- The paper introduces E-valuator, converting black-box verifier scores into sequential tests with provable false alarm (type I error) control.
- It employs density ratio estimation and test martingales to detect unsuccessful agent trajectories early across diverse settings.
- Empirical results demonstrate significant token usage efficiency and robust statistical power compared to traditional verifier thresholding methods.
E-valuator: Statistically Reliable Agent Verification via Sequential Hypothesis Testing
Evaluating agentic AI systems—agents that autonomously perform sequences of actions—poses significant reliability challenges, especially in high-stakes applications where error rates must be provably controlled. Existing approaches employ black-box verifier models, such as LLM judges or process-reward models, to assign instantaneous trust scores to agent trajectories. However, when these heuristic scores are thresholded to flag unsuccessful trajectories, there exist no guarantees on type I error (i.e., the false alarm rate), particularly in online or sequential settings where agents' action sequences are of variable and unknown length.
This paper frames agent verification as an online sequential hypothesis testing problem. The central question is: given a sequence of verifier scores, how can one decide as early as possible, and with guarantees on false positive rates, whether the agent will yield a correct final outcome? The E-valuator method offers a statistical wrapper to convert any black-box verifier’s scores into decision rules with provable, anytime-valid false alarm control.
Methodology: Sequential Hypothesis Testing with E-Processes
Given calibration data comprising sequences of verifier scores from successful and unsuccessful trajectories, E-valuator proceeds as follows:
- Density Ratio Estimation: The method models the data-generating distributions of verifier scores for successful (p1) and unsuccessful (p0) trajectories. Since direct access to these distributions is unavailable, E-valuator employs Bayes-based classifier density ratio estimation. Logistic regression is typically used, though any probabilistic classifier is compatible.
- Sequential Testing Statistic Construction: At each timestep t, it computes the estimated density ratio M^t=p1(S[1:t])p0(S[1:t]) using the learned discriminative model. This statistic forms a test martingale, i.e., an e-process, ensuring that Ville's inequality gives a rigorous upper bound on the type I error under the null hypothesis (success).
- Threshold Determination: Two approaches are proposed:
- Using cα=1/α ensures anytime-valid type I error control for arbitrarily long action sequences.
- A quantile-based approach (PAC-threshold) leverages held-out calibration data and allows for a less conservative threshold, reflecting finite expected trajectory lengths, still achieving high probability error control.
- Online Decision Policy: At each timestep, if M^t≥cα, the trajectory is flagged as unsuccessful and can be terminated early. If the threshold is never crossed, the agent is deemed successful upon trajectory completion.
Empirical Results and Analysis
A comprehensive evaluation is conducted across six datasets—including mathematical reasoning (GSM8k, MATH), general and medical QA (HotpotQA, MedQA, MMLU-Pro), and chess games—with four agent-verifier pairings, spanning LLM-based and non-LLM agents. Comparisons include raw and calibrated verifier baselines and Bonferroni-corrected sequential tests.
1. False Alarm Rate Control and Power
E-valuator demonstrates robust empirical false alarm rate control on GSM8k and MATH datasets for both the 1/α and PAC-threshold variants, while achieving high statistical power.
(Figure 1)
Figure 1: GSM8k and MATH: E-valuator tightly controls false alarm and achieves optimal power among valid testing strategies.
Notably, the raw and calibrated verifier baselines often inflate the false alarm rate above the nominal α value, especially in longer sequences, while E-valuator tightly adheres to error control constraints.
2. Efficiency in Token Usage
In resource-constrained deployment, early termination of detected unsuccessful trajectories is essential to reduce computational and annotation costs. On the MATH and MMLU-Pro datasets, E-valuator achieves up to 86% of baseline total accuracy using only 81% of the tokens—a substantial reduction in inference cost relative to alternative methods that require nearly the full budget for similar accuracy restoration.
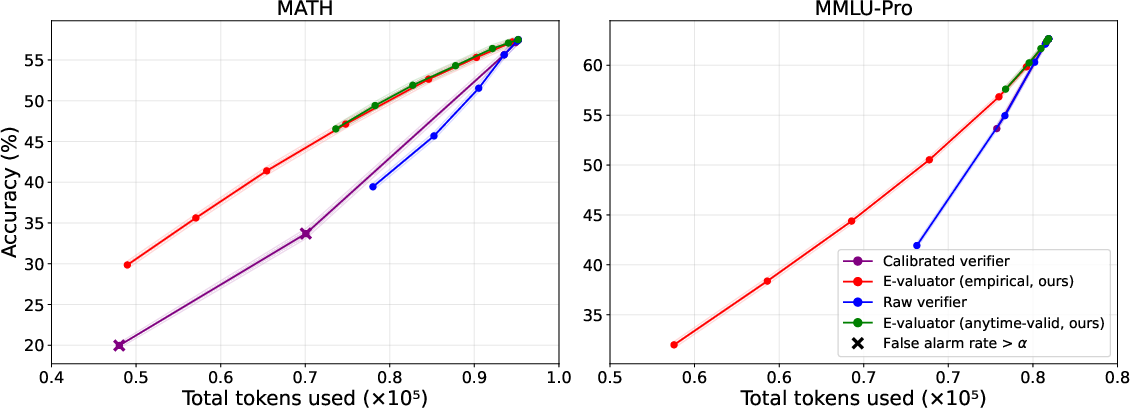
Figure 2: E-valuator achieves a superior trade-off between retained accuracy and token usage compared to verifier-based thresholding.
E-valuator recovers a large fraction of correct predictions with fewer tokens than both raw and calibrated alternatives, resulting in improved efficiency and cost savings in practical deployment.
3. Calibration Set Size and Robustness
Empirical analysis indicates the method is robust to calibration set size, consistently controlling false alarm rates across a range of calibration fractions, except at extremely small calibration sizes (1% of data, or 50 labeled trajectories on MATH), where variance increases.
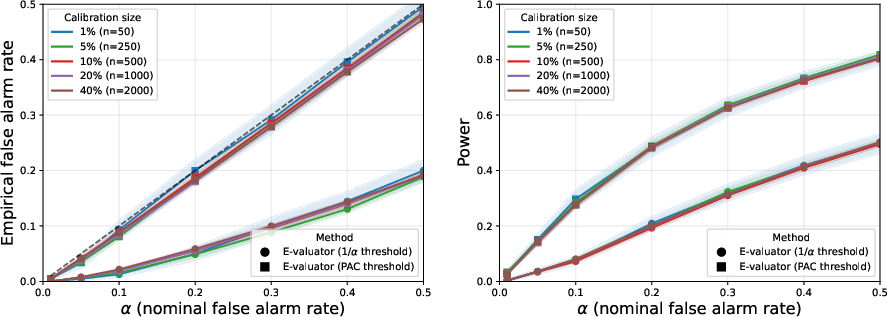
Figure 3: On MATH, false alarm control is largely stable for varied calibration set sizes; control degrades only for minimal data.
4. Sequential Rejection Dynamics
Inspection of individual sequence trajectories reveals that, in mathematical reasoning tasks, many unsuccessful trajectories are detected rapidly—often after the first step—highlighting the discriminative power of early actions. In contrast, for deterministic settings such as chess, separation between successful and unsuccessful sequences emerges more gradually.
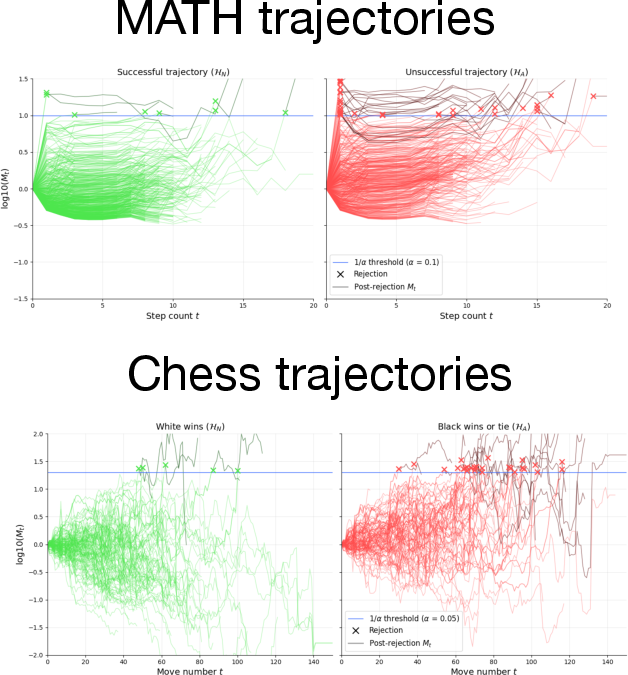
Figure 4: Example Mt trajectories: For MATH, early steps are highly informative for rejection; for chess, trend separation is more gradual.
Theoretical Guarantees
The approach leverages foundational results from sequential hypothesis testing and the theory of e-processes. Under the true data-generating distribution, the sequential density ratio statistic Mt is a test martingale. Ville's inequality ensures that, for any user-chosen α∈(0,1), the probability that a successful trajectory is incorrectly flagged at any point is bounded by α, independent of trajectory length.
Moreover, the density ratio martingale is log-optimal among all e-processes in terms of growth under the alternative hypothesis, akin to the Neyman-Pearson lemma for classical testing. This ensures maximal power for detecting failures, given accurate density ratio estimation.
Practical and Theoretical Implications
From a deployment perspective, E-valuator supplies a lightweight Python package requiring only black-box verifier access, modest calibration data, and minimal compute. The method is agnostic to the agent architecture and verifier model, making it broadly applicable—from LLM tool agents in scientific applications to non-LLM domains such as chess or robotics.
Theoretically, E-valuator strengthens the reliability of agentic systems by offering a formal methodology for agent verification with anytime-valid error guarantees. This reliability is especially critical for high-assurance contexts in scientific discovery, healthcare, and autonomous systems.
Beyond the current scope, the framework opens several avenues for future research, such as investigating relaxation of independence assumptions in verifier score modeling, extending to multi-agent and interactive environments, and integrating universal inference techniques for even tighter error control with empirical ratios.
Conclusion
E-valuator synthesizes ideas from sequential hypothesis testing, e-process theory, and discriminative density ratio estimation to enhance the reliability of agent verification. By transforming arbitrary verifier heuristics into principled, high-power sequential tests with provable false alarm rate control, E-valuator sets a new standard for auditing agentic AI systems and addresses a critical bottleneck for trustworthy long-horizon AI deployments (2512.03109).