- The paper introduces a Superchip-centric offloading system that eliminates GPU idle time and boosts throughput by rethinking traditional offloading methods.
- The paper details techniques such as adaptive offloading, fine-grained bucketization, and speculation-then-validation scheduling to optimize data placement and computation.
- The paper also presents GraceAdam, an optimized Adam for ARM CPUs, achieving up to 2.5× throughput improvement and enabling training of models with up to 200B parameters.
SuperOffload: Systematic Offloading for Large-Scale LLM Training on Superchips
Introduction and Motivation
The exponential growth in LLM parameter counts has outpaced the increase in GPU memory capacity and bandwidth, creating a persistent memory wall for large-scale training. While distributed training techniques such as ZeRO-DP, tensor parallelism, and pipeline parallelism have enabled scaling, they require substantial GPU resources, limiting accessibility for many practitioners. Offloading-based solutions, which leverage CPU memory to store model states and perform memory-intensive computations, have emerged as a promising alternative. However, these methods were designed for traditional, loosely-coupled GPU-CPU architectures connected via PCIe, and their design assumptions do not hold for the new generation of tightly-coupled Superchips.
Superchips, exemplified by NVIDIA's GH200 Grace Hopper, integrate Hopper GPU and Grace CPU in a single package with a high-bandwidth NVLink-C2C interconnect (up to 900 GB/s), fundamentally altering the compute and memory landscape. The paper introduces SuperOffload, a Superchip-centric offloading system that systematically rethinks offloading strategies to maximize utilization of GPU, CPU, and interconnect resources. SuperOffload combines adaptive offloading policies, fine-grained bucketization, speculation-then-validation scheduling, Superchip-aware casting, and an optimized Adam implementation for ARM CPUs, achieving significant throughput and scalability improvements over prior art.
Superchip Architecture and Offloading Challenges
Superchips differ from conventional GPU+CPU nodes in several key aspects: (1) the NVLink-C2C interconnect offers 30× higher bandwidth than PCIe, (2) the Grace CPU provides substantial memory and compute resources, and (3) the tightly-coupled design enables low-latency data movement. These features invalidate the PCIe-centric design principles of previous offloading systems, which focused on minimizing communication volume and avoiding PCIe bottlenecks.
Despite these advantages, naive offloading approaches still suffer from substantial GPU and CPU idle time due to synchronization barriers and suboptimal scheduling. For example, ZeRO-Offload incurs 40–50% GPU idle time per iteration on Superchips, as shown in the following figure:
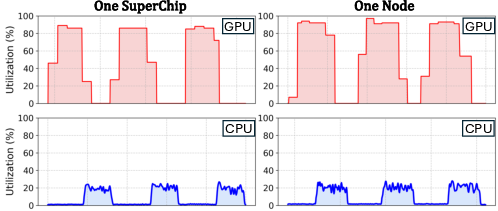
Figure 1: Prior offloading-based solutions cause idle time on both GPU and CPU side, with the GPU remaining idle for 40–50% of the total execution time per iteration.
SuperOffload addresses these inefficiencies by redesigning the offloading pipeline to fully exploit Superchip hardware characteristics.
SuperOffload System Design
System Overview
SuperOffload models the training pipeline as a Superchip-aware dataflow graph (SA-DFG), where each operator is assigned to either the Hopper GPU or Grace CPU based on compute and communication costs. The system employs a combination of techniques to optimize data placement, computation, and tensor migration.
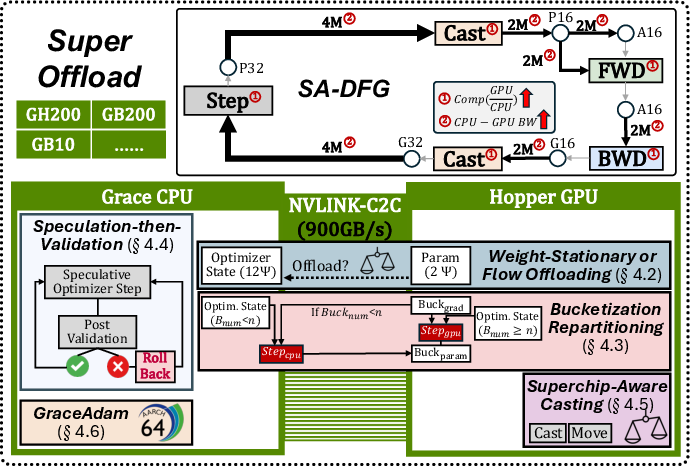
Figure 2: Overview of SuperOffload, showing Superchip-centric optimization of data placement, computation, and tensor migration between Hopper GPU and Grace CPU via NVLink-C2C.
Adaptive Weight Offloading
SuperOffload supports both weight-stationary (weights remain on GPU) and weight-flow (weights are offloaded to CPU and loaded as needed) policies. The optimal strategy is scenario-dependent: for large models with small batch sizes, weight-stationary is preferred; for long-sequence training where activation memory dominates, weight-flow becomes advantageous. The system adaptively selects the offloading policy based on model size, batch size, and sequence length, ensuring high efficiency.
Fine-Grained Bucketization
To overlap computation and communication, SuperOffload partitions model states into buckets (optimal size ≈ 64 MB, matching C2C bandwidth saturation) and dynamically determines the number of buckets to retain on GPU. This approach balances the compute gap between Hopper GPU and Grace CPU (FLOPS ratio ≈ 330), minimizing critical path latency and maximizing resource utilization.
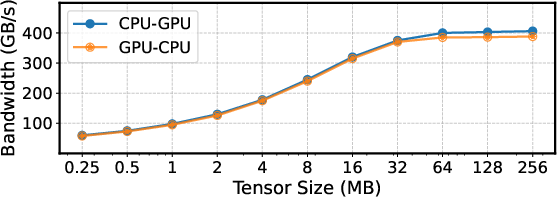
Figure 3: GH200 bandwidth measurement, showing bandwidth saturation at tensor sizes ≈ 64 MB.
Speculation-Then-Validation Scheduling
SuperOffload introduces a speculation-then-validation (STV) schedule, replacing the conventional synchronization-then-execution paradigm. The CPU speculatively performs optimizer steps in parallel with GPU backward propagation, deferring global checks (e.g., gradient clipping, NaN/INF detection) to idle CPU cycles. Rollbacks are triggered only when necessary, preserving exact convergence while eliminating synchronization bottlenecks.
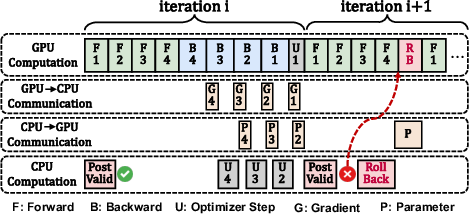
Figure 4: SuperOffload speculation-then-validation schedule, overlapping optimizer steps with backward propagation and eliminating synchronization bottlenecks.
Superchip-Aware Casting
Mixed-precision training requires frequent casting between FP16 and FP32. SuperOffload empirically demonstrates that casting on GPU and transferring FP32 tensors is faster than casting on CPU and transferring FP16, due to memory alignment and pinned memory effects. The system adopts GPU-side casting, further reducing overhead.
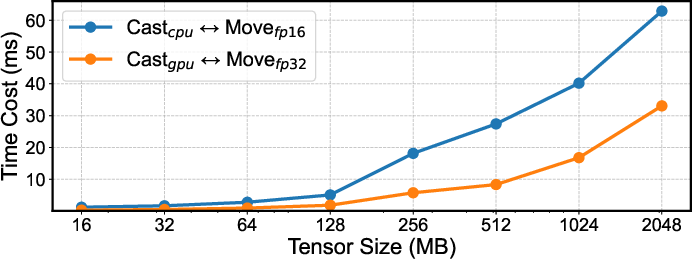
Figure 5: Time cost comparison for casting operations on GPU vs. CPU (including data transfer overhead), showing GPU-side casting is consistently faster.
GraceAdam: Optimized Adam for ARM CPUs
SuperOffload implements GraceAdam, an Adam optimizer tailored for ARM's Scalable Vector Extension (SVE), leveraging length-agnostic vectorization, cache-friendly tiling, explicit prefetching, and OpenMP multithreading. GraceAdam achieves >3× speedup over PyTorch's native CPU Adam and 1.36× over ZeRO-Offload's CPU-Adam.
Multi-Superchip Scaling and Long-Sequence Training
SuperOffload integrates seamlessly with ZeRO-3 data parallelism and Ulysses sequence parallelism, enabling efficient scaling across multiple Superchips. The system supports training of 50B-parameter models on 4 Superchips and 200B models on 16 Superchips, far exceeding the limits of prior solutions. For long-sequence training, SuperOffload-Ulysses enables million-token context windows for 13B models on 8 Superchips, achieving 55% MFU.
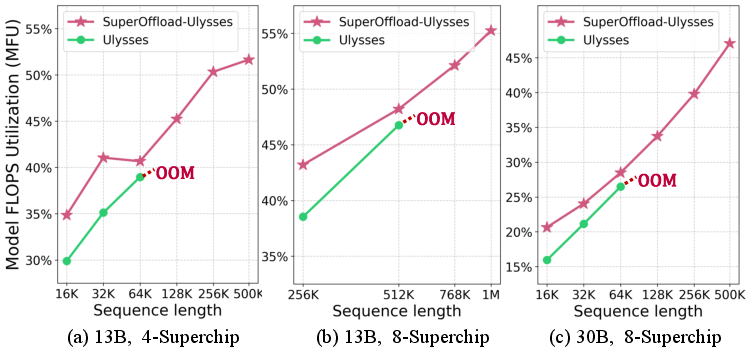
Figure 6: Supported sequence lengths and corresponding MFU using SuperOffload-Ulysses and Ulysses. OOM denotes the point where increasing sequence length causes OOM.
Throughput and Model Scale
SuperOffload achieves up to 2.5× throughput improvement over ZeRO-Offload and outperforms GPU-only approaches across all tested model sizes. On a single Superchip, it enables training of 25B-parameter models (7× larger than GPU-only), and on 16 Superchips, it scales to 200B parameters.
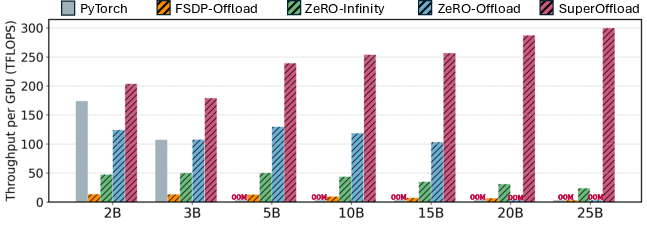
Figure 7: Training throughput with PyTorch DDP, FSDP-Offload, ZeRO-Infinity, ZeRO-Offload, and SuperOffload on a single Superchip.
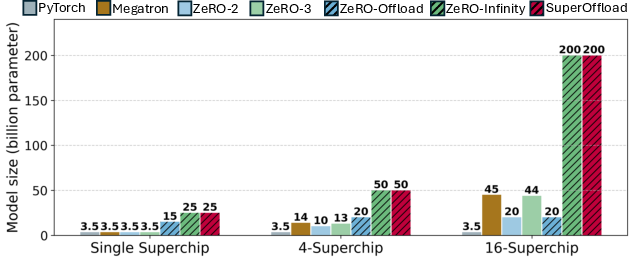
Figure 8: The size of the biggest model that can be trained on single Superchip, 4 and 16 Superchips.
Component Breakdown
A systematic ablation paper shows that speculation-then-validation delivers the largest throughput gain (45%), followed by bucketization repartitioning (14%), Superchip-aware casting (12.7%), and GraceAdam (10.4%). The combined effect yields a 2.06× improvement over the baseline.
GPU Utilization
SuperOffload eliminates GPU idle time, achieving near-complete resource utilization.
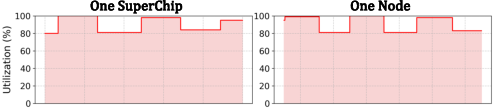
Figure 9: SuperOffload fully utilizes the GPU resources.
Rollback Overhead
Speculation-then-validation incurs negligible rollback overhead (<0.12% of iterations for 175B model), with rollbacks completed in parallel across CPUs.
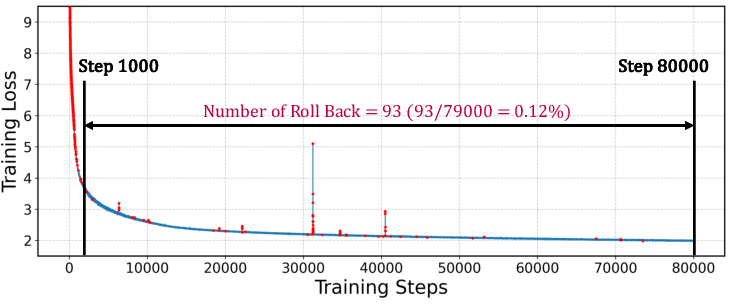
Figure 10: Training loss and rollback occurrences during training of the GPT 176B model over 80,000 iterations. Red dots indicate iterations where rollbacks were triggered due to gradient clipping, NaN or INF values.
Practical Implications and Future Directions
SuperOffload fundamentally challenges the conventional wisdom that offloading incurs a performance penalty, demonstrating that, with Superchip-centric optimizations, offloading can outperform GPU-only training. The system democratizes large-scale LLM training, enabling researchers to train models with hundreds of billions of parameters and million-token contexts using modest Superchip clusters. The integration with DeepSpeed and minimal code changes (see Figure 11) further enhance usability.

Figure 11: SuperOffload can be enabled with a few lines of change. The code on left shows a standard training pipeline, while the right shows the same pipeline with SuperOffload.
Theoretically, the work motivates a re-examination of offloading strategies in the context of emerging hardware architectures, emphasizing the need for hardware-aware system design. Practically, it opens avenues for efficient post-training, long-context adaptation, and fine-tuning on resource-constrained clusters.
Future research directions include extending SuperOffload to heterogeneous Superchip clusters (e.g., Blackwell-based systems), further optimizing inter-node communication, and exploring offloading strategies for multimodal and vision-LLMs.
Conclusion
SuperOffload presents a comprehensive, Superchip-centric solution for large-scale LLM training, systematically addressing the limitations of prior offloading systems. Through adaptive offloading, fine-grained scheduling, hardware-aware casting, and optimized CPU computation, SuperOffload achieves substantial throughput and scalability improvements, fully utilizing Superchip resources. The system enables training of models and sequence lengths previously unattainable on modest hardware, with direct implications for democratizing LLM research and deployment.

