Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Abstract: Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of LLMs. Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision LLMs (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Render-of-Thought” for a 14-year-old
1. What is this paper about?
This paper looks at a problem with how AI models think through tough questions. Many strong AI systems write out long step-by-step explanations, called “chain-of-thought,” to solve math or logic problems. That works well, but it’s slow and uses a lot of computer power.
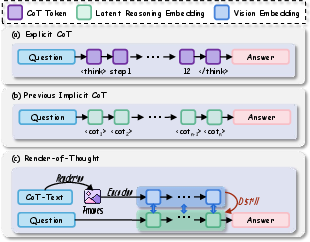
The authors introduce “Render-of-Thought” (RoT), a new way to speed things up. Instead of making the AI write long text steps, they turn those steps into small images and let the model “think” in a compact visual form. This makes the thinking process shorter and faster, but still understandable and traceable.
2. What goals or questions did the researchers have?
The paper asks simple but important questions:
- Can we make AI reasoning faster by compressing its step-by-step thinking?
- Can we keep the AI’s reasoning clear and traceable, even if we compress it?
- Can we reuse existing vision-LLMs (AI that understands images and text) without retraining everything from scratch?
3. How did they do it? (Methods in everyday language)
Think of normal chain-of-thought like writing a long essay to show your work. Render-of-Thought turns that “essay” into a thin, single-line image that shows the same content but in a more compact format.
Here’s the approach, step by step:
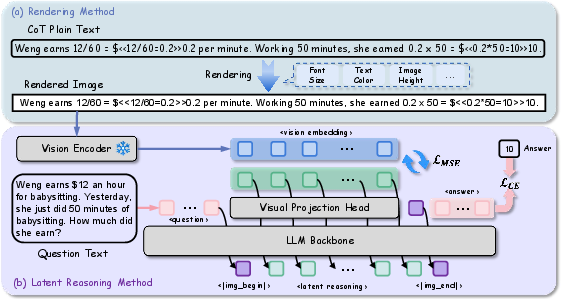
- Turning text into images:
- They “render” each step of the AI’s reasoning into a slim, single-line image (black text on a white background).
- The image has a fixed height and a width that grows as needed, so the text stays left-to-right and in order—just like reading a line of text.
- Using a vision-LLM as an anchor:
- A vision encoder (the part of a model that understands images) converts each reasoning image into numbers called “embeddings.” Think of embeddings like a neat code that captures the meaning of the image.
- These embeddings act as “semantic anchors,” guiding the AI’s internal reasoning to match what the vision encoder understands.
- Two-stage training:
- Stage I: Alignment
- The AI learns to map its internal thoughts to match the vision encoder’s embeddings of the rendered reasoning images.
- The main models are kept frozen (not changed). A small “projection head” (a tiny neural network) learns to convert the AI’s hidden states into visual embeddings.
- The AI also learns when to stop the visual reasoning and start producing the final answer.
- Stage II: Latent reasoning
- The AI is fine-tuned (lightly updated using LoRA, a small, efficient method) to generate a sequence of these visual embeddings on its own, then produce the final text answer.
- The vision encoder and projection head are frozen here, so the AI must learn to think using this visual latent space.
- Decoding (switching from visual thinking to text answers):
- They test two ways to decide when to stop the visual thinking: a special “end” token or a fixed number of visual tokens (like giving the AI a specific “budget” of steps). Fixed budgets worked better and were more stable.
4. What did they find, and why does it matter?
The results show big gains in efficiency with competitive performance:
- Fewer tokens, faster thinking:
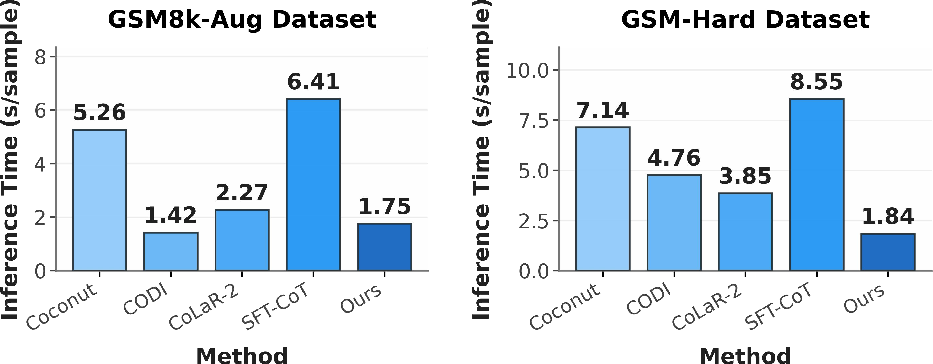
- RoT compresses the reasoning steps by about 3–4 times compared to regular chain-of-thought text.
- In one hard dataset, average inference time dropped from about 8.6 seconds to 1.8 seconds per problem.
- Accuracy stays strong:
- On easier math tasks, RoT’s accuracy was close to the full-text chain-of-thought while using far fewer tokens.
- On tougher tasks (like the MATH benchmark), RoT beat the “no chain-of-thought” baseline and performed reasonably compared to long-text chain-of-thought, despite using far fewer tokens.
- Better than some other “latent” methods:
- Compared to alternative ways of compressing reasoning into hidden vectors, RoT often did better or was more robust, likely because the visual embeddings from the vision encoder provide clearer guidance.
- Design choices matter:
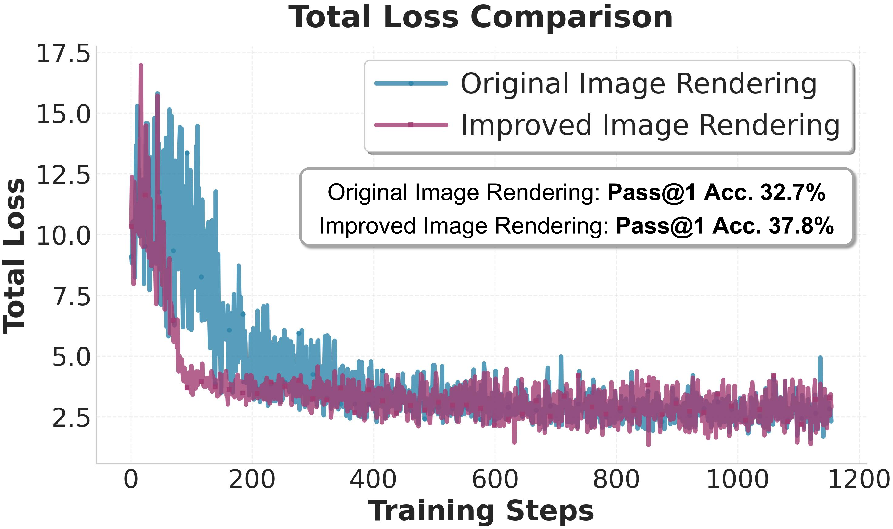
- The single-line rendering (dynamic width, fixed height) converged faster and worked better than square, multi-line images. Keeping text left-to-right avoids confusing visual gaps and keeps the sequence natural.
- Two-stage training is crucial:
- Removing either Stage I (alignment) or Stage II (fine-tuning) reduced accuracy, showing both are needed for stable and effective visual reasoning.
- Practical tip:
- Fixed token budgets (like 32 or 64 visual tokens) worked better than relying on a “stop” token in this continuous visual space.
Why it matters: It shows that “thinking in images” can be a compact, fast, and understandable way for AI to reason—potentially saving energy and time while keeping the steps traceable.
5. What does this mean for the future? (Implications)
- Faster and cheaper AI reasoning:
- Compressing thoughts into visual embeddings can make AI more efficient, especially for devices or services that need quick responses.
- More transparent reasoning:
- Because the steps are rendered as images tied to visual embeddings, you can visualize and analyze the AI’s intermediate thinking—helpful for debugging and trust.
- Easy to plug into existing models:
- RoT reuses pre-trained vision encoders, avoiding expensive retraining.
- What’s next:
- Automatically choosing the right number of visual tokens (instead of hand-tuning) could make it more flexible.
- Trying this on more kinds of problems (beyond math), in more languages, and improving stability when using special “end” tokens.
- Reducing training overhead from rendering images and running the vision encoder.
In short, Render-of-Thought suggests a fresh idea: instead of writing long explanations, let the AI “think” through slim, visual steps. It’s faster, keeps the reasoning visible, and works well with current models—showing that images can be a powerful carrier for thoughts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions left unresolved by the paper, aimed to guide future work.
- Human-interpretable reconstruction: The paper does not demonstrate a way to decode latent visual tokens back into readable reasoning steps (text or images). Develop and evaluate a decoder (image/text) to reconstruct CoT from latent tokens and measure faithfulness.
- Formalization ambiguity in Stage I: The definition of the generated latent embedding in Stage I includes the vision encoder applied to LLM outputs, which is conceptually unclear. Precisely specify how LLM hidden states are mapped via the projection head, how sequence lengths are matched (), and how patch-level visual sequence aligns with textual step order.
- Alignment objective and head design: Only MSE with a 2-layer MLP (SwiGLU) is used. Compare against alternative objectives (cosine, InfoNCE, triplet, predictive coding) and architectures (attention-based heads, residual adapters) to test stability and performance.
- Vision encoder dependence and sensitivity: The approach relies on the native Qwen3-VL vision encoder. Evaluate across multiple encoders (e.g., CLIP/SigLip/EVA variants, different patch sizes) and quantify sensitivity to the choice of visual embedding space.
- Domain and language generalization: The evaluation is limited to English math/logical tasks. Test commonsense, causal, code reasoning, theorem proving, and multilingual settings (non-Latin scripts, RTL languages), including math with LaTeX-heavy expressions and diagrams.
- Rendering robustness: Single-line black-on-white rendering is assumed. Assess robustness to fonts, sizes, kerning/anti-aliasing, background colors, text noise/OCR-like artifacts, ligatures/Unicode confusables, and multi-line/2D mathematical layouts (fractions, matrices).
- Adaptive token budgeting: Token budgets are manually tuned per dataset. Design learned/adaptive controllers (e.g., RL, difficulty predictors, confidence-based stopping) to select budget per instance without manual calibration.
- Stabilizing dynamic termination: Dynamic stopping via special tokens is unstable. Investigate stabilization (auxiliary termination classifier, confidence calibration, monotonic constraints, energy-based stopping) and compare with learned adaptive budgets.
- Scaling laws and limits: No systematic study of accuracy versus latent token length, model size, and training data size. Establish scaling curves to identify diminishing returns and optimal budgets per task.
- Efficiency accounting: Inference speed gains are reported, but memory footprint, energy usage, throughput under varying batch sizes, and end-to-end training cost (including rendering/vision encoding) are not quantified. Provide comprehensive efficiency metrics and amortization analysis.
- Traceability/faithfulness verification: Claims of “analyzability via visualization” lack quantitative validation. Evaluate process faithfulness (step-wise verification, causal scrubbing), human ratings of traceability, and whether latent tokens enable error diagnosis.
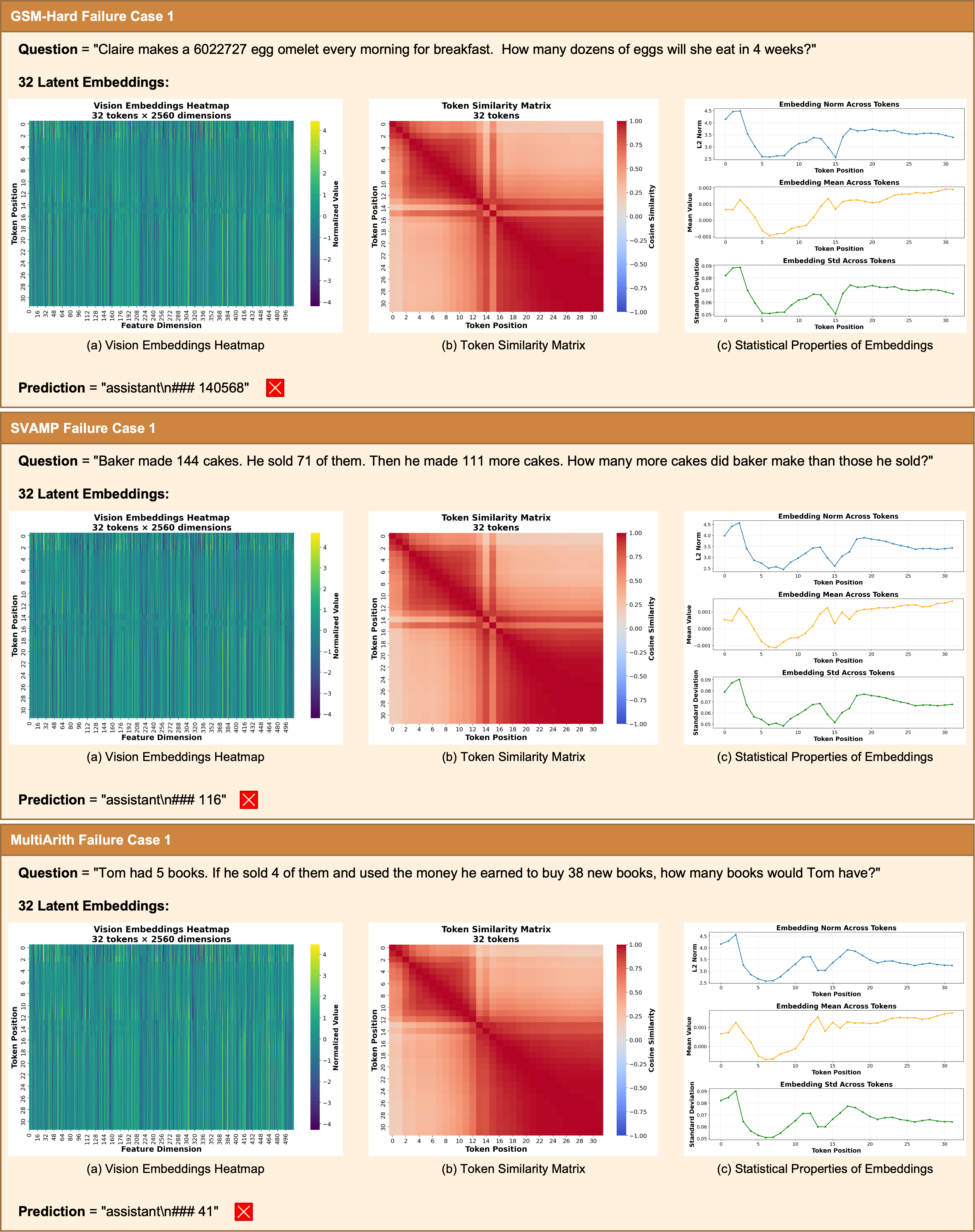
- Error analysis and redundancy: The observed latent token saturation/homogeneity is not addressed beyond description. Conduct error categorization (arithmetic, logical, decoding), analyze correlation with token similarity, and test regularizers (diversity/variance-preserving losses) to reduce redundancy.
- Architectural portability: Beyond three VLMs, assess portability to larger/different backbones (e.g., Llama-VL, Mistral-VL, GPT-4V-like) and pure LLMs with attached visual encoders; test whether the learned projection head transfers across models.
- Interaction with input text-as-image compression: The paper focuses on reasoning compression. Explore combining visual input compression with visual latent reasoning and quantify additive/synergistic effects.
- Calibration and robustness: No evaluation of confidence calibration, abstention, or adversarial robustness. Compare calibration and error sensitivity of RoT versus explicit CoT under distribution shifts and adversarial prompts.
- Dataset dependence and CoT source: Training is largely on GSM8k-Aug (distilled CoT). Test on unseen/real-world datasets and analyze sensitivity to the quality/source of CoT (distilled vs self-generated), including overfitting risks.
- Hyperparameter sensitivity and reproducibility: Limited reporting on sensitivity to learning rate, temperature/top-p, LoRA rank, projection head width/depth, and rendering parameters. Provide systematic sensitivity analyses and reproducibility guidelines.
- Theoretical grounding: The claim that visual embeddings act as “semantic anchors” lacks theoretical justification. Analyze the geometry of textual vs visual manifolds and provide theory or empirical evidence linking anchor properties to reasoning stability and performance.
- Handling complex math layouts: Single-line rendering may distort multi-step derivations and 2D structures. Evaluate support for aligned environments, piecewise equations, tables/diagrams, and their impact on reasoning.
- Security/safety of rendering: Rendering may introduce vulnerabilities (glyph-based prompt injection, Unicode confusables). Assess and design sanitization/normalization pipelines to mitigate such risks.
- Tool use and verification integration: It remains unclear how RoT interacts with program-of-thought, external verifiers, or calculators. Explore hybrid pipelines where latent visual tokens guide tool calls or verifier checks.
- Stage II loss design: Stage II omits explicit supervision on latent tokens. Evaluate auxiliary losses (teacher-forcing on latent sequences, KL to Stage I targets, predictive consistency) to reduce drift and enhance stability.
- Visual-token length mapping: The relationship between latent token count (), image width, and vision patch sequence length is not detailed. Clarify mapping and test alignment strategies when lengths differ (padding, down/up-sampling).
- Data pipeline details: The renderer and pre-processing choices (font family, anti-aliasing, DPI, line spacing) are only partially specified. Release detailed configurations and assess their impact to ensure reproducibility.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization. "Throughout Stage I and Stage II, we use the AdamW~\cite{adamw} optimizer with a fixed learning rate of 2e-5, a weight decay of 1e-2, and a batch size of 16."
- Autoregressive: A generation process where each step conditions on previously generated outputs. "Subsequently, we enable the model to autoregressively generate the visual reasoning trajectory without requiring explicit text decoding."
- Cross-Entropy Loss: A standard classification loss measuring the difference between predicted and true distributions. "Furthermore, to align the model with the proposed reasoning paradigm during Stage I, we simultaneously model the cross-entropy loss for both the \colorbox[HTML]{E0E0E0}{$<\vertimg\_end\vert>$} special token and the answer:"
- Dynamic Latent Compression: Techniques that adaptively compress internal reasoning representations into a compact latent form. "CoLaR~\cite{colar} further enhanced performance through dynamic latent compression mechanisms."
- Dynamic Termination: A decoding approach where the model learns when to stop reasoning via a special token. "Fixed token budgets consistently outperform dynamic termination via special tokens."
- Fixed Token Budgets: A decoding strategy that enforces a predetermined number of latent tokens for the reasoning phase. "Fixed Token Budgets"
- Latent Visual Tokens: Continuous vectors produced by the model that represent reasoning steps in a visual embedding space. "The model generates a sequence of latent visual tokens $\hat{\mathbf{V}$ followed by the special token \colorbox[HTML]{E0E0E0}{$<\vertimg\_end\vert>$} and final textual answer ."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small low-rank adapters into pretrained weights. "We fine-tune the LLM backbone parameters using LoRA~\cite{lora} to adapt the model to the latent reasoning task."
- Mean Squared Error (MSE) Loss: A regression loss that penalizes the squared difference between predicted and target vectors. "which are aligned with the visual features using Mean Squared Error (MSE) loss."
- Multimodal LLMs (MLLMs): LLMs that process and integrate multiple modalities (e.g., text and images). "While this alignment strategy mirrors the standard paradigm of Multimodal LLMs (MLLMs), it operates in the inverse direction."
- Out-of-Distribution (OOD): Data that differs from the training distribution, used to test generalization. "We also assess the robustness of our model on three Out-of-Distribution (OOD) datasets:"
- Pass@1: Accuracy metric indicating whether the top (first) generated answer is correct. "Our evaluation framework simultaneously measures accuracy (Pass@1) and computational efficiency (\char`#\ L, denoting the average token length of the reasoning chain)."
- Projection Head: A small neural module (often an MLP) that maps one representation space to another. "The projection head is implemented as a two-layer MLP with SwiGLU~\cite{glu} activation."
- Representation Collapse: A failure mode where diverse inputs map to similar embeddings, reducing expressiveness. "visual alignment is vital for structuring the latent space and preventing representation collapse during complex tasks."
- Self-Distillation: Training a model using its own (or a similar model’s) outputs as supervision to improve efficiency or performance. "allowing standard VLMs to be upgraded via self-distillation without extra pre-training."
- Semantic Anchors: Stable, pretrained features used to ground and align another model’s latent states. "we utilize the frozen vision encoders of existing VLMs as semantic anchors."
- SwiGLU: An activation function variant that improves Transformer MLP blocks via gated linear units. "The Visual Projection Head consists of a two-layer MLP based on the SwiGLU~\cite{glu} activation function."
- Token Compression: Reducing the number of generated tokens while preserving reasoning quality. "our method achieves 3-4 token compression and substantial inference acceleration compared to explicit CoT."
- Visual Embeddings: Vector representations produced by a vision encoder from images. "The Vision Encoder processes this image to extract target visual embeddings , where ."
- Visual Latent Space: A continuous embedding space derived from visual encoders used to carry reasoning signals. "validating the feasibility and efficiency of the visual latent space as a reasoning carrier."
- Vision Encoder: A neural network that extracts features from images for downstream tasks. "For the Vision Encoder, we directly employ the native module from Qwen3-VL and keep it frozen."
- Vision LLMs (VLMs): Models jointly trained or used over vision and language modalities. "we leverage the vision encoders of existing Vision LLMs (VLMs) as semantic anchors"
- Visual Rendering: Converting text into image form so it can be processed by vision modules. "The design of visual rendering configurations significantly influences the effectiveness of latent reasoning."
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now or with minimal engineering, leveraging the paper’s findings on compressing chain-of-thought into visual latent tokens, two-stage alignment/training, and fixed token budgets.
- Inference cost and latency reduction for CoT-heavy assistants — sectors: software, cloud AI, finance, education
- What: Replace verbose textual CoT with RoT’s latent visual reasoning to achieve 3–4× token compression and notable speedups (e.g., 8.55s → 1.84s/sample in experiments).
- How: Add a “visual projection head” to existing VLMs (e.g., Qwen3-VL, LLaVA) and fine-tune with the two-stage procedure; at inference, generate fixed-budget latent tokens then decode the final answer.
- Tools/products/workflows: “RoT fine-tuning pack” for popular open-source VLMs; serving-side middleware that swaps explicit CoT for RoT.
- Assumptions/dependencies: Access to CoT-annotated training data in the target task; fixed token budgets need per-task calibration; strongest evidence on English math/logic tasks.
- Throughput and energy efficiency gains for LLM serving — sectors: cloud/edge infrastructure, MLOps, energy
- What: Reduce GPU hours and memory pressure for reasoning workloads by compressing intermediate thinking into latent visual tokens.
- How: Deploy RoT-augmented models in batch serving; reduce output token streaming; increase concurrent sessions per GPU.
- Tools/products/workflows: Autoscaler policies tuned to latent token budgets; cost dashboards showing Pass@1 per token ratio (as in paper’s Pass@1/#L metric).
- Assumptions/dependencies: Gains correlate with how CoT-heavy the workload is; benefits shrink for tasks solvable without CoT.
- Explainability dashboards for “latent visual traces” — sectors: MLOps, AI governance/compliance, academia
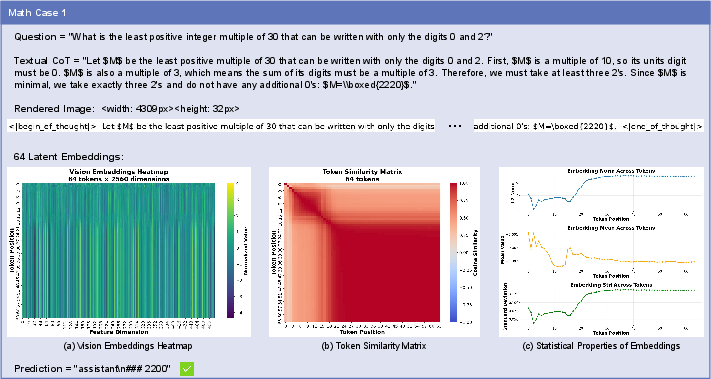
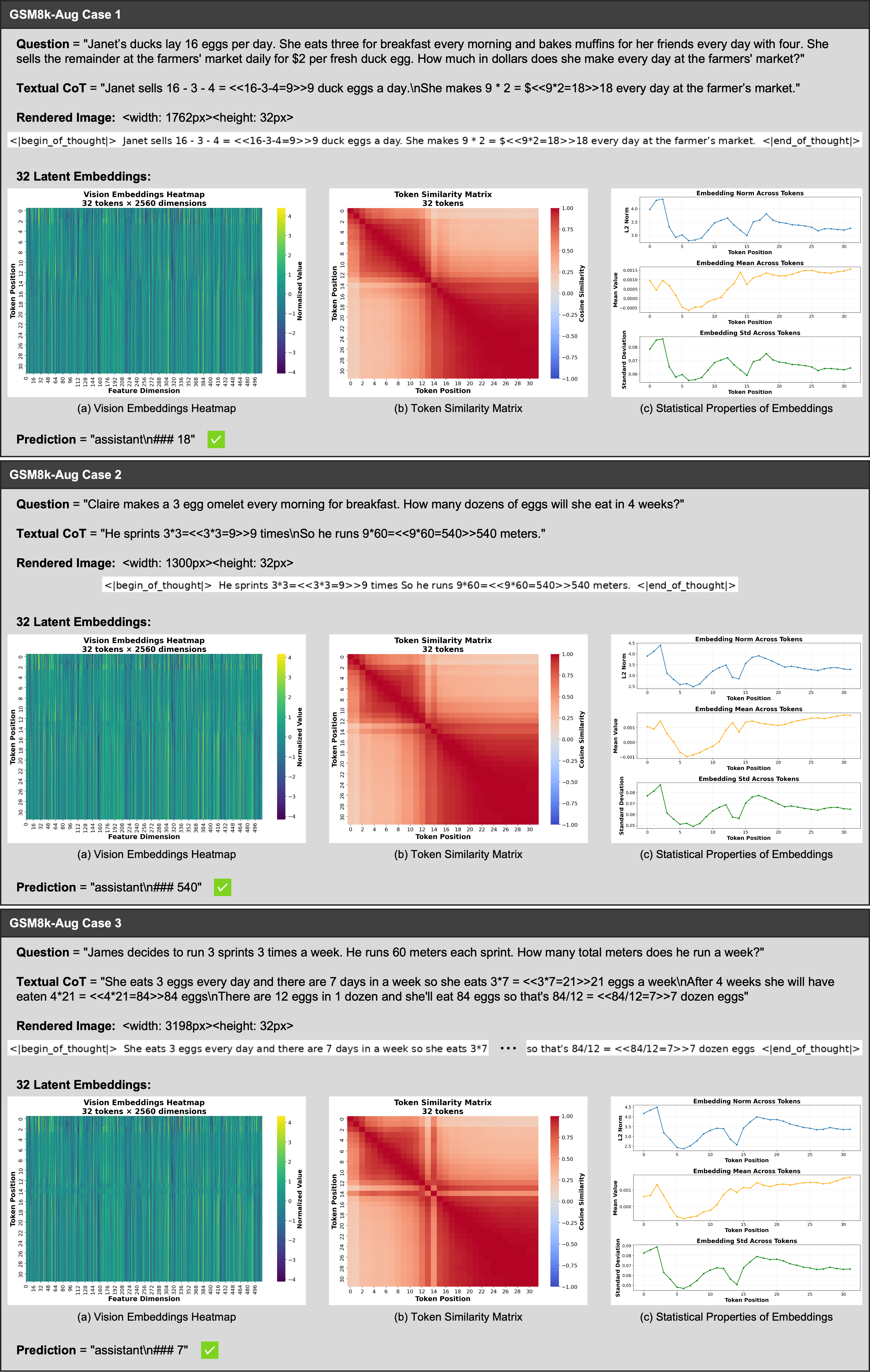
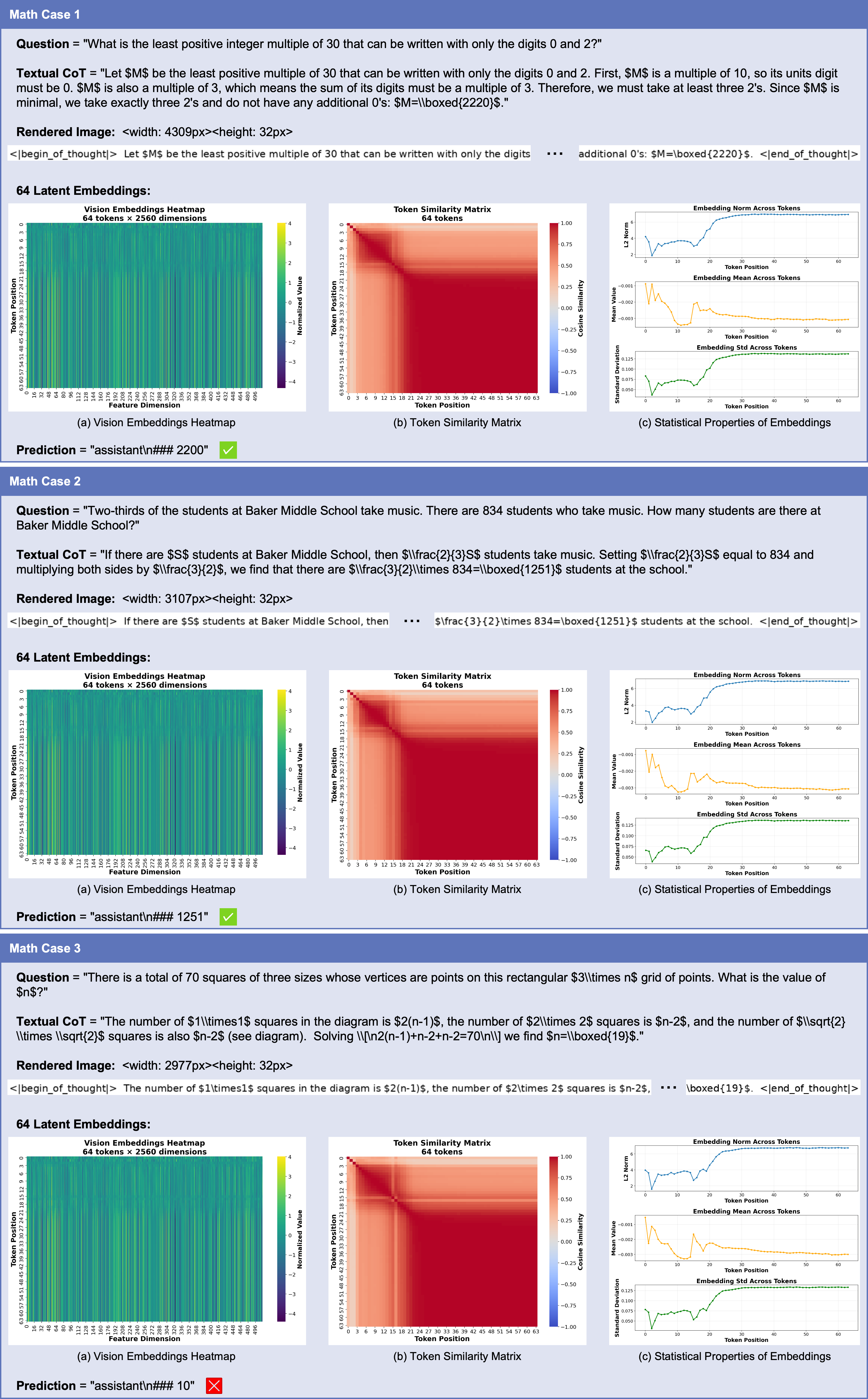
- What: Visualize intermediate latent embeddings (e.g., similarity matrices, activation heatmaps) to audit and diagnose reasoning paths.
- How: Export latent sequences and render them via the vision encoder for human inspection.
- Tools/products/workflows: “Latent Trace Viewer” panel in ML observability tools; CI checks that flag degenerate/plateaued token runs.
- Assumptions/dependencies: Visual traces are proxies, not literal human-readable steps; requires internal policy on how to interpret and store traces.
- Mobile/on-device tutoring and calculator apps with faster reasoning — sectors: education, consumer apps
- What: Offer math word-problem help with lower latency and reduced compute on-device or at the edge.
- How: Fine-tune small VLMs with RoT; deploy fixed latent token budgets (e.g., 32 for GSM8k-like tasks, 64 for MATH-like tasks).
- Tools/products/workflows: “RoT Tutor” SDK for iOS/Android; offline math help with optional cloud verification.
- Assumptions/dependencies: Accuracy is competitive but below full explicit CoT on harder tasks; UX must set expectations and offer fallback to server-side CoT when needed.
- Safer partial disclosure of “reasoning” in user-facing apps — sectors: consumer apps, healthcare admin, finance ops
- What: Provide users with a compact, non-verbatim “trace card” (rendered latent summary) rather than full free-form CoT, reducing risk of revealing sensitive prompts while preserving some transparency.
- How: Store latent sequences and a small set of decoded key frames for consented disclosure.
- Tools/products/workflows: Exportable “RoT trace card” PDFs for audits and client communications.
- Assumptions/dependencies: Not a full explanation; policy review needed to ensure such traces meet internal transparency requirements.
- Research baseline for latent reasoning studies — sectors: academia, industrial research
- What: Use RoT (code/models provided) as a reproducible baseline to study latent CoT, compression-vs-accuracy tradeoffs, and visual anchoring strategies.
- How: Plug into Qwen3-VL or LLaVA backbones; run ablations (e.g., single-line rendering vs. square, Stage I/II removal).
- Tools/products/workflows: Jupyter templates and experiment trackers for token budget sweeps; reproducible seed packs.
- Assumptions/dependencies: Current evidence is strongest in math/logic; domain transfer requires fresh experiments.
- Document QA pipelines that already use text-as-image input compression — sectors: legal tech, finance back-office, enterprise search
- What: Combine existing document ingestion via “text-as-image” with RoT’s reasoning compression to reduce end-to-end latency and cost.
- How: Keep visual input encoders; add RoT head for the reasoning phase; fix token budgets per task difficulty.
- Tools/products/workflows: Dual-stage visual pipelines: visual input compression + visual latent reasoning.
- Assumptions/dependencies: Requires careful integration to avoid compounding errors from two visual stages; validate on domain-specific QA sets.
- Training-time supervision enrichment without extra pretraining — sectors: software, model providers
- What: Use frozen vision encoders as semantic anchors to stabilize supervision of intermediate steps during SFT.
- How: Stage I aligns LLM hidden states to vision embeddings via an MLP head; Stage II LoRA fine-tunes autoregressive generation.
- Tools/products/workflows: Lightweight “RoT head” library; LoRA configs for rapid SFT iterations.
- Assumptions/dependencies: Vision encoder quality matters; synchronization of tokenization and rendering parameters is required.
Long-Term Applications
The following applications require additional research, domain adaptation, or scaling beyond current math/logic benchmarks.
- Cross-domain, multilingual RoT for complex reasoning — sectors: healthcare, legal, scientific R&D, public sector
- What: Extend RoT to clinical decision support, legal argumentation, and multilingual settings with domain-specific CoT.
- How: Curate domain/multilingual CoT corpora; retrain Stage I/II; calibrate token budgets per domain/difficulty.
- Tools/products/workflows: Domain-tuned “RoT packs” (e.g., RoT-Med, RoT-Law) with vetted data and evaluation harnesses.
- Assumptions/dependencies: High-quality, compliant CoT data; rigorous validation to avoid harmful errors in safety-critical contexts.
- Adaptive token budget controllers — sectors: platform engineering, model serving
- What: Predict optimal latent token length per query to balance accuracy and cost automatically.
- How: Train budget predictors from problem features or meta-signals (uncertainty, difficulty); or reinforcement learning to optimize Pass@1/latency tradeoffs.
- Tools/products/workflows: “Budget-as-a-Service” microservice; policy hooks that cap cost by SLA or user tier.
- Assumptions/dependencies: Reliability under distribution shifts; guardrails against under/over-allocation harming accuracy.
- Standardized “RoT Trace” for AI compliance — sectors: policy, governance, regulated industries
- What: Define a portable, auditable format for latent visual traces that satisfies auditability requirements without revealing sensitive CoT verbatim.
- How: Community schema for latent token stats, similarity matrices, and selective reconstructions; versioned provenance and cryptographic attestation.
- Tools/products/workflows: Compliance SDKs that attach trace artifacts to model decisions; dashboards for reviewers.
- Assumptions/dependencies: Regulator acceptance; consensus on interpretability sufficiency and retention policies.
- Multi-agent systems communicating via latent visual tokens — sectors: software agents, robotics, logistics
- What: Reduce inter-agent bandwidth by exchanging compact latent traces instead of long textual CoT.
- How: Define shared vision-anchored latent protocol; decode only at key decision points.
- Tools/products/workflows: Agent frameworks with “RoT channels”; simulators to measure coordination vs. bandwidth.
- Assumptions/dependencies: Interoperability across different encoders/backbones; empirical proof of coordination fidelity.
- Robotics and real-time planning with compact reasoning — sectors: robotics, manufacturing, warehousing
- What: Use RoT to keep planning latency low on edge hardware while maintaining interpretable intermediate states for debugging.
- How: Align planning/task-decomposition CoT to vision embeddings (text overlays, diagrams); fix budgets for tight control loops.
- Tools/products/workflows: “RoT Planner” modules in robot stacks; trace viewers for failure analysis.
- Assumptions/dependencies: Transfer from math benchmarks to embodied tasks; robust grounding in perception-action loops.
- Hardware/software co-design for latent visual reasoning — sectors: semiconductor, systems
- What: Optimize training/inference stacks for RoT (e.g., fast rendering/caching at training, projection-head-friendly kernels).
- How: Kernel fusion for SwiGLU MLPs; caching pre-rendered supervision; memory-optimized latent token handling.
- Tools/products/workflows: RoT-optimized runtimes; profiler presets for latent reasoning workloads.
- Assumptions/dependencies: ROI justifies engineering; interoperability with mainstream inference servers.
- Distillation to smaller student models using visual anchors — sectors: model providers, edge AI
- What: Use vision-anchored supervision to distill reasoning into compact students that retain analyzable latent traces.
- How: Multi-objective training on answers + latent alignment + trace statistics.
- Tools/products/workflows: “RoT Distiller” pipelines for 1–3B parameter students.
- Assumptions/dependencies: Student capacity limits; need for robust alignment without catastrophic compression of logic.
- Secure-by-design reasoning that minimizes prompt/trace leakage — sectors: security, enterprise AI
- What: Reduce exposure of sensitive internal CoT by operating largely in latent space and controlling what is decoded.
- How: Policy-gated decoding; encrypted storage of latent traces; selective disclosure workflows.
- Tools/products/workflows: “Confidential RoT” modes in enterprise assistants.
- Assumptions/dependencies: Must validate that latent traces do not enable inversion attacks; security review required.
- Program/tool-use integration with latent visual reasoning — sectors: software engineering, data analytics
- What: Render intermediate program states or tool outputs into visual tokens for compact, guided reasoning before final text/code output.
- How: Unified latent channel for tool results (tables, logs, plots) encoded as rendered visuals; decode only final actions.
- Tools/products/workflows: RoT-enabled “Program-of-Thought” agents; analytics copilots with latent dashboards.
- Assumptions/dependencies: Robust OCR/visual feature alignment for program artifacts; careful error recovery.
- Personalized education at scale with real-time feedback — sectors: EdTech
- What: Deliver step-aware tutoring that scales to large classrooms by using low-latency RoT while logging interpretable latent traces for teacher review.
- How: Fixed budgets tuned to topic difficulty; teacher dashboards summarizing latent trace progression and misconceptions.
- Tools/products/workflows: LMS integrations; student progress analytics from latent trace stats (e.g., early plateau detection).
- Assumptions/dependencies: Domain generalization beyond math; privacy safeguards for student data.
Notes on general feasibility
- Dependencies: Availability of frozen vision encoders compatible with the base VLM; access to CoT-rich training data in the target domain; engineering to implement Stage I/II and manage token budgets.
- Assumptions: Performance gains hold when moving beyond math/logic; fixed token budgets outperform dynamic termination for now; visual traces are acceptable proxies for intermediate reasoning in governance contexts.
- Risks: Domain shift may lower accuracy; explainability via latent traces is partial; safety-critical use requires extensive validation and human oversight.
Collections
Sign up for free to add this paper to one or more collections.

