How Far Are We from Genuinely Useful Deep Research Agents?
Abstract: Deep Research Agents (DRAs) aim to automatically produce analyst-level reports through iterative information retrieval and synthesis. However, most existing DRAs were validated on question-answering benchmarks, while research on generating comprehensive reports remains overlooked. Worse, current benchmarks for report synthesis suffer from task complexity and subjective metrics -- this fails to reflect user demands and limits the practical utility of generated reports. To address these gaps, we present Fine-grained DEepResearch bench (FINDER), an enhanced benchmark consisting of 100 human-curated research tasks with 419 structured checklist items that standardize report structure, analytical depth, and factual grounding. Based on approximately 1,000 reports produced by mainstream DRAs, we further propose Deep rEsearch Failure Taxonomy (DEFT), the first failure taxonomy for deep research agents. DEFT contains 14 fine-grained failure modes across reasoning, retrieval, and generation, and is built upon grounded theory with human-LLM co-annotating and inter-annotator reliability validation. Our experimental findings reveal that current DRAs struggle not with task comprehension but with evidence integration, verification, and reasoning-resilient planning.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at “Deep Research Agents” (DRAs) — AI systems that browse the web, collect information, and write long, organized research reports (like a detailed school project). The authors ask a simple question: How close are these AIs to being truly useful in real-world research?
To answer that, they build two things:
- Finder: a tougher, clearer test with checklists that tell the AI exactly what a good report should include.
- DEFT: a “map of mistakes” that shows the common ways these AIs mess up when doing research.
What questions the paper tries to answer
The authors focus on three easy-to-understand questions:
- Can current AIs write reliable, well-structured research reports, not just short answers?
- What specific kinds of mistakes do these AIs make when they search, think, and write?
- How can we fairly test and compare different AIs on real research tasks?
How they did the research (in simple terms)
Think of this like testing students with a fair exam and a detailed grading rubric:
- Finder (the exam and rubric):
- They made 100 real research tasks (like “compare two technologies and include sources”).
- For each task, they wrote detailed checklists (419 items total) saying what the report should contain: structure, depth, and correct citations.
- This makes grading fair and repeatable, not just based on someone’s opinion.
- DEFT (the map of mistakes):
- They collected about 1,000 reports written by different DRAs (both popular paid ones and open-source ones).
- Humans and AIs worked together to read these reports and label the mistakes.
- Using a careful method (called grounded theory), they grouped mistakes into 14 types, organized under three stages of the process:
- Reasoning (planning and understanding the task)
- Retrieval (finding and checking information)
- Generation (writing the final report)
- They also turned mistake counts into simple scores: fewer mistakes = higher score.
- They checked fairness:
- Multiple experts reviewed the labels to make sure people agreed on what counts as a mistake.
What they found and why it matters
Here are the most important results:
- The biggest problems aren’t about understanding the question — they’re about using evidence well.
- Many AIs struggle to combine sources, cross-check facts, and plan in a way that survives confusing or conflicting information.
- The worst failures happen during writing (the “Generation” stage).
- A common big mistake is “strategic content fabrication”: the AI writes something that sounds smart and professional but isn’t supported by real evidence (basically, confident-sounding made-up stuff).
- This is a serious trust problem: the report looks good but isn’t reliable.
- Retrieval problems are also common.
- AIs often don’t gather enough information, don’t connect the dots between sources, or fail to verify important claims.
- Some systems look strong on general benchmarks but slip on this deeper, report-focused test.
- For example, some score well on short-answer tasks but struggle to write accurate, well-cited long reports.
- Not all models fail the same way.
- Some are good at understanding and planning but weaker at writing solid, evidence-backed text.
- Others follow instructions and structure well but still include false “facts”.
Why this matters: In real life, a report you can’t trust is worse than a short answer you can check. For businesses, academics, and anyone doing serious research, reliability and verification matter more than sounding smart.
What this means for the future
The paper’s message is hopeful but firm: to make deep research AIs truly useful, we must focus on:
- Evidence-first thinking: Always verify important claims with strong, traceable sources.
- Reasoning resilience: Plans should adapt when new facts appear or when sources disagree.
- Safer writing: Add stronger checks during the writing stage to block made-up references and fake details.
- Better evaluation tools: Use benchmarks like Finder and taxonomies like DEFT so we can measure real progress, not just flashy demos.
In short, the next big leap isn’t making AIs write longer reports — it’s making them write reports you can trust. Finder and DEFT give the community the tools to spot weaknesses and build better, more reliable research agents.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future work:
- Benchmark representativeness: The 100-task Finder benchmark lacks a documented domain distribution and difficulty stratification; quantify coverage (e.g., enterprise, biomedical, finance, policy) and calibrate task complexity tiers to ensure generalizability.
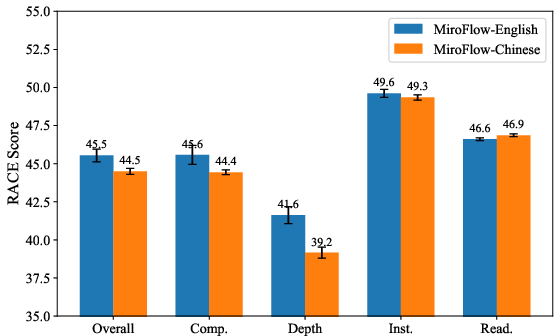
- Language coverage: Evaluation is limited to English and Chinese; assess cross-lingual performance across morphologically diverse languages (e.g., Arabic, Hindi, Japanese) and quantify language-specific failure mode shifts.
- Dynamic web reproducibility: The paper does not specify how time-varying web content is controlled; introduce snapshotting/archival and sandboxed search to isolate model differences from web drift.
- Reference bias in RACE: RACE scores are anchored to a single Gemini-generated reference report; validate fairness with multi-reference sets (human and diverse-model references) and quantify “style proximity” bias.
- LLM-judge circularity: Gemini 2.5 Flash both refines checklists and judges checklist compliance; measure and mitigate judge–subject coupling by using independent LLM judges and human adjudication panels.
- Incomplete FACT reporting: Missing FACT results for several systems limit comparability; implement a unified logging and citation-parsing protocol so all agents can be scored consistently.
- Positive Taxonomy Metric validity: The cosine-based scoring treats all errors equally and is dataset-size dependent; calibrate category weights by harm/severity, sensitivity to report length, and validate against human utility ratings.
- Taxonomy saturation and breadth: Selective coding claims saturation from only 36 records and two agents; expand coding across more agents, domains, languages, and toolchains to stress-test category stability.
- Causal validation of failure pathways: Correlation analysis is observational; run controlled interventions (e.g., ablate retrieval, enforce verification) to test whether reducing specific failures causally reduces downstream modes (e.g., SCF).
- Mitigation efficacy: The paper offers “insights” but no tested interventions; implement and evaluate anti-fabrication guards, mandatory cross-source verification, adaptive planning policies, and structured synthesis templates on Finder.
- User-centered utility: Claims of aligning with user demands lack human studies; conduct analyst-in-the-loop evaluations (task usefulness, decision impact, time saved, trust) and compare with RACE/FACT/DEFT scores.
- Efficiency and cost: No analysis of compute budgets, latency, tool-call counts, or cost–quality trade-offs; benchmark agents under fixed budgets and report cost-performance curves.
- Tool/environment comparability: Proprietary agents use undisclosed pipelines while open agents rely on varying toolsets; enforce a common evaluation environment (browser, search engine, scraping limits) or report per-environment stratified results.
- Checklist design scalability: Checklist authoring/refinement is expert+LLM mediated without cost or reliability metrics; quantify creation cost, inter-rater agreement, item discriminativeness, and automate checklist generation with quality guarantees.
- Evidence verification depth: FACT checks citation accuracy/effectiveness but not cross-source triangulation or conflict resolution; add tasks requiring reconciliation of contradictory sources and measure verification rigor.
- Fabrication detection and penalties: Strategic Content Fabrication (SCF) is the top failure but detection is not operationalized; build and evaluate automatic SCF detectors (precision/recall), and incorporate severity-weighted penalties in scoring.
- Reasoning resilience operationalization: The concept is introduced but unmeasured; define resilience metrics (e.g., recovery from feedback/noise, plan adaptation rate) and create evolving-requirement tasks to quantify it.
- Multimodal research: Many real reports require PDFs, tables, figures, and datasets; extend Finder to multimodal retrieval/synthesis and evaluate modality-specific failure modes.
- Cross-lingual failure profiling: Failure proportions are aggregated; report per-language distributions and analyze language-specific taxonomy differences (e.g., SCF vs. SOD prevalence).
- Release completeness and licensing: Clarify availability of full reports, annotations, checklists, and proprietary outputs (licensing constraints); ensure reproducible artifacts for independent re-evaluation.
- Taxonomy bias from LLM coders: Using LLMs as coders may imprint model biases; replicate taxonomy construction with human-only coders and cross-cultural expert panels to assess stability.
- Failure severity rubric: Different failures have unequal impact on user decisions; create and validate a severity rubric, integrate it into DEFT and the Positive Taxonomy Metric, and report severity-weighted scores.
- Safety, privacy, and compliance: Enterprise use-cases require privacy/compliance assessments; add tasks and metrics for data leakage, citation of sensitive sources, and adherence to regulatory constraints.
- Personalization: Finder is not personalized; evaluate agents’ ability to tailor reports to user preferences (depth, tone, format) and develop personalized checklists with preference-weighted scoring.
- Long-horizon iteration: Evaluation is single-pass; test multi-episode research workflows (draft–review–revise), memory utilization, and error correction over extended horizons.
- Robustness to misinformation: No robustness tests against adversarial SEO, low-quality sources, or coordinated misinformation; add stress tests and measure retrieval/verification resilience.
- Scaling with task complexity: Report-level analyses do not quantify how failure rates change with task length/complexity; design controlled complexity ladders and report scaling curves.
Practical Applications
Overview
The paper introduces two practical contributions for evaluating and improving Deep Research Agents (DRAs):
- Finder: a fine-grained benchmark with 100 expert-curated tasks and 419 structured checklist items that measure report quality, structure, evidence use, and instruction adherence.
- DEFT: a grounded failure taxonomy with 14 fine-grained failure modes across reasoning, retrieval, and generation, supported by inter-coder reliability and a positive performance metric.
Below are actionable applications derived from these contributions, grouped by immediacy and linked to relevant sectors. Each item notes potential tools/workflows and key assumptions or dependencies.
Immediate Applications
These applications can be deployed now, leveraging the publicly released benchmark, taxonomy, and evaluation procedures.
- DRA quality assurance pipelines for enterprises
- Sectors: software (SaaS research platforms), business intelligence, consulting, competitive analysis, pharma CI, journalism
- Tools/products/workflows: DEFT-based failure detectors (e.g., SCF detector for “strategic content fabrication”), Finder checklist adherence scoring, citation validators, dashboard with Reasoning/Retrieval/Generation positive scores, automated red/amber/green gating for reports
- Assumptions/dependencies: access to an LLM judge or evaluation model, integration with existing agent frameworks, domain-specific checklist customization, reproducible prompts, audit logging
- Vendor evaluation and procurement due diligence for DRA solutions
- Sectors: enterprise IT, MLOps, procurement
- Tools/products/workflows: standardized evaluation harness combining RACE/FACT + DEFT + Checklist Pass Rate; side-by-side comparisons; procurement scorecards
- Assumptions/dependencies: stable APIs/models during evaluation; compute budget; willingness of vendors to be benchmarked; dataset relevance to target use cases
- Agent workflow redesign to close retrieval and verification loops
- Sectors: software (agent frameworks), search/retrieval tooling
- Tools/products/workflows: mandatory “retrieve→process→integrate→represent→verify” loop; cross-source fact checks; explicit evidence graphs; hard constraints on citing and grounding
- Assumptions/dependencies: access to web/search APIs; reliable citation validation; support for iterative planning and re-checks; configurable guardrails
- Guardrails for generation to reduce confident fabrication (SCF)
- Sectors: healthcare (non-clinical research), finance (market analysis), legal (secondary research), journalism
- Tools/products/workflows: generation constraints (style/structure templates, schema validators), post-generation verification hooks (e.g., unsupported claim filters), “Evidence Meter” UI showing evidence coverage and verification status
- Assumptions/dependencies: high-recall retrieval; domain-appropriate templates; acceptance of stricter output formats by users
- Training curricula for model developers using DEFT failure modes
- Sectors: AI development (academia and industry)
- Tools/products/workflows: curated datasets targeting evidence integration and verification; failure-aware RLHF/RLAIF objectives; adversarial task sets focusing on SCF and IIA (insufficient external information acquisition)
- Assumptions/dependencies: labeled data reflecting DEFT categories; annotation resources; alignment between training and deployment domains
- Compliance and risk auditing of AI-generated reports
- Sectors: finance (research compliance), healthcare (policy briefs), legal (internal memos), public sector (policy analysis)
- Tools/products/workflows: DEFT-to-compliance mapping (e.g., SCF ↔ misrepresentation risk); audit trails; minimum Checklist Pass Rate thresholds before publication; exception workflows
- Assumptions/dependencies: human-in-the-loop review; prioritization of auditability; privacy-preserving retrieval; organizational policies
- Academic integrity checks for research assistive tools
- Sectors: academia, scholarly publishing
- Tools/products/workflows: pre-submission checks for citation grounding and methodological rigor; journal editorial triage using DEFT categories (e.g., DAR—deficient analytical rigor)
- Assumptions/dependencies: integration with editorial systems; domain-specific citation validation; acceptance by institutions
- Teaching aids for research methods courses
- Sectors: education (higher ed, professional training)
- Tools/products/workflows: classroom rubrics mirroring Finder checklists; practice assignments diagnosing LAD (lack of analytical depth) vs LAS (limited scope); feedback assistants highlighting verification gaps
- Assumptions/dependencies: adapting tasks to curriculum; educator buy-in; reduced reliance on subjective grading
- Public leaderboards and competitions for DRAs
- Sectors: AI community, benchmarking platforms
- Tools/products/workflows: hosted evaluation using Finder + DEFT; periodic rounds with dynamic tasks; prizes for improvements in retrieval/generation resilience
- Assumptions/dependencies: infrastructure for evaluation; community engagement; governance for submissions
- Personal research hygiene for daily life decisions
- Sectors: consumer information (e.g., evaluating products, travel planning, health information)
- Tools/products/workflows: browser extensions flagging unsupported claims; simple checklists for verifying claims and citing sources; “report quality” badges
- Assumptions/dependencies: accessible extension APIs; lightweight verification; user education on interpreting scores
- Continuous monitoring in production (Agentic MLOps)
- Sectors: software/platform operations
- Tools/products/workflows: post-deployment DEFT telemetry; alerting when failure mode rates exceed thresholds; A/B tests of retrieval strategies; regression detection when model updates increase SCF/VMF
- Assumptions/dependencies: observability stack; routing for remediation; cost budget for periodic evaluations
Long-Term Applications
These applications require further research, scaling, consensus-building, or integration in sensitive domains.
- Sector-specific Finder variants and checklists (e.g., clinical, regulatory-grade finance)
- Sectors: healthcare, finance, energy policy, public administration
- Tools/products/workflows: domain-tailored tasks, evidence standards, citation policies; specialized verification modules (e.g., clinical guideline cross-checks)
- Assumptions/dependencies: extensive SME involvement; regulatory alignment; data access to authoritative sources; robust provenance tracking
- Industry standards and certification for DRA quality
- Sectors: policy, standards bodies (ISO/IEEE), regulated industries
- Tools/products/workflows: DEFT-based conformance profiles; minimum acceptable Checklist Pass Rates; standardized reporting schemas; pre-deployment certification
- Assumptions/dependencies: multi-stakeholder consensus; governance mechanisms; legal acceptance; interoperability with compliance tooling
- Self-correcting agents using failure-mode feedback
- Sectors: software (advanced agents), research automation
- Tools/products/workflows: meta-controllers that detect DEFT failures and adapt planning (improving “reasoning resilience”); dynamic re-retrieval and re-verification; automatic repair of SCF via targeted fact checks
- Assumptions/dependencies: reliable in-situ detection; robust planning adaptation; latency and cost controls; strong retrieval backends
- Provenance and cryptographic attestation for evidence chains
- Sectors: healthcare (clinical evidence summaries), journalism, public policy
- Tools/products/workflows: signed citations; tamper-evident provenance ledgers; evidence graphs linked to verifiable identifiers; chain-of-custody for facts
- Assumptions/dependencies: infrastructure for signing and verification; adoption by publishers and data providers; interoperability with KGs
- Liability and insurance products based on DEFT risk scores
- Sectors: insurance, legal, finance
- Tools/products/workflows: underwriting models pricing risk of AI-generated analyses; contractual SLAs keyed to SCF/VMF rates; warranties tied to verified evidence coverage
- Assumptions/dependencies: actuarial data on error impacts; regulatory clarity; standardized scoring practices; auditability
- Regulatory sandboxes for AI research agents
- Sectors: public sector, regulators
- Tools/products/workflows: sandbox protocols requiring DEFT/Finder evaluation prior to pilot deployments; public reporting on failure profiles; controlled data access for testing
- Assumptions/dependencies: regulator engagement; ethical review; privacy-preserving benchmarks; stakeholder transparency
- Multilingual and culturally-aware Finder expansions
- Sectors: global enterprises, international research
- Tools/products/workflows: tasks and checklists across languages; culturally relevant sources; cross-lingual verification strategies
- Assumptions/dependencies: multilingual SME curation; high-quality translation; diverse source coverage; LLM performance parity
- Evidence-aware user interfaces and interactive checklists
- Sectors: SaaS platforms, productivity tools
- Tools/products/workflows: adaptive UIs guiding users through verification steps; interactive “evidence gaps” prompts; progressive disclosure of sources and confidence
- Assumptions/dependencies: UX research; integration with retrieval services; user willingness to follow structured workflows
- Scholarly publishing pipelines with automated AI screening
- Sectors: academic journals, preprint servers
- Tools/products/workflows: pre-submission DEFT screeners; automatic flagging of DAR (methodological flaws) and CSD (spec deviations); reviewer aids showing evidence maps
- Assumptions/dependencies: editorial policy changes; domain-specific validators; minimal false positives; researcher acceptance
- Marketplace quality ratings and reputation systems for AI research outputs
- Sectors: B2B/B2C AI content marketplaces
- Tools/products/workflows: public quality scores based on DEFT + Finder; reputation accrual for models and vendors; consumer alerts for high-risk outputs
- Assumptions/dependencies: transparent scoring governance; anti-gaming safeguards; broad ecosystem adoption
- Cost-aware, parallel retrieval and verification at scale
- Sectors: large enterprises, cloud AI platforms
- Tools/products/workflows: DAG-based parallel retrieval (e.g., Flash-Searcher-style) combined with verification pipelines; dynamic compute allocation tied to failure risk
- Assumptions/dependencies: scalable infra; smart orchestration; budget controls; robust failure prediction
Notes on Cross-Cutting Assumptions and Dependencies
- LLM judge reliability: many applications depend on consistent, unbiased evaluation. Ongoing calibration and human-in-the-loop validation are advisable.
- Domain adaptation: Finder and DEFT provide general structures; effectiveness increases with sector-specific checklists and source policies.
- Source availability and quality: robust retrieval and verification depend on access to authoritative, up-to-date, and licensable data.
- Cost and latency: deeper verification loops and iterative planning increase compute; productization requires careful trade-off management.
- User acceptance: stricter templates and verification steps can affect usability; UI/UX needs to balance rigor with productivity.
- Governance and compliance: successful adoption in regulated sectors requires alignment with legal and ethical frameworks.
- Benchmark maintenance: tasks and checklists must evolve with time-varying contexts; continuous updates prevent overfitting and drift.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a short definition and a verbatim usage example.
- Agent Framework: A system architecture that orchestrates models, tools, and workflows to enable agent behaviors and evaluations. "Agent Framework encompass OWL, OpenManus, and MiroFlow, where MiroFlow is evaluated in both English and Chinese versions to examine cross-lingual performance within a unified framework."
- Agent-as-Judge: An evaluation paradigm where an agent automatically judges outputs for verification and attribution. "Mind2Web 2 \citep{gou2025mind2web} comprises 130 time-varying daily life tasks and proposes an ``Agent-as-Judge'' framework to achieve automated verification and attribution."
- Agentic orchestration: The explicit coordination of agent steps, tools, or sub-processes to enforce disciplined reasoning and output quality. "MiroFlow demonstrates the specific advantage of explicit agentic orchestration, proprietary models like Kimi and Gemini remain robust, outperforming O3 (57.52) and other baselines."
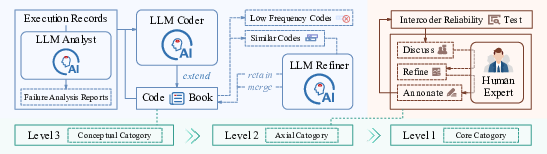
- Axial Category: A structured grouping formed during axial coding that organizes related concepts through defined relationships. "Through merging, splitting, removing, or modifying these relationships, it forms axial categories."
- Axial Coding: A grounded-theory stage that links concepts by analyzing their relationships (semantics, causality, function, structure) to form categories. "Axial coding employs both deductive and inductive reasoning to explore relationships among concepts based on semantics, context, process, causality, function, structure, and strategy."
- Checklist Accuracy: A metric assessing how well an agent’s report satisfies explicit checklist items that encode task requirements. "We evaluate model performance across three dimensions: RACE and FACT, Positive Taxonomy Metrics, and the Checklist Accuracy."
- Checklist Pass Rate: The proportion of checklist items satisfied by a generated report. "The final column reports the Checklist Pass Rate."
- Codebook: A dynamically updated inventory of concept names and descriptions used to manage and refine codes during grounded-theory analysis. "we adopted the core principle of constant comparative analysis from grounded theory and maintained a dynamically updated conceptual inventory, hereafter referred to as the codebook~(), defined as:"
- Constant comparative analysis: A grounded-theory method that compares new codes against existing ones to refine categories and ensure consistency. "we adopted the core principle of constant comparative analysis from grounded theory"
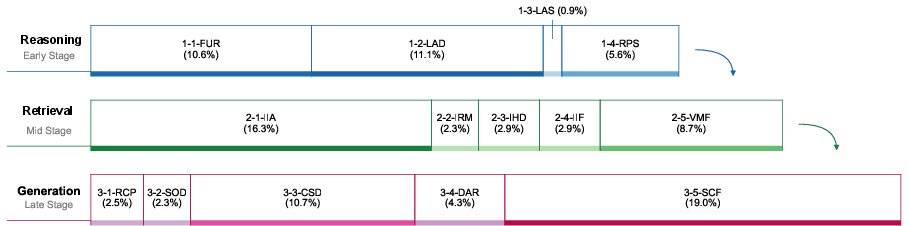
- Content Specification Deviation (CSD): A failure mode where generated content violates specified constraints (format, scope, required elements). "Specifically, they include Redundant Content Piling (3-1-RCP, 2.51\%), Structural Organization Dysfunction (3-2-SOD, 2.26\%), Content Specification Deviation (3-3-CSD, 10.73\%), Deficient Analytical Rigor (3-4-DAR, 4.31\%), and Strategic Content Fabrication (3-5-SCF, 18.95\%)."
- Cosine similarity: A vector-space measure of similarity used here to merge redundant concepts and in defining a bounded performance metric. "we employ Seed1.5-Embedding, which ranked first in MTEB (eng-v2, API available) \citep{enevoldsen2025mmteb}, as the embedding model to identify concept pairs with cosine similarity ."
- DEFT (Deep rEsearch Failure Taxonomy): A taxonomy of fine-grained failure modes for deep research agents across reasoning, retrieval, and generation. "we propose Deep rEsearch Failure Taxonomy (DEFT), the first failure taxonomy developed specifically for DRAs."
- Deficient Analytical Rigor (DAR): A failure mode indicating weak methodological soundness (e.g., unsubstantiated claims, missing validation). "Specifically, they include Redundant Content Piling (3-1-RCP, 2.51\%), Structural Organization Dysfunction (3-2-SOD, 2.26\%), Content Specification Deviation (3-3-CSD, 10.73\%), Deficient Analytical Rigor (3-4-DAR, 4.31\%), and Strategic Content Fabrication (3-5-SCF, 18.95\%)."
- Deep Research Agents (DRAs): Autonomous systems that retrieve, analyze, and synthesize large-scale information into structured reports. "Deep Research Agents (DRAs) have recently attracted increasing attention due to their ability to autonomously retrieve, analyze, and synthesize web-scale information into structured research reports"
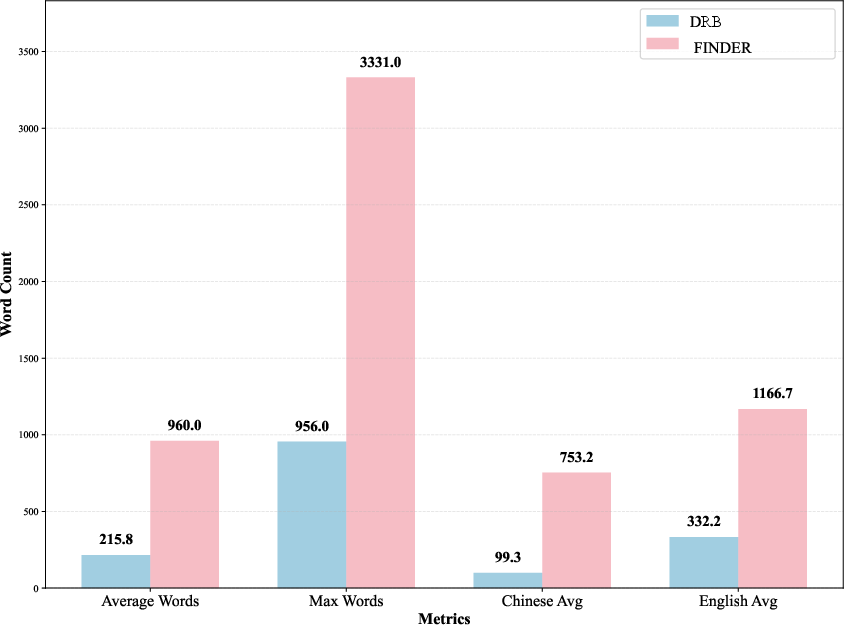
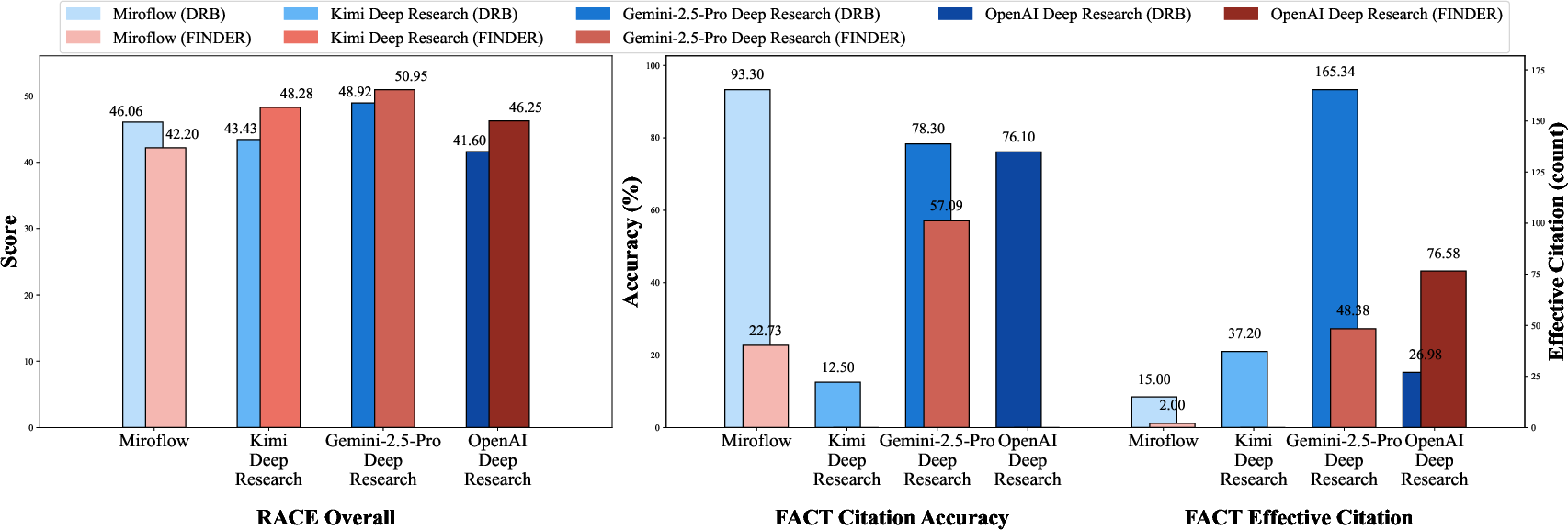
- DeepResearch Bench (DRB): An open-ended benchmark of 100 PhD-level problems with evaluation frameworks RACE and FACT. "DeepResearch Bench \citep{du2025deepresearchbenchcomprehensivebenchmark} contains 100 PhD-level problems spanning 22 domains, introducing the RACE and FACT evaluations for report quality and effectiveness."
- DeepResearchGym: A benchmarking framework with sandboxed, reproducible search environments and standardized protocols. "DeepResearchGym \citep{coelho2025deepresearchgym} provides sandbox environments with reproducible search APIs and standardized protocols for transparent deep research benchmarking."
- DeepScholar-Bench: A benchmark for evaluating research synthesis via content coverage, citation accuracy, and organization. "DeepScholar-Bench ~\citep{patel2025deepscholar} is a benchmark that automatically evaluates research synthesis abilities through content coverage, citation accuracy, and organizational quality."
- Effective citations (E.Cit.): An evaluation measure capturing the average number of citations that are both relevant and verifiable. "FACT, which assesses retrieval effectiveness through citation accuracy and average effective citations"
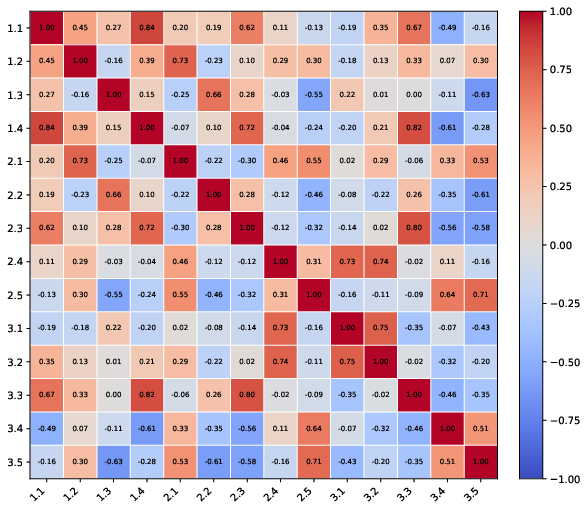
- Evidentiary Rigor cluster: A correlated failure cluster linking poor retrieval to confident but unsupported fabrications. "The Evidentiary Rigor cluster connects poor retrieval (2.1 IEIA) to \"confident fabrications\" (3.5 SCF)."
- FACT: An evaluation framework assessing retrieval effectiveness via citation accuracy and effective citations. "FACT, which assesses retrieval effectiveness through citation accuracy and average effective citations"
- Failure Taxonomy: A structured classification of failure types used to diagnose where agents break down. "we propose Deep rEsearch Failure Taxonomy (DEFT), the first failure taxonomy developed specifically for DRAs."
- Finder (Fine-grained DEepResearch bench): A benchmark with expert-curated tasks and detailed checklists for robust, reproducible evaluation. "we introduce Fine-grained DEepResearch bench (Finder), a fine-grained benchmark designed to evaluate DRAs in a more comprehensive manner."
- Grounded theory: A qualitative methodology for systematically deriving categories and theories from data. "The design of this process draws on grounded theory, which is a classic qualitative methodology that has been widely adopted across disciplines"
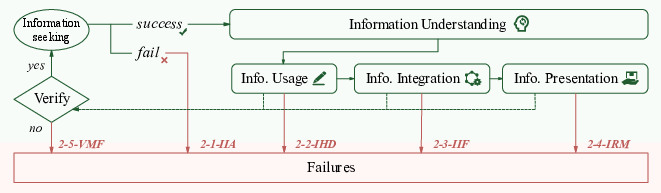
- Information Handling Deficiency (IHD): A failure mode involving poor processing or utilization of retrieved information. "Specifically, they include Insufficient External Information Acquisition (2-1-IIA, 16.30\%), Information Handling Deficiency (2-2-IHD, 2.26\%), Information Integration Failure (2-3-IIF, 2.91\%), Information Representation Misalignment (2-4-IRM, 2.91\%), and Verification Mechanism Failure (2-5-VMF, 8.72\%)."
- Information Integration Failure (IIF): A failure mode where retrieved information is not coherently combined into the report. "Specifically, they include Insufficient External Information Acquisition (2-1-IIA, 16.30\%), Information Handling Deficiency (2-2-IHD, 2.26\%), Information Integration Failure (2-3-IIF, 2.91\%), Information Representation Misalignment (2-4-IRM, 2.91\%), and Verification Mechanism Failure (2-5-VMF, 8.72\%)."
- Information Representation Misalignment (IRM): A failure mode where the form or framing of information misaligns with task needs or user intent. "Specifically, they include Insufficient External Information Acquisition (2-1-IIA, 16.30\%), Information Handling Deficiency (2-2-IHD, 2.26\%), Information Integration Failure (2-3-IIF, 2.91\%), Information Representation Misalignment (2-4-IRM, 2.91\%), and Verification Mechanism Failure (2-5-VMF, 8.72\%)."
- Insufficient External Information Acquisition (IIA): A failure mode where the agent retrieves too little or irrelevant external data to support claims. "Specifically, they include Insufficient External Information Acquisition (2-1-IIA, 16.30\%)"
- Inter-annotator reliability: A measure of agreement among annotators assessing the same data. "DEFT contains 14 fine-grained failure modes across reasoning, retrieval, and generation, and is built upon grounded theory with human–LLM co-annotating and inter-annotator reliability validation."
- Inter-Coder Reliability (ICR): A statistical measure of consistency among coders applying the same coding schema. "ICR measures the consistency among coders when encoding the same data"
- K-Alpha Calculator: A tool for computing Krippendorff’s alpha for reliability assessment. "For practical calculations, we utilized the web-based statistical package K-Alpha Calculator \citep{marzi2024k}."
- Krippendorff's Alpha: A reliability coefficient quantifying agreement among coders beyond chance. "We selected Krippendorff's Alpha \citep{krippendorff2018content} to assess ICR."
- Lack of Analytical Depth (LAD): A failure mode where analysis is shallow and lacks deep reasoning or insight. "Specifically, they include Failure to Understand Requirements (1-1-FUR, 10.55\%), Lack of Analytical Depth (1-2-LAD, 11.09\%), Limited Analytical Scope (1-3-LAS, 0.90\%), and Rigid Planning Strategy (1-4-RPS, 5.60\%)."
- Limited Analytical Scope (LAS): A failure mode where the analysis omits necessary dimensions or breadth. "Specifically, they include Failure to Understand Requirements (1-1-FUR, 10.55\%), Lack of Analytical Depth (1-2-LAD, 11.09\%), Limited Analytical Scope (1-3-LAS, 0.90\%), and Rigid Planning Strategy (1-4-RPS, 5.60\%)."
- MTEB: A benchmark suite for evaluating text embeddings; used to rank embedding models. "Seed1.5-Embedding, which ranked first in MTEB (eng-v2, API available)"
- Multi-step web exploration: A technique involving iterative browsing and querying to gather and refine information. "These agents utilize advanced techniques in multi-step web exploration, data retrieval, and synthesis"
- Open Coding: A grounded-theory stage that identifies and labels conceptual categories directly from raw data. "Open coding entails analyzing and conceptualizing raw textual data to identify and label underlying conceptual categories within the study context"
- Open-ended benchmarks: Benchmarks without a single definitive solution, emphasizing comprehensive synthesis over exact answers. "In contrast, open-ended benchmarks treat deep research as a task without a single definitive solution."
- Positive Taxonomy Metric: A success-oriented scoring scheme that maps category-specific error counts to interpretable scores. "Positive Taxonomy Metric"
- RACE: An evaluation framework scoring reports for comprehensiveness, depth, instruction-following, and readability. "RACE, which dynamically scores report quality in terms of comprehensiveness, depth, instruction-following, and readability"
- Reasoning resilience: The ability of an agent to maintain and adapt its reasoning under evolving, noisy task conditions. "Reasoning resilience, rather than reasoning intensity, is the key factor determining whether an agent can consistently produce high-quality deep research outcomes."
- Redundant Content Piling (RCP): A failure mode producing verbose, low-value text that lacks substantive insight or structure. "Specifically, they include Redundant Content Piling (3-1-RCP, 2.51\%)"
- Retrieval Category: A taxonomy dimension capturing failures in acquiring, processing, integrating, representing, and verifying external information. "Retrieval Category refers to the failures mainly exhibited during the middle stage of execution, arising from inadequate abilities in external knowledge retrieval and evidence construction."
- Rigid Planning Strategy (RPS): A failure mode where the agent follows inflexible plans that do not adapt to feedback or changing requirements. "Specifically, they include Failure to Understand Requirements (1-1-FUR, 10.55\%), Lack of Analytical Depth (1-2-LAD, 11.09\%), Limited Analytical Scope (1-3-LAS, 0.90\%), and Rigid Planning Strategy (1-4-RPS, 5.60\%)."
- Sandbox environments: Controlled settings with reproducible APIs for transparent benchmarking of agent behaviors. "DeepResearchGym \citep{coelho2025deepresearchgym} provides sandbox environments with reproducible search APIs"
- Seed1.5-Embedding: An embedding model used to identify redundant or similar concepts in coding via similarity thresholds. "we employ Seed1.5-Embedding, which ranked first in MTEB (eng-v2, API available)"
- Selective Coding: A grounded-theory stage that synthesizes axial categories into core categories and clarifies their relationships. "Selective coding synthesizes the concepts and categories developed in the first two coding stages to establish overarching core categories."
- Structural Organization Dysfunction (SOD): A failure mode where report structure is unclear or incoherent, hampering readability and utility. "Specifically, they include Redundant Content Piling (3-1-RCP, 2.51\%), Structural Organization Dysfunction (3-2-SOD, 2.26\%), Content Specification Deviation (3-3-CSD, 10.73\%), Deficient Analytical Rigor (3-4-DAR, 4.31\%), and Strategic Content Fabrication (3-5-SCF, 18.95\%)."
- Strategic Content Fabrication (SCF): A failure mode where agents generate plausible but unsupported content to mimic rigor. "This failure indicates that the agents tend to generate seemingly professional but factually unsupported terms, methods, or references in order to create an illusion of academic rigor"
- Verification Mechanism Failure (VMF): A failure mode where agents omit cross-checks of critical or conflicting information, degrading factuality. "Specifically, they include Insufficient External Information Acquisition (2-1-IIA, 16.30\%), Information Handling Deficiency (2-2-IHD, 2.26\%), Information Integration Failure (2-3-IIF, 2.91\%), Information Representation Misalignment (2-4-IRM, 2.91\%), and Verification Mechanism Failure (2-5-VMF, 8.72\%)."
Collections
Sign up for free to add this paper to one or more collections.

