Faster LLM Inference via Sequential Monte Carlo
Abstract: Speculative decoding (SD) accelerates LLM inference by drafting tokens from a cheap proposal model and verifying them against an expensive target model via rejection sampling. Because rejection truncates the draft block at the first error, throughput degrades when draft and target diverge. Rather than rejecting draft tokens outright, we propose to reweight them. To this end, we introduce sequential Monte Carlo speculative decoding (SMC-SD), which replaces token-level rejection with importance-weighted resampling over a population of draft particles. SMC-SD is a principled approximate inference scheme that trades exactness for additional speed, while preserving theoretical bounds on its per-step approximation error. Because LLM inference is memory bandwidth-bound, the arithmetic needed to draft particles and to score them in parallel comes nearly for free -- SMC-SD uses idle compute to turn verification into a vectorized, fixed-size operation with no rollback. Empirically, SMC-SD achieves 2.36x speed-up over speculative decoding and a 5.2x speed-up over autoregressive decoding, while remaining within 3% of the target model's accuracy on reasoning, instruction-following, and coding benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to make big LLMs answer faster. Instead of having a small model “draft” several words and a big model “check” them one by one (throwing away everything after the first mistake), the authors keep a small crowd of candidates at once, score them, keep the best, and continue. This method is called Sequential Monte Carlo Speculative Decoding (SMC‑SD). It makes generation faster while staying very close to the big model’s accuracy.
What questions were the researchers trying to answer?
- Can we speed up LLM text generation more than current “speculative decoding” methods?
- Can we avoid wasting work when the small draft model disagrees with the big target model?
- Can we design a method that uses GPUs better (so we get more speed for “free”)?
- If we make the method approximate instead of perfectly exact, can we control how close it stays to the big model?
How does the method work?
First, the usual approach (and its limits)
- Autoregressive decoding: The model writes one token at a time, and each new token depends on all previous tokens—so it’s naturally slow.
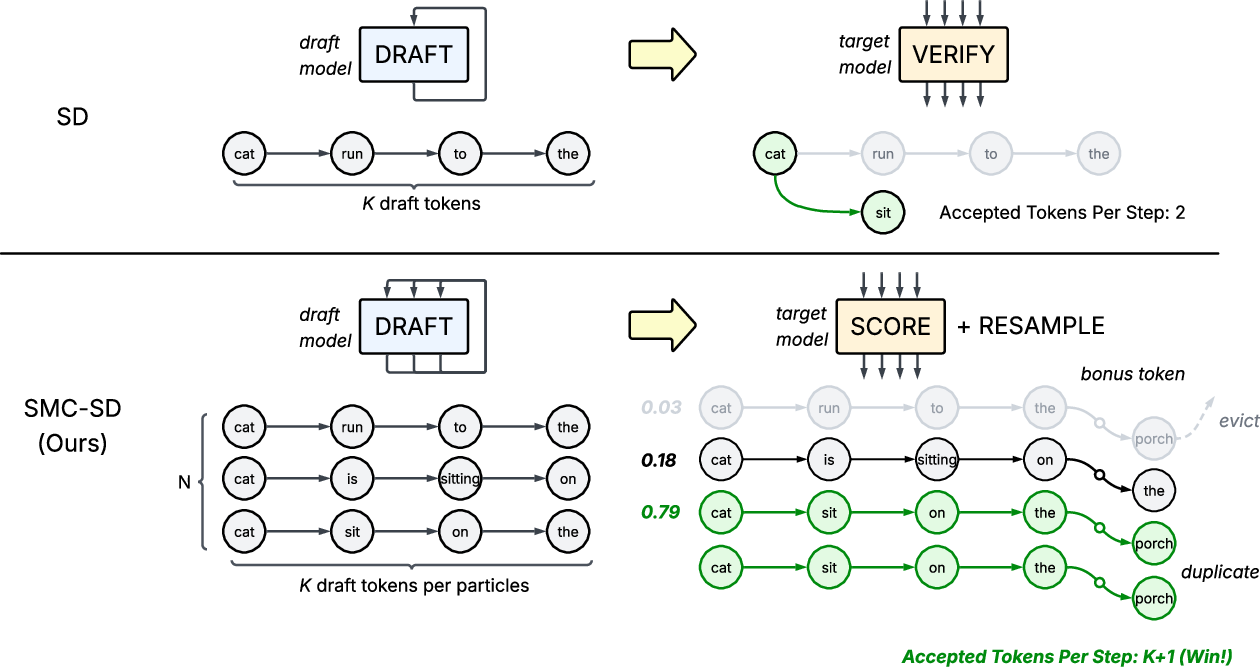
- Speculative decoding (SD): A small, fast model drafts K tokens; the big model checks them all at once. If the big model finds the third token wrong, tokens 3–K are thrown away and the system “rolls back.” This is exact (no approximation), but wastes work whenever draft and target disagree.
Think of it like a writing team: a junior writer drafts a paragraph; the senior editor reads it. If the editor spots a mistake in sentence 3, sentences 3–K get tossed—even if 4–K might’ve been great.
The new idea: SMC‑SD (keeping a “team” of candidates)
- Keep N different candidate continuations (called “particles”) instead of just one draft.
- Each round: 1) The small model extends each of the N candidates by K tokens. 2) The big model scores all these extensions in one go and adds one extra “bonus” token. 3) Each candidate earns a score (a weight). Candidates with higher weights are more likely to be kept; low‑scoring ones are dropped. High‑scoring ones may be duplicated (like “cloning” winners in a tournament) so the group focuses on promising paths.
- Repeat until you’ve generated enough text.
Analogy: Imagine a game show where multiple contestants propose short answers. A judge gives points; the best answers are kept (and even copied), weaker ones exit. Next round starts from the best answers so far. This way, you don’t throw away everything after a single mistake—you shift attention to the best options.
Key differences from standard SD:
- No token‑by‑token rejection chain and no rollback.
- Every round generates exactly K+1 tokens per candidate (K draft + 1 bonus), so the work per round is fixed and easy to batch on GPUs.
Why this runs fast on GPUs (simple view)
GPUs can do huge amounts of math, but LLM decoding often runs into a different bottleneck: moving model weights from memory to the compute units (like waiting on a slow faucet instead of stirring the water). Because of this:
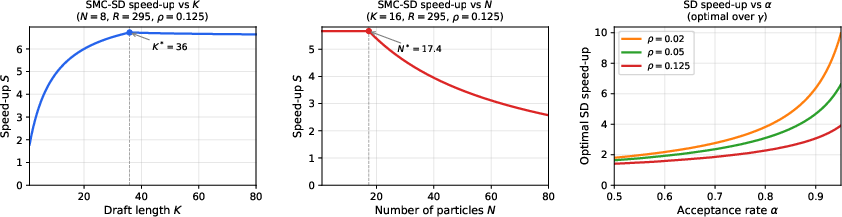
- Scoring many candidates together often costs almost the same as scoring a few—up to a point. So evaluating N candidates “in parallel” is close to free when memory bandwidth is the limiter.
- The authors show that, in the memory‑limited regime, SMC‑SD’s speed‑up grows mainly with K (tokens drafted per round) and barely depends on N (number of candidates). Past a certain point, if you push N too high, you hit a compute limit and gains taper off.
A small safety net for accuracy
SMC‑SD is an approximate method (unlike standard SD, which is exact), but:
- The more candidates N you use, the closer the results get to the big model.
- The authors give mathematical bounds showing the error shrinks as N grows, and that how “different” the small model is from the big model also matters.
- In practice, a modest N already keeps accuracy very close to the target model.
Systems tricks that make it practical
- Vectorized, batched execution: Draft and score many tokens across many candidates at once.
- Smart memory handling: When good candidates are duplicated, the system shares the same stored “prefix” (past context) by reusing pointers instead of copying big memory blocks. This saves time and memory.
What did they find?
Across math, instruction‑following, and coding benchmarks, and on different model families:
- SMC‑SD is fast:
- Up to about 2.5× faster than a strong, optimized speculative decoding (single‑GPU tests).
- About 2.36× faster than speculative decoding and about 5.2× faster than standard one‑token‑at‑a‑time decoding in multi‑GPU tests.
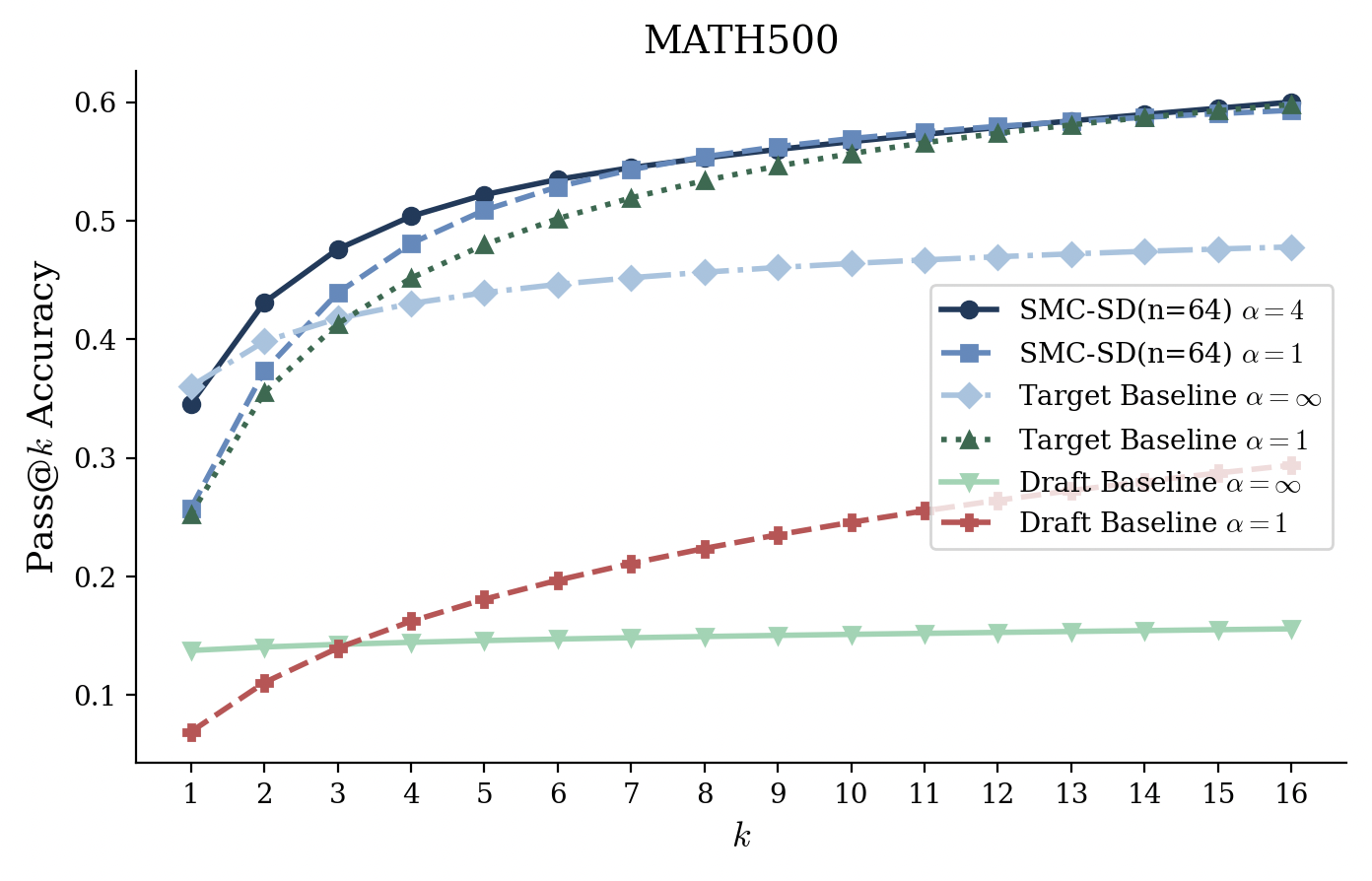
- Accuracy stays high:
- Outputs stay within roughly 3% of the big model’s accuracy on average, even while running much faster.
- Stable, predictable work per step:
- Because SMC‑SD doesn’t rollback on rejection, each round does fixed work (K+1 tokens per candidate), which GPUs handle efficiently.
Why this matters:
- Less wasted work than standard speculative decoding (no discarding long chunks after one mistake).
- Better use of “idle” GPU compute: when memory bandwidth is the limiter, scoring multiple candidates is nearly “free.”
Why does this matter?
- Faster assistants and tools: Chatbots, code helpers, and tutoring systems can respond quicker without a big hit to quality.
- Lower costs at scale: More tokens per second means better throughput on the same hardware.
- A flexible knob: You can trade speed for accuracy by choosing N (how many candidates) and K (how many tokens per round). Need higher fidelity? Increase N. Need more speed? Tune K and N based on your GPU’s sweet spot.
- Solid foundations: Even though it’s approximate, the method comes with error guarantees and shows strong real‑world results.
In short, SMC‑SD changes “draft and reject” into “draft many, score, and keep the best.” That simple shift makes better use of GPUs, cuts wasted work, and delivers big speed‑ups while keeping answers very close to what the large model would produce on its own.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what the paper leaves unresolved—items future work could concretely address.
- End-to-end theory: No bound on the total variation (or other) distance between SMC-SD’s final output distribution and the target across multiple rounds with resampling; current results cover only single-round importance resampling, leaving error accumulation, path degeneracy, and inter-particle correlations across rounds uncharacterized.
- Termination semantics: The paper presents inconsistent descriptions of when tokens are committed (emitted prefix after each round vs. “sampled only at termination”); a precise, provably correct streaming/commitment protocol and its effect on distributional fidelity remains unspecified.
- EOS handling: Lack of a formal treatment of end-of-sequence probabilities under blockwise weighting and resampling (e.g., when and how EOS is emitted, and how EOS biases accumulate across rounds).
- Absolute continuity in practice: Theoretical guarantees assume and finite higher moments of weights, but practical decoding often uses truncation (top-, top-, typical), which can assign zero probability under ; no remedy (e.g., support-repair, soft-truncation, or proposal tempering) is provided.
- Impact of decode-time controls: No analysis or experiments on how temperature, top-, top-, penalties, or logit bias interact with SMC-SD’s weighting and resampling or its guarantees.
- ESS thresholding: No guidance or principled method for choosing the ESS threshold , nor analysis of how resampling frequency affects accuracy, variance, and throughput across tasks.
- Resampling choices: Only multinomial resampling is used; the variance and throughput impact of alternative schemes (systematic, stratified, residual) and of rejuvenation moves (e.g., MCMC or ancestor sampling) are not investigated.
- Adaptive hyperparameters: No algorithm for adaptive control of (particles) and (block length) based on online diagnostics (e.g., ESS, divergence proxies), latency budgets, or hardware utilization to meet a target error/throughput budget.
- Proposal–target divergence: While per-round bounds depend on , there is no empirical characterization of this divergence for real draft–target pairs, nor a diagnostic to detect when divergence becomes too large and to trigger fallback strategies.
- Draft model learning: No exploration of training or fine-tuning the draft model specifically to minimize (or a surrogate) under SMC-SD, or of online adaptation of the proposal to reduce weight variance.
- Long-sequence stability: Weight degeneracy and path collapse over long outputs are not analyzed; the effect of sequence length on accuracy and diversity, and mitigation strategies (e.g., periodic rejuvenation), remain open.
- Bonus token bias: The effect of drawing a single “bonus” token from per particle per round on the overall sampling distribution and bias accumulation is not theoretically analyzed.
- Roofline model limits: The speed-up analysis assumes ideal memory-bandwidth dominance and equates cost ratios with parameter ratios; it does not quantify deviations due to kernel launch overheads, KV-cache management, communication, or non-ideal batching across different GPUs and quantizations.
- Hardware generality: Speed-up predictions are not validated across diverse accelerators (A100, H200, consumer GPUs), quantization formats (INT8/FP8), or TPUs; sensitivity to hardware-specific ridge points is untested.
- Latency metrics: The paper reports throughput but not latency (e.g., time-to-first-token, per-token latency, end-to-end latency) or streaming smoothness—critical for interactive applications.
- Memory scaling: Although pointer-based KV reuse reduces duplication, worst-case memory growth with , , context length, and long outputs is not quantified; limits under large or very long contexts are unclear.
- Multi-tenant scheduling: Interactions with dynamic batching across heterogeneous requests and fairness/quality isolation in shared serving scenarios are not studied.
- Broader evaluation: Benchmarks cover reasoning/coding (GSM8K, MATH500, AlpacaEval, DS1000) but omit long-form generation, multilingual tasks, safety/toxicity, hallucination, and human preference evaluations.
- Baseline coverage: No empirical comparison to recent approximate speculative methods (e.g., FSD, FLy, Judge Decoding) or to tree-based exact methods under matched hardware/throughput targets.
- Failure modes: No systematic analysis of cases with severe draft–target mismatch (domain shift, specialty domains) where SMC-SD may suffer drastic weight degeneracy; no detection/fallback policy is provided.
- Tokenization assumptions: The approach assumes shared tokenizers/vocabularies; strategies for cross-tokenizer draft–target pairs or subword mismatches are not discussed.
- Determinism/reproducibility: The degree of stochastic variability in outputs and throughput across runs (due to resampling randomness) and mechanisms to control it (seeding, variance reduction) are not detailed.
- Integration with constraints: How SMC-SD composes with grammar-guided decoding, constrained beam search, or reward guidance is unexplored, both algorithmically and in terms of guarantees.
- Distributed scaling: Multi-GPU experiments exist but lack details on communication overheads, partitioning strategies, and how SMC-SD interacts with tensor/pipeline parallelism at larger scales.
- Energy efficiency: Speed-up is reported, but tokens-per-watt and energy–accuracy trade-offs are not measured, limiting deployability guidance.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage SMC-SD’s findings, methods, and systems innovations. Each item includes the most relevant sectors and key dependencies that affect feasibility.
Software/AI Infrastructure and Cloud Inference
- Faster, cheaper LLM serving in inference engines
- What: Integrate SMC-SD into serving stacks (e.g., SGLang fork provided; extend to vLLM, TensorRT-LLM) to convert idle GPU compute into throughput, achieving up to ~2.36× over SD and ~5.2× over autoregressive (AR) on tested setups while staying within ~3% accuracy on reasoning/coding tasks.
- Sectors: Software, Cloud/SaaS, AI platforms.
- Tools/workflows: “SMC” decoding mode with tunable (N, K), automatic dynamic batching, page-based KV cache with pointer-based resampling, RadixAttention/PagedAttention.
- Dependencies/assumptions: Availability of a compatible draft–target model pair; GPUs with high memory bandwidth and support for paged KV caches; tolerance for small accuracy deltas; tuning N, K to stay in memory-bound regime for “free” particles.
- Throughput and cost reduction for batch content generation
- What: Use SMC-SD on offline/batch pipelines (e.g., data labeling, synthetic data generation, red teaming corpora, test-set augmentation) to reduce time/cost per token.
- Sectors: Software, Marketing, Data Ops, Safety/Alignment.
- Tools/workflows: Batch schedulers that set (N, K, batch size B) to maximize tokens-per-second (TPS) under the roofline model; ESS telemetry to auto-resample.
- Dependencies/assumptions: Workloads tolerate approximate sampling; access to a stronger draft for better ESS and lower divergence; compute remains memory-bound at chosen batch and particle counts.
- Lower latency for interactive assistants and chatbots
- What: Use SMC-SD to improve perceived responsiveness and reduce token latency in user-facing chats, customer support, and copilots.
- Sectors: Customer service, Productivity tools, Developer tools.
- Tools/workflows: Latency-aware scheduling that increases K when memory-bound; fallback to standard SD/AR if QoS demands exactness; streaming with fixed-round output (K+1 tokens per round, no rollback).
- Dependencies/assumptions: UI-level tolerance for slight quality variability; prompt/task distributions similar to those tested (reasoning, instruction-following, coding).
- Multi-GPU serving with higher per-GPU throughput
- What: Deploy SMC-SD across multi-GPU clusters (e.g., 1B→70B) to increase throughput per GPU at common batch sizes.
- Sectors: Cloud/SaaS, Managed AI services.
- Tools/workflows: Pipeline parallelism plus SMC-SD batch/particle sizing to avoid compute-bound region; telemetry that adjusts N based on ridge point R per hardware.
- Dependencies/assumptions: Efficient cross-GPU KV partitioning; careful placement to keep target verification memory-bound where possible.
- KV cache memory savings and larger effective context
- What: Use pointer-based resampling (page metadata swaps and ref-counts) to reduce KV cache movement and memory footprint, enabling larger batch sizes or longer contexts on the same hardware budget.
- Sectors: Software, Cloud/SaaS, Edge.
- Tools/workflows: Page-based KV buffers (e.g., vLLM-style), deduplicated prefix pages across particles, lowered KV memory up to ~70% in tested configs.
- Dependencies/assumptions: Engine support for paged KV caches and reference counting; shared-prefix exploitation; long-context tasks benefit most.
Enterprise Applications
- Cost-effective coding assistants and IDE integrations
- What: Increase TPS for code completion/refactoring while maintaining accuracy within acceptable bounds for developer workflows.
- Sectors: Software development, DevTools.
- Tools/workflows: “Performance mode” toggle (SMC-SD) vs “exact mode” (AR/SD); per-language and per-file-size (N, K) presets.
- Dependencies/assumptions: Tolerance for small non-determinism; fallback for critical completions requiring exactness.
- Enhanced RAG and multi-step pipelines
- What: Reduce latency in multi-stage pipelines (retrieve → reason → generate) by accelerating the generation steps with SMC-SD, especially with chain-of-thought or tool-use patterns.
- Sectors: Knowledge management, Analytics, Search.
- Tools/workflows: Pipeline controllers that boost draft length K in steps with higher compute-to-bandwidth slack; ESS-based resampling gates to keep quality stable.
- Dependencies/assumptions: Largely bandwidth-bound tokens; RAG stages robust to small output variance.
Academia and Research
- Faster experimental throughput for LLM research
- What: Shorten model evaluation cycles (benchmarks like GSM8K/MATH/AlpacaEval/DS1000) with SMC-SD, enabling more ablations per unit time.
- Sectors: Academia, Corporate research labs.
- Tools/workflows: Benchmark harnesses adding SMC-SD decoding and ESS logging; A/B runs across (N, K) to map speed–accuracy Pareto.
- Dependencies/assumptions: Researchers accept approximate decoding for exploratory experiments; target exact baselines kept for final reporting.
Finance, Healthcare, Education, and Daily Life (with guardrails)
- Higher-capacity internal chat and document assistants
- What: Support more concurrent users or longer documents at similar cost, with small, controlled accuracy deltas.
- Sectors: Finance, Healthcare (non-critical summarization), Education, HR/Legal (drafting).
- Tools/workflows: Admin control to cap N in compute-bound periods; per-tenant tuning to stay within defined accuracy budgets.
- Dependencies/assumptions: Non-safety-critical uses; institutional acceptance of approximate decoding; governance/QA on sensitive tasks.
- Energy and cost efficiency for sustainable AI ops
- What: Reduce wall-clock time, energy per token, and compute bills by increasing arithmetic intensity with SMC-SD in memory-bound regimes.
- Sectors: Green IT, FinOps.
- Tools/workflows: Energy dashboards correlating TPS and power draw; schedules that boost K when servers are in bandwidth-bound windows.
- Dependencies/assumptions: Benefits taper in compute-bound regimes; energy savings depend on workload mix and hardware ridge points.
Long-Term Applications
These applications require further research, scaling, or engineering development before broad deployment.
Methods and Model Co-Design
- Co-trained draft models optimized for SMC-SD
- What: Train drafts to minimize χ² divergence to targets, directly improving ESS, stability, and speed–accuracy trade-offs.
- Sectors: AI model providers, Foundation model labs.
- Tools/workflows: Joint or distillation objectives targeting importance weight stability; automated selection of draft–target pairs per domain.
- Dependencies/assumptions: Access to target internals or high-quality distillation data; compute budget for co-training.
- Adaptive controllers for (N, K) using ESS and ridge-point sensing
- What: Online control loops that adjust particle count and draft length based on observed ESS and hardware-state estimation (memory- vs compute-bound).
- Sectors: Cloud/SaaS, AI platforms.
- Tools/workflows: Runtime telemetry, closed-loop optimizers, service-level objective (SLO)-constrained tuning.
- Dependencies/assumptions: Accurate ESS estimation and stable correlations between ESS, accuracy, and latency across workloads.
- Cross-round error control and certified bounds
- What: Extend per-round bias/MSE bounds to multi-round SMC-SD with resampling, enabling certified service tiers (e.g., “≤X% TV distance”).
- Sectors: Regulated industries, AI assurance.
- Tools/workflows: Statistical auditors; calibration on workload distributions; standardized reporting.
- Dependencies/assumptions: New theory to bound path degeneracy; empirical validation across domains.
Systems and Hardware
- Inference-runtime and compiler support for SMC primitives
- What: Native SMC operators in inference engines (paged KV ref-counting APIs, vectorized resampling kernels) and graph compilers.
- Sectors: Systems software, Accelerators.
- Tools/workflows: vLLM/SGLang/TensorRT-LLM plugins; specialized CUDA kernels for weighted resampling and block weight computation.
- Dependencies/assumptions: Engine adoption; cross-vendor GPU support.
- Hardware co-design for SMC-heavy decoding
- What: Architect accelerator features (e.g., on-die KV paging, fast categorical sampling, blockwise scoring) to push ridge points and keep workloads memory-bound longer.
- Sectors: Semiconductor, Cloud.
- Tools/workflows: Roofline-guided microarchitectural tuning; simulator-based design space exploration.
- Dependencies/assumptions: Long hardware lead times; coordinated software–hardware roadmaps.
New Product Patterns
- Edge–cloud cascades (on-device draft, cloud target)
- What: Run the draft locally (phone/edge) and do periodic batched target verification in the cloud with SMC-style resampling to reduce round-trips and bandwidth.
- Sectors: Mobile, IoT, Consumer apps.
- Tools/workflows: Opportunistic K expansion when connectivity is strong; privacy-preserving partial decoding.
- Dependencies/assumptions: Stable connectivity for bonus/verification; acceptable privacy posture for token-level metadata.
- “Approximation knob” in LLM APIs
- What: Offer API tiers that expose an “accuracy vs speed” parameter mapped to (N, K), with telemetry on expected quality deltas.
- Sectors: LLM-as-a-service, Platforms.
- Tools/workflows: SLAs that bound quality loss; usage-based pricing that reflects efficiency gains.
- Dependencies/assumptions: Customer education on approximate decoding; monitoring for drift when prompts shift.
- Hybrid decoders combining SMC-SD with tree decoding
- What: Use SMC resampling across branches in Medusa/Eagle-style trees to capture more accepted tokens while amortizing compute.
- Sectors: AI platforms, Research.
- Tools/workflows: Tree-of-blocks verification; priority-based resampling on branch weights.
- Dependencies/assumptions: More complex KV and scheduler logic; careful empirical validation.
Domain Extensions
- Multimodal and speech models
- What: Apply SMC-SD to multimodal LLMs (text+vision/audio) where verification passes remain bandwidth-bound and benefit from batched block scoring.
- Sectors: Media, Accessibility, AR/VR.
- Tools/workflows: Modality-aware block weighting; caching for cross-attention KV.
- Dependencies/assumptions: Draft–target availability across modalities; consistent divergence properties.
- Real-time robotics and planning
- What: Use SMC-SD to produce fixed-rate token blocks for planners and policies needing deterministic control cycles (K+1 tokens per round).
- Sectors: Robotics, Autonomous systems.
- Tools/workflows: Controllers that align control cycle with decoder rounds; safety filters downstream.
- Dependencies/assumptions: Safety-critical acceptance requires strong guarantees; often needs bounded approximation error and fallback modes.
- Privacy-preserving or federated SMC pipelines
- What: Particles drafted locally with only compressed importance signals/bonus tokens shared, reducing raw text exposure.
- Sectors: Healthcare (PHI), Finance (PII), Government.
- Tools/workflows: Secure aggregation of weights; TEEs for target verification.
- Dependencies/assumptions: Protocol design to avoid leakage via weights; legal approval.
Policy and Governance
- Standards and audits for approximate decoding
- What: Create evaluation protocols that specify acceptable total-variation or task-specific performance gaps for approximate decoders.
- Sectors: Policy, Standards bodies, Enterprise governance.
- Tools/workflows: Disclosure templates for speed–accuracy trade-offs; carbon and cost reporting linked to decoding modes.
- Dependencies/assumptions: Consensus on metrics; alignment with regulatory requirements in sensitive sectors.
- Sustainability incentives and procurement guidelines
- What: Encourage adoption of decoding modes that reduce energy/cost per token (when within quality thresholds), informed by roofline analysis.
- Sectors: Public sector, Large enterprises.
- Tools/workflows: Green AI procurement criteria; runtime policies that prefer memory-bound operating points.
- Dependencies/assumptions: Transparent measurement and third-party verification of energy savings.
Notes across applications:
- Tasks with strict exactness requirements (e.g., clinical decision support, legal reasoning for binding outputs) may require AR/SD baselines or strong certified bounds before adopting SMC-SD.
- Benefits are largest when the verification pass is memory bandwidth-bound; in compute-bound regimes, increasing particles (N) can hurt speed—controllers should adapt N and K accordingly.
- Approximation quality improves with more particles and better draft–target alignment (lower χ² divergence); draft quality and quantization levels materially affect outcomes.
Glossary
- Absolutely continuous: A relationship between distributions where one assigns zero probability only where the other does; written p ≪ q. Example: "we say that a LLM is #1{absolutely continuous} with respect to a second LLM , written "
- Arithmetic intensity: FLOPs performed per byte of memory moved; indicates whether a workload is memory- or compute-bound. Example: "its arithmetic intensity, or the floating-point operations (FLOPs) used per byte of memory loaded for the workload"
- Autoregressive decoding: Token-by-token generation where each token depends on previous context. Example: "Autoregressive decoding is heavily memory bandwidth-bound"
- Autoregressive factorization: Expressing a sequence probability as a product of conditional token probabilities. Example: "Every LLM admits an #1{autoregressive factorization}:"
- Chi-squared divergence (χ²-divergence): A measure of discrepancy between two distributions used in importance sampling error bounds. Example: "with constants governed by the -divergence between draft and target model"
- Compute-bound: A regime where throughput is limited by available compute, not memory bandwidth. Example: "the target pass becomes compute-bound."
- Draft model: A smaller, cheaper model used to propose token blocks before verification by a larger model. Example: "a smaller, faster-to-evaluate #1{draft model} "
- Dynamic batching: Grouping variable requests into larger batches at runtime to improve hardware utilization. Example: "The draft model uses dynamic batching to concurrently generate tokens at a time in lockstep"
- Effective sample size (ESS): A measure of how many weighted particles effectively contribute in SMC. Example: "The #1{effective sample size} (ESS) \citep{huggins2014information} quantifies how many particles contribute meaningfully:"
- Importance resampling distribution: The empirical distribution obtained by resampling particles according to importance weights. Example: "Let $denote this #1{importance resampling distribution}:" - **Importance sampling**: A technique to estimate expectations under a target distribution using samples from a proposal with weighted corrections. Example: "since SMC-SD is based on importance sampling, bounds on its divergence from a target distribution can be obtained" - **Importance-weighted resampling**: Replacing hard accept/reject with weighted duplication/pruning of proposals based on importance weights. Example: "which replaces token-level rejection with importance-weighted resampling" - **KV cache**: Cached key–value tensors storing past attention states to speed up incremental decoding. Example: "For KV cache management, we observe that all KV cache data movement during the resampling step can be replaced with efficient in-place pointer exchanges" - **KV-cache rollback**: Discarding previously cached attention states due to a rejected token sequence. Example: "truncates the draft and triggers a KV-cache rollback" - **Mean squared error (MSE)**: The expected squared difference between an estimator and the true quantity; decomposes into bias and variance. Example: "The #1{mean squared error} combines both sources of error and decomposes via the bias--variance identity:" - **Memory bandwidth-bound**: A regime where throughput is limited by memory bandwidth rather than compute. Example: "Because LLM inference is memory bandwidth-bound" - **Non-asymptotic bounds**: Finite-sample guarantees on approximation error, not relying on limits as sample size goes to infinity. Example: "non-asymptotic bounds on its approximation error can be obtained" - **PagedAttention**: A page-based KV-cache management technique for efficient memory usage in attention. Example: "dynamic batching, PagedAttention, and RadixAttention" - **Pareto frontier**: The set of configurations where no other configuration is strictly better in both speed and accuracy. Example: "We characterize the speed--accuracy Pareto frontier of SMC-SD" - **Path degeneracy**: In SMC, the collapse of many particle ancestries to a few paths after repeated resampling. Example: "path degeneracy may accumulate across rounds" - **Prefix probability**: The probability mass of all sequences that begin with a given prefix. Example: "we define the #1{prefix probability} of a string $\srcStr$" - **RadixAttention**: An attention optimization that exploits shared prefixes to reduce computation. Example: "dynamic batching, PagedAttention, and RadixAttention" - **Rejection sampling**: A method to sample from a target distribution by accepting or rejecting proposals with a certain probability. Example: "Speculative decoding \citep{leviathan2023fast, chen2023accelerating} accelerates autoregressive inference by applying #1{rejection sampling} at the token level." - **Re-prefill step**: Recomputing attention states in a batched manner to score a block of tokens efficiently. Example: "using a single re-prefill step." - **Residual distribution**: The conditional distribution over alternatives after removing the accepted mass of a rejected proposal. Example: "the token is resampled from the residual distribution and all subsequent draft tokens are discarded" - **Ridge point**: The hardware-specific arithmetic-intensity threshold separating memory-bound and compute-bound regimes. Example: "the ridge point of the hardware, or its peak FLOPs per memory bandwidth." - **Roofline model**: A performance model relating achievable FLOPs to arithmetic intensity and hardware limits. Example: "We analyze SMC-SD TPS under the roofline model" - **Sequential Monte Carlo (SMC)**: A family of particle methods that iteratively sample, weight, and resample to approximate distributions over sequences. Example: "Sequential Monte Carlo \citep{doucet2001sequential, del2006sequential, naesseth2024elementssequentialmontecarlo} runs a population of particles" - **Sequential Monte Carlo speculative decoding (SMC-SD)**: The proposed method that uses SMC with a draft model to accelerate LLM inference. Example: "we introduce sequential Monte Carlo speculative decoding (SMC-SD)" - **Speculative decoding (SD)**: An exact acceleration method that drafts tokens with a small model and verifies them with a large model via rejection sampling. Example: "Speculative decoding \citep[SD;][]{leviathan2023fast} addresses this bottleneck" - **Target model**: The larger, more accurate model whose distribution the sampler aims to match. Example: "We consider a #1{target model} " - **Tokens-per-second (TPS)**: A throughput metric for generation speed. Example: "We analyze SMC-SD TPS under the roofline model" - **Total variation distance**: A measure of discrepancy between two distributions, equal to the L1 distance of their probabilities. Example: "controlling the total variation distance between the SMC-SD outputp$"</li> <li><strong>Weight degeneracy</strong>: In SMC, when a single particle carries almost all the weight, reducing diversity. Example: "when $ESS1$ (#1{weight degeneracy}), a single particle dominates."
Collections
Sign up for free to add this paper to one or more collections.