Can AI Agents Agree?
Abstract: LLMs are increasingly deployed as cooperating agents, yet their behavior in adversarial consensus settings has not been systematically studied. We evaluate LLM-based agents on a Byzantine consensus game over scalar values using a synchronous all-to-all simulation. We test consensus in a no-stake setting where agents have no preferences over the final value, so evaluation focuses on agreement rather than value optimality. Across hundreds of simulations spanning model sizes, group sizes, and Byzantine fractions, we find that valid agreement is not reliable even in benign settings and degrades as group size grows. Introducing a small number of Byzantine agents further reduces success. Failures are dominated by loss of liveness, such as timeouts and stalled convergence, rather than subtle value corruption. Overall, the results suggest that reliable agreement is not yet a dependable emergent capability of current LLM-agent groups even in no-stake settings, raising caution for deployments that rely on robust coordination.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: if we put several AI chatbots in a group and ask them to agree on one number, can they actually agree? The twist is that some group members might be “troublemakers” or broken on purpose. The authors build a controlled game to test how well AI agents reach agreement and what makes them fail.
What are the researchers trying to find out?
They focus on four plain questions:
- Can groups of AI agents agree on a number when no one cares which number it is, as long as they all match?
- Do bigger, stronger AI models agree more reliably than smaller ones?
- What happens when a few agents are faulty or try to disrupt the group?
- When things go wrong, is it because they choose a bad number, or because they never finish agreeing?
How did they test this?
Think of a classroom where:
- Each student starts with a random number between 0 and 50 written on a sticky note.
- In each “round,” every student tells everyone else their current number and a short reason for it.
- After hearing from everyone, each student can either “vote to stop” (if they think the group has agreed) or say “continue.”
- The teacher ends the activity only if at least two-thirds of the class votes to stop. If they never reach that point within 50 rounds, it’s a timeout.
Two types of students:
- Honest students: they start with a random number and try to agree.
- Byzantine students: these are troublemakers. They can send confusing numbers or reasons to slow things down. In this test, they’re limited: they must send the same message to everyone (no private lies), and they can’t block messages.
The AI agents:
- Each student is actually an AI model that reads a short summary of the last round, then proposes a number, explains why, and decides whether to stop.
- The researchers used two AI model sizes from the same family: Qwen3-8B (smaller) and Qwen3-14B (larger).
- They tested different group sizes (4, 8, and 16 agents), and tried two instruction styles: one that mentions possible troublemakers and one that doesn’t.
- For each setup, they ran 25 separate simulations to see patterns, not just one-off luck.
Two kinds of “success” they tracked:
- Validity: if the group agrees, is the final number one that originally came from an honest agent?
- Liveness: does the group actually finish and agree within the time limit?
In everyday terms: “validity” means they didn’t pick a made-up or suspicious number; “liveness” means they didn’t stall forever.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- Agreement is hard even without troublemakers.
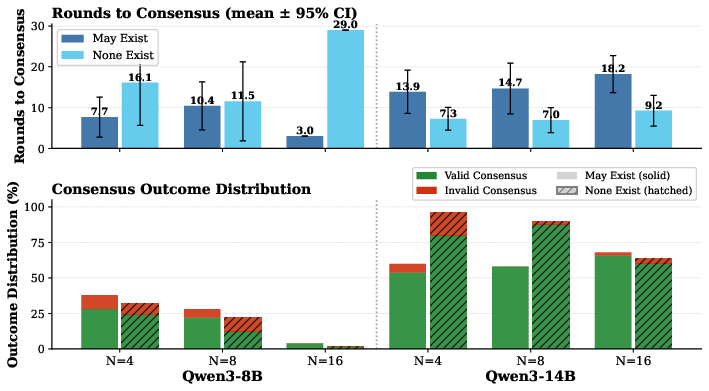
- Across many tests with no bad agents, groups only reached a valid agreement about 42% of the time before the time limit.
- Bigger model helps: the larger model (Qwen3-14B) agreed much more often than the smaller one (67% vs 16%).
- Larger groups struggled more: going from 4 to 16 agents made agreement less likely and slower.
- Just mentioning possible attackers can hurt finishing.
- When the instructions warned agents that bad actors might exist, they were more cautious and slowed down.
- With the larger model, not mentioning attackers raised valid agreement from about 59% to 75% and sped things up.
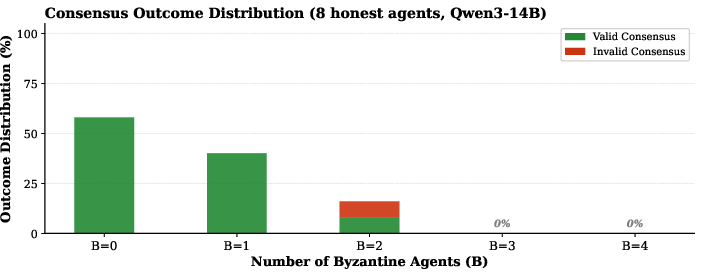
- Adding even a few troublemakers makes agreement much harder.
- When they added 1 to 4 Byzantine agents into a group with 8 honest agents, agreements often failed to happen at all.
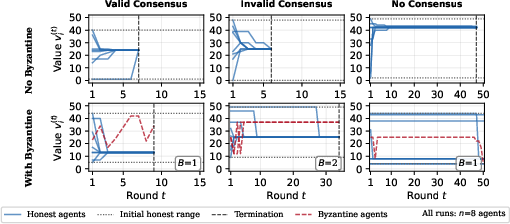
- Importantly, the agents rarely agreed on the “wrong” number; instead, they mostly failed by never finishing (timeouts). In other words, the main problem was liveness, not picking a corrupted value.
- The main failure mode is “not finishing,” not “choosing badly.”
- Most failures were due to stalling, hesitation, or indecision rather than the group being tricked into a wrong outcome.
Why this matters: Many real systems—like fleets of delivery drones coordinating routes, software systems deciding on updates, or multi-agent AI teams planning tasks—need reliable agreement. If even small groups of today’s AI agents struggle to finish agreeing, and just one troublemaker can stall them, then we should be cautious about using them for important coordination tasks without extra safeguards.
What does this mean for the future?
The big message: current AI agents are not yet dependable “team players” for reaching agreement, even in a simple, no-stakes game where any honest number is fine. Before deploying AI groups in the real world for coordination, we likely need:
- Stronger rules and protocols that keep the group moving toward a decision (better “liveness”).
- Robust designs that can handle different kinds of troublemakers, not just the limited ones tested here.
- Better prompts and instructions that encourage steady progress without making agents overly cautious.
- Possibly larger or more capable models, as larger models performed better, though they still weren’t perfect.
Overall, this study is a caution sign: agreement isn’t yet an automatic or “emergent” skill of current AI groups. More research is needed to make AI agents reliable at reaching consensus, especially when things go wrong.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The study raises several unresolved issues that future work can concretely address. Below is a single, actionable list of gaps and open questions:
- External validity across models: only Qwen3-8B/14B were tested; it remains unknown how results transfer to other families (e.g., Llama, GPT, Claude, Mixtral) and to larger or smaller models.
- Homogeneous teams: all agents used the same model and prompts; the effects of heterogeneous teams (mixed model families/sizes, specialized roles) on agreement and robustness are unexplored.
- Narrow task domain: the game is scalar, no-stake consensus over [0,50]; performance on higher-dimensional, discrete/structured, constrained, or real-stakes decisions with agent preferences is unknown.
- Limited initial-value regimes: only i.i.d. uniform initialization was used; how different distributions (clustered, multimodal, adversarially skewed) affect convergence and validity is not studied.
- Small scale: benign settings tested up to N=16; adversarial up to 12 total agents; scaling behavior and potential “failure scaling laws” for larger N are uncharacterized.
- Single topology and timing: only synchronous, all-to-all communication was considered; behavior under partial synchrony, asynchrony, delays, message loss, and sparse or dynamic topologies is unknown.
- Restricted threat model: Byzantine agents could not equivocate, forge identities, drop/suppress messages, or perform Sybil attacks; robustness to stronger and more realistic adversaries is untested.
- Limited adversarial strategies: the paper notes using a single Byzantine strategy; systematic exploration of diverse, adaptive, and coordinated adversarial policies (e.g., RL or search-learned tactics) is missing.
- No systematic study of collusion: the impact of coordinated Byzantine behaviors (including targeted stalling or value-herding) across varying fractions and team structures remains open.
- Termination rule design: the fixed 2/3-of-all stop rule may enable easy stalling; how alternative quorums (e.g., stronger quorums, weighted or reputation-based voting, leader-driven commits) trade off liveness vs. safety is unexamined.
- Timeout sensitivity: T_max was fixed at 50; the sensitivity of outcomes to timeout budgets and adaptive stopping policies is not quantified.
- Decoding and sampling effects: temperature, top-p, nucleus sampling, deterministic vs. stochastic decoding, and guided-decoding constraints were not ablated; their impact on liveness and validity is unknown.
- Prompting confounds: only two honest-agent prompt variants (adversary mentioned vs. not) were evaluated; deeper prompt design ablations (e.g., explicit procedural rules, stop criteria framing, role instructions) and their causal mechanisms on liveness remain unclear.
- History management: agents saw only compact summaries of the previous round; whether richer memory (full history, multi-round summaries, structured logs, external memory) improves reliability is untested.
- Message content design: the effects of justification length, structure, and the inclusion of explicit state (e.g., votes received, proposed quorums) on coordination have not been ablated.
- Private strategy handling: the role and utility of the private strategy state r_it were not analyzed; how different forms of internal memory/planning affect convergence is unknown.
- Mechanistic diagnosis of liveness loss: while timeouts dominate failures, the concrete behaviors causing stalls (e.g., oscillations, overcautious voting, anchoring, deadlocks) are not systematically categorized or measured.
- Effect of “adversary awareness”: mentioning possible adversaries harms liveness, but the mechanism (e.g., increased caution, cognitive load, paranoia heuristics) is not probed; targeted wording and instruction ablations are needed.
- Baseline comparisons: there is no side-by-side baseline with classical BFT algorithms implemented in the same simulator to isolate whether failures stem from LLM behavior vs. protocol design or simulator constraints.
- Protocol scaffolding: the study tests free-form LLM policies; whether algorithmic scaffolding (e.g., explicit BFT pseudocode, tool-use for vote counting, state machines, or verifiable logs) can recover liveness and safety is unknown.
- Confidence and calibration: agents do not expose or use calibrated confidence; whether confidence-weighted aggregation or self-consistency checks improve outcomes is untested.
- Detection and mitigation of Byzantine agents: no mechanisms for adversary detection, quarantine, reputation, or reconfiguration are evaluated; the feasibility and effectiveness of such defenses are open.
- Cost/latency and resource trade-offs: the compute, latency, and bandwidth costs of multi-round, multi-agent LLM consensus—and how resource limits degrade reliability—are not analyzed.
- Generalization across languages and domains: the study is in English and a narrow numeric domain; cross-lingual behavior and application domains with richer semantics are unexamined.
- Reproducibility and variance sources: with 25 runs per configuration, the statistical power to detect smaller effects is limited; sensitivity to random seeds, batching effects, and inference backends needs quantification.
- Safety metrics beyond validity: validity is defined as choosing an initial honest value; broader safety properties (e.g., consistency under reconfigurations, integrity under stronger faults, persistence of decisions) are not assessed.
- Leadership and role specialization: the potential benefits of leader-based protocols, proposer/validator roles, or rotating leadership to break symmetries and accelerate termination are unexplored.
- Quorum intersection and commit rules: designs ensuring strong quorum intersections (à la PBFT/HotStuff) and their realizability via LLM policies are not investigated.
- Mixed-initiative oversight: the effects of lightweight human audit, automated monitors, or rule-checkers to prevent stalls or invalid commits are not tested.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that translate the paper’s findings into design choices, testing practices, and controls across sectors.
- AI agent orchestration guardrails (software, enterprise IT)
- Replace “agent consensus” with deterministic controllers for correctness-critical steps; use single-agent decisions plus tool calls, or classical consensus (Raft/Paxos/Tendermint) if agreement is required.
- Add leader-of-last-resort and bounded-round policies (e.g., T_max) with escalation to a human when liveness degrades.
- Potential tools/workflows: “Consensus Gate” microservice that routes any agreement step to a BFT engine; “Leader fallback” workflow in LangGraph/AutoGen-like orchestrators.
- Dependencies/assumptions: Results are from a no-stake scalar task under synchronous all-to-all messaging and a non-equivocating adversary. Generalization to complex tasks requires validation.
- Agent team sizing and topology tuning (software, MLOps)
- Cap group sizes and prefer simple topologies to mitigate the observed liveness degradation with increasing N.
- Potential tools/workflows: “Team Size Tuner” that auto-finds the smallest agent team satisfying latency/SLO targets; “Topology switcher” that collapses to star/leader topologies for convergence.
- Dependencies/assumptions: Liveness degradation with scale was observed on Qwen3-8B/14B; other models/topologies should be re-tested.
- Prompt hygiene for liveness (software, education, enterprise apps)
- Avoid threat-aware language in prompts when adversaries are not expected; the paper shows such warnings harm liveness even in benign settings.
- Potential tools/workflows: “Prompt Switcher” that toggles threat-aware phrasing only when a credible adversarial risk is detected; prompt linting rules in CI for agent apps.
- Dependencies/assumptions: Effect measured on this task and model family; evaluate for domain-specific prompts before broad rollout.
- Liveness-first SLOs and monitoring for agent systems (software, DevOps/MLOps)
- Track and alert on timeouts, stalled convergence, and premature stops; define “Agent Liveness SLOs” distinct from accuracy metrics.
- Potential tools/products: Liveness dashboards integrated with LangSmith/Weights & Biases; “Consensus Watchdog” that terminates cycles and triggers fallback.
- Dependencies/assumptions: Requires instrumentation at the agent framework level and agreement on SLO thresholds.
- Red-teaming and acceptance testing with Byzantine injects (industry, academia)
- Use the paper’s A2A-Sim-style setup to stress-test multi-agent apps with controlled Byzantine fractions and measure liveness vs. validity.
- Potential tools/workflows: A2A-Sim-inspired test harness in CI/CD; “Byzantine Fuzzer” that introduces non-equivocating adversarial behaviors and evaluates outcome distributions.
- Dependencies/assumptions: The paper’s adversary cannot equivocate; include stronger adversaries over time.
- Sector-specific safeguards
- Healthcare: Do not rely on AI agent consensus for treatment plans or triage; use guideline engines and clinician review; if agents are used, treat them as independent second opinions with a deterministic adjudication rubric.
- Dependencies: Regulatory constraints; patient safety.
- Finance/back-office reconciliation: Replace agent “agreement” with rule-based reconciliation and human approval; agents provide rationales and candidate matches only.
- Dependencies: Auditability and compliance requirements.
- Robotics/multi-robot systems: Keep LLMs at high-level reasoning; use classical distributed consensus or a central planner for coordination.
- Dependencies: Real-time constraints; existing ROS2/BFT modules.
- Education/group tutoring: Use a moderator/leader agent; cap group size; present multiple rationales rather than forcing agent consensus.
- Dependencies: Pedagogical goals; platform UI to surface diverse answers.
- Energy/operations (grid, SCADA): Use deterministic control and operator playbooks; allow LLM agents as advisory only with strict liveness timeouts and human gating.
- Dependencies: Safety margins and ops procedures.
- Governance and policy-in-practice (policy, enterprise risk)
- Update AI risk registers: flag multi-agent consensus as a reliability risk; require proofs-of-liveness or fallback plans before production use.
- Procurement guidance: Require vendors to disclose consensus mechanisms and liveness mitigation.
- Dependencies/assumptions: Organizational change management and audit processes.
- Reproducible benchmark adoption (academia, R&D labs)
- Adopt the provided simulator and metrics (valid/invalid/no-consensus, rounds-to-termination) to compare models, prompts, and threat models in lab settings.
- Dependencies/assumptions: Compute budget for repeated runs (25+ per config) and access to model-serving stacks (e.g., vLLM).
Long-Term Applications
These applications require further research, scaling, or development to be reliable.
- Hybrid BFT–LLM consensus frameworks (software, blockchain, robotics)
- Architectures where LLMs propose and justify options, but agreement is executed by formally verified BFT protocols; optionally include confidence-weighted or trust-scored aggregation.
- Potential products: “Agent Swarm OS” with pluggable BFT backplanes; “Consensus Proxy” SDKs for LangChain/AutoGen.
- Dependencies/assumptions: Identity, signing, and secure broadcast; handling equivocation; latency/cost trade-offs at scale.
- Training LLMs for liveness-aware coordination (academia, foundation model providers)
- Fine-tune with process-level rewards (e.g., terminating within bounds, protocol adherence) and adversarial curricula; learn “stop” policies and leader roles.
- Potential tools: RL from process feedback; synthetic curricula generators; chain-of-vote datasets.
- Dependencies/assumptions: Access to training pipelines; generalization beyond scalar tasks; evaluation standards.
- Protocol innovation for stochastic agents (academia, standards)
- Design consensus protocols robust to stochastic, prompt-driven agents, including asynchronous settings and heterogeneous populations; formalize validity/liveness trade-offs and stopping rules.
- Potential outputs: New protocol specs, proofs, and reference implementations for agent frameworks.
- Dependencies/assumptions: Theoretical advances and large-scale empirical validation.
- Secure multi-agent infrastructure (software, cybersecurity, identity)
- Add identity, message signing, anti-equivocation broadcast, and ledger-backed audit trails for agent communications; enable accountable and replayable decision processes.
- Potential products: “Agent PKI,” secure pub/sub buses with attestations, ledger-based conversation journals.
- Dependencies/assumptions: Standards for agent identity; privacy/compliance constraints.
- Domain-certified multi-agent systems (policy, healthcare, aviation, energy)
- Certification programs and regulatory standards for multi-agent AI use in safety-critical domains, including mandated liveness/validity testing under adversaries.
- Potential outcomes: NIST/ISO test suites; industry-specific compliance marks; regulatory sandboxes.
- Dependencies/assumptions: Consensus on metrics, robust evidence from cross-model evaluations.
- AI governance and DAO-like systems with robust agreement (finance, Web3, enterprise governance)
- AI-enabled committees/DAOs that make bounded, auditable decisions using hybrid consensus; automated boardrooms with human-in-the-loop for final ratification.
- Potential products: Governance agents integrating BFT voting, rationale tracing, and policy constraints.
- Dependencies/assumptions: Legally recognized decision frameworks, reliable identity, and on-chain/off-chain interoperability.
- Personal “AI teams” that can truly coordinate (consumer, productivity)
- Household scheduling, budgeting, and travel planning teams that converge reliably using protocol-aware agents and deterministic tie-breakers.
- Potential products: Consumer orchestrators with built-in liveness guarantees and graceful degradation to a single agent.
- Dependencies/assumptions: Efficient local/on-device inference; robust protocols usable by non-experts.
- Expanded benchmark ecosystems and open datasets (academia, industry consortia)
- Large-scale evaluations across models, adversary classes (including equivocating attackers), network conditions, and task types (beyond scalar values).
- Potential outputs: Public leaderboards, challenge tracks, and community baselines.
- Dependencies/assumptions: Shared compute, reproducibility infrastructure, and data standards.
Cross-cutting assumptions and dependencies to consider
- The study focuses on a no-stake scalar task, synchronous all-to-all messaging, and non-equivocating adversaries; real deployments may face utility-bearing tasks, partial synchrony, identity attacks, and equivocation.
- Findings were measured on Qwen3-8B/14B with compact history summaries; other model families, longer contexts, or tool-augmented agents may differ.
- High timeout/stall rates highlight latency and cost concerns in large agent collectives; SLOs must reflect these trade-offs.
- Validity failures were rare while liveness failures dominated; applications should prioritize termination guarantees and fallback design over value-optimization in early deployments.
Glossary
- A2A-Sim: The paper’s synchronous all-to-all simulator used to orchestrate agent messaging, rounds, and outcomes. "We run 600 simulations using A2A-Sim,"
- batched inference: Serving multiple model queries in parallel to improve throughput and efficiency. "All experiments were conducted using vLLM for batched inference and guided-decoding."
- Byzantine agent: An adversarial participant that may behave arbitrarily to disrupt or bias consensus. "Introducing a small number of Byzantine agents further reduces success."
- Byzantine consensus: Consensus in the presence of potentially malicious (Byzantine) participants. "We evaluate LLM-based agents on a Byzantine consensus game over scalar values using a synchronous all-to-all simulation."
- Byzantine fault-tolerant consensus: A class of consensus protocols that remain correct despite a bounded number of Byzantine faults. "Classical Byzantine fault-tolerant consensus provides strong guarantees for deterministic algorithms"
- Byzantine fraction: The proportion of agents that are Byzantine in the system, often denoted f. "First, we introduce a controlled Byzantine fraction."
- confidence-weighted consensus: An aggregation approach where agent votes are weighted by their reported confidence. "proposes aggregation mechanisms such as confidence-weighted consensus"
- context window: The maximum number of tokens the model can condition on in a single input. "8{,}192 tokens context window."
- equivocate: To send different messages to different recipients, a classic Byzantine behavior. "they cannot equivocate (send different messages to different recipients)"
- FP16/BF16 precision: Reduced-precision floating-point formats used to speed up and scale model serving. "FP16/BF16 precision"
- guided-decoding: Constraining generation (e.g., to schemas or formats) by guiding the decoder during inference. "All experiments were conducted using vLLM for batched inference and guided-decoding."
- i.i.d.: Independent and identically distributed; a standard assumption for random initialization of variables. "initialized at t=0 by sampling i.i.d. from a fixed distribution"
- liveness: The property that the system eventually makes progress or terminates (as opposed to stalling). "Failures are dominated by loss of liveness"
- no-stake setting: A scenario where agents have no utility preference over the final agreed value. "a no-stake setting where agents have no preferences over the final value"
- synchronous all-to-all network: A communication model where, in lockstep rounds, every agent sends the same message to all others. "on a synchronous all-to-all network"
- termination vote: An agent’s explicit decision to stop or continue the protocol in a given round. "Query the LLM to emit a termination vote"
- threat model: The assumed capabilities and limitations of adversaries used to analyze robustness. "We demonstrate that even this straightforward threat model can have a substantial impact on consensus performance."
- validity constraint: A requirement that any decided value must come from the initial proposals of honest agents. "we enforce a validity constraint requiring the decided value to be an initial honest proposal."
- vLLM: A system for efficient LLM serving used to run experiments in the paper. "All experiments were conducted using vLLM for batched inference and guided-decoding."
- Wilson confidence interval: A binomial proportion interval with good small-sample properties used for reporting outcome rates. "95% Wilson confidence intervals"
Collections
Sign up for free to add this paper to one or more collections.

