TiDAR: Think in Diffusion, Talk in Autoregression
Abstract: Diffusion LLMs hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a fundamental question: can we achieve a synergy with high throughput, higher GPU utilization, and AR level quality? Existing methods fail to effectively balance these two aspects, either prioritizing AR using a weaker model for sequential drafting (speculative decoding), leading to lower drafting efficiency, or using some form of left-to-right (AR-like) decoding logic for diffusion, which still suffers from quality degradation and forfeits its potential parallelizability. We introduce TiDAR, a sequence-level hybrid architecture that drafts tokens (Thinking) in Diffusion and samples final outputs (Talking) AutoRegressively - all within a single forward pass using specially designed structured attention masks. This design exploits the free GPU compute density, achieving a strong balance between drafting and verification capacity. Moreover, TiDAR is designed to be serving-friendly (low overhead) as a standalone model. We extensively evaluate TiDAR against AR models, speculative decoding, and diffusion variants across generative and likelihood tasks at 1.5B and 8B scales. Thanks to the parallel drafting and sampling as well as exact KV cache support, TiDAR outperforms speculative decoding in measured throughput and surpasses diffusion models like Dream and Llada in both efficiency and quality. Most notably, TiDAR is the first architecture to close the quality gap with AR models while delivering 4.71x to 5.91x more tokens per second.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way for AI LLMs to generate text called TiDAR (Think in Diffusion, Talk in Autoregression). It combines two different styles of thinking:
- Diffusion (think in parallel): quickly drafts several possible next words at once.
- Autoregression (talk step-by-step): carefully checks and finalizes the best next word one at a time.
By blending these two, TiDAR aims to be both fast and high-quality—like a person who brainstorms multiple ideas quickly, then picks the best one carefully.
Objectives: What questions does the paper try to answer?
The paper asks:
- Can we make LLMs generate text much faster without losing quality?
- Can we use GPUs (powerful computer chips) more efficiently during text generation?
- Can we get the best of both worlds: the speed of diffusion models and the quality of autoregressive (AR) models?
Methods: How does TiDAR work?
Think of text generation like building a sentence word-by-word.
- Autoregressive (AR) models: add one word at a time, always checking the previous words. This is careful and usually high-quality, but slow.
- Diffusion models: guess several words at once by filling in blanks. This is fast, but sometimes less accurate.
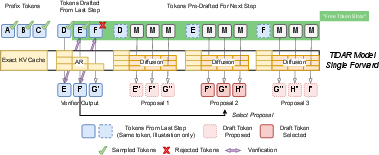
TiDAR mixes them inside one model and one “forward pass” (one trip through the network):
- Three parts of the sequence:
- Prefix (what’s already written).
- Last step’s draft (words the model proposed previously).
- Next step’s pre-draft (future words it prepares in advance).
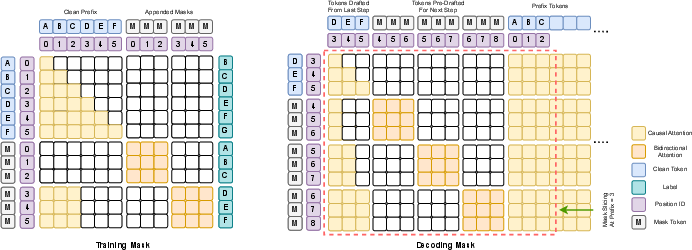
- Special attention masks (who can “see” whom):
- Causal attention for the prefix (left-to-right, like AR).
- Bidirectional attention for the draft/pre-draft block (words can see each other, like diffusion).
- Parallel “Think” + Careful “Talk” in one go:
- The model pre-drafts multiple possible next words in parallel (diffusion = “think” fast).
- At the same time, it checks and approves the drafted words using the careful AR method (autoregression = “talk” clearly).
- It uses a method called rejection sampling: if a drafted word doesn’t match the careful AR check, it gets rejected; otherwise, it’s accepted.
- “Free token slots” (a systems trick):
- When the GPU loads the model for one step, adding a few extra positions (extra drafted words) often costs almost no extra time—like carrying more items in the same car trip.
- TiDAR packs drafting and checking into the same trip to save time.
- Training setup (teaching the model both styles):
- The model is trained to do both AR and diffusion at once using a hybrid attention mask.
- In training, the diffusion part uses full masks (all tokens are treated as “blanks”) so the model learns to fill in missing words efficiently in a single step.
- This allows one-step diffusion at inference, which is faster and simpler.
- Memory efficiency with KV cache:
- KV cache is like notes the model keeps about previous context to avoid rethinking everything.
- TiDAR supports exact caching (like AR), reuses it for accepted words, and discards only the parts it doesn’t need—avoiding wasted work.
Findings: What did the experiments show, and why does it matter?
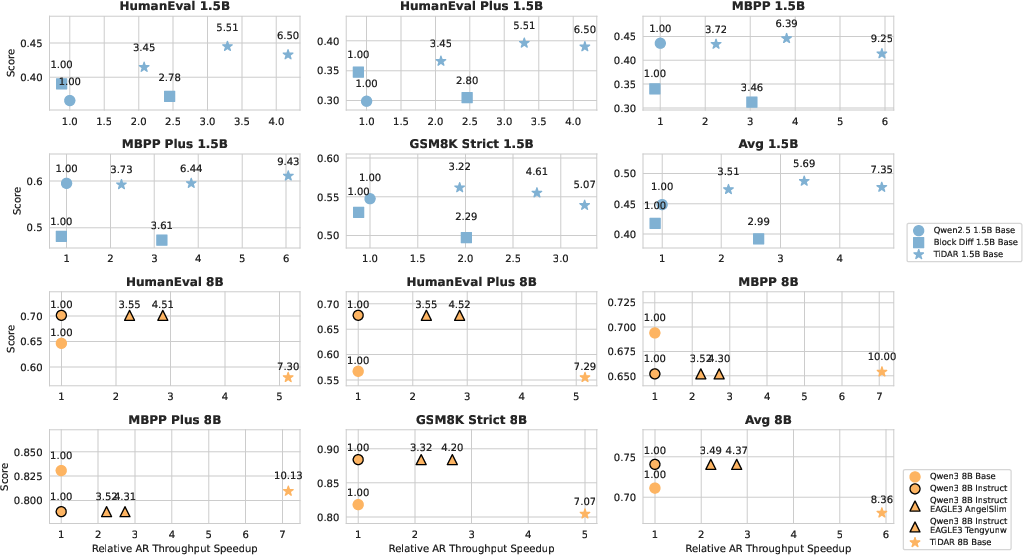
- Speed: TiDAR generated 4.71× to 5.91× more tokens per second than strong AR models of similar size (at 1.5B and 8B parameters).
- Quality: It reached the same or nearly the same quality as AR models on coding, math, and reasoning tasks—and beat leading diffusion models like Dream and Llada in both speed and quality.
- Efficiency: It outperformed advanced speculative decoding systems (like EAGLE-3) in throughput, thanks to doing drafting and verification in parallel within a single forward pass.
- Likelihood evaluation: Unlike many diffusion models, TiDAR can evaluate “likelihood” (a standard scoring method) just like AR models—making it easier to compare fairly and quickly.
Why this matters:
- You get AR-level quality but with diffusion-level speed.
- It works in a serving-friendly way (low overhead), which is good for real-world apps.
- It uses GPU time more effectively, which reduces costs and can lower response times.
Impact: What could this mean for the future?
- Faster, better AI assistants: Chatbots, coding helpers, and math solvers can respond much quicker without sacrificing correctness.
- Lower latency and cost: Companies can serve more users with the same hardware—and users get snappier responses.
- Better model design: TiDAR shows that mixing different generation styles inside one model can break old trade-offs (speed vs. quality).
- Easier evaluation: Because TiDAR supports AR-style likelihood, it fits smoothly into existing benchmarks and tooling.
In short, TiDAR is like a smart teammate who quickly brainstorms many ideas and then speaks only the best ones—doing both the thinking and talking at the same time. This makes AI faster and just as reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved gaps, limitations, and open questions that future work could address:
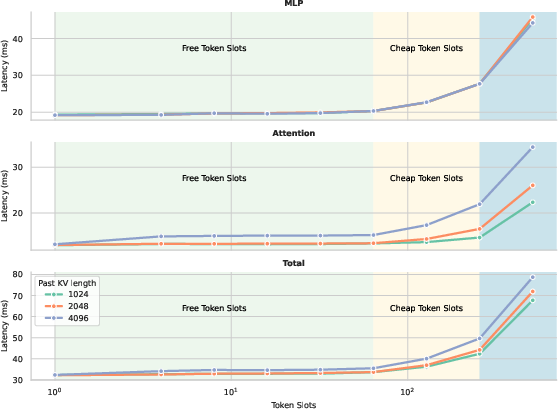
- Hardware- and workload-dependent “free token slots”: The paper shows one profile (H100, batch=1) where extra token slots are “free” before hitting the compute-bound regime. Systematically map the latency/throughput regimes across model sizes, batch sizes, sequence lengths, kernels, and hardware (A100/H100/consumer GPUs) to derive actionable guidance for choosing draft length per deployment setting.
- Memory footprint and KV cache pressure: Quantify end-to-end memory usage when caching causal tokens for all drafted positions and then evicting rejected tokens, especially for large models, long contexts, and large draft lengths. Characterize fragmentation, paging behavior (e.g., with PagedAttention), and OOM risk under concurrent requests.
- Complexity of pre-drafting “all possible acceptance outcomes”: Provide a rigorous analysis of the computational and memory cost of conditioning pre-drafts on every possible acceptance prefix for draft length k. Clarify how the method scales beyond k≈16, and whether approximate schemes (e.g., lattice pruning, prefix sampling, or partial conditioning) can retain quality while controlling cost.
- One-step diffusion optimality: The paper adopts one-step diffusion with fully masked tokens during training. Evaluate multi-step diffusion variants (e.g., 2–4 steps) to quantify the quality–throughput–acceptance trade-offs and identify regimes where extra steps yield net gains.
- Formal acceptance criterion and sampling under temperature/top-p: Specify and evaluate the exact verification rule (e.g., exact-match argmax vs. acceptance probability per speculative decoding theory) under common sampling settings (temperature, top-p). Measure effects on diversity, calibration, and acceptance rates.
- Calibration and logit mixing: The method mixes AR and diffusion logits via a fixed β. Investigate per-token or adaptive β schedules, calibration differences between heads, and whether temperature scaling or calibration losses reduce mismatch and improve acceptance/quality.
- Dynamic draft length and entropy-aware control: Develop policies that adapt draft length at runtime based on entropy/uncertainty, prefix length, or nearing EOS, to maintain quality while maximizing throughput as conditions change.
- Tail-latency and worst-case behavior: Report distributional metrics (p95/p99 latency) and worst-case acceptance/Tokens-per-NFE on heterogeneous prompts. Analyze long-tail failures (e.g., high-entropy spans) and propose mitigation strategies (e.g., dynamic fallback to AR).
- Long-context generalization: The max length used is 4k. Evaluate scalability and stability at 8k–128k contexts (including sliding-window KV, chunked attention) and quantify how the “free slot” assumption and cache strategy behave at long context lengths.
- Instruction tuning and RLHF/SFT: Most results use base models. Assess how the dual-mode objective interacts with instruction tuning, RLHF, and preference optimization, including any impact on helpfulness, safety, and controllability.
- Constrained and structured decoding: Explore compatibility with grammar-constrained decoding, JSON schemas, and function calling. Determine how AR rejection and diffusion drafting can enforce constraints without negating speedups.
- Fair apples-to-apples baselines: Some comparisons use different training budgets or model variants (e.g., EAGLE-3 on an instruct base). Reproduce baselines with identical data, training tokens, and decoding settings to isolate architectural effects.
- Multilingual and domain robustness: Extend evaluation beyond English coding/math/MCQ to multilingual, code-mixed, biomedical, and legal domains to test generality of quality–throughput gains.
- Energy efficiency and cost per generated token: Report wall-clock energy consumption/TFLOPs per token and GPU-utilization metrics to substantiate “serving-friendly” claims beyond tokens/sec.
- Quantization and low-precision serving: Test INT8/INT4/AWQ/GPTQ quantization and KV-quantization compatibility with the hybrid masks and dual-mode heads; quantify accuracy/speed trade-offs post-quantization.
- Batching and multi-request serving: The main benchmarks use batch=1. Analyze throughput scaling under realistic server load, request multiplexing, batching policies, and scheduler interactions (e.g., paged KV, chunked prefill).
- Theoretical grounding and guarantees: Provide formal connections to speculative decoding acceptance bounds, analyze when diffusion–AR logits converge, and characterize error introduced by intra-step independence assumptions and one-step diffusion.
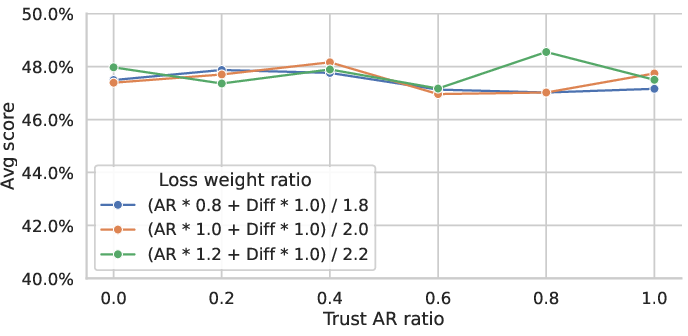
- Loss balancing and training stability: The paper typically uses α=1. Systematically study α schedules, curriculum masking (partial vs. full), and optimization stability (e.g., gradient interference between AR and diffusion losses) across scales.
- Training efficiency: Quantify the extra FLOPs, memory, and wall-clock due to doubled sequence length and dual-mode losses, and explore efficiency optimizations (e.g., shared heads, weight tying, partial teacher-forcing).
- Block size transferability: The model is trained with fixed block sizes (4/8/16). Investigate training once and decoding with variable block sizes; analyze robustness of acceptance rates and quality when block size at inference differs from training.
- EOS handling and late-stage efficiency: Study behavior near EOS where many drafted slots go unused; propose mechanisms (e.g., early-shrink, draft-aware stopping) to avoid wasted “free slots.”
- Failure analyses and safety: Provide qualitative error analyses (e.g., hallucinations, logical inconsistencies due to intra-step independence) and evaluate toxicity/bias to understand safety implications of hybrid decoding.
- From continual pretraining to from-scratch scaling: Results focus on continual pretraining on Qwen bases. Examine from-scratch training and scaling laws (data vs. compute) to assess whether the hybrid architecture has different data efficiency than pure AR.
- Compatibility with beam search and reranking: Explore integration with beam or tree-based decoding and learned rerankers while preserving one-pass parallelism benefits.
- Open-source reproducibility: The paper relies on modified Megatron-LM/Torchtitan internals. Releasing code, masks, and trained weights would enable independent verification and further research on mask design and kernels.
Glossary
- APD: A diffusion-based acceleration approach that studies parallel decoding trade-offs. "As reported in APD~\cite{israel2025apd}, there is a clear trend of declining generation quality with increasing number of tokens to generate in parallel per step."
- Autoregressive (AR) models: Sequence models that generate one token at a time conditioned on previous tokens. "Although autoregressive models~\cite{vaswani2017attention,radford2019language} are the prevailing approach"
- Autoregressive rejection sampling: Validating drafted tokens by comparing them against the AR distribution and accepting only matches. "Tokens proposed from the last step are autoregressively sampled via rejection sampling guided by computed at current step."
- BFloat16 (BF16) precision: A 16-bit floating-point format optimized for deep learning training/inference. "Both training and inference are conducted in the standard BFloat 16 precision."
- Block Diffusion: A semi-autoregressive diffusion model that denoises tokens within blocks while maintaining autoregression across blocks. "Block Diffusion (also known as semi-autoregressive models)~\cite{arriola2025blockdiffusion} attempts to address this issue by interpolating between discrete diffusion and autoregressive models."
- Block-causal attention: An attention pattern that is bidirectional within a block and causal across blocks. "mask tokens block-causally (bidirectional within each block) for one-step diffusion pre-drafting."
- Block parallel decoding: Decoding multiple tokens in parallel within blocks to accelerate diffusion generation. "Fast-dLLM~\cite{wu2025fastdllmtrainingfreeaccelerationdiffusion,wu2025fastdllmv2efficientblockdiffusion} proposes to perform block parallel decoding with the prefix and optionally the suffix being cached"
- Causal attention: Attention restricted to past tokens to enforce left-to-right generation. "clean input tokens are self-attended causally and mask tokens within-block bidirectionally"
- Chain-factorized joint distribution: The AR factorization of the joint probability into a product over conditional next-token distributions. "AR models sample from a chain-factorized joint distribution:"
- Compute-bound regime: A regime where runtime is dominated by computation rather than memory or I/O. "Latency stays relatively the same with a certain amount of tokens sent to forward (free + cheap token slots), before transitioning to the compute-bound regime."
- Compute density: The amount of useful computation achieved per unit of loaded model state; higher density improves throughput. "This design exploits the free GPU compute density"
- Cosine scheduling: A learning-rate schedule that follows a cosine curve from max to min LR. "We adopt the cosine scheduling with and a warm-up step fraction of ."
- Cross-entropy loss: A standard classification loss used for both AR and diffusion token predictions. "and are cross-entropy losses with logits calculated at clean and masked sequences"
- d-KV cache: A selective caching strategy for diffusion models that delays and chooses which tokens to cache to balance quality and efficiency. "d-KV cache~\cite{ma2025dkvcachecachediffusionlanguage}, on the other hand, takes a more dynamic route by selectively cache certain tokens step by step in a delayed fashion"
- Diffusion LLMs (dLMs): Generative models that iteratively denoise masked or noisy tokens and can decode multiple tokens in parallel. "Diffusion LLMs~\cite{austin2021structured,li2022diffusion,nie2025large, ye2025dream, arriola2025blockdiffusion,sahoo2024simpleeffectivemaskeddiffusion} (dLMs) offer a promising alternative to purely sequential generation"
- Distributed Adam: A distributed variant of the Adam optimizer for large-scale training. "with distributed Adam~\cite{kingma2017adammethodstochasticoptimization} optimizer"
- Distributed Data Parallel (DDP): A training paradigm that splits data across devices and synchronizes gradients. "with a global batch size of 2M tokens (DDP)"
- E2D2: An encoder–decoder diffusion architecture that separates clean-token processing from noisy token decoding. "E2D2 ~\cite{arriola2025encoderdecoderdiffusionlanguagemodels} adopts an encoder-decoder architecture"
- EDLM: A diffusion approach using residual energy-based modeling to align training and sampling distributions. "EDLM ~\cite{xu2025energybaseddiffusionlanguagemodels} introduces residual energy-based approach to reduce mismatch between training and sampling distributions"
- Entropy-based sampling: A decoding strategy that uses token entropy/confidence to choose how many tokens to decode per step. "for Dream-7B with the entropy-base sampling strategy~\cite{ye2025dream}"
- Fast-dLLM: A system-level optimization for diffusion LLMs enabling efficient block-level caching and parallel decoding. "Fast-dLLM~\cite{wu2025fastdllmtrainingfreeaccelerationdiffusion,wu2025fastdllmv2efficientblockdiffusion} proposes to perform block parallel decoding"
- Flash Attention 2: A high-performance attention kernel improving memory efficiency and speed. "Flash Attention 2~\cite{dao2023flashattention2fasterattentionbetter}"
- Flex Attention: A flexible attention implementation enabling reusable, pre-initialized masks for efficiency. "without recomputing it for Flex Attention~\cite{dong2024flex}"
- Free token slots: Extra token positions carried through a forward pass that add little or no latency in memory-bound regimes. "We refer to the extra token slots as free token slots"
- Gradient checkpointing: A memory-saving technique that recomputes activations during backward pass. "and we turn on gradient checkpointing for the 8B model."
- Hybrid attention mask: A training mask combining causal attention for clean tokens and bidirectional attention for masked tokens. "as it employs a structured causalâbidirectional hybrid attention mask over the input sequence"
- Intra-step token independence assumption: The assumption that tokens decoded in parallel within a step are independent, which can hurt sequence quality. "which introduces an intra-step token independence assumption~\cite{wu2025fastdllmv2efficientblockdiffusion}"
- KV cache: Cached key–value attention states reused across decoding steps to avoid recomputation. "Decoding in AR models is memory-bound because the latency is dominated by loading the model weights and KV cache rather than compute"
- Label leakage: Unintended access to future token labels due to bidirectional attention, invalidating certain losses. "because of the label leakage issue of intra-block bidirectional attention."
- Label shifts: Shifting labels for next-token prediction targets; diffusion often avoids this during masked training. "due to no label shifts"
- Likelihood evaluation: Assessing model performance via probability of correct answers, often challenging for diffusion models. "Evaluating model performance based on likelihood for traditional diffusion LLMs (e.g. LLaDA, Dream, MDLM) has been very challenging"
- Marginal distribution: The token-wise distribution used by diffusion to propose multiple tokens in parallel. "from the marginal distribution via diffusion"
- Megatron-LM: A large-scale transformer training framework used for multi-billion parameter models. "The overall training framework is a modified Megatron-LM~\cite{shoeybi2020megatronlmtrainingmultibillionparameter}"
- Memory-bound decoding: A regime where decoding speed is limited by memory I/O rather than compute throughput. "Decoding in AR models is memory-bound because the latency is dominated by loading the model weights and KV cache rather than compute"
- Monte Carlo (MC) sampling: Stochastic sampling technique used to estimate diffusion likelihoods over masked positions. "which are averaged over Monte Carlo sample budgets."
- Multi-Token Prediction (MTP): Techniques that predict multiple future tokens at once using additional heads/layers. "DeepSeek-V3 Multi-Token Prediction (MTP)~\cite{liu2024deepseekv3} use additional autoregressive layers"
- Network Function Evaluation (NFE): A single forward pass of the model used to quantify tokens generated per pass. "a single model forward (or network function evaluation, NFE for short)"
- Next-token prediction (NTP) loss: The standard AR training objective of predicting the next token given past context. "compute next token prediction (NTP) loss on the prefix becomes possible"
- One-step diffusion: Drafting tokens with a single denoising step to maximize parallel efficiency. "We adopt a one-step diffusion drafting~\cite{liu2025sequential}."
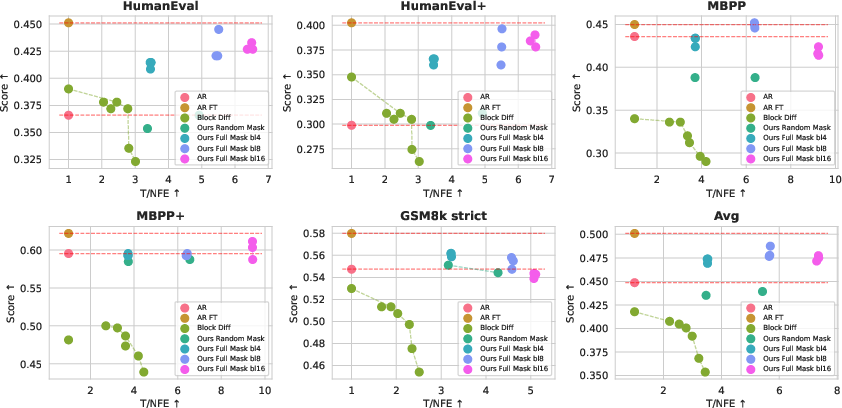
- Pareto frontier: The trade-off curve showing optimal combinations of quality and efficiency across methods. "Our model achieves the best Pareto Frontier compared to Block Diffusion and AR"
- Rejection sampling: A validation mechanism that accepts drafted tokens only if they match the target distribution. "a modified rejection sampling strategy~\cite{leviathan2023fast}"
- Semi-autoregressive models: Models that combine autoregressive dependencies across blocks with parallel decoding within blocks. "Block Diffusion (also known as semi-autoregressive models)"
- Set Block Decoding (SBD): A diffusion-related scheme that doubles sequence length and applies block-wise bidirectional attention. "Set Block Decoding (SBD)~\cite{gat2025set}"
- Speculative decoding: A two-stage acceleration method that drafts with a fast model and verifies with a base model. "speculative decoding~\cite{chen2023accelerating}"
- Structured attention mask: Carefully designed attention masks that enforce different patterns for drafting and sampling. "using specially designed structured attention masks."
- Throughput: The rate of token generation, often measured in tokens per second. "relative decoding throughput speedup measured in tokens per second"
- Torchtitan: A PyTorch-native tooling stack for large-model training support. "with Torchtitan~\cite{liang2025torchtitanonestoppytorchnative} support."
- Uniform suffix masking: A training-time masking strategy that masks future tokens uniformly to align diffusion with AR order. "change the masking strategy to uniform suffix masking during training."
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now using the paper’s TiDAR architecture and training/inference recipes.
- High-throughput LLM serving for chat and agentic automation (software, enterprise, finance, e-commerce)
- Product/workflow: Replace or augment standard AR decoders with TiDAR to “draft in diffusion, sample in AR” in one forward pass; integrate structured attention masks, exact KV-cache reuse, and mask slicing into existing inference stacks.
- Benefits: 4.7×–5.9× tokens/sec throughput vs AR with comparable quality, lower cost per conversation, better SLA adherence at small batch sizes.
- Assumptions/dependencies: GPUs operating in the memory-bound regime (e.g., H100-class), support for custom attention masks (e.g., Flex Attention), exact KV-cache management, acceptance that outputs may not exactly match a baseline AR model (unlike speculative decoding guarantees).
- IDE code completion and code assistant backends (software development)
- Product/workflow: TiDAR-powered autocompletion engine in IDEs (e.g., VS Code plugins), pair-programming assistants, unit test generation; AR rejection sampling keeps syntax and coherence while diffusion drafting accelerates token flow.
- Benefits: Snappier completions with near-AR quality; improved developer productivity in coding, test scaffolding, and code refactoring.
- Assumptions/dependencies: Availability of 1.5B–8B TiDAR models; integration with model servers that support structured masks and KV-cache reuse; domain-adapted finetuning for target languages/stacks.
- RAG summarization and document automation (knowledge management, legal, finance)
- Product/workflow: Use TiDAR in the answer-generation stage of RAG pipelines to reduce latency for long-form summaries, compliance check narratives, or executive briefs; AR mode enables standard likelihood scoring.
- Benefits: Faster end-to-end latency in RAG systems; improved throughput without compromising factuality tasks measured via likelihood.
- Assumptions/dependencies: Stable retrieval layers, long-context inference support, and robust prompt templates; slight quality difference vs pure AR must be acceptable.
- Real-time multilingual captioning and translation (education, accessibility, media)
- Product/workflow: Streaming translation/caption services deploy TiDAR to reduce token delay while preserving coherence via AR sampling.
- Benefits: More responsive captions/subtitles; better user experience in live broadcasts and accessibility tooling.
- Assumptions/dependencies: Reliable streaming I/O; domain-adapted models for target languages; GPUs at the edge or low-latency cloud nodes.
- Interactive math/coding tutoring systems (education)
- Product/workflow: LLM tutors for step-by-step reasoning in math/coding tasks leverage TiDAR’s acceptance rates and AR sampling quality; faster feedback enhances engagement.
- Benefits: Near-AR correctness with faster turn-around times; improved student interactivity.
- Assumptions/dependencies: Appropriate content filtering and pedagogy alignment; task-specific evaluation ensures minimal performance regressions.
- Content moderation and compliance triage (policy/compliance, platform safety)
- Product/workflow: TiDAR accelerates generation of moderation rationales, incident summaries, and triage notes; AR likelihood scoring streamlines multiple-choice safety checks.
- Benefits: Lower moderation backlog; faster audit narratives with comparable quality.
- Assumptions/dependencies: Fairness auditing and alignment datasets; acceptance of small behavioral deviations vs a baseline AR.
- NPC dialog generation and live game narrative services (gaming)
- Product/workflow: Use TiDAR in live dialogue generation services to reduce per-turn latency and cost for online games.
- Benefits: Faster, more scalable NPC interactions; better player experience under load.
- Assumptions/dependencies: Server infrastructure with mask support and KV-cache management; acceptance of minor differences relative to pure AR responses.
- LLM-assisted data labeling and rationales at scale (MLOps)
- Product/workflow: Batch labeling tools adopt TiDAR to generate candidate labels and rationales (with AR verification) at lower latency.
- Benefits: Reduced labeling time and cost; improved throughput in dataset curation.
- Assumptions/dependencies: QA loops to catch mistakes; domain-specific calibration of acceptance lengths and diffusion block sizes.
- Likelihood evaluation parity for benchmarking (academia, evaluation platforms)
- Product/workflow: Use TiDAR’s AR mode to compute likelihood like standard AR models (single NFE), avoiding Monte Carlo diffusion likelihood overhead.
- Benefits: Efficient and comparable evaluation across model families; cleaner benchmarking workflows.
- Assumptions/dependencies: Availability of AR-mode inference masks; standardized task configs (e.g., lm_eval_harness).
Long-Term Applications
These opportunities require additional research, scaling, engineering, or regulatory work before broad deployment.
- Multimodal “think-talk” systems (speech, audio, video, robotics)
- Vision: Extend TiDAR’s paradigm—diffusion for parallel “thinking,” autoregression for high-quality “talk”—to tokenized audio/vision streams (e.g., phoneme drafting with AR validation, frame drafting for captioning).
- Potential tools: TiDAR-style multimodal decoders; unified dual-mode attention masks for text+audio+vision.
- Dependencies: Robust multimodal tokenization, appropriate bidirectional/causal mask designs per modality, training data scale, and real-time alignment across modalities.
- Hardware/kernel co-design for TiDAR (energy, efficiency)
- Vision: Specialized kernels for structured masks, exact KV-cache eviction, and single-pass draft+verification; integrating with TensorRT-LLM, vLLM, Triton, or custom GPU runtimes.
- Benefits: Lower energy per token, improved throughput at small batches, better compute density utilization.
- Dependencies: Vendor support (CUDA, ROCm), Flex/Flash Attention integration, request schedulers aware of “free token slots,” and mask precomputation.
- On-device and edge TiDAR deployments (mobile, AR glasses, robotics)
- Vision: Quantized, memory-aware TiDAR variants (≤1.5B) on NPUs/edge GPUs enabling real-time assistants, captions, and control policies.
- Tools: Quantization-aware training for dual-mode losses; mask-friendly runtime libraries for mobile.
- Dependencies: Efficient block-bidirectional attention on NPUs, memory-bandwidth characteristics, battery constraints, and privacy-by-design.
- Deterministic, auditable TiDAR for regulated domains (healthcare, finance, legal)
- Vision: Constrained TiDAR variants that either (a) guarantee equivalence to an AR baseline under certain conditions or (b) produce auditable rejection-sampling traces for compliance.
- Benefits: Trust and reproducibility in safety-critical use.
- Dependencies: Formal acceptance-rate bounds, output equivalence guarantees, domain certification, and rigorous validation datasets.
- Multi-agent orchestration with intra-step parallel drafting (software robotics, automation)
- Vision: Use TiDAR’s “free slots” to draft next steps for multiple agents/tools within one forward, while AR sampling verifies and prunes candidates.
- Benefits: Reduced wall-clock time in toolchains; higher throughput in complex automation workflows.
- Dependencies: Orchestrators that batch masks across agents, tool latency modeling, and conflict-resolution policies.
- Serverless “fixed-forward” LLM services (cloud platforms)
- Vision: Per-invocation fixed NFE budgets with mask reuse and KV-cache sharing; predictable cost/latency models for function-as-a-service LLMs.
- Tools: TiDAR-aware schedulers; mask-slicing libraries.
- Dependencies: Platform support for cache residency, cross-request mask caching, and cold-start mitigation.
- Data-efficient dual-mode pretraining pipelines (academia, open models)
- Vision: Public TiDAR checkpoints and recipes demonstrating balanced AR+diffusion losses (e.g., full-mask training), enabling community exploration of throughput-quality Pareto frontiers.
- Benefits: Faster iteration on hybrid architectures; broader adoption.
- Dependencies: Licensed corpora at scale, training compute, and reproducible evaluation harnesses.
- Policy and sustainability metrics (policy, energy)
- Vision: Standardize energy-per-token and cost-per-token metrics recognizing hybrid decoders that boost tokens/sec; inform procurement and sustainability targets.
- Benefits: Incentivizes efficient serving; transparent reporting.
- Dependencies: Measurement standards, third-party audits, and stakeholder buy-in.
- Scientific and HPC workflow synthesis (academia, engineering)
- Vision: TiDAR-powered code and narrative generation for scientific pipelines, leveraging parallel drafting to explore candidate steps and AR validation for correctness.
- Benefits: Faster prototyping of computational experiments.
- Dependencies: Domain adaptation, integration with scientific runtimes, and formal verification where needed.
Collections
Sign up for free to add this paper to one or more collections.