Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Abstract: We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to rebuild a 3D model of an object from just a few photos (as few as four). Instead of placing 3D pieces on a fixed grid tied to the images, the method freely places many tiny colored “blobs” in 3D space. These blobs are called “3D Gaussians,” and when you render them, they look like the object. The authors’ method is “generative,” which means it learns to imagine and fill in parts that the photos don’t show, while still matching what the photos do show.
What questions were the researchers trying to answer?
- Can we reconstruct complete, sharp 3D objects from only a few photos—even when some parts are never seen?
- Can we avoid wasteful, grid-based layouts and place the 3D pieces exactly where they’re needed?
- Can we keep the model efficient (fast and compact) without losing detail?
How did they do it? (In everyday language)
Think of building a 3D object from lots of tiny, soft, colored balloons. Each balloon has a position, size, shape, transparency, and color. If you throw enough balloons into the right places, you can make a 3D object that looks real when you take a picture of it from any angle. That’s the idea behind “3D Gaussian splatting.”
Here’s how their approach works:
- Free placement, not on a grid:
- Older methods glue each balloon to a pixel in a photo (pixel-aligned) or to a cube in a 3D grid (voxel-aligned). That makes them easy to organize but very wasteful and limited: they put too many balloons in seen areas and leave holes or blur in places the photos didn’t show.
- This paper’s method is “free-range”: balloons can go anywhere in 3D to best match the object. No grid required.
- Generative reconstruction (flow matching):
- Imagine starting with a cloud of noise—balloons placed randomly.
- Step by step, a learned model “denoises” this cloud, nudging balloons into the right positions, sizes, and colors so that, in the end, the balloon cloud looks like the object.
- This process is called “flow matching.” It learns how to move from noise to the final shape smoothly.
- Because it’s generative, the model can make sensible guesses for parts of the object that weren’t visible in the photos, instead of averaging everything into a blurry mush.
- Handling lots of balloons efficiently (hierarchical patching):
- High-quality models need tens of thousands of balloons. Processing all of them at once is heavy.
- The authors build a “family tree” (a level-of-detail hierarchy) for the balloons: big balloons at the top represent coarse shape; as you go down the tree, you split into smaller balloons for finer detail.
- During training, they use a “coarse-to-fine” schedule: first teach the model with fewer, coarser balloons, then refine with more, finer balloons.
- They also “patchify” by grouping nearby balloons into pairs before feeding them to the transformer (a type of neural network). This cuts the sequence length roughly in half while keeping local structure.
- Extra guidance to keep results sharp and faithful to the photos:
- Timestep-weighted rendering loss: early in denoising, the model’s guess is messy, so strong image penalties aren’t helpful. The loss gradually increases later, when the shape is clearer—like focusing on details once the outline is right.
- Photometric gradient guidance: at each step, the method measures how the current balloon cloud’s render differs from the input photos and uses that “nudge” to push balloons in the right direction. It does this during both training and testing to stay faithful to the images.
- Classifier-free guidance: when generating, it “turns up the volume” on the conditioning from the input photos so the final result sticks to what’s seen.
- The model in brief:
- It uses a transformer (a powerful sequence model) to process image features (from a pre-trained image encoder) and balloon parameters together.
- It predicts how to move from noisy balloons to clean, correctly placed balloons over about 50 steps.
What did they find?
- Fewer balloons, better coverage:
- Their method reconstructs objects using around 8,000 balloons, while many other methods use 45,000–500,000. That’s about 10× fewer, which is more compact and efficient.
- Strong quality with only four input photos:
- When the four photos cover the whole object, quality is on par with or better than grid-based methods, despite using far fewer balloons.
- When the four photos only show one side (large unseen areas), their method clearly outperforms others. It keeps seen parts accurate and fills in unseen parts with sharp, believable details—fewer holes and less blur.
- Tested on diverse data:
- They trained on a large set of 3D objects (Objaverse) and evaluated on both Objaverse and Google Scanned Objects (real-world household items).
- Across these tests, they got better perceptual scores (meaning the results looked sharper and more realistic) and maintained good faithfulness to the input views.
- Practical performance:
- On powerful hardware, generating a single object takes under half a minute. The compact balloon set means less memory and faster rendering at test time.
Why does this matter?
- Better 3D from fewer photos:
- For AR/VR, games, e-commerce, or robotics, being able to quickly create a detailed 3D model from just a handful of pictures is extremely useful.
- Compact and fast:
- Using far fewer balloons makes models lighter and more practical to store and render in real time.
- Sharp, believable results even with missing views:
- The generative approach can “imagine” plausible unseen parts without ignoring what the photos actually show, making the final 3D object both faithful and complete.
In short, this work shows that letting “free-range” 3D blobs be placed anywhere—guided by a smart, step-by-step generative process—can rebuild high-quality 3D objects from just a few pictures, with sharper details and fewer resources than grid-based methods.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps, limitations, and open questions that remain unresolved and could guide future research:
- Assumption of known, accurate camera poses: sensitivity to pose/intrinsic errors is unquantified; extension to uncalibrated or noisy-pose settings (including joint pose refinement) is unexplored.
- Reliance on pseudo–ground-truth Gaussians (3DGS-MCMC) from Objaverse introduces teacher bias; the impact of inaccuracies in teacher reconstructions and alternative supervision sources (e.g., meshes, raw multi-view photos without 3DGS pre-optimization) is unstudied.
- Object-centric scope only: extension to full scenes with cluttered backgrounds, occlusions, multiple objects, and large-scale environments is not addressed.
- Background handling/segmentation assumptions are unclear; robustness to in-the-wild captures with complex backgrounds and imperfect masks is not evaluated.
- Appearance modeling appears limited to per-Gaussian RGB (no explicit view dependence); the ability to reproduce specular/transparent materials and strong view-dependent effects is not characterized; SH or learned appearance decoders remain unexplored.
- Lack of 3D geometry accuracy metrics: evaluation focuses on image-space metrics; no Chamfer/EMD-to-mesh, normal consistency, or depth accuracy benchmarks to quantify geometric fidelity.
- Behavior under very sparse views (1–2) and extreme occlusions is only partially explored; failure modes and minimum-view thresholds are not systematically characterized.
- Fixed Gaussian budget and fixed hierarchical topology: there is no mechanism for adaptive token count, dynamic densification/refinement, or learned hierarchy at inference.
- Training-time LoD/patchification depends on a ground-truth tree; how to form coherent patches at inference without a teacher hierarchy (and sensitivity if spatial coherence breaks) is not addressed.
- Sequence scalability remains constrained (4K tokens after patching; quadratic attention): alternatives like larger patch sizes, sparse/linear attention, graph attention, or latent-space diffusion to scale to 50K–100K Gaussians are not investigated.
- Computational cost is high (≈26 s per object, 50 steps; training on 64×H200 for 6 days); acceleration via distillation, consistency models, higher-order ODE solvers, or step-reduction techniques is not studied.
- Photometric gradient guidance alters the ODE dynamics; theoretical analysis of stability/convergence, as well as sensitivity to the guidance scale and adaptive scheduling, is missing.
- Classifier-free guidance can trade diversity for fidelity; there is no study of diversity–fidelity trade-offs, sample variance across multiple draws, or selection strategies among plausible completions.
- Robustness to pose/intrinsic noise and domain shift (e.g., real, handheld captures with varying exposure/lighting) is insufficiently quantified; GSO is a step, but broader real-world evaluation is needed.
- The timestep weighting w(t) for rendering loss is heuristic; comparisons to learned schedules or principled alternatives (e.g., loss-aware curricula) and theoretical justification are absent.
- No direct comparison to strong deterministic set-regression baselines (e.g., predicting non-grid Gaussians with Chamfer/EMD losses under matched compute) to more rigorously substantiate generative vs. regressive claims.
- Uncertainty estimation is absent; per-region uncertainty over hallucinated completions (and its use for active next-best-view selection) is not explored.
- Multi-view consistency metrics and user studies for hallucinated regions are lacking; evaluation could include CLIP-IQA, multi-view photometric consistency, and human preference studies.
- Illumination/BRDF disentanglement is not addressed; the model does not separate geometry from lighting/materials, limiting relighting and generalization under novel illumination.
- Category-specific performance and failure cases (thin structures, high-frequency textures, glossy/transparent, textureless objects) are not analyzed; robustness stratified by category remains unknown.
- Integration with active view planning is untapped: using predicted uncertainty or gradient signals to decide which novel views to capture could further improve reconstruction.
- Extension to dynamic or non-rigid objects (temporal coherence, motion) is not considered.
- Data efficiency is unclear: scaling laws, performance with fewer training objects, augmentation strategies, or pretraining/fine-tuning regimes have not been studied.
- Baseline fairness and reproducibility: GS-LRM is reimplemented; ReconViaGen requires alignment with reported high failure rates—standardized, public evaluation protocols and code would strengthen comparisons.
- Resolution limits: only up to 512×512 inputs in training; behavior with higher-resolution inputs/outputs and explicit multi-scale image features remains unexplored.
- Loss design: only L1 photometric loss is used; adding geometry-aware supervision (silhouette, depth, normals) without inducing blurriness is an open direction.
- Redundancy control: sparsity/entropy regularization over opacity/color to reduce redundant Gaussians and improve parsimony is not investigated.
- Token-order invariance and stability: with no positional encodings, attention is permutation-equivariant, but supervision uses a fixed slot order; sensitivity to token ordering and its effect on generalization is not characterized.
- Patchification design space is narrow (pairs of siblings): larger/overlapping groups, learned graph-based groupings, or content-adaptive patching could offer better speed–quality trade-offs.
- Generalization across camera models and extreme baselines: although Plücker rays are used, robustness to wide-FOV/fisheye, rolling shutter, or large parallax is not studied.
Practical Applications
Overview
Based on the paper “Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction,” the method enables compact, high-fidelity 3D object reconstructions from as few as four posed images by generatively denoising non-grid-aligned 3D Gaussian parameters using flow matching. Key practical advantages are: sharp completion of unobserved regions, an order-of-magnitude fewer Gaussians than grid-aligned methods, and compatibility with real-time 3D Gaussian Splatting renderers. Below are concrete applications mapped to sectors, deployment timelines, and dependencies.
Immediate Applications
- Fast 3D product digitization for web and mobile (retail/e-commerce, software)
- Use case: Create photoreal 3D product viewers from 4 smartphone photos for online listings, ads, and AR try-ons.
- Tools/workflows:
- Capture guide (4 posed photos with basic calibration or ARKit/ARCore pose estimates).
- Cloud/API service running the model; export to 3DGS for web viewers or convert to meshes for broad engine support.
- Plugins for Shopify, WooCommerce, or social ad platforms to embed interactive 3D.
- Assumptions/dependencies: Requires estimated camera poses; best performance with opaque, matte objects and clean backgrounds; domain shift from Objaverse training may require light fine-tuning for niche categories.
- Rapid asset creation for XR and games from sparse views (media/entertainment, AR/VR)
- Use case: Turn art reviews, mood boards, or model sheets into 3D assets with only 4 reference images; plausible backside completion reduces manual modeling time.
- Tools/workflows:
- DCC plugins (Blender, Maya) to import/export Gaussians, edit materials, and convert to meshes.
- Unreal/Unity integration via 3DGS renderers or mesh conversion.
- Assumptions/dependencies: Gaussian-based assets may need remeshing/retopology for physics, LODs, or engine constraints; reflective/translucent materials remain challenging.
- Inventory digitization at scale (marketplaces, logistics)
- Use case: Warehouse-side capture booths take four shots per item to auto-generate 3D previews; asset counts benefit from 10× fewer Gaussians (lower hosting and rendering costs).
- Tools/workflows:
- Fixed multi-camera rigs with known intrinsics/extrinsics.
- Batch inference pipeline; automated quality checks for pose errors and outliers.
- Assumptions/dependencies: Calibration stability and controlled lighting materially improve results; hallucinated unseen regions may be unsuitable for metrology-grade use.
- Object shape completion for robot perception (robotics)
- Use case: Improve grasp planning or collision avoidance when only partial views are available; the model infers plausible completions for hidden geometry.
- Tools/workflows:
- ROS node that ingests 2–4 robot-camera frames with poses and outputs a compact 3D Gaussian model or mesh.
- Plug into existing grasp planners or occupancy predictors.
- Assumptions/dependencies: Completeness is plausible—not guaranteed accurate—for unobserved regions; unsuitable where exact geometry is required (e.g., tight tolerances).
- Cultural heritage item capture with limited access (museums/GLAM)
- Use case: Digitize artifacts (front-only access) from a small number of allowed viewpoints; fill in plausible, visually consistent backsides for public visualization.
- Tools/workflows:
- Portable rig with constrained camera placements and pose estimation.
- Online/onsite processing; view-only web experiences using 3DGS viewers.
- Assumptions/dependencies: Completed areas are plausible reconstructions; curatorial notes should disclose synthetic completion to avoid misinterpretation.
- Education and research prototyping (academia)
- Use case: Teaching and experimentation with flow matching in 3D, hierarchical tokenization, and guidance strategies for conditional generation from sparse views.
- Tools/workflows:
- Open-source 3DGS rasterizers; integration with PyTorch/DiT training stacks; curriculum for LoD training.
- Assumptions/dependencies: Requires GPU resources; training at scale demands large 3D datasets similar to Objaverse.
- Insurtech and claims visualization (finance/insurance)
- Use case: Produce quick 3D visualizations from a few claim photos to support remote assessments and customer communication.
- Tools/workflows:
- Claim intake app guiding users to capture four views (with phone pose sensing).
- Assumptions/dependencies: Visual plausibility ≠ geometric ground truth; not suitable for precise damage quantification without corroborating measurements.
- Consumer “scan-to-share” apps (daily life)
- Use case: Users create interactive 3D models of collectibles or personal items for social sharing or classifieds from four photos.
- Tools/workflows:
- Mobile app with guided capture; server-side processing; viewer embedding with 3DGS.
- Assumptions/dependencies: Requires pose estimation via mobile AR; variable lighting/backgrounds affect quality.
Long-Term Applications
- Scene-level sparse-view reconstruction and AR maps (AR/VR, robotics)
- Use case: Extend from objects to room-scale scenes using non-grid-aligned Gaussians for low-latency AR mapping and rendering with partial coverage.
- Tools/workflows:
- Integration with SLAM/visual odometry; hierarchical scene graph of Gaussians; streaming LoD.
- Assumptions/dependencies: Current method is object-centric; scene-scale generalization needs new training data, memory scaling, and handling of large dynamic ranges.
- Closed-loop active perception with next-best-view planning (robotics, autonomy)
- Use case: Use generative reconstructions to estimate uncertainty and propose views that reduce ambiguity; tighter loops between perception and control.
- Tools/workflows:
- Uncertainty maps over Gaussian parameters; planner that selects camera motions; real-time guidance updates.
- Assumptions/dependencies: Requires fast inference or distillation to lightweight models; robust on-robot pose estimation.
- CAD-quality reverse engineering from few photos (manufacturing, engineering)
- Use case: Convert Gaussian reconstructions into watertight, dimensionally accurate meshes or parametric CAD for rapid redesign or additive manufacturing.
- Tools/workflows:
- Surface extraction from Gaussians; fitting parametric primitives; metrology post-checks.
- Assumptions/dependencies: Hallucinated areas must be eliminated or verified; achieving tolerances requires additional constraints or measurements.
- Medical and dental object capture (healthcare)
- Use case: Quick 3D models of small devices or prosthetics; limited-intraoral view reconstruction for preliminary planning/communication.
- Tools/workflows:
- Clinic capture kits; integration with practice management and visualization tools.
- Assumptions/dependencies: Regulatory and accuracy requirements are stringent; reflective/biological surfaces and safety constraints necessitate dedicated training and validation.
- Real-time, on-device 3D capture (mobile/edge computing)
- Use case: Near-instant 3D models powered by optimized or distilled versions of the model running on phone or headset GPUs.
- Tools/workflows:
- Model compression, token pruning, smaller DiTs; incremental updates as new frames arrive.
- Assumptions/dependencies: Requires significant engineering for latency, power, and memory constraints; may trade off fidelity.
- Standardized provenance, watermarking, and disclosure for 3D content (policy)
- Use case: Frameworks to tag reconstructions that include hallucinated completions; consumer labels for 3D assets used in commerce and cultural heritage.
- Tools/workflows:
- Content credentials for 3D (e.g., C2PA extensions); automated disclosure pipelines in marketplaces and museums.
- Assumptions/dependencies: Multi-stakeholder standards and governance needed; enforcement and detection mechanisms for non-compliant content.
- Security and rights management (policy, legal)
- Use case: Guardrails to prevent unauthorized reconstruction of proprietary objects; compliance checks for dataset licensing and object IP.
- Tools/workflows:
- Object recognition/blacklists; pose-restricted capture policies; in-app warnings and upload scanning.
- Assumptions/dependencies: Balance between usability and protection; evolving legal precedents for 3D reconstructions.
- Training data engines and synthetic augmentation (academia, software)
- Use case: Use the model to complete partial scans, generating diverse 3D training sets for downstream tasks (grasping, segmentation, rendering).
- Tools/workflows:
- Automated pipelines that take partial inputs and generate multiple plausible completions with guidance scales.
- Assumptions/dependencies: Synthetic diversity may introduce bias; need labeling or validation strategies to avoid downstream drift.
- Multi-modal extensions and text/image conditioning (software, media)
- Use case: Combine few views with textual prompts to steer unseen regions (e.g., “back has straps”); controlled completion for design workflows.
- Tools/workflows:
- Multi-conditional DiT variants; joint image–text encoders; UI for prompt-guided editing.
- Assumptions/dependencies: Requires additional training with aligned text–3D data; risk of weakened input fidelity without strong guidance.
Cross-cutting dependencies and assumptions
- Camera poses: The current method assumes posed multi-view images; uncalibrated capture requires additional pose estimation modules.
- Fidelity vs. plausibility: Unobserved regions are plausibly completed, not guaranteed accurate—use caution in safety-critical or metrological contexts.
- Material/scene limitations: Reflective, transparent, or thin structures may be challenging; object-centric training may not generalize to all categories.
- Compute and integration: Reference implementation reports ~26 s/object on an H200 GPU; production deployment may need batching, cloud GPUs, or distilled models.
- Asset format interchange: 3D Gaussians render well in modern pipelines but many workflows still require meshes; robust mesh extraction is often necessary.
These applications leverage the paper’s core contributions—non-grid-aligned generative reconstruction, hierarchical patchification for scalability, and guidance strategies for fidelity—to reduce capture requirements, cut asset sizes, and improve completeness under sparse observations.
Glossary
- 3D Gaussian Splatting (3DGS): A 3D scene representation that renders scenes using many anisotropic Gaussians for real-time, differentiable rendering. "3D Gaussian splatting (3DGS) \cite{KerblKLD2023} has emerged as a compelling representation offering real-time differentiable rendering with high visual quality."
- AdaLN: Adaptive Layer Normalization that conditions transformer layers on additional signals such as timesteps. "Each block consists of self-attention with 16 64-dimensional heads, AdaLN \cite{PeeblX2023} conditioning on the timestep , and a GEGLU feed-forward network."
- Chamfer distance: A set-to-set distance measuring nearest-neighbor discrepancies, often used to compare point sets. "One solution is permutation-invariant losses (\eg, using Chamfer or Earth Mover's distance), but these are imperfect proxies for reconstruction quality"
- classifier-free guidance: A technique that mixes conditional and unconditional generations to amplify conditioning signals during sampling. "We use classifier-free guidance \cite{HoS2021} to further amplify the influence of the conditioning views."
- conditional distribution: The probability distribution of outputs given inputs; sampling from it avoids blurry averages. "A generative model instead samples from the conditional distribution , enabling sharp completions."
- conditional expectation: The mean of the output distribution given inputs; optimizing toward it often yields blurred predictions in ambiguous regions. "regression-based methods trained with L2 losses ... predict the conditional expectation "
- cosine schedule: A commonly used timestep or learning-rate schedule shaped by a cosine function. "Timesteps follow a cosine schedule \cite{nichol2021improved}."
- cost-volume cues: Aggregated multi-view matching costs over depth hypotheses to guide 3D inference. "MVSplat \cite{ChenXZZPGCC2024} create Gaussians from multi-view stereo depth and cost-volume cues, respectively."
- diffusion prior: A generative prior modeled by diffusion that regularizes or guides reconstruction. "ReconFusion \cite{WuMHPGWSVBPH2024} regularizes a neural radiance field (NeRF) \cite{MildeSTBRN2020} at novel poses with a diffusion prior"
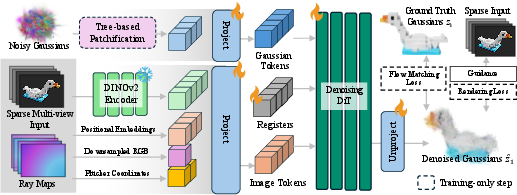
- Diffusion Transformer (DiT): A transformer architecture adapted for diffusion/flow-based generative modeling. "Our Diffusion Transformer (DiT) operates on Gaussian tokens without positional encodings"
- DINO similarity: A perceptual metric computed from features of a DINO model to assess image similarity. "The values for DreamSim (DS) \cite{FuTSCZDI2023} and DINO similarity are ."
- DINOv2: A self-supervised vision transformer used to extract image features. "The input images are processed by a frozen DINOv2-Base \cite{OquabDMVSKFHMEABGHHLMRSSXJMLJB2024} encoder"
- DreamSim: A perceptual similarity metric based on learned features for comparing images. "The values for DreamSim (DS) \cite{FuTSCZDI2023} and DINO similarity are ."
- Earth Mover’s distance: A set distance measuring the minimal “work” to transform one distribution into another. "One solution is permutation-invariant losses (\eg, using Chamfer or Earth Mover's distance)"
- Euler steps: A simple numerical integration scheme used to integrate ODEs in generative samplers. "At inference, starting from pure noise, this velocity is integrated via Euler steps "
- FID (Fréchet Inception Distance): A distributional metric that measures realism by comparing feature statistics of generated and real images. "achieving state-of-the-art quality for both observed (high PSNR) and unobserved regions (low FID)"
- feed-forward methods: Approaches that predict outputs in a single forward pass without per-scene optimization. "This has spurred feed-forward methods that predict 3DGS from sparse views in a single forward pass, bypassing costly per-scene optimization."
- flow matching: A generative modeling technique that learns a velocity field along a probability path between noise and data. "This is done through flow matching over Gaussian parameters."
- generative reconstruction: Formulating reconstruction as conditional generation to synthesize plausible content and avoid blur. "We address their limitations through generative reconstruction: instead of deterministically regressing Gaussian parameters, we use flow matching"
- GEGLU: A gated activation (GELU with gating) used in transformer feed-forward networks. "Each block consists of self-attention ... and a GEGLU feed-forward network."
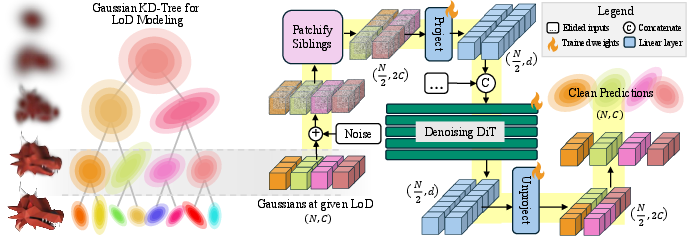
- hierarchical level-of-detail (LoD): A multi-resolution organization of Gaussians enabling coarse-to-fine processing. "We construct a level-of-detail (LoD) hierarchy \cite{KerblMKWLD2024} over ground-truth Gaussians"
- latent diffusion: Diffusion modeling performed in a learned latent space rather than pixel space. "Direct3D \cite{WuLZZXTCY2024} applies a 3D latent diffusion transformer for scalable image-to-3D generation."
- logit-opacity: Opacity parameterized in logit space for stable learning and unconstrained optimization. "We use the standard parameterization of 3D Gaussians by mean position, log-scale, quaternion rotation, logit-opacity, and RGB color."
- multi-view rendering loss: A supervision signal comparing renderings from multiple viewpoints to ground-truth images. "LaRa \cite{ChenXETG2024}, a voxel-based method trained with multi-view rendering loss"
- patchification: Grouping neighboring elements into larger tokens to reduce sequence length while preserving locality. "we propose a patchification strategy that cuts the number of tokens in half while preserving locality."
- permutation-invariant losses: Set-based losses that do not depend on ordering of elements. "One solution is permutation-invariant losses (\eg, using Chamfer or Earth Mover's distance)"
- photometric gradient guidance: Using gradients of photometric error to steer the generative trajectory toward better reconstructions. "photometric gradient guidance \cite{MuZGWLWXDYC2024} to steer denoising toward input views"
- photometric loss: An image-space error (e.g., L1/L2) between rendered and observed pixels used for supervision. "trained only with a photometric loss, these methods predict blurry conditional means for unobserved areas."
- plane-sweep cost volumes: Aggregations of matching costs over hypothesized planes to enable multi-view stereo reasoning. "MVSNeRF \cite{ChenXZZXYS2021} was an early work combining plane-sweep cost volumes with volume rendering"
- Plücker ray coordinates: A 6D representation of 3D lines (rays) used to encode viewing geometry. "and Plücker ray coordinates (6 channels) of each view."
- Plücker ray embeddings: Encoded Plücker ray features for transformer inputs capturing camera-ray geometry. "GS-LRM \cite{ZhangBTXZSX2024} extends LRM \cite{HongZGBZLLSBT2024} with pixel-aligned transformer tokens and Plücker ray embeddings."
- PSNR (Peak Signal-to-Noise Ratio): A pixel-wise fidelity metric commonly used to measure reconstruction quality. "achieving state-of-the-art quality for both observed (high PSNR) and unobserved regions (low FID)"
- QK-normalization: Normalization applied to query/key vectors in attention to stabilize training. "QK-normalization \cite{henry2020query} via RMSNorm \cite{zhang2019root} is applied for training stability."
- quaternion rotation: A rotation parameterization used for stable optimization of 3D orientations. "We use the standard parameterization of 3D Gaussians by mean position, log-scale, quaternion rotation, logit-opacity, and RGB color."
- radiance field (NeRF): A volumetric representation mapping 3D points and viewing direction to radiance and density. "regularizes a neural radiance field (NeRF) \cite{MildeSTBRN2020} at novel poses with a diffusion prior"
- rectified flow models: Flow-based generative models with a “rectified” training objective for efficient sampling. "TripoSG \cite{LiZLWLYLGLOC2026} employs large-scale rectified flow models over a point-cloud-structured latent space"
- RMSNorm: Root Mean Square Layer Normalization, a lightweight normalization alternative to LayerNorm. "QK-normalization \cite{henry2020query} via RMSNorm \cite{zhang2019root} is applied for training stability."
- standard normal prior: A Gaussian prior N(0, I) used as the starting distribution for generative sampling. "we define a linear probability path between a standard normal prior and the data distribution of 3D Gaussians"
- timestep-weighted rendering loss: A rendering loss whose influence increases over the denoising trajectory to stabilize training. "We further propose a timestep-weighted rendering loss during training"
- U-Net: A convolutional encoder–decoder with skip connections commonly used in image-to-image and diffusion tasks. "LGM \cite{TangCCWZL2024} does so from four views using a U-Net."
- voxel grid: A 3D volumetric grid discretization that anchors predictions to fixed 3D cells (voxels). "An alternative approach decouples the reconstruction from input pixels by using a volumetric grid"
- x-prediction: A parameterization where the model predicts the clean data sample directly instead of noise or velocity. "The model predicts the clean sample directly (-prediction \cite{li2025backtobasics})"
- VQ-VAE (Vector-Quantized Variational Autoencoder): A discrete latent autoencoder that quantizes latent codes into a learned codebook. "L3DG \cite{RoessMPBKDN2024} performs latent diffusion with a VQ-VAE \cite{OordVK2017}"
Collections
Sign up for free to add this paper to one or more collections.

