- The paper introduces a comprehensive evaluation framework for multimodal research agents that benchmarks both process and outcome using real-user and LLM-generated tasks.
- It employs a three-layer evaluation pipeline assessing synthesis quality, factuality via multimodal evidence verification, and process transparency through atomic operation tracking.
- Empirical results reveal that process metrics strongly correlate with overall performance and highlight the challenges posed by multimodality in maintaining report specificity.
MiroEval: A Comprehensive Evaluation Framework for Multimodal Deep Research Agents
Motivation and Benchmark Design
The proliferation of agentic research systems—embodied by autonomous LLM-based agents capable of long-context reasoning, iterative information acquisition, and multimodal evidence integration—necessitates diagnostic benchmarks that rigorously evaluate both outcome and process. Prevailing benchmarks focus predominantly on static, rubric-based assessment of terminal outputs, often restricting their scope to text-only contexts or synthetic queries, thus failing to measure the core competencies demanded by real users: rigorous, factually grounded, auditable research workflows capable of leveraging text and multimodal information sources.
MiroEval introduces a benchmark suite and evaluation paradigm addressing these limitations through three axes: (i) real-user, continuously updatable task suite construction, (ii) multidimensional, agentic evaluation encompassing synthesis quality, factuality, and process transparency, and (iii) comprehensive support for multimodal research tasks, including attachment-grounded analysis.
Task Suite Construction and Coverage
To ensure task diversity, authenticity, and temporal relevance, MiroEval employs a dual-path pipeline for query generation (Figure 1):
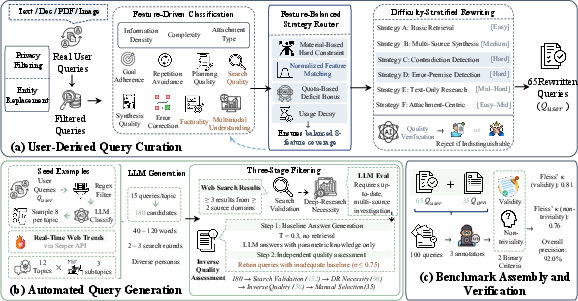
Figure 1: Query construction pipeline depicting the paths for user-derived and auto-generated queries, privacy-preserving rewriting, and multi-stage filtering.
The benchmark comprises 100 deep research tasks (70 text-only, 30 multimodal) spanning 12 domains and 10 task archetypes (Figure 2). The first path curates 65 queries via privacy-preserving abstraction and rewriting of authentic user interactions, stratified by difficulty and evaluation feature representation. The second path generates 35 queries using LLM-guided distillation of emergent real-world trends—anchored in live web headlines and filtered for research necessity, information-seeking complexity, and parametric knowledge limitations.
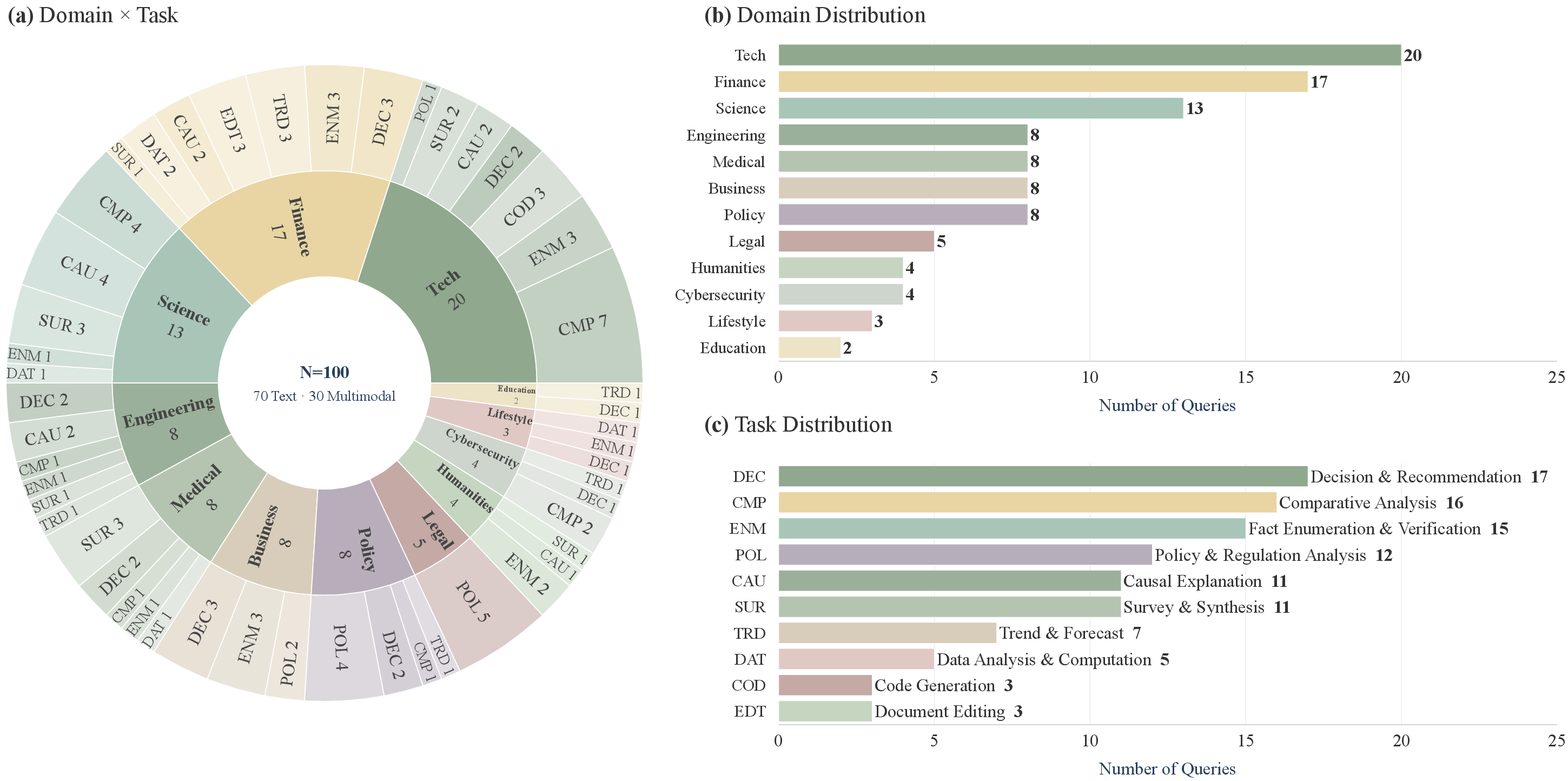
Figure 2: (a) Joint domain×task-type distribution, (b) domain distribution, (c) task-type distribution for all 100 tasks.
Tasks encompass major verticals (technology, finance, science, engineering, healthcare, etc.) and research patterns (comparative analysis, causal explanation, data analysis, code synthesis, etc.). Rigorous human verification achieves 92.0% majority-vote precision, and construction protocols enable periodic refresh, preventing benchmark staleness.
Multi-Dimensional Agentic Evaluation Pipeline
MiroEval formalizes evaluation as a three-layer process, decoupling report artifact assessment from research trajectory audit (Figure 3):
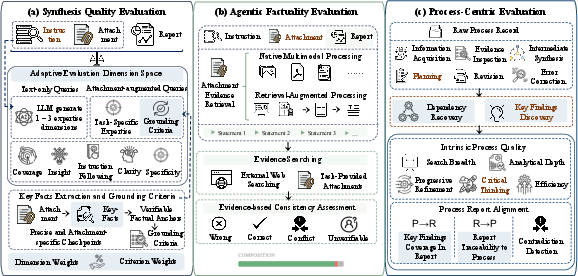
Figure 3: The evaluation pipeline—spanning synthesis quality, factual verification, and process-centric audit.
1. Adaptive Synthesis Quality Evaluation.
Task-specific rubrics are generated dynamically, augmenting four universal dimensions (coverage, insight, instruction-following, clarity) with context-grounded axes (e.g., attachment-grounded specificity, evidence-based analytical rigor). For multimodal queries, the framework enforces alignment with extracted key facts from attachments, penalizing decontextualized or invented detail. Dimension and criterion weights are learned per task, and report scores are aggregated over this weighted multidimensional space.
2. Agentic Factuality Verification.
Reports are decomposed into atomic claims via agent-driven extraction. Each claim is checked against both external web resources and task-provided multimodal evidence (PDFs, images, spreadsheets), employing both native multimodal model reasoning and retrieval-augmented chunk analysis. Consistency is labeled as RIGHT, WRONG, CONFLICT (cross-source contradiction), or UNKNOWN, explicitly tracking cross-modal and inter-source discrepancies. This enables isolation of factuality failure modes not detectable in purely text-based settings.
3. Process-Centric Evaluation.
Beyond output, MiroEval audits research procedures. Raw system trajectories are abstracted into structured process graphs: atomic operations (retrieval, reading, synthesis, hypothesis generation, contradiction handling), dependencies, and surfaced findings. Intrinsic process metrics include search breadth, analytical depth, iterative refinement, critical thinking, and redundancy minimization. The framework assesses process–report alignment bidirectionally: all report conclusions must be traceable to procedural findings (R→P) and key procedural findings must appear in the final report (P→R). Contradiction handling is separately measured.
Systematic Results and Empirical Insights
Figure 4 visualizes performance on 70 representative text-only tasks across Synthesis, Factuality, and Process:
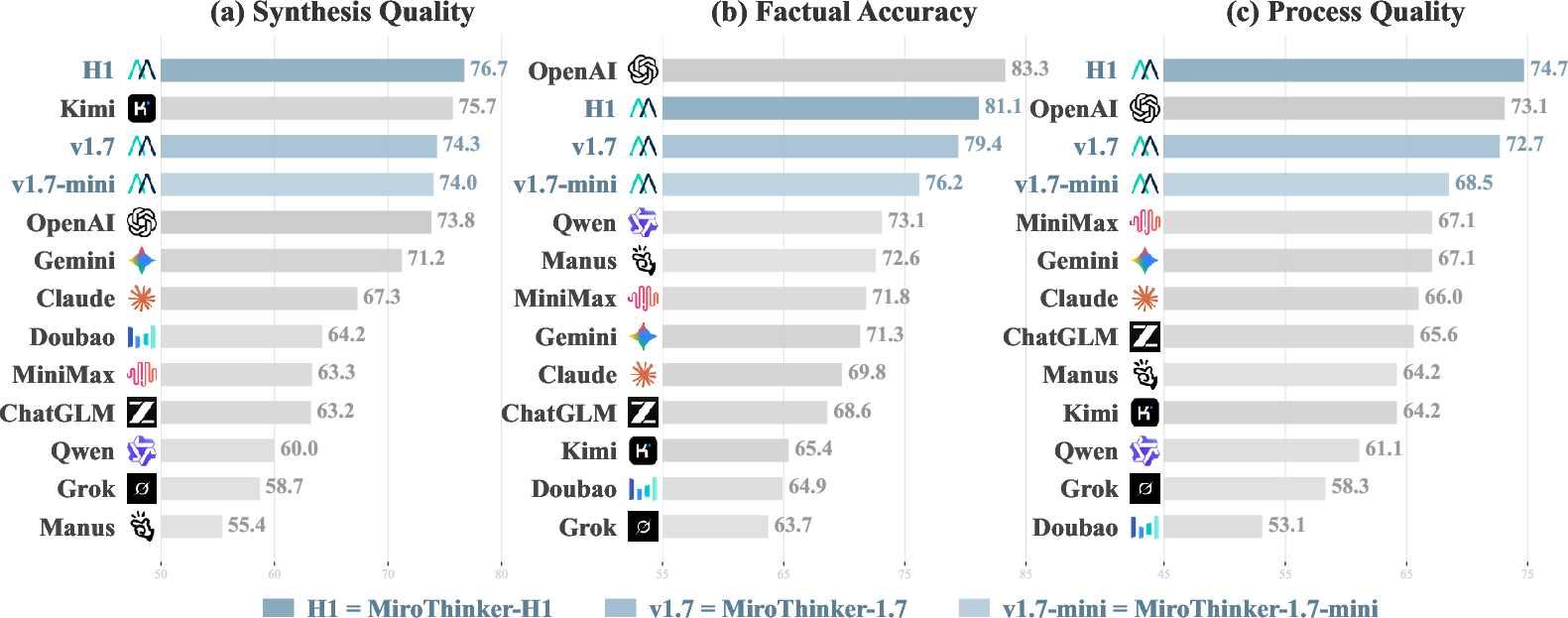
Figure 4: Comparative model performance on 70 text-only tasks across three evaluation dimensions.
Key empirical findings include:
- Non-Redundancy Across Dimensions. System rankings are non-uniform across Synthesis, Factuality, and Process. Notably, Kimi-K2.5 achieves the highest non-MiroThinker Synthesis but ranks near the bottom in Factuality, while the reverse occurs for Manus-1.6-Max Wide Research.
- Process Quality as a Predictor. Strong alignment is observed between process-centric scores and overall system outcome (Pearson's ρ = 0.88), underscoring the necessity of process-based evaluation for robust agent assessment.
- Multimodality Amplifies Challenge. Introduction of attachments causes a consistent 3–10 point drop in overall scores across evaluated systems, mainly driven by declines in report specificity and process depth, not factuality.
The MiroThinker series demonstrates balanced performance, with H1 achieving the highest overall and subdimension scores. Noteworthy is the series' capacity to maintain high claim volume and low error rates simultaneously, breaking the traditionally observed precision–volume tradeoff (Figure 5):
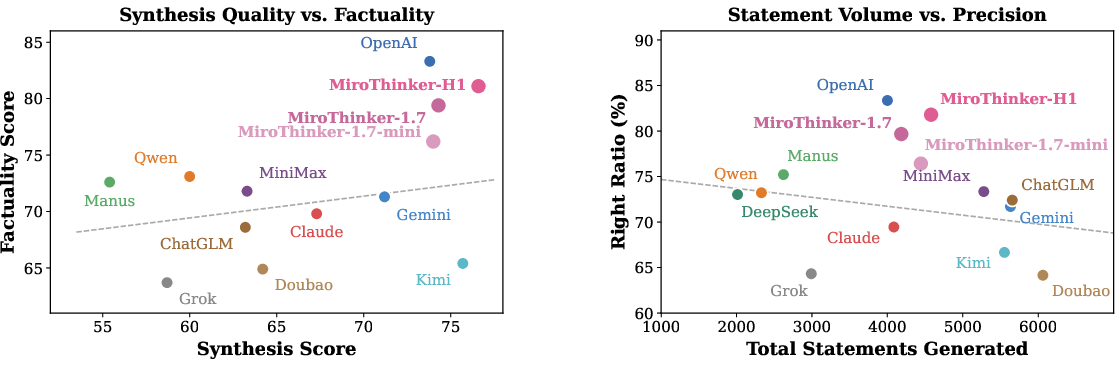
Figure 5: Left—synthesis quality vs. factuality, showing weak correlation. Right—statement count vs. right ratio, indicating a negative correlation except for top-tier systems.
Further analyses reveal:
- User-Derived vs. Auto-Generated Tasks: User-derived queries are systematically more difficult, yet relative system rankings are stable, supporting robust, extensible benchmark construction.
- Systematic Failure Modes: The main bottlenecks are lack of report specificity, shallow analytical reasoning in the research process, and traceability gaps (unlinked report claims).
- Evaluation Robustness: Human and alternative-LM judges reproduce ranking with Kendall’s τ = 0.91, and cross-configuration evaluation yields <2 point standard deviations.
Implications and Future Directions
MiroEval defines a comprehensive standard for benchmarking deep research agents, enabling phase-aligned optimization and fine-grained diagnosis. Multimodal research challenges remain acute—integration of attachment-grounded reasoning, process-traceable synthesis, and contradiction resolution over heterogeneous and evolving corpora are open problems.
Practically, MiroEval provides actionable diagnostics for model development pipelines, guiding improvements in multimodal understanding, procedural transparency, and fact-grounded synthesis. The benchmark’s live-refresh feature suggests a pathway for model–benchmark co-evolution, reducing overfitting and ensuring continued relevance to emergent user needs.
Theoretically, the work exposes fundamental deficiencies in current agent architectures—particularly around process–output decoupling, factual discipline, and alignment under ambiguity—directing future research toward architectures that optimize not just for output quality but transparent, auditable research workflows. Methodological advances are still needed in multi-agent conflict adjudication, adaptive rubric construction, and agentic long-context trajectory modeling.
Conclusion
MiroEval establishes a rigorous agentic evaluation paradigm for deep research, integrating user-aligned, multimodal, and temporally adaptive benchmarks with multidimensional process/outcome auditing. The frameworks and empirical baselines presented provide essential infrastructure for advancing research agent capabilities, system transparency, and trustworthiness at the intersection of language, reasoning, and multimodal understanding (2603.28407).

