- The paper introduces a human-annotated dataset for verifiable, long-chain GUI tasks with subtask-level supervision.
- It details a robust data pipeline combining LLM-based instruction generation with human annotation to create diverse and realistic GUI tasks.
- Experimental results reveal significant performance gaps in current agents, highlighting challenges in long-horizon planning and error recovery.
VeriGUI: A Verifiable Long-Chain GUI Dataset for Generalist Agent Evaluation
Motivation and Problem Statement
The development of autonomous agents capable of executing complex tasks in graphical user interface (GUI) environments has advanced rapidly, driven by progress in multimodal LLMs (MLLMs) and the increasing demand for generalist agents that can operate across diverse digital platforms. However, the evaluation and training of such agents have been constrained by the limitations of existing datasets, which predominantly focus on short-horizon tasks and rely on outcome-only verification. This restricts the assessment of agents' abilities in long-horizon planning, multi-step reasoning, and robust error recovery—capabilities essential for real-world deployment.
VeriGUI addresses these deficiencies by introducing a large-scale, human-annotated dataset specifically designed for verifiable, long-chain GUI tasks. The dataset emphasizes two critical dimensions: (1) long-chain complexity, with tasks decomposed into interdependent subtasks spanning hundreds of steps, and (2) subtask-level verifiability, enabling fine-grained evaluation and open-ended exploration strategies.
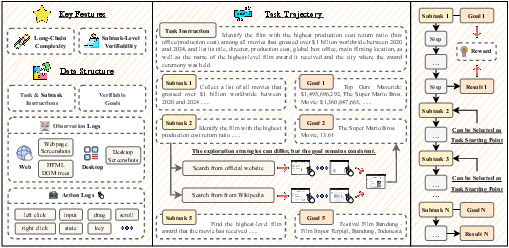
Figure 1: An overview of the VeriGUI dataset, which emphasizes (1) long-chain complexity, where each task consists of interdependent subtasks that span hundreds of steps, with each subtask serving as a valid starting point; and (2) subtask-level verifiability, enabling diverse exploration strategies while ensuring that the goal of each subtask is verifiable and consistent.
Dataset Construction and Structure
VeriGUI tasks are formalized as POMDPs, with the environment state, partial observations (screenshots, DOM trees for web; screenshots for desktop), a unified action space (click, drag, scroll, input, key events), and a reward function defined at the subtask level. Each task trajectory is decomposed into K subtasks, each with its own sub-instruction and verifiable goal function G(k), providing binary supervision and supporting dense, intermediate feedback.
Data Collection Pipeline
The data collection process combines LLM-based instruction generation with rigorous human annotation. Seed instructions are expanded via LLMs, then curated and decomposed into subtasks by human annotators. Demonstrations are collected through manual execution, with detailed action and observation logs, and strict quality control ensures the correctness and consistency of subtask outcomes.
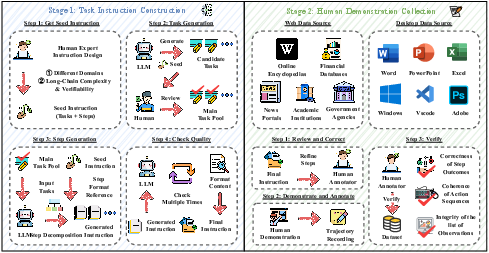
Figure 2: An overview of the proposed VeriGUI framework, consisting of two stages: task instruction construction and human demonstration collection. The framework combines LLM-based generation with human annotation to ensure realistic, high-quality GUI tasks and demonstrations.
Task Diversity
VeriGUI encompasses both web and desktop tasks. Web tasks focus on deep research scenarios requiring multi-hop information retrieval and reasoning, while desktop tasks emphasize application operation, state management, and complex GUI interactions. The dataset covers a broad range of domains, including scientific research, finance, technology, arts, and social policy.

Figure 3: The VeriGUI dataset consists of various GUI tasks spanning both desktop and web.
Statistical Properties
The initial release includes 130 web task trajectories, each averaging 214.4 steps and 4.5 subtasks, with ongoing expansion to desktop tasks. The action distribution covers a wide range of GUI operations, and the subtask structure supports intermediate supervision and evaluation.
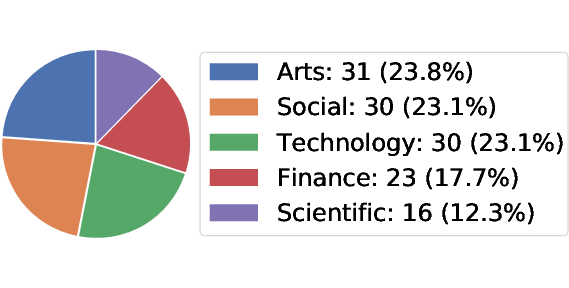
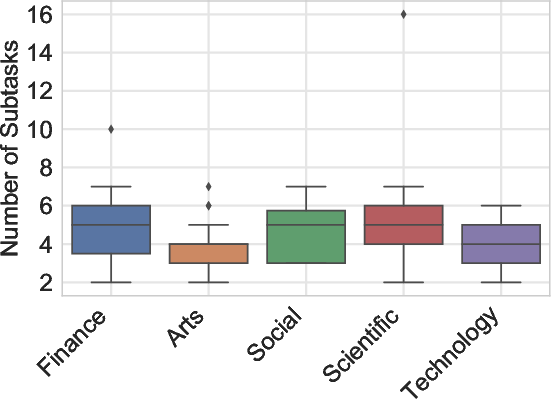
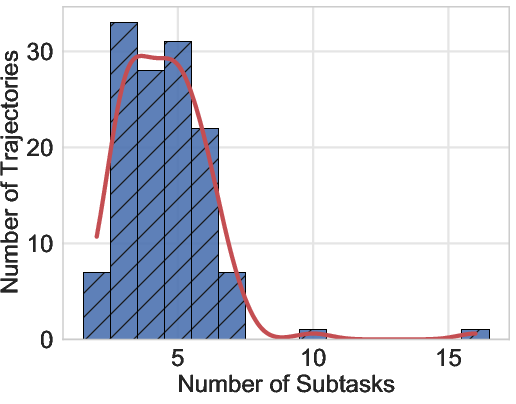
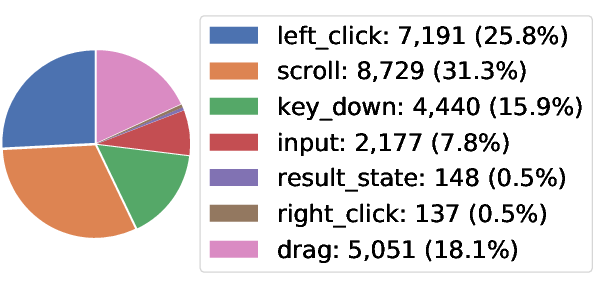
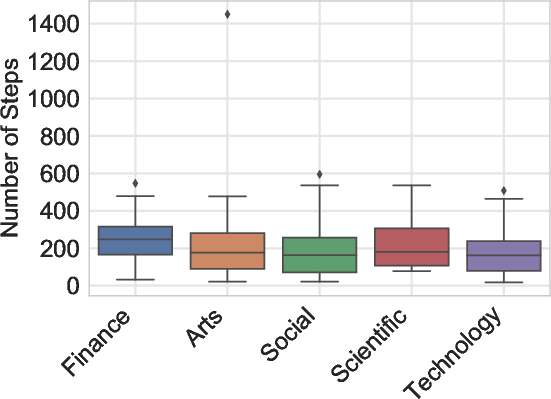
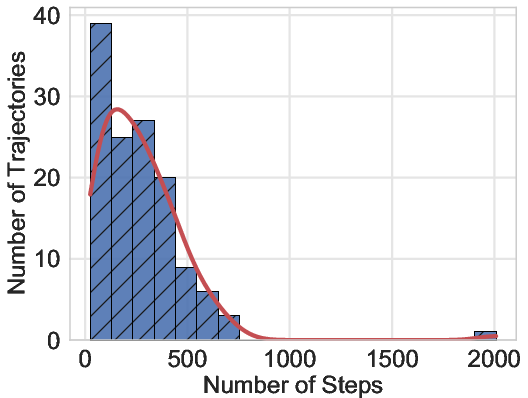
Figure 4: The detailed data statistics of the proposed VeriGUI dataset based on 130 collected web task trajectories, with additional data including desktop task trajectories currently in process.
Experimental Evaluation
Baselines and Metrics
A comprehensive benchmark is established using a diverse set of agent frameworks and foundation models, including deep research agents (e.g., OpenAI Deep Research, Gemini Deep Research), search engine agents (LLMs with retrieval tools), browser-use agents (web element operations), and multi-agent systems (e.g., Camel OWL). Evaluation metrics include:
- Task Success Rate (SR): Binary measure of overall task completion.
- Task Completion Rate (CR): Proportion of correct elements in the output, providing granularity for partially completed tasks.
- Action Efficiency (AE): Number of steps required for successful completion, reflecting planning effectiveness.
Main Results
Across all agent types and models, the results reveal a substantial performance gap on long-chain tasks:
- No configuration achieves an average SR above 10% or CR above 30%.
- Deep research agents (OpenAI-o3, Gemini-2.5-Pro) achieve the highest average SR (8.5%) and CR (28.8%, 28.1%).
- Search engine and browser-use agents perform significantly worse, with most models achieving SRs between 0.8–5.4% and CRs below 18.3%.
- Domain analysis shows that tasks in arts and entertainment are relatively more tractable, while finance and social policy domains are particularly challenging.
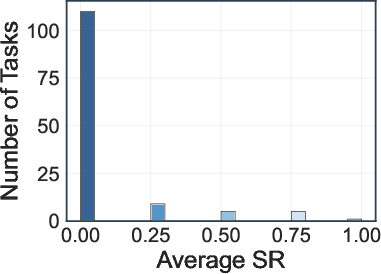
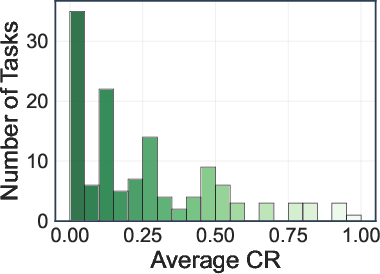
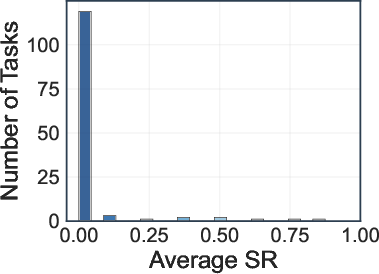
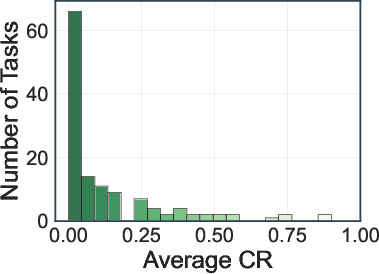
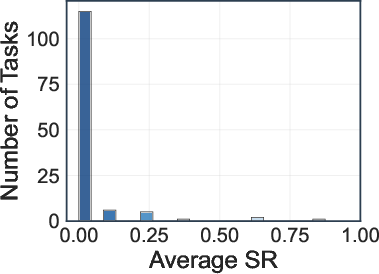
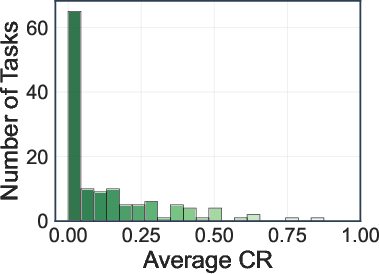
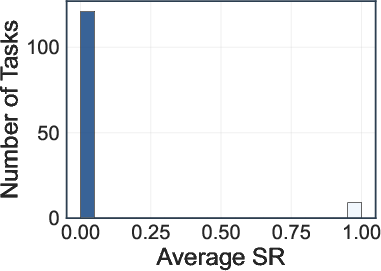
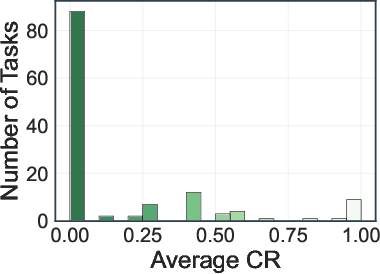
Figure 5: Distribution of task success rate (SR) and completion rate (CR) across 130 web tasks.
Analysis of Task Difficulty and Agent Behavior
A fine-grained analysis categorizes tasks into five difficulty levels based on SR and CR. The majority of tasks fall into levels with zero SR, indicating high complexity and partial achievability. Action efficiency analysis shows that lower action counts do not always correlate with higher success, as some models exhibit brittle reasoning despite efficient execution.
Case studies highlight typical failure modes, including misinformation, incomplete results, retrieval failures, and irrelevant outputs. Agents often terminate prematurely or fail to extract precise information, underscoring the need for improved long-horizon planning and robust error recovery.
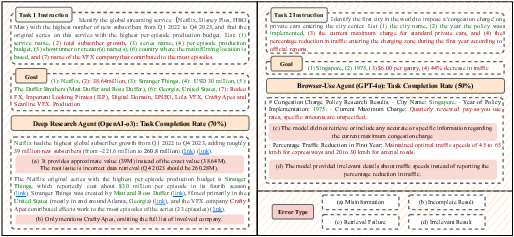
Figure 6: Case studies of agent performance on two web tasks in VeriGUI.
Implications and Future Directions
Practical Implications
VeriGUI exposes the limitations of current agent architectures in handling long-horizon, multi-step GUI tasks. The dataset's subtask-level verifiability and open-ended interaction design provide a foundation for developing agents with advanced planning, memory, and decision-making capabilities. The results suggest that:
- Deep research agents currently outperform browser-based GUI agents in information-seeking tasks, but lack the ability to perform interactive GUI operations.
- GUI agents, while underperforming in the current benchmark, are essential for tasks requiring interface manipulation and generalization across platforms.
Theoretical Implications
The persistent performance gap highlights the need for new algorithmic advances in hierarchical planning, memory-augmented architectures, and multimodal perception. The subtask-level supervision in VeriGUI enables research into curriculum learning, error localization, and fine-grained credit assignment in RL and imitation learning settings.
Future Developments
The expansion of VeriGUI to include more interactive web tasks and complex desktop workflows will enable a more comprehensive evaluation of generalist agents. The dataset's design supports research into unified agent architectures capable of seamless operation across heterogeneous digital environments. As agent frameworks mature, leveraging subtask-level feedback and dense supervision will be critical for closing the gap between human and agent performance in real-world GUI tasks.
Conclusion
VeriGUI represents a significant step toward rigorous, fine-grained evaluation of generalist GUI agents. By introducing long-chain complexity and subtask-level verifiability, it provides a challenging benchmark that exposes the limitations of current models and motivates the development of more capable, robust, and generalizable agents. The open-sourcing of VeriGUI is expected to catalyze further research into interactive, multimodal agent intelligence and accelerate progress toward practical, general-purpose digital assistants.