- The paper introduces a method that combines masked input training, gated LoRA, and a lightweight sampler module to enable simultaneous multi-token prediction.
- The approach preserves original model accuracy during fine-tuning by activating LoRA adapters only for masked tokens while leveraging a latent consistency loss.
- Experimental results show up to 5× speedup for code and math tasks and nearly 2.5× for chat tasks, validating its practical efficiency across domains.
The paper "Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential" (2507.11851) introduces a method to enhance the inference speed of autoregressive LLMs by enabling them to predict multiple tokens simultaneously. This is achieved through a combination of masked input training, gated LoRA adaptation, a lightweight sampler module, and a consistency loss, facilitating a speculative generation strategy. The method aims to leverage the inherent knowledge of future tokens already present in autoregressive models without compromising generation quality.
Methodology and Implementation
The core idea involves training the model to predict multiple future tokens at once using a masked input formulation. Special mask tokens are appended to the input sequence, and the model is trained to predict the tokens that would follow the original sequence. This is illustrated in Figure 1, showing how a pretrained model can be nudged towards better prediction of future tokens using mask tokens and a sampling module.
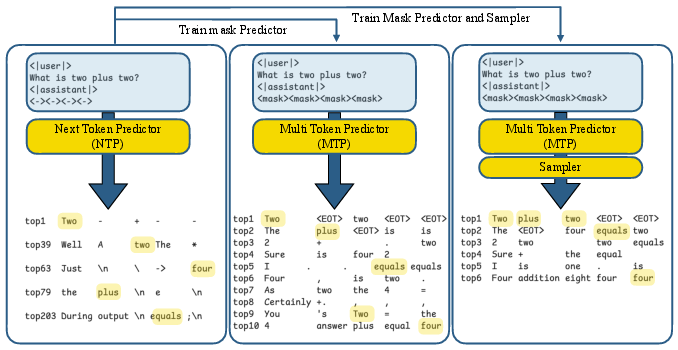
Figure 1: Autoregressive models implicitly anticipate future tokens. (Left): A pretrained model queried with a prompt plus redundant (-) tokens ranks the correct next token within the top-200. (Middle): Finetuning with <mask> tokens improves structure, pushing correct predictions into the top-10. (Right): Training a sampler head further refines future token prediction.
To preserve the original model's performance during fine-tuning, the authors employ a gated LoRA approach. This involves adding low-rank adapters to the model's linear layers but activating them only for the masked tokens. This ensures that the original next-token prediction capabilities of the model are not affected. The gated LoRA module is shown in the context of the overall MTP model architecture in Figure 2.
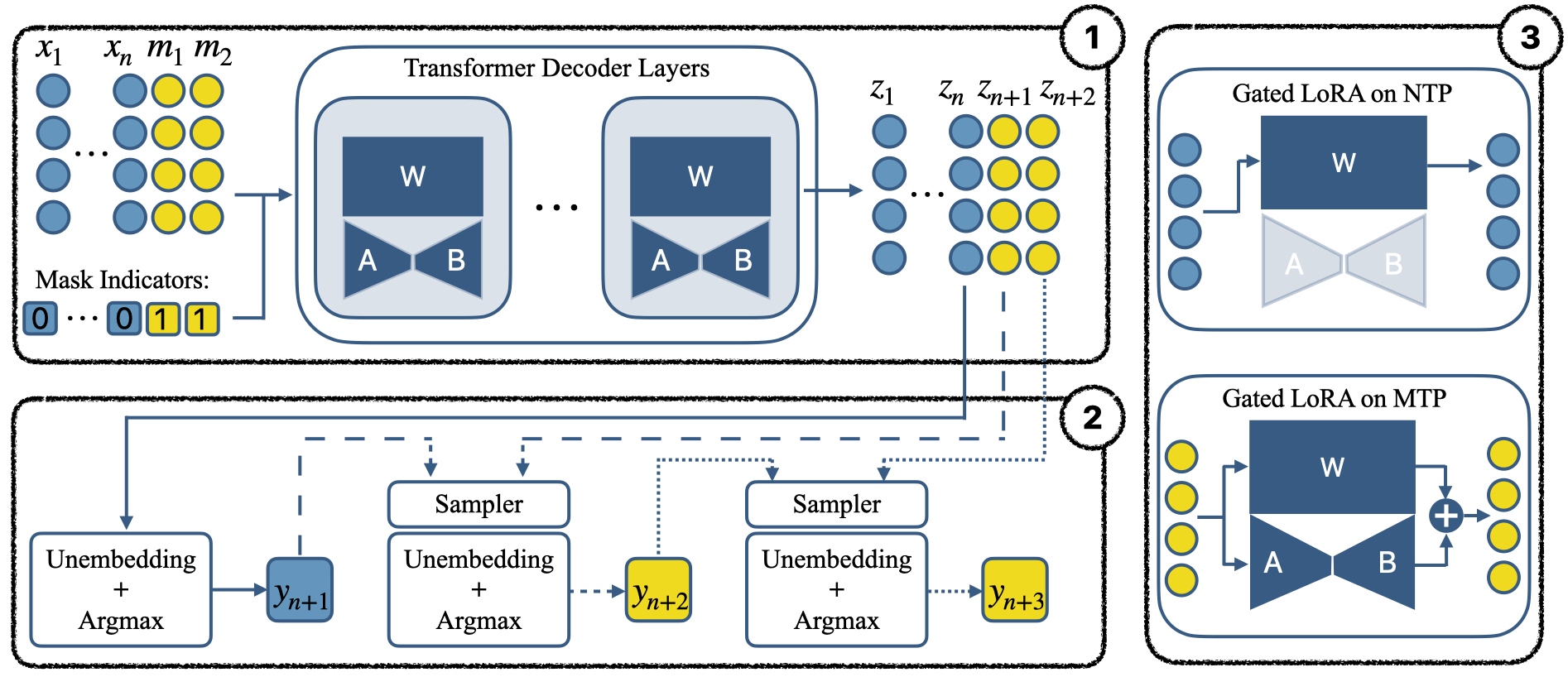
Figure 2: Components of our MTP model. Box-1 (top-left) shows the autoregressive model augmented with gated LoRA parameters. Box-2 (bottom left) illustrates the sampler head. Box-3 (right) presents the block diagram of the gated LoRA module.
A lightweight, two-layer MLP sampler module is introduced to generate coherent sequences from the predicted tokens. This module conditions each predicted token on the previously sampled ones, ensuring that the generated sequence is contextually consistent.
During training, the input tokens, position IDs, labels, and attention biases are modified to simulate multiple prompts in parallel, where each prompt includes a different number of tokens followed by mask tokens. This is depicted in Figure 3, which illustrates how regular inputs are converted to masked inputs for predicting additional tokens.
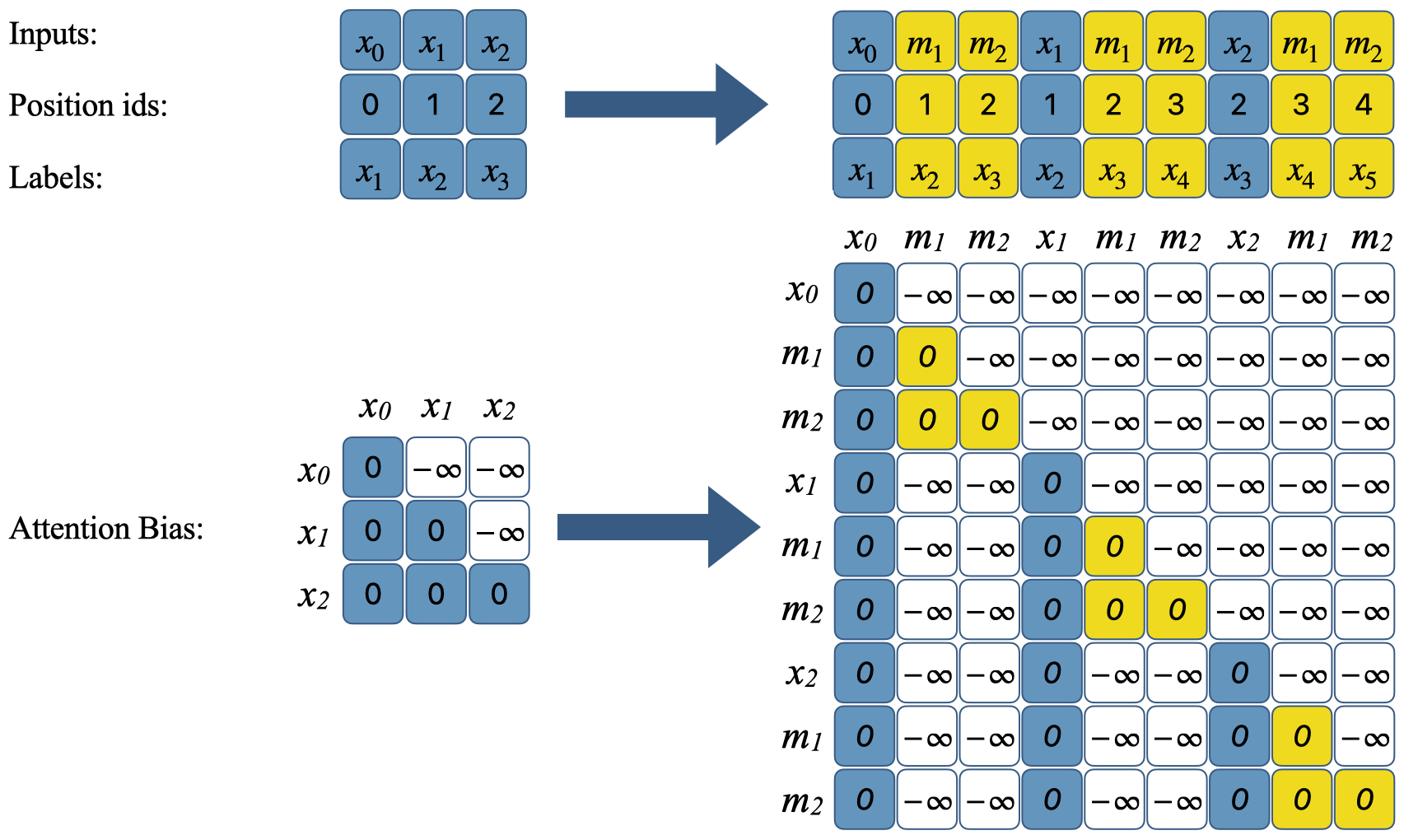
Figure 3: Converting regular inputs to masked inputs for predicting 2 extra tokens during training. NTP and MTP tokens are shown in blue and yellow, respectively. NTP tokens attend only to previous NTP tokens, which guarantees that the model's output for NTP tokens does not change. MTP tokens attend to previous NTP tokens and MTP tokens of the same block, but not to earlier MTP blocks.
Training and Inference Strategies
The training process incorporates a latent consistency loss (LCM) to enhance the alignment between the masked token predictions and the next-token predictions. This loss function minimizes the distance between the hidden representations of the MTP tokens and the corresponding NTP tokens, as shown in Figure 4.
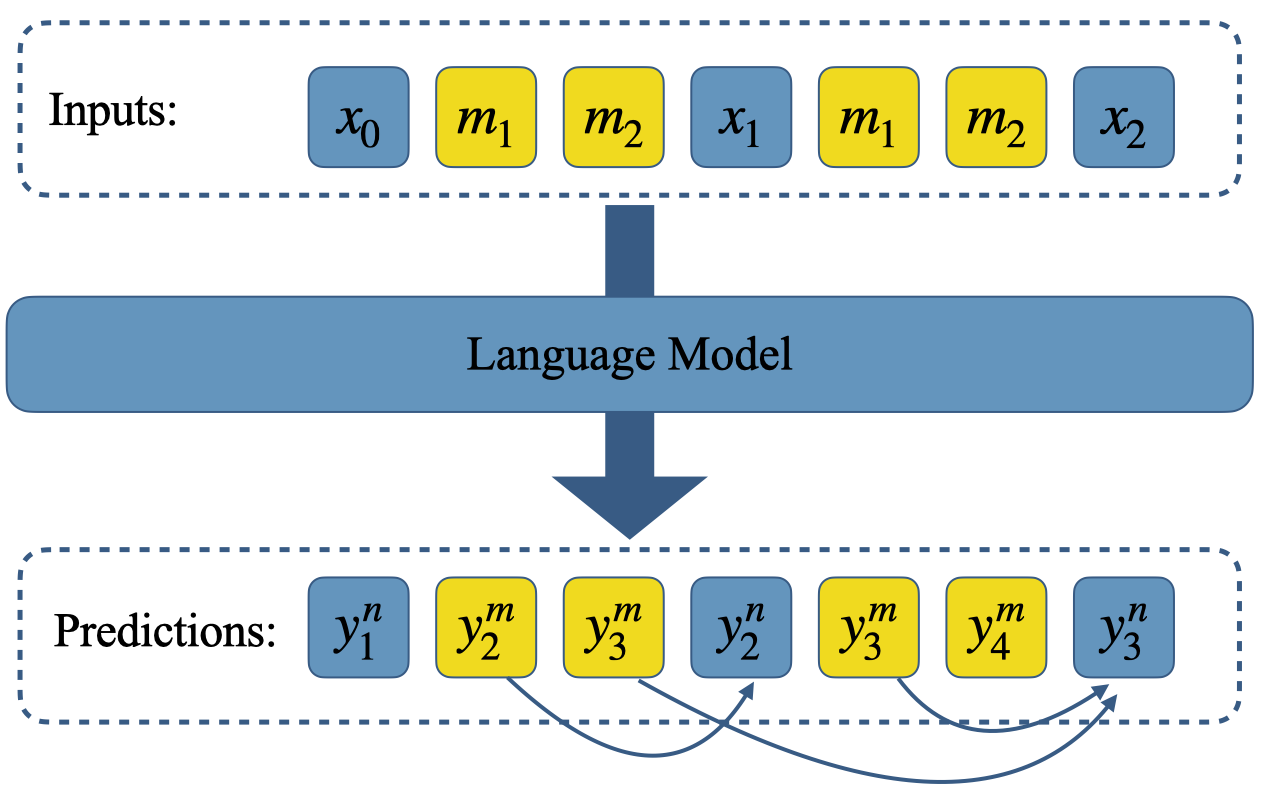
Figure 4: Illustration of the consistency loss. The goal is to minimize the distance between masked token predictions and the corresponding next-token predictions for each token. The arrows indicate which masked token predictions should be matched with which next-token predictions.
For inference, the paper explores two decoding strategies: linear decoding and quadratic decoding. Linear decoding involves verifying the predicted tokens sequentially, while quadratic decoding interleaves mask tokens within the speculative tokens to ensure that a fixed number of speculative tokens are always available for verification. The overall training loss is computed as the average of the base cross-entropy loss, the sampler cross-entropy loss, and the LCM loss over the relevant token positions.
Experimental Results
The experiments were conducted on the Tulu3-8B SFT model, and the results demonstrate significant speedups across various domains, including knowledge, math, coding, and chat. For instance, the method achieves nearly 5× speedup for code and math tasks and almost 2.5× for general chat tasks. The speedup achieved after training gated LoRA and the sampler head is shown in Figure 5.
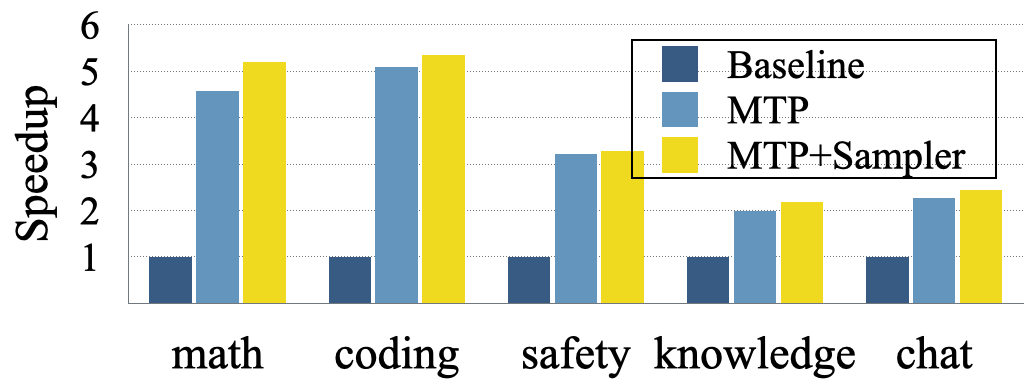
Figure 5: Speedup achieved after training gated LoRA and sampler head with supervised finetuning.
Ablation studies were performed to assess the contribution of each component, revealing that the sampler head, LCM loss, and quadratic decoding all contribute to improved speedup. The experiments also investigated the effect of LoRA rank, finding that the model maintains reasonable speedup even with very low ranks.
The paper highlights that using gated LoRA maintains accuracy during fine-tuning, whereas using standard LoRA causes accuracy to drop sharply as shown in Figure 6.
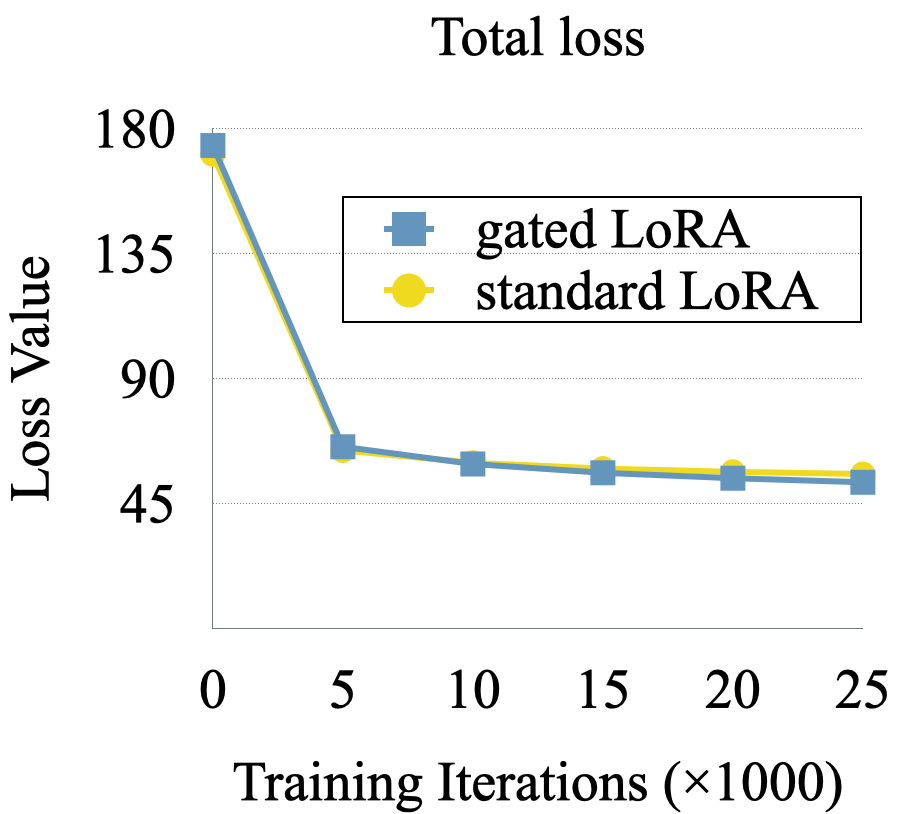
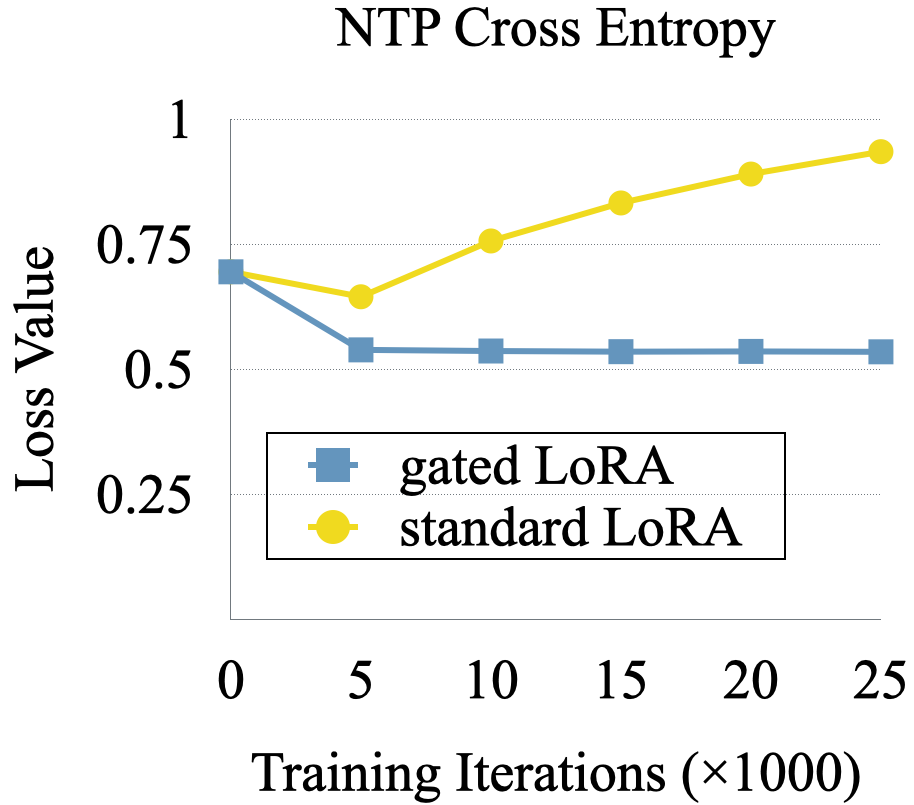
Figure 6: Arc-challenge accuracy
The paper relates to existing work on multi-token prediction and speculative decoding. It differentiates itself by training the model to fill in mask tokens with future tokens, leveraging the full depth and capacity of the model. The paper also contrasts its approach with other MTP methods that use additional prediction heads, which can increase inference cost and parameter count.
Conclusion
The method presented in "Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential" (2507.11851) offers a way to accelerate the inference speed of autoregressive LLMs by leveraging their inherent knowledge of future tokens. The combination of masked input training, gated LoRA adaptation, a lightweight sampler module, and a consistency loss enables the model to predict multiple tokens simultaneously without compromising generation quality.