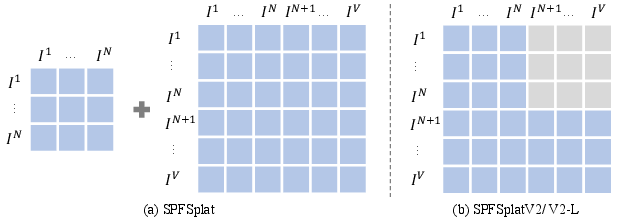- The paper presents a self-supervised approach that unifies 3D Gaussian prediction and camera pose estimation without requiring ground-truth poses.
- It leverages a transformer-based architecture with masked attention and learnable pose tokens to achieve state-of-the-art novel view synthesis and 3D reconstruction.
- Experimental results demonstrate superior cross-dataset generalization, efficient training, and high-fidelity 3D geometry even under sparse and extreme viewpoints.
SPFSplatV2: Self-Supervised Pose-Free 3D Gaussian Splatting from Sparse Views
Introduction and Motivation
SPFSplatV2 addresses the challenge of 3D scene reconstruction and novel view synthesis (NVS) from sparse, unposed multi-view images, eliminating the need for ground-truth camera poses during both training and inference. This is a significant departure from prior 3DGS and NeRF-based pipelines, which typically rely on accurate pose information, often obtained via computationally expensive and unreliable SfM, especially in sparse-view or low-overlap scenarios. The method is designed to be scalable, efficient, and robust, enabling the exploitation of large, diverse, and unposed datasets for 3D reconstruction.
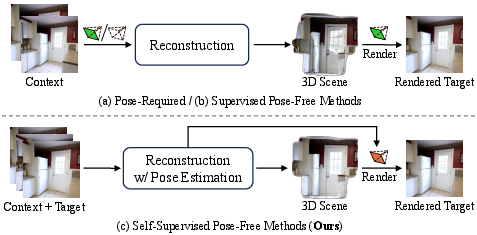
Figure 1: Comparison of three typical training pipelines for sparse-view 3D reconstruction in novel view synthesis. SPFSplatV2 (c) eliminates the need for ground-truth poses by leveraging estimated target poses for both reconstruction and rendering loss.
Methodology
Unified Feed-Forward Architecture
SPFSplatV2 employs a unified feed-forward transformer-based architecture with a shared backbone for both 3D Gaussian primitive prediction and camera pose estimation. The network processes N context images and M target images, predicting 3D Gaussians in a canonical space (with the first view as reference) and estimating all camera poses relative to this reference.
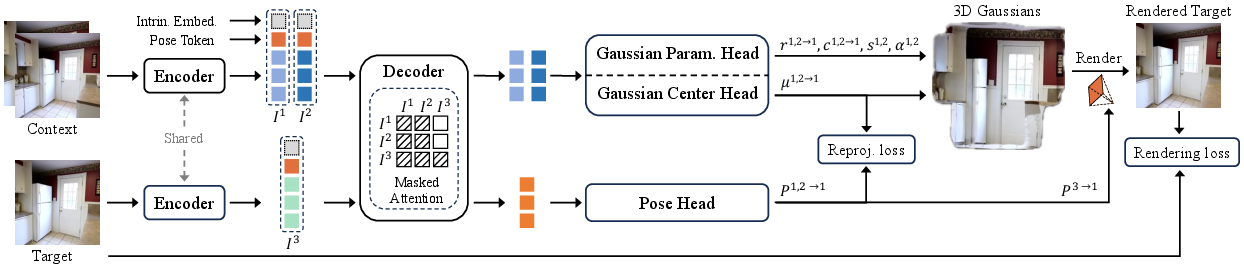
Figure 2: Training pipeline of SPFSplatV2. A shared backbone with three specialized heads predicts Gaussian centers, additional Gaussian parameters, and camera poses from unposed images. Masked attention ensures independence between context and target information during Gaussian reconstruction.
Key architectural components include:
Loss Functions and Optimization
- Rendering Loss: Combines L2 and LPIPS losses between rendered and ground-truth target images, using predicted target poses.
- Reprojection Loss: Enforces geometric consistency by minimizing the reprojection error between predicted 3D Gaussian centers and their corresponding 2D pixels, using the estimated context poses.
- Multi-View Dropout: Randomly drops intermediate context views during training, improving generalization to varying input configurations.
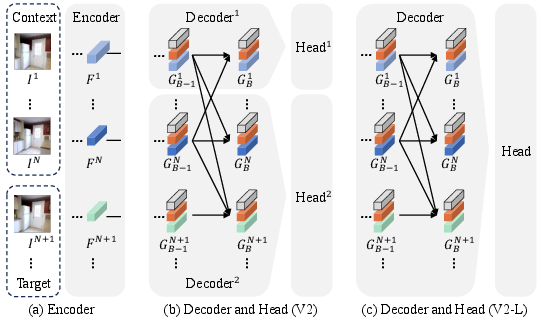
Model Variants
Experimental Results
Novel View Synthesis
SPFSplatV2 and SPFSplatV2-L achieve state-of-the-art results on RE10K and ACID, outperforming both pose-required and pose-free baselines, including those with ground-truth pose supervision. Notably, the models maintain high performance even under minimal input overlap and extreme viewpoint changes.

Figure 5: Qualitative comparison on RE10K and ACID. SPFSplatV2 better handles extreme viewpoint changes, preserves fine details, and reduces ghosting artifacts compared to baselines.
Cross-Dataset Generalization
Both variants generalize robustly to out-of-domain datasets (ACID, DTU, DL3DV, ScanNet++), demonstrating strong zero-shot performance and geometric consistency, even when trained solely on RE10K.

Figure 6: Qualitative comparison on cross-dataset generalization. SPFSplatV2 and SPFSplatV2-L yield more accurate reconstructions than prior methods.
Relative Pose Estimation
SPFSplatV2 achieves superior pose estimation accuracy compared to both classical SfM pipelines and recent learning-based methods, despite the absence of geometric supervision. Both direct regression and PnP-based strategies yield consistent results, indicating strong alignment between predicted poses and reconstructed 3D points.
3D Geometry Quality
The method produces high-fidelity 3D Gaussians and sharper renderings, with improved structural accuracy and reduced artifacts relative to prior approaches.

Figure 7: Comparison of 3D Gaussians and rendered results. SPFSplatV2 produces higher-quality 3D Gaussians and better rendering over baselines.
Scalability and Efficiency
- Inference: Comparable or better runtime and FLOPs than prior pose-free methods, with significant speedups over methods relying on explicit geometric operations.
- Training: Masked attention reduces training FLOPs and memory usage compared to dual-branch designs.
- Scalability: The framework scales efficiently to large, unposed datasets, with performance improving as training data increases.
Ablation Studies
- Masked Attention: Reduces computational cost and improves geometric alignment.
- Learnable Pose Tokens: Enhance pose estimation accuracy.
- Reprojection Loss: Critical for stable training and accurate geometry.
- Intrinsic Embedding: Improves scale alignment but is not essential for strong performance.
- Initialization: Pretraining on MASt3R or VGGT is beneficial; random initialization leads to a performance drop but does not preclude learning.
Real-World and Failure Cases
SPFSplatV2 generalizes to in-the-wild mobile phone images without intrinsics, but failure cases occur in occluded, textureless, or highly ambiguous regions.

Figure 8: 3D Gaussians from smartphone without intrinsics and rendered image.

Figure 9: Failure cases of SPFSplatV2. Blurriness and artifacts occur in occluded or texture-less regions and under extreme viewpoint changes.
Implications and Future Directions
SPFSplatV2 demonstrates that self-supervised, pose-free 3D Gaussian splatting is feasible and effective for sparse-view NVS, even in the absence of any geometric supervision. The approach enables scalable 3D reconstruction from large, unposed, and diverse datasets, removing a major bottleneck in data collection and annotation. The joint optimization of geometry and pose within a unified architecture leads to improved geometric consistency and stability.
However, the method still benefits from pretrained geometric priors, and its non-generative nature limits the reconstruction of unseen regions. Future work should explore integrating generative models for hallucinating occluded content, further improving robustness to ambiguous or textureless regions, and leveraging even larger and more diverse datasets for enhanced generalization.
Conclusion
SPFSplatV2 establishes a new paradigm for pose-free 3D scene reconstruction and novel view synthesis from sparse, unposed images. By unifying scene and pose estimation in a single feed-forward transformer with masked attention and geometric constraints, it achieves state-of-the-art performance in both in-domain and out-of-domain settings, with strong efficiency and scalability. The framework's independence from ground-truth poses paves the way for large-scale, real-world 3D reconstruction and generalizable NVS, with broad implications for computer vision, robotics, and AR/VR applications.