Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Abstract: Recent advances in Deep Research Agents (DRAs) are transforming automated knowledge discovery and problem-solving. While the majority of existing efforts focus on enhancing policy capabilities via post-training, we propose an alternative paradigm: self-evolving the agent's ability by iteratively verifying the policy model's outputs, guided by meticulously crafted rubrics. This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements. We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories. We present DeepVerifier, a rubrics-based outcome reward verifier that leverages the asymmetry of verification and outperforms vanilla agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score. To enable practical self-evolution, DeepVerifier integrates as a plug-and-play module during test-time inference. The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrapping, refining responses without additional training. This test-time scaling delivers 8%-11% accuracy gains on challenging subsets of GAIA and XBench-DeepResearch when powered by capable closed-source LLMs. Finally, to support open-source advancement, we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification. These examples emphasize reflection and self-critique, enabling open models to develop robust verification capabilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A 14-year-old’s Guide to “Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification”
What is this paper about?
This paper is about making smart computer agents better at researching things on the internet and solving multi-step problems. Instead of only training them more, the authors teach these agents to check their own work while they’re answering a question—like a student carefully grading their own homework with a checklist and then fixing mistakes. Their system for doing this is called DeepVerifier.
What questions are the researchers asking?
In simple terms, the paper explores:
- Can an agent improve its answers by checking itself during the test (not just during training)?
- Is it easier to check an answer than to generate it from scratch, and can we use that to help the agent?
- If we give the agent a clear grading guide (a “rubric”), can it give better feedback and fix its own mistakes?
- Will this self-checking loop actually boost scores on tough tests?
- Can we help open-source models (free models anyone can use) learn this self-checking skill with a special training set?
How did they do it? (Methods explained simply)
Think of a “Deep Research Agent” (DRA) as a digital researcher: it reads webpages, collects facts, reasons through steps, and writes an answer. These agents can be wrong for lots of reasons (bad sources, misreading, jumping to conclusions, tool errors). The authors build a system that helps the agent catch and correct those errors at test time.
Here’s the approach, with everyday analogies:
- Build a map of common mistakes (a “failure taxonomy”)
- They watched many agent attempts and listed the most common ways agents mess up.
- This list is like a coach’s playbook of “things to watch out for.”
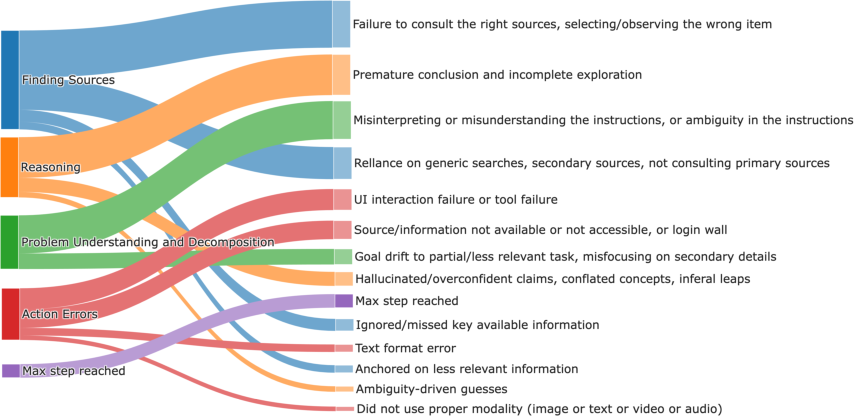
- The big mistake families they found include:
- Finding Sources (e.g., wrong website, missing key evidence)
- Reasoning (e.g., wrong conclusion, overconfident claims)
- Understanding the Problem (e.g., misunderstanding the question)
- Actions/Tools (e.g., clicking the wrong button, wrong file format)
- Running out of steps (getting stuck and timing out)
- Turn that map into a grading checklist (rubrics)
- A rubric here is just a structured checklist teachers use to grade fairly.
- The agent uses this rubric to judge answers and write focused feedback.
- Use the “checking is easier than solving” trick (asymmetry of verification)
- Solving a hard problem from scratch is tough.
- But checking specific claims is often much easier (for example: “Does the official report say the number is 2.3%?”).
- So instead of redoing the whole task, the system breaks the check into small questions that can be verified with evidence.
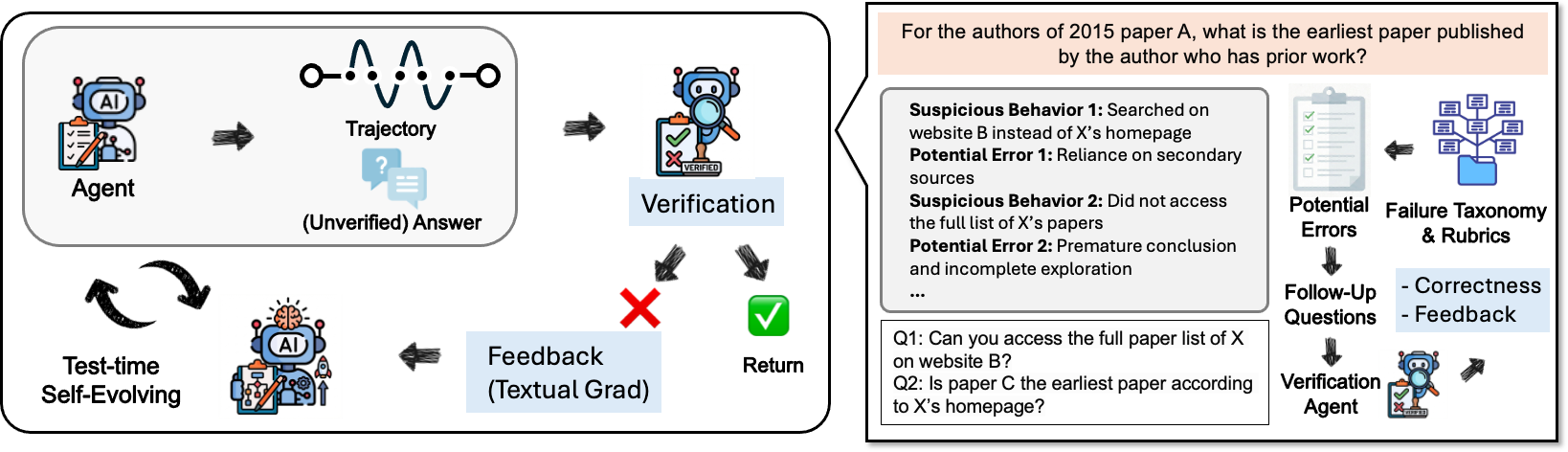
- The DeepVerifier pipeline (three helpful roles)
- Decomposition agent: Summarizes what happened and breaks the big answer into smaller, checkable questions (like “Does source X really say Y?”).
- Verification agent: Looks up evidence for those small questions (searching the web, opening files, taking screenshots).
- Judge agent: Reads the evidence and gives a simple score (1–4) plus clear feedback and suggestions to fix the answer.
- Self-improvement at test time (no extra training needed)
- The agent answers a question, DeepVerifier checks it with the rubric, gives feedback, and the agent tries again.
- This loop repeats a few times (usually only a handful of rounds are needed).
- Training open models to reflect
- They also released a training set called DeepVerifier-4K (4,646 examples) focused on reflection and self-critique.
- Using it, they fine-tuned an open model (DeepVerifier-8B) to get better at verification and feedback.
What did they find, and why does it matter?
Main results (on tough benchmarks like GAIA and XBench-DeepSearch):
- Better judging of answers: DeepVerifier beats standard “LLM-as-judge” and simple agent judges by about 12%–48% in F1 score (a balance of precision and recall). That means it’s more reliable at telling correct from incorrect answers.
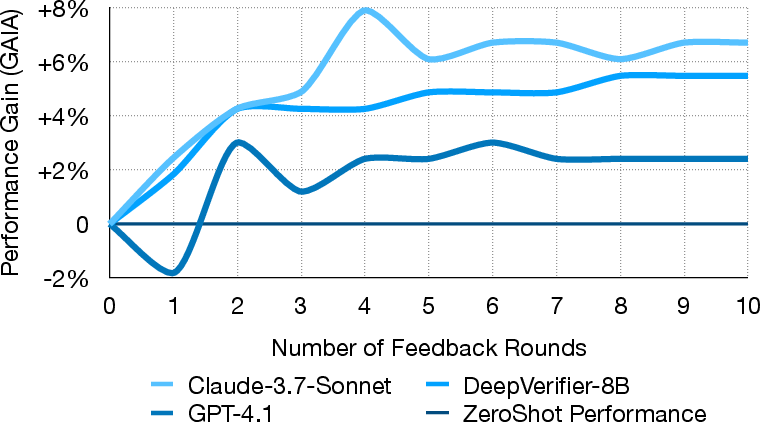
- Self-checking boosts accuracy: When the agent uses DeepVerifier’s feedback for a few rounds, accuracy goes up:
- On hard web-search parts of GAIA, accuracy rose by about 8%–11% with strong models.
- On other datasets, gains of about 3%–6% were observed.
- Works across models and tasks: Improvements show up with different LLMs and on different kinds of problems (web browsing, reasoning, files).
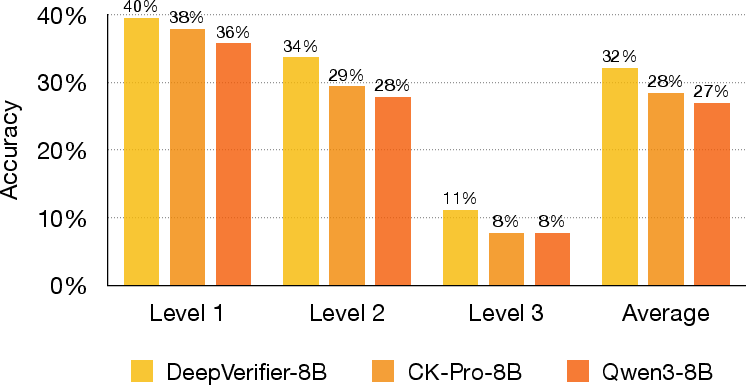
- Open-source models get smarter with the new dataset: After fine-tuning on DeepVerifier-4K, the open model (DeepVerifier-8B) improved by around 5–6 points after reflection, doing better than similar open models without this training.
Why the “few rounds” pattern?
- Early rounds fix many mistakes (wrong → right).
- Later, a few correct answers might get unfairly rejected (right → wrong) due to imperfect judging.
- So performance typically peaks after a small number of feedback rounds.
What’s the big picture? (Implications)
- More reliable AI researchers: Agents that check themselves with clear rubrics can produce better, more trustworthy answers without needing extra training each time.
- Practical and scalable: Because it works at test time, you can plug this into existing systems and get immediate gains.
- Helps the open community: The new dataset (DeepVerifier-4K) and a fine-tuned model (DeepVerifier-8B) help open-source tools catch up, encouraging wider and fairer access.
- Real-world impact: From looking up accurate facts to writing reports or analyzing files, self-verifying agents can reduce errors, save human supervision time, and make AI tools safer and more useful.
In short, the paper shows a simple but powerful idea: teach AI agents to be their own careful graders using a good checklist, and have them fix their work step by step. This makes them smarter, more accurate, and more dependable on tough, real-world tasks.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The following list summarizes the missing, uncertain, and unexplored aspects of the paper that future researchers could investigate:
- Generalization of the failure taxonomy: validate coverage and transferability across diverse agents, domains (beyond WebAggregatorQA), tasks (coding, data analysis), languages, and modalities.
- Clarity of “automatic” taxonomy construction: reconcile the claim of automatic construction with manual annotation; fully document the pipeline, criteria, iteration protocol, and inter-annotator agreement beyond overlap percentage (e.g., Cohen’s κ).
- Rubric design and derivation: specify how rubrics are mapped from taxonomy subclasses, their granularity, and how rubric weighting affects judgments; test adaptive or dynamically updated rubrics under distribution shift.
- Decomposition module quality: quantify the number, specificity, and discriminative power of follow-up questions; compare hand-crafted prompts vs. learned decomposition strategies; measure sensitivity to prompt variants.
- Formalization of verification asymmetry: develop metrics to quantify when verification is easier than generation; identify task classes where asymmetry fails and propose mitigation.
- Multi-modal verification: evaluate verification of image/video content (e.g., charts, OCR, screenshots), measure reliability on visual claims, and design modality-specific rubrics and tools.
- Source reliability and conflict resolution: define policies for prioritizing primary vs. secondary sources, resolving conflicting evidence, and handling unreliable or adversarial content; incorporate calibrated trust models.
- Web dynamics and accessibility: assess robustness to paywalls, CAPTCHAs, client-side rendering, rate limits, personalization, and regional restrictions; propose reproducible page snapshotting.
- Computational cost and latency: report token usage, wall-clock time, API costs, and step counts per verification round; provide cost–accuracy trade-off analyses and guidelines for practical deployment.
- Stopping criteria and convergence: design principled stopping conditions (confidence thresholds, marginal gain tests) to avoid regressions and diminishing returns observed after ~4 rounds.
- Calibration of the judge: justify the 1–4 scoring scale and acceptance mapping (≥3 = correct); provide calibration curves, ROC/AUC, and threshold robustness analyses.
- Baseline breadth and statistical rigor: include more verification baselines (programmatic checkers, retrieval-based judges, human evaluation), report confidence intervals/significance tests, and ensure matched compute.
- Cross-model robustness: reduce dependence on Claude-3.7-Sonnet (used in trajectory generation and verification); test with varied closed/open models to identify model-specific biases or overfitting.
- Per-category impact analysis: quantify which taxonomy subclasses are most reduced by DeepVerifier; identify persistent failure modes and tailor rubrics or tools accordingly.
- Handling ambiguous or multi-answer tasks: evaluate judge behavior when tasks admit multiple valid answers or evolving ground truth; design rubrics to avoid unfair rejections.
- Impact on trajectory length and agent behavior: measure whether verification reduces “Max Step Reached,” goal drift, or redundant actions; analyze changes in planning and tool-use strategies.
- Integration with other test-time scaling methods: study combinations with best-of-N, majority vote, ToT/CoT search, or ensembles; compare additive vs. redundant gains.
- Robustness to adversarial or noisy web content: test on misinformation, SEO spam, and conflicting sources; develop adversarial verification benchmarks and defenses.
- Multi-lingual and cross-lingual verification: extend beyond Chinese (XBench-DeepSearch) to more languages; evaluate cross-lingual source aggregation and rubric adaptation.
- Toolchain dependence: assess portability beyond CK-Pro (different agent frameworks, tool APIs, sandboxing); standardize verifier interfaces and logging for reproducibility.
- Prompt sensitivity and stability: perform prompt ablations for decomposition, verification, and judge modules; explore automated prompt optimization or instruction tuning.
- Learning-to-verify beyond SFT: compare supervised fine-tuning with RL using rubric rewards, synthetic hard negatives, and counterfactual data; study sample efficiency and stability.
- Dataset quality and licensing: audit DeepVerifier-4K for label errors (especially from model-generated verification), domain balance, adversarial cases, and licensing/consent for included web content.
- Risk of catastrophic forgetting: quantify how SFT on DeepVerifier-4K affects base capabilities (reasoning, coding); design training curricula to preserve general skills.
- Security and safety considerations: analyze risks from executing code, automating web actions, and handling sensitive data; propose sandboxing, access controls, and ethical safeguards.
- Privacy and compliance: document how trajectory summaries and web snapshots are stored and anonymized; assess compliance with data protection regulations (e.g., GDPR).
- Reproducibility gaps: provide missing training hyperparameters, inference settings, and seeds; release code for summarization, decomposition, verification, and judge orchestration.
- Offline verification and caching: explore caching of verified evidence, snapshotting, and provenance tracking to reduce cost and increase reproducibility across runs.
- Acceptance threshold tuning under cost constraints: optimize the 1–4 score threshold jointly with round budgets to maximize net utility (accuracy gain per dollar/second).
- Failure when follow-up questions are unanswerable: detect and handle cases where evidence is unavailable or inconclusive; design “uncertainty-aware” judges that avoid erroneous rejections or acceptances.
- Scalability to large benchmarks and real deployments: test on larger GAIA splits and live production settings; report operational metrics (SLA compliance, throughput) and failure recovery strategies.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s plug-and-play, test-time, rubric-guided verification (DeepVerifier), its failure taxonomy, and the released DeepVerifier-4K + DeepVerifier-8B resources. Reported gains (e.g., +8–11% on GAIA subsets; +12–48% meta-eval F1 over LLM/agent judges) indicate practical uplift without retraining the main agent model.
Software and AI Tooling
- Verified agent output gate for production LLM agents
- Sector: Software, enterprise AI platforms
- What: Insert DeepVerifier as a “verification gate” after agent responses. Use 1–4 judge scores to accept (≥3), return rubric-based feedback, and trigger controlled retries (e.g., up to 4 rounds).
- Tools/workflows/products: “Verification middleware” for existing agents; SDK/adapter for CogKernel-Pro/SmolAgents; acceptance thresholds; retry controllers; evidence cards attached to answers.
- Assumptions/dependencies: Access to browsing/tool APIs for verification; added inference-time budget; careful prompt/round limits to avoid regressions noted after ~4 rounds.
- Upgrade agent-as-a-judge components
- Sector: Software evaluation stacks, MLOps
- What: Replace generic LLM judges with rubric- and taxonomy-guided verification to reduce false accepts, particularly for subtle reasoning and evidence errors.
- Tools/workflows/products: Judge microservice; rubric editor; taxonomy-driven critique templates; meta-evaluation dashboards with precision/recall/F1 tracking.
- Assumptions/dependencies: Domain-specific rubric customization; consistent evaluation datasets for calibration.
- CI/CD for agents (verification tests)
- Sector: Software, DevOps for agents
- What: Add verification tests to agent pipelines to prevent regressions in browsing, reasoning, and tool-use; fail builds if verification F1 drops.
- Tools/workflows/products: “Agent unit tests” using DeepVerifier-4K-style cases; nightly GAIA/XBench subsets; release gates.
- Assumptions/dependencies: Curated test suites; compute budget for periodic verification runs.
Information and Media
- Newsroom fact-checking and source corroboration
- Sector: Media, content platforms
- What: Use decomposition to check claims (“Does source X state Y?”), attach evidence snippets and rubric-based notes to articles or drafts.
- Tools/workflows/products: Editorial assistant plugin; evidence dossiers; claim-by-claim confidence cards.
- Assumptions/dependencies: Access to paywalled/authorized sources; link rot handling; editorial review remains final arbiter.
- Misinformation triage for platforms
- Sector: Trust & Safety
- What: Rapid, structured verification passes on trending claims; escalate low-score items to human fact-checkers with localized error summaries.
- Tools/workflows/products: Triage queues, rubric heatmaps by failure category (e.g., “secondary-source dependence”); policy-aligned rubrics.
- Assumptions/dependencies: Coverage across languages (supported by XBench-DeepSearch results but still needs localized rubrics); governance for intervention thresholds.
Finance and Legal
- Analyst copilot for filings and earnings call verification
- Sector: Finance
- What: Validate extracted numbers, dates, and statements from 10-K/10-Qs and earnings transcripts; force follow-up checks on “risky” claims.
- Tools/workflows/products: Filings ingestor with verification layer; discrepancy flags; evidence links to filing sections.
- Assumptions/dependencies: Reliable access to EDGAR/filing vendors; time-boxed verification loops to control latency.
- Contract and brief review with rubric anchors
- Sector: Legal
- What: Use domain rubrics (e.g., clause coverage, risk, compliance references) and follow-up questions to verify presence/accuracy of key terms and citations.
- Tools/workflows/products: Clause-verifier plugin; audit trails with taxonomy labels; “evidence required” gates before sign-off.
- Assumptions/dependencies: Domain-specific rubrics from legal teams; confidentiality and on-prem deployment options.
Healthcare and Life Sciences
- Evidence-grounded medical assistant for non-diagnostic workflows
- Sector: Healthcare (non-clinical decision support)
- What: Verify guideline references, coding justifications, and administrative documentation; flag generic or outdated sources.
- Tools/workflows/products: Verification gate for guideline lookup tasks; citation checkers; claim-specific follow-up prompts.
- Assumptions/dependencies: Strict scope (no autonomous clinical decisions); access to trusted guideline repositories; compliance (HIPAA/GDPR).
- Systematic review support
- Sector: Research, pharma
- What: Validate extracted outcomes and study metadata with targeted follow-up questions; annotate failure modes (e.g., misinterpretation, missing critical evidence).
- Tools/workflows/products: Review copilot with per-claim evidence cards; taxonomy-based error logs.
- Assumptions/dependencies: Paywalled access and full-text availability; human reviewer remains in-loop.
Education and Academia
- Citation and number verification for literature reviews
- Sector: Academia, scholarly publishing
- What: Check that cited sources actually support claims and figures; produce “evidence cards” with quotes and links.
- Tools/workflows/products: Reference verifier for LaTeX/Word; pre-submission checkers; arbiter scorecards (1–4).
- Assumptions/dependencies: Access to publisher APIs; disambiguation of editions/versions.
- Rubric-guided grading assistants
- Sector: Education
- What: Use structured rubrics and failure taxonomy to evaluate student responses, highlight missing reasoning steps, and suggest targeted feedback.
- Tools/workflows/products: LMS integration; per-criterion scoring; retry suggestions.
- Assumptions/dependencies: Instructor-defined rubrics; privacy-preserving deployment.
Customer Support and Enterprise Knowledge
- Verified answer generation from enterprise KBs
- Sector: Customer support, internal IT
- What: Add a verification loop to ensure answers cite the correct, current KB entries; auto-retry if score ≤2.
- Tools/workflows/products: Helpdesk copilot with verification gate; freshness checks; evidence attachment in tickets.
- Assumptions/dependencies: Up-to-date KB indexing; guardrails for unsupported queries.
Public Sector and Policy
- Policy brief and press release fact-checking
- Sector: Government, NGOs
- What: Validate statistics and references before publication; attach transparent evidence dossiers.
- Tools/workflows/products: “Pre-brief check” workflow; rubric templates aligned to policy domains (health, energy, education).
- Assumptions/dependencies: Source provenance tracking; multilingual coverage when required.
Daily Life
- Personal fact-checking for health, travel, and shopping claims
- Sector: Consumer
- What: Verify key claims in itineraries (fees, visa rules), product comparisons, and general health information; provide per-claim evidence.
- Tools/workflows/products: Browser extensions; mobile assistant with “verify this” action; evidence cards.
- Assumptions/dependencies: Website access; clarity on regional variations and fast-changing info (e.g., travel rules).
Data and Model Development
- Fine-tuning open models for reflection with DeepVerifier-4K
- Sector: Model development, OSS
- What: Use the released dataset to train internal 7–13B models for verification/reflection (as shown by DeepVerifier-8B gains).
- Tools/workflows/products: SFT recipes combining CK-Pro + DeepVerifier-4K; evaluation harnesses on GAIA/XBench.
- Assumptions/dependencies: Compute availability; data licensing; domain adaptation for specialized tasks.
Long-Term Applications
These applications may require further research, domain-specific rubrics, scaling, or regulatory alignment to become mainstream.
Cross-Domain, Regulated, and High-Stakes AI
- Domain-specialized verifiers with auditable trails
- Sectors: Healthcare (clinical), finance, aviation, energy
- What: Train verifiers on regulated corpora and domain rubrics; produce machine-checkable audit logs for compliance and liability.
- Tools/products: “Safety-grade” Verification-as-a-Service; auditable evidence graphs; certification support.
- Dependencies: Regulatory approval; robust provenance tracking; bias and coverage assessments; robust multilingual support.
- Contractual and regulatory compliance copilot
- Sectors: Finance, healthcare, public sector
- What: Continuous verification of obligations, thresholds, and reporting across documents and data streams.
- Tools/products: Compliance dashboards; automated exception workflows; regulator-facing reports.
- Dependencies: Up-to-date regulation knowledge; access to sensitive systems; secure on-prem/hybrid deployments.
Self-Evolving Agent Systems
- Persistent self-improvement loops beyond single tasks
- Sector: Software, agent platforms
- What: Accumulate verification outcomes and rubrics as intrinsic feedback to improve policy models across sessions (beyond test-time).
- Tools/products: Memory stores of failure modes; curriculum generation from verification logs; offline RL from verification signals.
- Dependencies: Stable data pipelines; safety controls to prevent overfitting to narrow rubrics; governance for continuous learning.
- Chain-of-verifiers and committee oversight
- Sector: Safety-critical AI, AGI oversight
- What: Ensembles of specialized verifiers (reasoning, sourcing, math, modality) with adjudication to reduce correlated failures.
- Tools/products: Verifier orchestration frameworks; confidence calibration; adversarial “red team” verifiers.
- Dependencies: Cost/latency constraints; conflict resolution strategies; monitoring for failure cascades.
Science and Scholarly Ecosystem
- Automated pre-publication checks in journals
- Sector: Academic publishing
- What: At submission, verify numerical claims, reference support, and data availability; return structured checklists to authors/reviewers.
- Tools/products: Publisher APIs; integrated reviewer dashboards; reproducibility flags.
- Dependencies: Access to manuscripts/data; domain rubrics; community buy-in.
- Living systematic reviews with continuous verification
- Sector: Evidence-based medicine, social science
- What: Keep reviews current by periodically verifying if new sources confirm/refute claims; trigger updates.
- Tools/products: Review maintenance pipelines; drift detection; claim lifecycle tracking.
- Dependencies: Longitudinal source access; versioning; human-in-the-loop governance.
Enterprise Knowledge and Operations
- Enterprise “truth service” layer
- Sector: Horizontal (all industries)
- What: A central verification service that other apps call to validate facts, metrics, and citations before surfacing to users or customers.
- Tools/products: Internal Verification APIs; SLA-backed verification queues; organization-specific rubrics.
- Dependencies: Data access controls; PII handling; budget for shared compute.
- Procurement and vendor due diligence
- Sector: Public sector, large enterprises
- What: Verify claims in RFP responses (certifications, references, financials) using targeted follow-up questions and evidence packs.
- Tools/products: Diligence copilot; risk scoring with rubric tags; audit archives.
- Dependencies: Authentic source access; anti-fraud checks; multilingual corpora.
Consumer and Civic Tech
- Community fact-checking platforms with transparent evidence cards
- Sector: Civic tech, media literacy
- What: Crowd workflows augmented with agentic verification; standardized evidence presentation for public scrutiny.
- Tools/products: Open evidence ledger; reusable rubric templates; API for claim widgets.
- Dependencies: Moderation; preventing brigading; sustainable funding.
Infrastructure and Efficiency
- Hardware/software co-design for verification-heavy workloads
- Sector: AI infra
- What: Optimize retrieval + multi-round verification at scale (e.g., batching, caching, lighter verifiers).
- Tools/products: Verification accelerators; cost-aware scheduling; memory of prior “verified facts.”
- Dependencies: Workload characterization; platform-level integrations.
- Data generation pipelines for reflection training
- Sector: Model development
- What: Auto-curate domain-specific DeepVerifier-style datasets to train new reflection-capable models.
- Tools/products: Data distillation from verification logs; rubric mining tools; synthetic-hard-case generators.
- Dependencies: Quality control; label noise mitigation; domain adaptation.
Notes on assumptions and dependencies across applications:
- Verification requires reliable access to primary sources, tools (browsers, APIs), and may be constrained by paywalls, rate limits, and privacy/compliance rules.
- Inference-time scaling increases latency and cost; practical deployments should cap rounds (empirically ~4 often optimal) and calibrate acceptance thresholds.
- Rubrics and taxonomies must be adapted per domain/language; oversight remains essential in high-stakes settings.
- Reported gains are benchmark-based; real-world distributions and drift may require additional tuning and monitoring.
Glossary
- Ablation study: An experiment that removes or alters components of a system to measure their impact on performance. "We conduct an ablation study using the trajectories of the CK-Pro agent with a Claude-3.7-Sonnet backbone on the GAIA-Web dataset"
- Agent-as-judge: A paradigm where an agent (or LLM) evaluates the correctness or quality of another agent’s output. "outperforms vanilla agent-as-judge and LLM judge baselines"
- Agentic pipeline: A structured, multi-step process orchestrated by agents to perform complex tasks end-to-end. "we present DeepVerifier, an agentic pipeline for automatically verifying the success of DRA output and provide feedbacks based on the rubrics."
- Asymmetry of verification: The idea that checking correctness is often easier than generating the correct solution, enabling more reliable evaluation. "we exploit the asymmetry of verification to decompose complex problems into simpler sub-tasks"
- Best-of-N selection: A test-time strategy that samples multiple candidate outputs and picks the best according to a criterion. "proposes Best-of-N selection, majority vote, etc."
- BrowseComp: A benchmark focused on evaluating agents’ ability to retrieve difficult, entangled information via browsing. "BrowseComp measures agents' ability to retrieve extremely hard-to-find and entangled information."
- Cognitive Kernel-Pro (CK-Pro): An open-source, multi-module deep research agent framework used for orchestration and tool use. "We use Cognitive Kernel-Pro~\cite{fang2025cognitivekernelpro}, a high-performing fully open-source multi-module DRA framework"
- Decomposition agent: A module that breaks a complex verification or reasoning problem into smaller, targeted sub-questions. "The decomposition agent leverages previous trajectories and the DRA failure taxonomy to exploit the asymmetry of verification."
- Deep Research Agents (DRAs): Autonomous systems powered by LLMs/VLMs designed for multi-step research tasks such as web browsing, coding, and analysis. "Recent advances in Deep Research Agents (DRAs), powered by LLMs and vision-LLMs (VLMs), are transforming automated knowledge discovery and complex problem-solving."
- DeepVerifier-4K: A curated supervised fine-tuning dataset of agent verification steps aimed at training reflection and critique. "we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification."
- DRA Failure Taxonomy: A structured classification of common deep research agent failures into major categories and sub-categories. "We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories."
- GAIA benchmark: A comprehensive evaluation suite testing reasoning, multimodality, browsing, and tool-use capabilities. "We evaluate DeepVerifier on the GAIA benchmark~\citep{Mialon2023GAIAAB}, which assesses core abilities including reasoning, multimodality, web browsing, and tool use."
- Inference-time scaling of verification: Improving agent performance by increasing verification effort during inference, often via iterative feedback. "This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements."
- Iterative bootstrapping: A process where feedback is repeatedly fed back into the agent to refine answers without further training. "The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrappingârefining responses without additional training."
- Judge agent: A component that evaluates answers and assigns correctness scores based on gathered evidence and rubric criteria. "This framework consists of a decomposition agent, a verification agent, and a judge agent."
- LLM judge: A LLM used to automatically evaluate outputs or trajectories. "outperforms vanilla agent-as-judge and LLM judge baselines"
- Long-horizon tasks: Problems requiring many steps, actions, or pages of evidence, often making human supervision impractical. "In long-horizon tasks involving dozens of pages and hundreds of actions, online human supervision becomes infeasible."
- Majority vote: A selection strategy that chooses the output agreed upon by most samples/rollouts. "proposes Best-of-N selection, majority vote, etc."
- Meta-evaluation F1 score: The F1 metric used to assess the quality of evaluators (e.g., verifiers or judges) rather than task solutions directly. "by 12\%â48\% in meta-evaluation F1 score."
- Multimodality: Handling multiple input/output modalities (e.g., text, images) within a single system. "which assesses core abilities including reasoning, multimodality, web browsing, and tool use."
- Narrative-driven aggregation: Combining information from multiple iterations using a coherent narrative to improve final decisions. "employed narrative-driven aggregation across iterations."
- Optimal trajectory search: Searching over multiple action sequences (trajectories) to find the most promising solution path. "introduced parallel sampling for optimal trajectory search"
- Outcome-based rewards: Evaluation signals derived from the final outcome or answer quality rather than intermediate steps. "derive structured rubrics for outcome-based rewards."
- Outcome reward verifier: A verifier that scores outputs based on outcome-focused criteria defined by rubrics. "a rubrics-based outcome reward verifier"
- Parallel rollouts: Running multiple independent executions of an agent to diversify candidate solutions. "selection across parallel rollouts."
- Parallel sampling: Generating multiple candidate trajectories or outputs in parallel for selection or aggregation. "introduced parallel sampling for optimal trajectory search"
- Plug-and-play module: A component that can be integrated into an existing system at inference time without retraining. "DeepVerifier integrates as a plug-and-play module during test-time inference."
- Reflexion: A method where agents generate and use textual self-feedback to improve subsequent attempts. "Despite existence of Reflexion~\citep{shinn2023reflexion}-based methods use textual feedback"
- Rubrics-based rewards: Structured, criteria-driven evaluation signals that guide verification or learning. "we incorporate rubrics-based rewards~\citep{gunjal2025rubrics, huang2025reinforcementrubrics} to provide structured, discriminative signals"
- Supervised fine-tuning (SFT): Training a model on labeled input–output pairs to specialize capabilities. "a high-quality supervised fine-tuning (SFT) dataset comprising 4,646 prompt-response pairs"
- Test-time inference: The phase when a model or agent is applied to new inputs (without further training). "during test-time inference."
- Test-time scaling: Improving performance by allocating more computation or iterations at inference time. "This test-time scaling delivers 8\%â11\% accuracy gains"
- Test-time self-evolution pipeline: A verify–feedback–retry loop applied during inference to iteratively improve answers. "A more robust test-time self-evolution pipeline involves (1) verifying generated outputs, (2) producing targeted feedback upon detecting errors, and (3) iterating with this feedback."
- Trajectory: The sequence of actions, observations, and decisions made by an agent while solving a task. "we first collect problem-solving trajectories from a representative deep research agent."
- Verification agent: A module that retrieves and checks evidence to confirm or refute claims in an answer. "In our experiment, we use the CK-Pro agent~\cite{fang2025cognitivekernelpro} as the verification agent"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs. "powered by LLMs and vision-LLMs (VLMs)"
- WebAggregatorQA: A benchmark for multi-domain information aggregation used to collect and analyze agent trajectories. "Trajectories are generated by running the agent on WebAggregatorQA~\cite{Wang2025ExploreTE}"
- XBench-DeepSearch: A benchmark (including non-English tasks) for evaluating search/tool-use capabilities. "3--6\% improvements on the XBench-DeepSearch dataset."
Collections
Sign up for free to add this paper to one or more collections.