Auto-Regressive Masked Diffusion Models
Abstract: Masked diffusion models (MDMs) have emerged as a promising approach for language modeling, yet they face a performance gap compared to autoregressive models (ARMs) and require more training iterations. In this work, we present the Auto-Regressive Masked Diffusion (ARMD) model, an architecture designed to close this gap by unifying the training efficiency of autoregressive models with the parallel generation capabilities of diffusion-based models. Our key insight is to reframe the masked diffusion process as a block-wise causal model. This perspective allows us to design a strictly causal, permutation-equivariant architecture that computes all conditional probabilities across multiple denoising steps in a single, parallel forward pass. The resulting architecture supports efficient, autoregressive-style decoding and a progressive permutation training scheme, allowing the model to learn both canonical left-to-right and random token orderings. Leveraging this flexibility, we introduce a novel strided parallel generation strategy that accelerates inference by generating tokens in parallel streams while maintaining global coherence. Empirical results demonstrate that ARMD achieves state-of-the-art performance on standard language modeling benchmarks, outperforming established diffusion baselines while requiring significantly fewer training steps. Furthermore, it establishes a new benchmark for parallel text generation, effectively bridging the performance gap between parallel and sequential decoding.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make AI write text quickly and well. It combines two popular ideas for making text: autoregressive models (which write one word at a time, like GPT) and diffusion models (which “fill in” missing parts in steps). The new model is called Auto-Regressive Masked Diffusion (ARMD). Its goal is to keep the high quality of autoregressive models while gaining the speed and parallelism of diffusion models.
What problem is the paper trying to solve?
In simple terms, the paper tackles two issues:
- Autoregressive models are very good at writing text, but they are slow because they generate one token at a time.
- Diffusion models can generate multiple tokens in parallel, which is faster, but in text they usually aren’t as accurate and need lots of training.
The big question: Can we build a model that is both accurate like autoregressive models and fast like diffusion models?
How does the method work?
Think of writing a sentence as solving a puzzle. Autoregressive models place one piece at a time from left to right. Diffusion models hide pieces and then reveal them step by step. ARMD uses the “hide and reveal” idea but organizes it so the puzzle can be solved faster and more efficiently.
Here are the core ideas, explained with everyday language:
- Masked diffusion as “blocks”: In a masked diffusion process, some words are hidden with a special [mask] token, and the model learns to uncover them in steps. The authors noticed that if you look at which words get unmasked at each step, you can group words into blocks. Earlier blocks are like “already revealed clues,” and later blocks are “still hidden.”
- Block-wise causality: The model is designed so that when it predicts a word in one block, it only looks at words from earlier blocks. That’s like saying: “Only use the clues we’ve already uncovered—no peeking at future answers.” This keeps the generation honest and well-structured.
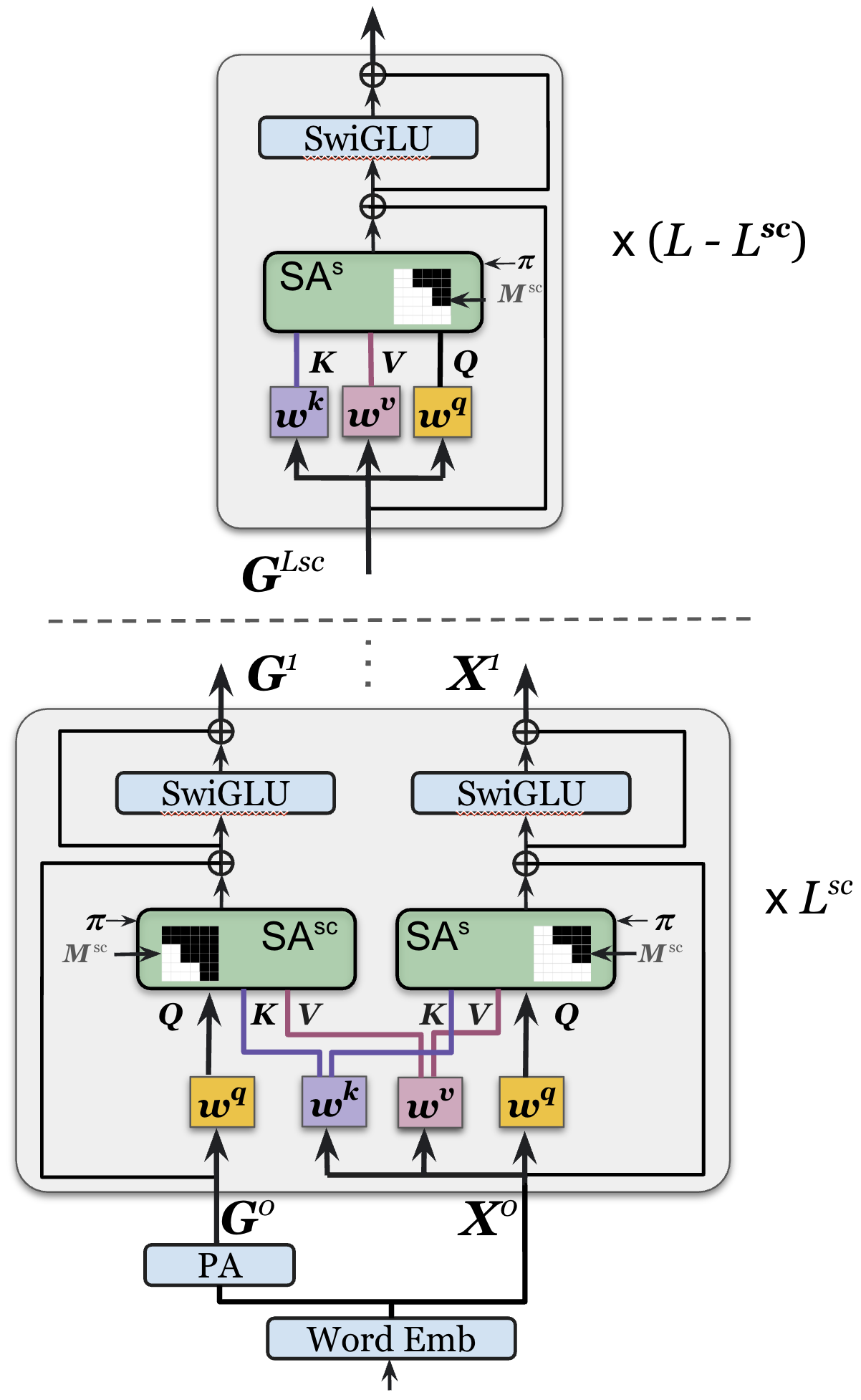
- A strictly causal Transformer: The authors build a Transformer (the same kind of model used in GPT) that is “strictly causal” at the block level. That means it enforces the rule above using an attention mask that allows attention only to earlier blocks, not the current or future ones.
- Two-stream attention (simple mental model): Imagine two lanes in the model:
- A “causal” lane that can look at the current and earlier blocks (like standard GPT).
- A “strictly causal” lane that can only look at earlier blocks.
- They share parameters (so the model doesn’t get bloated), and the strictly causal lane produces the final predictions. This helps the model learn rich context while still following the no-peeking rule.
- Permutation-equivariance: During training, the model sometimes shuffles the order in which tokens are “revealed.” The model is built so it doesn’t care about these shuffles—it can handle many reveal orders without breaking. This makes it flexible and robust.
- Progressive permutation training: The model first learns the common left-to-right order (like reading a sentence normally), then gradually practices with randomly shuffled orders. This curriculum helps it master both the classic order and flexible orders.
- Strided parallel generation: For faster writing, ARMD splits the sentence into several “streams.” It writes the first token of each stream one by one to set context, and then writes the next tokens of each stream in parallel. It’s like writing every other word across the sentence in parallel, then filling in the next set, and so on. This makes generation much faster while keeping the overall story coherent.
- One forward pass for training: A key efficiency gain is that ARMD can compute all the needed probabilities across multiple “unmasking steps” in one go, rather than calling the model many times. That makes training much faster per batch.
A helpful analogy: Picture building a Lego model with instructions split into phases (blocks). You can’t use pieces from a future phase. ARMD enforces this rule during learning and generation, but does it in a way that lets it build parts in parallel when safe.
What did they find?
- Better accuracy among diffusion-style methods: On standard language benchmarks (like WikiText, PTB, LAMBADA, 1BW), ARMD achieves state-of-the-art results for diffusion-based models and often closes the gap with strong autoregressive baselines.
- Fewer training steps: ARMD reaches these results with significantly fewer training iterations than typical masked diffusion models. That means it’s more training-efficient.
- Fast parallel generation with good quality: Using strided parallel generation, ARMD can generate multiple tokens at once and still keep the text coherent. With a bit of extra fine-tuning, the quality of parallel generation gets very close to the quality of the slower, purely sequential method.
- Practical speed-ups: With 2 or 4 parallel streams, generation speed increases roughly 2x–4x, while the text quality remains strong (measured by perplexity and entropy).
- Compatible with standard tricks: Because ARMD is Transformer-based and causal under the hood, it can use key-value caching (a way to avoid recomputing attention over past tokens), which speeds up inference just like in GPT-style models.
Why is this important?
- It bridges two worlds: ARMD combines the best parts of autoregressive and diffusion models—accuracy and speed—addressing long-standing trade-offs in text generation.
- Faster, high-quality text generation: For applications like chatbots, story writing, or code assistants, generating several tokens in parallel can greatly reduce waiting time without sacrificing quality.
- Training efficiency: Getting strong results with fewer training steps reduces compute costs and makes research and deployment more accessible.
- Flexibility and robustness: The ability to learn from multiple token orders can help the model handle tasks that don’t fit a simple left-to-right pattern, like editing, infilling, or reasoning with non-local context.
What could this lead to?
- More responsive language systems: Users could get high-quality responses faster, especially for long outputs.
- Better infilling and editing tools: Because ARMD handles masked and shuffled orders well, it can be naturally suited for “fill in the blank,” document editing, or structured generation tasks.
- Easier upgrades to existing models: The design hints that large autoregressive models could be fine-tuned into ARMD-style models, potentially speeding them up and making them better at parallel generation.
- Broader impact beyond text: The same ideas—strict causality, block-wise reasoning, and parallel generation—could help with other sequence data like music, DNA, or graphs.
In short, ARMD shows a promising path to make LLMs both fast and accurate by carefully rethinking how we “unmask” and generate tokens, and by designing a Transformer that enforces the right rules while still taking advantage of parallelism.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the main unresolved issues, limitations, and concrete open questions left by the paper that future researchers could address:
- Formal equivalence and correctness of the reformulation:
- Provide a rigorous derivation/proof that the block-wise causal reformulation of the MDM objective yields an unbiased estimator of the original ELBO (or its simplified absorbing-diffusion variant) when computed in a single forward pass.
- Precisely define and justify the reweighting factor in Eq. (loss_diff_AR), and show its correspondence to the original diffusion schedule and ELBO weighting.
- Prove the claimed permutation invariance/equivariance properties for the conditional probabilities when combined with positional encodings (e.g., RoPE) and the proposed masking, including edge cases and constraints.
- Architecture design trade-offs and scalability:
- Quantify the computational and memory overheads of the two-stream strictly causal stack (including KV caching behavior) versus standard AR transformer baselines at scale (e.g., >1B parameters and long contexts, >4K tokens).
- Characterize the impact of the number and placement of strictly causal layers ( ratio) on perplexity, training stability, and sampling efficiency; provide ablation studies and scaling laws.
- Analyze how the prefix aggregation module (linear attention via positional embedding dot products) scales with sequence length and whether it introduces expressivity bottlenecks or position-dependent artifacts; benchmark alternative designs (e.g., learned pooling, attention-based aggregation).
- Training objective and schedules:
- Clarify the diffusion hyperparameters used in practice (e.g., , , ) and their interaction with the autoregressive-style loss; provide sensitivity analyses.
- Systematically study the progressive permutation schedule (e.g., , , ): quantify its effects on forward (left-to-right) next-token performance versus robustness to random permutations; identify curricula that optimize both.
- Detail how block partitions and masking times are sampled per batch, and provide reproducible recipes for constructing the block masks and permutations used during training.
- Strided parallel generation (SBP) validity and limits:
- Quantify the approximation error induced by the assumption of conditional independence among tokens generated in parallel blocks as a function of stride , sequence length , and domain; provide theoretical bounds or empirical diagnostics (e.g., mutual information estimates, dependency leakage).
- Characterize how SBP affects global coherence, long-range dependency modeling, and error propagation versus sequential generation; include human evaluations and task-specific metrics beyond perplexity/entropy.
- Explore larger parallelism factors (), varying interleaving schemes, adaptive block sizing, and hybrid strategies (e.g., alternating parallel and sequential phases) to optimize speed-quality trade-offs.
- Evaluation breadth and methodology:
- Extend evaluations beyond OpenWebText training and English LM benchmarks to multilingual corpora, code modeling, and domains with atypical dependency structures; assess generality and robustness.
- Provide a clear, unified methodology for computing perplexity with diffusion-based models (upper bounds vs. exact log-likelihood approximations) and ensure comparability across baselines and ARMD, especially for “generative perplexity.”
- Include ablations on key architectural choices (e.g., RoPE vs. alternatives, mask design variants, query aggregation strategies) and report variance across random seeds.
- Compatibility with pretrained LLMs and fine-tuning:
- Empirically validate the claim that pretrained AR LLMs can be adapted to ARMD via minor mask modifications; quantify the transfer efficiency, convergence behavior, and final performance versus training from scratch.
- Investigate how ARMD fine-tuning interacts with existing LLM features (e.g., instruction tuning, RLHF, KV caching implementations) and whether it preserves or degrades downstream capabilities.
- Theoretical positioning relative to OA-ARMs and absorbing discrete diffusion:
- Provide a formal, constructive equivalence between ARMD’s objective and order-agnostic ARMs (or absorbing discrete diffusion) under explicit assumptions; identify cases where equivalence breaks (e.g., specific positional encoding schemes, non-stationary masks).
- Analyze whether ARMD’s single-pass training introduces biases relative to OA-ARM marginalization over permutations, and propose correction terms or sampling strategies if necessary.
- Long-context handling and variable-length sequences:
- Demonstrate ARMD’s performance and efficiency on sequences significantly longer than 1024 (e.g., 8K–32K), including memory footprint, latency, and quality; evaluate the recurrent/scan implementation promised for the prefix aggregation layer.
- Clarify how the architecture handles variable-length inputs and dynamic block counts at inference; assess robustness to truncation and padding.
- Conditional and guided generation:
- Explore classifier-free guidance (or other conditioning mechanisms) in ARMD for controlled text generation; benchmark efficiency and quality against diffusion baselines that use guidance.
- Evaluate ARMD on conditional tasks (e.g., summarization, translation, code completion) to understand how strict causality constraints interact with conditioning signals.
- Reproducibility and implementation clarity:
- Release code, training scripts, and detailed hyperparameters for loss weighting, mask construction, permutation sampling, and SBP fine-tuning to enable independent verification.
- Provide end-to-end complexity and throughput measurements (training and inference) under standardized hardware and batching setups, including comparisons with tuned AR baselines using KV caching.
Glossary
- Absorbing state: A state in a stochastic process that, once entered, cannot be left in subsequent steps. "the \verb|[mask]| state is absorbing:"
- Auto-Regressive Masked Diffusion (ARMD): The proposed architecture that unifies diffusion-based learning with autoregressive efficiency. "we present the Auto-Regressive Masked Diffusion (ARMD) model"
- Autoregressive Models (ARMs): Generative models that factorize a joint distribution into a product of conditionals over a predefined order. "Autoregressive Models (ARMs) have demonstrated significant success"
- Block-lower-triangular attention matrix: An attention structure that permits attention only within current and preceding blocks, enforcing causality. "This results in a block-lower-triangular attention matrix"
- Block-wise causal model: A causal formulation where tokens are grouped into blocks and each block depends only on previous blocks. "reframe masked diffusion models (MDMs) as block-wise causal models."
- Causal mask matrix: A masking matrix that restricts attention to enforce causal dependencies. "the causal mask matrix"
- Causal Self-Attention: Self-attention with a causal mask that prevents access to future tokens. "Causal Self-Attention."
- Chain rule: The probabilistic factorization that expresses a joint distribution as a product of conditional probabilities. "using the chain rule"
- Classifier-free guidance: A guidance technique that conditions generation without a separate classifier. "an unsupervised classifier-free guidance technique"
- Cross entropy: A loss function measuring the difference between predicted and true distributions, commonly used for classification. "is a cross entropy objective"
- Denoising process: The reverse process in diffusion models that removes noise to recover clean data. "reverse denoising process"
- Discrete diffusion models: Diffusion models defined on discrete variables such as tokens or categories. "discrete diffusion models have struggled to match the performance benchmarks"
- Evidence Lower Bound (ELBO): A variational objective that lower-bounds the log-likelihood and is optimized during training. "optimizing the Evidence Lower Bound (ELBO) on the log-likelihood of the data"
- Isotropic Gaussian: A Gaussian distribution with equal variance in all directions (identity covariance). "such as an isotropic Gaussian."
- Joint probability distribution: The probability distribution over all variables in a sequence considered together. "factorizing the joint probability distribution of a sequence"
- Key-value (KV) caching: Caching key and value projections during decoding to speed up autoregressive inference. "enabling efficient key-value (KV) caching for fast decoding"
- K-simplex: The set of all K-dimensional probability vectors that sum to one and are nonnegative. "the -simplex"
- Kullback–Leibler divergence: A measure of discrepancy between two probability distributions. "is the KullbackâLeibler divergence"
- Linear attention: An attention mechanism or formulation with linear time/space complexity in sequence length. "as a linear attention form"
- Markov chain: A stochastic process where the next state depends only on the current state. "The forward process is defined as a Markov chain"
- Masked Diffusion Model (MDM): A discrete diffusion variant where a special mask token is absorbing and the model learns to unmask tokens. "is the Masked Diffusion Model (MDM)."
- Order Agnostic ARMs (OA-ARMs): Autoregressive models that marginalize over many possible generation orders rather than a single fixed order. "Order Agnostic ARMs (OA-ARMs)"
- Permutation-equivariant: A model property where outputs transform consistently with permutations of inputs in the conditioning set. "permutation-equivariant architecture"
- Progressive permutation schedule: A training curriculum that gradually increases the amount of token permutation to improve robustness. "we introduce a progressive permutation schedule during training"
- Rotary Positional Embedding (RoPE): A positional encoding technique that uses rotations to encode relative positions in attention. "Rotary Positional Embedding (RoPE)"
- Score entropy objective: An objective for discrete score-based diffusion that encourages correct score estimation. "using a novel score entropy objective."
- Stationary noise distribution: A time-invariant noise distribution used in the forward diffusion process. "a stationary noise distribution"
- Strided block-parallel (SBP) sampling strategy: A generation method that partitions sequences into parallel streams for simultaneous token generation. "we introduce a strided block-parallel (SBP) sampling strategy."
- Strided parallel generation: A parallel decoding scheme that interleaves multiple token streams to accelerate inference. "a novel strided parallel generation strategy"
- Teacher forcing: A training method where ground-truth tokens are provided as inputs to predict the next tokens. "Thanks to causal masking and teacher forcing,"
- Two-stream attention architecture: An architecture maintaining parallel causal and strictly causal streams that share parameters but use different masks/queries. "we adopt a two-stream attention architecture."
- Variational lower bound: A lower bound on the data likelihood optimized in variational inference settings. "optimizes a variational lower bound on the data likelihood."
- Zero-shot perplexity: Perplexity evaluation without task-specific fine-tuning, measuring generalization. "using zero-shot perplexity on a suite of widely-used benchmark datasets"
Practical Applications
Immediate Applications
The following applications can be implemented today with modest engineering effort, using the paper’s ARMD architecture, progressive permutation training, and strided parallel generation (SBP) strategy.
- Faster LLM-powered chat and drafting with parallel decoding (software, media)
- Application: Reduce user-perceived latency in chat, autocomplete, and long-form drafting by generating tokens in parallel streams (
S=2–4) with KV caching. - Tools/workflows: Inference server update to support SBP; dynamic
Sselection; fall back to sequential decoding for hard segments; lightweight fine-tuning for SBP (10–80K steps). - Assumptions/dependencies: Quality depends on approximate conditional independence of far-apart tokens; requires ARMD-style strictly causal, permutation-equivariant attention and progressive permutation training.
- Application: Reduce user-perceived latency in chat, autocomplete, and long-form drafting by generating tokens in parallel streams (
- High-throughput content generation pipelines (marketing A/B variants, multi-section reports) (media, enterprise software)
- Application: Generate multiple sections or variants simultaneously while maintaining global coherence via block-wise causal masking.
- Tools/workflows: Batch schedulers that assign sections to parallel streams; coherence checks; entropy/perplexity monitors.
- Assumptions/dependencies: Parallel blocks should be separated sufficiently in the document to preserve independence; quality improves with SBP fine-tuning.
- Mask-based editing and partial regeneration in document/IDE tools (productivity, developer tools)
- Application: Regenerate middle sections or masked spans without re-decoding entire documents—leveraging MDM-style unmasking with ARMD’s efficient parallel likelihood evaluation.
- Tools/workflows: Editor plugins that let users “lock” context and unmask target spans; localized fine-tuning for domain text/code.
- Assumptions/dependencies: Requires attention masks that prevent leakage from masked regions; more effective with progressive permutation training.
- On-device assistants with lower energy and memory footprint (mobile, embedded)
- Application: Faster inference at lower compute budgets via KV caching and reduced decoding steps; improved sustainability and responsiveness.
- Tools/workflows: Optimized kernels for strictly causal/two-stream attention; quantization; memory-aware
Sscheduling. - Assumptions/dependencies: Hardware acceleration for attention ops; small/medium ARMD models trained with fewer steps as shown in the paper.
- Retrieval-augmented generation (RAG) with parallel section drafting (enterprise, knowledge management)
- Application: Draft multiple report sections concurrently after retrieval; preserve coherence through block-wise causal attention.
- Tools/workflows: RAG orchestrators that assign retrieved chunks to streams and interleave output; section-level validation.
- Assumptions/dependencies: Retrieval must provide strong shared context across streams; stream heads should be generated sequentially to anchor context.
- Accelerated research prototyping and evaluation in language modeling (academia)
- Application: Train competitive models with substantially fewer steps; run parallel text-generation benchmarks; investigate OA-ARM and diffusion links using the strictly causal two-stream architecture.
- Tools/workflows: Open-source attention layers and masks; curriculum for progressive permutation; reproducible SBP benchmarks.
- Assumptions/dependencies: Implementation of permutation-equivariant attention and training curricula; existing datasets/metrics.
- Sustainability and cost reductions in ML operations (policy, enterprise IT)
- Application: Lower training and inference energy by adopting ARMD’s efficient objective (single forward pass for all conditionals) and parallel decoding.
- Tools/workflows: Carbon accounting dashboards; procurement criteria favoring efficient generative models; cost/perf A/B tests.
- Assumptions/dependencies: Transparent reporting of energy and training step budgets; policy teams accept perplexity as a quality proxy.
- Multi-cursor code completions (developer tools)
- Application: Generate suggestions for several cursors/files in parallel while maintaining shared context across the repo or session.
- Tools/workflows: IDE integration with stream assignment; global symbol table anchoring via sequential stream heads.
- Assumptions/dependencies: Independence holds better across distant files/functions; tokenization and context windows tuned for code structure.
Long-Term Applications
These applications require further research, scaling, or productization, especially around very large models, domain adaptation, and new inference controllers.
- Foundation models with native parallel decoding (software, cloud AI)
- Application: Integrate ARMD at scale to bridge parallel vs. sequential performance, offering tunable latency-quality trade-offs for large LLMs.
- Tools/workflows: Parallelism controllers that adapt
Sper segment; memory-aware KV caching at scale; robust SBP training at >1B params. - Assumptions/dependencies: Scaling laws and stability of strictly causal two-stream attention at large sizes; strong infrastructure support.
- Cross-domain discrete sequence generation (bio, chemistry, graphs, robotics)
- Application: Faster generation of proteins/DNA, molecular graphs, schedules, or action plans using ARMD’s masked diffusion with parallel streams.
- Tools/workflows: Domain tokenization (k-mers, graph encodings), task-specific masking schedules, constraint-aware generation (e.g., motifs, valence).
- Assumptions/dependencies: Validity of conditional independence across distant positions; domain constraints integrated into masks/guidance; rigorous evaluation (e.g., wet lab, simulation).
- Adaptive parallelism and quality controllers (software infrastructure)
- Application: Real-time
Sadjustment using uncertainty metrics (entropy, perplexity) and semantic signals (topic shifts) to balance speed vs. coherence. - Tools/workflows: Telemetry-driven schedulers; confidence-aware fallbacks to sequential decoding; segment-level re-ranking.
- Assumptions/dependencies: Reliable online quality proxies; guardrail policies for high-risk content; robust recovery from parallelization-induced errors.
- Application: Real-time
- Parallel beam search and structured decoding algorithms (ML research, tooling)
- Application: Combine SBP with beam search across streams and blocks; discover improved exploration strategies for long sequences.
- Tools/workflows: Libraries for block-wise scoring, shared caches, and stream-level pruning; evaluation suites.
- Assumptions/dependencies: New theory/algorithms for beams under block masks; careful memory management.
- Conversion frameworks to fine-tune ARMs into diffusion-style models (ML platforms)
- Application: Reuse pretrained AR weights, anneal attention masks, and adopt ARMD objectives for improved controllability and parallel decoding.
- Tools/workflows: Mask-annealing recipes; parameter-efficient adapters; curriculum schedulers.
- Assumptions/dependencies: Compatibility across architectures; retention of learned knowledge; stability under hybrid objectives.
- Privacy-preserving, edge-native assistants in regulated sectors (healthcare, finance, public sector)
- Application: On-device generation with efficient decoding to keep sensitive data local; mask-based redaction/regeneration workflows.
- Tools/workflows: Auditable inference logs; redaction masks; policy-compliant deployment templates.
- Assumptions/dependencies: Robustness against leakage; domain fine-tuning; formal privacy assurances.
- Education and tutoring systems with parallel solution drafting (education)
- Application: Generate multiple solution paths or hints concurrently, then reconcile for coherent feedback.
- Tools/workflows: Stream-to-section mapping (e.g., steps of proofs); scaffolding controllers; student-facing UIs.
- Assumptions/dependencies: Pedagogical validity; alignment and fact-checking; adaptive control of
Sfor harder material.
- Real-time translation and captioning with low latency (media, accessibility)
- Application: Generate multiple sentences/segments in parallel while maintaining cross-segment coherence.
- Tools/workflows: Segmenter that anchors stream heads on sentence boundaries; bilingual alignment-aware masks.
- Assumptions/dependencies: Parallel generation may struggle with tight local dependencies; extensive domain fine-tuning.
- Multi-agent planning and ensemble generation (autonomy, operations)
- Application: Agents propose plans or drafts in parallel streams and reconcile via block-wise causal aggregation.
- Tools/workflows: Orchestrators with stream-consistency checks; conflict resolution policies.
- Assumptions/dependencies: Reliable coherence mechanisms; evaluation of safety and correctness.
- Governance and standards for efficient generative AI (policy)
- Application: Standards incentivizing models that reduce training steps and inference energy; reporting norms for parallel decoding quality.
- Tools/workflows: Benchmarks for parallel-generation coherence; lifecycle carbon accounting; procurement guidelines.
- Assumptions/dependencies: Cross-industry acceptance of metrics; regulatory frameworks that recognize efficiency as a compliance factor.
Collections
Sign up for free to add this paper to one or more collections.