- The paper presents a fully open-source framework for computer-use agents that integrates a cross-OS demonstration tool, large-scale dataset, and reflective long Chain-of-Thought reasoning.
- It details a rule-based action reduction pipeline that converts raw user interactions into meaningful state-action pairs with accurate visual grounding.
- Experimental results show significant performance improvements over prior models, establishing new state-of-the-art success rates on both offline and GUI grounding benchmarks.
OpenCUA: Open Foundations for Computer-Use Agents
Motivation and Problem Statement
The automation of computer-use tasks by vision-LLMs (VLMs) has become a central research focus, with Computer-Use Agents (CUAs) demonstrating the ability to perform complex workflows across diverse applications and operating systems. However, the most capable CUA systems remain proprietary, with closed datasets, architectures, and training recipes, impeding reproducibility, safety analysis, and further progress. Existing open-source efforts are hampered by the lack of scalable, diverse data collection infrastructure, limited dataset scope, and insufficient modeling transparency. OpenCUA addresses these deficiencies by providing a fully open-source framework for CUA research, encompassing annotation tools, large-scale datasets, advanced data processing pipelines, and state-of-the-art agent models.
OpenCUA Framework Overview
OpenCUA is structured around four core components: (1) AgentNet Tool for cross-OS demonstration capture, (2) AgentNet Dataset, a large-scale, diverse collection of computer-use trajectories, (3) a scalable data processing and reasoning augmentation pipeline, and (4) end-to-end agent models trained with reflective long Chain-of-Thought (CoT) reasoning.
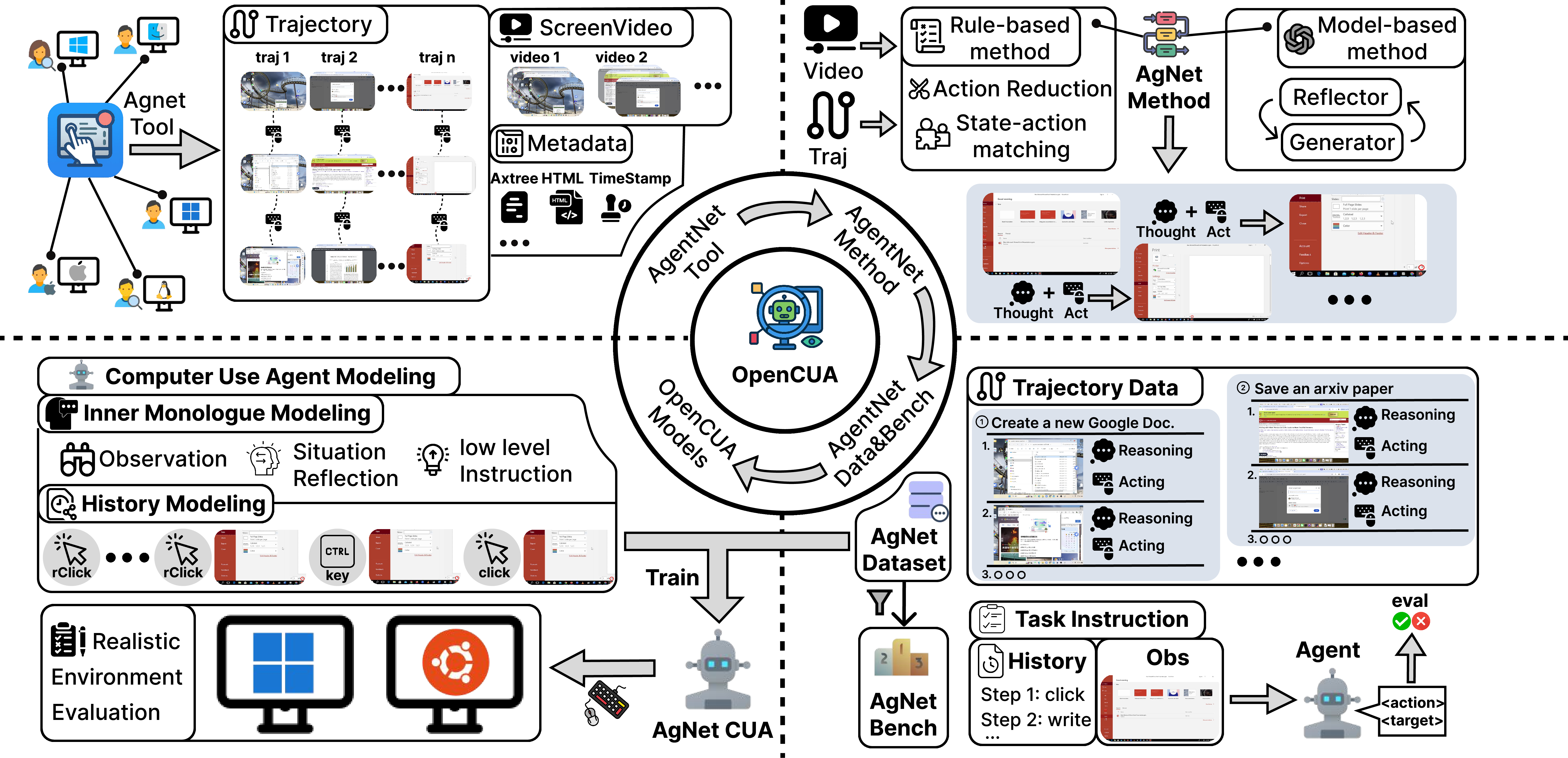
Figure 2: Overview of the OpenCUA framework, from data collection to model training and evaluation.
The AgentNet Tool enables seamless, minimally intrusive recording of human computer-use demonstrations across Windows, macOS, and Ubuntu. It captures screen videos, mouse/keyboard events, and accessibility trees, supporting naturalistic, unconstrained user behavior. The resulting AgentNet Dataset comprises 22,625 trajectories (average 18.6 steps), spanning over 140 applications and 190 websites, with a focus on diversity and complexity (multi-app workflows, professional tools, uncommon features).
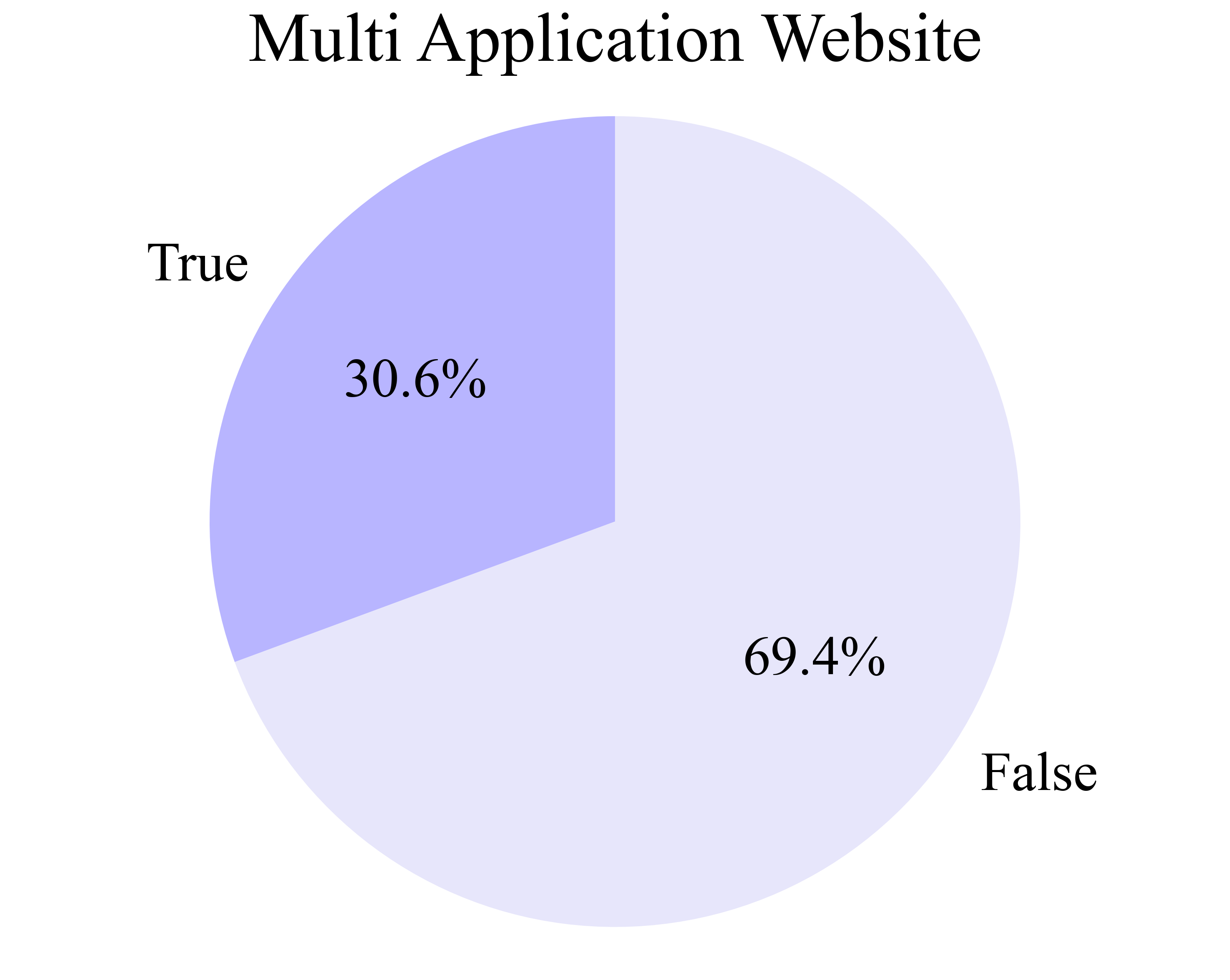
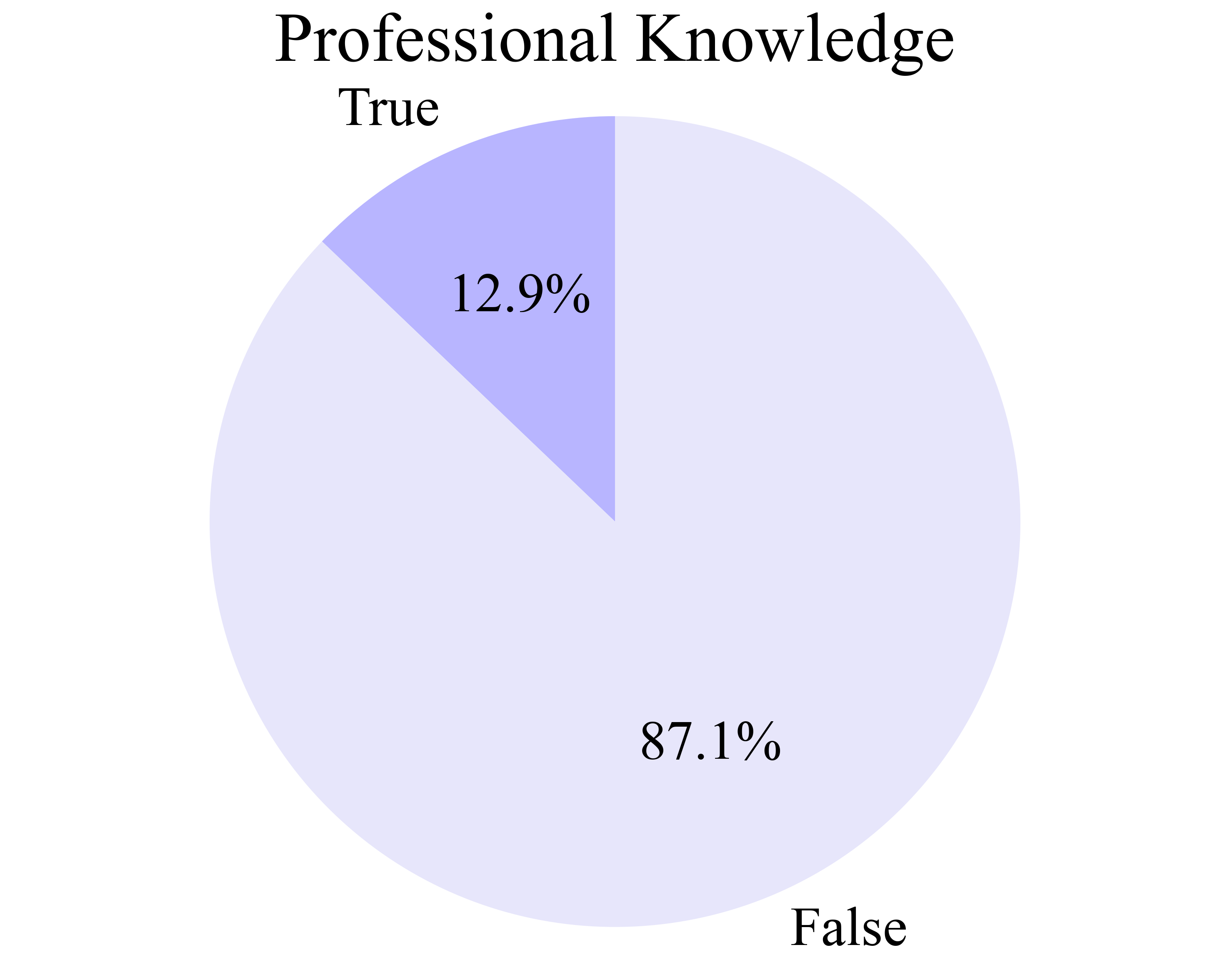
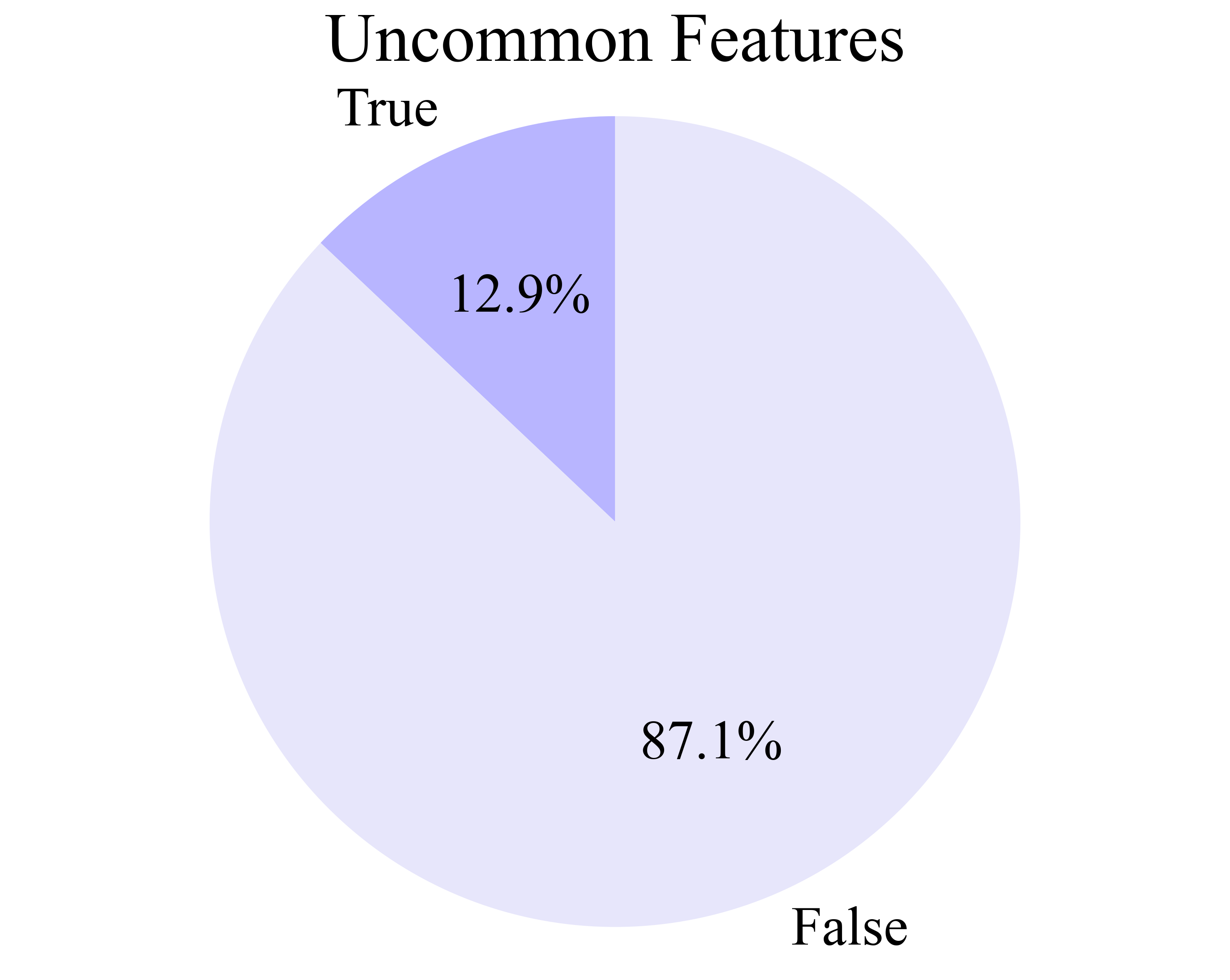
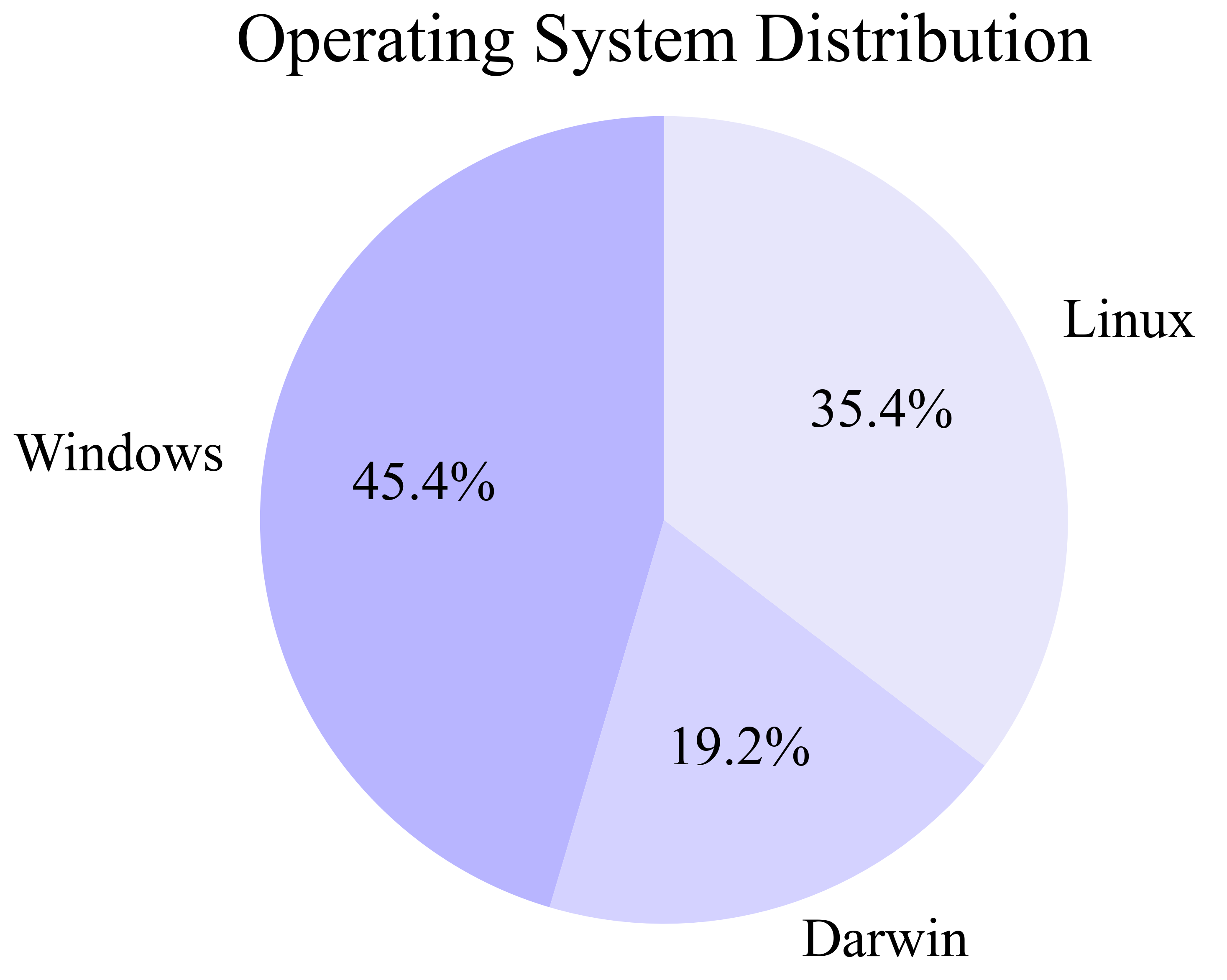
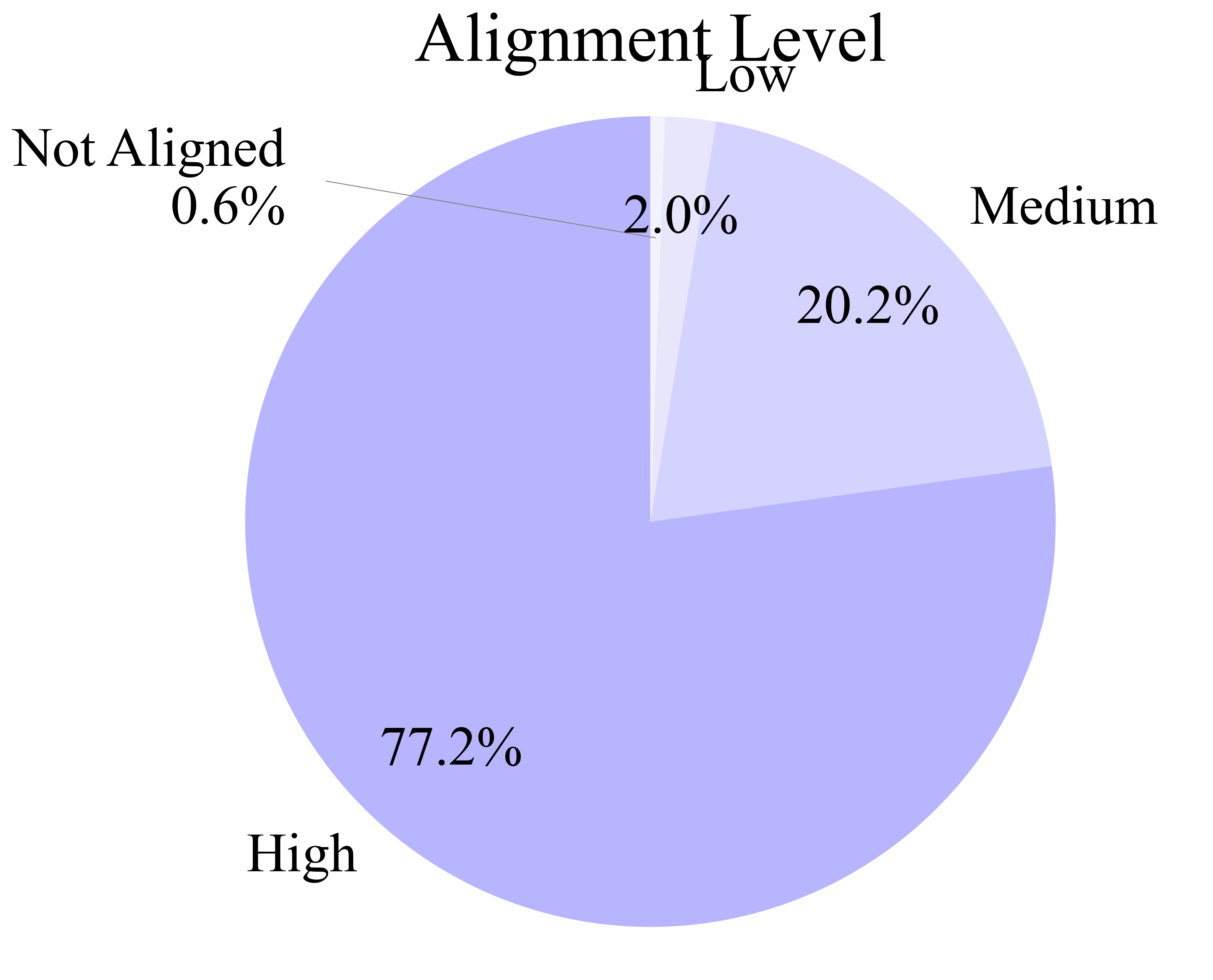
Figure 4: Distributions of data characteristics in AgentNet, including multi-application workflows, professional knowledge, and OS diversity.
Data Processing: Action Discretization and State-Action Matching
Raw demonstrations are transformed into compact state-action pairs via a rule-based action reduction pipeline, compressing high-frequency atomic events into semantically meaningful actions (e.g., click, drag, hotkey, write). State-action matching aligns each action with a representative pre-action screenshot, using backtracking to avoid future information leakage. This yields a training-ready dataset suitable for vision-language modeling.
Reflective Long Chain-of-Thought Reasoning
A key innovation is the synthesis of reflective long CoT reasoning for each state-action pair. The CoT is hierarchically structured: L3 (contextual observation), L2 (reflective reasoning with planning, memory, and error correction), and L1 (executable action). The pipeline employs a generator-reflector-summarizer architecture, where the reflector identifies errors and generates reflection traces, the generator produces structured reasoning, and the summarizer refines task goals and scores trajectories.
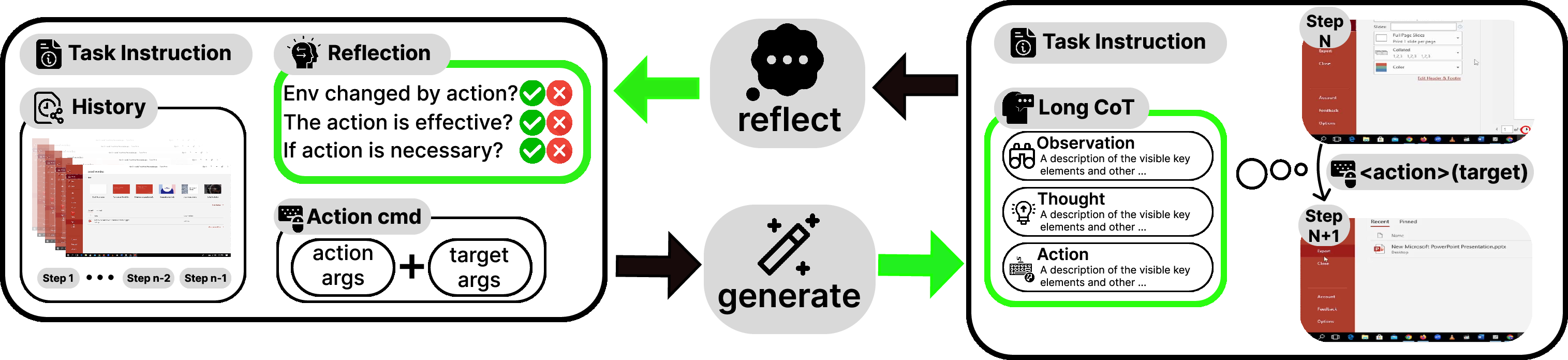
Figure 1: Reflective long CoT synthesis pipeline, with iterative generation and verification of reasoning components.

Figure 5: Example of reflective long CoT, where the model identifies and corrects a prior mistake before predicting the next action.
Model Training and Data Mixtures
OpenCUA models are trained via supervised fine-tuning (SFT) on mixtures of CoT-augmented trajectories, grounding data, and general vision-language SFT data. Three training strategies are explored: (1) Stage 2 only (CUA data + general SFT), (2) Stage 1 + Stage 2 (grounding then planning), and (3) joint training. The models leverage both textual and visual history (multi-image context), with ablations showing that three screenshots and concise L1 textual history provide the best trade-off between performance and efficiency.
Experimental Results
OpenCUA-32B achieves a 34.8% success rate (100 steps) on OSWorld-Verified, surpassing all prior open-source models and outperforming OpenAI CUA (GPT-4o-based). OpenCUA-7B achieves 26.7%, also establishing a new SOTA at the 7B scale. Performance scales with both model and data size, and the pipeline generalizes across architectures (MoE and dense) and OS domains.
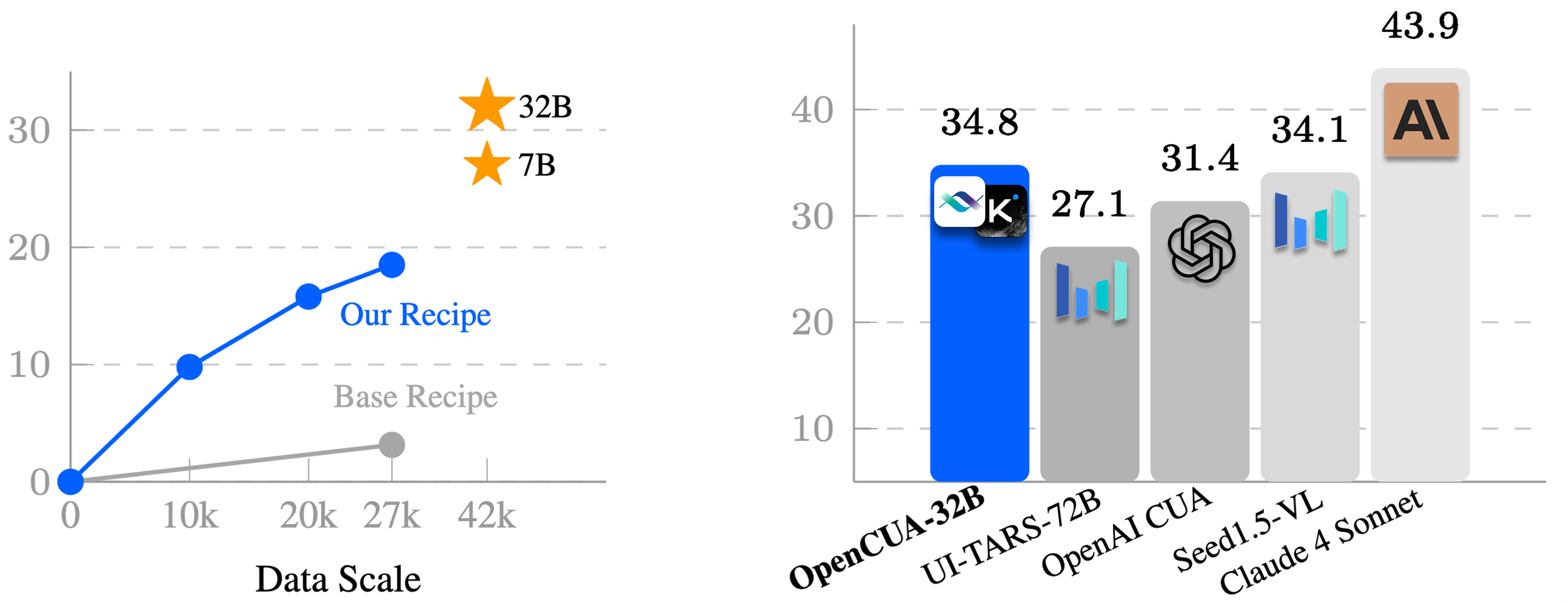
Figure 6: OSWorld-Verified performance scaling with data and model size; OpenCUA-32B outperforms all open-source and some proprietary models.
Offline and GUI Grounding Benchmarks
On AgentNetBench (offline), OpenCUA-32B achieves 79.1% average step success rate, with strong performance on both coordinate and content actions. On GUI grounding benchmarks (OSWorld-G, Screenspot-V2, Screenspot-Pro), OpenCUA-32B consistently ranks first among open-source models, demonstrating robust visual grounding and high-resolution understanding.
Data Scaling and Generalization
Performance exhibits strong scaling laws with both in-domain and out-of-domain data. Cross-platform training improves generalization, and even out-of-domain data (e.g., Windows data for Ubuntu tasks) yields substantial gains, indicating minimal negative transfer.
Figure 8: Clustering and t-SNE visualization of task domains, illustrating the diversity and coverage of AgentNet.
Ablation and Analysis
- Reflective long CoT: Ablations show that reflective long CoT yields a 33% relative improvement over short CoT, primarily by enhancing error correction and recovery.
- CoT mixture: Training with a mixture of L1, L2, and L3 CoT outperforms L2-only or L1-only training, despite L2 being optimal at inference.
- General SFT data: Incorporating general-domain text data provides a measurable boost to agentic performance, improving instruction understanding and generalization.
- Test-time compute: Pass@n evaluation reveals a large gap between Pass@1 and Pass@16, indicating substantial headroom for reranking and multi-agent methods.
Practical and Theoretical Implications
OpenCUA establishes a reproducible, extensible foundation for CUA research, enabling systematic study of agent capabilities, limitations, and risks. The open release of tools, data, and models facilitates benchmarking, safety analysis, and rapid iteration. The demonstrated scaling laws and cross-domain generalization suggest that further gains are achievable with larger, more diverse data and models. The reflective long CoT methodology provides a template for integrating planning, memory, and self-correction into agentic VLMs, with implications for robustness and reliability in real-world deployments.
Limitations and Future Directions
The primary bottleneck remains human annotation cost, despite the streamlined AgentNet Tool. Selection bias is introduced by ethical consent requirements. Future work should explore semi-automated or synthetic data augmentation, improved privacy-preserving data collection, and more advanced error recovery mechanisms. The persistent gap to proprietary models at large scale highlights the need for continued scaling and architectural innovation.
Conclusion
OpenCUA delivers a comprehensive, open-source framework for computer-use agents, addressing critical gaps in data, infrastructure, and modeling transparency. The framework demonstrates strong empirical performance, clear scaling laws, and robust generalization, providing a solid foundation for future research on autonomous digital agents. By releasing all components, OpenCUA enables the community to rigorously investigate the capabilities, limitations, and societal impacts of CUAs as they become increasingly integrated into digital workflows.