoughtComm, as their effectiveness hinges on the embedding proxy. Practical deployment demands careful encoder selection and validation to guarantee that diversity measurements reflect genuine reasoning independence.
Limitations and Future Directions
Accuracy improvements are modest and within stochastic variance; a factorial design varying hint sharing, weighting, and projection would clarify protocol contributions. Results are restricted to two Qwen2.5 scales, two encoder families, and N=3 agent committees. Future exploration should encompass cross-architecture committees, large N, prompt diversity, expert-level benchmarks, and hidden-state probes with advanced similarity measures (CKA, SVCCA).
Conclusion
This research provides rigorous quantification of representational collapse in multi-agent LLM committees, demonstrating its prevalence and operational consequences in resource allocation and aggregation schemes. DALC offers a protocol to exploit diversity, but its benefit is constrained by collapse severity and encoder characteristics. Effective deployment of agentic systems requires embedding-based diagnostics and careful validation of representation spaces to ensure genuine reasoning independence, with implications for both practical efficiency and theoretical understanding of committee dynamics.