GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
Abstract: The efficient spatial allocation of primitives serves as the foundation of 3D Gaussian Splatting, as it directly dictates the synergy between representation compactness, reconstruction speed, and rendering fidelity. Previous solutions, whether based on iterative optimization or feed-forward inference, suffer from significant trade-offs between these goals, mainly due to the reliance on local, heuristic-driven allocation strategies that lack global scene awareness. Specifically, current feed-forward methods are largely pixel-aligned or voxel-aligned. By unprojecting pixels into dense, view-aligned primitives, they bake redundancy into the 3D asset. As more input views are added, the representation size increases and global consistency becomes fragile. To this end, we introduce GlobalSplat, a framework built on the principle of align first, decode later. Our approach learns a compact, global, latent scene representation that encodes multi-view input and resolves cross-view correspondences before decoding any explicit 3D geometry. Crucially, this formulation enables compact, globally consistent reconstructions without relying on pretrained pixel-prediction backbones or reusing latent features from dense baselines. Utilizing a coarse-to-fine training curriculum that gradually increases decoded capacity, GlobalSplat natively prevents representation bloat. On RealEstate10K and ACID, our model achieves competitive novel-view synthesis performance while utilizing as few as 16K Gaussians, significantly less than required by dense pipelines, obtaining a light 4MB footprint. Further, GlobalSplat enables significantly faster inference than the baselines, operating under 78 milliseconds in a single forward pass. Project page is available at https://r-itk.github.io/globalsplat/





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GlobalSplat, a new way to quickly build a 3D scene from a bunch of photos or video frames and then render new views of that scene. It focuses on making the 3D model very compact, fast to create, and fast to show, without needing to do slow, per-scene tuning.
In simple terms: imagine rebuilding a room from many pictures. Instead of making a huge, heavy 3D model, GlobalSplat creates a lightweight one that still looks good and can be shown from new angles almost instantly.
What questions were the researchers trying to answer?
- How can we turn multiple photos into a small, clean 3D model that still looks sharp when viewed from new angles?
- How can we keep the model size roughly the same even if we add more input photos?
- Can we do this in one quick pass (feed-forward), without slow, scene-by-scene optimization?
- Can we keep the 3D model globally consistent (no mismatched parts) by fusing all the views smartly?
How did they do it? (Methods explained simply)
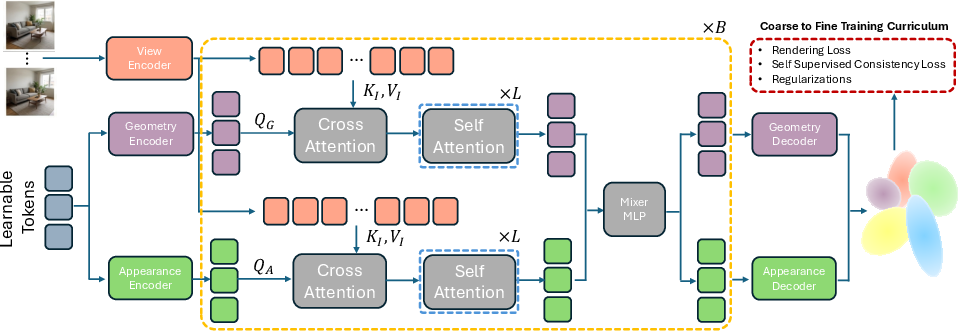
Think of each input photo as a witness describing the same scene. Earlier methods listened to each witness separately and then tried to merge everything at the end—this often produced lots of duplicate 3D stuff. GlobalSplat flips the order:
- Align first, decode later
- The system first gathers all the photos and “aligns the stories” into a shared, global summary.
- It uses a fixed number of “scene tokens.” You can think of tokens as a compact set of smart notes that summarize the whole scene. The number of tokens is fixed, so the model doesn’t bloat when you add more images.
- Separate shape from color
- The model has two parallel “branches”: one learns geometry (where things are and their shape), and the other learns appearance (what things look like: color and texture).
- Keeping these separate helps avoid hiding bad geometry behind pretty textures.
- Decode into Gaussians (“soft blobs”)
- The final 3D model is made of many tiny, soft 3D blobs called Gaussians. Imagine painting the scene with semi-transparent bubbles that, when rendered, blend into a realistic image.
- Because the tokens are globally consistent, the blobs are placed only where needed, keeping the model compact.
- Coarse-to-fine training (like sketch → detail)
- During training, the model starts simple (fewer details) and gradually adds more capacity to refine fine details.
- This prevents the model from exploding in size and helps it find a good global layout before adding small features.
- Smart inputs and checks
- Cameras are normalized to a common coordinate system so all views “speak the same language.”
- The model uses both image features and information about each camera’s position and direction.
- It trains with losses that:
- Make the rendered image match the target view (rendering loss).
- Encourage consistency when using different subsets of the input images (self-supervision).
- Keep the geometry tidy and in front of the cameras (regularization).
What did they find, and why is it important?
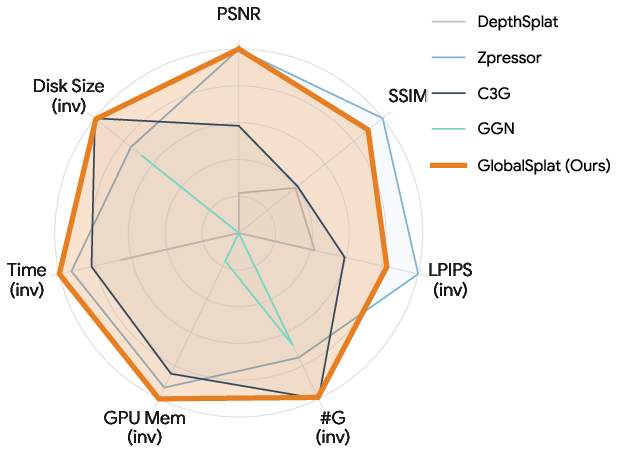
GlobalSplat reaches a sweet spot: strong image quality, tiny model size, low memory use, and fast speed—all at once.
Here are the highlights:
- Compact models: As few as 16,000 Gaussians (vs. hundreds of thousands or even millions in many other methods).
- Small files: About 4 MB per scene.
- Fast: Around 78 milliseconds to produce the 3D model in one forward pass.
- Low memory: About 1.79 GB of GPU memory at inference.
- Quality: Competitive image quality on standard benchmarks (e.g., on RealEstate10K with 24 input views, around 28.5 PSNR—a “higher is better” image quality score).
- Stable as you add views: Unlike many methods, the model size does not blow up when you add more input photos, because the number of scene tokens is fixed.
They also tested on a very different dataset (ACID, which is aerial drone footage) without retraining and still got strong results. That means the method generalizes well and isn’t just memorizing one type of scene.
What does this mean for the future?
- Practical 3D capture: You could turn short phone videos into shareable, light 3D models that are easy to store, stream, and render, even on modest hardware.
- Better VR/AR and games: Fast, compact 3D reconstructions make it easier to bring real-world spaces into virtual experiences without heavy processing.
- Robotics and mapping: Robots and drones could build usable 3D maps quickly without needing big computers or long processing times.
- Scalability and next steps:
- Today’s method fixes the number of tokens and works great for room-sized or local outdoor scenes. For very large city-scale spaces, future versions could adapt the number of tokens based on scene complexity.
- The current system assumes static scenes. Extending it to handle motion (dynamic or 4D scenes) is a promising direction.
- Extremely sparse inputs (only a couple of photos) are still tough; adding stronger single-image depth hints could help.
In short, GlobalSplat shows how to “listen to all the witnesses first” (align), then “draw the scene” (decode), producing a small, fast, and consistent 3D model from multiple photos.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following aspects uncertain or unexplored:
- Scaling to large, unbounded, or city-scale scenes: How to adapt the fixed token/Gaussian budget (e.g., 16K) to scenes whose spatial extent and complexity exceed room- or short-trajectory scales; effectiveness of adaptive/hierarchical token allocation and per-scene capacity selection.
- Dynamic (4D) scenes: How to extend global scene tokens and the decoder to handle temporal dynamics, moving objects, and changing geometry/appearance while preserving compactness and fast inference.
- Sparse-view regimes: Performance and stability with extremely few inputs (e.g., 2–3 images); effectiveness of integrating monocular priors (depth/normal/edge) or geometric constraints to disambiguate structure in low-parallax settings.
- Robustness to calibration noise: Sensitivity to pose/intrinsics errors, rolling-shutter artifacts, and lens distortion; whether joint pose refinement or pose-uncertain training improves stability; applicability to uncalibrated inputs.
- Input-view scalability: The cross-attention cost to patchified multi-view features likely grows with number of views; missing empirical and theoretical scaling curves (memory/latency) for >36 views and strategies (e.g., sparse attention, view selection) to keep cost bounded.
- Resolution scaling: All evaluations are at 256×256; missing analysis of quality, run-time, and memory at higher resolutions (e.g., 512p, 1080p) and multi-resolution training/inference strategies.
- 3D geometry accuracy: No evaluation with geometry metrics (e.g., depth error, Chamfer/L1 to COLMAP/MVS reconstructions) to quantify structural fidelity and failure modes beyond image-space PSNR/SSIM/LPIPS.
- View-dependent appearance and specularity: SH-based color may underfit strong specularities/complex BRDFs; need to assess on scenes with glossy/reflective materials or explore richer appearance models (e.g., learned BRDFs or neural view-dependence).
- Challenging materials and structures: Robustness to transparency, thin structures, and reflective/textureless surfaces is not systematically measured; require targeted benchmarks and diagnostics.
- Coarse-to-fine curriculum design: Choice of K_s=16 candidates per slot, the merge schedule (G=1→2→4→8), and the temperature/aggregation operator are not justified or compared to alternatives; open to schedule optimization and curriculum learning studies.
- Token vs. splat allocation: While more tokens outperform more splats-per-token at fixed budgets, there is no mechanism for adaptive per-scene allocation or per-region refinement; explore learn-to-allocate or hierarchical tokenization.
- Canonical alignment robustness: The average-camera canonical frame and scale normalization may fail for diverse trajectories (e.g., circular/orbital, multi-floor, outdoor); analyze failure cases and alternative normalizations.
- Consistency objective scope: The self-supervised consistency uses depth/opacity rendered images with stop-grad; unexplored are 3D-consistency directly over Gaussian parameters, multi-view photometric consistency, or cycle consistency, and their impact on stability.
- Training cost and data requirements: Missing details on training compute (GPU-days), memory footprint, wall-clock time, and sensitivity to training data diversity; energy/compute efficiency compared to baselines.
- Asset footprint accounting: The reported ~4 MB for 16K Gaussians lacks serialization details (precision, quantization, entropy coding); need to quantify compression vs. fidelity trade-offs and runtime implications.
- SH order and appearance capacity: The order of spherical harmonics and its effect on compactness/quality-speed trade-offs are not specified or ablated.
- Downstream editability and relighting: Whether the compact Gaussian asset supports interactive editing (geometry/appearance, object insertion/removal) and relighting; constraints and required parameterizations.
- Uncertainty estimation: No mechanism for per-splat or per-token uncertainty to drive adaptive capacity, view selection, or active acquisition; potential benefits for reliability and refinement.
- Photometric inconsistencies: Robustness to exposure changes, auto white-balance, motion blur, and sensor noise is not evaluated; strategies for photometric normalization remain open.
- Benchmark coverage and fairness: Some baselines (e.g., EcoSplat) are reported from papers with different protocols; several strong feed-forward 3DGS methods are missing under the unified evaluation; need standardized high-resolution, multi-view benchmarks.
- Domain generalization breadth: Zero-shot tests on ACID are promising but limited; need evaluations on urban outdoor (e.g., KITTI-360, Waymo), synthetic (Blender), and varying illumination datasets to measure OOD robustness.
- Differentiability for downstream optimization: It is unclear how stable end-to-end gradients are through the encoder–decoder–renderer for tasks like finetuning, pose refinement, or task-driven optimization.
- Compatibility with post-hoc compression/LoD: Whether GlobalSplat assets remain amenable to ProtoGS/GoDe/entropy models for further compression or LoD hierarchies without degrading the quality–compactness point.
- Geometric priors and constraints: Lack of explicit occupancy/visibility constraints risks “floating” Gaussians behind surfaces; investigate priors (e.g., signed distance/occupancy hints) or occlusion-aware decoding.
- Outlier handling: How the method deals with inconsistent inputs (moving objects across views, rolling shutter) and whether robust aggregation or outlier rejection is needed.
- Temporal consistency of renderings: While single-view NVS is measured, temporal flicker across rendered trajectories and stability under camera motion are not quantified; require temporal metrics and user studies.
- Streaming/incremental operation: The pipeline produces an asset per context set but does not explore streaming updates or persistent memory across long sequences; design and evaluation of online updates remain open.
- Attention complexity characterization: Formal complexity (time/memory) as a function of tokens, patches, and views is not provided; guidance for deployment-time tuning (tokens, patch size, views) is missing.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s ecosystem of cameras, SfM/ARKit poses, and existing 3D Gaussian Splatting (3DGS) renderers. Each item notes the sector, a suggested product/workflow, and key assumptions/dependencies that affect feasibility.
- Ultra‑light 3D virtual tours for real estate and architecture
- Sectors: real estate, AEC (architecture/engineering/construction), media
- Tools/products/workflows:
- Capture 16–36 images or a short video walkthrough with camera poses from ARKit/ARCore or COLMAP.
- Run GlobalSplat inference (single forward pass, ~78 ms reported, ~1.79 GB peak GPU memory) to produce a compact 3DGS asset (e.g., ~16K Gaussians ≈ ~4 MB).
- Host and render via existing 3DGS viewers or game engine plugins (Unity/Unreal CUDA/WebGPU integrations) on listing sites or design review portals.
- Assumptions/dependencies: Static interiors; reliable camera pose estimation; sufficient view coverage; trained model generalizes best to room‑scale scenes; web/mobile viewer support for 3DGS.
- On‑set previsualization and location scouting
- Sectors: film/VFX, media production
- Tools/products/workflows:
- Use a phone or mirrorless camera to capture a space; obtain poses (ARKit/COLMAP).
- Generate a lightweight Gaussian asset for quick set blocking, virtual camera moves, and lighting exploration in Unreal/Unity.
- Assumptions/dependencies: Static sets; moderate scene size; production pipelines that accept 3DGS or convert it to meshes for downstream tools if needed.
- Drone-based site snapshots and rapid situational awareness
- Sectors: construction, energy (substations, solar/wind farms), infrastructure inspection, public safety
- Tools/products/workflows:
- Fly a short path (dozens of frames) over a site with known/inferred poses.
- Produce a compact 3D asset on the edge (truck/ground station) for supervisors; overlay with annotations in a web dashboard.
- Assumptions/dependencies: Mostly static environments; adequate viewpoint coverage; GPS/SfM poses; domain generalization is supported (demonstrated on aerial dataset), but extreme scale or high-altitude imagery may need fine-tuning.
- Low-bandwidth 3D scene sharing for telepresence and collaboration
- Sectors: communications, enterprise collaboration, customer support
- Tools/products/workflows:
- Replace repeated video streaming with a single small 3DGS upload (~MBs).
- Remote participants render novel views locally at interactive rates via 3DGS rasterization.
- Assumptions/dependencies: Static scene during a session; an initial capture step; recipients must have a 3DGS-capable viewer (desktop/mobile/web).
- Mobile AR occlusion and background reconstruction
- Sectors: software, AR/VR, retail marketing
- Tools/products/workflows:
- Use multi-view frames and ARKit poses on-device or via edge service to reconstruct a compact 3DGS that provides geometry cues for occlusion and basic physics.
- Render and composite virtual content in real time.
- Assumptions/dependencies: Static backgrounds; short capture window; device or edge GPU for inference; integration with AR frameworks; fidelity tied to training distribution and capture coverage.
- Digital heritage and cultural assets (static)
- Sectors: museums, cultural heritage, education
- Tools/products/workflows:
- Capture galleries or static exhibits; generate compact 3DGS for archiving and web-accessible walkthroughs with minimal storage costs.
- Assumptions/dependencies: Primarily room‑scale interior scenes; policies and permissions for filming; for small artifacts/objects, domain fine‑tuning may be required.
- Property documentation for insurance and facilities
- Sectors: insurance, facilities management, real estate operations
- Tools/products/workflows:
- Adjusters/inspectors capture a walkthrough; back office or on-device inference produces a small 3D asset for claims review or maintenance planning.
- Assumptions/dependencies: Static interior spaces; privacy controls (face/license blurring) handled in preprocessing; reliable pose estimation.
- Photoreal backdrops for robotics simulation and training
- Sectors: robotics, autonomy R&D
- Tools/products/workflows:
- Capture real rooms/shops to create lightweight photoreal backgrounds for simulation testbeds; render GPUs can host many scenes due to small assets.
- Assumptions/dependencies: Representation is view-synthesis oriented (not metrically perfect surfaces); suitable for visual realism, less for precision geometry/physics.
- Classroom/lab demonstrations and benchmarking in 3D vision
- Sectors: education, academia
- Tools/products/workflows:
- Use open implementation to demonstrate feed‑forward multi‑view fusion, latent scene tokens, and 3DGS rendering; assign projects on compactness vs. fidelity trade‑offs.
- Assumptions/dependencies: Curriculum and compute availability; dataset preparation with camera poses.
- Cloud “photo‑to‑3D” APIs
- Sectors: software platforms, developer tools
- Tools/products/workflows:
- Offer an API where users upload images+poses; return a compact 3DGS asset and preview viewer; enable integration into CMS and web apps.
- Assumptions/dependencies: Licensing for pretrained weights; privacy/consent workflows; GPU-backed inference; pose estimation pipeline for user uploads.
- CDN-friendly hosting of 3D scenes
- Sectors: web platforms, media/CDN providers
- Tools/products/workflows:
- Store and distribute small 3DGS assets (e.g., ~4 MB per room) for rapid loading; progressive scene loading by region for large spaces.
- Assumptions/dependencies: Browser support (WebGPU/WebGL rasterizers); consistent runtime performance across devices.
- Rapid interior visualization in real-time BIM review
- Sectors: AEC, design review
- Tools/products/workflows:
- Convert site captures into 3DGS to compare “as‑is” with BIM; switch views interactively during coordination meetings.
- Assumptions/dependencies: Static site segments; BIM alignment steps; enterprise IT support for new viewers.
Long-Term Applications
These opportunities require further research, scaling, or integration beyond the current scope (e.g., dynamic scenes, city-scale, uncalibrated inputs, richer semantics).
- Dynamic 4D scene capture (time‑varying Gaussians)
- Sectors: telepresence, sports broadcasting, live events
- Tools/products/workflows:
- Extend global scene tokens with temporal modeling for moving subjects; stream evolving 3DGS over time for live experiences.
- Assumptions/dependencies: New training for spatiotemporal tokens; motion-aware rendering; higher capture bandwidth.
- City‑scale and outdoor digital twins with hierarchical tokens
- Sectors: smart cities, GIS, autonomous driving maps
- Tools/products/workflows:
- Introduce hierarchical/adaptive token allocation for large unbounded scenes; stream level-of-detail (LoD) by viewport.
- Assumptions/dependencies: Scalable training; streaming tiling infrastructure; robust outdoor pose estimation.
- Online SLAM and persistent mapping via feed‑forward tokens
- Sectors: robotics, AR cloud anchors
- Tools/products/workflows:
- Fuse GlobalSplat’s global latent tokens with SLAM back‑ends for rapid online map reconstruction and loop closure hints.
- Assumptions/dependencies: Incremental update mechanics for tokens; handling long-term changes; drift correction.
- Uncalibrated capture (joint pose + Gaussian prediction)
- Sectors: consumer apps, casual creators
- Tools/products/workflows:
- Integrate a learned pose estimation frontend; enable “just shoot” capture without explicit calibration.
- Assumptions/dependencies: Training on uncalibrated datasets; robustness to rolling shutter and motion blur.
- Semantic editing and compositing of Gaussian assets
- Sectors: game dev, VFX, XR content creation
- Tools/products/workflows:
- Add segmentation and material labels to Gaussians; enable text/brush-based edits (recolor, remove, relight).
- Assumptions/dependencies: Semantic supervision or multimodal training; editor UX and DCC (digital content creation) integration.
- Standardization and streaming protocols for 3DGS
- Sectors: standards bodies, CDNs, browser vendors
- Tools/products/workflows:
- Define interoperable 3DGS container/bitstream, compression profiles, and DRM; ensure smooth delivery across devices.
- Assumptions/dependencies: Industry consensus; reference decoders in WebGPU/Metal/Vulkan.
- On‑device real-time capture for AR glasses
- Sectors: consumer AR/VR hardware
- Tools/products/workflows:
- Optimize model and renderer for low‑power NPUs/GPUs to capture and render scenes on wearables.
- Assumptions/dependencies: Model compression/quantization; power and thermals; on‑device pose estimation.
- Foundation models for 3D perception using global scene tokens
- Sectors: AI research, multimodal platforms
- Tools/products/workflows:
- Use global tokens as a backbone for downstream 3D tasks (depth, normals, relighting, physics cues) or as conditioning for 3D/4D generative models.
- Assumptions/dependencies: Large-scale pretraining; multi-task heads; broader datasets beyond interiors.
- Enterprise privacy and security policies for 3D captures
- Sectors: policy, compliance, legal
- Tools/products/workflows:
- Establish consent workflows, on-device redaction, encryption/signing of 3D assets, and governance for storage/retention of captured interiors.
- Assumptions/dependencies: Toolchain for automatic PII detection/blurring; regulatory alignment (e.g., GDPR, CCPA).
- Insurance, appraisal, and claims automation with analytics
- Sectors: insurance, proptech, finance
- Tools/products/workflows:
- Combine compact 3DGS assets with analytic models (room volume, material classification) to automate estimates.
- Assumptions/dependencies: Semantic enrichment and calibration to metric scales; standardized capture protocols.
- Industrial inspection and asset management at scale
- Sectors: energy, manufacturing, logistics
- Tools/products/workflows:
- Periodic drone captures produce compact 3DGS snapshots over time; change detection and anomaly triage in a dashboard.
- Assumptions/dependencies: Temporal alignment; training on industrial textures; handling partial occlusions and clutter.
Notes on Feasibility and Dependencies
- Camera poses: The reported pipeline normalizes and leverages known camera poses. For many consumer/enterprise cases, ARKit/ARCore or SfM (COLMAP) can supply these. Uncalibrated capture remains a research direction.
- Scene type: The method assumes static scenes and shows strongest results on room‑scale and localized aerial trajectories; very large, unbounded, or highly dynamic scenes may exceed current capacity without hierarchical/adaptive extensions.
- View coverage: Performance improves with more input views (e.g., 16–36); extremely sparse inputs (<4 views) can be challenging.
- Runtime and memory: Inference was reported at ~78 ms and ~1.79 GB peak memory on an A100 GPU at 256×256 evaluation resolution. Mobile/edge deployment will require optimization; fidelity at higher resolutions depends on training and renderer.
- Rendering ecosystem: Adoption depends on availability of robust 3DGS renderers across platforms (CUDA/Metal/WebGPU) and integration into engines (Unity/Unreal) and browsers.
- Data and compliance: Capturing indoor spaces raises privacy considerations; organizations should implement consent, redaction, and secure storage practices.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit neural rendering representation that models scenes as collections of 3D Gaussians which can be efficiently rasterized for view synthesis. "3D Gaussian Splatting (3DGS) introduced an explicit alternative, representing a scene as a set of anisotropic Gaussians that can be rendered efficiently~\cite{kerbl2023gaussian}."
- alpha-blending (α-blending): A compositing technique that accumulates colors along the viewing direction using per-splat opacity; commonly done front-to-back for efficiency and correctness. "The final pixel color is accumulated through front-to-back -blending of overlapping splats sorted by depth:"
- anisotropic Gaussians: Gaussians with direction-dependent covariance (ellipsoidal rather than spherical), allowing varied spread along different axes. "representing a scene as a set of anisotropic Gaussians that can be rendered efficiently~\cite{kerbl2023gaussian}."
- camera intrinsics: Internal camera parameters (e.g., focal length, principal point) that define the camera’s projection model. "Let be the camera center and the intrinsics."
- canonical coordinate system: A normalized, scene-agnostic reference frame used to standardize poses across inputs. "we map each scene into a canonical coordinate system using a similarity transform so that camera poses have consistent orientation, translation, and scale across scenes."
- canonical frustum: A standardized viewing volume derived from normalized camera poses; helpful as a geometric prior. "This ``canonical frustum'' initialization provides a strong geometric prior, allowing the model to focus on refining local structure rather than searching for the global scene location."
- coarse-to-fine training curriculum: A staged training strategy that starts with low-capacity representations and progressively increases capacity to refine details stably. "Utilizing a coarse-to-fine training curriculum that gradually increases decoded capacity,"
- codebooks (learned codebooks): Compact sets of learned vectors used to quantize and reconstruct attributes efficiently. "via quantization, entropy modeling, masking, and learned codebooks over Gaussian attributes,"
- cross-attention: An attention mechanism where a set of queries attends to external key/value features to fuse information. "Within each branch, we apply a cross-attention mechanism between the input patches and the stream features,"
- dual-branch encoder: An architectural split into geometry and appearance streams to disentangle structure from texture during feature fusion. "we introduce a dual-branch encoder consisting of blocks."
- entropy modeling: Modeling the distribution of data for efficient compression by estimating code lengths. "via quantization, entropy modeling, masking, and learned codebooks over Gaussian attributes,"
- Fourier positional encoding: Encoding coordinates using sinusoidal functions at multiple frequencies to capture high-frequency variations. "where uses resolution-normalized intrinsics and denotes Fourier positional encoding."
- frustum constraint: A regularization encouraging predicted geometry to lie within plausible camera viewing volumes. "which consists of soft thresholding on features, and a frustum constraint which is further elaborated in Appendix~\ref{supp:impl}."
- graph interaction and pooling: Operations on predicted Gaussians treated as graph nodes to aggregate and refine representations. "introduces Gaussian-level aggregation via graph interaction and pooling~\cite{zhang2024gaussian, bai2025graphsplat},"
- implicit radiance fields: Continuous functions (usually neural networks) mapping 3D coordinates and viewing directions to color and density. "NeRF and its extensions represent scenes as implicit radiance fields~\cite{mildenhall2021nerf},"
- latent scene tokens: Learnable vectors representing global scene factors that aggregate multi-view information before decoding explicit geometry. "GlobalSplat aggregates multi-view inputs into a fixed set of global latent scene tokens before decoding geometry."
- LPIPS: A perceptual image similarity metric based on deep features; lower is better. "We report PSNR (), SSIM (), LPIPS (), and the number of Gaussians ()."
- Mixer MLP: A small multi-layer perceptron used to fuse outputs of parallel branches into updated tokens. "The streams are fused via a Mixer MLP to update the tokens for the subsequent block."
- Multi-Plane Images (MPIs): Layered depth images at discrete planes that enable fast view synthesis via warping and blending. "Multi-Plane Images (MPIs) such as Stereo Magnification \cite{zhou2018stereo},"
- NeRF: A neural implicit representation that learns radiance and density fields for novel view synthesis. "NeRF and its extensions represent scenes as implicit radiance fields~\cite{mildenhall2021nerf},"
- novel view synthesis (NVS): The task of generating new views from a scene given a set of input images. "We tackle this allocation challenge within the setting of feed-forward novel view synthesis (NVS)."
- perceptual loss: A loss computed in a deep feature space (e.g., VGG) to better align visual quality with human perception. "where $\mathcal{L}_{\mathrm{perc}$ is a perceptual loss."
- plane-sweep volumes: Volumetric representations formed by sweeping hypothetical depth planes and aggregating reprojection evidence. "plane-sweep volumes \cite{kalantari2016learning},"
- Plücker rays: A 6D representation of 3D lines using direction and moment, useful for geometry-aware encodings. "While Plücker rays effectively represent line geometry, they lack focal and translation information;"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise fidelity metric; higher is better. "We report PSNR (), SSIM (), LPIPS (), and the number of Gaussians ()."
- quaternion: A four-parameter rotation representation used to predict Gaussian orientation robustly. "It employs two specialized linear heads to disentangle the geometric properties (positions, scales, quaternions, opacity)"
- quantization: Discretization of continuous values to reduce storage/bitrate in compression pipelines. "via quantization, entropy modeling, masking, and learned codebooks over Gaussian attributes,"
- re-orthonormalizing: Re-enforcing orthonormality of rotation axes after averaging directions to maintain a valid rotation frame. "and re-orthonormalizing."
- register tokens: Learnable auxiliary tokens that help capture and distribute global context during attention-based fusion. "We also incorporate learnable register tokens to facilitate the capture of global contextual information and prevent local feature over-fitting."
- self-attention: An attention mechanism where tokens attend to each other to integrate global context. "followed by a self-attention blocks:"
- self-supervised consistency: A training objective encouraging different subsets or passes to produce consistent geometry/appearance without extra labels. "supervised jointly by rendering, self-supervised consistency, and regularization losses."
- similarity transform: A transformation combining rotation, translation, and uniform scaling used to normalize scenes. "we map each scene into a canonical coordinate system using a similarity transform so that camera poses have consistent orientation, translation, and scale across scenes."
- SLAM-derived camera poses: Camera trajectories estimated using Simultaneous Localization and Mapping methods. "typically featuring forward-facing camera trajectories and room walkthroughs with SLAM-derived camera poses."
- Spherical Harmonics (SH): A basis of spherical functions used to model view-dependent color efficiently. "view-dependent color coefficients modeled via Spherical Harmonics (SH)."
- stop-gradient: An operation that blocks gradient flow through certain tensors to stabilize objectives or prevent collapse. "We perform independent forward passes and minimize the distance between the resulting geometry using a stop-gradient () operation:"
- Structure-from-Motion (SfM): A technique to reconstruct camera poses and sparse geometry from images. "equipped with Structure-from-Motion (SfM) camera trajectories."
- temperature-scaled softmax: A softmax function with a temperature parameter to control the sharpness of the distribution over choices. "We derive importance weights from a temperature-scaled softmax."
- unprojecting (pixels): Lifting 2D pixels with depth into 3D space to form primitives aligned with views. "By unprojecting pixels into dense, view-aligned primitives, they bake redundancy into the 3D asset."
- voxel-aligned outputs: Predictions made on a 3D voxel grid, aligning features and primitives to fixed spatial cells. "or voxel-aligned outputs), attempting to reconcile them globally only afterward."
- pixel-aligned: Predictions tied to 2D image pixels, often leading to view-specific redundancies in multi-view fusion. "Specifically, current feed-forward methods are largely pixel-aligned or voxel-aligned."
Collections
Sign up for free to add this paper to one or more collections.

