The Art of Building Verifiers for Computer Use Agents
Abstract: Verifying the success of computer use agent (CUA) trajectories is a critical challenge: without reliable verification, neither evaluation nor training signal can be trusted. In this paper, we present lessons learned from building a best-in-class verifier for web tasks we call the Universal Verifier. We design the Universal Verifier around four key principles: 1) constructing rubrics with meaningful, non-overlapping criteria to reduce noise; 2) separating process and outcome rewards that yield complementary signals, capturing cases where an agent follows the right steps but gets blocked or succeeds through an unexpected path; 3) distinguishing between controllable and uncontrollable failures scored via a cascading-error-free strategy for finer-grained failure understanding; and 4) a divide-and-conquer context management scheme that attends to all screenshots in a trajectory, improving reliability on longer task horizons. We validate these findings on CUAVerifierBench, a new set of CUA trajectories with both process and outcome human labels, showing that our Universal Verifier agrees with humans as often as humans agree with each other. We report a reduction in false positive rates to near zero compared to baselines like WebVoyager ($\geq$ 45\%) and WebJudge ($\geq$ 22\%). We emphasize that these gains stem from the cumulative effect of the design choices above. We also find that an auto-research agent achieves 70\% of expert quality in 5\% of the time, but fails to discover all strategies required to replicate the Universal Verifier. We open-source our Universal Verifier system along with CUAVerifierBench; available at https://github.com/microsoft/fara.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers how to reliably check whether other AI “computer-using agents” actually did what they were asked to do. Imagine an AI that browses websites, fills out forms, or books tickets. After it tries, we need a fair, careful “referee” to decide: did it really succeed? The authors built such a referee, called the Universal Verifier, and showed how to make it accurate and trustworthy.
What questions were the researchers trying to answer?
The authors focused on a few simple questions:
- How can we judge if an AI using a computer truly finished a task, especially when tasks involve many steps and lots of screenshots?
- How can we tell the difference between “the agent did the right things but got blocked” and “the agent actually completed the goal”?
- How do we spot honest mistakes versus problems outside the agent’s control (like a login wall)?
- Can we design a verifier that matches human judgment and avoids saying “success” when the agent didn’t really succeed?
- Could another AI automatically design this verifier as well as a human expert?
How did they approach it?
The team built the Universal Verifier around four practical ideas. You can think of the verifier like a fair judge using a detailed checklist and instant replay footage.
1) Make a clear checklist (“rubric”) with non-overlapping items
- Analogy: If your chore list says “clean your room,” a good checklist breaks that into clear, non-overlapping items like “make the bed,” “put clothes in the closet,” “vacuum the floor.” No duplicates. No made-up tasks.
- They generate the checklist from the user’s goal (not from the agent’s actions) to avoid bias, handle “conditional” items (like “buy organic, or if none, non-organic”), and prevent one early mistake from unfairly causing many penalties (“no cascading errors”).
2) Separate effort (process) from end result (outcome)
- Analogy: Baking a cake. Process = did you follow the recipe steps well? Outcome = does the cake taste good?
- Process score: How well the agent executed each sub-goal (0.0–1.0). Outcome label: Did the user’s main goal actually get done? (yes/no)
- This avoids punishing agents for things they can’t control (e.g., an out-of-stock item) and avoids rewarding “effort” when the goal isn’t achieved.
3) Tell apart controllable vs. uncontrollable failures
- Uncontrollable (don’t penalize process): site requires login with no credentials, CAPTCHAs, items out of stock, business closed.
- Controllable (do penalize process): wrong item/place/person, sloppy reasoning, claiming success without proof, giving up too early, skipping needed steps.
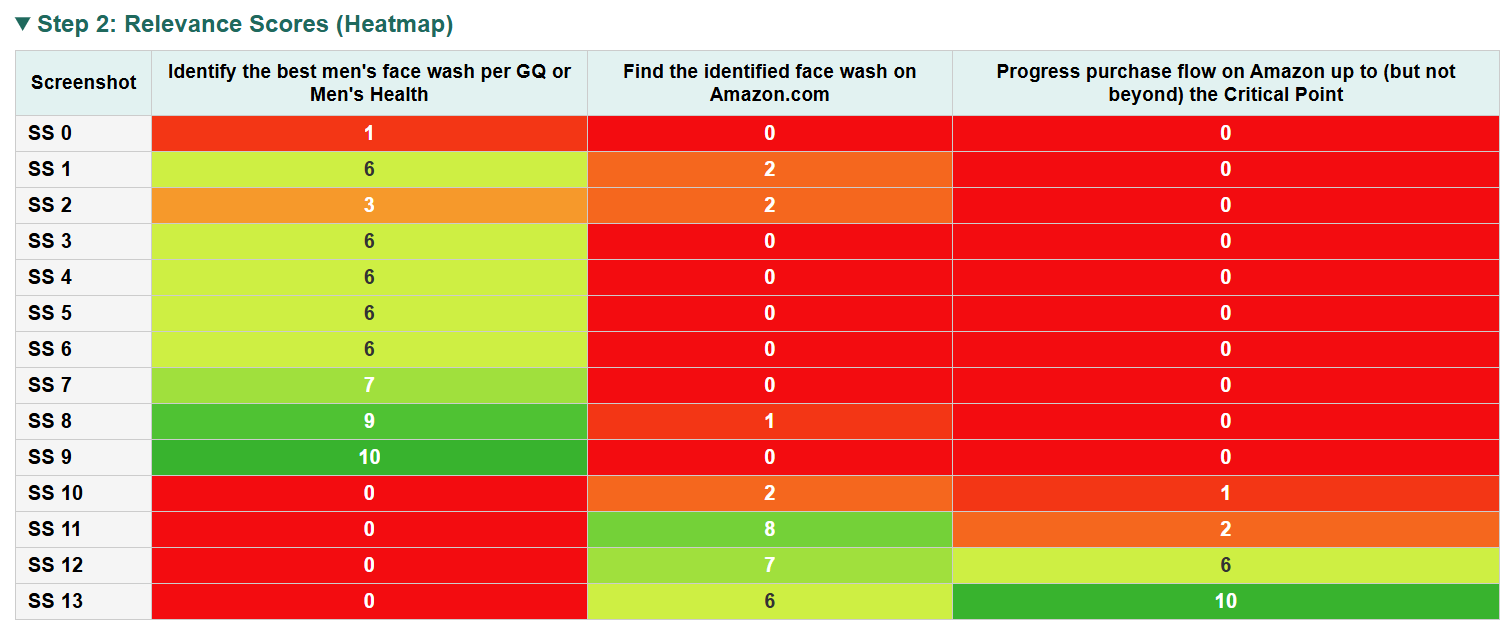
4) Carefully manage the “evidence” (screenshots)
- Analogy: Watching a sports game, not all camera angles are equally important for each rule. For each checklist item, the verifier builds a “highlight reel” of the most relevant screenshots instead of dumping all frames at once.
- This “divide and conquer” approach helps it find the right evidence for each sub-goal and avoids missing important moments hidden deep in long tasks.
To test and improve their design, the authors also:
- Built a new human-labeled dataset (CUAVerifierBench) where people marked both process and outcome, so they could compare the verifier to human judgments.
- Compared the Universal Verifier to other popular judges (like WebVoyager and WebJudge).
- Tried an “auto-research agent” (an AI scientist) to see if it could design a verifier as well as a human expert.
What did they find, and why is it important?
Main takeaways:
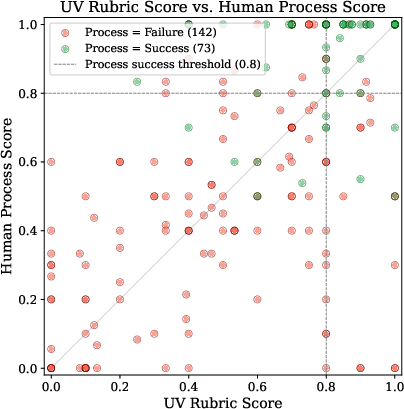
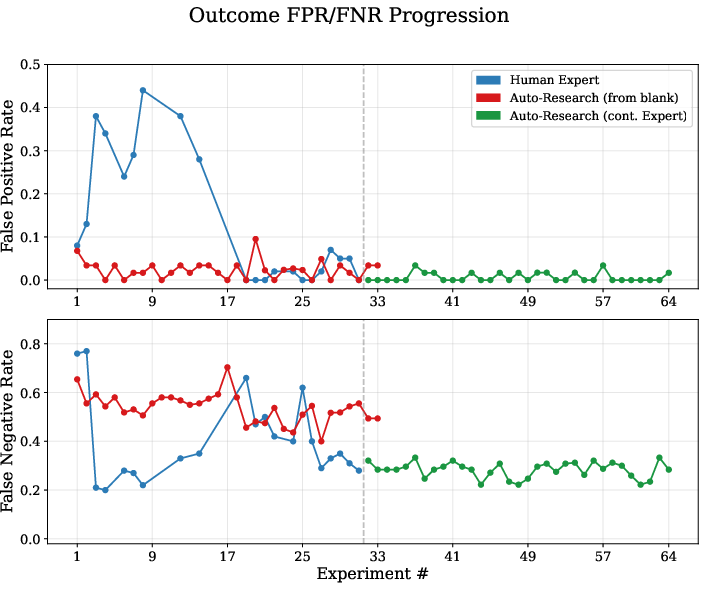
- Much fewer “false successes”: The Universal Verifier cut false positives (saying a task succeeded when it didn’t) from around 22–45% in existing systems down to about 1–8%. That means it almost never gives credit for work that isn’t truly done.
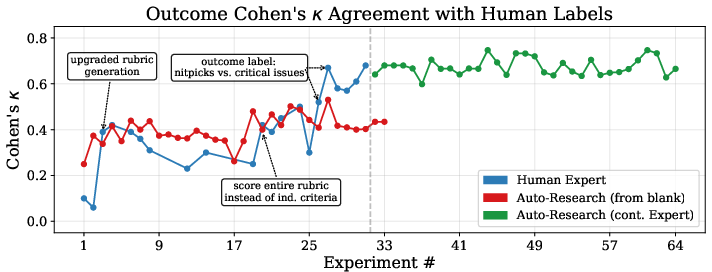
- Human-level agreement: Its agreement with human labels was about as high as humans agree with each other (measured by a standard score called Cohen’s kappa, roughly in the 0.6–0.7 range at best). In simple terms, it judges a lot like people do.
- Better design beats bigger models: Simply swapping in a stronger AI model in older verifiers didn’t fix their problems. The improvements mainly came from the new design (the rubric, process/outcome split, and smarter screenshot handling).
- Helpful explanations: When human annotators saw the Universal Verifier’s reasoning, they often updated their judgments in sensible ways (for example, noticing failures they initially missed), suggesting the verifier’s logic is clear and useful.
- Auto-research is promising but not enough alone: An AI “researcher” could reach about 70% of expert quality very fast (in about a day), but it missed some key design insights. When it started from the human’s best version, though, it could fine-tune further. This suggests humans are great at big ideas; AI is great at polishing.
Why this matters:
- Training and evaluation you can trust: If you can’t reliably tell whether an agent truly succeeded, you can’t properly train it or measure progress. A trustworthy verifier prevents “garbage” from sneaking into training data and leaderboards.
- Fairer, clearer feedback for agents: Splitting process vs. outcome means agents can learn both how to do the right steps and how to actually achieve the goal—without being punished for things outside their control.
- Safer, more transparent systems: The verifier spots hallucinations (like claiming success without evidence) and catches unwanted side effects (like adding extras to a cart without being asked).
What could this mean in the future?
- Better web and app assistants: With reliable checking, future agents can practice on clear, accurate feedback and improve faster and more safely.
- Standardized benchmarks: The authors released their verifier and dataset so others can measure judges in a consistent way and push the field forward.
- Human–AI co-design: The results hint that the best systems may come from humans discovering the key ideas and AI helping fine-tune them—combining creativity with speed.
In short: The paper shows how to build a careful, fair “referee” for AI agents that use computers. By using clear checklists, separating effort from results, distinguishing controllable from uncontrollable problems, and smartly organizing screenshot evidence, the Universal Verifier matches human judgment and avoids “pretend successes.” This makes future AI agents more reliable and easier to improve.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps the paper leaves unresolved, intended to guide future research.
- External validity beyond web tasks: Evaluate the Universal Verifier (UV) on non-web computer-use settings (e.g., OSWorld-style desktop workflows, native apps, file managers, PDFs, spreadsheets, system dialogs) and mobile app environments to test generalization of the rubric and screenshot-relevance designs.
- Multilingual and internationalization robustness: Assess performance on non-English UIs, mixed-language content, and locale variations (currencies, date formats, right-to-left scripts), and identify failure modes introduced by localization.
- Evidence sources beyond screenshots: Incorporate and ablate DOM/HTML diffs, accessibility trees, network logs, OS/file-system events (downloads, file writes), and email/notification traces to verify outcomes and side-effects that are not visually apparent.
- Scalability and cost profile: Quantify runtime, memory, and token/image costs of the relevance matrix (O(T×N)) and top-k per-criterion scheme across long trajectories; report latency vs. accuracy trade-offs and practical budgets for use in training loops at scale.
- Sensitivity to hyperparameters: Systematically ablate k in top-k screenshot selection, screenshot relevance thresholding, rubric binarization threshold for process labels (e.g., 0.8), and per-criterion max-point weights to understand robustness and optimal settings.
- Determining rubric criterion weights: Provide a principled method (learned from human preferences, utility modeling, or analytic hierarchy processes) for setting and validating per-criterion max points rather than relying on implicitly chosen weights.
- Rubric generation stability and reproducibility: Measure variance across seeds and runs, cross-model consistency, and failure modes where LLM-generated rubrics drift semantically; explore caching or canonicalization to reduce rubric churn.
- Boundary of controllable vs. uncontrollable factors: Formalize ambiguous cases (e.g., availability behind login, CAPTCHAs that can be bypassed, paywalls with possible alternatives) and test how different operationalizations change process scores and agreement with humans.
- Diagnostic accuracy evaluation: Validate the failure taxonomy and step localization against human-labeled diagnoses; report inter-annotator agreement and UV–human agreement on diagnostic categories and failure timesteps, not only success/failure.
- Side-effect detection performance: Build labeled datasets of unsolicited side-effects (e.g., upsells, subscriptions, privacy leaks) and report precision/recall; formalize severity weighting and demonstrate consistency across annotators and tasks.
- Hallucination-specific benchmarking: Construct targeted test suites for common hallucination types (visual, textual, state-claim fabrications) to directly quantify UV’s claimed improvements in hallucination resistance and false positives.
- Managing long-horizon evidence: Provide coverage metrics for the relevance scorer (recall of truly relevant frames) and analyze failure cases where critical evidence is missed; explore learned long-context models vs. heuristic top-k selection.
- Outcome acceptability and user preferences: Replace global heuristics (e.g., “primary intent” forgiveness, rounding tolerance) with explicit, parameterizable user preference models; test how preference conditioning affects agreement and FPR/FNR.
- FPR–FNR trade-offs and calibration: Present explicit cost-sensitive analyses, ROC/PR curves, and calibrated probability outputs for process and outcome decisions so downstream users can set operating points appropriate to their risk tolerance.
- Dependence on closed LLMs: Quantify performance and FPR/FNR when replacing GPT-5.2 with open-weight multimodal models; identify which UV components degrade most and where fine-tuning or distillation can recover accuracy.
- Generalization across agents and task distributions: Evaluate UV across a broader set of agents (planning styles, error profiles) and benchmarks (e.g., VisualWebArena, WorkArena/++, AssistantBench) to test robustness to diverse behaviors and visual layouts.
- Training impact of process vs. outcome rewards: Demonstrate that using UV-derived signals improves agent training (RL, DPO, or offline RL) compared to alternative judges; report learning curves, stability, and ablations on reward mixing.
- Robustness to strategic/adversarial agents: Investigate how easily agents can game or spoof the verifier (e.g., manipulating screens, injecting misleading UI states, crafting actions to trigger rubric credit) and develop defenses or adversarial testbeds.
- Handling ephemeral or hidden states: Evaluate tasks with transient toasts, modals that quickly disappear, background operations, or delayed confirmations; design mechanisms to ensure such evidence is captured and scored reliably.
- Ground-truth formation and label noise: Expand human-labeled datasets with cross-institution annotators, adjudication protocols, and uncertainty labels; study how median/majority aggregation choices and thresholds affect conclusions.
- Auto-research generality and reproducibility: Compare different auto-research systems, search strategies (e.g., Bayesian optimization, evolution), and objective functions; release protocols to reproduce the auto-research findings and test generality beyond the internal dataset.
- Throughput and deployment considerations: Report end-to-end throughput in production-like settings (concurrency, batching, caching); evaluate integration into continuous evaluation/training pipelines and the impact on iteration speed and cost.
- Privacy and safety handling: Specify practices for PII redaction in screenshots and logs, data retention policies, and compliance constraints when deploying UV on real user data.
- Benchmarking against video-based models: Compare UV to sequence/video-level reward models and hybrid approaches that encode temporal dynamics more explicitly; test whether such models reduce missed evidence or improve diagnostic fidelity.
- Continual adaptation to web drift: Propose and evaluate methods for maintaining verifier reliability amid frequent UI/content changes (self-healing rubrics, automated rubric regression tests, or continual learning from new annotations).
Practical Applications
Practical Applications Derived from “The Art of Building Verifiers for Computer Use Agents”
The paper introduces the Universal Verifier (UV) and CUAVerifierBench, demonstrating architectural principles (well-scoped rubrics, separate process/outcome signals, controllable vs. uncontrollable failure analysis, and divide-and-conquer screenshot relevance) that materially reduce false positives and align verifier judgments with humans. Below are concrete applications, grouped by deployment horizon.
Immediate Applications
- Robust evaluation of web/computer-use agents in R&D and product teams
- Sectors: software/AI, robotics (HMI/GUI control), enterprise automation
- Tools/workflows/products: integrate UV as a standardized evaluator for agent trajectories; use Cohen’s κ and FPR dashboards to gate models before release; replace or audit existing verifiers with high FPR
- Assumptions/dependencies: access to trajectory logs (screenshots + action history); vision-capable LLM backend; budget for inference; adoption of UV rubric templates
- Training signal generation for RL/RLAIF and dataset curation
- Sectors: AI/ML (agent training), MLOps
- Tools/workflows/products: use separate process and outcome scores to shape rewards, filter noisy successes, and prioritize constructive near-misses; build high-precision training sets by down-weighting trajectories UV marks as false positives
- Assumptions/dependencies: pipeline alignment between UV scores and training framework; compute to run UV at scale; clear task goals to generate task-specific rubrics
- CI/CD test gating for agent releases
- Sectors: software/AI product engineering
- Tools/workflows/products: treat UV + curated task suites as unit/integration tests; block deployments if outcome FPR or κ fall below thresholds; run UV on canary releases
- Assumptions/dependencies: stable test task bank; reproducible environments; policy thresholds for FPR/κ
- Human-in-the-loop annotation acceleration and quality control
- Sectors: data annotation services, academia (benchmarking), enterprise QA
- Tools/workflows/products: two-stage annotation workflows where UV pre-scores trajectories and provides rubrics; use UV to surface missed failures and reduce adjudication time
- Assumptions/dependencies: annotation guidelines aligned to UV’s process/outcome definitions; privacy-compliant screenshot sharing
- Safety/compliance auditing of agent actions (hallucination and side-effect detection)
- Sectors: finance, healthcare, e-commerce, IT ops, customer support
- Tools/workflows/products: automatically flag outcome-hallucinations (e.g., claiming a booking without evidence) and unsolicited side effects (e.g., adding warranties or extra subscriptions); add UV checks before committing irreversible actions or transactions
- Assumptions/dependencies: real-time or near-real-time UV scoring in workflows; escalation paths for human review; well-defined “material side-effect” policies
- Transparent user-facing agent reports
- Sectors: consumer software, enterprise SaaS
- Tools/workflows/products: expose UV’s process/outcome rationale to end users (e.g., “task completed” with evidence snapshots, or “attempted but blocked by login wall”); improve trust and reduce support tickets
- Assumptions/dependencies: UI surfaces to present evidence; guardrails for sensitive data in screenshots
- A/B testing and error taxonomy-driven product analytics
- Sectors: AI product management, UX engineering
- Tools/workflows/products: use UV’s controllable/uncontrollable failure tags to attribute regressions (model vs. environment); run feature A/Bs and track improvements in process vs. outcome
- Assumptions/dependencies: consistent logging, stable taxonomies, analytics pipeline
- Benchmark creation and verification
- Sectors: academia, open-source communities, standards bodies
- Tools/workflows/products: use CUAVerifierBench and UV to build/curate benchmarks with process and outcome labels; audit existing benchmarks for mislabeled successes
- Assumptions/dependencies: access to raw trajectories; agreement on labeling guidelines; community governance for updates
- Vendor evaluation and procurement due diligence
- Sectors: enterprise IT, procurement, risk management
- Tools/workflows/products: run UV on vendors’ agent demos to compare process/outcome quality and FPR; request κ/precision targets as part of SLAs
- Assumptions/dependencies: standardized tasks; vendor cooperation in providing logs; clear acceptance criteria
- QA for RPA/UI automation and regression suites
- Sectors: enterprise RPA, QA/testing
- Tools/workflows/products: use UV to verify that scripted flows truly reach intended end-states and to detect silent failures masked by UI changes
- Assumptions/dependencies: instrumented test runs with screenshots; mapping RPA goals to rubrics
- Personal automation verification (daily life)
- Sectors: consumer automation (browser extensions, task runners)
- Tools/workflows/products: UV-backed “verify before commit” for automations like bill pay, appointment booking, or online orders; display evidence-backed confirmation
- Assumptions/dependencies: lightweight, affordable verifier access; privacy controls (local/on-device or redaction)
- Auto-research for prompt/heuristic tuning after expert scaffolding
- Sectors: AI tooling, internal platform teams
- Tools/workflows/products: use auto-research to fine-tune prompts/code starting from human-designed UV templates while enforcing FPR constraints
- Assumptions/dependencies: versioned prompts/code; guardrails against overfitting to eval sets; monitoring of FPR/κ
Long-Term Applications
- Cross-domain universal verification (desktop, mobile, OS agents, and mixed-modality)
- Sectors: software/AI, robotics (human-computer interaction), IT automation
- Tools/workflows/products: extend UV’s rubric and relevance framework to native apps and mobile UIs; standard “verifier adapters” for different GUIs
- Assumptions/dependencies: robust screen/video capture beyond web; broader multimodal reasoning; new benchmarks per domain
- Trainable multimodal reward models distilled from UV
- Sectors: AI/ML research and production
- Tools/workflows/products: fit compact process and outcome reward models on UV outputs to avoid LLM-judge latency and cost; use online during agent planning
- Assumptions/dependencies: labeled data at scale; model compression; calibration to maintain low FPR
- Verifier-in-the-loop self-correcting agents
- Sectors: AI agents in safety-/cost-sensitive workflows (healthcare, finance, e-commerce)
- Tools/workflows/products: inner-loop checks where agents query a verifier during task execution to avoid side effects or hallucinated success before committing actions
- Assumptions/dependencies: latency budgets; APIs for partial trajectory scoring; decision policies to handle verifier disagreement
- Industry standards and certification for agent evaluation
- Sectors: policy/standards, regulated industries
- Tools/workflows/products: standardized definitions of process vs. outcome success, maximum FPR targets, and evidence requirements; third-party certifications for agent products
- Assumptions/dependencies: multi-stakeholder consensus; test suites and audits; legal frameworks
- Privacy-preserving/on-device verification
- Sectors: healthcare, finance, public sector, consumer
- Tools/workflows/products: on-device or enclave-based UV variants; redaction pipelines for sensitive screenshots
- Assumptions/dependencies: efficient local models; secure enclaves; robust redaction and data minimization
- Fleet-level root-cause analytics and AIOps integration
- Sectors: enterprise IT, platform engineering
- Tools/workflows/products: aggregate UV failure taxonomies across fleets to drive remediation (e.g., login/CAPTCHA handling, brittle selectors); automated alerts and rollbacks
- Assumptions/dependencies: telemetry pipelines; incident response playbooks; mapping failure taxonomies to remediation actions
- Evidence-aware UX and API design for agent compatibility
- Sectors: platform/product teams, web frameworks
- Tools/workflows/products: design UIs/APIs to minimize uncontrollable failures (e.g., optional logins, accessible evidence of success states); “agent-friendly” patterns validated by UV metrics
- Assumptions/dependencies: product roadmaps; measurable UV improvements; accessibility/compliance constraints
- Adversarial/hard-case mining and active evaluation
- Sectors: AI safety, robustness research
- Tools/workflows/products: use UV to mine trajectories with subtle hallucinations or cascading errors; continually expand “hard sets” for training/evaluation
- Assumptions/dependencies: storage and curation infrastructure; human review loops
- Generalized multimodal retrieval for long-horizon tasks
- Sectors: enterprise search, e-discovery, customer support tools
- Tools/workflows/products: adapt UV’s per-criterion screenshot relevance to retrieve salient visual evidence across long sessions (e.g., session QA, compliance audits)
- Assumptions/dependencies: domain-specific criteria; scalable embeddings/retrieval; governance for evidence storage
- Government and public-service digital transformation
- Sectors: public sector, social services
- Tools/workflows/products: verify agent-driven interactions with benefits portals, licensing systems, and citizen services; reduce error rates and fraud by requiring evidence-backed success
- Assumptions/dependencies: approved agent use; procurement of verifier tooling; accessibility and privacy requirements
- Security and abuse detection for agent-mediated actions
- Sectors: cybersecurity, fraud prevention
- Tools/workflows/products: use side-effect detection and outcome evidence checks to identify prompt-injection-induced behavior changes or fabricated confirmations
- Assumptions/dependencies: integration with security monitoring; attack simulations; incident workflows
- Education and training on evaluative judgment and rubric design
- Sectors: education, corporate training
- Tools/workflows/products: curricula and labs using UV and CUAVerifierBench to teach rigorous, non-overlapping rubric construction and process vs. outcome reasoning
- Assumptions/dependencies: accessible courseware; compute grants or small models for classrooms
- Marketplaces and leaderboards with trusted scores
- Sectors: AI ecosystems, open-source communities
- Tools/workflows/products: hosted evaluator services where teams submit trajectories for standardized UV scoring; public leaderboards with strict FPR/κ criteria
- Assumptions/dependencies: governance, anti-gaming measures, reproducible task environments
Notes on feasibility across applications:
- UV’s gains are architectural; swapping to stronger LLMs alone did not match its performance. Successful deployment depends on replicating its design choices (rubric quality, process/outcome split, controllable/uncontrollable taxonomy, relevance-based context management).
- Cost and latency scale with trajectory length and LLM size; for production use, consider batched scoring, top‑k evidence selection, and eventual distillation to smaller reward models.
- Privacy and compliance constraints may require on-prem deployments or rigorous redaction.
Glossary
- Ablations: Targeted experiments that remove or vary components to assess their impact on performance. "We conduct two additional ablations of the Universal Verifier"
- Action history: The sequence of actions taken by the agent during a trajectory. "and judges success using only the top- selected screenshots and the full action history."
- Agentic RAG: Retrieval-augmented generation carried out by autonomous agents in multi-step settings. "Others extend to agentic RAG domains~\citep{zhang2025processoutcome}."
- Auto-research agent: An automated system that iteratively edits prompts/code and runs experiments to improve a method. "We also find that an auto-research agent achieves 70\% of expert quality in 5\% of the time"
- Backbone LLM: The underlying LLM used to power a component or pipeline. "we vary the backbone LLMs of the UV end-to-end (each model generates and scores its own rubric)"
- Cascading errors: Failures where one upstream mistake triggers multiple downstream penalties across dependent criteria. "Cascading errors. When rubric criteria are not logically independent, a single upstream error propagates into downstream criteria"
- Cascading-error-free strategy: A scoring approach that prevents early obstacles from unfairly penalizing all subsequent steps. "distinguishing between controllable and uncontrollable failures scored via a cascading-error-free strategy"
- Cohen's kappa: A statistic measuring inter-rater agreement that corrects for chance agreement. "as measured by Cohen's "
- Conditional criteria: Rubric items that apply only under certain real-world conditions and are excluded otherwise. "Conditional Criteria: Some criteria may not apply depending on reality"
- Context window: The maximum amount of text and images an LLM can consider in a single input. "assess a large amount of screenshots in one LLM context window"
- Controllable factors: Failure causes attributable to the agent’s decisions or effort, which should be penalized in process scoring. "Controllable factors: Avoidable mistakes the agent should be penalized for in process."
- Diagnostic report: A structured output that classifies and localizes failures within a trajectory. "a diagnostic report that classifies and localizes failures within ."
- Divide-and-conquer context management scheme: A strategy that partitions and focuses evidence to attend to all screenshots in long trajectories. "a divide-and-conquer context management scheme that attends to all screenshots in a trajectory"
- Error taxonomy: A predefined classification of failure types used for analysis and diagnosis. "We hand-crafted an error taxonomy with 7 categories and 24 subcodes"
- False negative rate (FNR): The fraction of successful cases incorrectly judged as failures. "FNR drops sharply from 0.32 to 0.09."
- False positive rate (FPR): The fraction of failures incorrectly judged as successes. "We report a reduction in false positive rates to near zero"
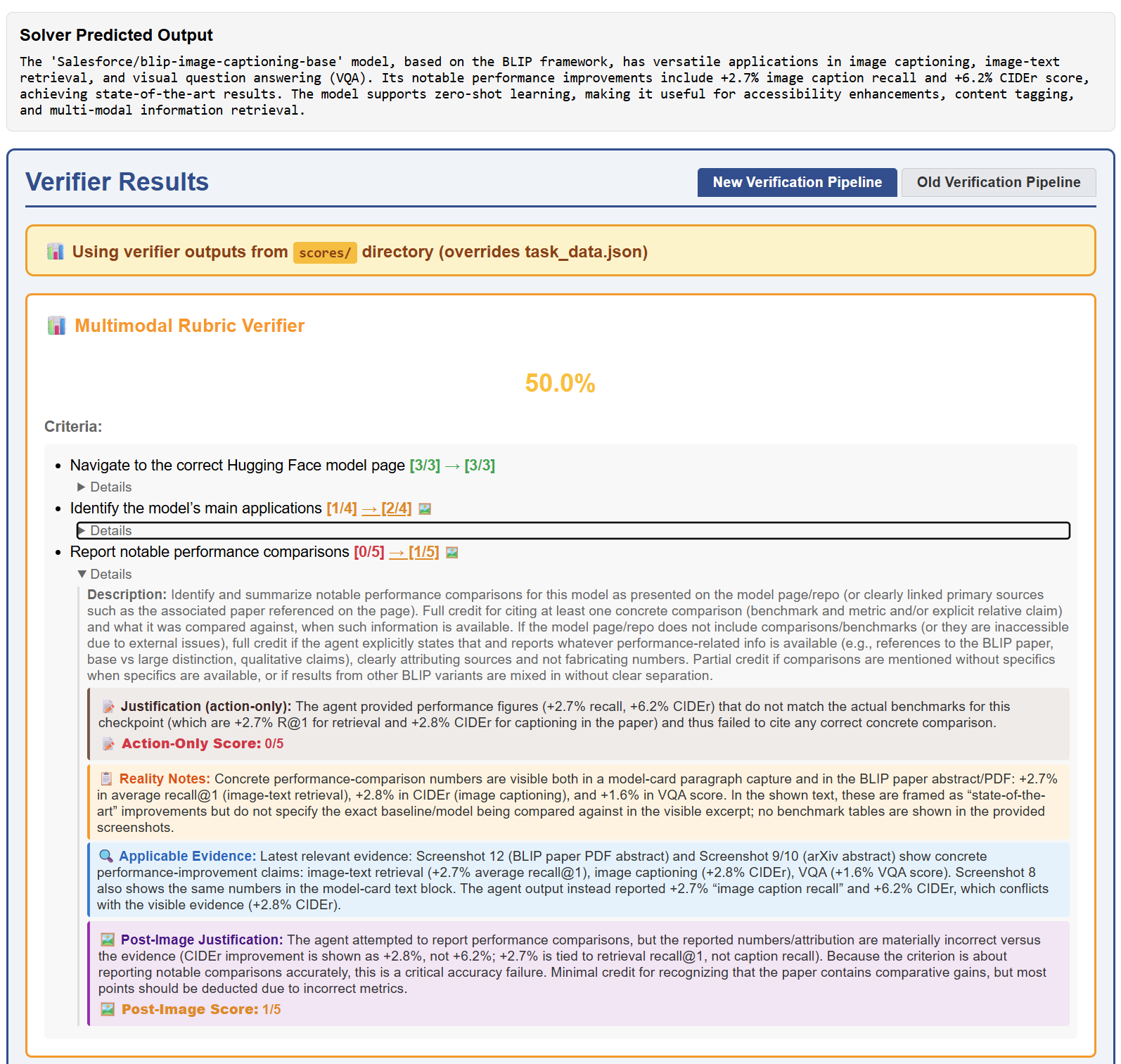
- Hallucination: Claims of success or information not supported by the available evidence. "Hallucinations: claiming success without evidence, fabricating information."
- Human oracle: The gold-standard human annotator used as the reference for measuring verifier quality. "agreement with a human oracle "
- Inter-annotator agreement: The consistency of labels provided by different human annotators. "Human inter-annotator agreement was 89.3\%."
- LLM-based judge: An evaluator implemented as a prompted LLM that outputs trajectory judgments. "no LLM-based judge exceeds 70\% precision"
- Normalized score: A score scaled to a fixed range (e.g., [0,1]) relative to maximum attainable points. "It is reported as a normalized score from 0.0 to 1.0"
- Outcome label: The binary decision about whether a reasonable user would consider the task done. "The outcome label is a binary yes/no judgment"
- Outcome reward: The signal indicating whether the user’s goal was achieved (success/failure). "report both process and outcome rewards---these provide complementary signals"
- Process label: The continuous rubric-based score reflecting execution quality across sub-goals. "Process Label (Rubric Score):"
- Process reward: The signal that evaluates how well the agent followed correct steps, independent of success. "a process reward (a fine-grained rubric whose score reflects execution across sub-goals)"
- Relevance matrix: A matrix of scores relating each screenshot to each rubric criterion to focus evidence. "produce relevance matrix "
- Rubric: A task-specific set of non-overlapping, weighted criteria used to score agent behavior. "The root of the pipeline is rubric generation"
- Set-of-Marks Agent: An agent prompting paradigm that structures reasoning and actions into enumerated marks. "GPT-5 as a Set-of-Marks Agent~\citep{yang2023setofmarkpromptingunleashesextraordinary}"
- Token overload: Overwhelming an LLM by passing too many tokens (e.g., all screenshots) in one input. "token overload from passing all screenshots unfiltered."
- Top-: Selecting the k most relevant items (e.g., screenshots) per criterion for further analysis. "judges success using only the top- selected screenshots"
- Trajectory: The ordered sequence of observations and actions collected while the agent operates. "producing a trajectory "
- Uncontrollable factors: Environmental conditions outside the agent’s control that should not reduce process credit. "Uncontrollable factors: Conditions beyond the agent's control; not penalized in process."
- Unsolicited side-effects: Extraneous agent actions with material consequences that were not requested by the task. "Unsolicited Side-Effects"
- Verifier: A function that maps a goal and trajectory to scores and diagnostics assessing success and quality. "We define a verifier as a function "
- Visual evidence: Information extracted from screenshots used to support or refute rubric criteria. "extract visual evidence ."
Collections
Sign up for free to add this paper to one or more collections.