MARS: Enabling Autoregressive Models Multi-Token Generation
Abstract: Autoregressive (AR) LLMs generate text one token at a time, even when consecutive tokens are highly predictable given earlier context. We introduce MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that teaches an instruction-tuned AR model to predict multiple tokens per forward pass. MARS adds no architectural modifications, no extra parameters, and produces a single model that can still be called exactly like the original AR model with no performance degradation. Unlike speculative decoding, which maintains a separate draft model alongside the target, or multi-head approaches such as Medusa, which attach additional prediction heads, MARS requires only continued training on existing instruction data. When generating one token per forward pass, MARS matches or exceeds the AR baseline on six standard benchmarks. When allowed to accept multiple tokens per step, it maintains baseline-level accuracy while achieving 1.5-1.7x throughput. We further develop a block-level KV caching strategy for batch inference, achieving up to 1.71x wall-clock speedup over AR with KV cache on Qwen2.5-7B. Finally, MARS supports real-time speed adjustment via confidence thresholding: under high request load, the serving system can increase throughput on the fly without swapping models or restarting, providing a practical latency-quality knob for deployment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MARS: Making AI Write Several Words at Once (in simple terms)
Overview
This paper introduces MARS, a training method that helps LLMs write more than one token (tiny pieces of text, like words or parts of words) in a single step. The big idea: speed up writing without changing the model’s structure, size, or how you call it. When needed, the model still writes one token at a time with the same or better quality as before.
What questions did the paper ask?
The authors focused on three simple questions:
- Can a regular LLM be taught to safely write several tokens per step, without adding extra parts or a second model?
- Can it keep the same quality when it writes one token per step, so nothing breaks for normal use?
- Can this multi-token writing actually make real systems faster (not just in theory), especially when serving many users?
How did they do it? (Methods in everyday language)
Think of normal AI writing like this: the model looks at everything it has written so far and adds the next word. It repeats this one step at a time. This is safe but slow.
MARS teaches the model a new trick using a simple practice routine:
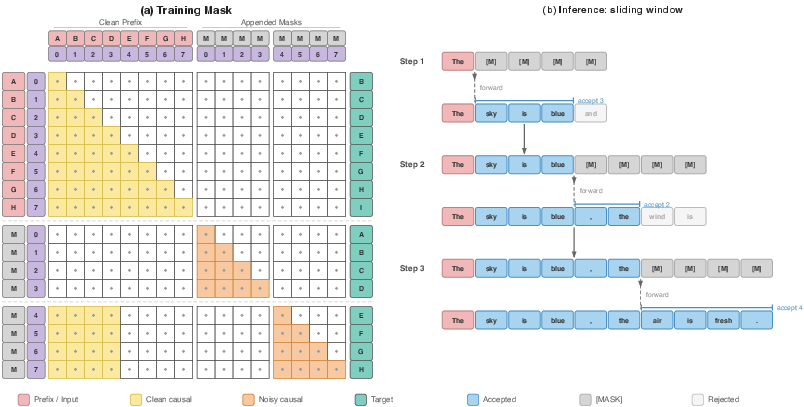
- Filling in blanks in small chunks: The model takes the next few spots (a “block,” like 4 positions) and temporarily puts [MASK] blanks there. It then tries to guess all those blanks at once.
- Two versions of the text during training:
- The clean version: the regular text, used to keep practicing normal “next word” prediction.
- The masked version: the same text but with blocks replaced by [MASK], used to learn filling in several future tokens at once.
- Important rule stays the same: The model still only looks left (at what’s already written), never peeks ahead. It predicts strictly left-to-right. This keeps it behaving like a normal autoregressive model so it doesn’t forget how to write well.
- A confidence check at writing time: When the model is generating, it appends a few [MASK] slots, predicts them, and then accepts the guesses from left to right as long as it feels confident enough (above a threshold). If it’s unsure, it stops and continues one token at a time. This acts like a speed knob: higher confidence threshold means safer, slower; lower threshold means faster, slightly riskier.
A key detail that protects quality:
- Keep practicing the “old skill” while learning the “new trick”: During training, the model is always doing both normal next-token prediction and the masked-block prediction. Without this, bigger blocks make it forget how to write carefully. With this, it keeps its original skills and learns the new ones.
A practical speed boost for servers:
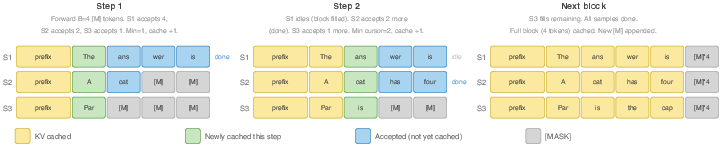
- Caching past work: The model saves what it already computed (like keeping notes) so it doesn’t redo everything each time. The authors design a block-level “KV cache” that fits how MARS writes in chunks. This turns the “tokens per step” speedup into real wall-clock time savings.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- No quality loss in normal mode:
- When set to write one token at a time, the MARS-trained models match or slightly beat the original models on six standard tests (math word problems, coding tasks, school subject questions, and instruction-following).
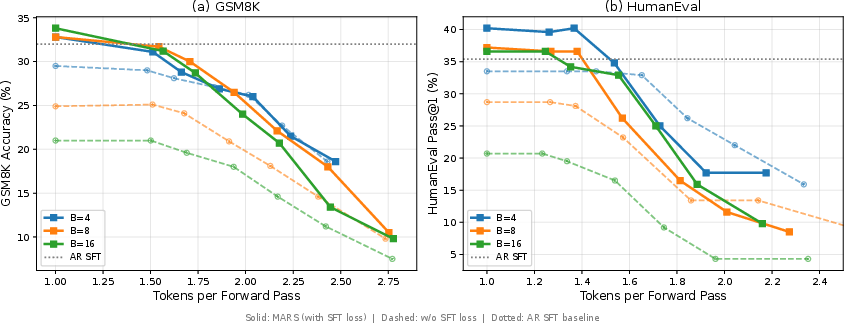
- Faster writing with small accuracy changes:
- When allowed to accept multiple tokens per step, MARS gets about 1.5–1.7× more tokens per model step, with only small drops in accuracy on most tasks. Some formatting-heavy tests drop more because accepting multiple tokens can skip tiny format details—so turn the speed knob up or down depending on the task.
- Real-world speed, not just theory:
- With their block-level cache, overall time to finish jobs improved by up to 1.71× compared to a strong baseline that already uses caching. That means users can see replies faster, especially at smaller batch sizes.
- No extra parts needed:
- Unlike other methods that add extra “heads” to the model or require running a second “draft” model, MARS needs no architectural changes and no extra parameters. It’s just fine-tuning on the same kind of instruction data.
Why this matters (Implications)
- One model, two modes: You can deploy a single model that behaves exactly like the original for high-accuracy needs, and flip on multi-token generation for faster replies when the system is busy. No need to swap models or restart anything.
- A practical speed–quality knob: The confidence threshold is a simple dial that lets you trade a bit of accuracy for a lot of speed, or vice versa, per request.
- Easier engineering: Because MARS doesn’t change the model’s structure or size, it’s easier to maintain in production than methods that add extra components.
Before using it everywhere, note a few limits the authors mention:
- Training is a bit heavier than standard fine-tuning because the model sees both clean and masked versions of each sequence.
- If you push the speed knob too far (very low confidence), quality drops more.
- The batch-speed trick (block-level caching) needs the system to sync at block boundaries, which can limit gains at very large batch sizes.
In short, MARS teaches a regular LLM a new, optional skill: writing several tokens at once when it’s confident. It keeps the original writing quality, makes real systems faster, and stays simple to deploy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address:
- Scaling and block size at larger model scales: Only Qwen2.5-7B was evaluated with B=4 due to compute limits. It remains unknown how MARS behaves at 7B+ (and larger) with B>4 (e.g., B=8, 16) in terms of accuracy, stability, and speed–quality trade-offs.
- Generality across architectures: Results are limited to Qwen2.5 Instruct variants. It is unclear whether the same training and inference recipe transfers to other families (e.g., Llama, Mistral, Mix-of-Experts, decoder-only vs. encoder–decoder), and whether architectural idiosyncrasies affect acceptance rates or stability.
- Multilingual and domain coverage: Evaluation is predominantly English and instruction-following. Robustness on multilingual settings, specialized domains (law, medicine), and low-resource languages is untested.
- Long-context and long-output behavior: Benchmarks used modest generation lengths (max 256 new tokens). The impact of multi-token acceptance on very long generations (e.g., multi-thousand-token outputs) and long-context scenarios (e.g., 100k-token contexts) is unknown, especially regarding error accumulation and drift.
- Interaction with sampling-based decoding: Experiments used greedy decoding. How MARS behaves with temperature, top-k/top-p, or contrastive decoding (including calibration of acceptance under stochastic distributions) is unstudied.
- Confidence calibration and acceptance policy: The method uses max softmax probability with a fixed threshold τ and always accepts at least one token. The quality impact of miscalibration, per-step vs per-token thresholding, adaptive thresholds, or alternative uncertainty estimates (e.g., entropy, margin, expected calibration error) remains unexplored.
- Formatting- and structure-sensitive tasks: IFEval drops notably under multi-token mode. Strategies to avoid skipping format-critical tokens (e.g., disallow acceptance across delimiters, punctuation, or JSON/Markdown boundaries) and their efficacy are untested.
- Safety, truthfulness, and hallucination: The effect of multi-token acceptance on safety, toxicity, bias, jailbreak robustness, and factuality has not been evaluated.
- Alignment preservation: The SFT loss preserves AR competence, but whether masked-prediction fine-tuning shifts RLHF-aligned behaviors (e.g., helpfulness/harmlessness) or instruction adherence beyond the reported tasks is unknown.
- Training efficiency and resource use: Training concatenates clean and noisy streams, doubling effective sequence length. The precise compute/throughput trade-off (FLOPs, wall-clock, memory) vs. gains in inference speed is not quantified across hardware settings.
- Memory footprint at inference: While parameter count is unchanged, the memory overhead of MARS with block-level KV cache (per-sample KV growth, cache granularity, fragmentation) versus standard AR KV caching is not quantified.
- Cache synchronization bottlenecks: Block-level KV caching requires batch synchronization at block boundaries, limiting gains at large batch sizes. The viability of cursor-based or asynchronous cache advancement (per-sample) and its effect on throughput/latency/accuracy is open.
- Adaptive block sizing: Block size B is fixed during inference. Algorithms to adapt B online (e.g., based on token-level confidence, perplexity spikes, or task type) and their impact on the Pareto frontier remain to be designed and evaluated.
- Placeholder design: The approach uses a single [MASK] token. Alternatives (learned mask embeddings, position-dependent masks, partial-noise schemes, or curriculum masking) and their impact on quality and acceptance rates have not been compared.
- Loss weighting and curricula: The combined loss uses equal weights for masked and AR losses. Sensitivity to loss weights, block-size curricula, or staged training (e.g., progressively increasing B) is unreported.
- Robustness under distribution shift: Performance under out-of-distribution prompts, adversarial inputs, and noisy user text is unknown, particularly when multi-token acceptance might accelerate past ambiguities.
- Error propagation analysis: A fine-grained study of how early multi-token acceptance errors propagate within or across blocks (especially in chain-of-thought and code generation) is missing.
- Perplexity and calibration metrics: Standard LM metrics (perplexity, ECE) pre-/post-MARS fine-tuning are not reported, making it hard to assess calibration shifts that directly affect the confidence-thresholding mechanism.
- Streaming behavior and user-perceived latency: While throughput improves, the impact on token-level latency and streaming smoothness (e.g., bursty emission vs. steady token flow) is not measured.
- Interplay with speculative decoding/auxiliary heads: The paper proposes integrating with speculative decoding as future work, but concrete designs and empirical analysis of quality, memory, orchestration complexity, and net wall-clock gains are absent.
- Interaction with RAG and tool use: How multi-token acceptance interacts with mid-generation retrieval, external tool calls, or function-calling protocols (which often require strict token-by-token control) is unexplored.
- Aggressive thresholds (τ<0.7): Substantial quality loss occurs at low τ. Techniques to push the frontier (e.g., verifier passes, lightweight consistency checks, fallback heuristics, or confidence tempering) are untested.
- Acceptance boundaries and special tokens: The current left-to-right policy may accept across semantic or syntactic boundaries. Policies to prevent acceptance across sentence boundaries, code blocks, or function arguments and their impact on accuracy/speed are unstudied.
- Evaluation breadth: Benchmarks are limited (e.g., GSM8K, HumanEval). Effects on summarization, translation, dialogue, long-form writing, program synthesis with execution-based metrics, and real-world task suites are not assessed.
- Generalization of SFT-loss insight: The claim that SFT loss stabilizes AR competence above 50% signal needs validation across datasets, model sizes, and pretraining regimes (e.g., base vs. instruction-tuned vs. RLHF-tuned).
- Failure modes when “force-accepting” one token: The rule to always accept at least one token could introduce low-confidence tokens. The frequency, downstream impact, and potential mitigations (e.g., minimum-score floors, backtracking) are unexamined.
- Tokenization effects: Dependence of acceptance behavior on tokenizer granularity (e.g., multi-character tokens, byte-level tokens) and whether certain token types (whitespace, punctuation) should be handled specially is unexplored.
- Energy and cost accounting: End-to-end energy/carbon savings and serving cost reductions (training overhead vs. inference savings) are not quantified, leaving operational trade-offs uncertain.
Practical Applications
Practical Applications of MARS (Mask AutoRegreSsion)
Below are concrete, real-world applications derived from the paper’s findings and methods. Each item notes relevant sectors, potential tools/products/workflows, and assumptions/dependencies. Applications are grouped by feasibility horizon.
Immediate Applications
- Bold drop-in acceleration for existing LLM services
- What: Fine-tune current instruction-tuned AR models with MARS to gain 1.5–1.7× tokens/forward and up to 1.71× wall‑clock speedup, without changing model architecture or APIs.
- Sectors: Software, cloud/AI platforms, enterprise SaaS, customer support, content generation.
- Tools/workflows: Integrate MARS-trained checkpoints into vLLM, TGI, TensorRT-LLM; enable the MARS decoding loop (left-to-right sliding window with [MASK]); deploy the real-time confidence threshold “knob.”
- Assumptions/dependencies: Access to instruction-tuned base checkpoints and SFT data; training infra for MARS (sequence length ×2 during training); tokenizer includes a [MASK] token (or equivalent); serving stack supports custom decoding and block-level KV cache.
- Real-time latency–quality control (“knob”)
- What: Adjust the confidence threshold per request to trade accuracy for speed on the fly, with no model swap (e.g., set higher τ for safety- or format-critical tasks, lower τ under peak load).
- Sectors: Multi-tenant cloud, contact centers, A/B testing platforms, on-call/incident chatops.
- Tools/workflows: Request-level policy engine that sets τ from SLAs; autoscaling tied to acceptance rate (tokens accepted per forward) and throughput.
- Assumptions/dependencies: Calibrated confidence proxy (max softmax prob) is available; quality-monitoring and guardrails in place for low-τ operation.
- Cost and energy reduction in LLM inference
- What: Fewer forward passes per output token reduce GPU hours and energy per request.
- Sectors: Cloud/infra, sustainability programs, public-sector deployments with fixed budgets.
- Tools/workflows: Cost dashboards tracking tokens/forward and wall-clock speedup; budgeting models updated to reflect 1.5–1.7× algorithmic gains.
- Assumptions/dependencies: Realized wall-clock gains depend on integrating block-level KV caching (batch sizes and cache granularity tuned).
- Batch inference acceleration for offline pipelines
- What: Speed up evaluation, data labeling, synthetic data generation, and content backfills with MARS + block-level KV cache.
- Sectors: Data engineering, MLOps, LLM evaluation labs, growth/content ops.
- Tools/workflows: Airflow/Ray pipelines that use cache granularity B_cache tuned for batch size to maximize wall-clock speedup; throughput-aware retriers.
- Assumptions/dependencies: Synchronization at block boundaries is acceptable; optimal B_cache depends on batch size and sequence lengths.
- Faster RAG answer generation without architecture changes
- What: Use the same model in AR-compatible mode for retrieval and in multi-token mode for response generation, switching τ based on prompt complexity.
- Sectors: Enterprise search, knowledge bases, developer support.
- Tools/workflows: Heuristics to raise τ for JSON/structured outputs; lower τ for free-form narrative answers.
- Assumptions/dependencies: Prompt classifier for format-critical vs open-ended tasks; careful handling of function-calling/JSON outputs to avoid formatting regressions.
- Coding assistants and IDE integration
- What: Accelerate generation of boilerplate and common patterns (high-confidence spans) while preserving token-by-token reasoning for novel code.
- Sectors: Software engineering, DevTools.
- Tools/workflows: IDE plugins with dynamic τ tied to context (e.g., raise τ inside structured formats or tests); offline code generation pipelines.
- Assumptions/dependencies: Ensure strict formatting constraints (e.g., linting/JSON) are respected by adjusting τ or temporarily disabling multi-token acceptance.
- Higher-throughput education/tutoring chatbots
- What: Serve more students per GPU by lowering τ for predictable explanations, raising τ for rubric- or formatting-dependent tasks (e.g., step lists).
- Sectors: EdTech.
- Tools/workflows: Lesson-type aware τ schedules; monitoring to detect format errors.
- Assumptions/dependencies: Clear segmentation of prompt types; evaluation to ensure pedagogical quality is preserved at chosen τ.
- Customer support and CX automation
- What: Faster, consistent replies for templated workflows (refunds, shipping, password resets) where continuations are highly predictable.
- Sectors: E-commerce, telecom, banking CX.
- Tools/workflows: Intent detection to set τ; templates for high-confidence segments; QA sampling focused on low-τ requests.
- Assumptions/dependencies: Route format/verification-heavy flows to higher τ; compliance review for any quality trade-offs.
- On-device and edge inference for small models
- What: Apply MARS to small instruction-tuned LMs (e.g., ≤1B) to improve responsiveness on laptops/phones/edge devices.
- Sectors: Consumer apps, embedded/IoT, automotive.
- Tools/workflows: Local fine-tuning (LoRA/QLoRA) with MARS objective; lightweight decoding loop; caching within device constraints.
- Assumptions/dependencies: Memory limits restrict cache size; expect smaller absolute gains but still meaningful perceived latency reductions.
- Research baselines and ablations without architectural confounds
- What: Use MARS as a “no-extra-parameters” multi-token baseline in academic benchmarks and ablation studies (vs speculative decoding, multi-head methods).
- Sectors: Academia, applied research labs.
- Tools/workflows: Shared code recipes for MARS training; standard Pareto curves (accuracy vs tokens/forward) in papers.
- Assumptions/dependencies: Availability of SFT-quality datasets and compute for continued training.
- MLOps observability for multi-token decoding
- What: New metrics—acceptance rate, tokens/forward, τ distribution—to drive capacity planning and alerting.
- Sectors: Platform engineering.
- Tools/workflows: Prometheus/Grafana dashboards; SLOs defined over tokens/forward and response times.
- Assumptions/dependencies: Instrumentation in the decoding loop and serving stack.
Long-Term Applications
- First-class multi-token decoding in serving frameworks
- What: Incorporate MARS-style decoding and block-level KV caching into vLLM/TensorRT-LLM/TGI as a standard mode.
- Sectors: AI infra, open-source ecosystems.
- Tools/products: “Multi-token mode” flags; unified APIs for confidence-threshold control; per-tenant routing.
- Assumptions/dependencies: Community adoption; standardized [MASK]/logit conventions across models.
- Adaptive, context-aware block sizing and acceptance
- What: Dynamically choose block size B and per-token τ based on model uncertainty, prompt type, or structure (e.g., code/JSON vs prose).
- Sectors: All LLM application domains.
- Tools/products: Calibration models for confidence; detectors for structured outputs; context-complexity classifiers.
- Assumptions/dependencies: Reliable uncertainty estimation; additional training/evaluation to avoid regressions.
- Cursor-based cache management and finer-grained synchronization
- What: Remove batch-level block synchronization to improve throughput at large batch sizes; cache only newly accepted tokens.
- Sectors: AI infra, cloud providers.
- Tools/products: New KV-cache data structures and kernels; scheduler policies to minimize tail latency.
- Assumptions/dependencies: Kernel-level engineering; careful correctness proofs and benchmarking.
- Hybrid accelerators: MARS + speculative decoding or multi-head MTP
- What: Combine MARS’s AR-compatibility with drafter-verifier or auxiliary-head proposals for further speedups.
- Sectors: High-throughput cloud inference.
- Tools/products: Ensemble decoders that choose between MARS acceptance and speculative drafts; policy learning to route segments.
- Assumptions/dependencies: Additional memory for draft/heads; orchestration complexity; careful evaluation of quality.
- Energy- and cost-aware orchestration policies
- What: Autoscalers that adjust τ and B to minimize energy or cost under SLA constraints across fleets.
- Sectors: Cloud/enterprise, sustainability/green AI.
- Tools/products: Schedulers integrating acceptance metrics; carbon-aware routing.
- Assumptions/dependencies: Accurate telemetry; governance over quality trade-offs.
- Sector-specific deployments with calibrated safety envelopes
- Healthcare
- Use: Faster triage assistants and documentation drafting under high load; default to high τ for safety-critical facts.
- Dependencies: Clinical QA pipelines; human-in-the-loop review; audit trails capturing τ values used.
- Finance
- Use: Low-latency analyst copilots and report drafting; strict mode (τ≈1.0) for compliance/structured outputs.
- Dependencies: Compliance gating; logs for post-hoc audits.
- Robotics/automation
- Use: Faster LLM planning loops where common action sequences are predictable, preserving AR behavior for novel sequences.
- Dependencies: Safety checks and fallback behaviors.
- Standardized “efficiency profiles” for procurement and policy
- What: Benchmark and report tokens/forward and wall-clock speedups under MARS to inform model selection and public-sector procurement.
- Sectors: Policy, public sector IT.
- Tools/products: Efficiency certification suites; fair-usage policies reflecting speed–quality trade-offs.
- Assumptions/dependencies: Community-agreed metrics and testbeds.
- Open-source model suites with MARS pre-fine-tuned variants
- What: Publish MARS checkpoints for popular base and instruct models, giving developers a no-friction acceleration path.
- Sectors: Open-source communities, startups.
- Tools/products: Model hubs (e.g., Hugging Face) tags for “MARS-ready”; cookie-cutter repos for training/serving.
- Assumptions/dependencies: Legal permissions for continued SFT; community maintainers.
- Extension to other AR sequence tasks
- What: Apply MARS to domains like music, DNA/protein sequence generation, or speech token generation where predictable spans exist.
- Sectors: Bioinformatics, media, speech.
- Tools/products: Domain-specific tokenizers with a [MASK]-like token; evaluation harnesses tuned to domain.
- Assumptions/dependencies: Task-appropriate SFT data; validation for domain-specific quality metrics.
- Curriculum/training research on uncertainty-aware acceptance
- What: Train models to calibrate confidence for multi-token acceptance better (e.g., entropy-aware objectives, distillation).
- Sectors: Academia, labs.
- Tools/products: New losses/regularizers that improve acceptance without accuracy loss at low τ.
- Assumptions/dependencies: Additional training data/compute; careful ablations.
Cross-cutting assumptions and dependencies impacting feasibility
- Quality preservation depends on including the auxiliary SFT loss on the clean stream; omitting it degrades reasoning/coding, especially for larger blocks.
- Gains are demonstrated on Qwen2.5-0.5B and 7B; porting to other families (e.g., Llama, Mistral) is likely but requires validation.
- Block size and cache granularity must be tuned for workload characteristics; B=4 is a safe default for 7B in the paper.
- Formatting- and structure-critical outputs (e.g., JSON, tool calls, exact-count instructions) are sensitive; use high τ or single-token mode for those prompts.
- Training-time overhead is ~2× per-sample sequence length due to concatenated clean/noisy streams; still far lighter than pretraining, but requires planning.
- Serving stacks may need modest engineering: decoding loop updates, access to logits/confidence, and block-level KV cache implementations.
Glossary
- [MASK] placeholders: Special tokens used as stand-ins for unknown future tokens during training or inference to enable parallel prediction. "replace a contiguous block of future tokens with [MASK] placeholders"
- any-order generation: A generation paradigm where tokens can be produced in an order other than strictly left-to-right. "ARMD and A3 similarly adopt causal structure for masked diffusion and any-order generation, respectively."
- attention mask: A matrix that specifies which token positions can attend to which others during self-attention. "We define the attention mask over ."
- bidirectional attention: An attention pattern where each position can attend to tokens on both the left and right (past and future). "These models typically use bidirectional attention, a design choice inherited from diffusion models in vision."
- Block Diffusion: A method interpolating between AR and diffusion LMs that mixes causal and bidirectional attention within blocks. "Block Diffusion uses causal attention across blocks while keeping bidirectional attention within each block."
- block-level KV cache: A caching scheme that stores key-value states at the granularity of token blocks to accelerate multi-token inference. "Block-level KV cache for batch inference ($B_{\text{cache}{=}4$, batch size 3)."
- block-masked prediction: Training/inference scheme where a contiguous block of future tokens is masked and predicted in parallel given a clean prefix. "a natural construction is block-masked prediction: replace a contiguous block of future tokens with [MASK] placeholders"
- causal attention: Left-to-right attention where each token attends only to previous positions, preserving autoregressive conditioning. "via causal (left-to-right) attention."
- causal self-attention: Self-attention constrained to causal (past-only) visibility, used in standard AR training. "standard causal self-attention, identical to AR training."
- CLLMs: Causally trained LLMs that accelerate convergence under parallel decoding schemes like Jacobi. "CLLMs improve upon this by training the model to converge faster under Jacobi iteration."
- confidence-based diffusion: Unmasking strategy that selects which masked tokens to reveal based on confidence, not strictly in order. "confidence-based diffusion methods unmask tokens out of order within a block"
- confidence thresholding: A runtime mechanism that accepts multiple predicted tokens only if their confidences exceed a set threshold to trade speed for quality. "supports real-time speed adjustment via confidence thresholding"
- draft model: An auxiliary lightweight model used to propose tokens for speculative decoding before verification by the target model. "maintains a separate draft model alongside the target"
- fixed-point iteration: A decoding view that iteratively refines future tokens toward a self-consistent solution using the same model. "by treating AR generation as a fixed-point iteration"
- instruction-tuned: Fine-tuned on instruction-following datasets to improve adherence to tasks and prompts. "teaches an instruction-tuned AR model"
- Jacobi decoding: A parallel decoding method that treats AR generation as a Jacobi-style fixed-point iteration over future tokens. "Jacobi decoding and Lookahead decoding achieve parallel generation from a single unmodified model"
- KV cache: Cached key-value states from previous tokens used to avoid recomputation during transformer decoding. "achieving up to 1.71 wall-clock speedup over AR with KV cache on Qwen2.5-7B."
- LLM head: The output projection layer mapping hidden states to vocabulary logits. "using the same backbone and LLM head"
- Lookahead decoding: A parallel generation approach that proposes future tokens beyond the next step and refines them iteratively. "Jacobi decoding and Lookahead decoding achieve parallel generation from a single unmodified model"
- masked diffusion LLMs: Diffusion-style LMs that generate text by iteratively unmasking tokens rather than predicting strictly next tokens. "masked diffusion LLMs apply iterative unmasking to text generation"
- Multi-token prediction (MTP): Training setup where future tokens are predicted in parallel, often with auxiliary heads. "Multi-token prediction (MTP) trains AR models with auxiliary heads to predict future tokens in parallel"
- right-shifted logits: The AR convention where the model at position t predicts the token at position t+1, aligning outputs one step to the right. "uses right-shifted logits"
- SFT loss: An auxiliary supervised fine-tuning objective computed on the clean (unmasked) stream to preserve AR competence during masked training. "We identify an auxiliary SFT loss on the clean input stream"
- sliding-window inference: Decoding procedure that appends a block of masks, fills them in a pass, accepts confident tokens, and slides the window forward. "Right: sliding-window inference."
- speculative decoding: An acceleration technique where a draft model proposes tokens that the target model verifies or rejects. "Unlike speculative decoding, which maintains a separate draft model alongside the target"
- structured attention mask: A specially constructed mask that enforces causal and cross-stream visibility patterns within concatenated clean/noisy sequences. "with a structured attention mask that controls visibility"
- wall-clock speedup: Actual end-to-end time reduction measured in real time, beyond theoretical token-per-step gains. "achieving up to 1.71 wall-clock speedup over AR with KV cache"
Collections
Sign up for free to add this paper to one or more collections.