- The paper presents a formal analysis of MDLMs, decomposing the trade-off between parallel decoding and accuracy using hardware-agnostic metrics.
- It demonstrates that smaller block sizes yield up to 3x–5x accuracy improvements by preserving inter-token dependencies in generation.
- The work proposes a 'generate-then-edit' paradigm as a potential solution to mitigate the inherent accuracy loss in massively parallel token generation.
Parallelism and Generation Order in Masked Diffusion LLMs
Introduction
The paper "Parallelism and Generation Order in Masked Diffusion LLMs: Limits Today, Potential Tomorrow" (2601.15593) addresses the empirical and theoretical limits of Masked Diffusion LLMs (MDLMs) in parallel text generation. While MDLMs are compelling for their ability to decode tokens in parallel and in arbitrary order, a formal understanding of their practical capabilities, accuracy–parallelism trade-offs, and the structure of their generation order has been lacking. This work fills that gap with a systematic analysis over 58 benchmarks, decoupling the notions of parallelism and generation order using hardware-agnostic metrics, and presents insights for both limitations and architectural potential of MDLMs.
Large-Scale Empirical Comparison: MDLMs Trail AR Models
This study benchmarks eight state-of-the-art MDLMs, including LLaDA2-flash (100B parameters), alongside competitive autoregressive (AR) LMs such as Qwen3 and Gemini-2.5 Pro. Evaluation covers six core capability domains: Knowledge, Math, Reasoning, Language Understanding, Agentic capabilities, and Coding, totaling 58 tasks. Results highlight a persistent accuracy gap: at comparable model scale, MDLMs fall short of AR models in almost all performance dimensions.
Figure 1: Overall performance comparison between AR and DLM models across six evaluation dimensions.
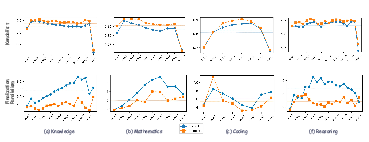
The empirical bottleneck is excessive per-step parallelism, which directly reduces performance. Detailed ablation on block size demonstrates that smaller blocks (i.e., less parallelism per step) correlate with higher accuracy. For example, OpenPangu-7B-Diffusion with block size 4 and greedy decoding yields much higher precision than with a larger block size, up to a 3x–5x improvement across tasks.
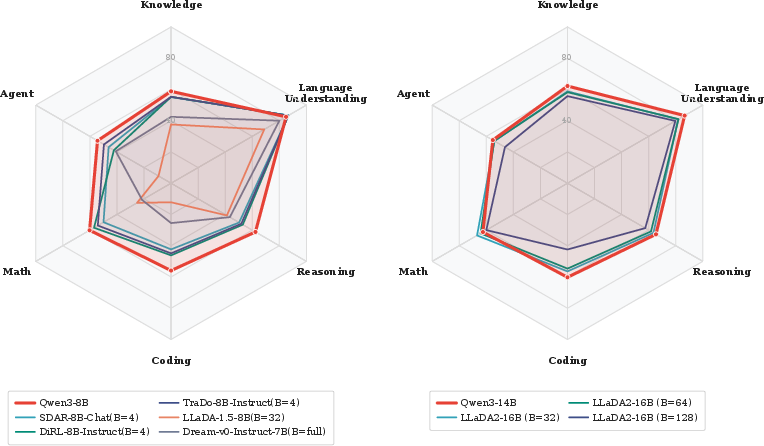
Figure 2: At fixed model scale, smaller block size (B) consistently yields superior performance.
The underlying cause is a fundamental parallel factorization limit: when decoding multiple tokens in parallel within a block, MDLMs treat the tokens' conditional distributions as independent given the context, discarding inter-token dependencies. This introduces an unavoidable quality floor, proportional to the Conditional Total Correlation (CTC)—that is, the statistical dependency among tokens within a block.
Decoding Trajectory Analysis: Parallelism and Order Metrics
A key contribution of the paper is disentangling "parallelism" from "generation order". The authors introduce Average Finalization Parallelism (AFP) to quantify how many tokens are finalized per step (hardware-agnostic), and use Kendall's τ to measure alignment between finalization order and left-to-right (surface) order.
- AFP: AR decoding yields AFP ≈1; fully parallel decoding yields AFP =n (sequence length).
- Kendall's τ: AR decoding gives τ=1. Lower values indicate non-monotonic or out-of-order generation.
In-depth trajectory studies on LLaDA2-flash-100B reveal highly adaptive, domain- and step-wise behaviors:
Block-level analysis further reveals that decoding order varies across domains and across stages within a single generation. For instance, in "knowledge" and "math", AFP grows as more context is accumulated and uncertainty decays, while in code, AFP peaks at boilerplate regions and drops in logic-heavy spans.
Microstructure of Parallel and Non-monotonic Decoding
Token-level studies and case analyses reveal that parallel decoding is concentrated on "formulaic" patterns—such as formatting tokens, structural markers (e.g., newlines, punctuation), and rigid template sequences—where inter-token dependencies are minimal. High parallelism rarely occurs within semantically-rich, interdependent regions.
The paper also probes generation order via POS tagging: structural elements appear prior to details, with the model constructing scaffolds (e.g., punctuation, conjunctions) before filling in content (e.g., arguments, modifiers). Local minima of Kendall's τ occur at semantic pivots, such as transitioning between states or closing an argument and opening another. These order disruptions support the idea that MDLMs conduct out-of-order content planning, pre-structuring, and efficient filling when data supports it.

Figure 4: Visualization of parallelism intensity per block; color intensity represents tokens decoded per step, peaking in deterministic content.
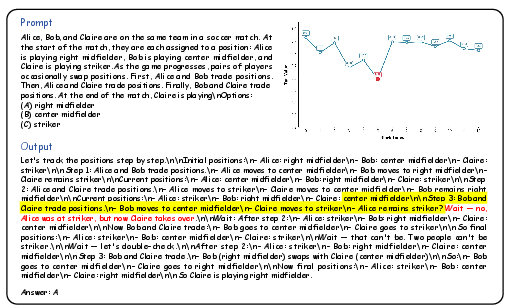
Figure 5: Case studies where highlighted blocks indicate local minima of τ, pointing to semantic or logical transition points with increased parallelism.
Non-Monotonic Reasoning: Constraint Satisfaction Tasks
An applied study on Sudoku and cross-math tasks demonstrates MDLMs outperform AR models for tasks that require non-sequential, global reasoning. In low-data settings (only 50 training samples), a fine-tuned Dream-7B (diffusion) solver exceeds both Qwen3-8B (AR, trained for 50 epochs) and even un-tuned LLaDA2-flash-100B AR baselines, both in accuracy and convergence rate.

Figure 6: Cross-math puzzle case—MDLMs can solve interlocked arithmetic grids (requiring simultaneous horizontal and vertical constraint satisfaction) more efficiently than AR models.
This supports the claim that, for problems where dependencies are not naturally left-to-right, any-order parallel updating confers a tangible advantage. The grid refinement process of MDLMs is inherently more compatible with bidirectional or global constraint satisfaction than the strictly causal progression of AR models.
Theoretical Insights and the Generate-then-Edit Paradigm
The authors formalize the theoretical floor for parallel decoding accuracy loss via the Conditional Total Correlation, proving that for highly-coupled tokens, no increase in parameter count can recover the lost accuracy while maintaining parallel independence. However, they also establish—via Dobrushin-like contraction arguments—that this dependency gap can be mitigated by iterative parallel editing: that is, making an initial parallel guess and then refining uncertain, interdependent regions in further rounds, which recouples dependencies across steps.
A "generate-then-edit" approach, wherein the initial output is progressively refined, is both provably convergent and does not inherently increase wall-clock runtime (given parallel throughput gains per iteration). The paper provides explicit runtime and mixing bounds, showing this format can match or exceed AR throughput while potentially closing the accuracy gap.
Implications and Future Directions
The study suggests three main vectors for future progress in MDLMs:
- Parallelism Potential: Realizing true end-to-end acceleration requires dedicated inference and system optimizations. Current pipelines do not exploit maximal possible parallelism.
- Non-sequential Reasoning: Tasks with bidirectional, global, or cyclic dependencies (e.g., CSPs, planning, certain code synthesis) are where MDLMs may inherently excel. Developing adaptive masking and path-mining strategies, rather than fixed or random masking, can amplify these strengths.
- Editing Paradigms: Shifting from strictly sampling to iterative refinement opens opportunities for more intelligent error correction, self-planning, and reduced error propagation. Theory supports that well-designed editing can be both efficient and accurate.
Conclusion
This work provides the most comprehensive mechanistic evaluation of MDLMs to date, establishing both their current limitations and avenues for improvement in arbitrary-order, parallel language generation. The findings indicate an intrinsic accuracy–parallelism trade-off imposed by independence assumptions but also point to editing-based inference as a means to recover dependencies and achieve high-quality, efficient text generation. These insights should inform the design of future non-autoregressive architectures, emphasizing not only the raw ability for parallel token decoding but the structural mechanisms to exploit it without undue loss of expressiveness or precision.
(2601.15593)