- The paper introduces ResearcherBench, a benchmark that evaluates Deep AI Research Systems on frontier scientific questions using rubric and factual assessments.
- It details a three-step framework: dataset collection from real research scenarios, rubric assessment for insight quality, and factual assessment for citation accuracy.
- Findings highlight superior performance in open consulting queries by systems like OpenAI Deep Research and Gemini Deep Research, setting new standards for AI research evaluation.
ResearcherBench: Evaluating Deep AI Research Systems on the Frontiers of Scientific Inquiry
Introduction
"ResearcherBench: Evaluating Deep AI Research Systems on the Frontiers of Scientific Inquiry" explores the evaluation of Deep AI Research Systems (DARS) using a novel benchmark designed to assess their capability to address frontier scientific questions. While existing benchmarks focus on evaluating AI as agents for web retrieval and report generation, "ResearcherBench" specifically targets the assessment of DARS on frontier AI scientific questions.
The paper presents a dataset of 65 research questions harnessed from scenarios including laboratory discussions and interviews, spanning 35 AI subjects. The evaluation framework combines rubric assessment, focusing on insight quality, with factual assessment, measuring citation accuracy (faithfulness) and coverage (groundedness). The study found that OpenAI Deep Research and Gemini Deep Research systems perform well in open-ended consulting questions, representing a significant step toward AI self-improvement.
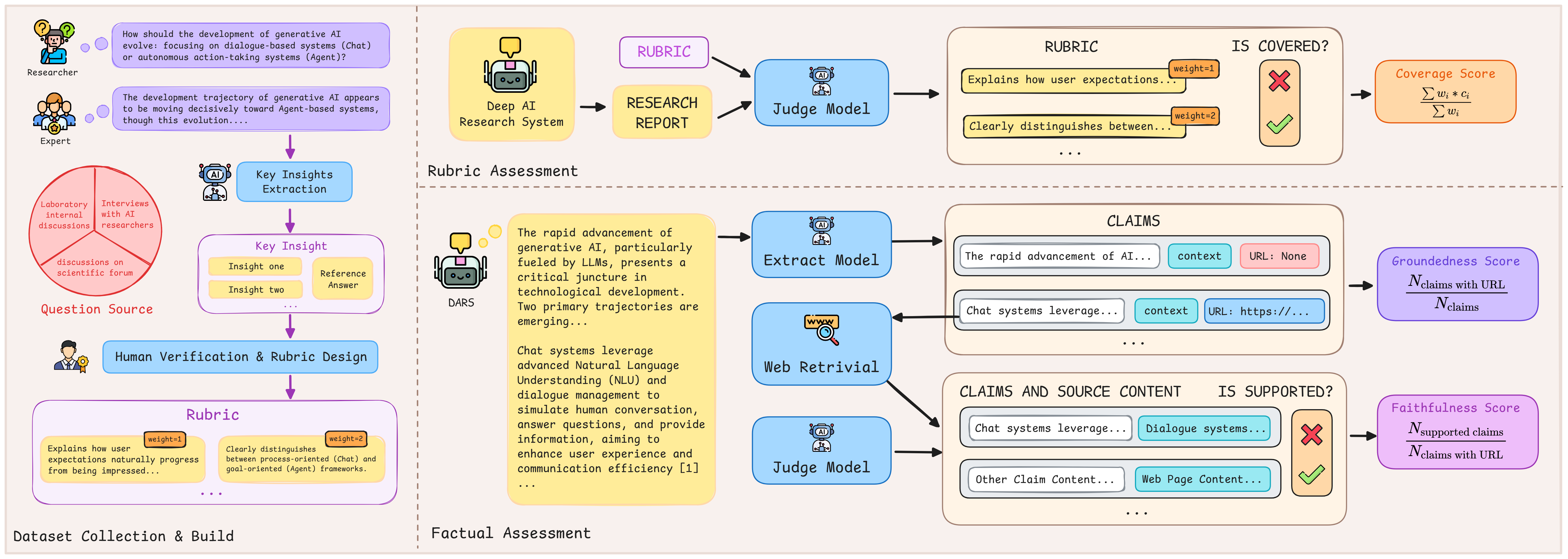
Figure 1: ResearcherBench Framework Overview. The framework consists of three main components from top to bottom: (1) Dataset collection from authentic research scenarios leading to expert-generated rubrics, (2) Rubric assessment to evaluate coverage against rubrics, and (3) Factual assessment to measure faithfulness and groundedness scores.
ResearcherBench Framework
The ResearcherBench framework involves three primary steps: dataset collection, rubric assessment, and factual assessment.
Experimental Evaluation
The study evaluated several leading commercial DARS platforms, such as OpenAI Deep Research, Gemini Deep Research, and others, using the dual evaluation framework. The results showed that systems excel at open consulting questions but varied in performance across technical details and literature review tasks. Notably, OpenAI Deep Research achieved the best performance in rubric assessment, while Gemini Deep Research exhibited a balanced performance in citation strategy optimization.
Key findings include the limited correlation between groundedness scores and research quality, and the superior performance of DARS over LLMs with basic web search capabilities on frontier research tasks.
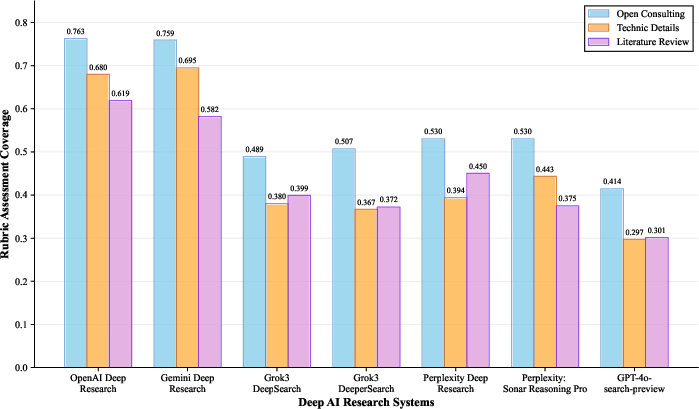
Figure 3: Performance Analysis by Question Type (Rubric Assessment Coverage). Performance comparison across different question types for Deep AI Research Systems. Each system shows varying strengths across open consulting, technical details, and literature review categories.
Implications and Future Directions
The ResearcherBench initiative provides a standardized platform for advancing AI research assistant development. The findings suggest a shift towards AI as genuine research partners, capable of exploring novel insights and conducting complex scientific inquiries. The implications extend to potential collaborations where AI systems contribute meaningfully to scientific advancements and foster accelerated AI self-improvement aligned with Artificial Superintelligence (ASI) aspirations.
Future work could involve expanding the benchmark to additional scientific domains, enabling cross-domain evaluation of DARS capabilities. Continuous updates to the benchmark, incorporating emerging scientific questions, could further maintain its relevance as frontier research evolves.
Conclusion
ResearcherBench emerges as a pivotal tool in the evaluation of DARS, emphasizing not only the ability to retrieve information but to deeply engage with and provide insights on frontier scientific queries. By promoting the development of next-generation AI research assistants, ResearcherBench lays foundational work for progressing towards AI systems that are valued partners in the scientific discovery process.