ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Abstract: Deep Research (DR) is an emerging agent application that leverages LLMs to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is about testing “Deep Research” AI systems—tools that use LLMs to browse, read, and combine information from many places on the web to answer big, open-ended questions. These questions don’t have one short, obvious answer and often need careful reasoning, checking facts, and writing long explanations.
The authors built ResearchRubrics, a new way to fairly grade these AI systems. It includes real-world questions plus detailed checklists (rubrics) written by humans that say what a good answer must include. Then they used both people and strong AI models to grade the AI systems according to these rubrics.
What the paper is trying to figure out
- Can we create a reliable, human-quality way to judge deep, open-ended research answers from AI systems?
- What makes some research questions harder than others?
- How well do today’s best Deep Research AIs actually do on realistic tasks?
- Can AI “judges” grade answers in a way that matches human graders?
- What makes a good rubric (grading checklist) clear and fair?
How they did it (in simple terms)
Think of a teacher who gives students a research project and a detailed checklist for grading. The authors do something similar, but for AI:
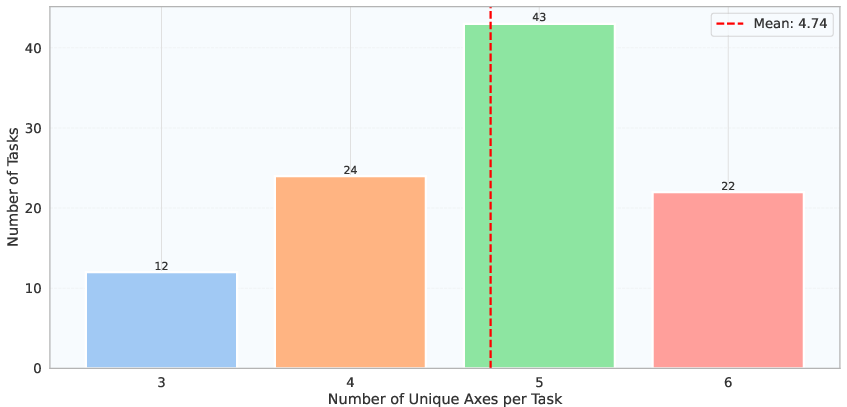
- They collected 101 real-style research prompts across nine areas (like business planning, history, consumer decisions, and technical topics).
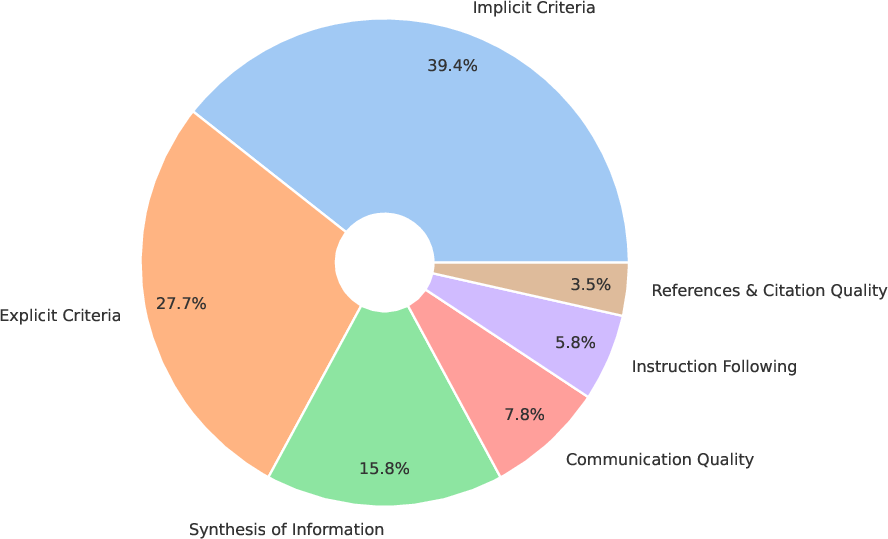
- For each prompt, human experts wrote a careful rubric with 20–43 specific items (2,593 total items). These items check things like:
- Explicit requirements: Did you answer the question as asked?
- Implicit requirements: Did you include important things people expect, even if not asked?
- Synthesis: Did you connect ideas from multiple sources, not just list facts?
- References: Did you cite evidence that truly supports your claims?
- Communication: Is it clear and well organized for the reader?
- Instruction following: Did you follow the directions (format, tone, limits)?
- Some rubric items are mandatory (must-have) and others are optional (nice-to-have). Items also have weights (big points or small points), and there are negative items that subtract points for mistakes like false facts.
- They introduced a simple “three-level” grading for each item: satisfied (full credit), partially satisfied (half credit), or not satisfied (no credit). That’s like getting full, half, or zero points on a question.
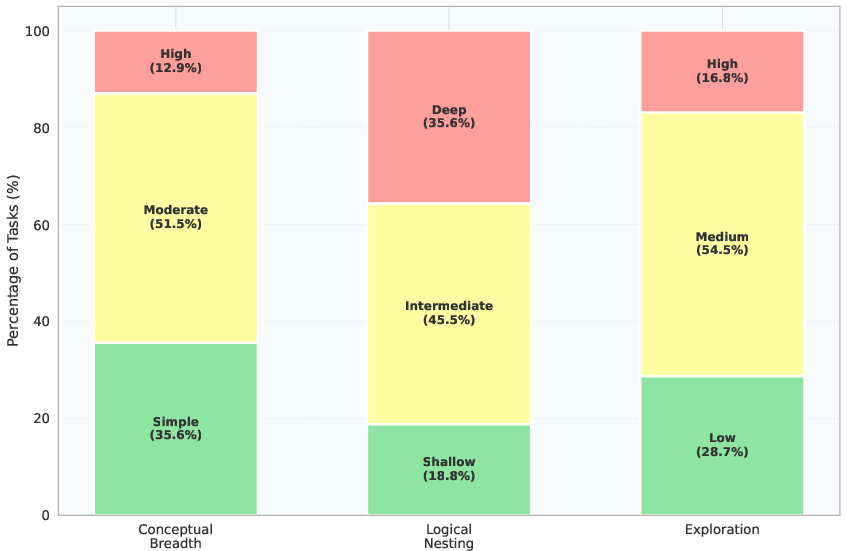
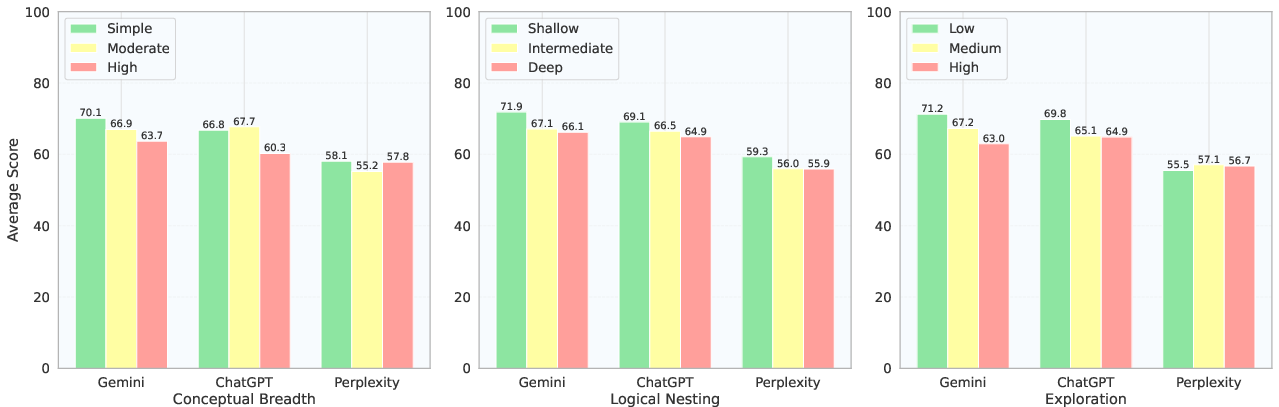
- They also created a way to label how hard a task is, along three axes:
- Conceptual breadth: How many different topics you must cover.
- Logical nesting depth: How many reasoning steps are needed (one step vs. a chain of steps).
- Exploration: How open-ended or underspecified the task is.
- They tested popular Deep Research systems (from big AI companies) and had strong LLMs act as “AI judges” to grade the answers, then compared those grades with human graders to see how closely they match.
What they found and why it matters
- Overall performance is far from perfect:
- Even the best systems scored under 70% on the rubrics (about 68% at best with partial credit; about 62% with strict grading).
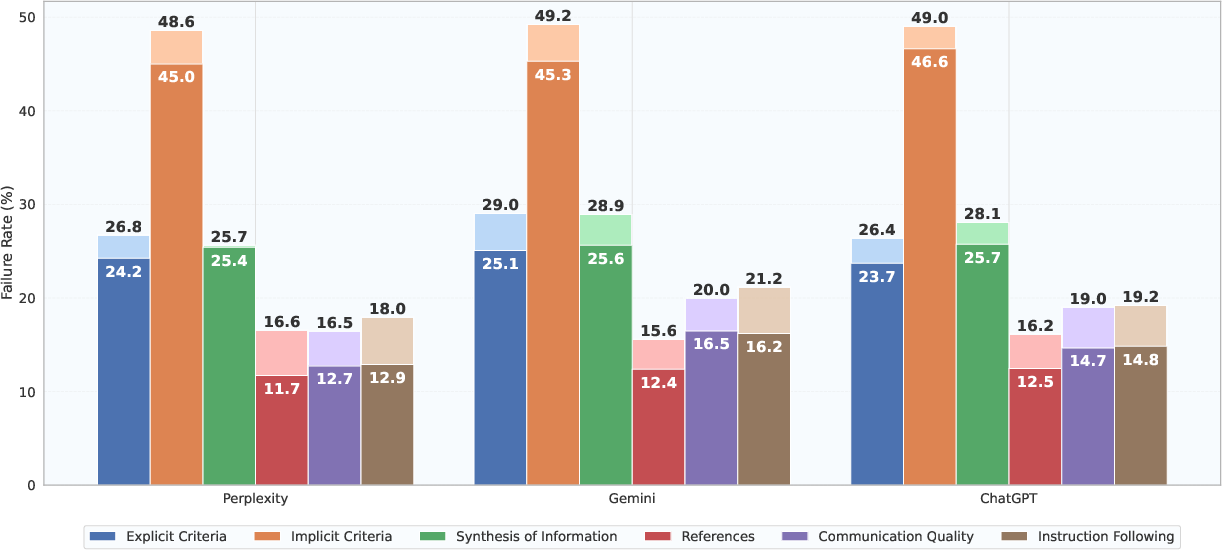
- Where AIs struggle most:
- Implicit reasoning: They often miss important context that isn’t spelled out.
- Synthesis: They have trouble weaving information from multiple sources into one coherent argument.
- Deep reasoning chains: Performance drops as the number of dependent steps grows (multi-step thinking is hard).
- Length helps a bit—but not just because it’s longer:
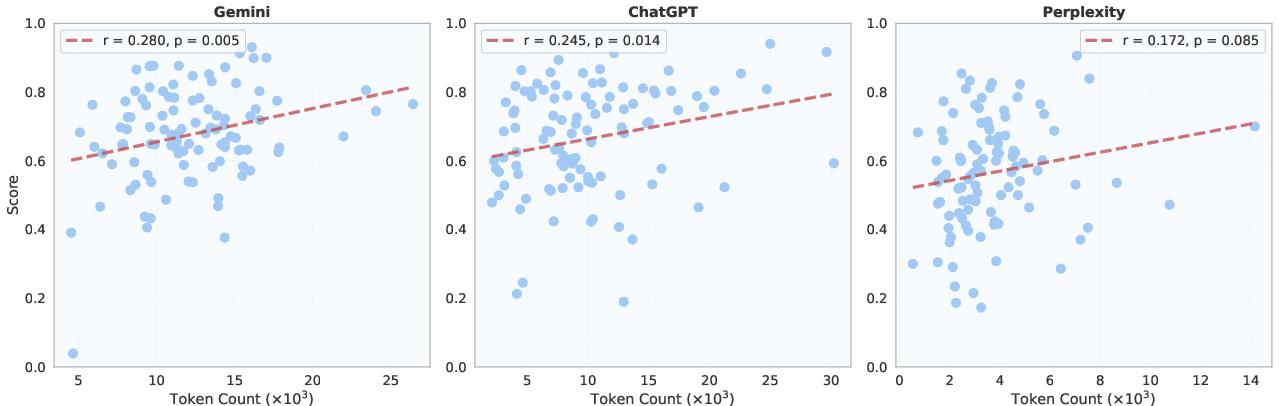
- Longer answers tended to score somewhat higher, likely because they cover more of the checklist, not simply because they’re wordy.
- References show a trade-off:
- Some systems include many citations but make more mistakes in them; others include fewer citations but are more accurate. Balancing coverage and precision is hard.
- Human vs. AI judge agreement:
- With strict (yes/no) grading, AI judges matched humans fairly well (around 0.72–0.76 Macro F1), which is good enough to make large-scale automated grading practical.
- With partial credit (full/half/none), agreement dropped, because “partial” introduces more gray areas.
- What makes a good rubric:
- Adding short, concrete examples to each rubric item improved agreement between human and AI judges.
- Letting an AI “rewrite” or “expand” rubric items made grading worse—human-written, concise criteria worked best.
Why this matters: Without a strong, fair way to grade deep research answers, it’s hard to improve these systems or trust them. ResearchRubrics provides a clearer path to measure progress and pinpoint weaknesses.
What this could change going forward
- Better training targets: Developers can see exactly where their systems fail (for example, missing implicit context or weak multi-document synthesis) and train models to fix those gaps.
- Safer, more reliable AI assistants: By focusing on mandatory criteria and factual grounding, future systems can avoid serious mistakes while still improving their overall quality.
- Smarter evaluations at scale: Because AI judges can align well with humans (especially with clear rubrics), researchers can evaluate many answers quickly and still keep quality high.
- Improved rubric design: Short, human-crafted criteria with examples will likely become standard, while auto-generated rubric text should be used cautiously.
- A shared benchmark for progress: Since the authors released the prompts, rubrics, and code, other teams can compare fairly and push the field forward.
In short, the paper builds a clear, human-centered way to grade deep research answers, shows where today’s systems fall short, and offers practical tools and tips to help the next generation of AI research assistants become more trustworthy and useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps the paper leaves unresolved and actionable questions for future research:
- Multi-turn evaluation: The benchmark uses single-turn prompts; it does not assess interactive, iterative deep-research workflows (clarifying questions, scoping, replanning over multiple turns).
- Process evaluation: Scoring focuses on final reports, not the research process (planning quality, exploration strategies, retrieval paths, stopping criteria, tool selection, and decision logs).
- Provenance and evidence linkage: There is no process-level evaluation of source provenance (e.g., stepwise evidence chains, claim-to-citation alignment, or counterfactual support) beyond coarse citation accuracy counts.
- Citation verification rigor: Methods for verifying that cited sources specifically support claims (not just being relevant) are under-specified; automated claim-evidence consistency checking is missing.
- Time-bounded truth and freshness: The benchmark does not control for temporal drift in “live” or current-event tasks; no time-bounded ground truth or freshness-aware scoring protocol is provided.
- Length–quality confounding: The authors observe a positive correlation between output length and scores but do not isolate causality; controlled studies holding information content constant are needed.
- Partial credit design: Ternary grading shows lower human–LLM agreement than binary, but it remains unclear how to design stable partial-credit scales (criterion-specific partial weights, continuous scoring, or anchors) that increase discriminative power without ambiguity.
- Weight calibration and reliability: Criterion weights are expert-assigned; there is no inter-rater reliability, sensitivity analysis, or psychometric validation (e.g., IRT) to test stability of weights and their impact on rankings.
- Mandatory vs. optional criteria: The practical threshold for “sufficient” responses (all mandatory met) versus overall quality remains uncalibrated; guidance for deployment thresholds and risk trade-offs is missing.
- Negative criteria semantics: The judge treats “negative criteria satisfied” as a penalty, which may be confusing for automated graders; the paper does not test whether judges reliably detect and correctly interpret such failure conditions.
- Score normalization and comparability: Normalizing by positive weights only may yield cross-task comparability issues (especially with different counts of optional/negative criteria); no analysis of score invariance across rubric lengths and weight distributions.
- Statistical rigor: Results lack confidence intervals, per-task variance, and significance tests for model comparisons; stability of rankings under re-sampling or judge changes is unknown.
- Judge reliability and bias: LLM-as-judge uses closed, proprietary models; cross-judge consistency, susceptibility to prompt phrasing, adversarial responses, and potential training contamination are not systematically stress-tested.
- Human–human agreement baseline: The paper reports human–LLM agreement but does not establish a human–human ceiling on rubric judgments to contextualize the achievable upper bound for automated judges.
- Complexity labeling validity: The triplet (breadth, depth, exploration) is expert-annotated with no inter-annotator reliability, operationalization protocol, or automatic labeling method; construct validity and predictive validity need evaluation.
- Domain expertise depth: “Experts” are STEM-generalists; the benchmark may under-capture nuances in high-stakes or highly specialized domains (e.g., clinical, legal, finance). Impact of involving domain specialists is not measured.
- Coverage and scale: With 101 tasks and nine domains, coverage of real-world deep research breadth (languages, cultures, regulatory contexts, long-horizon projects) remains limited; scaling guidelines and sampling strategy justification are absent.
- Multilingual and multimodal gaps: Tasks are English-only and text-centric; evaluation of multilingual agents, cross-lingual research, or multimodal evidence (figures, tables, PDFs with complex layouts) is missing.
- Tool-use and environment realism: The benchmark evaluates final outputs rather than the agent’s interaction with tools (browsers, APIs, spreadsheets); no metrics for tool efficacy, action quality, or efficiency (time, steps, compute).
- Robustness to gaming: Fine-grained, public rubrics may incentivize rubric gaming; no anti-gaming tests (e.g., vacuous verbosity, check-listing without synthesis, adversarial formatting) or stealth rubrics are explored.
- Safety and ethics: While negative criteria penalize disallowed content, the benchmark lacks explicit safety/ethics stress-tests (harmful advice, biased sourcing, equity considerations) and domain-specific harm assessments.
- Generalization and contamination: Using proprietary DR systems and judges raises replicability risks; potential data leakage after benchmark release and strategies for ongoing contamination mitigation are not addressed.
- Rubric augmentation and examples: Although LLM-augmented rubrics degrade agreement, the paper does not explore hybrid strategies (expert-written rubrics with verified micro-examples, counter-examples, or adversarial “gotchas”) that might improve clarity without semantic drift.
- Alternative evaluation paradigms: The study does not compare rubric-based scoring to complementary methods (pairwise human preference judgments, automated fact-checking, retrieval grounding scores, or passage-level entailment).
- Personalized objectives: Exploration tasks often require eliciting user preferences; the benchmark does not measure how well agents identify missing constraints or align outputs to individualized goals.
- Release artifacts and reproducibility: It is unclear whether all human judgments, annotation guidelines, and judge prompts are released to enable exact replication of scoring pipelines and alignment analyses.
- Ethical review of rubric design: The social and normative assumptions embedded in “implicit requirements” and “communication quality” are not audited for demographic or cultural bias; fairness of rubric expectations is unexamined.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, drawing on the paper’s benchmark, rubrics, evaluation protocols, and design recommendations.
- Enterprise “Research QA Gate” for AI-generated reports (finance, healthcare, legal, consulting, journalism)
- Use: Enforce mandatory rubric thresholds before any AI research report is shared or acted upon; route failures to human review.
- Tools/workflows: LLM-as-judge microservice; weighted rubric scoring; mandatory/optional criteria gating; quality dashboards.
- Assumptions/dependencies: Domain-tailored rubrics; reliable judge model selection; privacy/compliance for internal documents; threshold calibration.
- Vendor benchmarking and procurement (IT, AI platform teams)
- Use: Compare DR agent vendors on standardized rubric compliance (binary and ternary grading) to inform purchase decisions and SLAs.
- Tools/workflows: Benchmark harness using the released prompts/rubrics/code; compliance reporting.
- Assumptions/dependencies: Access to vendor systems; reproducible evaluation environment; organizational acceptance of rubric-based KPIs.
- Training signals for reinforcement learning from AI feedback (software/AI)
- Use: Convert rubric judgments (Satisfied/Partially/Not) into reward signals to train research agents for better synthesis and implicit reasoning.
- Tools/workflows: RLAIF/RLHF pipelines; reward shaping using weighted rubrics; failure-mode sampling.
- Assumptions/dependencies: Model training access; careful reward design to avoid gaming; cost/compute for iterative training.
- Editorial and fact-check workflows (media/journalism)
- Use: Score drafts for references, synthesis, and implicit requirements; auto-flag missing evidence or off-topic content via negative criteria.
- Tools/workflows: CMS plugin or editor extension; citation verification module; rubric-aligned checklists; human override.
- Assumptions/dependencies: Topic-specific rubric tailoring; source access and link-check reliability.
- Academic grading and formative feedback for long-form assignments (education)
- Use: Grade literature reviews and research papers with explicit/implicit criteria; provide partial credit via ternary grading.
- Tools/workflows: LMS integration; rubric banks; automated feedback summaries aligned to criterion weights.
- Assumptions/dependencies: Instructor oversight; transparent criteria; fairness controls; policies for AI use.
- Internal research quality dashboards (enterprise R&D, market intelligence)
- Use: Track team- and project-level rubric compliance; identify recurrent failure modes (implicit reasoning, synthesis).
- Tools/workflows: KPI dashboards; axis-level breakdowns; trend analysis across breadth/depth/exploration dimensions.
- Assumptions/dependencies: Consistent task annotation; data pipelines; leadership buy-in for metric-driven quality.
- Prompt scoping and triage using the tri-axial complexity framework (product, research ops)
- Use: Route high-depth/high-exploration tasks to humans or hybrid workflows; assign SLAs based on complexity labels.
- Tools/workflows: Task annotation services; decision policies; automated triage rules; cost estimation by complexity.
- Assumptions/dependencies: Reliable labeling; organizational tolerance for hybrid (human+AI) processes.
- Safety and red teaming checklists focused on implicit requirements (AI safety, trust & safety)
- Use: Use negative criteria to catch hallucinations, unjustified claims, and instruction violations; quantify risk contributions.
- Tools/workflows: Red-team runs with criterion-level failure analytics; regression tests; policy-compliance flags.
- Assumptions/dependencies: Domain-specific negative criteria; periodic rubric maintenance; human escalations for high-risk failures.
- Citation-quality QA module (publishing, pharma RWE, legal)
- Use: Verify source relevance and authority; penalize unsupported claims; analyze breadth-accuracy trade-offs.
- Tools/workflows: Link checking; source authority scoring; citation accuracy audits; report annotations.
- Assumptions/dependencies: Access to citation graphs/indexes; live web retrieval; citation parsing in long PDFs.
- Editor/browser extensions for on-demand scoring (software tooling)
- Use: Score drafts in IDEs or document editors against rubrics; highlight missing or weak criteria in-line.
- Tools/workflows: VSCode/Google Docs plugins; local or cloud judge service; per-criterion hints.
- Assumptions/dependencies: Integration engineering; latency budgets; model cost controls.
- Deployment gating policy: binary vs. ternary grading selection (SaaS, platform ops)
- Use: Choose strict binary gating for external-facing outputs; use ternary partial credit to support internal iteration.
- Tools/workflows: Environment-specific grading mode; release pipelines; exception handling.
- Assumptions/dependencies: Risk posture; user expectations; monitoring alignment with human reviewers.
- Marketing claims substantiation via standardized benchmarks (vendor/product marketing)
- Use: Back performance claims with domain-diverse rubric scores; publish axis-level breakdowns.
- Tools/workflows: Public evaluations; whitepapers; audit trails.
- Assumptions/dependencies: Transparent methodology; reproducibility; accepted benchmark governance.
- Rubric design best practices adoption (toolmakers, evaluators)
- Use: Include brief concrete examples in criteria; avoid LLM-augmented rubric rewriting to prevent drift.
- Tools/workflows: Rubric authoring guidelines; review checklists; ablation-informed templates.
- Assumptions/dependencies: Human expert availability; continuous rubric iteration; documentation discipline.
- Knowledge-base and wiki update QA (enterprise KM)
- Use: Validate long-form updates for completeness, synthesis, and clarity before publishing to internal wikis.
- Tools/workflows: Pre-publish QA gate; rubric-driven content linting; change logs tied to criteria.
- Assumptions/dependencies: Access control; versioning; reviewer workflows.
- Compliance and audit evidence packs (regulated industries)
- Use: Attach rubric compliance reports to submissions (e.g., policy analyses, medical summaries) to demonstrate QA rigor.
- Tools/workflows: Audit bundles; normalized scores with mandatory criteria coverage; failure rationale logs.
- Assumptions/dependencies: Regulator acceptance; mapping rubrics to regulatory requirements; secure storage.
- Public benchmark for progress tracking and research reproducibility (academia/AI labs)
- Use: Use released tasks and code to run controlled experiments; analyze improvements in synthesis and implicit reasoning over time.
- Tools/workflows: Leaderboards; per-axis stratification; open evaluation scripts.
- Assumptions/dependencies: Timely updates; community governance; avoiding overfitting.
Long-Term Applications
Below are use cases that will benefit from further research, scaling, standardization, or productization before broad deployment.
- Sector standards for deep research quality and certification (policy/regulation)
- Use: Establish formal “DR Quality Standards” (mandatory/optional criteria, failure-rate thresholds) for regulated domains.
- Tools/workflows: Standards bodies; certification programs; external audits; model cards referencing rubric scores.
- Assumptions/dependencies: Multi-stakeholder consensus; legal frameworks; evolving rubric catalogs.
- Automated peer-review assistants for journals and conferences (academia)
- Use: Criterion-driven checks for factual grounding, synthesis, and references; structured reviewer support with partial credit.
- Tools/workflows: Submission portals with rubric scoring; reviewer augmentation dashboards.
- Assumptions/dependencies: Ethical acceptance; bias auditing; transparency to authors.
- Personalized research tutors and writing coaches (education)
- Use: Deliver rubric-based, granular feedback on student research, including implicit requirements and synthesis coaching.
- Tools/workflows: Adaptive feedback systems; progress tracking by axis; curricular alignment.
- Assumptions/dependencies: Pedagogical validation; safeguarding against over-reliance; accessibility.
- Live, dynamic benchmarks tied to current web content (AI evaluation)
- Use: Evaluate agents on up-to-date tasks; measure robustness to changing information and citation veracity.
- Tools/workflows: Live retrieval harnesses; content freshness policies; temporal evaluation metrics.
- Assumptions/dependencies: Stable web APIs; caching and provenance; anti-gaming measures.
- Source credibility modeling and authority-aware citation scoring (media, law, healthcare)
- Use: Weight rubric judgments by source authority; penalize reliance on weak or conflicted sources.
- Tools/workflows: Authority graphs; provenance tracing; claim-source alignment analytics.
- Assumptions/dependencies: High-quality metadata; domain-specific authority criteria; maintenance costs.
- Architectural advances for implicit reasoning and multi-document synthesis (AI vendors)
- Use: New planning and memory mechanisms optimized for high-depth reasoning and cross-document integration.
- Tools/workflows: Hierarchical planners; source-aware memory; multi-hop synthesis modules trained on rubric signals.
- Assumptions/dependencies: Research breakthroughs; compute budgets; evaluation beyond prompt engineering.
- Trust labels and consumer risk flags on AI research outputs (policy, platforms)
- Use: Display standardized “quality badges” based on rubric compliance; warn users when mandatory criteria fail.
- Tools/workflows: UI components; public APIs; cross-platform interoperability.
- Assumptions/dependencies: Policy alignment; user comprehension; abuse prevention.
- Strategic decision-support with evidence gates (finance, energy, public policy)
- Use: Gate investment or policy recommendations behind synthesis/implicit-requirement thresholds; scenario stress tests.
- Tools/workflows: Decision boards; rubric-conditioned approval workflows; audit archives.
- Assumptions/dependencies: Executive buy-in; domain-specific rubrics; integration with data sources.
- Clinical evidence synthesis with robust QA (healthcare, pharma)
- Use: Ensure systematic reviews satisfy mandatory criteria (methods, outcomes, biases); track optional quality indicators.
- Tools/workflows: EBM-aligned rubrics; trial registry integration; citation verification.
- Assumptions/dependencies: Medical oversight; regulatory acceptance; liability management.
- Legal drafting auditors for multi-document case synthesis (legal)
- Use: Evaluate briefs for precedent coverage, argument coherence, and instruction following; flag missing authorities.
- Tools/workflows: Legal rubric libraries; case law retrieval; structured deficiency reports.
- Assumptions/dependencies: Jurisdiction-specific rubrics; professional standards; confidentiality.
- Government analysis portals for evidence-backed policy (public sector)
- Use: Publish analysis with transparent rubric scores for grounding, synthesis, and clarity; improve public trust.
- Tools/workflows: Open dashboards; provenance records; citizen access.
- Assumptions/dependencies: Policy commitments to transparency; data availability; accessibility standards.
- Misinformation detection and research integrity pipelines (platforms)
- Use: Use negative criteria to detect unsupported claims and instruction violations at scale; escalate high-risk items.
- Tools/workflows: Content triage; risk scoring; human verification loops.
- Assumptions/dependencies: Throughput and latency; false-positive controls; alignment with moderation policies.
- CI/CD for long-form agent systems (software engineering)
- Use: Treat research outputs like code—run rubric tests per commit; block releases until mandatory criteria pass.
- Tools/workflows: “Rubric-as-Code” repositories; templated tests; versioned criteria.
- Assumptions/dependencies: Developer adoption; test coverage; evolution management.
- Multilingual expansion of rubrics and judges (global deployment)
- Use: Port rubrics and evaluation protocols to additional languages for equitable access.
- Tools/workflows: Translation with expert review; multilingual judge models; cross-language consistency checks.
- Assumptions/dependencies: Native expert availability; model quality parity; cultural adaptation.
- Length-bias–aware evaluation and training (AI research)
- Use: Adjust scoring and training to reduce verbosity bias while preserving information density.
- Tools/workflows: Controlled-length experiments; criterion reweighting; calibration studies.
- Assumptions/dependencies: Careful experimental design; stakeholder agreement on trade-offs.
- Marketplace and governance for “Rubric-as-Code” (ecosystem)
- Use: Share, version, and certify domain-specific rubric packs; foster interoperable evaluation standards.
- Tools/workflows: Registries; governance councils; compatibility guidelines.
- Assumptions/dependencies: Community incentives; IP/licensing; curation quality.
- Sector-specific turnkey products (e.g., “ResearchRubrics for Pharma RWE,” “Legal Case Synthesis QA”)
- Use: Offer prebuilt rubric libraries and judge services tailored to high-stakes domains.
- Tools/workflows: Managed services; domain integrations; support SLAs.
- Assumptions/dependencies: Domain experts; ongoing maintenance; liability frameworks.
These applications leverage the paper’s innovations—expert-authored, fine-grained rubrics; ternary and binary scoring; a tri-axial complexity framework; LLM-as-judge protocols; and validated rubric design guidelines—to build practical, scalable workflows for evaluating and improving deep research agents across sectors.
Glossary
- Ablation studies: Controlled experiments that remove or modify components to assess their impact on performance or alignment. "We also run ablation studies to isolate the most significant factors in the level of alignment between the model-based grader and human judgments."
- Agent-as-a-Judge: An evaluation setup where an AI agent (often an LLM) acts as the evaluator of outputs according to criteria or rubrics. "so that the Agent-as-a-Judge framework can operate effectively with LLM-generated rubrics."
- Binary grading: A scoring scheme where each criterion is marked as either satisfied or not satisfied, without partial credit. "Under binary grading, we collapse Partially Satisfied verdicts to Not Satisfied, measuring strict compliance."
- Breadth-accuracy trade-off: The tendency for systems to sacrifice precision when aiming for wider coverage, or vice versa. "The implicit reasoning gap explains the breadth-accuracy trade-off documented in citation analysis"
- Bridge entity resolution: The process of correctly identifying and linking intermediate entities required across multi-hop reasoning steps. "bridge entity resolution in early neural layers creates hard limits on subsequent reasoning depth."
- Calibrated human preference scale: A weighting scheme aligned to human judgments that maps criteria to importance levels for consistent scoring. "These weights are aligned with a calibrated human preference scale (\cref{tab:rubric-scale}) spanning six levels, from Critically Detrimental to Critically Important."
- CLEAR framework: An evaluation framework that uses high-quality references to assess outputs, often in expert domains. "using the CLEAR framework"
- Conceptual Breadth: A complexity dimension indicating how many distinct topics or domains a task spans. "We categorize each ResearchRubrics task along three orthogonal complexity dimensions: Conceptual Breadth, Logical Nesting Depth, and Exploration"
- Criterion-level analysis: Analysis performed at the granularity of individual rubric criteria to understand specific performance patterns. "Our criterion-level analysis reveals a nuanced relationship: longer responses correlate with higher scores"
- Cross-document synthesis: Integrating information from multiple documents to form a coherent, evidence-backed answer. "including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers."
- Deep Research agents: Autonomous LLM-based systems that perform multi-step exploration, retrieval, and synthesis to answer open-ended queries. "Deep Research agents: autonomous LLM-based systems that conduct multi-step web exploration, targeted retrieval, and synthesis to answer open-ended queries."
- Exploration: A complexity dimension reflecting how underspecified or open-ended a task is, requiring goal clarification or creative reframing. "We categorize each ResearchRubrics task along three orthogonal complexity dimensions: Conceptual Breadth, Logical Nesting Depth, and Exploration"
- Factual grounding: The requirement that claims be supported by accurate, verifiable evidence or sources. "to assess factual grounding, reasoning soundness, and clarity."
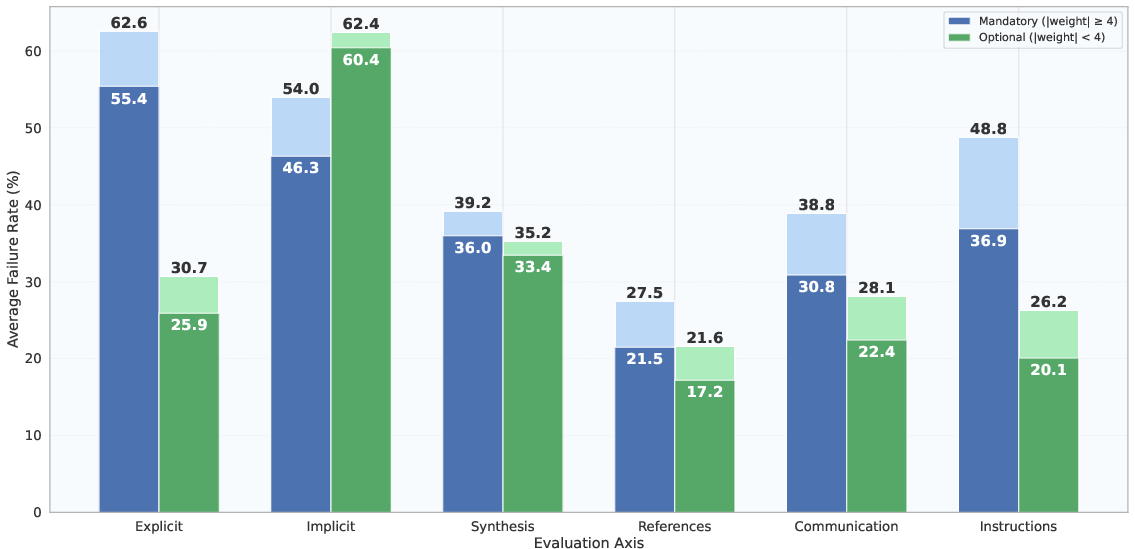
- Failure rate stratification: Breaking down failure rates by categories such as criterion importance to identify where systems fail most. "Failure rate stratification by criterion importance."
- Fine-grained rubrics: Detailed, specific evaluation criteria that allow nuanced assessment of answers. "We introduce outcome-based, fine-grained rubrics that provide rigorous evaluation of long-form research answers and closely align with expert judgments."
- Human–LLM judge alignment: The degree of agreement between human evaluators and LLM-based judges. "Human-LLM Judge Alignment for Auto-Evaluation"
- Implicit Requirements: Criteria covering expected but unstated aspects that a good answer should include. "Implicit Requirements"
- Instruction Following: Adherence to explicit user constraints or format requirements specified in the prompt. "Instruction Following"
- Length-quality conflation hypothesis: The idea that longer outputs may be judged as higher quality due to covering more criteria, not inherent superiority. "This supports the length-quality conflation hypothesis: longer reports often perform better because they cover more rubric criteria, not necessarily because evaluators prefer verbosity."
- LLM augmentation: Using a LLM to expand or rephrase rubric text in hopes of improving clarity. "LLM Augmentation evaluates whether prompting a LLM to automatically expand or rephrase rubric text adds clarity."
- LLM-as-judge: An evaluation paradigm where a LLM serves as the grader against rubric criteria. "Following the LLM-as-judge paradigm, we use powerful LLMs to assess rubric compliance"
- LLM-generated reference reports: Reference outputs produced by LLMs that are then used as the basis for evaluation, potentially introducing circularity. "evaluation metrics reliant on LLM-generated reference reports"
- LLM-generated rubrics: Rubrics produced automatically by LLMs rather than by human experts. "some benchmarks introduce LLM-generated rubrics and evaluation metrics reliant upon LLM-generated reference reports"
- Logical Nesting Depth: A complexity dimension capturing the number of dependent reasoning steps or hierarchical planning required. "We categorize each ResearchRubrics task along three orthogonal complexity dimensions: Conceptual Breadth, Logical Nesting Depth, and Exploration"
- Macro F1 score: The unweighted average of per-class F1 scores, used to measure agreement across multiple classes. "Macro scores between human annotators and automated evaluation across grading schemes and judge models."
- Mandatory criteria: Essential requirements that must be satisfied for an answer to be considered adequate. "Mandatory criteria define the minimum requirements for a valid response"
- Multi-document synthesis: Combining evidence from multiple retrieved sources into a unified, justified answer. "room for improvement in multi-document synthesis and rigorous justification."
- Multi-hop reasoning: Reasoning that requires chaining multiple dependent steps to arrive at an answer. "Multi-hop reasoning studies~\citep{yang-etal-2018-hotpotqa} demonstrate that while agents achieve 80%+ success on first-hop inference, bridge entity resolution in early neural layers creates hard limits on subsequent reasoning depth."
- Negative criteria: Rubric items designed to penalize undesirable behaviors such as inaccuracies or irrelevance. "included negative criteria targeting likely pitfalls"
- Negative rubrics: Evaluation checks that explicitly deduct points for incorrect, extraneous, or disallowed content. "The benchmarks also include negative rubrics that specifically aim to penalize extraneous or incorrect content."
- Optional criteria: Non-essential attributes that improve quality but are not required for sufficiency. "Optional criteria capture desirable but non-essential qualities"
- Partial credit: Awarding intermediate credit when a criterion is only partly met. "The shift from ternary to binary evaluation increases agreement by approximately 20 percentage points, confirming that partial credit introduces ambiguity without improving discriminative power."
- Reference overlap metrics: Evaluation measures based on the overlap between a model’s output and a reference text, often too coarse for nuanced tasks. "and simplistic reference overlap metrics."
- Rubric compliance: The extent to which an output satisfies the specified rubric criteria. "The results show that even the strongest agents fall below 68\% average rubric compliance"
- Rubric-based benchmark: A benchmark that evaluates outputs against a detailed set of rubric criteria rather than a single answer key. "ResearchRubrics is a rubric-based benchmark: each prompt is judged against a tailored set of criteria that define the requirements of a good answer."
- Semantic drift: Unintended changes in meaning introduced during rewriting or augmentation. "Human-authored concise rubrics with targeted examples outperform machine-generated verbose descriptions, likely because augmentation introduces semantic drift and emphasis distortion."
- Synthesis of Information: A rubric dimension assessing whether information is integrated across sources rather than merely listed. "across six dimensions: Explicit Requirements, Implicit Reasoning, Synthesis of Information, References, Communication Quality, and Instruction Following."
- Ternary grading: A scoring scheme with three levels (e.g., satisfied, partially satisfied, not satisfied) enabling partial credit. "We propose a ternary grading scheme for a rubrics-based benchmark that supports partial credit assignment"
- Ternary indicator: The three-valued marker returned by the judge for each criterion (1, 0.5, 0). "m_{r_i} is the ternary indicator returned from the model-based judge"
Collections
Sign up for free to add this paper to one or more collections.