RevFFN: Memory-Efficient Full-Parameter Fine-Tuning of Mixture-of-Experts LLMs with Reversible Blocks
Abstract: Full parameter fine tuning is a key technique for adapting LLMs to downstream tasks, but it incurs substantial memory overhead due to the need to cache extensive intermediate activations for backpropagation. This bottleneck makes full fine tuning of contemporary large scale LLMs challenging in practice. Existing distributed training frameworks such as DeepSpeed alleviate this issue using techniques like ZeRO and FSDP, which rely on multi GPU memory or CPU offloading, but often require additional hardware resources and reduce training speed. We introduce RevFFN, a memory efficient fine tuning paradigm for mixture of experts (MoE) LLMs. RevFFN employs carefully designed reversible Transformer blocks that allow reconstruction of layer input activations from outputs during backpropagation, eliminating the need to store most intermediate activations in memory. While preserving the expressive capacity of MoE architectures, this approach significantly reduces peak memory consumption for full parameter fine tuning. As a result, RevFFN enables efficient full fine tuning on a single consumer grade or server grade GPU.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
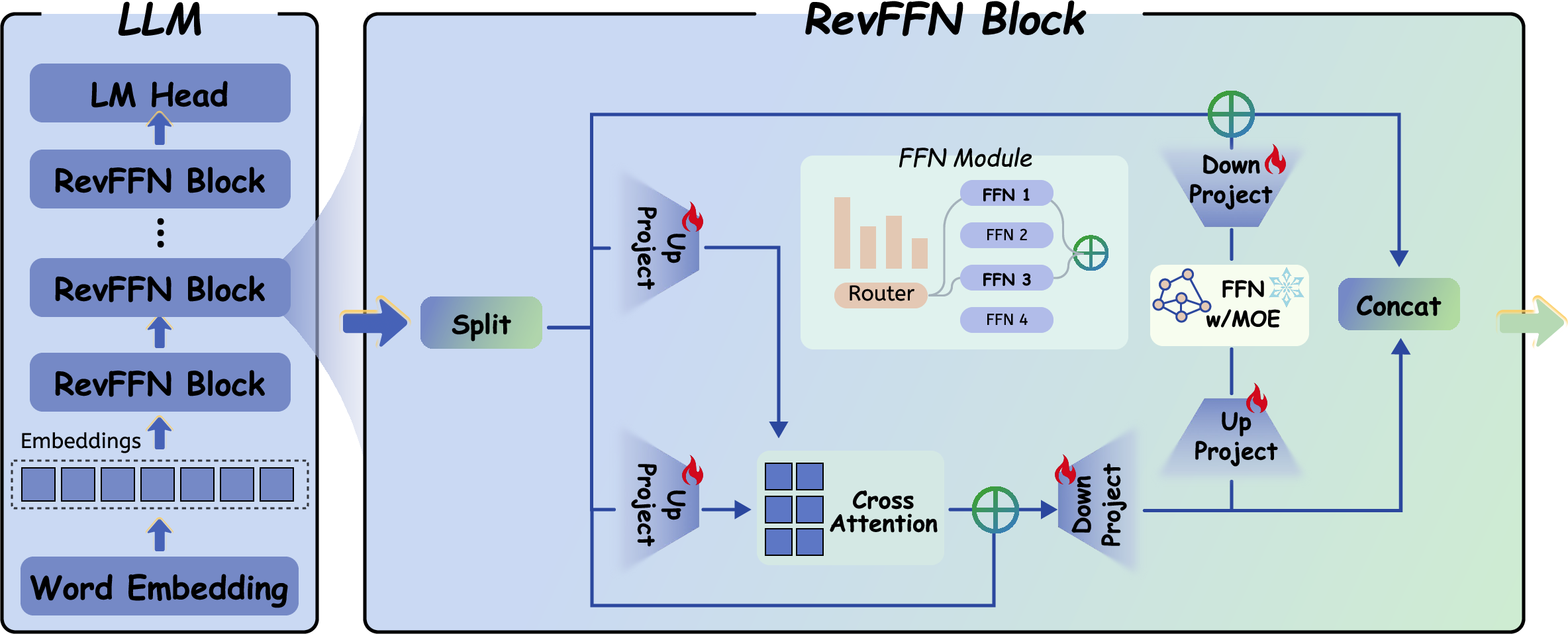
This paper introduces a way to fine-tune big LLMs using much less memory so you can do full fine-tuning on a single GPU. The method is called RevFFN. It uses “reversible” building blocks so the computer doesn’t have to remember lots of temporary data during training. The team shows this works well for Mixture-of-Experts (MoE) models, which are LLMs that use a set of specialized “experts” to process different parts of the input.
What questions did the researchers ask?
They focused on three simple questions:
- Can we fine-tune all the parameters of a large MoE LLM using the memory of just one GPU?
- Can we do this without slowing training down too much?
- Can we keep or improve the model’s performance compared to popular low-memory methods that train only a small part of the model?
How did they try to solve it?
They solved it by rethinking how a Transformer layer (the main part of many LLMs) is built and trained.
The big idea: reversible blocks
- Normally, when a model trains, it saves a lot of “activations” (think of them as the model’s scratch work) so it can calculate how to improve itself later. Saving all that scratch work eats up memory.
- A reversible block is like following instructions you can perfectly undo. Imagine a Lego build where every step is designed so you can take the pieces off in the exact reverse order without keeping notes.
- In RevFFN, each layer splits the hidden features into two halves (two streams), lets them “talk” to each other with attention and an FFN (or MoE), and updates them in a way that can be reversed. Because you can reconstruct the earlier steps from the later ones, you don’t have to store most of the scratch work in memory.
Working with Mixture-of-Experts (MoE)
- MoE models have many expert sub-networks, a bit like having a panel of specialists where only a few are called to help for each input. This saves compute while keeping the model powerful.
- RevFFN keeps the MoE structure intact. It just wraps each layer in a reversible scaffold so memory use goes way down during training.
Adapter projections: making halves fit full-sized parts
- Pretrained attention and FFN modules expect full-sized inputs (the original feature width), but RevFFN splits features into half-sized streams.
- To bridge that gap, RevFFN adds tiny “projection adapters” before and after each pretrained module. Think of them as translators: they turn the half-sized features into full-sized ones going in, then back to half-sized coming out.
- These adapters are small compared to the rest of the model, so they add little cost but let you reuse the pretrained weights effectively.
Two-stage training schedule
- Stage 1: Warm-up the adapters. Freeze the big pretrained parts and train only the projection adapters for a short time. This helps the half-sized streams align with the pretrained modules without “forgetting” what the model already knows.
- Stage 2: Full fine-tuning. Unfreeze the main layers and train the whole system end-to-end. The MoE router (which picks experts) stays frozen to keep training stable.
Experimental setup
- Base model: Qwen1.5-MoE-A2.7B (a 2.7B-parameter MoE model).
- Hardware: A single NVIDIA H800 GPU with 80GB VRAM.
- Dataset: Databricks Dolly 15k (instruction-following data).
- Comparisons: Against PEFT methods (LoRA, DoRA, IA³) and memory-efficient full fine-tuning methods (SFT with checkpointing, LOMO, GaLore).
- Metrics: Peak GPU memory (VRAM), training speed (samples/sec), and benchmark scores (MMLU for broad knowledge, GSM8K for math reasoning, Multilingual average, and MT-Bench for chat quality).
What did they find, and why is it important?
Here are the key findings:
- Memory: RevFFN cut peak VRAM to about 39.5 GB, much lower than standard full fine-tuning with activation checkpointing (about 65.4 GB) and lower than GaLore (about 45.1 GB). This is a big deal because it means full fine-tuning can fit on a single high-end GPU.
- Speed: RevFFN was slower than PEFT methods (which are very fast because they train only a small part of the model) but faster than standard full fine-tuning with checkpointing. It sits in the middle: you get full updates with acceptable speed.
- Performance: RevFFN achieved top or near-top results:
- MMLU: 66.7% (best among the tested methods)
- GSM8K: 75.1% (best)
- MT-Bench: 7.65 (best)
- Multilingual: 38.8% (competitive; close to other methods, though not the highest)
- Training strategy matters: In an ablation (a test where they remove parts to see what breaks), skipping the warm-up stage or training only the adapters caused large performance drops. So the two-stage plan is important for stability and strong results.
Why this matters:
- Many teams don’t have huge multi-GPU clusters. RevFFN makes full fine-tuning of powerful LLMs much more accessible.
- Full fine-tuning often gives better results than training only small adapters. RevFFN lets you get those benefits without requiring extreme hardware.
What could this mean going forward?
- More accessible AI: With RevFFN, more researchers and organizations can fully fine-tune large MoE LLMs on a single GPU, lowering costs and barriers.
- Better models for specific tasks: Because you can update all parameters without massive memory needs, models can be better tailored to new jobs (like tutoring, customer support, or medical Q&A).
- Future directions: The authors suggest scaling to even larger models and mixing RevFFN with other tricks (like smart optimizers or knowledge distillation) to push memory use and performance further.
- Practical takeaway: If you want the quality gains of full fine-tuning but are limited by GPU memory, reversible blocks plus small adapters are a promising recipe.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a single, concrete list of the key gaps and uncertainties that remain in the current work and that future researchers could address.
- Theoretical guarantees for inversion: no proof or formal conditions are provided for the convergence of the fixed-point iteration used to reconstruct
X1(e.g., contraction mapping criteria, error bounds across depth), despite the claim of “below machine epsilon.” - Robustness of reversibility under common training practices: the paper does not clarify whether dropout, attention dropout, stochastic depth, or noise injections are disabled, and how their presence would affect exact reconstruction and gradient correctness.
- LayerNorm and normalization effects on invertibility: it remains unclear how normalization placement and parameterization influence the invertibility and stability of the reversible block; a formal analysis or empirical study is missing.
- Architectural deviation from standard self-attention: cross-branch attention (queries from
X1, keys/values fromX2) departs from the original pre-trained self-attention; there is no ablation isolating its impact versus a reversible variant that preserves self-attention semantics. - Adapter overhead quantification: the claim that the projection adapters are “negligible” is not substantiated with per-layer parameter counts, memory for optimizer states, and total added FLOPs; provide precise scaling with , number of layers, and sequence length.
- Memory breakdown and scaling curves: the work lacks a component-wise memory profile (parameters, optimizer states, activations, MoE buffers/KV), and scaling analyses versus batch size and sequence length to substantiate the “roughly half” activation memory claim.
- Clarification of optimizer choice and memory: the optimizer used (e.g., Adam vs. memory-efficient alternatives) is unspecified, and the relative contributions of optimizer states to peak VRAM are not analyzed or compared.
- Interaction with MoE routing: routers are frozen during joint fine-tuning; the impact of freezing vs. updating gating networks on accuracy, expert utilization, and stability is not measured, and memory-efficient strategies to train routers are unexplored.
- Expert load balancing and routing diagnostics: no metrics (e.g., load imbalance, token-to-expert distribution, dropped tokens) are reported to ensure the reversible scaffold preserves MoE efficiency and expert specialization.
- Generality across models: results are restricted to Qwen1.5-MoE-A2.7B; generalization to larger MoE models (e.g., ≥7B activated parameters), dense non-MoE transformers, encoder–decoder architectures, and multilingual/backbone variants remains unchecked.
- Single-GPU claim vs. hardware used: the evaluation uses an 80GB H800 (server-grade); feasibility on common consumer GPUs (e.g., 24–48GB) is not demonstrated, nor are batch size/sequence length trade-offs for such devices.
- Throughput overhead decomposition: recomputation costs are only described qualitatively; a detailed breakdown of runtime overhead attributable to reversible replays vs. forward compute and attention kernels is missing.
- Long-context training behavior: the method’s memory and speed advantages for very long sequences (e.g., 16–64k tokens) are not characterized; attention memory and recomputation demands at long context lengths need empirical scaling curves.
- Compatibility with existing memory techniques: synergies/conflicts with ZeRO/FSDP, activation checkpointing, FlashAttention, quantization-aware training (e.g., QLoRA), and low-rank gradient methods (e.g., GaLore) are not tested.
- Numerical stability under mixed precision: the paper does not report the precision mode (FP16/BF16/FP32) or assess whether mixed-precision arithmetic affects reversible reconstruction accuracy or training stability.
- Inference-time costs: adapters add compute at inference, but latency, throughput, and memory impact during generation are not measured; clarify whether reversible scaffolding is used or bypassed at inference and its practical overheads.
- Evaluation protocol and statistical rigor: results are single-run without seeds, variance, or confidence intervals; significance of small deltas on MMLU/GSM8K/MT-Bench is unclear; standardized evaluation settings and multiple seeds are needed.
- Training data representativeness: fine-tuning only on Dolly-15k may not be sufficient to claim broad improvements on diverse benchmarks; assess performance across varied instruction-tuning datasets and domain-specific tasks.
- Fairness of throughput comparisons: batch size is “maximized to fit VRAM” per method, potentially conflating algorithmic efficiency with batch-size effects; normalized comparisons (e.g., fixed batch size/seq length) are needed.
- Implementation details for reproducibility: key hyperparameters (learning rates, warm-up duration, optimizer configs, gradient clipping, scheduler, precision, tokenization) and code availability are missing, hindering replication.
- Ablations on reversible design choices: no ablation for symmetric vs. asymmetric coupling, attention vs. FFN order, number/placement of projection adapters, or alternative normalization schemes to isolate what drives gains.
- Error accumulation across depth: while per-layer reconstruction is addressed, cumulative numerical error across deep stacks during backpropagation is not measured; report layer-wise and end-to-end inversion error statistics.
- Impact on pre-trained representations: the two-stage adapter warm-up is proposed without analysis of how it preserves or distorts pre-trained feature geometry; probe with representation similarity metrics (e.g., CKA) and perplexity.
- Memory of MoE-specific buffers: the work does not quantify memory used by expert-specific activations, routing structures, and dispatch/combining buffers under reversibility, especially with top-k expert selection.
- Safety and stability under distribution shift: whether freezing routers and altering attention coupling affects robustness on out-of-distribution inputs or multilingual domains is untested; targeted evaluations needed.
Practical Applications
Immediate Applications
The following applications can be implemented now using the RevFFN approach described in the paper. They leverage its reversible Transformer blocks, projection adapters, and two-stage fine-tuning schedule to reduce activation memory during backpropagation while preserving full-parameter updates.
- Single-GPU, full-parameter fine-tuning for regulated on-prem deployments (healthcare, finance, legal)
- Use case: Fine-tune domain-specific LLMs on sensitive data within hospital, bank, or law firm servers without multi-GPU clusters.
- Tools/products/workflows: A “revffn-hf” wrapper for Hugging Face Transformers; training ops using the two-stage schedule (adapter warm-up → joint fine-tuning); MoE router freezing for stability.
- Assumptions/dependencies: Availability of a compatible MoE backbone (e.g., Qwen1.5-MoE), GPU with sufficient VRAM (e.g., 24–80 GB depending on model size and batch), careful numerical handling of reversible inversion and fixed-point iteration.
- Cost-aware fine-tuning pipelines for small and mid-sized enterprises (software, customer support, e-commerce)
- Use case: Reduce training hardware costs by enabling full fine-tuning on fewer GPUs and smaller instances without sacrificing downstream performance.
- Tools/products/workflows: MLOps integration (Weights & Biases, MLflow) with RevFFN training profiles; memory-aware schedulers that pack more experiments per GPU.
- Assumptions/dependencies: Throughput overhead due to recomputation is acceptable; task performance gains justify longer wall-clock times versus PEFT.
- Academic reproducibility and broader access to full fine-tuning (education, research)
- Use case: Labs and courses can run full-parameter fine-tuning of MoE LLMs on single-GPU workstations, enabling hands-on teaching and experiments previously gated by memory constraints.
- Tools/products/workflows: Teaching modules and templates demonstrating reversible blocks, adapter warm-up, and MoE preservation; open-source tutorial notebooks.
- Assumptions/dependencies: Availability of open-source MoE checkpoints; instructor familiarity with Hugging Face/PyTorch; datasets that fit single-GPU training budgets.
- Privacy-preserving local customization of open-source assistants (daily life, SMBs)
- Use case: Individuals and small businesses customize assistants (e.g., internal FAQs, specialized workflows) locally without cloud data transfer.
- Tools/products/workflows: CLI for converting standard Transformer layers to RevFFN; small-batch training scripts tuned to consumer/server-grade GPUs.
- Assumptions/dependencies: Model size chosen to fit VRAM; data curation quality; potential pairing with quantization for 16–24 GB GPUs.
- CI/CD for model iteration with memory-efficient full fine-tuning (software/MLOps)
- Use case: Integrate RevFFN into automated training pipelines to push frequent model updates (new datasets, reward-model improvements) without scaling GPU fleets.
- Tools/products/workflows: GitHub Actions or self-hosted runners using RevFFN profiles; experiment orchestration with throughput/memory KPIs.
- Assumptions/dependencies: Stable reversible implementation; monitoring to catch rare numerical issues; task-specific validation (e.g., MT-Bench, MMLU).
- On-premise AI adoption for public sector organizations (policy/government)
- Use case: Agencies fine-tune LLMs for citizen services, regulations, and multilingual communication under strict data sovereignty constraints.
- Tools/products/workflows: Procurement-ready training profiles emphasizing reduced hardware requirements; governance templates referencing on-prem fine-tuning feasibility.
- Assumptions/dependencies: Reliability demonstration beyond Dolly; multilingual benchmarks relevant to jurisdiction; procurement compliant with local regulations.
- Benchmarking and model analysis with full-parameter updates at lower memory (academia/industry R&D)
- Use case: Run ablations, hyperparameter sweeps, and architecture studies on MoE LLMs with reduced activation memory pressure.
- Tools/products/workflows: Automated sweeps using RevFFN; instrumentation to compare reversible vs. residual stacks; router-freeze vs. router-tune variants.
- Assumptions/dependencies: Sufficient compute for recomputation overhead; robust logging and diagnostics during inversion.
- Fine-tune-as-a-Service offerings with lower hardware footprints (cloud and AI services)
- Use case: Managed services provide full-parameter fine-tuning tiers at lower cost by using RevFFN to reduce GPU memory requirements.
- Tools/products/workflows: REST APIs and consoles exposing RevFFN-backed training jobs; price tiers mapped to memory savings.
- Assumptions/dependencies: SLA alignment with slower throughput; customer tasks benefit from full fine-tuning over PEFT; robust support for multiple backbones.
Long-Term Applications
The following applications require further research, scaling, integration, or engineering to become deployable. They extend RevFFN’s ideas to larger models, modalities, and deployment contexts.
- Extension to dense and multimodal LLMs (vision-language, speech-language)
- Use case: Memory-efficient full fine-tuning of dense Transformers and VLMs with reversible blocks (e.g., encoder-decoder stacks; expert routing across modalities).
- Tools/products/workflows: Reversible adapters for vision encoders, cross-attention bridges, and audio front-ends.
- Assumptions/dependencies: Stability of reversible designs beyond MoE; adapter generalization to non-MoE layers; careful handling of normalization across streams.
- RevFFN + quantization and optimizer-level memory reduction (software/AI platforms)
- Use case: Combine reversible activations with QLoRA-like quantization, GaLore/LoMo optimizers, or ZeRO/FSDP to push memory requirements into 16–24 GB territory.
- Tools/products/workflows: Composite training stacks (RevFFN + quantization + low-rank gradients); auto-tuning of precision vs. stability; compatibility matrices.
- Assumptions/dependencies: Maintaining reversibility and accuracy under quantization; optimizer interactions not destabilizing training.
- Continuous, privacy-preserving on-device adaptation (edge computing, robotics)
- Use case: Periodic or streaming fine-tuning of local assistants or robot instruction models using small edge servers.
- Tools/products/workflows: Lightweight continual learning pipelines; reversible checkpoints; drift detection and rollback mechanisms.
- Assumptions/dependencies: Hardware constraints on the edge; catastrophic forgetting mitigations; energy and thermal limits.
- Federated full fine-tuning with lower client hardware requirements (healthcare networks, finance consortia)
- Use case: Clients with modest GPUs participate in federated training of MoE LLMs, contributing updates without storing heavy activations.
- Tools/products/workflows: Federated orchestration integrating RevFFN clients; secure aggregation; differential privacy.
- Assumptions/dependencies: Communication overhead vs. memory savings balance; legal/privacy frameworks; robustness to heterogeneous hardware.
- Scaling to very large MoE models with hybrid distributed strategies (HPC, cloud)
- Use case: Train/tune trillion-parameter MoE models using reversible layers to reduce activation memory, combined with ZeRO/FSDP for parameter sharding.
- Tools/products/workflows: High-bandwidth interconnect-aware schedulers; reversible-aware checkpointing; router tuning protocols.
- Assumptions/dependencies: Inter-device bandwidth still critical; recomputation overhead manageable at scale; robust error handling for inversion.
- Energy and carbon footprint reductions via fewer GPUs (energy, sustainability)
- Use case: Lower total GPU count for training tasks, potentially reducing energy use and emissions, especially in data centers with green targets.
- Tools/products/workflows: Sustainability calculators integrated with RevFFN job profiles; reporting dashboards for procurement and ESG compliance.
- Assumptions/dependencies: Net energy balance must account for recomputation overhead; empirical audits needed across tasks and model sizes.
- Policy frameworks for equitable AI access and data sovereignty (policy)
- Use case: Guidelines encouraging memory-efficient training practices to broaden access in education and public sector while keeping data local.
- Tools/products/workflows: Policy drafts referencing reversible training; grant programs that fund single-GPU AI labs; compliance checklists.
- Assumptions/dependencies: Demonstrated reliability across diverse benchmarks; vendor-neutral implementations to avoid lock-in.
- Production-grade libraries and SDKs for reversible Transformers (software tooling)
- Use case: A stable SDK that wraps common LLM architectures with reversible blocks, offering configuration presets and validation harnesses.
- Tools/products/workflows: PyTorch/Hugging Face extensions; automated sanity checks for inversion error; profiling and memory tracing tools.
- Assumptions/dependencies: API stability across model families; community adoption; robust test suites.
- Lifelong learning pipelines leveraging reversible memory savings (education tech, enterprise knowledge management)
- Use case: Regularly refresh models with new curricula or corporate knowledge without expanding hardware fleets.
- Tools/products/workflows: Scheduled fine-tuning jobs; adapters for domain shifts; assessment loops (MMLU, MT-Bench, domain-specific KPIs).
- Assumptions/dependencies: Avoiding representation drift; router-freeze policies may need rethinking for major domain changes.
- Personalized AI on consumer devices as hardware evolves (daily life)
- Use case: Future consumer GPUs or specialized NPUs enable limited on-device full fine-tuning using reversible designs for customization (e.g., personal journals, local datasets).
- Tools/products/workflows: Privacy-first local training apps; reversible-aware mobile runtimes; safe model update UX.
- Assumptions/dependencies: Hardware trajectory (VRAM, bandwidth) and efficient reversible implementations; robust fallback to PEFT when full fine-tuning is infeasible.
Glossary
- Activation checkpointing: A technique that reduces memory usage during training by recomputing certain activations instead of storing them. "Activation checkpointing further reduces memory via recomputation, but these techniques usually require multi-GPU clusters and are often constrained by interconnect bandwidth when offloading activations."
- Adapter warm-up: An initial training phase where only adapter layers are trained to align new components with pre-trained representations. "Stage 1: Adapter warm-up."
- Backpropagation: The gradient-based process of updating model parameters by propagating errors from outputs back through the network. "caching extensive intermediate activations for backpropagation."
- Bijection: A one-to-one and onto mapping that enables exact inversion; in reversible networks, it ensures inputs can be reconstructed from outputs. "form a bijection,"
- Catastrophic forgetting: A phenomenon where a model abruptly loses previously learned knowledge when trained on new tasks. "while avoiding catastrophic forgetting."
- Cross-Attention: An attention mechanism where queries attend to keys/values from a different representation or stream. "processed by Cross-Attention and MoE,"
- Fixed-point iteration: An iterative method to solve equations where a function is repeatedly applied to approach a stable solution. "in practice we run one fixed-point iteration starting from ."
- Fully Sharded Data Parallel (FSDP): A distributed training approach that partitions model parameters, gradients, and optimizer states across devices to reduce per-GPU memory. "DeepSpeed ZeRO and Fully Sharded Data Parallel (FSDP) address memory bottlenecks by partitioning model states across devices."
- GaLore: A memory-efficient full-parameter training method that projects gradients into a low-rank space to reduce optimizer memory. "GaLore: A state-of-the-art memory-efficient strategy that uses a Gradient Low-Rank Projection optimizer to enable full-parameter tuning with reduced memory overhead"
- Gating networks: Components in MoE models that route tokens to experts based on learned scores. "MoE gating networks remain frozen to preserve routing stability"
- Gradient checkpointing: A memory-saving technique that stores fewer activations during the forward pass and recomputes them during the backward pass. "augmented with gradient checkpointing to reduce memory at the cost of recomputation"
- Gradient Low-Rank Projection: An optimization strategy that reduces memory by constraining gradients to a low-rank subspace. "uses a Gradient Low-Rank Projection optimizer"
- LayerNorm: A normalization technique applied per token across features to stabilize and accelerate training. "LayerNorm + residual connections around both."
- LoMo: A memory-efficient optimizer that fuses gradient computation with parameter updates to reduce memory for optimizer states. "LoMo: A memory-efficient optimizer that fuses gradient computation and parameter updates, significantly reducing memory usage for optimizer states"
- LoRA: A parameter-efficient fine-tuning method that inserts trainable low-rank adapters into existing layers. "LoRA: A widely-used method that trains low-rank adapters, serving as a low-memory, high-throughput baseline"
- Memory sharding: Distributing model states across multiple devices to reduce the memory burden on any single GPU. "Memory sharding and offloading, exemplified by DeepSpeed's ZeRO and PyTorch's FSDP,"
- Mixture-of-Experts (MoE): An architecture that uses multiple expert networks with sparse routing to increase model capacity efficiently. "preserving the integrity of the Mixture-of-Experts (MoE) architecture,"
- Parameter-Efficient Fine-Tuning (PEFT): A class of methods that fine-tune a small subset of parameters or added modules rather than all model weights. "Parameter-Efficient Fine-Tuning (PEFT), such as LoRA, which drastically cuts memory usage by training only a small set of adapter parameters"
- Projection adapters: Lightweight linear layers that map between different feature dimensions to interface reversible streams with pre-trained modules. "we introduce lightweight projection adapters: two small linear layers placed before and after each pre-trained block,"
- QLoRA: A PEFT variant enabling fine-tuning of quantized models using low-rank adapters. "LoRA\cite{DBLP:journals/corr/abs-2106-09685} and its variants (e.g., QLoRA\cite{dettmers2023qloraefficientfinetuningquantized}) exemplify parameter-efficient fine-tuning (PEFT), achieving low memory usage by inserting low-rank adapters and training only these modules."
- Residual connections: Skip connections that add input to output of a sub-layer to aid gradient flow and stability. "LayerNorm + residual connections around both."
- RevFFN: The proposed reversible Transformer block design for memory-efficient full-parameter fine-tuning of MoE LLMs. "we introduce RevFFN, a novel memory-efficient fine-tuning paradigm."
- Reversible networks: Architectures where layer inputs can be exactly reconstructed from outputs, eliminating the need to store activations. "Reversible networks, first introduced by RevNet, draw inspiration from Ordinary Differential Equation (ODE) solvers"
- Routing stability: The consistency of expert selection in MoE models during training, important for convergence and performance. "to preserve routing stability"
- SFT w/ Activation Checkpointing: Supervised fine-tuning enhanced by activation/gradient recomputation to reduce memory. "SFT w/ Activation Checkpointing: The conventional approach to full fine-tuning, augmented with gradient checkpointing to reduce memory at the cost of recomputation"
- Two-Stage Training Schedule: A curriculum that first trains adapters then performs joint fine-tuning for stability and performance. "Two-Stage Training Schedule"
- VRAM: The GPU’s memory used to store activations, parameters, and intermediate states during training. "Peak VRAM Usage: The maximum GPU memory allocated during training, measured in Gigabytes (GB)."
- ZeRO: A DeepSpeed optimization that partitions optimizer states, gradients, and parameters across devices to reduce memory. "DeepSpeed's ZeRO"
Collections
Sign up for free to add this paper to one or more collections.