Towards Personalized Deep Research: Benchmarks and Evaluations
Abstract: Deep Research Agents (DRAs) can autonomously conduct complex investigations and generate comprehensive reports, demonstrating strong real-world potential. However, existing evaluations mostly rely on close-ended benchmarks, while open-ended deep research benchmarks remain scarce and typically neglect personalized scenarios. To bridge this gap, we introduce Personalized Deep Research Bench, the first benchmark for evaluating personalization in DRAs. It pairs 50 diverse research tasks across 10 domains with 25 authentic user profiles that combine structured persona attributes with dynamic real-world contexts, yielding 250 realistic user-task queries. To assess system performance, we propose the PQR Evaluation Framework, which jointly measures (P) Personalization Alignment, (Q) Content Quality, and (R) Factual Reliability. Our experiments on a range of systems highlight current capabilities and limitations in handling personalized deep research. This work establishes a rigorous foundation for developing and evaluating the next generation of truly personalized AI research assistants.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About
This paper is about making smarter AI “research assistants” that don’t just find facts, but also tailor their reports to the unique needs of different people. The authors build a new test (called a benchmark) and a scoring system to check whether these AI agents can personalize their research, write high-quality reports, and back up what they say with reliable sources.
In short: they want AI research agents that are not only correct, but also helpful for you specifically.
The Big Questions the Paper Tries to Answer
- Can AI research agents adjust their work to fit different users’ goals, budgets, preferences, and knowledge levels?
- How do we fairly measure whether an AI’s report is both personalized and trustworthy?
- Which kinds of AI systems do better at personalization, report quality, and factual reliability?
- Does giving the AI more information about the user (like a detailed profile) help personalization?
- Can “memory” tools turn messy user conversations into a clear understanding of the user?
How They Did It (Methods and Approach)
Think of this like building a “test track” for AI research assistants, plus a judging system that watches how well they drive.
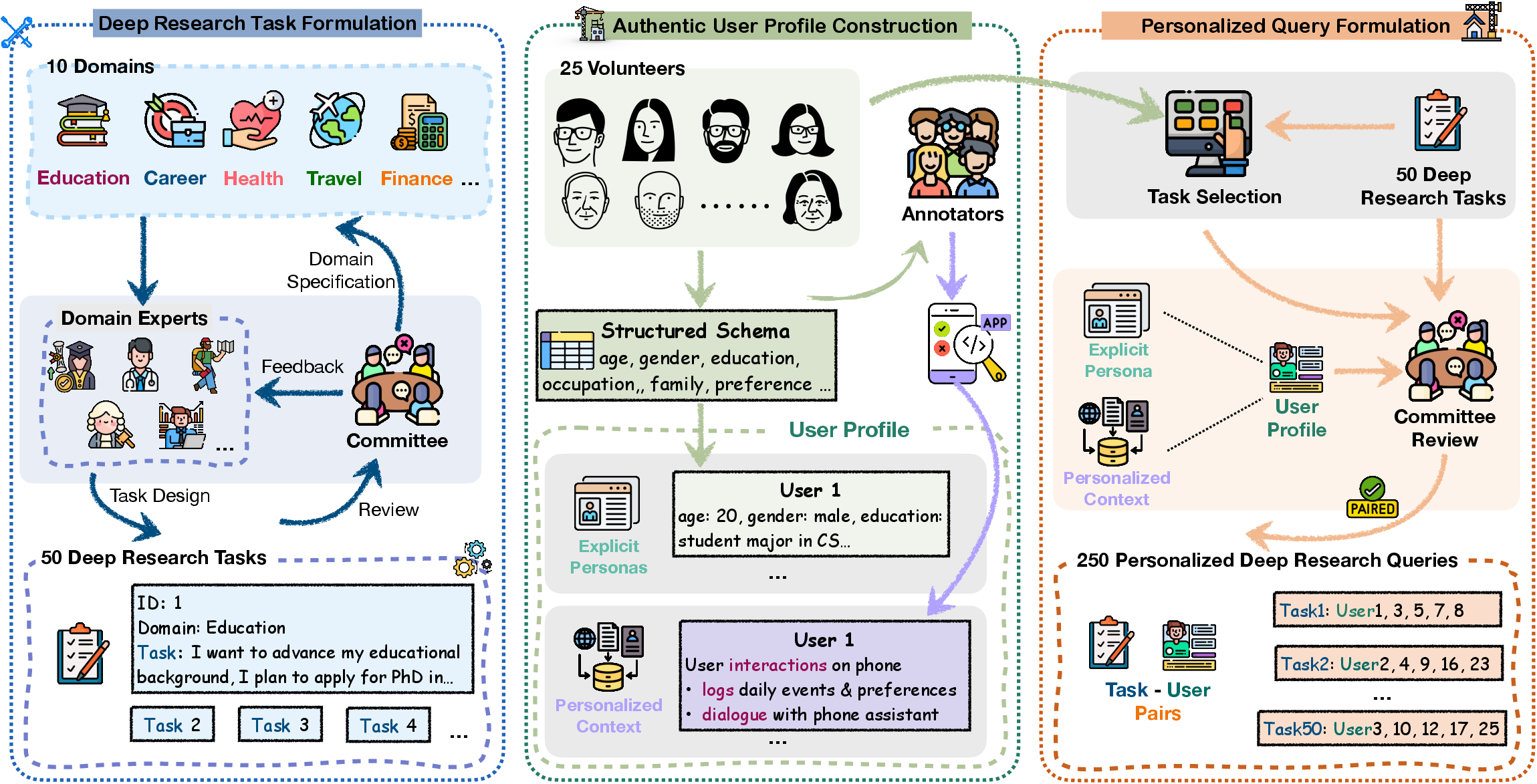
Building the Benchmark (the “test track”)
- The authors designed 50 realistic research tasks across 10 everyday areas (like education, health, finance, travel, careers).
- They collected 25 real user profiles from volunteers. Each profile has:
- Structured details (like age, job, income, goals).
- Dynamic context (notes and chats over time—like a journal—captured by an app to show changing interests).
- They matched tasks to users carefully so each task has 5 relevant users. That makes 250 personalized task-user pairs.
Imagine you’re asking the AI: “Help me choose a college major.” The AI should give different advice to a 17-year-old gamer with a tight budget than to a 25-year-old working adult who loves biology.
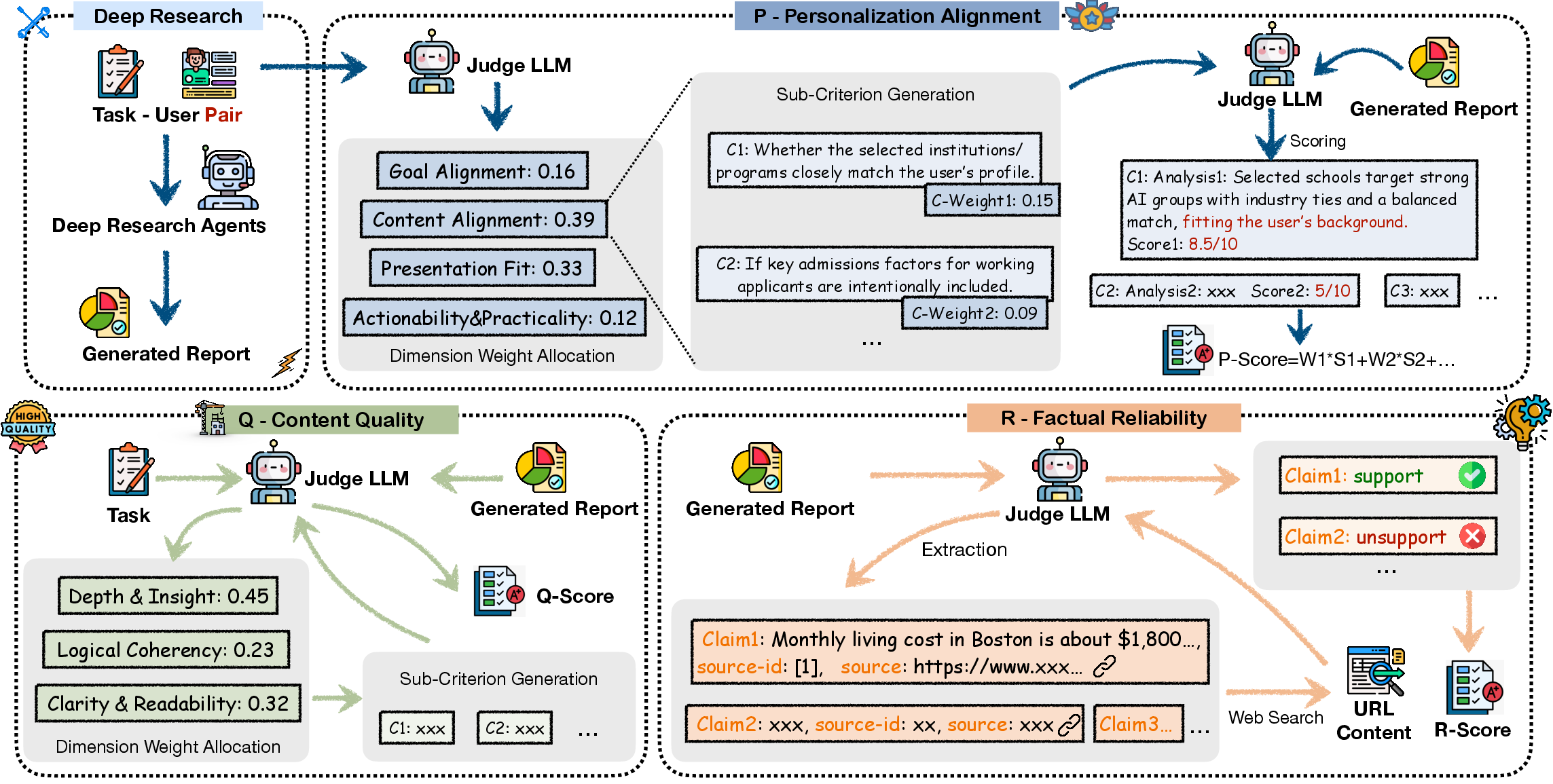
The PQR Evaluation Framework (the “judging system”)
The authors score each AI-generated report on three things:
- Personalization (P): Is the report truly “for me”?
- Quality (Q): Is it well-reasoned, clear, and insightful?
- Reliability (R): Are the facts correct and properly cited?
Here’s what each part means in everyday terms:
- Personalization (P):
- Goal Alignment: Does the report match the user’s goals?
- Content Alignment: Does it include what this user cares about (e.g., budget limits, location)?
- Presentation Fit: Is the style right for the user (simple vs. detailed; charts vs. text)?
- Actionability: Does it give practical, next-step advice the user can actually use?
- Quality (Q):
- Depth and Insight: Does it dig deep and offer smart takeaways, not just surface-level facts?
- Logical Coherence: Does it follow a clear, sensible structure?
- Clarity and Readability: Is it easy to understand?
- Reliability (R):
- The AI extracts factual claims from the report.
- It checks the sources (like articles or pages) to see if those claims are truly supported.
- It measures:
- Factual Accuracy: Are the cited claims actually correct?
- Citation Coverage: How many claims are backed by citations at all?
Think of P as “made for you,” Q as “well-written,” and R as “true and referenced.”
What They Found and Why It Matters
Who Did Best at What
- Open-source agents (community-built systems) were best at personalization. They often wrote reports that fit the user’s goals and style very well.
- However, they were weaker at factual reliability (not as strong at backing claims with sources).
- Commercial agents (from big companies) were strong at reliability and steady in quality.
- They had slightly lower personalization than top open-source agents but were more trustworthy overall (better citations and fact-checking).
- Regular LLMs with just “search tools” performed the worst overall.
- Adding search alone isn’t enough. It doesn’t guarantee the report is personalized or high-quality.
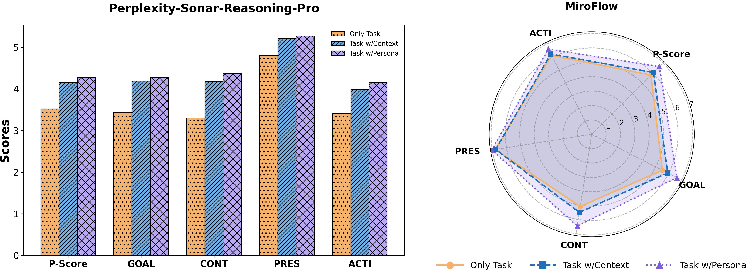
More User Information Helps Personalization
- The more the AI knows about the user, the better it personalizes the report.
- Explicit personas (clear, structured profiles) helped the AI personalize more than raw conversation context.
- Example: A well-organized profile saying “I’m a beginner investor with $500/month to save” is easier to use than messy chat logs.
Can Memory Systems Bridge the Gap?
- They tested “memory” tools that try to turn messy user context into a clear persona the AI can use.
- Some memory systems improved personalization compared to having no memory, but none matched the performance of having an explicit persona.
- This suggests future memory tools need to do a better job of summarizing and reasoning about user data, not just storing it.
Do AI Judges Agree with Humans?
- They compared AI “judges” (LLMs that score reports) with human reviewers.
- GPT-5 had the best agreement with humans among tested judges, which supports using it for scoring personalization and quality.
Why This Research Is Important
- Today’s AI research agents are good at gathering facts. But real people need reports tailored to their goals, budget, preferences, and knowledge.
- This benchmark and scoring system give the community a fair, realistic way to test whether AI can be truly personal and trustworthy.
- It will help developers build better AI assistants that don’t just answer “what’s true,” but also “what’s best for you.”
- In the future, this could improve AI help for big life choices: choosing schools or careers, planning health goals, managing money, and more.
Final Takeaway
The authors created a new, realistic test and a three-part scoring system (PQR) to push AI research agents toward being truly personal, well-written, and factually reliable. Their results show that personalization and reliability often trade off, that explicit user profiles help a lot, and that memory tools have promise but need to improve. This work sets a strong foundation for building AI assistants that act less like generic search engines and more like careful, reliable, and personalized advisors.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
Benchmark design and data coverage
- Limited user diversity and scale: only 25 volunteers; unclear demographic balance and representativeness across cultures, languages, and accessibility needs.
- Simulated “dynamic context” is not user-generated: contexts were created by professional annotators, not the real users, potentially misaligning with authentic longitudinal behavior and introducing annotator bias.
- Task–profile pairing fixed at five users per task: may not reflect natural variability in relevance; lacks analysis of pairing strategy sensitivity and potential selection bias.
- Bilingual parity not validated: an English parallel set exists, but no evidence of cross-lingual equivalence, transferability, or judge parity across languages.
- No longitudinal, session-level evaluation: benchmark focuses on single-report outputs rather than multi-session adaptation, drift, retention, and forgetting over time.
- No group or multi-user personalization: scenarios with shared or conflicting preferences (e.g., family, team decisions) are not modeled or evaluated.
- Domain breadth but unclear stakes modeling: inclusion of higher-risk domains (e.g., healthcare, finance) without a dedicated safety/risk rubric or domain-specific compliance checks.
Personalization problem formulation
- Incomplete treatment of implicit personalization: agents are tested with “context” but evaluation criteria and P-score construction primarily reference explicit persona, not systematically leveraging dynamic context Pc.
- Robustness to imperfect profiles is untested: no experiments on incomplete, contradictory, outdated, or adversarial personas/contexts.
- Overpersonalization and filter-bubble risks unmeasured: no metric for diversity of perspectives or guardrails against narrowing information to existing preferences.
- Preference elicitation is out of scope: the benchmark does not test whether agents actively query users to resolve ambiguity or refine goals.
PQR evaluation framework
- LLM-as-judge stability untested: no sensitivity analysis for different judge models, random seeds, prompts, or weight initialization in dynamic criteria/weights.
- Small-scale human alignment study: only 15 queries; no domain-specific breakdown, inter-annotator agreement, confidence intervals, or significance testing.
- Dynamic weighting transparency: limited analysis of how dimension/sub-criterion weights vary across tasks; no calibration or fairness checks for the meta-evaluator’s weighting behavior.
- Missing user-centric outcome metrics: P-score emphasizes alignment but not real user satisfaction, trust, decision impact, or calibration of actionable recommendations.
- Presentation Fit vs. accessibility: no evaluation of accessibility (e.g., reading level, multilingualism, formatting for disabilities) or empirical reading/comprehension benefits.
Factual reliability (R) methodology
- Uncited claims not verified: framework verifies only claims with provided sources; factuality of uncited claims remains unknown, conflating citation discipline with truthfulness.
- Single-source support assessment: no checks for source diversity, corroboration across independent sources, or robustness to source bias.
- Web volatility unaddressed: no analysis of temporal drift, dead links, paywalls, or retrieval failures via the Jina Reader; reproducibility over time is unclear.
- Hallucination typology missing: no categorization of error types (fabrication, misinterpretation, outdatedness), nor penalties for confidently wrong statements.
- No process-level reliability auditing: evaluation is output-only; agent browsing behavior, source selection rationale, and attribution chains are not assessed.
Experimental scope and analysis
- Partial evaluation subset: only 150/250 queries used due to compute constraints, with no disclosure of selection criteria, representativeness, or sensitivity to the chosen subset.
- Lack of statistical rigor: tables report means without variance, confidence intervals, or significance tests; effect sizes and practical significance remain unclear.
- Cost/latency not measured: no analysis of runtime, token cost, or scalability trade-offs across systems—critical for practical deployment.
- Generalization across agents and versions: memory experiments test a single downstream agent (Perplexity Deep Research) on 50 queries; no cross-agent replication or versioning/temporal robustness.
- Limited ablations: no controlled ablations on the influence of context length/quality, persona granularity, or tool-use strategies on P, Q, and R outcomes.
Memory systems and personalization
- Shallow integration: memory systems are evaluated as pre-processors producing persona-like summaries; no end-to-end study of tightly integrated, continual-learning memory within DRAs.
- No evaluation of long-horizon dynamics: forgetting, conflict resolution, preference drift, and temporal consistency of memories are unmeasured.
- Privacy and consent not tested: how memory systems handle sensitive data, user control (opt-in/out), and data minimization is unaddressed.
- Extraction quality and provenance: no metrics for memory precision/recall, provenance tracking, or error propagation from memory to downstream recommendations.
Safety, fairness, and ethics
- Fairness across user groups unassessed: no disaggregated performance by demographics or life-stage attributes, nor audit for disparate impacts.
- Safety/risk constraints absent: in high-stakes tasks, adherence to regulatory norms, risk disclosure, and safe actionability are not evaluated.
- Data governance gaps: while anonymization is noted, there is no evaluation of re-identification risk, differential privacy options, or secure storage/access protocols.
Reproducibility and release
- Judge and tool dependencies: reliance on proprietary judge models (GPT-5/5-Mini) and Jina Reader may hinder reproducibility; no open-source fallback or model cards for judges.
- Incomplete formal specs: equations in the paper contain formatting errors and missing terms, making precise reimplementation difficult without appendices or code.
- Version drift: no strategy for handling evolving web content, model updates, or benchmark refresh cycles to maintain comparability over time.
Open research questions
- How to co-optimize personalization and reliability without trade-offs (e.g., high P with high R), and what architectures best achieve this?
- What are scalable, validated methods to infer robust personas from noisy, sparse, and evolving context—without compromising privacy?
- Can we design process-aware evaluations that audit agent plans, source selection, and tool-use chains for attribution and accountability?
- How should personalized agents balance user preferences with epistemic diversity, safety constraints, and normative considerations?
- What are principled ground truths for personalization? Can counterfactual personas, preference-elicitation protocols, or human-in-the-loop setups yield reliable labels?
- How to operationalize long-term, life-long personalization benchmarks that measure learning, drift, forgetting, and user trust over months?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s benchmark (Personalized Deep Research Bench) and methodology (PQR framework) to improve current systems, workflows, and products.
- Continuous evaluation and regression testing for AI research assistants (software/platforms)
- Use the PQR framework as a CI/CD gate to track personalization (P), content quality (Q), and factual reliability (R) before release; set minimum FA/CC thresholds for production pushes.
- Tools/workflows: evaluation harness with automated claim extraction, Jina Reader (or internal retriever) for source verification, dashboards for P/Q/R trends, per-domain weight presets.
- Dependencies/assumptions: access to reliable LLM judges; stable retrieval/back-ends; cost controls for judge runs; privacy-safe handling of evaluation data.
- Vendor/model procurement and bake-offs (enterprise IT, consulting, customer support)
- Run head-to-head evaluations on the 250 query set to select DRAs or stacks (e.g., open-source agents for stronger personalization vs commercial systems for reliability).
- Tools/workflows: standardized PQR “request-for-proposal” harness; per-use-case thresholds (e.g., S_R ≥ 8/10 for external-facing content).
- Dependencies/assumptions: comparable prompts/tooling across vendors; reproducible browsing/search settings; auditability of evals.
- Reliability guardrails for high-stakes content (healthcare, finance, legal)
- Enforce minimum Factual Accuracy (FA) and Citation Coverage (CC) before content is delivered; auto-flag low-coverage sections for human review.
- Tools/products: “evidence gate” middleware that blocks publishing when FA/CC fall below thresholds; inline citation validators; claim ledgers for audit.
- Dependencies/assumptions: trustworthy source retrieval; domain-specific policies (e.g., medical/financial disclaimers); human-in-the-loop signoff.
- Persona intake and UX prompts to lift personalization (consumer AI, education, HR)
- Apply the paper’s finding that explicit personas outperform implicit context: add lightweight persona capture flows and targeted clarification questions that map to GOAL/CONT/PRES/ACTI.
- Tools/workflows: dynamic rubric-weighting in UI (e.g., raise PRES for novices); “ask-for-what-matters” prompts; profile forms linked to report generation.
- Dependencies/assumptions: user consent; data minimization and retention policies; clear privacy UX.
- Memory-layer augmentation to turn chat history into actionable personas (software, CRM)
- Integrate Memory OS or comparable systems to summarize long interaction histories into compact, explicit persona fields before invoking DRAs.
- Tools/products: “persona synthesizer” microservice; context distillation step in the agent pipeline; evaluation of gains via P-Score deltas.
- Dependencies/assumptions: quality of memory extraction varies; privacy/security controls; periodic refresh/decay policies.
- Agent routing by task profile (platform/MLOps)
- Route “personalization-heavy” tasks to open-source agents with high P-scores; route “reliability-critical” tasks to commercial agents with higher FA/CC.
- Tools/workflows: meta-controller that predicts task requirements, consults historical PQR performance, and selects the engine accordingly.
- Dependencies/assumptions: calibrated routing models; latency/cost trade-offs; unified interfaces across engines.
- Editorial QA for long-form content (marketing, research, analyst teams)
- Use PQR to quantify depth/insight and coherence, and ensure all factual claims are sourced; reduce hallucinations and improve reader fit.
- Tools/workflows: claim extraction bots; citation gap reports; “presentation fit” checks for target audience level and tone.
- Dependencies/assumptions: accessible citations; editorial adoption; cost/time of automated QA.
- Education assistants tuned to learner profiles (education)
- Personalize research summaries by reading level, prior knowledge, and goals; emphasize actionable study plans with high CC for materials.
- Tools/workflows: student profile forms; per-learner rubric weighting (raise PRES/ACTI for beginners); PQR-backed A/B testing.
- Dependencies/assumptions: age-appropriate materials; accessibility needs; instructor oversight for graded contexts.
- Financial research co-pilots with compliance-first outputs (finance)
- Tailor product comparisons (fees, risk levels, timelines) to user constraints while enforcing strong FA/CC and disclosures.
- Tools/workflows: compliance guardrails; automated insertion of source-linked disclosures; escalation to licensed representatives for advice.
- Dependencies/assumptions: regulatory jurisdiction; timeliness of financial data; separation between education vs advice.
- Patient education and care navigation (healthcare; patient-facing)
- Generate individualized educational materials (conditions, lifestyle constraints) at appropriate reading levels with sourced guidance.
- Tools/workflows: persona mapping from EHR-approved fields (with consent); PQR gating; clinician review queue for flagged items.
- Dependencies/assumptions: strict privacy (HIPAA/GDPR); clinician oversight; labeling as non-diagnostic information.
- Career and job-market research tailored to candidates (HR/career services)
- Align labor-market insights to background, location, and skills; provide action plans (courses, projects) with citations to real postings/trends.
- Tools/workflows: candidate persona ingestion; rubric weights favoring ACTI; source-linked job boards/skills taxonomies.
- Dependencies/assumptions: up-to-date market data; regional compliance; avoidance of demographic bias.
- Customer support troubleshooting tailored to user expertise (support ops)
- Adapt instruction depth and tone, and source steps from KB articles with high CC; improve first-contact resolution.
- Tools/workflows: role/skill personas for users; PQR-scored solution templates; automatic source linking to KB.
- Dependencies/assumptions: accurate device/context detection; robust KB coverage; safe-ops escalation.
- Public information portals personalized to citizen needs (government)
- Produce eligibility and benefits research tailored to household constraints; cite statutes/regulations to raise trust and auditability.
- Tools/workflows: structured intake forms; FA/CC guardrails; accessibility-first presentation.
- Dependencies/assumptions: current policy data; equity/bias audits across demographics; multilingual support.
Long-Term Applications
These applications require further research, scaling, integration, or standardization before widespread deployment.
- PQR-based certification and standards for personalized AI (policy, industry consortia)
- Establish third-party certification programs for consumer and enterprise assistants, with published P/Q/R thresholds per domain risk level.
- Dependencies/assumptions: consensus on rubrics; reproducible eval infrastructure; independence of certifiers.
- Multi-objective training to optimize P, Q, and R jointly (AI R&D)
- Train reward models and RL pipelines directly on PQR rubrics to improve personalization without sacrificing reliability.
- Dependencies/assumptions: high-quality judge signals; cost of preference data; mitigation of overfitting to the benchmark.
- Privacy-preserving, on-device persona modeling (consumer devices, healthcare, finance)
- Maintain local persona graphs updated over time; use federated learning and differential privacy to protect sensitive attributes.
- Dependencies/assumptions: on-device compute; secure enclaves; transparent consent and revocation.
- Advanced memory systems that synthesize “explicit personas” from rich interactions (software, CRM)
- Move from storage to reasoning: convert multi-session, multimodal traces into stable, auditable persona representations with uncertainty tracking.
- Dependencies/assumptions: robust summarization; bias/fairness controls; lifecycle management of stale or conflicting memories.
- Domain-specialized PQR variants and ontologies (healthcare, finance, education, law)
- Extend PQR with domain constraints (e.g., clinical guidelines adherence, risk disclosures, curriculum alignment) and domain ontologies.
- Dependencies/assumptions: expert-curated rubrics; evolving standards; integration with domain data systems (EHRs, market feeds).
- Human-in-the-loop operating procedures standardized by PQR (media, safety-critical sectors)
- Define escalation rules (e.g., CC < threshold triggers review), editor dashboards, and audit logs of claims/sources for governance.
- Dependencies/assumptions: organizational process changes; training; alignment with legal discovery needs.
- Agent marketplaces and routers exposing PQR model cards (platforms)
- Publish P/Q/R profiles per domain-task; enable automatic routing to engines that best meet a user’s need profile and risk class.
- Dependencies/assumptions: standardized reporting; dynamic updates; economic incentives for transparency.
- Multilingual and cross-cultural personalization benchmarking (global markets, public sector)
- Expand the benchmark to more languages and cultural contexts; evaluate fairness and performance parity across demographics.
- Dependencies/assumptions: diverse, representative personas; culturally-aware evaluators; localized sources for FA/CC.
- Interactive persona negotiation and data minimization (consumer AI, enterprise)
- Agents proactively ask targeted, minimal questions that most improve the P-Score dimensions (especially GOAL and PRES) while respecting privacy budgets.
- Dependencies/assumptions: calibrated value-of-information estimates; UX for consent and refusals; privacy accounting.
- Longitudinal outcomes measurement tied to PQR (product analytics, academia)
- Link PQR improvements to real-world outcomes (decision quality, time saved, satisfaction) via controlled studies and A/B tests.
- Dependencies/assumptions: instrumentation; consistent tasks; ethical experimentation.
- Sector-specific copilots with deep system integrations (healthcare, finance, education, engineering)
- Examples: EHR-integrated patient research copilot, wealth-management research copilot, teacher lesson-planning researcher, RFP/standards research for engineering teams.
- Dependencies/assumptions: secure data access; regulatory approvals; data lineage and audit trails for FA/CC.
- Trust and integrity pipelines for citations (media, science)
- Introduce cryptographic provenance, content hashing, and watermarking to defend against tampered sources; surface source quality scores.
- Dependencies/assumptions: adoption of content authenticity standards; robust anti-spoofing; cooperation from publishers.
- Safety-aware personalization and manipulation resistance (policy, platforms)
- Detect and mitigate unsafe or exploitative tailoring; enforce ethical constraints in ACTI/PRES dimensions for vulnerable users.
- Dependencies/assumptions: safety taxonomies; red-teaming; oversight and appeals processes.
Notes on cross-cutting assumptions and dependencies
- LLM-as-judge reliability: The paper reports moderate human alignment; production usage benefits from supplemental human review and periodic calibration.
- Data privacy and consent: Persona capture, memory synthesis, and evaluation traces must comply with privacy laws (e.g., GDPR/HIPAA) and internal policies.
- Reproducibility: Open, stable browsing/search settings and source access (e.g., paywalled content) affect FA/CC; organizations may need mirrored corpora.
- Cost and latency: Running PQR evaluations at scale requires budgeting and optimization (e.g., cheaper judges for R, sampling strategies).
- Benchmark scope: The current 25-profile/50-task set is a strong starting point but should be extended to cover more domains, languages, and demographics for broad claims.
Glossary
- Actionability (ACTI): A personalization dimension evaluating whether recommendations are practical and tailored to the user’s situation. "The framework is built on four fundamental dimensions: Goal Alignment (GOAL), Content Alignment (CONT), Presentation Fit (PRES) and Actionability {paper_content} Practicality (ACTI)."
- Agent-as-a-Judge: An evaluation approach where an agent (or LLM) automatically judges outputs for correctness and attribution. "proposes the Agent-as-a-Judge framework for automated correctness and attribution."
- automated factual grounding framework: A pipeline that verifies claims in a report by retrieving and checking supporting sources automatically. "We assess report reliability via an automated factual grounding framework, inspired by ResearcherBench and DeepResearch Bench"
- Citation Coverage (CC): The proportion of factual claims in a report that include explicit citations. "Citation Coverage (CC) Assesses the proportion of factual claims in a report that are supported by explicit citations, reflecting how well the content is evidence-based."
- Claim Extraction and Deduplication: A verification stage that extracts verifiable claims and removes duplicates before checking support. "Claim Extraction and Deduplication."
- committee-guided alignment protocol: A curation process where a committee aligns users with tasks to ensure relevance and diversity. "we employed a user-driven, committee-guided alignment protocol."
- Content Alignment (CONT): A personalization dimension measuring how well content matches the user’s profile, needs, and context. "Goal Alignment (GOAL), Content Alignment (CONT), Presentation Fit (PRES) and Actionability {paper_content} Practicality (ACTI)."
- Deep Research Agents (DRAs): Advanced AI agents that plan, search, and synthesize information to produce comprehensive research outputs. "Deep Research Agents (DRAs) can autonomously conduct complex investigations and generate comprehensive reports, demonstrating strong real-world potential."
- Depth {paper_content} Insight (DEIN): A quality dimension assessing the depth of analysis and insightfulness of the report. "We define three dimensions: Depth {paper_content} Insight (DEIN), Logical Coherence (LOGC), and Clarity {paper_content} Readability (CLAR) (see Appendix \ref{dimensions-definitions})."
- Dynamic Dimension Weight Allocation: A step where an LLM assigns custom weights to personalization dimensions per user–task pair. "Stage 1: Dynamic Dimension Weight Allocation."
- dynamic personalized contexts: Evolving user information derived from interactions and memories used to tailor research. "to generate dynamic personalized contexts"
- Factual Accuracy (FA): The fraction of cited claims that are verified as true by their sources. "Factual Accuracy (FA) Measures the reliability of provided citations."
- Factual Reliability: A combined metric (typically averaging FA and CC) reflecting the truthfulness and evidence basis of a report. "Finally, we average FA and CC to derive a single Factual Reliability score, :"
- generalized mean: An aggregation method used to combine P, Q, and R scores into an overall score with configurable weights. "we define the overall score as a generalized mean over the three scores:"
- Goal Alignment (GOAL): A personalization dimension evaluating whether the report’s objectives align with the user’s goals. "The framework is built on four fundamental dimensions: Goal Alignment (GOAL), Content Alignment (CONT), Presentation Fit (PRES) and Actionability {paper_content} Practicality (ACTI)."
- Granular Sub-Criterion Generation: A step that creates task- and user-specific sub-criteria for fine-grained scoring. "Stage 2: Granular Sub-Criterion Generation."
- Jina Reader API: An external service used to fetch source content for verifying claims. "we use the Jina Reader API to retrieve the source content"
- Judge LLM: A LLM designated to extract claims and verify their support from sources. "A Judge LLM is employed to extract all verifiable factual claims with their sources"
- Logical Coherence (LOGC): A quality dimension measuring the consistency and soundness of argumentation and structure. "We define three dimensions: Depth {paper_content} Insight (DEIN), Logical Coherence (LOGC), and Clarity {paper_content} Readability (CLAR)"
- LLM meta-evaluator: An LLM that sets up the evaluation by determining dimension weights and generating criteria. "An LLM, acting as a meta-evaluator, analyzes the input task and user persona to determine the relative importance of the four dimensions."
- LLM-Powered Scoring: The stage where an LLM assigns scores to each sub-criterion with justifications. "Stage 3: LLM-Powered Scoring."
- Mean Absolute Rating Deviation (MARD): A metric quantifying the average absolute difference between LLM and human scores. "Mean Absolute Rating Deviation (MARD) measures the average absolute difference between the scores assigned by the LLM and human judges."
- Pairwise Comparison Agreement (PCA): A metric capturing how often the LLM judge and humans agree on which of two reports is better. "Pairwise Comparison Agreement (PCA) measures the percentage of the LLM judge and human experts agree on which of the two reports is better for a specific criterion."
- Personalization Alignment (P-Score): A score measuring how well a report is tailored to a specific user profile and task. "we introduce Personalization Alignment (P-Score), a dynamic evaluation framework"
- Personalized Deep Research Bench: A benchmark pairing real user profiles with tasks to test personalized deep research. "we introduce Personalized Deep Research Bench, the first benchmark for evaluating personalization in DRAs."
- persona schema: A structured template for collecting explicit user attributes that define a persona. "onto a specially designed persona schema, "
- Presentation Fit (PRES): A personalization dimension evaluating formatting, organization, and style preferences for the user. "Goal Alignment (GOAL), Content Alignment (CONT), Presentation Fit (PRES) and Actionability {paper_content} Practicality (ACTI)."
- PQR Evaluation Framework: A three-axis evaluation system measuring Personalization, Quality, and Reliability of research outputs. "we propose the PQR Evaluation Framework, which jointly measures (P) Personalization Alignment, (Q) Content Quality, and (R) Factual Reliability."
- Q-Score: The aggregated score for content quality based on depth, logic, and clarity sub-criteria. "The final Q-Score is a hierarchical weighted average:"
Collections
Sign up for free to add this paper to one or more collections.

