- The paper introduces a novel text-guided framework that grows 3D Gaussian primitives directly from point clouds, bypassing mesh-dependent artifacts.
- It leverages geometry-aware diffusion and optimized camera pose adjustments to achieve high-fidelity, multi-view consistency and detailed surface reconstruction.
- The iterative inpainting method effectively fills occluded and sparse regions, demonstrating superior performance on benchmarks like Objaverse and T3Bench.
Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance
Introduction and Motivation
The paper "GaussianGrow: Geometry-aware Gaussian Growing from 3D Point Clouds with Text Guidance" (2604.05721) introduces an advanced text-guided framework for direct synthesis of 3D Gaussian representations from raw point clouds. The core motivation addresses critical limitations in existing generative 3DGS paradigms: current models suffer from poor geometry priors and are often constrained by unreliable intermediate geometric reconstructions or mesh dependencies, resulting in artifacts, incomplete surfaces, and lack of detail. GaussianGrow bypasses these bottlenecks by growing spatially distributed 3D Gaussian primitives anchored strictly on point cloud geometries, optionally guided by natural language input, thus leveraging the accessibility and flexibility of point clouds acquired from large-scale databases or 3D sensors.
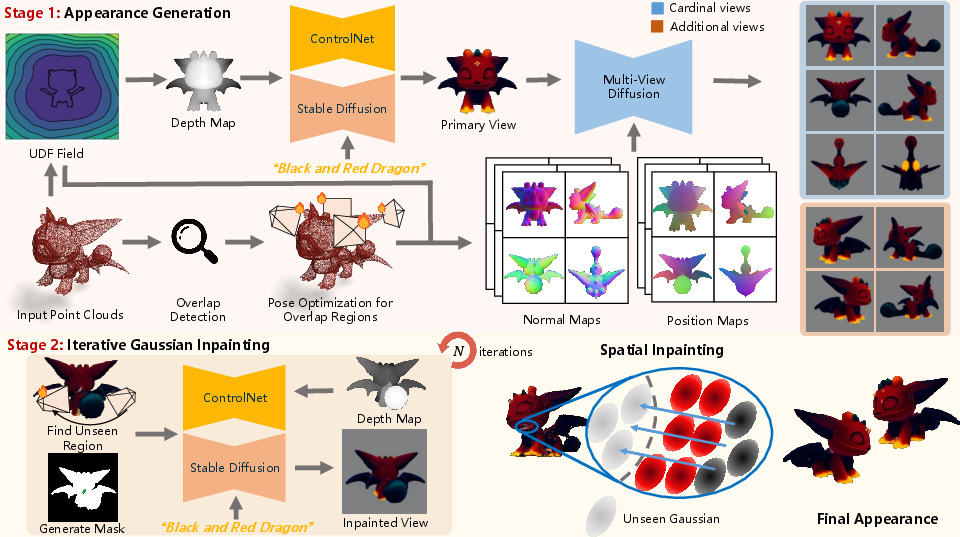
Figure 1: Pipeline overview—GaussianGrow grows Gaussians from point clouds via multistage supervision using diffusion models, optimized camera poses, and inpainting, yielding complete geometry-aligned 3DGS representations.
Methodology
Stage 1: Geometry-aware, Text-guided Appearance Synthesis
GaussianGrow initializes Gaussian primitives at point locations and orients them with normals derived from a neural unsigned distance field (UDF), allowing topologically flexible surface representation without relying on watertight meshes. Appearance synthesis for the Gaussians leverages multi-view diffusion: depth-aware ControlNet and advanced geometry-aware diffusion models (e.g., Hunyuan3D-Paint) generate well-aligned multi-view images as supervision.
A critical innovation is the explicit treatment of overlap regions between neighboring canonical views. GaussianGrow detects overlap regions and dynamically optimizes auxiliary camera poses to maximize coverage and minimize inconsistency in these areas. By computing intersections of visible sets of Gaussians across views and optimizing camera station alignment (via a cosine-normal alignment loss), the model generates targeted reference images that constrain the fusion of neighboring Gaussian sets.

Figure 2: Additional camera poses are optimized to observe and constrain the largest overlap regions for improved view consistency in appearance synthesis.

Figure 3: Effectiveness of selective processing for overlap regions—local inconsistencies are minimized via auxiliary targeted views.
Stage 2: Iterative Inpainting for Unobserved Regions
Despite dense multi-view coverage, point clouds often exhibit regions that are difficult to observe or texture due to occlusion or sampling sparsity. GaussianGrow deploys an iterative inpainting scheme: it searches for camera poses that maximally expose currently untextured (unoptimized) Gaussians, rendering their incomplete appearances, and then utilizes pretrained depth-aware 2D diffusion inpainting models to complete missing visual data. These inpainted synthetic images serve as new supervision targets for further optimization. The procedure cycles until full coverage of the underlying point cloud is achieved. A final spatial inpainting refinement propagates appearance from optimized to residual challenging Gaussians via neighborhood interpolation.

Figure 4: The effect of Gaussian inpainting—gap regions are filled, resulting in complete, visually seamless geometry and appearance.
Empirical Results
Text-guided Gaussian Generation
Evaluated on challenging synthetic (Objaverse) and real-scanned (DeepFashion3D) datasets, GaussianGrow demonstrates substantial improvement in both visual quality and geometric accuracy over mesh-based, triplane-based, and prior point-to-Gaussian approaches. Strong quantitative gains are demonstrated on the Objaverse benchmark with FID 36.07, KID 3.04, and CLIP Score 27.30, outperforming direct competitors by considerable margins.

Figure 5: Visual comparison (Objaverse): GaussianGrow operates directly on point clouds with no mesh intermediates, preserving complex geometry and eliminating mesh-induced artifacts.
Text-to-3D Synthesis
GaussianGrow extends to text-to-3D synthesis using point clouds retrieved (Uni3D) or generated by geometric priors (LGM). On T3Bench, it achieves the highest CLIP similarity and ImageReward scores, indicating superior semantic alignment and perceptual fidelity. Ablation reveals that the overlap-region camera optimization and iterative inpainting components provide measurable performance boosts.

Figure 6: Benchmark text-to-3D comparisons on T3Bench show GaussianGrow yields more realistic, text-aligned, and detailed assets than other SOTA pipelines.
Point-to-Gaussian Quality
For direct point-to-Gaussian generation, head-to-head comparisons with DreamGaussian and TriplaneGaussian yield clear empirical advantages. GaussianGrow maintains high-frequency detail and faithful appearance transfer even in challenging incomplete, noisy, or sparse real-world scans.

Figure 7: Point-to-Gaussian reconstruction fidelity—GaussianGrow preserves structure and appearance where baseline approaches exhibit smearing or color bleeding.
Style Diversity and Robustness
GaussianGrow supports high style diversity: text prompt variations lead to consistent geometry (inherited from the point cloud) yet diverse, prompt-aligned, high-fidelity appearance mappings.

Figure 8: Diverse style Gaussian generations—multiple textures for a single geometry under different textual prompts.
Implications and Future Directions
GaussianGrow demonstrates that 3DGS models can be tightly coupled with 3D point cloud priors and advanced diffusion-based supervision to produce highly robust, text-guided geometry-aware generative pipelines. Its direct use of point clouds enables applications in 3D content creation, digital twin synthesis, robotics, AR/VR, and acquisition pipelines where mesh modeling is infeasible.
The authors' overlap-aware and inpainting frameworks suggest new directions for viewpoint-tuned optimization in other generative 3D paradigms, including NeRFs and neural implicit surfaces. Integration with large-scale 3D retrieval, multimodal language vision models, and advanced geometric reasoning will further enhance practical coverage and quality. Future work may explore scaling to scene-level synthesis, dynamic content, and generalization beyond acquired point clouds.
Conclusion
GaussianGrow (2604.05721) sets a new benchmark in geometry-aware, text-guided 3D Gaussian Splatting from point clouds, achieving both high-fidelity geometry and appearance synthesis without mesh intermediaries. The methodology—anchoring on explicit geometry, optimizing for multi-view and overlap consistency, and closing unobserved regions via iterative inpainting—demonstrates clear empirical and theoretical superiority over prior art, and establishes new baselines in text-to-3D and point-to-Gaussian pipelines.

