Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Abstract: Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion LLMs (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making LLMs write faster without losing much accuracy. Normally, these models write one word at a time, in order, which can be slow. The authors introduce a new training method called “Jacobi Forcing” that teaches a model to confidently write several future words at once, in parallel. This makes the model much faster while keeping the same “cause and effect” rule it learned during pretraining (only looking at earlier words, not future ones). They also add smart tricks during inference (the model’s runtime) to accept more words per step.
What questions does the paper try to answer?
In simple terms, the paper asks:
- Can we make a standard LLM generate multiple future words at the same time, safely and accurately?
- Can we do this without breaking the model’s original habits (like only looking at previous words)?
- How much faster can we go, and will the answers stay just as good, especially for coding and math problems?
How did they do it? (Methods explained with analogies)
Think of writing as two styles:
- Autoregressive (AR): write one word at a time, left to right. Safe but slow.
- Parallel: try to write a chunk of words at once, then fix mistakes. Faster, but tricky.
The paper’s method has three main ideas, explained with everyday analogies:
1) Jacobi Decoding: “Draft, then refine”
- Imagine you guess a whole chunk of the next sentence (say 16 or 128 words) all at once.
- Then, in one pass, you update all those guesses based on what you’ve already written.
- You repeat this “update all at once” a few times. Eventually, the chunk settles into the same words you’d have written one-by-one. That final chunk is called the “fixed point.”
- You then move on to the next chunk.
This lets the model refine many positions in parallel, rather than stepping one word at a time.
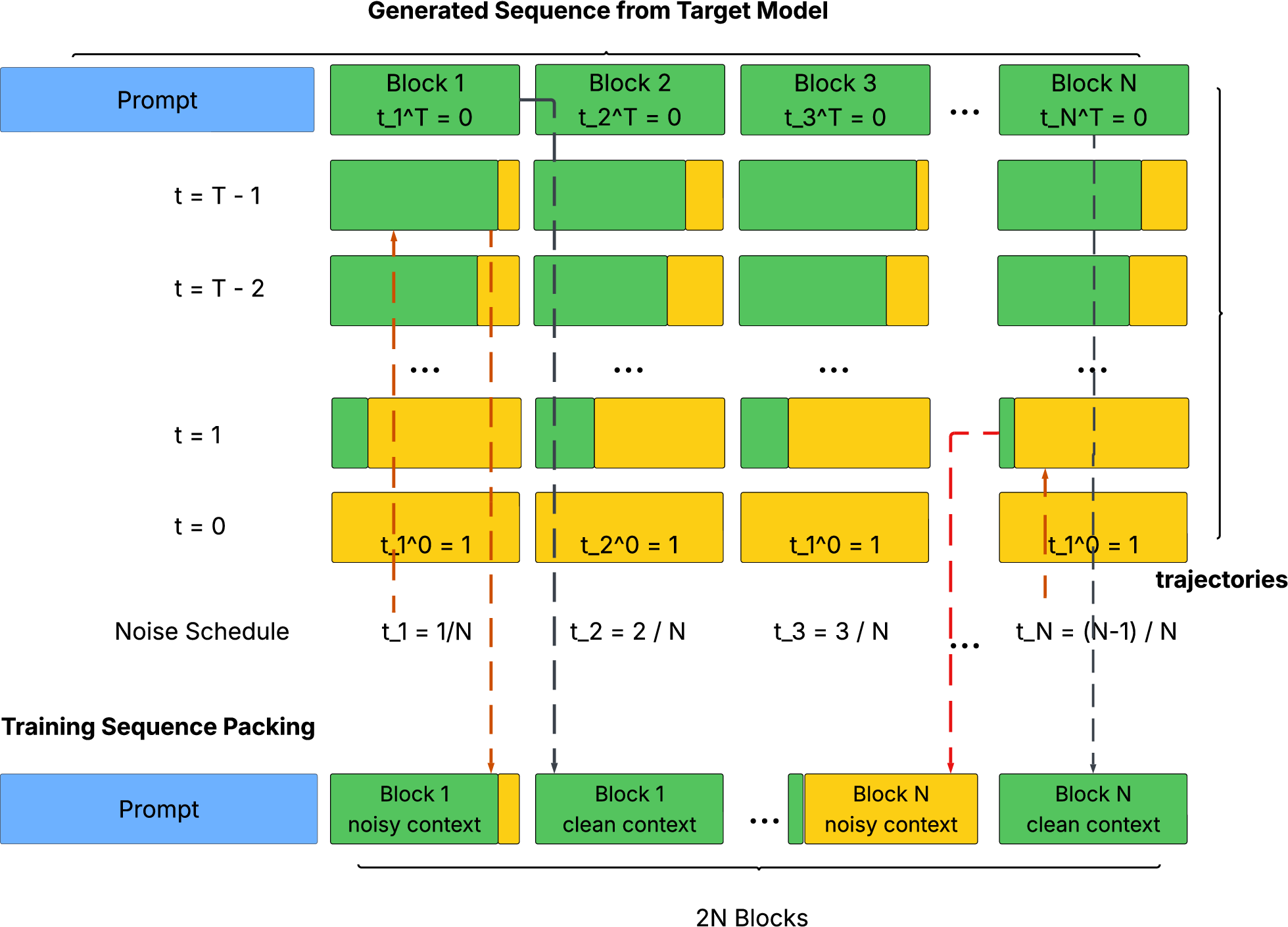
2) Jacobi Forcing (Training): “Practice on your own drafts, with growing difficulty”
- The model first runs Jacobi Decoding to produce its own “draft-to-final” trajectories for many prompts. These are like practice runs that show how rough guesses turn into correct chunks.
- During training, the model is shown these drafts where some words are intentionally wrong (this is the “noise”). It’s trained to still predict the correct final chunk, even when parts of the context are messy.
- The “noise schedule” gradually makes the drafts harder (more wrong words), like practicing with blurrier pictures over time.
- Crucially, the model keeps its original rule: it only looks at earlier words (causal attention). This avoids conflicts with how the model was pretrained and keeps it compatible with “KV cache,” which is like the model’s memory of past words used to avoid re-computation.
- They also keep a standard AR training loss to protect overall quality.
- After one round of training, they collect new, harder drafts with larger chunks and train again. This “progressive distillation” improves speed further.
3) Inference Optimizations: “Reuse good phrases and work ahead”
- Rejection Recycling: As the model refines a draft, it often produces correct little phrases (n-grams) before the whole chunk is final. The system saves these promising phrases and quickly checks them in parallel. If they’re right, it can accept many words in one go.
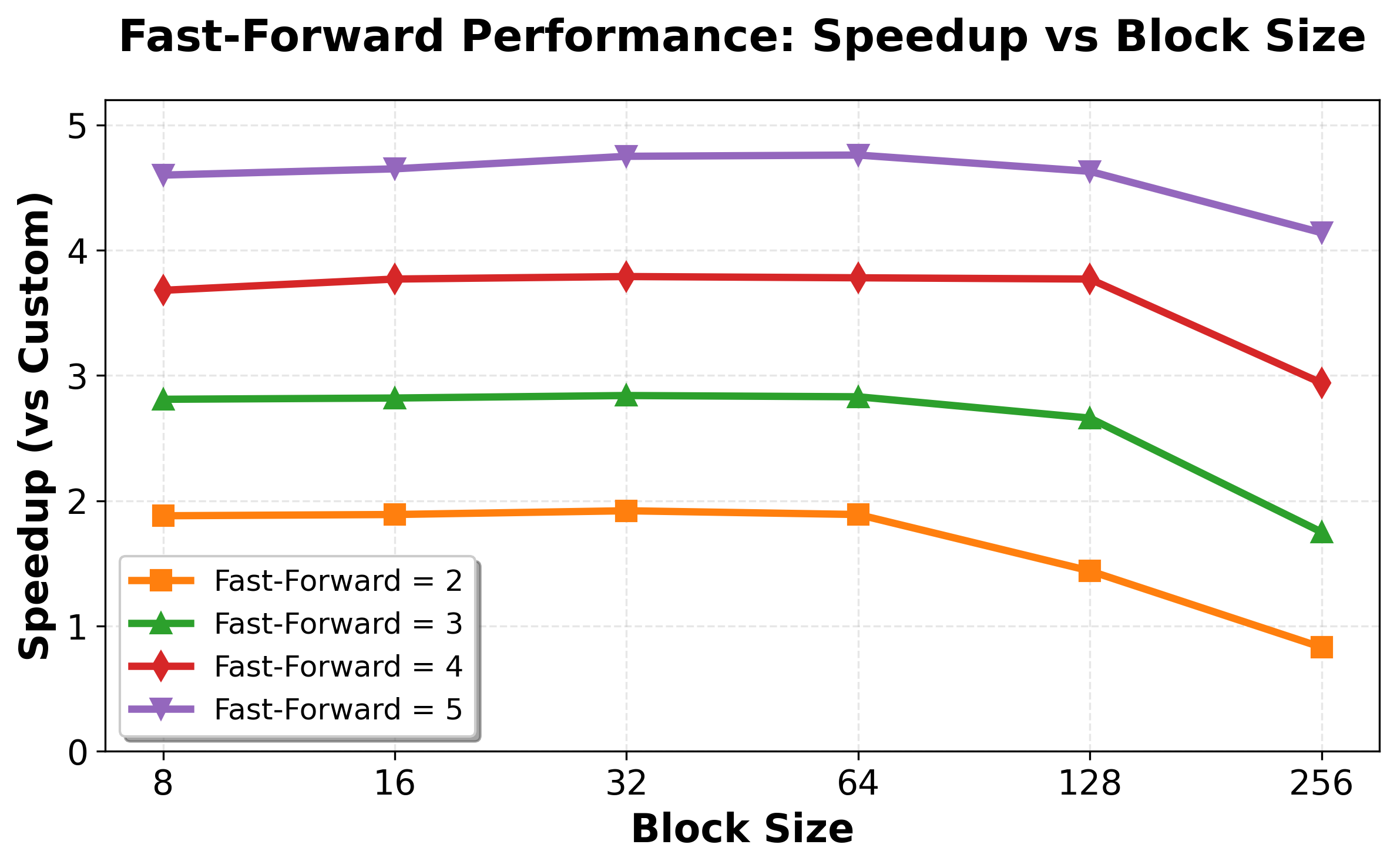
- Multi-block Decoding: The model drafts several upcoming chunks in parallel. Only one chunk (the “real-active” block) gets officially accepted right away. The others (the “pseudo-active” blocks) keep getting refined. When their turn comes, they’re already high-quality drafts, making acceptance faster. This is done carefully so the final text is exactly what the model would have written (“lossless” acceptance).
What did they find, and why is it important?
Across coding and math benchmarks, the method delivers big speedups with little or no drop in accuracy:
- Up to about 3.8× faster in wall-clock time compared to normal AR decoding, while staying very close in accuracy.
- With the runtime tricks (rejection recycling + multi-block decoding), speedups reach nearly 4×.
- The model accepts many more tokens per iteration—up to about 4.5× more—so fewer update rounds are needed.
- It outperforms several diffusion-style parallel methods in both speed and accuracy at the same model size.
- It works well on real hardware (A100, H200, B200 GPUs), making better use of available compute.
Why this matters:
- Faster generation reduces waiting time in real apps, like coding assistants or math solvers.
- Keeping “causal attention” means the method fits nicely with existing LLM infrastructure (like KV cache reuse), so it’s practical, not just theoretical.
- It avoids building extra draft models or changing the model’s architecture.
What’s the potential impact?
- Faster, still-accurate LLMs can improve user experience for coding, math, and general chatting.
- Better use of GPUs means servers can handle more requests at once, reducing costs and delays.
- The idea of “progressively training on your own drafts” could inspire similar approaches in other AI tasks (like planning or robotics), where you want parallel speed without losing reliability.
- Since it keeps the model’s original habits, it’s easier to integrate into current systems and combine with other speed-up techniques in the future.
In short: Jacobi Forcing teaches a standard LLM to safely “look ahead” and write multiple words per step, using its own practice drafts and a careful training schedule. It’s a practical way to get big speed gains while keeping accuracy high.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, structured to guide future research.
- Theory and guarantees
- Lack of formal convergence guarantees for Jacobi Forcing (JF) under noisy-context conditioning: when and why do fixed points emerge faster, and under what conditions does convergence degrade with larger blocks?
- No proof that JF’s decoding remains equivalent to the base model’s greedy AR beyond the lossless verification step in the real-active block; the method is “lossless” only relative to the fine-tuned model under greedy verification, not relative to the original AR distribution.
- Absence of a principled characterization of token acceptance/fast-forward distributions as a function of block size, noise schedule, and training depth (e.g., an analytical model predicting TPF/TPS vs. n, window size, and t).
- Unproven generalization of the progressive noise schedule claim (reducing longest noisy span to O(⌈tn⌉)) into sample complexity or optimization guarantees; no conditions provided for when progressive curricula outperform random schedules.
- Scope, datasets, and generalization
- Evaluation limited to coding and math with Qwen2.5 Instruct variants; no results for open-ended generation, dialogue, summarization, reasoning-heavy multi-turn tasks, or multilingual scenarios.
- No testing under long-context regimes (e.g., 32K–1M tokens) where KV cache pressure and noisy-context conditioning could behave differently.
- No multimodal or VLA experiments despite related work referencing consistency in VLAs; unclear applicability to non-text modalities.
- Training trajectories filtered to “passing” unit-test code and math-only splits; unclear bias introduced by using “only-correct” generations and how this affects robustness.
- Decoding modes and distributional fidelity
- Results target greedy decoding only; it is unknown how to adapt JF to probabilistic sampling (temperature, top-k, nucleus) without breaking correctness guarantees or losing speedup.
- Impact on diversity and calibration (e.g., entropy, self-consistency) is unmeasured; risk of collapsing to overly deterministic outputs under noisy-context training is not assessed.
- Compatibility with constrained decoding (e.g., JSON schemas, formal grammars) and beam search or MBR is unexplored.
- Training procedure, curriculum, and objectives
- Only two progressive distillation rounds studied; no analysis of diminishing returns, optimal stopping, or adaptive curricula driven by acceptance rate/trajectory statistics.
- Sensitivity to AR loss weight w in the joint objective is not reported; no guidance on how w impacts stability, quality, and speed.
- The progressive noise schedule is hand-crafted; no exploration of learned or adaptive schedules (e.g., curriculum policies that target hardest spans).
- Noise-aware causal masking variants are only partially ablated (NC vs. NC-IC); no exploration of hybrid or position-aware masks or their interaction with different architectures.
- Missing analysis of training compute cost vs. lifetime inference savings (ROI), including wall-clock, energy, and data requirements.
- Algorithmic components and design choices
- Rejection recycling: pool sizing, refresh policy, eviction strategy, and collision handling are not specified; no study of correctness/efficiency trade-offs under different pool designs.
- Multi-block decoding: scalability beyond K=2 is unclear; failure modes when pseudo-active blocks drift from future fixed points are not analyzed.
- No fallback mechanisms when drafts degrade (e.g., automatic reversion to AR/Jacobi-only or dynamic K/block-size adjustments).
- Limited exploration of larger block sizes (>128) where both acceptance and hardware constraints change; no systematic limit study.
- Hardware, systems, and scalability
- Speedups shown on A100/H200/B200; missing evaluations on consumer GPUs (e.g., RTX), CPUs, TPUs, and edge devices; unclear how shared KV and large parallel verification perform under stricter memory/latency constraints.
- No analysis with large models (e.g., 30B–70B+) or multi-node tensor/pipeline parallel setups; interactions with KV sharding, ZeRO, or activation checkpointing are unexplored.
- FLOPs/latency trade-offs assessed for a narrow regime; no p50/p95 latency distributions under concurrency, batching, and real-world service loads.
- Memory footprint of multi-block + verification (batching, shared KV) is not quantified; potential fragmentation/pressure on GPU memory is not addressed.
- Interoperability with inference optimizations (paged KV caches, quantization, FlashAttention variants, speculative hardware pipelines) is not studied.
- Comparisons and benchmarking
- dLLM baselines are not trained on the same data/compute budgets nor identical model families; the fairness and attribution of speed/quality gains remain uncertain.
- Missing standardized benchmarks for multi-token parallel decoding to enable apples-to-apples comparisons (e.g., unified prompts, hardware configs, reference implementations).
- No energy-efficiency metrics (tokens/Joule) or cost curves across speed/quality trade-offs versus alternative accelerators (speculative decoding, Medusa/EAGLE heads, dLLM dual-cache).
- Quality, robustness, and safety
- Accuracy drops on coding benchmarks (e.g., HumanEval −4.3 points) are not dissected; no error taxonomy to identify where noisy-context conditioning harms correctness.
- Robustness under distribution shift, adversarial prompts, and safety-related prompts not evaluated; potential amplification of pre-existing biases through self-generated trajectories is unaddressed.
- Stability on very long generations (error accumulation, drifting drafts) and multi-turn interactive use is untested.
- Perplexity and calibration metrics on general corpora are not reported; impact on base language modeling quality remains unknown.
- Extensions and integrations
- Combination with speculative decoding (e.g., Medusa/EAGLE feature-level drafting, online speculative drafter adaptation) is not explored; potential synergies are open.
- Unclear how JF interacts with downstream SFT/RLHF/Direct Preference Optimization; whether speedups persist post-alignment training is unknown.
- Adapter- or LoRA-style parameter-efficient fine-tuning for JF is not investigated; could enable faster adoption without full model updates.
- Applicability to structured generation tasks beyond unit-tested code (e.g., SQL, XML, program synthesis with formal verification) is an open direction.
- Reproducibility and implementation details
- Key implementation specifics are missing: exact batch shapes for multi-block + verification, KV cache sharing across candidates, memory usage, and parallelism strategies.
- Code claims availability, but full details for data curation, trajectory generation seeds, and hardware kernels used for parallel verification are not exhaustively documented.
These gaps suggest concrete directions: formalize convergence/acceptance behavior, broaden domains and decoding modes, develop adaptive curricula and robustifying fallbacks, systematize hardware scaling and memory costs, standardize benchmarks and energy reporting, and explore integrations with speculative methods, alignment pipelines, and parameter-efficient finetuning.
Practical Applications
Immediate Applications
The following applications can be deployed today by integrating the paper’s Jacobi Forcing (JF) training paradigm, noise-aware causal masking, and inference optimizations (multi-block decoding, rejection recycling) into existing LLM workflows. Each item notes relevant sectors, potential tools/workflows, and dependencies.
- Faster LLM inference in cloud services and APIs (3–4× lower latency for greedy decoding)
- Sectors: software, cloud platforms, finance, e-commerce, customer support
- Tools/workflows: JF-trained variants of popular AR models; integration into inference engines (e.g., vLLM, TensorRT-LLM/ONNX Runtime/Triton), exact KV-cache reuse, batched parallel verification via rejection recycling and multi-block decoding
- Assumptions/dependencies: best gains with greedy decoding; engine support for batched verification with shared KV; block-size tuning per hardware (e.g., A100/H200); minor accuracy trade-offs in some domains (e.g., HumanEval, MBPP)
- Accelerated coding assistants in IDEs (near-instant suggestions with minimal quality loss on structured coding tasks)
- Sectors: software development, DevTools
- Tools/workflows: fine-tune code LLMs (e.g., Qwen2.5-Coder) with JF on unit-testable datasets; deploy multi-block decoding for more accepted tokens/iteration; maintain KV-cache continuity for long contexts
- Assumptions/dependencies: unit tests/greedy decoding workflows favored; creative code generation involving sampling may need adaptation; block-size and verification-size tuned to GPU budget
- Faster math tutoring and problem solving (step-by-step solutions at lower latency with near-baseline accuracy)
- Sectors: education, EdTech
- Tools/workflows: JF-trained math models (e.g., Qwen2.5-Math) in tutoring apps; multi-block decoding for long reasoning chains; background n-gram candidate pools for verification
- Assumptions/dependencies: results validated on GSM8K/MATH; complex chain-of-thought with sampling may require careful calibration; streaming UX may need gating to avoid jitter from pseudo-accepted tokens
- High-throughput batch generation (summarization, report drafting, code refactoring)
- Sectors: enterprise software, analytics, content ops
- Tools/workflows: batch pipelines that feed Jacobi trajectories; FLOPs-aware scheduling (block size ~64–128; verification size ~2–8) to maximize parallel tokens; monitor TPS/TPF and accuracy
- Assumptions/dependencies: greatest benefit under deterministic greedy workflows; long sequences benefit from multi-block drafting; hardware scaling (H200 shows parallel decoding of up to ~126 tokens with negligible latency penalties)
- Cost and energy reduction in inference serving
- Sectors: cloud, energy, sustainability
- Tools/workflows: capacity planning with JF speedups; TPS-focused autoscaling; energy accounting per request/token; green AI reporting (latency/throughput reductions)
- Assumptions/dependencies: actual energy gains depend on hardware utilization and operator efficiency; benefits strongest for deterministic serving; careful monitoring to avoid hidden overheads from verification/drafting
- SQL and data engineering assistants (lower latency for structured query generation and refactoring)
- Sectors: data platforms, BI, ETL (notably relevant to Snowflake-like environments)
- Tools/workflows: JF fine-tuning on SQL corpora; multi-block decoding for long queries; rejection recycling on frequent n-grams
- Assumptions/dependencies: accuracy/semantic correctness must be validated (unit tests, DB constraints); block sizes tuned to serving cluster GPUs
- Drop-in inference engine modules for multi-block decoding and rejection recycling
- Sectors: software, infrastructure
- Tools/workflows: “JF-accelerator” plugin implementing: (1) n-gram pool management; (2) pseudo-acceptance for future blocks; (3) batch verification with shared KV; (4) greedy acceptance in the real-active block for lossless correctness
- Assumptions/dependencies: engine changes required (scheduler, KV-sharing across candidates, batching kernels); correctness guarantees tied to greedy verification
- Progressive distillation training recipe for AR models (producing parallel-decoder LLMs without bidirectional attention)
- Sectors: MLOps, model development
- Tools/workflows: sequence packing with noise-aware causal masks; progressive noise schedules (windowed linear ramps); iterative rounds with increasing block size; joint loss with AR term to preserve quality
- Assumptions/dependencies: compute budget (e.g., 10k+ steps per round) and data availability (Jacobi trajectory generation at scale); domain-specific curation (coding/math vs. general text); careful tuning of loss weight w and window size
- Improved self-speculative generation for existing AR models via rejection recycling (even without retraining)
- Sectors: software, infrastructure
- Tools/workflows: implement n-gram candidate pools and parallel verification atop Jacobi decoding; reuse existing KV caches; apply greedy acceptance for correctness
- Assumptions/dependencies: speedups smaller than with JF (fewer high-quality draft n-grams); engine must support efficient candidate batching; accuracy preserved only under greedy acceptance
- Research and benchmarking workflows in academia (replicating and extending JF results)
- Sectors: academia
- Tools/workflows: open-source code; standardized TPS/TPF and pass@1/solve-rate evaluation; ablations for noise schedules, masks, block sizes; data curation of Jacobi trajectories
- Assumptions/dependencies: access to mid/high-end GPUs (A100/H200/B200); reproducible training configs; domain-specific datasets (coding/math)
Long-Term Applications
These applications are promising but typically require additional research, scaling, or engineering before wide deployment.
- General-purpose LLM acceleration across diverse tasks (creative writing, dialogue with sampling, multilingual generation)
- Sectors: consumer apps, media, localization
- Tools/products: JF training adapted for sampling (top-k/p) with calibrated verification; domain-agnostic trajectory generation; dynamic block-size schedules
- Dependencies: additional research for non-greedy decoding compatibility; robustness across non-structured outputs; potential fine-tuning per genre/language
- Synergistic integration with speculative decoding (combining JF’s parallel blocks with drafter proposals)
- Sectors: infrastructure, software
- Tools/products: hybrid engines that (1) draft via lightweight heads/models; (2) verify via multi-block greedy acceptance; (3) recycle n-grams
- Dependencies: careful design to avoid duplicated work; scheduling between speculative proposals and Jacobi iterations; empirical quality-speed trade-offs
- Hardware/software co-design for parallel verification and shared KV caches
- Sectors: semiconductors, systems
- Tools/products: kernels for batched candidate verification; KV-sharing primitives; scheduler support for multi-block/pseudo-acceptance; accelerator instructions for block-wise masking
- Dependencies: vendor support (CUDA/ROCm/NPU SDKs); memory bandwidth vs. compute balance; operator fusion to minimize overhead
- On-device and edge deployment (mobile NPUs, embedded robotics)
- Sectors: mobile, IoT, robotics
- Tools/products: memory-efficient JF variants; quantization-aware training with progressive distillation; low-latency streaming block schedulers
- Dependencies: limited memory/KV capacity; operator availability on NPUs; adaptation for streaming I/O; energy budget constraints
- Real-time multimodal assistants (speech, vision, text) with parallel lookahead decoding
- Sectors: consumer assistants, accessibility
- Tools/products: JF-like training for multimodal transformer/VLA stacks; multi-block decoding adapted to multimodal tokens; pseudo-active blocks synchronized with sensor inputs
- Dependencies: consistent convergence under mixed modalities; temporal alignment; lossless behavior under greedy acceptance in multimodal settings
- RAG/agent pipelines with background drafting (generate multi-step plans and tool calls concurrently)
- Sectors: enterprise AI, automation
- Tools/products: multi-block drafts across planned steps; n-gram pools seeded from retrieved context; parallel verification of action sequences; KV reuse across sub-episodes
- Dependencies: correctness of tool-call arguments; non-greedy sampling often used in agents; maintaining determinism vs. exploration
- Domain-specific JF models (legal, medical, compliance) with safety guarantees
- Sectors: healthcare, legal, public sector
- Tools/products: regulated datasets for trajectory generation; audit trails; confidence thresholds on token acceptance; human-in-the-loop verification
- Dependencies: rigorous evaluation and certification; strict quality retention; alignment/guardrails under parallel decoding
- Dynamic block-size and verification-size controllers (adaptive to prompt length, hardware load)
- Sectors: infrastructure
- Tools/products: online schedulers that modulate block and verification sizes; feedback from TPS/latency targets; per-request quality budgets
- Dependencies: robust control policies; observability of per-request performance; avoiding oscillations and throughput fragmentation
- Formal analysis and training curricula for parallel fixed-point decoding
- Sectors: academia, education
- Tools/products: coursework and toolkits for Jacobi/Gauss-Seidel decoding; convergence diagnostics; progressive noise curriculum design; visualizers for trajectories
- Dependencies: theory-building for convergence under various masks/schedules; standardized benchmarks across domains
- Sustainability and policy frameworks (procurement standards emphasizing throughput/energy efficiency)
- Sectors: policy, cloud, sustainability
- Tools/products: reporting standards for TPS/TPF per watt; SLAs incorporating parallel decoding efficiency; incentives for deploying greener inference engines
- Dependencies: reliable energy measurements; industry-wide metrics; balancing speed with quality and fairness considerations
Glossary
- Autoregressive (AR) decoding: Token generation process where outputs are produced sequentially, each conditioned on previous tokens. "Yet, autoregressive (AR) decoding generates tokens sequentially, limiting parallelism and leading to high latency."
- Bidirectional attention: Attention mechanism that allows tokens to attend to both past and future positions, conflicting with causal generation. "and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse."
- Causal attention mask: An attention mask that restricts each token to attend only to previous tokens to preserve causality. "the above n maximization problems can be solved in parallel by using a causal attention mask, i.e., only one forward pass of the LLM is required to obtain {(j+1)} based on {(j)}."
- Causal prior: The learned preference of an autoregressive model to rely on past context only. "conflicts with the causal prior learned during pretraining"
- Consistency distillation: Training approach that teaches a model to map intermediate states along a decoding trajectory to the final solution to speed convergence. "consistency distillation, a training approach designed to accelerate convergence to the fixed point from arbitrary states on a Jacobi trajectory."
- Consistency loss: Objective encouraging the model to match its own predictions at different points along a trajectory, enabling multi-token prediction. "The key idea is to introduce a consistency loss that encourages an LLM p_\theta(\cdot|·) to predict multiple tokens simultaneously:"
- Diffusion-based LLMs (dLLMs): LLMs that decode by iterative denoising of whole sequences, enabling parallel generation. "A popular approach is diffusion-based LLMs (dLLMs), which relax left-to-right generation by modeling the entire sequence jointly and decoding via full-sequence denoising"
- Fixed point: A stable decoded state that no longer changes under further iterations and matches greedy AR output. "Let _{B_i}* denote the fixed point obtained for the i-th block."
- FLOPs (floating-point operations): Measure of computational work; often a hardware utilization target in inference. "underutilizing modern AI accelerators whose abundant FLOPs could otherwise be leveraged to decode more future tokens per iteration"
- Gauss–Seidel iterations: An iterative fixed-point method related to Jacobi used for solving systems of equations. "has been instantiated using Jacobi (Gauss-Seidel) iterations~\citep{song2021accelerating,santilli2023accelerating}."
- Greedy rejection sampling: Verification technique that accepts only tokens consistent with the target model under greedy decoding. "they employ greedy rejection sampling for token acceptance in the real-active block~\citep{leviathan2022speculative_decoding}."
- Greedy strategy: Decoding policy that selects the most probable token at each step. "the standard AR decoding under the greedy strategy produces a response sequentially as follows:"
- Jacobi Decoding: Parallel decoding method that frames generation as solving a system of nonlinear equations via fixed-point updates. "Jacobi decoding~\citep{song2021accelerating,santilli2023accelerating} addresses this bottleneck by reformulating token generation as solving a system of nonlinear equations:"
- Jacobi fixed-point iteration: The iterative update procedure used to solve the reformulated decoding equations in parallel. "This system can be solved in parallel using Jacobi fixed-point iteration~\citep{ortega2000iterative}."
- Jacobi Forcing: Progressive distillation paradigm that trains AR models on their own parallel decoding trajectories to enable fast parallel decoding. "we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories"
- Jacobi trajectory: The sequence of intermediate states produced by Jacobi decoding from initialization to fixed point. "Let \mathcal{J} := {{(0)}, \dots, {(k)}} denote the Jacobi trajectory."
- KL divergence: A divergence measure used in the training loss to match distributions across tokens. "denotes the KL divergence aggregated across the tokens in a block."
- KV cache: Cached key-value attention states reused across decoding steps to reduce computation. "hinders the integration of exact KV cache reuse."
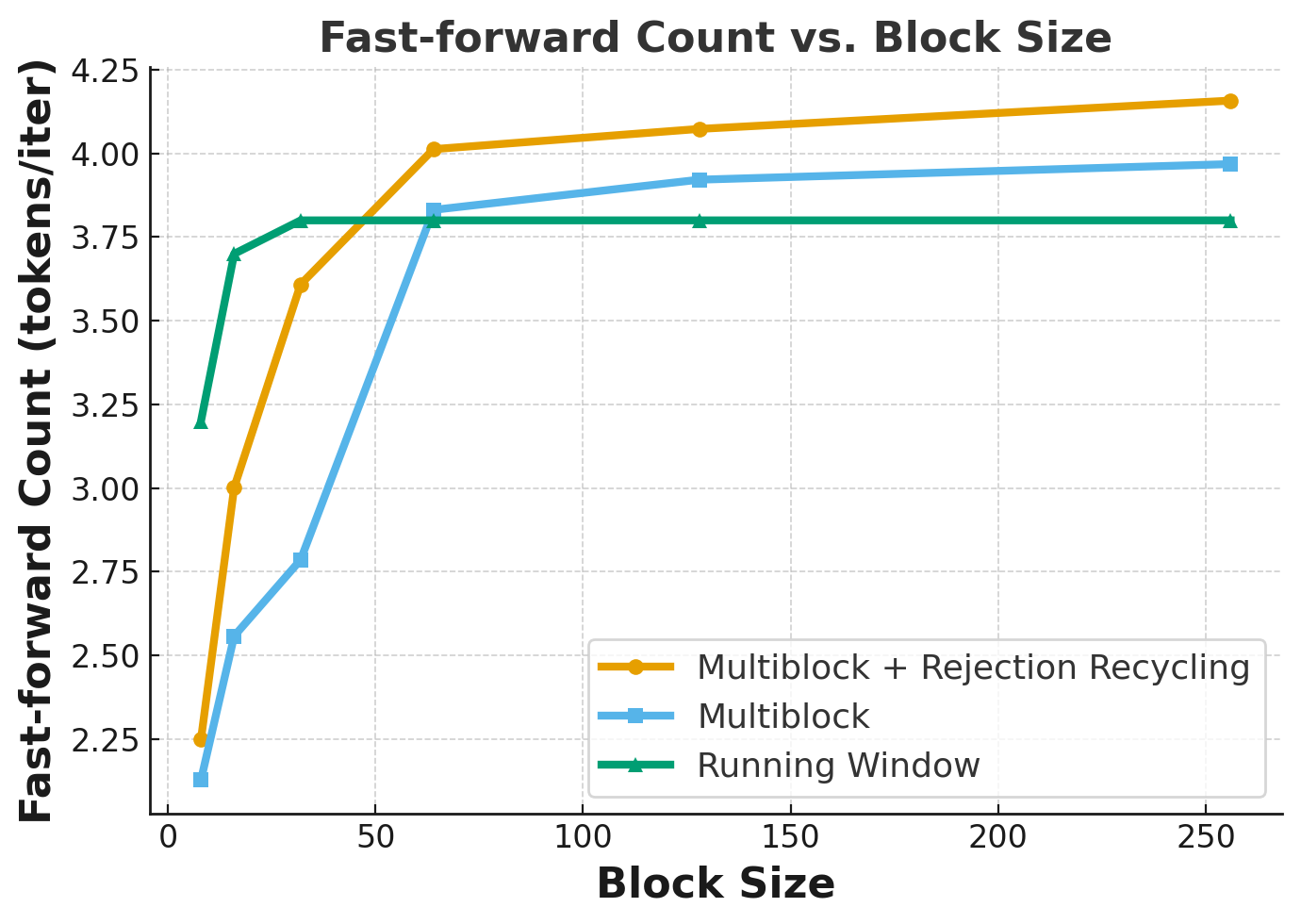
- Multi-block decoding: Decoding scheme that maintains and refines multiple future blocks in parallel while committing only the active block. "we introduce multi-block decoding, a new decoding paradigm that maintains and refines up to blocks simultaneously."
- Negative evidence lower bound (NELBO): A training objective used by diffusion LMs that loosely bounds NLL and can be less efficient. "due to their negative evidence lower bound (NELBO) training objective, a loose bound on AR's negative log-likelihood (NLL) that is proven less efficient"
- Negative log-likelihood (NLL): Standard AR training objective measuring the log-probability of the correct tokens. "a loose bound on AR's negative log-likelihood (NLL) that is proven less efficient"
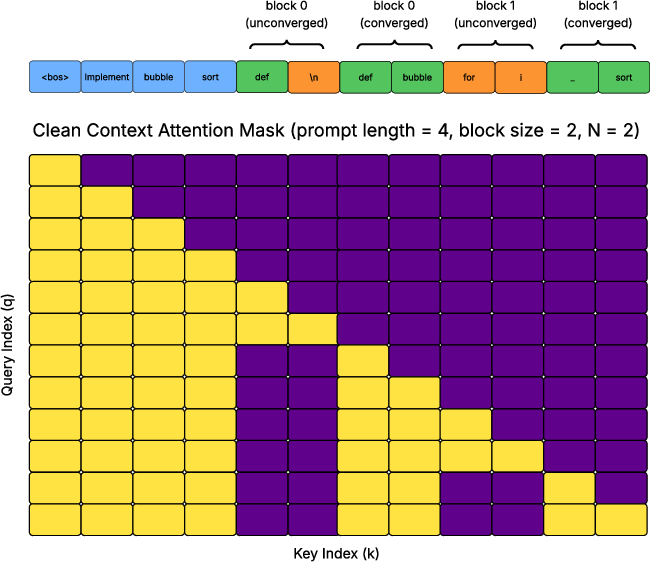
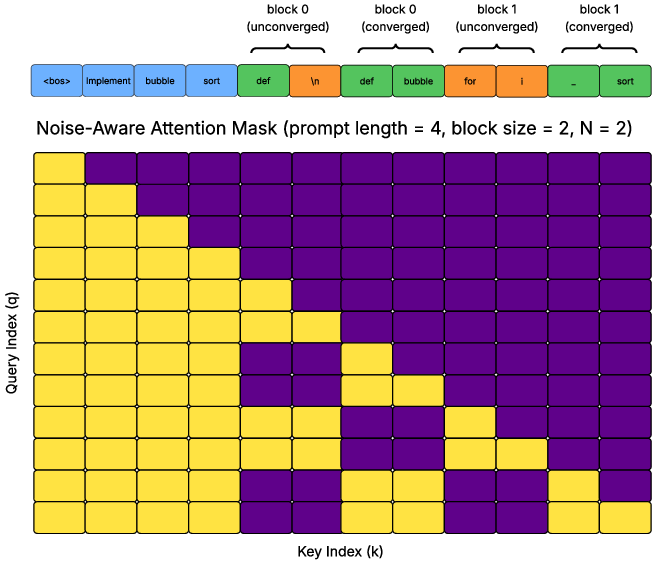
- Noise-aware causal attention: Attention mechanism that conditions predictions on a mix of clean and noisy contexts during training. "Jacobi Forcing addresses this by introducing a noise-aware causal attention that teaches the model to predict the converged point within each block conditioned on previous unconverged blocks"
- Progressive consistency loss: Loss that matches predictions under progressively increasing noise across blocks to stabilize and accelerate multi-token learning. "we introduce a new loss term, progressive consistency loss, which optimizes p_\theta under the progressive noise schedule"
- Progressive distillation: Training strategy that gradually increases difficulty (e.g., block size or noise) across rounds to improve parallel decoding. "we introduce Jacobi Forcing, a progressive distillation technique that addresses this pretrain-to-posttrain mismatch."
- Progressive noise schedule: Curriculum over noise ratios applied across blocks/windows to control noisy context length during training. "The noise schedule follows a cyclic strategy with window size , where the noise ratio linearly increases from 0 to 1 within each window"
- Rejection recycling: Technique that reuses verified n-grams from intermediate drafts to accelerate acceptance in subsequent iterations. "Rejection Recycling. Prior work has shown that n-grams produced during Jacobi iterations can be verified in parallel and reused in subsequent iterations"
- Real-active block: The block whose tokens are verified and committed to the KV cache, as opposed to pseudo-active blocks refined speculatively. "It marks the block closest to the effective KV cache boundary as the real-active block and all the other blocks as pseudo-active blocks."
- Sequence packing: Strategy for combining multiple masked/clean segments in a single forward pass with tailored attention masks. "Sequence packing with two attention mask implementations, both allow logits from clean blocks and noisy blocks to be generated with single forward pass"
- Speculative decoding: Family of methods that draft multiple future tokens and verify them with the target model in one pass to reduce latency. "Speculative Decoding. Speculative decoding speeds up AR generation by letting a lightweight drafter propose several future tokens and having the target model verify them in one pass"
- Stationary tokens: Tokens that are predicted correctly under noisy context and remain unchanged across iterations. "we also observe the increasing number of stationary tokens, which are correctly predicted with preceding noisy tokens and remain unaltered through subsequent iterations."
- Stop-gradient (stopgrad): Operator that prevents gradients from flowing through a term during optimization. "where "
- Token acceptance count per iteration: Number of tokens verified and accepted into the sequence in each decoding iteration. "enables up to higher token acceptance count per iteration"
- Wall-clock speedup: End-to-end latency improvement measured in real time. "achieves wall-clock speedup on coding benchmarks with minimal loss in performance."
Collections
Sign up for free to add this paper to one or more collections.