MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
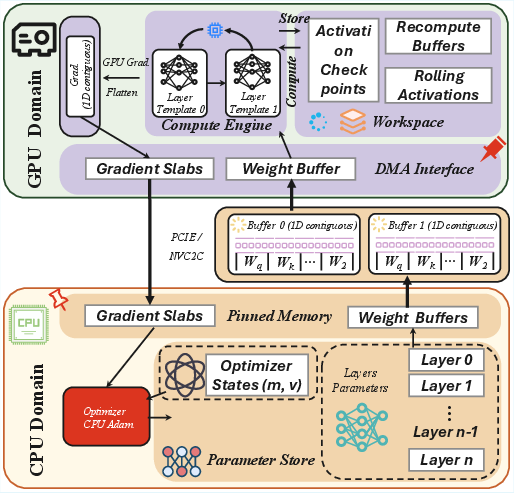
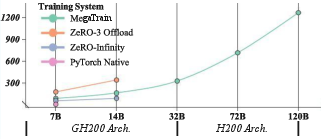
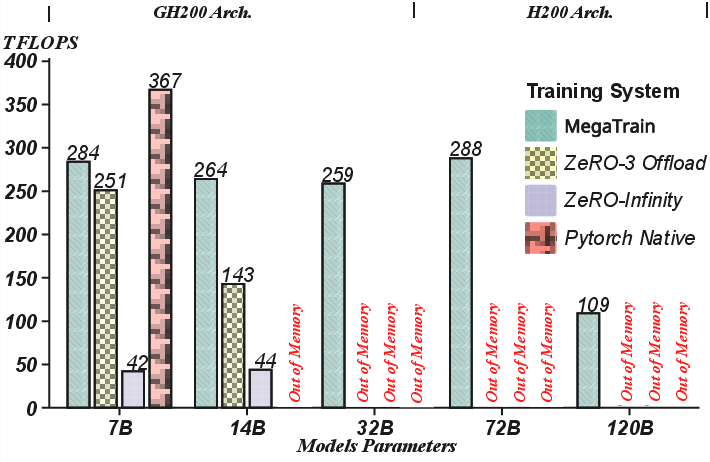
Abstract: We present MegaTrain, a memory-centric system that efficiently trains 100B+ parameter LLMs at full precision on a single GPU. Unlike traditional GPU-centric systems, MegaTrain stores parameters and optimizer states in host memory (CPU memory) and treats GPUs as transient compute engines. For each layer, we stream parameters in and compute gradients out, minimizing persistent device state. To battle the CPU-GPU bandwidth bottleneck, we adopt two key optimizations. 1) We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution. 2) We replace persistent autograd graphs with stateless layer templates, binding weights dynamically as they stream in, eliminating persistent graph metadata while providing flexibility in scheduling. On a single H200 GPU with 1.5TB host memory, MegaTrain reliably trains models up to 120B parameters. It also achieves 1.84$\times$ the training throughput of DeepSpeed ZeRO-3 with CPU offloading when training 14B models. MegaTrain also enables 7B model training with 512k token context on a single GH200.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MegaTrain, a new way to train very large AI LLMs (with over 100 billion parameters) on just one graphics card (GPU). Instead of cramming everything into the GPU’s limited memory, MegaTrain stores most of the model in the computer’s main memory (the CPU’s memory) and streams pieces to the GPU only when needed. This lets people with modest hardware train huge models more efficiently and accurately.
Think of it like a kitchen:
- The CPU’s memory is a big pantry where you keep all the ingredients.
- The GPU is a powerful stove with a small countertop.
- MegaTrain brings just the ingredients needed for the current dish from the pantry to the counter, cooks, and then sends results back, keeping the counter clear.
What questions were the researchers trying to answer?
- How can we train giant LLMs on a single GPU without running out of GPU memory?
- Can we move most data to cheaper, larger CPU memory and still keep the GPU busy and fast?
- Can we do this without losing training quality or accuracy?
- Can this approach also help with special cases like very long input texts?
How does MegaTrain work? (Methods explained simply)
MegaTrain flips the usual setup: it treats CPU memory as home base for the model and uses the GPU as a fast “compute engine” that processes small chunks at a time. Here are the main ideas, with analogies:
- Memory-centric design (pantry-to-counter cooking):
- All the model’s “weights” (the numbers the model learns) and the optimizer’s “notes” (extra values needed to update weights) live in CPU memory.
- For each layer of the model, MegaTrain streams the needed weights into the GPU, runs the math, and then releases those weights to make room for the next layer.
- Intermediate results (called activations) are handled carefully so they don’t build up and overflow memory.
- Double buffering and pipelining (two trays on a conveyor belt):
- To avoid waiting, MegaTrain uses two buffers and three parallel “conveyor belts”:
- 1) bring next layer’s weights to the GPU,
- 2) compute the current layer,
- 3) send gradients (the feedback used to learn) back to the CPU.
- With this overlap, the GPU is almost never idle—it’s always computing while new data arrives and old results leave.
- Stateless layer templates (reusable “cookie cutters”):
- Usual training systems build a big “memory of the whole recipe” (a computation graph) that assumes everything stays on the GPU.
- MegaTrain instead keeps simple, reusable templates for each layer’s operations on the GPU. It “plugs in” the current layer’s weights as they arrive.
- This avoids storing huge amounts of extra data and keeps GPU memory use as small as “one layer at a time.”
- Block-wise recomputation (checkpoints instead of saving everything):
- Instead of saving all intermediate results, MegaTrain saves a few “checkpoints” and recomputes smaller chunks during the backward pass. This trades a bit more computing for much less memory use.
- Result: memory needed on the GPU stays small and predictable.
- CPU-side optimizer updates (do the book-keeping near the pantry):
- Updating weights (like Adam optimizer) involves lots of reading and writing but not much heavy math.
- MegaTrain does these updates on the CPU, avoiding extra round-trips to the GPU.
What did they find, and why is it important?
- Trains 100B+ models on a single GPU:
- On a single H200 GPU with 1.5 TB of CPU memory, they trained models up to 120 billion parameters.
- This is a size many other “offloading” systems struggle to handle reliably.
- Faster than popular baselines:
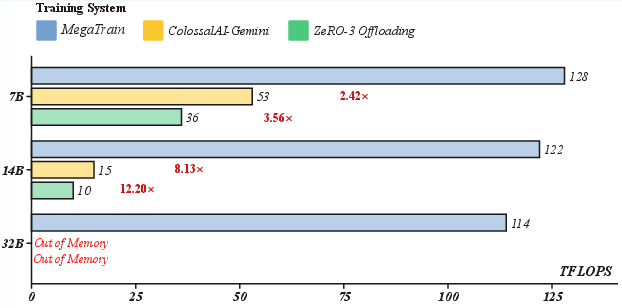
- For a 14B model, MegaTrain was about 1.84× faster than DeepSpeed ZeRO-3 with CPU offloading.
- It maintained high and steady performance as models grew, while other systems slowed down or ran out of memory.
- Works with ultra-long inputs:
- MegaTrain trained a 7B model with context lengths up to 512,000 tokens on a single GH200—a very long input window that’s useful for tasks like long documents or codebases.
- Maintains accuracy:
- On tested tasks, MegaTrain matched the accuracy of standard methods, showing its memory tricks don’t hurt learning quality.
- Runs on many kinds of hardware:
- Beyond top-end GPUs, MegaTrain worked well on A100, RTX A6000, and even consumer GPUs like the RTX 3090, often outperforming other offloading approaches and enabling larger batch sizes.
Why this matters:
- GPU memory is expensive and limited. By moving most data to cheaper, bigger CPU memory and streaming it smartly, MegaTrain makes training big models more accessible to small labs, schools, and independent developers.
How did they test it?
They trained and measured speed, memory use, and accuracy across:
- Different model sizes (7B, 14B, 32B, 72B, 120B).
- Different hardware (GH200, H200, A100 PCIe, RTX A6000, RTX 3090).
- Different shapes of models (more layers vs. wider layers).
- Long-context settings (up to 512k tokens). They compared against well-known systems like ZeRO-3 Offload, ZeRO-Infinity, PyTorch’s default, and ColossalAI Gemini.
What’s the bigger impact?
- Democratizing large-model training:
- If you can train 100B+ models on a single GPU with lots of CPU memory, more people can experiment and fine-tune big models without huge server clusters.
- Better use of memory hierarchies:
- The work shows that smart organization (what lives where, and when) can matter more than raw GPU memory size.
- Path to even larger models:
- The same streaming ideas could extend to multiple GPUs or even add SSDs as another storage tier, potentially pushing toward trillion-parameter training on everyday systems.
- Practical benefits:
- Faster fine-tuning, support for very long inputs, and reliable accuracy—all on limited hardware—helps research, education, and startups innovate more easily.
In short, MegaTrain is like turning a small kitchen into a high-throughput restaurant by organizing the pantry, counter, and conveyor belts perfectly—so you can cook giant meals with a small workspace, without slowing down or making mistakes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable items for future research:
- Validate training correctness at larger scales: provide accuracy, loss curves, and convergence diagnostics for models beyond 32B (e.g., 72B and 120B), across diverse datasets and tasks (reasoning, coding, multilingual).
- Clarify and evaluate “full precision” claims: systematically compare BF16/FP32 (used here) with FP16, FP8, and mixed-precision schemes in MegaTrain, quantifying numerical stability, convergence, and throughput trade-offs.
- Generalize to broader architectures: demonstrate stateless templates and streaming for MoE (beyond listing GPT-OSS-120B), encoder–decoder models, multimodal transformers, and attention variants (GQA/MQA, rotary embeddings, ALiBi, sliding-window, block-sparse).
- Optimizer coverage and performance: implement and benchmark CPU-side LAMB, Adafactor, SGD+momentum, RMSProp, and adaptive gradient clipping; quantify precision effects and throughput on different CPUs.
- Automatic scheduling and tuning: develop analytical or learned models to auto-select checkpoint interval K, slab pool size, and buffer sizes per layer so that P_i/B_link ≤ compute_i holds; expose an autotuner with measurable benefits.
- NUMA and multi-socket host memory behavior: characterize pinning, page table/TLB overheads, cross-socket bandwidth contention, and placement policies on 1–2 TB systems; provide NUMA-aware memory placement strategies.
- Fault tolerance and checkpointing: design and evaluate mechanisms to persist streamed parameters, gradients, and optimizer states; measure restart overheads and correctness after failures; define SSD-backed recovery protocols.
- Multi-GPU extension: specify how streaming interacts with tensor/expert/pipeline parallelism, inter-GPU synchronization, and gradient reduction in host memory; quantify scalability and overheads.
- Tiered storage with NVMe/SSD: prototype SSD tiering for parameters and optimizer states; define eviction/prefetch policies and scheduling to sustain training when host RAM is limited; report end-to-end throughput bounds.
- Ordering and correctness under asynchrony: formally specify synchronization guarantees between CPU-side optimizer updates and the next GPU step; verify absence of races, stale reads, or write–read hazards under CUDA stream/event orchestration.
- Energy and cost efficiency: measure total power and energy per step across devices (GPU, CPU, interconnect) and compare to GPU-centric/offloading baselines; include cost-per-token and cost-per-epoch analyses.
- Applicability to commodity memory sizes: quantify minimal host memory requirements per parameter (including optimizer/moments and fragmentation overheads); propose strategies for 64–128 GB RAM systems (compression, sharding, SSD tiering).
- Time-to-target accuracy: beyond TFLOPS, measure wall-clock time to reach target validation accuracy for representative tasks; isolate recomputation-induced overheads on total training time versus baselines.
- Long-context boundaries and kernels: evaluate limits beyond 512K (e.g., 1M tokens), assess kernel-specific constraints (FlashAttention versions, chunked MLP side effects), and report token throughput impacts and memory safety for alternative long-context designs.
- Data pipeline overlap: analyze data loading, tokenization, and host-side preprocessing overlap with weight streaming; identify and mitigate CPU bottlenecks in end-to-end pipelines.
- Ecosystem compatibility: quantify the impact of bypassing autograd on integration with PyTorch features (DDP, FSDP, torch.compile, CUDA Graphs, profiler); provide debugging/profiling workflows and limitations.
- Memory allocator behavior: study GPU allocator fragmentation and reuse under ping-pong buffers/templates; provide allocator tuning guidelines and empirical fragmentation metrics.
- Gradient accumulation/micro-batching: formally describe and validate how streaming interacts with gradient accumulation across micro-batches; detail buffering requirements and correctness guarantees.
- Parameter-efficient fine-tuning and quantization-aware training: support and evaluate LoRA/QLoRA, adapters, and QAT under streaming; measure memory, throughput, and convergence impacts.
- Handling large embeddings and tied weights: specify streaming/offloading strategies for massive vocab embeddings and tied LM head weights; quantify their memory and bandwidth costs.
- OS/driver sensitivity: document reproducibility across CUDA/toolkit versions, PCIe/NVLink configurations, and OS pinning limits; provide robust configuration checks and fallbacks.
- Predictive scalability model: build and validate a formal performance model mapping layer shapes, link bandwidths, and compute to predicted throughput and stall conditions; use it to guide scheduling/tuning.
- Reproducibility and benchmarking breadth: release end-to-end scripts, seeds, and configurations; expand evaluation beyond MetaMathQA to include common LLM benchmarks, report error bars/variance, and provide standardized baselines.
Practical Applications
Immediate Applications
The following items outline concrete, deployable use cases that can be put into practice now, leveraging MegaTrain’s memory-centric training, double-buffered streaming, and stateless layer templates.
Industry
- On‑prem post‑training of large LLMs in regulated environments
- Sectors: healthcare, finance, legal, government
- What: Fine-tune 7B–72B (and up to 120B with sufficient host RAM) models on a single machine for instruction tuning, domain adaptation, and alignment using full precision; keep all data in-house for compliance.
- Tools/products/workflows: “LLM Fine‑Tune Appliance” (1 GPU + 0.5–2 TB RAM); enterprise MLOps pipelines that schedule single-node post‑training jobs; CPU-based optimizer update services to avoid GPU memory pressure.
- Assumptions/dependencies: 256 GB–1.5 TB host memory depending on model size; PCIe Gen4/5 or NVLink‑C2C preferred; AVX‑512 or comparable CPU vector support; proper pinned-memory configuration.
- Ultra long‑context training for domain corpora without multi‑GPU clusters
- Sectors: software (codebase-wide modeling), AIOps/SRE (log comprehension), legal (case archives), healthcare (longitudinal EHR timelines)
- What: Train/fine‑tune models with 128K–512K contexts on a single GH200 or H200-class node; apply chunked MLP and block recomputation to bound memory.
- Tools/products/workflows: Long‑context curriculum trainers; “repository‑aware” dev assistants trained over entire codebases; log intelligence workflows that learn from months of logs end‑to‑end.
- Assumptions/dependencies: High host‑to‑device bandwidth; careful checkpoint interval and chunking configuration; storage throughput for large sequence datasets.
- Cost‑optimized single‑node post‑training during GPU‑scarcity windows
- Sectors: startups/SMBs across industries
- What: Use commodity PCIe servers (A100 PCIe, RTX A6000, RTX 3090) with large RAM to fine‑tune 3B–14B+ models at competitive throughput compared to ZeRO‑offload baselines.
- Tools/products/workflows: Capacity‑aware schedulers that target “RAM-rich, GPU‑light” nodes; job profiles that auto‑select batch size and checkpoint intervals to saturate compute while hiding transfers.
- Assumptions/dependencies: Model layer packing into contiguous host slabs; double buffering correctly configured; host RAM capacity determines upper bound.
- Cloud offerings and OEM SKUs optimized for RAM‑heavy LLM training
- Sectors: cloud, hardware vendors, MSPs
- What: Offer instance types and appliances with 1 GPU and high RAM (0.5–2 TB) marketed for single‑node 30B–120B post‑training.
- Tools/products/workflows: Managed “Single‑GPU 100B+ Tuning” SKUs; turn‑key racks with GH200/H200 + high‑capacity DDR/LPDDR; autoscaling that prioritizes RAM over GPU count for post‑training workloads.
- Assumptions/dependencies: Clear sizing guides (model parameters → RAM); optimized NUMA and page‑pinning; sustained DMA to saturate host‑device links.
- Privacy‑preserving model adaptation for enterprise knowledge bases
- Sectors: corporate knowledge management, customer support, cybersecurity
- What: Fine‑tune a 14B–32B model on proprietary documents/emails/tickets entirely on‑prem without multi‑GPU orchestration complexity.
- Tools/products/workflows: Nightly domain adaptation jobs; internal alignment training with CPU‑resident optimizer state; policy-locked data paths that never leave the node.
- Assumptions/dependencies: Data governance pipeline; CPU throughput sufficient to keep optimizer off GPU critical path.
Academia
- Democratized LLM post‑training in labs and classrooms
- What: Fine‑tune 7B–32B models on workstation‑class GPUs (24–48 GB VRAM) with 128–512 GB RAM; enable full‑precision instruction tuning/homework-scale experiments on a single node.
- Tools/products/workflows: Course labs on memory‑centric training; reproducible templates for stateless layer execution; assignments comparing checkpoint intervals and I/O overlap strategies.
- Assumptions/dependencies: Sufficient host RAM; up‑to‑date CUDA and driver stack; access to models/datasets under permissible licenses.
- Systems research baselines for memory‑centric ML
- What: Use MegaTrain as a baseline to study memory hierarchy utilization, CPU–GPU overlap, activation checkpointing strategies, and host‑resident optimizer design.
- Tools/products/workflows: Microbenchmarks (H2D/D2H overlap), ablation suites (double buffering, slab pools), host‑memory footprint tracing and analysis.
- Assumptions/dependencies: Ability to modify runtime (stateless templates, stream coordination); profiling tools for CUDA streams and pinned memory.
Policy
- Resource planning that prioritizes RAM over GPU count for post‑training
- What: Update procurement and grant guidelines to allow RAM‑heavy single‑GPU nodes for student access and small labs, improving equity under GPU scarcity.
- Tools/products/workflows: “H100‑equivalent per student” complemented by “RAM per student” metrics; shared campus RAM pools for booked single‑node post‑training.
- Assumptions/dependencies: Institutional policy updates; rack power and cooling support for high‑RAM nodes; training workloads are post‑training (not trillion‑token pretraining).
- On‑prem compliance pathways for sensitive model adaptation
- What: Provide compliance templates recognizing single‑node, on‑prem post‑training as a secure alternative to multi‑tenant cloud.
- Tools/products/workflows: Standardized security controls for pinned memory and data paths; audit checklists for CPU‑resident optimizer states.
- Assumptions/dependencies: Vendor hardening guidance; IT operations acceptance; traceability of model artifacts.
Daily Life
- Prosumer/home‑lab fine‑tuning of mid‑size models
- What: Fine‑tune 3B–14B models on RTX 3090/A6000‑class GPUs with 128–256 GB RAM for personal assistants, personal knowledge base integration, and hobby research.
- Tools/products/workflows: Desktop “single‑GPU fine‑tune” recipes; wizards that auto‑compute RAM needs and batch sizes; local long‑context training for personal archives.
- Assumptions/dependencies: Large system RAM and fast SSDs for datasets; OS tuning for large pinned allocations; power/thermal headroom.
Long‑Term Applications
The following require further research, scaling, or ecosystem development beyond the current implementation.
Industry
- Trillion‑parameter post‑training via tiered storage (RAM + NVMe)
- What: Extend the host‑master design to incorporate SSD tiers for parameters/optimizer states, using prefetch windows and read‑ahead to mask NVMe latency.
- Potential products: “Trillion‑Param Appliance” with high‑bandwidth NVMe arrays; cloud instances exposing huge NVMe pools with DMA‑friendly I/O.
- Dependencies: Robust prefetch scheduling; large‑page and IOMMU tuning; write‑amplification control and SSD endurance management.
- Multi‑GPU hybrid memory training (tensor/expert parallel + streaming)
- What: Combine layer‑streaming with tensor/expert parallelism to scale throughput while keeping persistent states in host/storage tiers.
- Potential products: Multi‑GPU nodes that prioritize interconnect bandwidth (NVLink/SXM) with coordinated host‑memory sharding; MoE‑aware streaming runtimes.
- Dependencies: Cross‑GPU stream coordination; collective ops that tolerate dynamic weight binding; scheduling to hide both inter‑GPU and H2D transfers.
- Memory‑centric inference extensions for ultra‑long contexts
- What: Adapt stateless templates and layered streaming to inference for 256K–1M token contexts where VRAM is insufficient, trading latency for feasibility.
- Potential products: Batch/offline inference services for eDiscovery, archival analytics, and code audits without sharding weights across GPUs.
- Dependencies: Latency‑aware scheduling; KV‑cache management that complements streamed weights; acceptable throughput/latency trade‑offs.
- Continuous learning on edge/branch servers with limited GPUs
- Sectors: retail, manufacturing, telecom
- What: Nightly small‑scale on‑prem updates on branch servers (1 GPU + high RAM) to adapt models to local data drift.
- Dependencies: Lightweight data governance at the edge; robust failure recovery in RAM/SSD tiers; bandwidth‑aware model distribution.
Academia
- Standard benchmarks for memory‑hierarchy‑aware training
- What: Community suites that vary depth/width/context to stress CPU–GPU links, I/O overlap, and host‑memory use; metrics beyond TFLOPS (e.g., bytes moved per flop).
- Dependencies: Consensus metrics; open datasets with variable sequence lengths; reproducible harnesses.
- Integration as first‑class backends in ML frameworks
- What: PyTorch/JAX backends that natively support stateless layer templates, contiguous slab packing, and multi‑stream pipeline scheduling.
- Dependencies: Framework API changes; portable pinned‑memory allocators; upstream community support and maintenance.
- Energy and cost studies for RAM‑heavy single‑node workflows
- What: Rigorous TCO and energy analyses comparing “1 GPU + huge RAM” vs “many GPUs” for post‑training and long‑context tasks.
- Dependencies: Instrumentation for CPU, GPU, and PCIe power; standardized workload mixes.
Policy
- Equity programs and funding for RAM‑centric compute
- What: Grants that fund high‑RAM nodes for teaching and small labs as an alternative to large GPU clusters; fair‑use sharing policies.
- Dependencies: Vendor pricing for large‑RAM configurations; facility readiness.
- Standards for privacy‑preserving single‑node fine‑tuning
- What: Certification checklists and audit standards that recognize CPU‑resident optimizer states and in‑node data boundaries.
- Dependencies: Collaboration between regulators and standards bodies; vendor‑provided attestations.
- Sustainability and hardware lifecycle guidance
- What: Encourage reuse of prior‑gen GPUs with upgraded RAM to reduce e‑waste; procurement frameworks that consider “RAM upgrades + single GPU” pathways.
- Dependencies: Evidence on performance‑per‑watt; refurbishment channels for RAM‑heavy servers.
Daily Life
- Consumer “LLM training workstation” segment
- What: Turn‑key desktops with 1 consumer GPU and 256–512 GB ECC RAM aimed at makers, researchers, and small businesses for periodic on‑prem tuning.
- Dependencies: OS installers pre‑tuned for pinned memory; simplified drivers and setup; approachable UX around batch size, checkpointing, and context length.
- Community/federated model adaptation without GPU clusters
- What: Neighborhood labs or collectives run periodic fine‑tunes on RAM‑heavy nodes, exchanging deltas rather than raw data for privacy.
- Dependencies: Secure aggregation protocols; versioning tools for model deltas; governance models.
Notes on feasibility across applications
- Performance scales with host memory bandwidth and interconnect: NVLink‑C2C (GH200) > PCIe Gen5 > Gen4/Gen3. Throughput remains viable on consumer PCIe but with lower ceilings.
- Host RAM is the primary capacity limiter: rough order‑of‑magnitude planning is ~12 bytes/parameter for BF16 weights + grads + FP32 Adam moments (excluding activations/workspaces).
- Correctness is preserved relative to full‑GPU training based on reported accuracy; ensure numerical parity under alternative optimizers/mixed precision settings.
- Operational reliability depends on careful buffer sizing, double buffering, pinned slab pools, and CUDA event orchestration; misconfiguration can serialize transfers and erode gains.
Glossary
- Adam optimizer: A stochastic optimization method that maintains first and second moment estimates to adapt learning rates per parameter. "For mixed-precision training with Adam Optimizer~\citep{micikevicius2018mixed, kingma2015adam}, for each parameter, memory needs to store BF16 weights (2\,B), BF16 gradients (2\,B), and FP32 optimizer moments ( and , 8\,B combined), giving a minimum of $12P$ bytes for parameters."
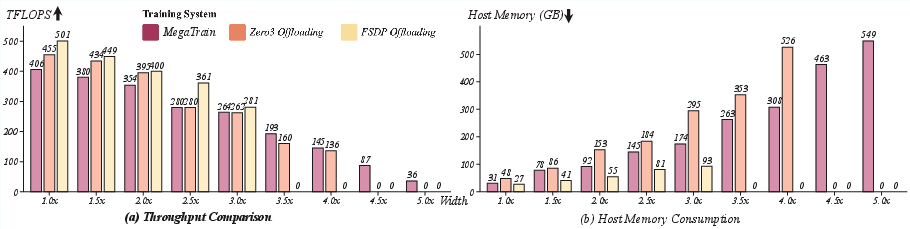
- arithmetic intensity: The ratio of computation to memory access; higher intensity generally yields better hardware utilization. "Longer contexts increase arithmetic intensity from larger attention workloads, yielding better hardware utilization."
- autograd: Automatic differentiation framework that builds and executes computation graphs to compute gradients. "Standard autograd in frameworks like PyTorch builds a global computation graph and retains activations until the backward pass completes."
- AVX-512: A set of 512-bit SIMD instructions for CPUs that accelerates vectorized operations. "Since PCIe bandwidth is the bottleneck rather than compute, executing Adam on the CPU with efficient vector instructions (e.g., AVX-512) matches or exceeds the throughput of GPU-based updates while eliminating four times the data movement."
- BF16: Brain floating point (16-bit) format used to reduce memory and bandwidth while preserving numerical range. "For mixed-precision training with Adam Optimizer~\citep{micikevicius2018mixed, kingma2015adam}, for each parameter, memory needs to store BF16 weights (2\,B), BF16 gradients (2\,B), and FP32 optimizer moments ( and , 8\,B combined)..."
- block-wise recomputation: A memory reduction method that recomputes activations for blocks of layers during backward instead of storing all intermediates. "In MegaTrain, we adopt a block-wise recomputation strategy, storing only one checkpoint of activations every layers."
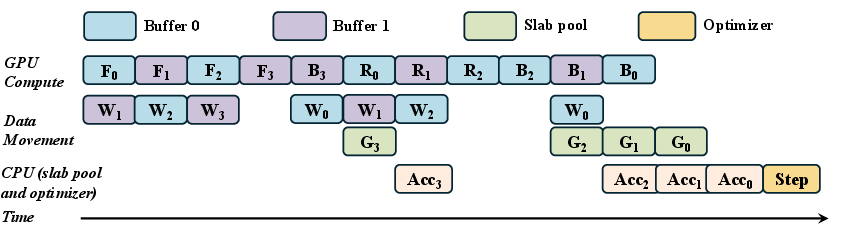
- CUDA events: Lightweight synchronization primitives used to order work across CUDA streams. "Coordination across streams is governed by lightweight CUDA events: (1)~a Weights-Ready event recorded by $S_{\mathrm{H2D}$ after completing , which $S_{\mathrm{comp}$ waits on before binding layer~; (2)~a Backward-Done event recorded by $S_{\mathrm{comp}$ after materializing , which triggers $S_{\mathrm{D2H}$ for evacuation; and (3)~a Buffer-Free event recorded by $S_{\mathrm{D2H}$ after offload completes..."
- CUDA Graphs: A mechanism to capture and replay static sequences of CUDA operations with low overhead. "CUDA Graphs offer low-overhead kernel replay but require a static execution pattern; streaming introduces dynamic address bindings (ping-pong buffers), shifting synchronization points, and interleaved recomputation that cannot be captured in a single graph."
- CUDA streams: Independent command queues that allow overlapping of computation and data transfers. "We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams, enabling continuous GPU execution."
- DDR5: A generation of double data rate synchronous DRAM used as host memory with high per-pin frequency. "the H200 SXM uses host DDR5---a standard optimized for high per-pin frequency to match modern CPU architectures---connected via PCIe Gen5 at 128\,GB/s."
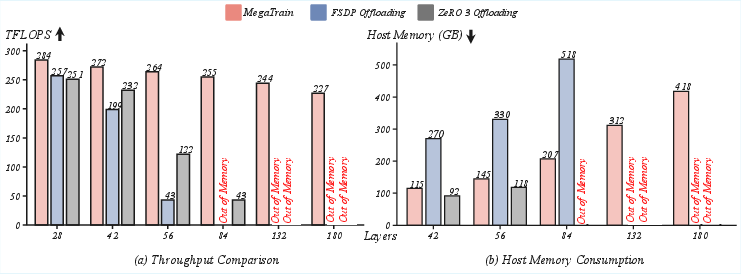
- device memory fragmentation: Inefficient allocation patterns in GPU memory that reduce effective capacity and performance. "FSDP shows lower host memory at small widths but fails early (after 3.0) due to device memory fragmentation and activation pressure."
- D2H: Device-to-host data transfer direction over the interconnect. "By treating gradient offloading as a background task, MegaTrain prevents D2H latency from entering the critical path, ensuring GPU throughput is limited only by compute or H2D bandwidth."
- double buffering: Using two alternating buffers to overlap data transfer with computation for continuous execution. "We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading..."
- FFN size: The dimensionality of the feed-forward subnetwork in a Transformer layer. "For GPT-OSS-120B, the hidden size and FFN size are written as per-expert width times the number of experts, which reflects its MoE design rather than a dense layout."
- FSDP (Fully Sharded Data Parallel): A training technique that shards model parameters, gradients, and optimizer states across data-parallel workers. "both ZeRO-3 Offloading and FSDP Offloading exhibit severe throughput collapse as depth increases."
- GH200: NVIDIA Grace-Hopper superchip architecture coupling a Grace CPU and a GPU via NVLink-C2C. "Experiments on the GH200 system are conducted on Grace-Hopper nodes."
- gradient checkpointing: A technique that saves selected activations during forward and recomputes others in backward to reduce memory. "All experiments use Qwen2.5 models with a fixed sequence length of 8{,}192 and gradient checkpointing applied every 4 layers."
- gradient offloading: Moving computed gradients from GPU to host memory to free device memory. "overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams"
- H200: NVIDIA Hopper-series GPU model with HBM3e memory, used as a platform in the experiments. "We additionally evaluate MegaTrain on a single NVIDIA H200 SXM node equipped with one Intel Xeon Platinum 8558 CPU (96 cores total) and 1.5\,TB of host memory."
- H2D: Host-to-device data transfer direction over the interconnect. "\hfill // H2D transfer"
- HBM3: Third-generation High Bandwidth Memory used on GPUs for extremely high throughput. "\quad HBM3 (per GPU) & 96\,GB & 4.0\,TB/s & 20"
- HBM3e: Enhanced third-generation HBM variant offering higher bandwidth. "\quad HBM3e (per GPU) & 141\,GB & 4.8\,TB/s & 20"
- layer template: A reusable, stateless kernel bundle that dynamically binds to streamed weights at execution time. "We replace persistent autograd graphs with stateless layer templates, binding weights dynamically as they stream in"
- layer-contiguous tiling: Packing all per-layer states into a single contiguous memory block to enable large, efficient transfers. "MegaTrain instead employs layer-contiguous tiling: all states for each layer---BF16 weights, BF16 gradients, and FP32 Adam moments---are packed into a single contiguous block aligned to 4KB pages"
- LPDDR5X: Low-power DDR memory variant with wide bus and lower power, used in GH200 host memory. "The GH200 GPU instead co-packages 480\,GB of LPDDR5X---a mobile-originated standard with a wider bus and lower power consumption, achieving 384--512\,GB/s aggregate bandwidth."
- loss anchoring: The step in training that computes the loss and initializes backward gradients from the output. "// Phase 2: Loss Anchoring"
- MoE (Mixture of Experts): An architecture that routes tokens through a subset of expert networks to increase model capacity efficiently. "For GPT-OSS-120B, the hidden size and FFN size are written as per-expert width times the number of experts, which reflects its MoE design rather than a dense layout."
- NVLink-C2C: NVIDIA interconnect that links CPU and GPU chip-to-chip with much higher bandwidth than PCIe. "It accesses this memory via NVLink-C2C at 900\,GB/s, a interconnect advantage over PCIe that fundamentally changes what offloading patterns are practical."
- NVMe SSD: High-speed non-volatile storage using the NVMe interface over PCIe. "NVMe SSDs add tens of terabytes of persistent storage at single-digit GB/s bandwidth."
- operator workspaces: Temporary buffers needed by certain GPU kernels during execution. "Operator workspaces: The workspace memory usage is hard to bound, but we assume it is bounded by a constant bytes."
- PCIe Gen4: Fourth-generation PCI Express interconnect standard. "This setup represents a widely available datacenter configuration and shows that MegaTrain does not depend on NVLink-class interconnects... connected via PCIe Gen4."
- PCIe Gen5: Fifth-generation PCI Express interconnect standard with higher bandwidth. "the H200 SXM uses host DDR5... connected via PCIe Gen5 at 128\,GB/s."
- pinned memory: Host memory pages locked to prevent paging, enabling faster, reliable DMA transfers. "Rather than pinning the entire model, which would exhaust host physical memory and page table resources, MegaTrain allocates a small pool of pinned staging buffers sized to ."
- ping-pong buffers: Alternating buffer sets used to overlap data movement and computation in streaming execution. "streaming introduces dynamic address bindings (ping-pong buffers), shifting synchronization points, and interleaved recomputation that cannot be captured in a single graph."
- pipelined double-buffered execution engine: A runtime mechanism that overlaps H2D prefetch, compute, and D2H offload using multiple streams. "We introduce a pipelined double-buffered execution engine that overlaps parameter prefetching, computation, and gradient offloading across multiple CUDA streams"
- slab pool: A pool of fixed-size pinned host buffers used to stage and evacuate gradients asynchronously. "To avoid blocking compute on gradient offloading, MegaTrain maintains a pool of pinned host slabs for gradient evacuation." and "w/o Gradient Slab Pool"
- SRAM: On-chip static RAM providing extremely high bandwidth but small capacity for GPU compute. "On-chip SRAM provides the highest bandwidth (\,TB/s) but only tens of megabytes of capacity."
- stateless execution model: An approach that decouples kernels from persistent weights/activations, binding data at runtime to avoid storing global graphs. "MegaTrain therefore adopts a stateless execution model that decouples mathematical structure from physical data."
- TFLOPS: Trillions of floating-point operations per second; a measure of sustained computational throughput. "Sustained TFLOPS across model scales. MegaTrain remains efficient while offloading baselines become GPU memory bound."
- ZeRO-3 Offload: A DeepSpeed variant that shards optimizer states and offloads to CPU to reduce GPU memory usage. "On a single GH200, MegaTrain achieves 1.84 the training throughput of ZeRO-3 Offload at 14B scale"
- ZeRO-Infinity: An offloading framework that extends GPU memory using CPU and NVMe tiers. "While offloading techniques such as ZeRO-Offload~\citep{rajbhandari2020zero} and ZeRO-Infinity~\citep{rajbhandari2021zero} have begun to extend GPU capacity by migrating model states to host memory (CPU memory) and NVMe storage"
- recomputation granularity: The frequency/size of activation segments recomputed during backward, affecting memory and throughput. "We evaluate the effect of recomputation granularity by setting the checkpoint interval to 1."
Collections
Sign up for free to add this paper to one or more collections.