- The paper introduces a novel iterative feed-forward framework that integrates generative priors via a frozen diffusion model to refine 3D Gaussian splatting from sparse views.
- The paper achieves a +2.1 dB PSNR gain over baselines, demonstrating efficient, second-scale inference without test-time optimization.
- The paper’s modular design leverages iterative residual updates and window attention to enhance geometry and texture, addressing challenges in sparse and out-of-domain scenes.
Generative Prior-Guided Iterative Feed-Forward 3D Gaussian Splatting from Sparse Views
Introduction and Motivation
Sparse-view 3D reconstruction remains a persistent challenge due to the trade-off between high-fidelity render quality and inference efficiency, especially in the absence of known camera parameters and when deploying generative priors. Conventional per-scene optimization pipelines, such as NeRF and 3D Gaussian Splatting (3DGS), provide superior performance with dense observation; however, they are impractical for scalable deployment due to test-time optimization requirements and poor performance on sparse or under-constrained scenes. In contrast, feed-forward models offer fast inference but suffer from capacity constraints, inability to inject scene-specific priors, and lack iterative refinement mechanisms.
A conceptual comparison of reconstruction paradigms is depicted below, highlighting the strengths and limitations of per-scene optimization, one-shot feed-forward architectures, and the proposed method.
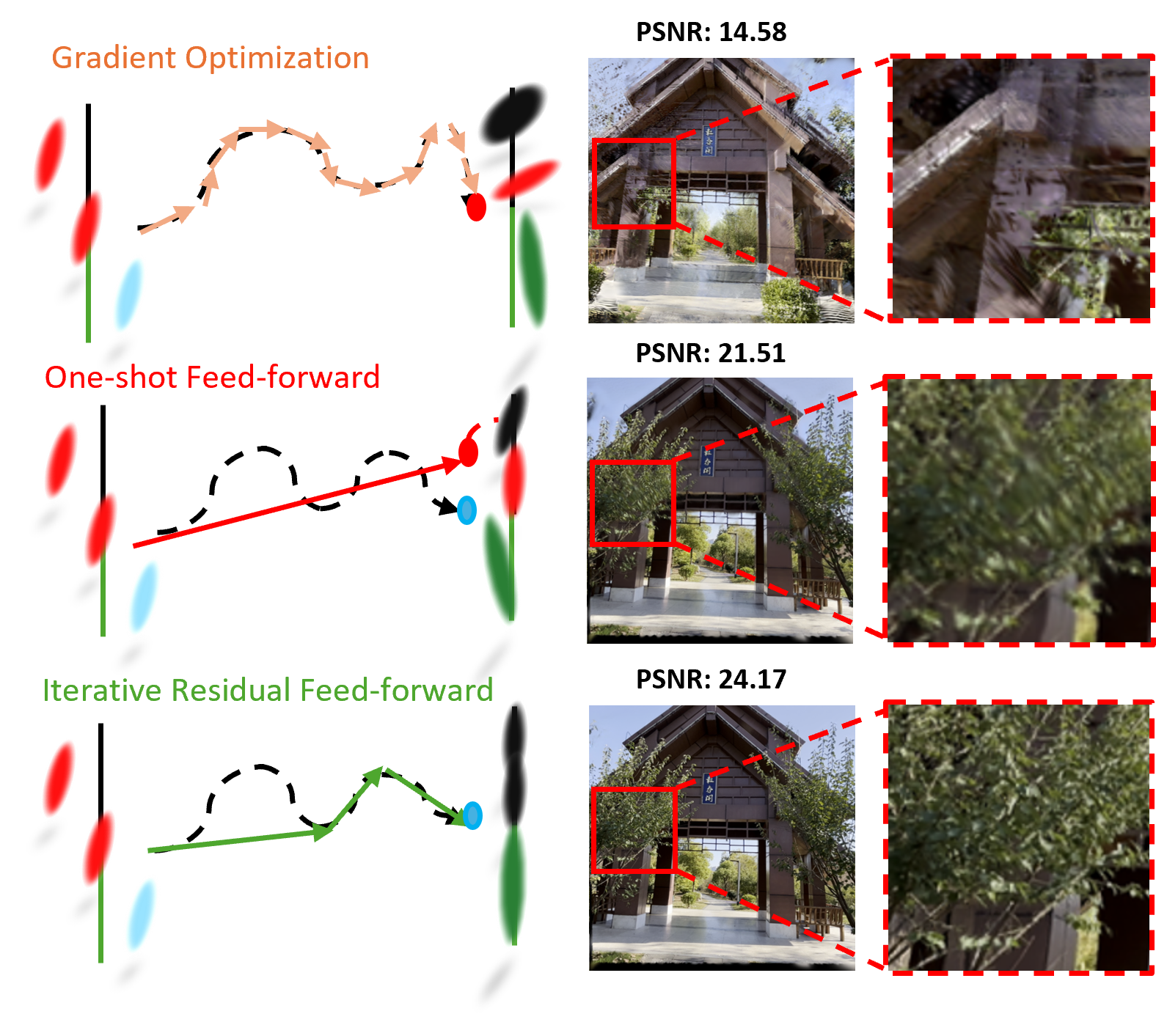
Figure 1: Comparison of gradient-based optimization, one-shot feed-forward, and the proposed iterative feed-forward refinement for 3D reconstruction.
GIFSplat Framework
GIFSplat introduces an iterative feed-forward architecture that merges the rapid inference of feed-forward networks with the scene-adaptive refinement typical of optimization-based procedures, but without test-time backpropagation. Central to the framework are three components: a feed-forward Gaussian initializer, an iterative Gaussian head for forward-only residual refinement, and a generative prior fusion module.
The framework begins with the initializer producing initial camera parameters and a coarse 3DGS from sparse unposed views. The iterative head refines these Gaussians in multiple steps using both observation-derived evidence and generative cues. Generative priors are distilled via a frozen diffusion model into Gaussian-level cues, which are concatenated with observation cues and integrated in the residual update loop.
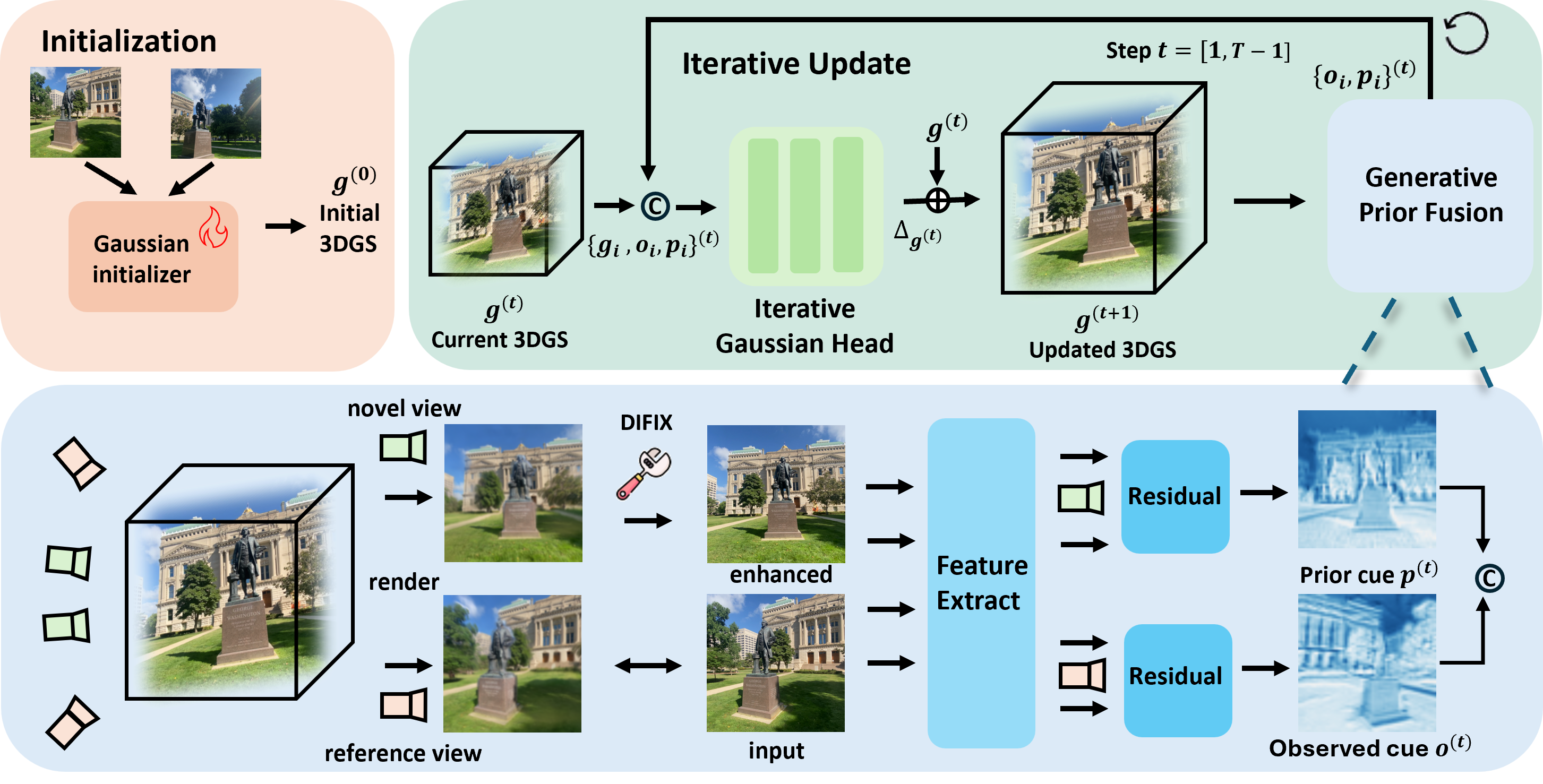
Figure 2: Overview of GIFSplat, illustrating the pipeline from initialization, through iterative refinement, to generative prior fusion for 3D Gaussian Splatting.
Iterative Feed-Forward Residual Refinement
Unlike traditional one-shot feed-forward approaches, the iterative Gaussian head in GIFSplat applies T forward-only updates to the current scene estimate, progressively correcting errors by minimizing discrepancies between rendered and observed features. Importantly, all updates occur without test-time gradients or viewset expansion, enabling efficient and adaptive scene refinement.
This approach is fundamentally different from previous pixel-aligned Gaussian splatters. By transitioning to point-based Gaussians and introducing window attention, the refinement process better preserves 3D geometry, respects local structure, and avoids the drawbacks of pixel-to-Gaussian assignments.
The improvement in geometry and appearance through forward steps is illustrated visually:

Figure 3: Visualization of forward-only iterative refinement: the process reduces blur and artifacts, incrementally sharpening the reconstruction.
Generative Prior Fusion
A distinctive aspect of GIFSplat is the formulation of generative prior integration. Using a frozen diffusion enhancer, rendered views are improved and feature-space differences (“enhancement deltas”) are extracted. These deltas are pooled at the Gaussian level and injected as cues in the iteration loop, facilitating detail recovery and perceptual quality improvements, particularly in sparsely observed or out-of-domain regions. The entire process is forward-only and requires no backpropagation through the diffusion model or expanded viewset.
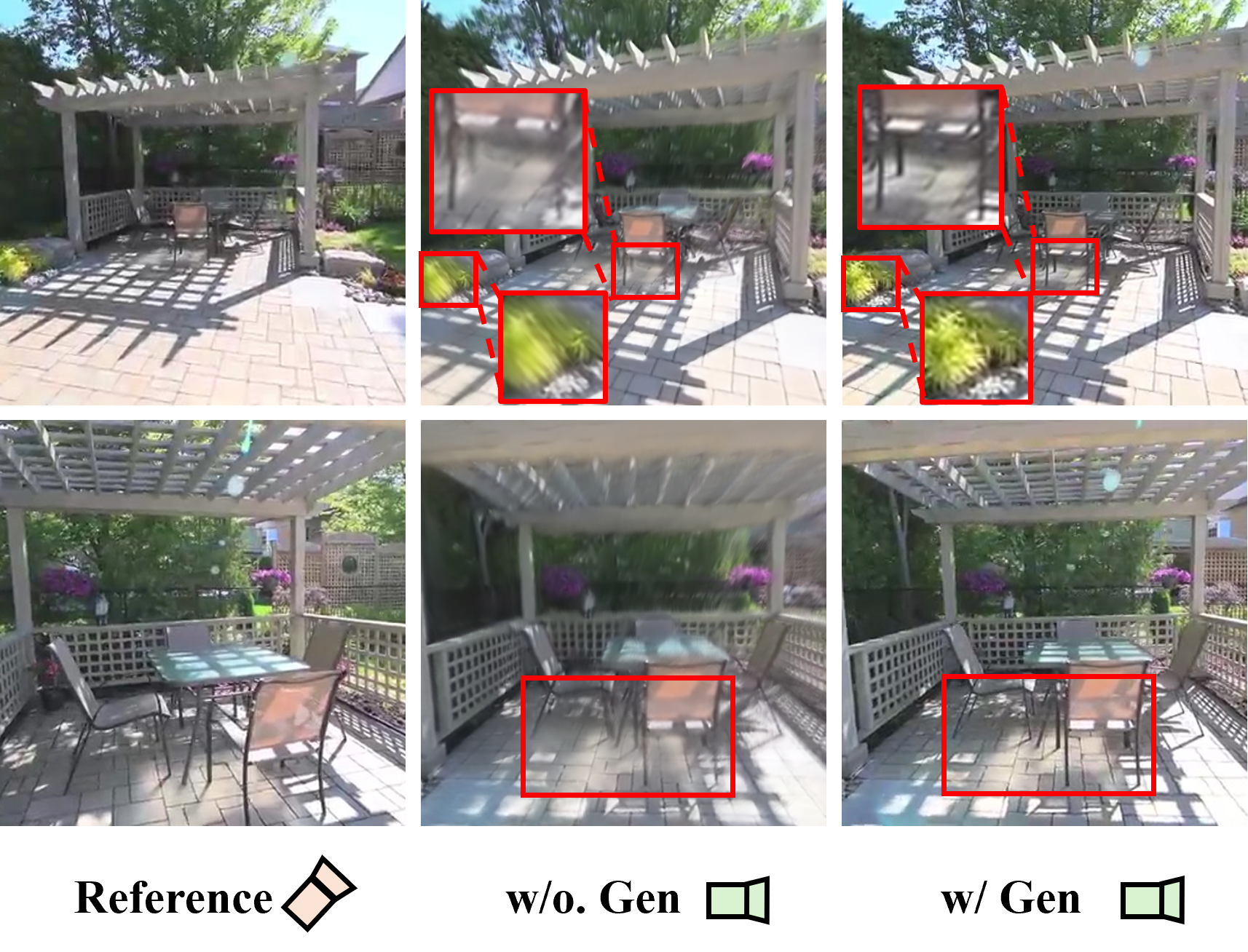
Figure 4: The generative prior fusion pipeline: starting from feed-forward render, enhanced by a diffusion-based module, then cues extracted and fed back for iterative refinement.
Experimental Results
GIFSplat demonstrates robust improvements on DL3DV, RealEstate10K, and DTU datasets, consistently outperforming baseline feed-forward methods such as FLARE, AnySplat, and NopoSplat. The model is pose-agnostic and yet achieves the highest reported PSNR, SSIM, and lowest LPIPS both in-distribution and under domain shift scenarios. Notably, GIFSplat attains +2.1 dB PSNR gain compared to competitive feed-forward baselines, even with only sparse views and without test-time gradient optimization.
Representative qualitative results further validate the fidelity of boundaries and textures achieved:

Figure 5: Indoor scene comparison: GIFSplat resolves fine boundaries and textures better than FLARE and AnySplat, with reduced artifacts.
In more challenging outdoor scenarios and cross-domain (DTU) evaluations, GIFSplat retains its superiority, offering generalization not achievable by the baselines:

Figure 6: DL3DV results: GIFSplat consistently produces sharper, less blurry reconstructions compared to leading feed-forward techniques.
Efficiency
A crucial aspect is the inference-time efficiency. Both IFSplat (the iterative observation-only variant) and GIFSplat scale linearly with the number of refinement steps T, preserving second-scale inference even with generative prior fusion.
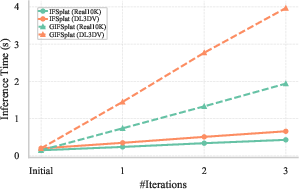
Figure 7: Inference runtime increases only linearly with the number of refinement steps for both IFSplat and GIFSplat.
Discussion and Implications
GIFSplat's iterative, forward-only refinement paradigm addresses fundamental limitations of current sparse-view 3D reconstruction: it combines adaptive correction and strong prior integration with the efficiency required for real-world deployment. The framework's architectural modularity allows flexible configuration of iterative depth and generative fusion strength, making it highly adaptable for differing data regimes and application requirements.
Key advances include:
- Feed-forward, test-time optimization-free iterative refinement supporting scene adaptation.
- Lightweight, frozen generative prior integration at Gaussian-level, avoiding viewset explosion.
- Strong cross-domain robustness and pose-free operation.
Notably, ablation studies reveal each module’s necessity (iterative residuals, window attention, and generative prior cues), confirming their individual and collective contributions.
Advancing this line, future work should target dynamic scenes, multimodal prior fusion (depth, normals), and accommodating variable input modalities to further push practical 3D vision systems toward robustness and versatility in unconstrained environments.
Conclusion
GIFSplat offers a robust, efficient, and extensible solution for sparse-view 3D reconstruction in both standard and out-of-domain scenarios, achieving state-of-the-art quantitative performance without the need for camera pose input or test-time optimization. The demonstrated capability to inject powerful generative priors via a frozen diffusion model, in a purely feed-forward iterative process, establishes a new benchmark for scalable 3DGS approaches. Further extensions in direction of dynamic content and additional priors are expected to enhance its applicability across diverse vision and graphics pipelines.