- The paper presents an autoregressive framework that synthesizes 3D scenes by sequentially generating discrete Gaussian primitives.
- It leverages a sparse 3D CNN autoencoder for tokenization, encoding both spatial geometry and appearance into a serialized token stream.
- Experimental results indicate superior visual quality and geometric consistency, enabling effective scene completion and large-scale outpainting.
GaussianGPT: Autoregressive 3D Gaussian Scene Generation
Motivation and Overview
The paper "GaussianGPT: Towards Autoregressive 3D Gaussian Scene Generation" (2603.26661) introduces a fully autoregressive framework for synthesizing 3D scenes by sequentially generating structured 3D Gaussian primitives. In contrast to prevailing diffusion and flow-matching paradigms, GaussianGPT leverages transformer-based next-token prediction to explicitly model scene geometry and appearance as discrete sequences of latent tokens. This method addresses the inherent challenges of 3D scene generation—high spatial dimensionality, lack of canonical sequential ordering, and compositional diversity—by combining discrete latent encoding with spatially-aware transformer conditioning.
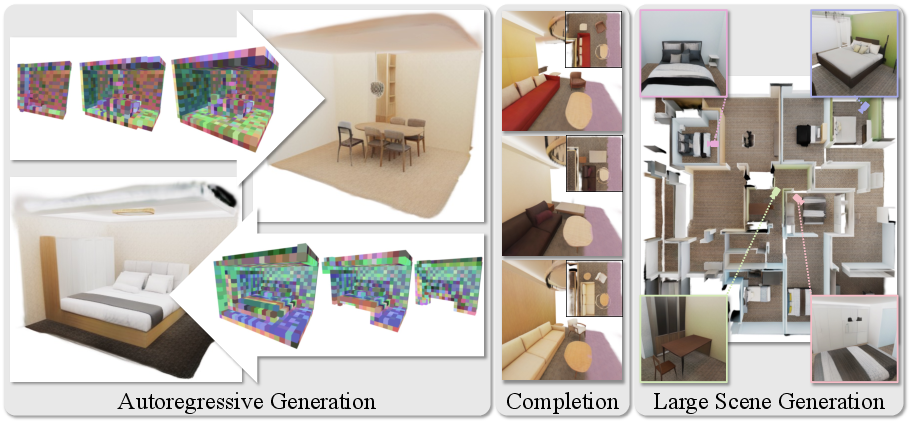
Figure 1: GaussianGPT employs a purely autoregressive paradigm for 3D Gaussian scene generation, enabling unconditional synthesis, scene completion, and large-scale scene outpainting with a unified model.
Methodology
Scene Encoding and Tokenization
The foundation of GaussianGPT is a sparse 3D convolutional autoencoder that compresses scenes comprised of Gaussian splats into a discrete latent voxel grid. Each Gaussian primitive, defined by spatial and appearance parameters (position, opacity, size, rotation, color), is mapped to a voxel, where features are encoded via lightweight attribute-specific heads. This input 3D grid is processed through a sparse 3D CNN encoder–decoder, which preserves spatial locality and distributes features into latent embeddings.
Vector quantization, specifically lookup-free quantization (LFQ) [yu_language_2024], converts decoder outputs into discrete codebook indices, facilitating efficient tokenization and regular code utilization. The 3D latent grid is serialized into an interleaved stream of position and feature tokens, organized via simple xyz column-wise traversal.
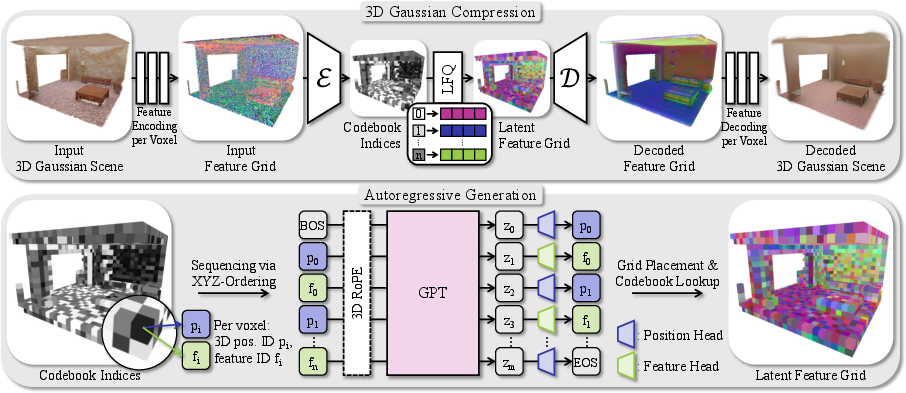
Figure 2: GaussianGPT's pipeline encodes a 3D Gaussian scene into a sparse voxel grid, compresses it with a sparse 3D CNN, serializes it into tokens, and applies a causal transformer for next-token prediction using 3D RoPE.
GaussianGPT deploys a GPT-2–style transformer with several modifications tailored for spatially structured 3D data:
- Token Alternation: Position and feature tokens are predicted alternately, separating geometric structure from appearance and preventing semantic conflicts in the vocabulary.
- 3D Rotary Positional Embedding (RoPE): Instead of standard 1D positions, 3D RoPE directly encodes spatial offsets into the attention mechanism, allowing the model to reason about explicit spatial locality regardless of serialization order [su_roformer_2023].
- Token-type Encoding: A fourth dimension indicates token type, further disentangling geometry from appearance in the unified attention stream.
Likelihood-based training is performed with cross-entropy over the token sequence, with masking for invalid tokens at each step.
Generation and Completion
Scene synthesis proceeds by alternating position and feature token prediction, optionally conditioned on partial context for completion. Scene outpainting is realized via iterative chunk-wise generation, leveraging local context windows in a sliding manner. Unoccupied columns are resampled to ensure meaningful occupancy.

Figure 3: Given a partial chunk, GaussianGPT produces plausible and diverse completions, maintaining structural and semantic consistency with observed context.
Experimental Results
Shape and Scene Synthesis
On PhotoShape, GaussianGPT achieves strong performance in both visual quality (FID=5.68, KID=1.835) and geometric metrics (COV=67.40, MMD=4.278), surpassing previous methods (e.g., DiffRF, L3DG, EG3D) in sample diversity and appearance fidelity [park_photoshape_2018, muller_diffrf_2023, roessle_l3dg_2024]. Qualitative chair generation exhibits sharper, cleaner structures with substantial intra-class variation.

Figure 4: Autoregressive chair generation comparison—GaussianGPT yields clean Gaussian allocations and consistent geometry versus DiffRF and L3DG.
For indoor scene generation on 3D-FRONT and ASE, GaussianGPT produces coherent layouts with plausible object placement, successfully extending scenes beyond training size via outpainting. Consistency across chunk boundaries is retained, demonstrating compositional stability.

Figure 5: Comparative scene synthesis—GaussianGPT (chunks) vs. L3DG (full normalized scenes), both generating plausible room-scale layouts.

Figure 6: 12m×12m scene synthesis through continuous outpainting showcases large-scale spatial coherence.
Scene Completion and Contextual Reasoning
GaussianGPT's autoregressive formulation naturally supports completion and inpainting. Given arbitrary scene prefixes (e.g., one-quarter of a chunk), completions exhibit diverse object layouts while preserving scene semantics. Multiple samples manifest structural variation, confirming probabilistic context reasoning and uncertainty modeling.

Figure 7: Scene completion in real-world ScanNet++ chunks—GaussianGPT generates diverse plausible completions, retaining learned synthetic priors.
Serialization Strategy Ablation
Ablation on serialization order (xyz, Z-order, Hilbert curves) shows negligible performance differences, with 3D RoPE effectively compensating for locality preservation. Simple xyz order yields optimal training and validation cross-entropy, underscoring the robustness of spatial encoding.
Implications and Future Directions
GaussianGPT demonstrates that autoregressive sequence modeling is not only feasible for structured 3D scene generation but also advantageous in terms of compositional flexibility, incremental scene construction, explicit control, and causal context-aware reasoning. Compared to diffusion-based approaches, it supports open-ended outpainting, arbitrary scene completion, and scalable generation horizons with a unified probabilistic framework.

Figure 8: Additional large-scale scene synthesis via autoregressive outpainting.
The modular latent encoding and tokenization strategy facilitate adaptation to varied spatial scales and representation formats, with potential for integration into real-world pipelines and foundation models. Limitations persist in autoencoder reconstruction fidelity for high-frequency details in real-world data and modeling unobserved regions in sparse scans.
Anticipated research directions include:
Conclusion
GaussianGPT provides a structured, autoregressive approach for 3D scene synthesis, completion, and outpainting, operating on discrete latent Gaussian representations. By synthesizing 3D scenes as sequential token streams and leveraging spatially-aware transformers, it achieves superior visual and geometric quality, compositional flexibility, and efficient context-aware reasoning. This paradigm is a compelling complement to diffusion and flow-based generative models, with practical and theoretical implications for scalable, controllable, and open-ended 3D generation (2603.26661).


