3D Gaussian Flats: Hybrid 2D/3D Photometric Scene Reconstruction
Abstract: Recent advances in radiance fields and novel view synthesis enable creation of realistic digital twins from photographs. However, current methods struggle with flat, texture-less surfaces, creating uneven and semi-transparent reconstructions, due to an ill-conditioned photometric reconstruction objective. Surface reconstruction methods solve this issue but sacrifice visual quality. We propose a novel hybrid 2D/3D representation that jointly optimizes constrained planar (2D) Gaussians for modeling flat surfaces and freeform (3D) Gaussians for the rest of the scene. Our end-to-end approach dynamically detects and refines planar regions, improving both visual fidelity and geometric accuracy. It achieves state-of-the-art depth estimation on ScanNet++ and ScanNetv2, and excels at mesh extraction without overfitting to a specific camera model, showing its effectiveness in producing high-quality reconstruction of indoor scenes.

































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making better 3D models of real places (like rooms) from regular photos. Many modern methods can create very realistic 3D scenes, but they often mess up flat, plain surfaces like walls, floors, ceilings, or tables. These areas can look wavy, see-through, or have holes. The authors introduce a new way to represent scenes that treats flat surfaces differently from everything else, so the final 3D model looks realistic and has clean, solid geometry.
Objectives and Questions
The paper asks a simple question: can we get the best of both worlds—great visuals and accurate geometry—especially for flat surfaces?
To do that, the authors aim to:
- Detect flat parts of a scene (like walls and floors) during training, not after.
- Represent flat areas using 2D “stickers” placed on planes, and represent the rest with 3D “blobs.”
- Train both kinds of shapes together so the scene looks good and has correct depth and solid surfaces.
- Show this works on indoor datasets and can produce meshes (triangulated surfaces) that are useful and clean.
Methods and How It Works
Think of building a LEGO model:
- For flat areas (walls, floors), you’d use flat plates (2D pieces).
- For everything else (sofas, plants), you’d use bricks (3D pieces).
This paper does the same with “Gaussians,” which you can think of as soft, colored blobs used to reconstruct scenes from photos.
Key Idea: Hybrid 2D/3D Gaussians
- 3D Gaussians: soft blobs floating in space; they’re great for modeling complex shapes and appearance.
- 2D Gaussians on planes (the “Flats”): soft blobs that live on a flat surface; they’re locked onto a plane and can move only within that plane.
Together, they form a “hybrid” scene: 2D Gaussians for flat parts and 3D Gaussians for everything else.
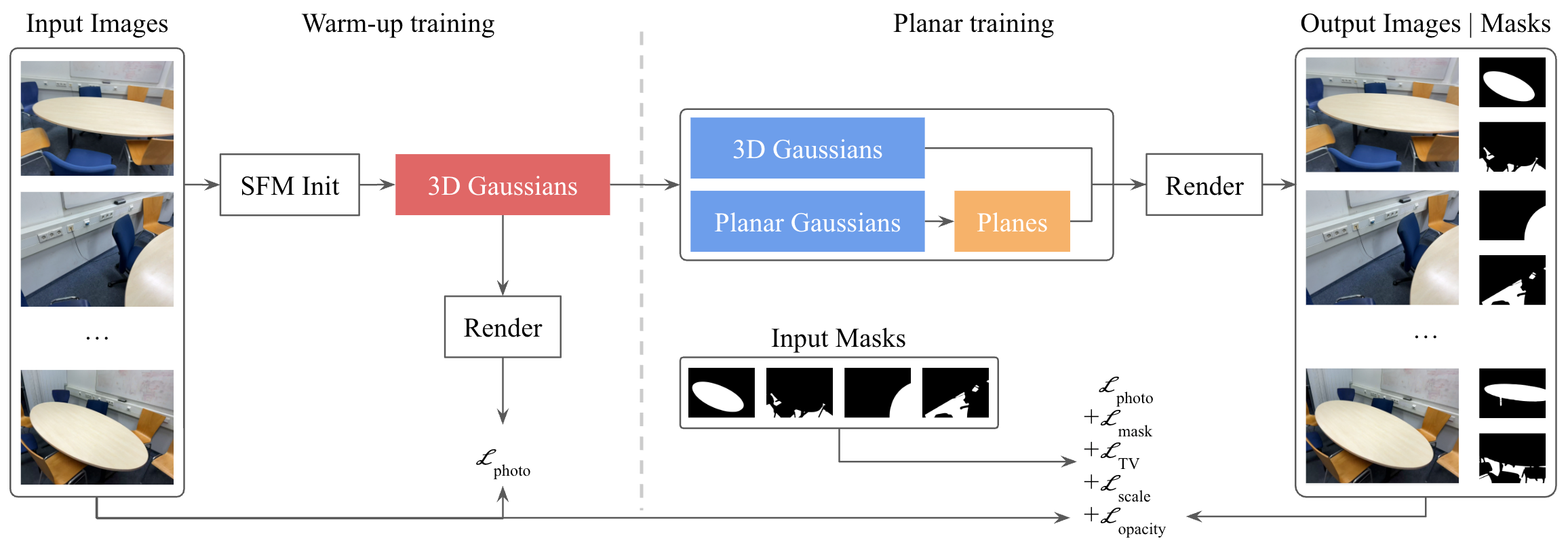
Training in Two Stages
- Warm-up: Start with only 3D blobs and train them to match the photos (using a photometric loss, which means “make the rendering look like the image”).
- Planar Phase: Detect planes (like walls) and convert suitable 3D blobs into 2D blobs living on those planes. Then continue training both types.
Detecting Planes Using Masks and Fitting
- The method uses 2D masks (outlines) that mark where planes are in the images. These come from a segmentation tool (like SAMv2 or PlaneRecNet).
- It finds blobs that likely belong to a plane and fits a plane using RANSAC (a robust method that ignores outliers).
- “Snapping”: blobs that are plane inliers get converted (“snapped”) from 3D blobs to 2D blobs attached to that plane.
Alternating Optimization (to keep things stable)
- First, tweak the plane’s position and direction to better match the images and masks.
- Then, with the planes fixed for a moment, adjust the blobs (their positions, sizes, colors, and opacity).
- Losses used:
- Photometric loss: match the photos.
- Mask loss: make sure the plane regions line up with the masks.
- Depth smoothness (TV loss): keep depth consistent and not too noisy.
- Scale and opacity regularizers: prevent meaningless blobs from growing or staying when not needed.
Densification (adding more detail)
Flat areas can be low-texture (plain colors), so regular training doesn’t place many blobs there. To fix this:
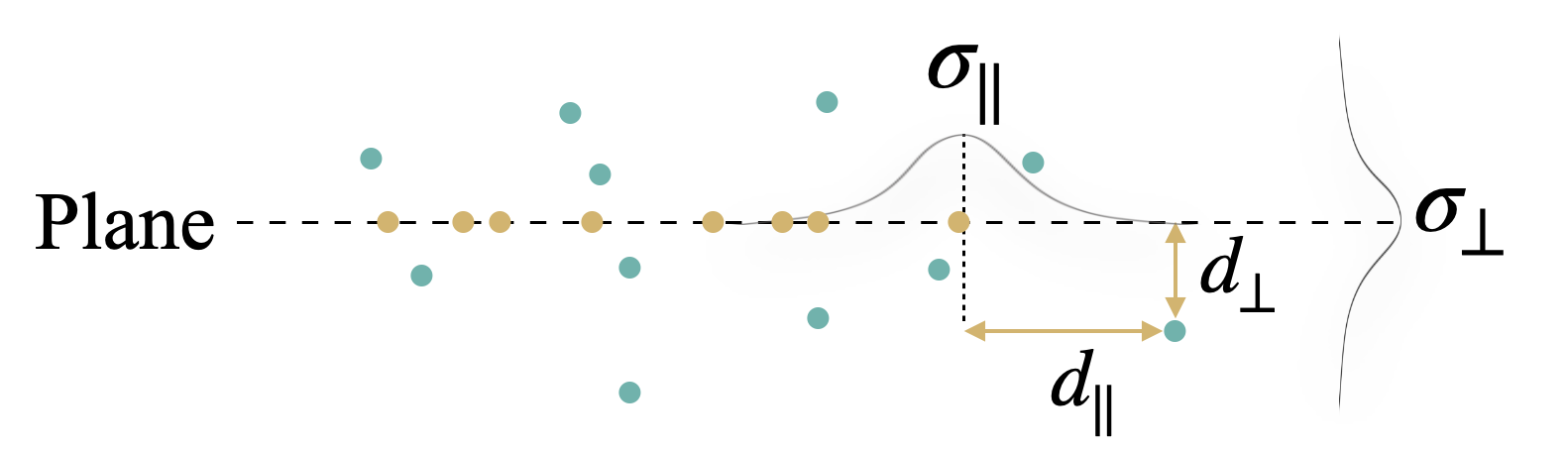
- If a 3D blob is near a plane (both in direction and along the plane), the method probabilistically relocates it onto the plane as a 2D blob.
- This increases detail on flat surfaces without creating artifacts.
Main Findings and Why They Matter
The method was tested on indoor scene datasets:
- ScanNet++ (dense, higher-quality captures)
- ScanNetv2 (sparser views)
Key results:
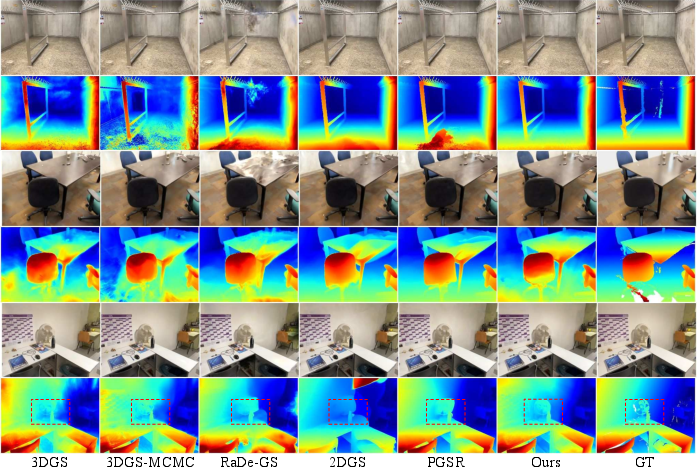
- Depth quality (how accurately the model knows distance) improved a lot compared to standard 3D-only methods and prior 2D-surface methods. That means walls and floors are crisp, solid, and correctly placed.
- Image quality (PSNR, SSIM, LPIPS) stayed on par with strong 3D methods. In other words, the scenes still look great.
- Mesh extraction (turning planes into usable surfaces) worked consistently across different cameras (iPhone and DSLR), while other methods often overfit to one type of camera and struggled on the other.
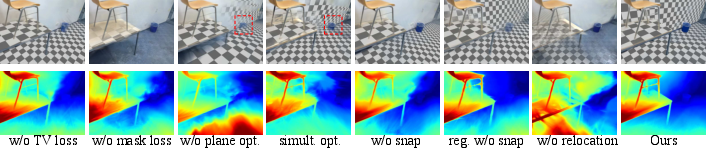
- Ablation tests (turning off parts of the method) showed that:
- Alternating plane-and-Gaussian optimization is crucial; doing both at once makes training unstable and results worse.
- Mask loss and depth smoothness help detect and refine planes.
- Snapping and relocation are essential to get enough detail on flat surfaces.
Implications and Impact
This hybrid 2D/3D approach makes 3D reconstructions:
- More reliable for indoor scenes with lots of flat surfaces.
- Better for creating clean meshes of walls, floors, and tables, which helps in VR/AR, robotics, gaming, and digital twins.
- More robust across different cameras and capture setups.
Limitations and future improvements:
- Very plain, textureless areas still need better strategies to add enough blobs early on.
- The appearance model is simple, so view-dependent effects (like shiny reflections) may cause minor geometry mistakes.
- Depends on segmentation masks; as those tools improve, results will improve too.
- Plane detection with RANSAC adds training time; future work could make it faster.
Overall, this paper shows a practical way to get both accurate geometry and high visual quality by treating flat surfaces as special, using 2D “flats” alongside regular 3D “blobs.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, missing analyses, and open questions that future work could address.
- End-to-end plane discovery: The method “assumes” per-view binary plane masks and relies on external segmentation (PlaneRecNet + SAMv2). How to jointly learn plane segmentation and reconstruction within the optimization loop, and how does performance degrade when masks are noisy, incomplete, or missing?
- Robustness to pose quality: Sensitivity to camera pose errors (e.g., inaccurate SfM, rolling-shutter, lens distortion) is not evaluated. Can the approach maintain its depth gains with noisy or estimated poses, and can it self-correct them?
- Small/occluded planes: The plane initialization discards planes with fewer than 100 inlier Gaussians. This threshold likely misses small planes, partially occluded planes, and thin structures. What strategies enable reliable detection and reconstruction at small scales?
- Curved and non-planar surfaces: Surfaces are constrained to planes. How can the framework be extended to weakly curved, piecewise planar, or parametric surfaces without breaking photometric fidelity?
- Specular and non-Lambertian materials: The weak SH appearance model is acknowledged as a limitation; however, the paper does not quantify the impact on specular highlights, reflections, and glossy materials, nor evaluate stronger appearance models (e.g., neural BRDFs) in this hybrid setting.
- Volumetric phenomena: The hybrid model is aimed at avoiding volumetric artifacts on planes but does not analyze performance on scenes with semi-transparency, participating media, or soft shadows where volumetric effects are important.
- Outdoor and diverse scene types: Experiments focus on indoor planar-heavy scenes. Generalization to outdoor, cluttered, and highly non-planar environments remains unexplored.
- Training efficiency and scalability: RANSAC-based plane fitting and alternating optimization introduce overhead; no runtime, memory, or scalability analysis is provided for large scenes (many planes, millions of primitives). What are the practical limits and how can they be reduced?
- Hyperparameter sensitivity: Many thresholds (e.g., opacity κ=0.1, depth shell δ=0.05, RANSAC ε, relocation σ⊥/σ∥, min-inliers=100) are fixed without sensitivity analysis. How do these parameters affect stability, accuracy, and convergence across datasets?
- Alternating schedule design: The 10-iteration plane and 100-iteration Gaussian blocks are heuristic. Is there a principled schedule, adaptive strategy, or convergence analysis that yields more reliable/efficient optimization?
- Plane merging criteria: Merging relies on angular proximity and origin distance to the nearest Gaussian center. Failure modes (e.g., merging distinct parallel planes or missing co-planar structures spanning multiple masks) are not analyzed or quantified.
- Mask loss formulation: The plane mask loss uses binarized colors and alpha blending to produce predicted masks. Are there more principled differentiable formulations (e.g., occupancy, silhouette consistency) that improve stability and reduce dependence on color heuristics?
- Densification on textureless planes: The paper notes slow densification in low-texture regions and introduces stochastic relocation. It lacks a comparison with alternative strategies (e.g., gradient-based plane-aware sampling, visibility-aware placement, adaptive birth/death proposals) and does not analyze relocation-induced artifacts.
- Numerical stability of planar Gaussians: Projecting 3D Gaussians to 2D with zero thickness (degenerate covariance) may cause ill-conditioned gradients or rasterization artifacts. A formal analysis of numerical stability and gradient behavior is missing.
- Mesh extraction robustness: The pipeline (ray-plane intersection, voxel downsampling, Marching Squares, ear-clipping) is heuristic. How robust is it to segmentation inconsistencies, occlusions, and noise? What is the sensitivity to voxel size and contour thresholds?
- Full-scene meshing: Mesh extraction is limited to detected planar surfaces. How can the method produce complete, watertight meshes of entire scenes and integrate non-planar geometry with consistent topology?
- Domain generalization in rendering: While planar meshing generalizes across iPhone and DSLR, there is no evaluation of novel-view synthesis generalization across camera models, lighting conditions, or HDR/auto-exposure variations.
- Dynamic scenes: The approach targets static scenes. How does it handle dynamic content (moving objects, people) and temporal consistency for plane detection and reconstruction?
- Evaluation breadth and bias: The datasets include a small number of indoor scenes; depth metrics are computed “only on the defined portion” of ground-truth depths. Broader evaluations (e.g., Tanks and Temples, ETH3D, synthetic benchmarks) and reporting on masked regions vs. full-frame metrics would improve confidence.
- Comparative fairness and tuning: Baselines may have different training budgets and modality-specific training (e.g., AirPlanes trained on phones). A controlled study with unified settings and tuned regularizers for each baseline is missing.
- Reproducibility details: Crucial implementation parameters (e.g., RANSAC ε, plane merge thresholds, mask loss weights, learning rates per phase) are deferred to the supplementary without thorough documentation; an ablation on these choices and open-source release would improve reproducibility.
- Failure case analysis: The paper shows overall improvements but lacks qualitative/quantitative analysis of failure modes (e.g., mirror surfaces, glass, strong reflections, parallel planes close together, clutter near planes), and strategies to detect and mitigate them.
- Theoretical underpinning: There is no formal justification or convergence analysis for the hybrid optimization (snapping, relocation, alternating phases). A theoretical framework or guarantees (even empirical) would strengthen the method’s reliability.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities described in the paper, leveraging the hybrid 2D/3D Gaussian representation, dynamic planar detection, improved depth estimation, and planar mesh extraction that generalizes across camera models.
- Indoor digital twins for VR/AR, gaming, and virtual tours
- Sectors: software, media/entertainment, real estate
- What it enables: High-fidelity indoor reconstructions with clean walls, floors, and ceilings; photorealistic rendering without “holes” or semi-transparent planes that often plague volumetric methods
- Tools/products/workflows: Pipeline combining video capture (smartphone/DSLR), plane masks from SAMv2/PlaneRecNet, 3DGS warm-up, hybrid training, export to Unreal/Unity/Blender for interactive visualization
- Assumptions/dependencies: Posed images (SfM or device AR tracking), reliable plane segmentation masks, sufficient compute for 30k training iterations, indoor scenes with prominent planar surfaces
- As-built BIM updates and floorplan extraction from scans
- Sectors: architecture, engineering, construction (AEC)
- What it enables: Accurate planar mesh recovery (walls, floors, ceilings) for updating BIM models and generating floorplans; better geometry in texture-less areas compared to volumetric-only pipelines
- Tools/products/workflows: Hybrid reconstruction → planar mesh extraction → alignment to BIM coordinate frames → import into Autodesk Revit/IFC; area/volume computation and wall alignment post-processing
- Assumptions/dependencies: Good coverage of indoor surfaces, robust plane detection (RANSAC), segmentation mask quality, optional Manhattan-world alignment step for floorplan generation
- Offline mapping for mobile robots in feature-poor indoor spaces
- Sectors: robotics, facility operations
- What it enables: Clean planar maps and improved depth for navigation, obstacle avoidance, and coverage planning (e.g., cleaning, inspection robots) in sparse-texture environments
- Tools/products/workflows: Record monocular video → hybrid reconstruction → export planar geometry to robot planners (ROS/MoveIt) → improve map priors and path planning
- Assumptions/dependencies: Offline processing (not real-time), access to posed imagery (or robust SfM), planar-heavy environments
- AR anchoring and occlusion for consumer apps and e-commerce
- Sectors: software, retail
- What it enables: More reliable AR placement and occlusion on surfaces (tables, floors, walls), reducing visual artifacts for product try-ons or furniture staging
- Tools/products/workflows: Capture quick room scan → hybrid 2D/3D reconstruction → lightweight export of planar meshes for anchors; plug-ins for ARKit/ARCore occlusion layers
- Assumptions/dependencies: Short training time feasible via cloud/offline workflows; segmentation masks; on-device usage may rely on simplified models
- Cultural heritage and museum interior digitization
- Sectors: culture, education
- What it enables: Photorealistic indoor reconstructions with faithful geometry of large, flat surfaces, aiding documentation, virtual exhibits, and remote education
- Tools/products/workflows: DSLR/smartphone capture → hybrid reconstruction → archival meshes + radiance fields; export into web viewers for educational access
- Assumptions/dependencies: Controlled capture with sufficient coverage; compute resources; consistent lighting helps photometric optimization
- Insurance and property assessment (area/volume measurements, damage reports)
- Sectors: finance/insurance, real estate
- What it enables: Accurate area/volume estimation from planar meshes; consistent results across different cameras; improved confidence in measurements of walls/floors
- Tools/products/workflows: Claims adjuster workflow: video capture → hybrid reconstruction → planar mesh extraction → measurement/annotations → standardized reporting
- Assumptions/dependencies: Regulatory acceptance of photogrammetry-based measurements; QA on segmentation and pose accuracy
- Cross-device quality assurance in scanning pipelines
- Sectors: software tooling, imaging
- What it enables: Reduced domain gap across camera models (smartphone vs DSLR); standardized indoor reconstruction quality checks
- Tools/products/workflows: Benchmarking suite that runs hybrid pipeline on mixed-device datasets, compares mesh quality metrics (Chamfer, precision/recall) and rendering metrics (PSNR/LPIPS/SSIM)
- Assumptions/dependencies: Access to calibration/pipeline metadata; consistent capture protocols
- Academic use in teaching and benchmarking 3D reconstruction
- Sectors: academia/education
- What it enables: Course modules on hybrid representations, planar detection, photometric optimization; reproducible experiments on ScanNet++/ScanNetv2
- Tools/products/workflows: Lab assignments integrating 3DGS + 2DGS with provided masks; ablation exercises on plane optimization and densification strategies
- Assumptions/dependencies: Access to datasets and GPU resources; familiarity with the 3DGS training stack
Long-Term Applications
The following applications are promising but require further research, optimization (e.g., real-time constraints), broader integration, standardization, or end-to-end training beyond current dependencies.
- Real-time/on-device hybrid reconstruction for AR and robotics
- Sectors: consumer AR, robotics
- What it enables: Live scene capture and reconstruction with planar constraints for immediate AR occlusion/navigation
- Tools/products/workflows: Hardware-accelerated rasterization and plane detection; low-latency block-coordinate optimization; streaming densification
- Assumptions/dependencies: Significant acceleration of training (reduce or replace RANSAC), model compression, on-device GPU/NPU support
- End-to-end plane detection without external masks
- Sectors: software, academia
- What it enables: Joint learning of geometry and planar segmentation, removing reliance on SAMv2/PlaneRecNet
- Tools/products/workflows: Multi-task networks that predict planes and optimize hybrid Gaussians; differentiable plane grouping and consistency constraints
- Assumptions/dependencies: Robust multi-view supervision; reliable plane priors; improved stability for simultaneous optimization
- Integration with SLAM for online mapping and navigation
- Sectors: robotics, industrial automation
- What it enables: Planar-aware SLAM that exploits hybrid Gaussians to reduce drift in textureless areas and improve map consistency in real time
- Tools/products/workflows: SLAM back-ends with plane-aware factor graphs; incremental plane/gaussian updates; lightweight occlusion-aware rendering
- Assumptions/dependencies: Low-latency optimization; robust handling of dynamic scenes; interplay with inertial sensing
- Automated building compliance and digital building registry
- Sectors: policy/regulation, AEC, smart cities
- What it enables: Standardized geometric checks (clearances, slopes, openings) from scans; creation of certified digital twins for permitting and audits
- Tools/products/workflows: Compliance engines reading planar meshes and volumetrics; integrations with municipal registries and BIM standards (IFC/COBie)
- Assumptions/dependencies: Regulatory frameworks for photogrammetric evidence; certification of accuracy; data privacy and access controls
- Energy modeling and retrofit planning
- Sectors: energy, sustainability, facility management
- What it enables: Using accurate interior geometry (surfaces, volumes) for thermal simulations and retrofit design (insulation, HVAC)
- Tools/products/workflows: Hybrid recon → planar meshes → material property assignment → coupling to energy simulators (EnergyPlus/Modelica)
- Assumptions/dependencies: Material/thermal properties acquisition; accurate window/door detection; validated end-to-end uncertainty estimates
- Emergency response mapping and autonomous indoor drones
- Sectors: public safety, robotics
- What it enables: Rapid 3D mapping of unfamiliar interiors with reliable planar geometry for safe navigation and situational awareness
- Tools/products/workflows: Drone capture → accelerated hybrid recon → floor/wall extraction → route planning and hazard visualization
- Assumptions/dependencies: Real-time or near-real-time reconstruction; robustness to challenging lighting/smoke; reliable pose estimation under stress
- Crowd-sourced, device-agnostic indoor datasets and platforms
- Sectors: software platforms, academia, policy
- What it enables: Large-scale, standardized indoor digital twins collected by citizens across devices; analytics on building stock
- Tools/products/workflows: Privacy-preserving upload pipelines; automatic hybrid recon; quality scoring and alignment to standardized schemas
- Assumptions/dependencies: Privacy/compliance frameworks; scalable compute; uniform capture guidance; governance
- Semantic-level editing and generative augmentation of digital twins
- Sectors: media/entertainment, design tools
- What it enables: Scene editing grounded on planar semantics (replace wall textures, move partitions) with photorealistic rendering
- Tools/products/workflows: Hybrid recon + semantic layers → generative tools for material changes and layout modifications → consistency-aware re-rendering
- Assumptions/dependencies: Stronger appearance models for view-dependent effects; reliable semantic segmentation and material inference
- Warehouse and manufacturing layout optimization
- Sectors: logistics, manufacturing, robotics
- What it enables: Accurate interior mapping for aisle planning, robot routing, and safety zone verification
- Tools/products/workflows: Capture → hybrid recon → planar/volumetric map ingestion by digital twin planners → simulation of flows and constraints
- Assumptions/dependencies: Integration with industrial planners; handling of occlusions and dynamic obstacles; operational certifications
- Surface-change monitoring for maintenance and inspections
- Sectors: facility management, infrastructure
- What it enables: Periodic scans to detect geometric changes on planar surfaces (bulges, warping, gaps) and early maintenance triggers
- Tools/products/workflows: Baseline hybrid recon → scheduled re-scans → plane-wise differencing and alerts → maintenance ticketing
- Assumptions/dependencies: Stable capture protocols for comparability; thresholds and uncertainty quantification; environmental variability management (lighting, occupancy)
Notes on core dependencies and assumptions (cross-cutting)
- Requires posed images; initialization via SfM or device tracking is critical.
- Most effective for indoor scenes with significant planar structures; outdoor or highly non-planar scenes may need extensions.
- Current pipeline depends on 2D semantic plane masks (SAMv2/PlaneRecNet); mask errors degrade plane detection and mesh quality.
- Training involves RANSAC-based plane fitting and block-coordinate descent; adds computational overhead and is not yet real-time.
- Spherical Harmonics appearance may not fully capture strong view-dependent effects; specular surfaces may induce geometry compensation artifacts.
- Performance and generalization benefits across camera models are promising but may still require calibration/QA in production settings.
Glossary
- 2D Gaussian Splatting (2DGS): A surface-focused representation that uses 2D Gaussian primitives constrained to planes to reconstruct flat geometry. "flat surfaces are modeled with 2D Gaussian splats~\cite{2dgs} that are confined to 2D planes"
- 3D Gaussian Splatting (3DGS): A scene representation that renders efficiently by rasterizing 3D Gaussian primitives, enabling fast, high-quality view synthesis. "3D Gaussian Splatting~(3DGS)~\cite{3dgs} overcame NeRF slow training/rendering speed by representing scenes as efficiently rasterizable 3D Gaussians"
- 3DGS-MCMC: A variant of 3DGS that adopts Markov Chain Monte Carlo training dynamics, improving robustness and reducing reliance on SfM initialization. "3DGS-MCMC~\cite{Kheradmand20243DGS} further enhancing its accessibility by eliminating the dependency on SfM initialization"
- AbsRel: Average absolute error relative to the ground-truth depth; a normalized depth accuracy metric. "average absolute error relative to ground truth depth (AbsRel)"
- alpha blending: A compositing technique that mixes colors using opacity values during rasterization. "alpha blended using the original Gaussian opacities during the rasterization"
- Bernoulli distribution: A probability distribution over binary outcomes; used here to stochastically decide relocation of Gaussians. "as expressed by the following Bernoulli distribution:"
- block-coordinate descent: An optimization strategy that alternates between optimizing different parameter blocks to improve stability. "We optimize our representation by block-coordinate descent"
- Chamfer distance: A geometric metric that measures the average nearest-neighbor distance between two point sets or meshes. "We report mesh accuracy metrics including accuracy, precision, recall, completeness and Chamfer distance"
- cumulative distribution function: The integral of a probability density function; here used to compute relocation probabilities. "where is the cumulative distribution function of a Gaussian"
- densification: A training process that increases the number or density of primitives to better represent the scene. "For densification of planes, we rely on relocating low-opacity Gaussians to locations of dense high-opacity Gaussians"
- differentiable volumetric rendering: Rendering that computes gradients through volume integration, enabling optimization of 3D representations from images. "optimized through differentiable volumetric rendering"
- ear-clipping triangulation: A polygon triangulation algorithm that removes “ears” iteratively to form triangles. "followed by ear-clipping triangulation to produce the final mesh"
- expected ray termination: The expected depth at which a rendering ray terminates; used to estimate per-pixel depth. "We provide depth quality metrics by computing the rendered depth as the expected ray termination at each pixel"
- fixed-size voxels: Uniform 3D grid cells used to downsample point clouds efficiently. "This point cloud is downsampled using fixed-size voxels"
- hom (homogeneous transform): A function constructing a plane-to-world rigid transform from rotation and origin. "The plane-to-world transformation matrix is defined as "
- LPIPS: A perceptual image similarity metric learned from deep features. "We use the common image quality metrics PSNR, SSIM and LPIPS"
- Manhattan world assumptions: A structural prior that assumes dominant scene planes are aligned with three orthogonal directions. "uses Manhattan world assumptions on semantically segmented regions"
- Marching Squares: A 2D contour extraction algorithm analogous to Marching Cubes in 3D. "We then use Marching Squares for contour extraction"
- Neural Radiance Field (NeRF): A neural scene representation that models view-dependent radiance and density fields for novel view synthesis. "Neural Radiance Field (NeRF)~\cite{nerf} pioneered scene reconstruction with a 3D neural representation optimized through differentiable volumetric rendering"
- opacity regularizer: A penalty encouraging unnecessary or unconstrained Gaussians to shrink or vanish. "the opacity regularizer from~\citet{Kheradmand20243DGS} that vanishes the size of Gaussians that are unconstrained by the photometric loss"
- photometric loss: A reconstruction objective comparing rendered images to input photos, typically via pixel-wise errors. "3D Gaussians are trained as in~\cite{3dgs} using a photometric loss"
- plane normal consistency: A constraint ensuring estimated plane normals are consistent across views or regions. "enforces plane normal consistency in textureless regions"
- PSNR: Peak Signal-to-Noise Ratio; a standard metric for image reconstruction fidelity. "as measured by PSNR"
- RANSAC: A robust estimation algorithm that fits models by iteratively selecting consensus inliers. "We then extract a candidate plane by RANSAC optimization"
- rasterization: Rendering by projecting primitives to the image plane and accumulating their contributions per pixel. "alpha blended using the original Gaussian opacities during the rasterization"
- ray-plane intersections: The computation of intersection points between camera rays and planes to lift 2D masks into 3D. "by computing ray-plane intersections"
- regularization term: A loss component that encodes priors to stabilize or bias reconstruction. "use a regularization term that encourages the Gaussians to align with the surface of the scene"
- rigid transformation: A rotation and translation mapping coordinates between frames without scaling or shearing. "through the rigid transformation:"
- semantic masks: Segmentation masks that denote semantically labeled regions (e.g., planes) in images. "all the semantic masks for that plane are excluded from subsequent RANSAC runs"
- SfM (Structure from Motion): A pipeline that estimates camera poses and sparse 3D points from image sequences. "eliminating the dependency on SfM initialization"
- Spherical Harmonics: A basis for efficiently modeling view-dependent color or lighting on the sphere. "All Gaussians have view-dependent colors represented as Spherical Harmonics"
- SSIM: Structural Similarity Index; an image quality metric assessing structural fidelity. "We use the common image quality metrics PSNR, SSIM and LPIPS"
- soup of planes: A representation using multiple independent planar primitives to approximate scenes. "soup of planes for dynamic reconstruction"
- Total depth variation regularization: A penalty that discourages rapid depth changes to stabilize geometry in sparse regions. "$L_{\text{TV}$ is the total depth variation regularization from~\citet{Niemeyer2021Regnerf}"
- volume rendering: Rendering through integrating radiance and transmittance along rays in a continuous volume. "which are optimized via volume rendering"
Collections
Sign up for free to add this paper to one or more collections.

