DEER: A Comprehensive and Reliable Benchmark for Deep-Research Expert Reports
Abstract: As LLMs advance, deep research systems can generate expert-level reports via multi-step reasoning and evidence-based synthesis, but evaluating such reports remains challenging. Existing benchmarks often lack systematic criteria for expert reporting, evaluations that rely heavily on LLM judges can fail to capture issues that require expert judgment, and source verification typically covers only a limited subset of explicitly cited statements rather than report-wide factual reliability. We introduce DEER, a benchmark for evaluating expert-level deep research reports. DEER comprises 50 report-writing tasks spanning 13 domains and an expert-grounded evaluation taxonomy (7 dimensions, 25 sub-dimension) operationalized into 130 fine-grained rubric items. DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently. Complementing rubric-based assessment, we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality. DEER correlates closely with human expert judgments and yields interpretable diagnostics of system strengths and weaknesses.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DEER, a new way to test how well advanced AI systems can write expert-level research reports. These AIs do more than answer simple questions—they search the web, read multiple sources, and build long, detailed arguments. DEER helps judge whether those reports are clear, accurate, well-supported by evidence, and trustworthy.
What are the main questions the paper asks?
To make sure AI-written expert reports are good, the paper asks:
- How can we fairly and consistently grade expert-level reports across many topics?
- How can we check not just the writing, but also whether the facts and evidence in the report are correct?
- Can AI “judges” score reports in ways that match what human experts think?
How did the researchers study this?
The team built a benchmark—a standard test—called DEER, and designed a grading system to evaluate AI-generated research reports.
The benchmark: topics and tasks
Think of DEER like a set of assignments teachers use to grade students across different subjects. It includes:
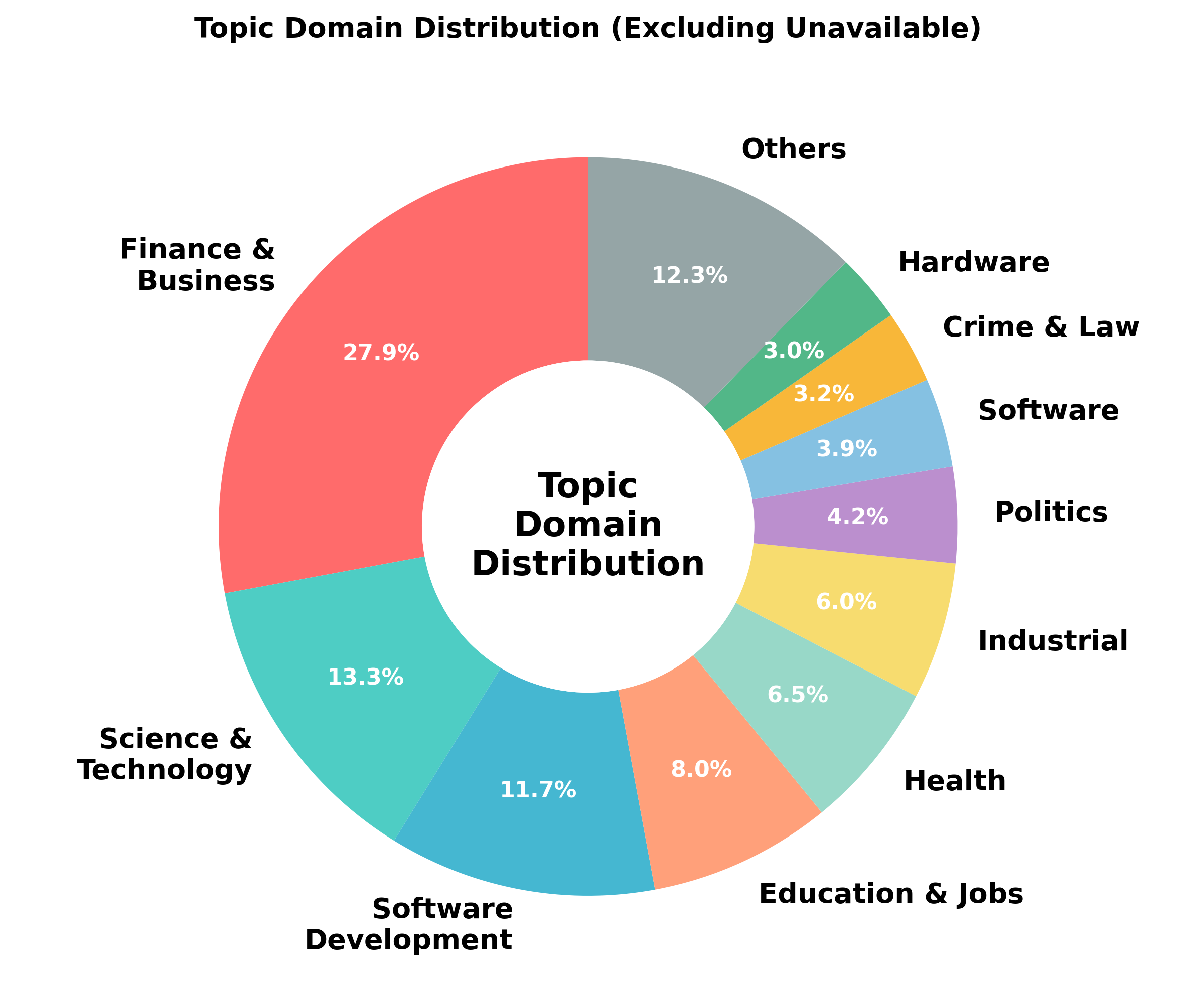
- 50 report-writing tasks across 13 domains (like physics, history, computer science).
- Each task is adapted from tough expert-level questions, rewritten by specialists so the AI must build a full report (not just give a short answer).
The grading system: a checklist and expert advice
Grading a complex report can be messy, so the team built a detailed system to make it fair:
- A 7-part “taxonomy” (a structured checklist) covering:
- Request Completeness: Did the report answer the full question?
- Evidence Validity: Are the facts, numbers, and logic correct?
- Structure Consistency: Is the report well-organized?
- Narration Style: Is the writing clear and easy to follow?
- Ethics Compliance: Is it safe, balanced, and respectful?
- Information Sufficiency: Are enough sources used?
- Information Integrity: Are claims factual and citations accurate?
- 130 concrete checklist items: Like a teacher’s rubric with yes/no or 1–10 scoring for specific things.
- Expert Evaluation Guidance: For each task, human experts wrote instructions that say what a good report must include. This helps AI “judges” know what’s important and avoid missing subtle mistakes.
The fact-checker: checking claims across the whole report
Reports often have many statements—some with citations and some without. DEER adds a “document-level fact-checker” that works like a detective:
- It finds all claims in the report, not just the ones with citations.
- It “backtracks” references: If a sentence relies on earlier evidence, it links that sentence to the right sources.
- It uses batching (splitting the report into chunks) so the AI doesn’t forget important details in the middle.
- It groups related claims for efficient checking, reducing cost while staying accurate.
- It sometimes retrieves only the most relevant context to save time and money, accepting a small accuracy trade-off.
Together, the rubric and the fact-checker give both a quality score (how well the report is written and structured) and an evidence score (how trustworthy and well-cited the report is).
What did they find?
In plain terms:
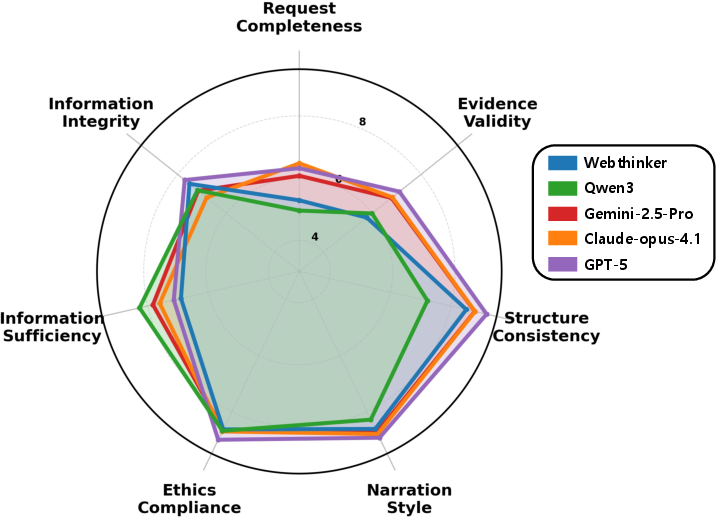
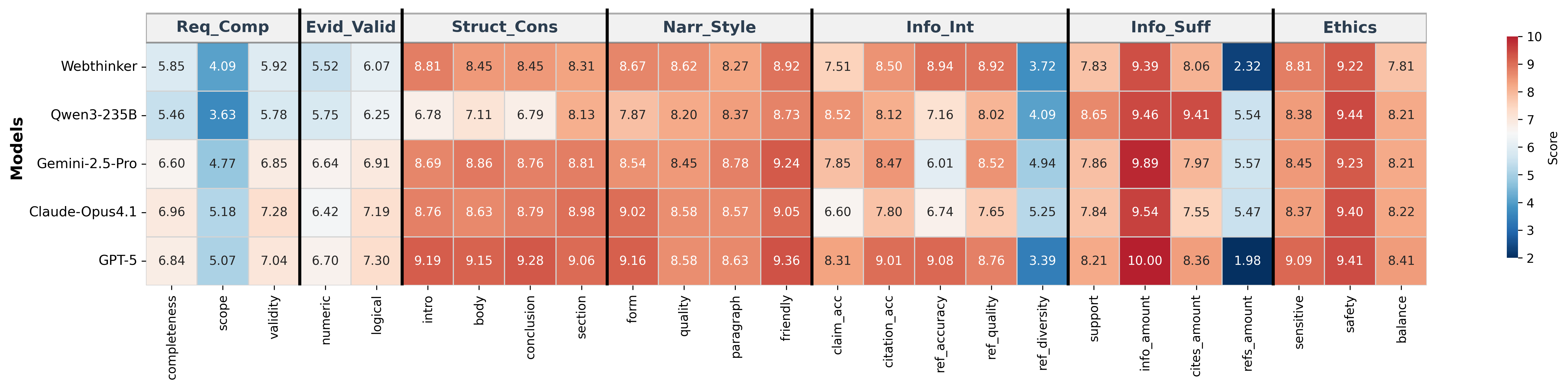
- Today’s AIs are good at writing clearly and organizing reports. They also generally follow ethical guidelines.
- But they struggle with two expert essentials:
- Fully answering the exact question asked (Request Completeness).
- Proving their points with solid numbers, methods, and logic (Evidence Validity).
- Giving AIs more “thinking time” (reasoning) improves their performance across most areas.
- Adding web search helps with information-related scores (like using more sources).
- Specialized “deep research” systems did best in evidence-related areas (Information Integrity and Sufficiency), but sometimes wandered off-topic—too much searching can cause “drift,” where the report focuses more on random facts than the original question.
- When AI judges use expert guidance along with the fixed checklist, their scores line up much better with human experts. This means DEER’s method is reliable.
- The fact-checker can check many claims efficiently:
- Grouping claims reduces cost a lot while keeping accuracy high.
- Using less context cuts costs even more but slightly lowers accuracy. It’s a trade-off you can choose based on your needs.
Why does this matter?
DEER helps make AI research reports more trustworthy. Here’s why that’s important:
- It sets a clear, fair standard for what “expert-level” means in AI-written reports.
- It shows where current AIs are strong (writing and structure) and where they need work (fully answering complex questions and backing up claims).
- It gives developers a roadmap to improve their systems—especially in fact-checking, citation quality, and precise reasoning.
- It builds confidence that AI evaluations are not random: they can match human experts when guided properly.
- In the long run, it can push AIs toward producing reliable knowledge, which matters for schools, research labs, companies, and public policy.
In short, DEER is like a smart teacher and a careful detective working together to judge AI-written reports—making sure they’re not just well-written, but also accurate, thorough, and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research.
- Benchmark scope and representativeness:
- Validate that 50 tasks (mapped from HLE QA items) sufficiently represent real-world deep-research queries; quantify coverage gaps relative to the 5,045-query distribution that motivated topic selection.
- Assess whether reformulating HLE QA items into report prompts introduces bias (e.g., toward exam-style reasoning) that departs from typical research-report genres.
- Provide task difficulty calibration and control across domains (e.g., physics vs. history) to disentangle domain effects from task complexity.
- Generalization and multilinguality:
- Evaluate DEER on non-English reports and multilingual sources; define procedures and metrics for cross-lingual claim extraction, citation validation, and judge consistency.
- Test generalization to non-text modalities (tables, figures, code, datasets) that commonly appear in expert reports; extend taxonomy and verification to multimodal evidence.
- Rubric design and aggregation:
- Justify and test alternative weightings of the 130 rubric items; compare equal-weight averaging vs. expert-weighted or task-adaptive schemes, and analyze sensitivity of overall scores.
- Provide anchor descriptions for the 1–10 scoring scale per rubric item to improve calibration and reduce interpretive variability across LLM judges and humans.
- Investigate aggregation strategies that penalize critical failures (e.g., minimum/thresholding on “Evidence Validity”) rather than averaging, and measure effects on human correlation.
- Expert Evaluation Guidance:
- Quantify the risk of “label leakage” whereby guidance unintentionally reveals expected content structures, making evaluation easier than generation; develop guidance formats that avoid answer-like cues.
- Run ablations with and without guidance to measure effects on judge performance, reliability, and potential overfitting of systems to the guidance style.
- Assess the expertise-level sensitivity (e.g., masters vs. PhD vs. practitioner) in authoring guidance; measure inter-expert agreement and the impact on scoring validity.
- LLM-as-a-judge reliability:
- Expand human evaluation beyond 15 tasks and 90 samples; report inter-annotator agreement for humans per dimension and rubric item, not just overall correlations.
- Analyze bias when judge and system models share families (e.g., GPT judging GPT); adopt cross-family, blinded judging and quantify effects on evaluations.
- Provide a detailed error analysis of disagreements between LLM judges and human experts to identify systematic blind spots (e.g., domain-specific numeric reasoning).
- Claim extraction and dependency tracking:
- Report precision (not only recall) for claim extraction; quantify false positives, duplication, and granularity mismatches relative to human ground truth.
- Establish inter-annotator reliability for the 728 human-labeled claims and describe the annotation protocol; expand the sample and domains for stronger statistical confidence.
- Validate the LLM-based sentence dependency mapping R(s_i) with human-labeled references; quantify errors in implicit citation inheritance and their impact on downstream verification.
- Fact verification methodology:
- Detail and evaluate source credibility scoring (peer-review status, authoritativeness, recency, independence, conflict of interest) and integrate it into Information Integrity metrics.
- Account for temporal validity (time-sensitive claims) and versioning of web content; provide a snapshotting protocol and re-verification strategy to ensure reproducibility over time.
- Compare web-only verification with curated scholarly indexes (e.g., PubMed, arXiv, Crossref) and paywalled sources; measure trade-offs in coverage, quality, and cost.
- Expand evaluation to normative, speculative, and causal claims that are not strictly factual; define policy-aware verification rules and uncertainty annotations.
- Provide a thorough error analysis of grouped claim verification and context retrieval: quantify when grouping induces cross-claim contamination and when context pruning drops necessary evidence.
- Metrics consistency and reporting:
- Resolve inconsistencies between reported accuracy/F1 improvements for grouping (e.g., 0.78 → 0.89 vs. 0.91 → 0.90); ensure metrics are comparable across datasets and stages.
- Report end-to-end costs (extraction + verification + judging), latency, and scalability under realistic workloads; include energy/compute footprint for cost-aware benchmarking.
- Robustness and adversarial evaluation:
- Stress-test the pipeline against adversarial behaviors (fabricated citations, misleading paraphrases, obfuscated claim chaining, cherry-picked evidence); add robustness metrics and adversarial suites.
- Evaluate resilience to retrieval-induced drift explicitly: define a metric for drift from the original query, quantify its prevalence, and test interventions (e.g., query anchoring, requirement tracking).
- Ethics and safety assessment:
- Validate Ethics Compliance scoring with human experts and domain-specific safety taxonomies; include sub-dimensions for dual-use risks, privacy, and regulatory compliance beyond general style checks.
- Test consistency of ethics judgments across cultures and jurisdictions; develop region-aware safety rubrics and guidance.
- Domain analyses:
- Investigate why physics underperforms and why CS/history/linguistics show large agent variance; perform per-domain error taxonomies and targeted remediation experiments.
- Control for differences in required quantitative rigor (units, formulas, statistical methods) and measure their specific impact on Evidence Validity sub-items.
- Reproducibility and openness:
- Document dataset availability (prompts, guidance, rubrics, reports, judgments), web snapshots, and licensing; provide scripts for replicable runs and judge ensembles.
- Measure sensitivity to LLM version changes (e.g., GPT-5 vs. GPT-5-mini updates) and retrieval backend differences; recommend stability protocols.
- Integration of qualitative and quantitative signals:
- Analyze the correlation structure between rubric dimensions and verification metrics; identify redundant vs. complementary signals and propose a principled fusion (e.g., multi-objective scoring, calibration).
- Explore counterfactual evaluations where claims verified as false trigger targeted rubric penalties; test whether coupled scoring improves alignment with expert judgments.
- Benchmark evolution:
- Establish procedures for periodic benchmark updates (new domains, tasks, modalities) without breaking longitudinal comparability; design versioned leaderboards and adjustment baselines.
- Add “process-oriented” measures (trace quality, search trajectories, reasoning steps) to complement product-focused report evaluation and diagnose root causes of failures.
Practical Applications
Below are actionable applications derived from the paper’s benchmark (DEER), taxonomy, expert-guided LLM judging, and document-level claim verification pipeline. Each item notes sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Model selection and procurement for expert-report generators (software, consulting, finance, pharma R&D, journalism)
- Use DEER’s 7-dimension scores and 130-item rubric to compare LLMs/agents and pick the best model per use case.
- Tools/workflows: Evaluation harness with dashboards that visualize Request Completeness, Evidence Validity, and Information Integrity; CI gating for model upgrades.
- Assumptions/dependencies: Access to evaluation prompts, model outputs, and a capable LLM-judge; stable internet access for verification; consistent cost budgets.
- Pre-publication quality gates for long-form content (marketing, policy think tanks, asset management, healthcare communications)
- Run DEER rubric + document-level fact verification before releasing whitepapers, policy briefs, analyst notes, patient education materials.
- Tools/workflows: “Report QA” pipeline with rubric JSON outputs and claim-level verification summaries; approval thresholds by dimension.
- Assumptions/dependencies: Web evidence reliability; content owners accept LLM-judge rationale; privacy-compliant browsing for sensitive docs.
- Compliance and risk checks on AI-generated reports (finance, healthcare, legal, safety-critical industries)
- Treat Information Integrity/Sufficiency as a “hallucination risk KPI” for regulated deliverables; track over time.
- Tools/workflows: Risk dashboard aggregating Claim Factuality, Citation Validity, Reference Quality/Diversity; alerting when thresholds drop.
- Assumptions/dependencies: Domain-specific thresholds calibrated with human experts; audit logs retained.
- Training signal for RLHF/RLAIF and reward modeling (AI/ML, software)
- Use rubric scores and verification metrics as structured rewards to finetune research agents for better evidence use, scope handling, and numeric accuracy.
- Tools/workflows: Offline evaluation-to-reward data pipeline; curriculum that emphasizes low-scoring rubric items.
- Assumptions/dependencies: Sufficient evaluation throughput; reward-model alignment with downstream objectives; no label leakage.
- Agent design optimization to reduce “retrieval-induced drift” (software, research tooling)
- Use DEER’s diagnostics to adjust agent planning and retrieval budget so external material doesn’t derail problem framing.
- Tools/workflows: Prompt templates that pin the request scope; retrieval-mixers that cap citation volume; mid-flight “scope audit” checks.
- Assumptions/dependencies: Observed drift patterns generalize beyond benchmark tasks; ability to modify agent orchestration.
- Integrated fact-checking for editorial workflows (newsrooms, encyclopedic platforms, enterprise knowledge management)
- Embed DEER’s claim extraction, implicit evidence backtracking, and grouped verification to flag weakly supported passages.
- Tools/workflows: Editor plugin that shows claim coverage and inherited citations; batch verification to balance cost and recall.
- Assumptions/dependencies: Adequate API budgets; robust handling of uncited/implicit claims; credible sources available.
- Academic use for method comparisons and ablation studies (academia)
- Compare browsing strategies, reasoning budgets, or retrieval rankers using DEER’s multi-dimensional outcomes and human-correlation analyses.
- Tools/workflows: Reproducible experiment scripts; per-dimension leaderboards; error heatmaps for numeric vs. logical validity.
- Assumptions/dependencies: Community access to benchmark tasks and evaluation pipeline; consistent judge settings.
- Editorial and citation auditing for research support tools (reference managers, scholarly assistants)
- Detect citation inaccuracies, insufficient reference diversity, or missing provenance.
- Tools/workflows: “Cite auditor” that evaluates Reference Accuracy, Diversity, and alignment at paragraph-level.
- Assumptions/dependencies: Access to sources (paywalled vs. open); discipline-specific citation norms.
- Educational writing assistants that grade expert reports (education)
- Provide rubric-based feedback on scope clarity, evidence logic, numeric correctness, and ethics compliance.
- Tools/workflows: Assignment grader with per-criterion rationales; formative guidance based on “Expert Evaluation Guidance” patterns.
- Assumptions/dependencies: Age-appropriate prompts; institutional policies on AI feedback; potential for false positives mitigated by instructor review.
- Cost-efficient verification services (startups, platforms)
- Offer grouped-claim verification (10–20 claims/source) and context retrieval to reduce API costs while maintaining acceptable F1.
- Tools/workflows: Tiered verification modes (high-accuracy vs. low-cost); usage-based pricing.
- Assumptions/dependencies: Customer tolerance for accuracy–cost trade-offs; dynamic tuning per document type.
Long-Term Applications
- Standardization and certification of AI-generated reports (policy, standards bodies, compliance)
- Develop DEER-inspired formal standards (e.g., ISO-like) for evaluating AI research reports; certify systems against minimum per-dimension scores.
- Tools/workflows: Third-party audit protocols; public scorecards; procurement checklists for government/enterprise.
- Assumptions/dependencies: Broad stakeholder consensus; evolving legal frameworks and industry buy-in.
- Safety cases and guardrails for autonomous research agents (software, safety-critical sectors)
- Use DEER metrics as continuous monitors and kill-switch thresholds for fully autonomous literature-review or policy-drafting agents.
- Tools/workflows: Always-on evaluators in agent loops; escalation to human review upon Integrity/Sufficiency dips.
- Assumptions/dependencies: Reliable real-time evaluation at scale; robust handling of adversarial sources.
- Multimodal expert-report evaluation (healthcare imaging, engineering, climate/energy modeling)
- Extend rubric and verification to figures, tables, code, and data; verify computations, units, and plots.
- Tools/workflows: Code execution sandboxes; dataset provenance checks; chart-to-claim alignment verifiers.
- Assumptions/dependencies: Access to data/code artifacts; reproducibility infrastructure; domain-specific validators.
- Automated peer review and meta-review assistance (academic publishing)
- Provide structured evaluative signals (e.g., Evidence Validity, Numeric Accuracy) to aid reviewers and editors.
- Tools/workflows: Reviewer copilot showing claim maps, contentious sections, and ref checks; submission triage by rubric profile.
- Assumptions/dependencies: Editorial policies for AI assistance; safeguards against over-reliance on LLM judges.
- Legal e-discovery and brief verification pipelines (legal tech)
- Trace implicit claim provenance in briefs; flag unsupported assertions; measure reference sufficiency/diversity.
- Tools/workflows: Discovery copilot that builds claim-evidence graphs; court-ready audit trails.
- Assumptions/dependencies: Access to case law databases; confidentiality and privilege protections.
- Government and legislative drafting assistants with embedded checks (public policy)
- Draft regulatory analyses or impact assessments with integrated ethics compliance and document-wide fact verification.
- Tools/workflows: Policy authoring suites with DEER-based QA stages and versioned evidence snapshots.
- Assumptions/dependencies: Long-horizon procurement and governance; archiving of evidence for transparency.
- Education-at-scale: curriculum-integrated auto-feedback for research writing (education)
- Program-level adoption of rubric-guided feedback for theses and capstone projects; analytics on cohort weaknesses.
- Tools/workflows: LMS integrations; learning analytics by dimension (e.g., weakest on Scope Boundary, Numeric Accuracy).
- Assumptions/dependencies: Institutional acceptance; equity and accessibility considerations.
- Insurance and SLAs for AI content (finance, enterprise risk)
- Underwrite “factuality insurance” using Information Integrity metrics; define SLAs tied to rubric thresholds.
- Tools/workflows: Policy pricing models calibrated to verification outputs; incident response playbooks for failures.
- Assumptions/dependencies: Actuarial data from wide deployments; legal clarity on liability.
- Retrieval alignment controllers to mitigate drift (software, IR)
- New agent components that adaptively cap or re-rank retrieval to maintain problem focus as suggested by DEER findings.
- Tools/workflows: Drift detectors tied to Request Completeness and Scope Boundary; retrieval-policy learning.
- Assumptions/dependencies: Generalization beyond benchmark; stable interfaces to search and RAG modules.
- Domain-specific judge models and guidance libraries (healthcare, law, finance, energy)
- Train specialized LLM judges calibrated with expert guidance to capture subtle errors in each discipline.
- Tools/workflows: Guidance repositories per domain; continual calibration with human experts; judge ensembles for robustness.
- Assumptions/dependencies: Expert time to author/validate guidance; avoiding judge-model bias and overfitting.
- Enterprise knowledge ops with provenance-aware reporting (all sectors)
- Company-wide practice where every internal report includes claim maps, inherited citation chains, and verification logs.
- Tools/workflows: Knowledge graph of claims→evidence; audit-ready archives; CI/CD for internal documentation.
- Assumptions/dependencies: Data governance maturity; change management for teams.
- Preprint and repository-integrated verification badges (academia, open science)
- Repositories display verification coverage and rubric summaries as badges on submissions to encourage rigor.
- Tools/workflows: Submission hooks that run verification; public metadata APIs for badges.
- Assumptions/dependencies: Community acceptance; mechanisms to prevent gaming the metrics.
- Personalized writing copilots with provenance overlays (daily life, knowledge workers)
- Consumer assistants that suggest scope clarifications, highlight weakly supported claims, and add citations on the fly.
- Tools/workflows: Real-time claim extraction with low-cost grouped checks; explainable overlays for edits.
- Assumptions/dependencies: Usability and latency; privacy for local documents and browsing.
- End-to-end RAG pipelines that are claim-aware (software)
- Retrieval/augmentation tuned at the claim level, budgeting context on high-importance assertions and numeric content.
- Tools/workflows: Claim importance scoring; selective evidence expansion; feedback loops from verification to retrieval.
- Assumptions/dependencies: Robust claim segmentation; scalable orchestration; domain data availability.
Notes on feasibility across applications:
- LLM-judge dependence: The approach assumes sustained, high correlation with human experts; domain-specific guidance improves reliability but requires expert time.
- Web evidence quality: Verification accuracy depends on access to credible, up-to-date sources; paywalled data may limit coverage.
- Cost–accuracy trade-offs: Grouped verification and context retrieval lower cost but can reduce F1; choices must match risk tolerance.
- Data privacy and security: Verification workflows that browse the web or external APIs must be compliant for sensitive content.
- Generalization: Results and best practices observed on DEER’s 13 domains and 50 tasks may require adaptation for highly specialized or multimodal domains.
Glossary
- agent-as-a-judge: An evaluation paradigm where autonomous agents or systems act as judges of other agents’ outputs. "Furthermore, ManuSearch~\cite{manusearch} and Mind2Web-2~\cite{mind2web2} employ multi-agent web browsing and agent-as-a-judge architectures to evaluate models' ability to replicate real-world research processes."
- ALiiCE: A framework for fine-grained positional citation evaluation in academic texts. "Additionally, research analyzing citation quality in detail, such as ALiiCE~\cite{xu2024aliiceevaluatingpositionalfinegrained} and CiteEval~\cite{xu2025citeevalprincipledrivencitationevaluation}, which evaluate citation accuracy and evidence alignment in academic texts, is increasing."
- Back-Tracking mechanism: A method that traces sentence-level dependencies to inherit citations for implicit claims. "we use a Back-Tracking mechanism to trace the reference source."
- Batch Extraction: A strategy that processes sentences in small batches while preserving global context to improve claim extraction recall. "To address this, we apply a Batch Extraction strategy that maintains the context of the entire document while parallel-processing only the target sentences divided into small batches :"
- Claim Extraction: The process of identifying verifiable assertions within a document. "Batch Processing for Claim Extraction"
- Claim Verification: The process of checking claims against external evidence to assess factuality. "In the claim verification stage, we conducted an ablation study on grouping and retrieval settings using GPT-4.1 (Table~\ref{tab:verification_ablation})."
- CiteEval: A principle-driven citation evaluation framework assessing source attribution quality. "Additionally, research analyzing citation quality in detail, such as ALiiCE~\cite{xu2024aliiceevaluatingpositionalfinegrained} and CiteEval~\cite{xu2025citeevalprincipledrivencitationevaluation}, which evaluate citation accuracy and evidence alignment in academic texts, is increasing."
- Context Retrieval: A scaling strategy that retrieves only necessary context for verification to reduce cost. "Second, greater API cost reduction is possible through the Context Retrieval strategy, which selectively provides only the context necessary for fact verification."
- Contextual citation inheritance: The phenomenon where a sentence implicitly relies on citations introduced earlier in the text. "However, most approaches focus on verifying explicit citations or single claims and fail to address issues such as implicit evidence, contextual citation inheritance, and Fair Use that appear in long-form reports."
- Deep Research: Systems that perform multi-step reasoning, web browsing, and synthesis to answer complex queries and produce expert-level reports. "Recently, Deep Research benchmarks have emerged that go beyond simple knowledge recall to evaluate complex reasoning, web browsing, and information integration capabilities."
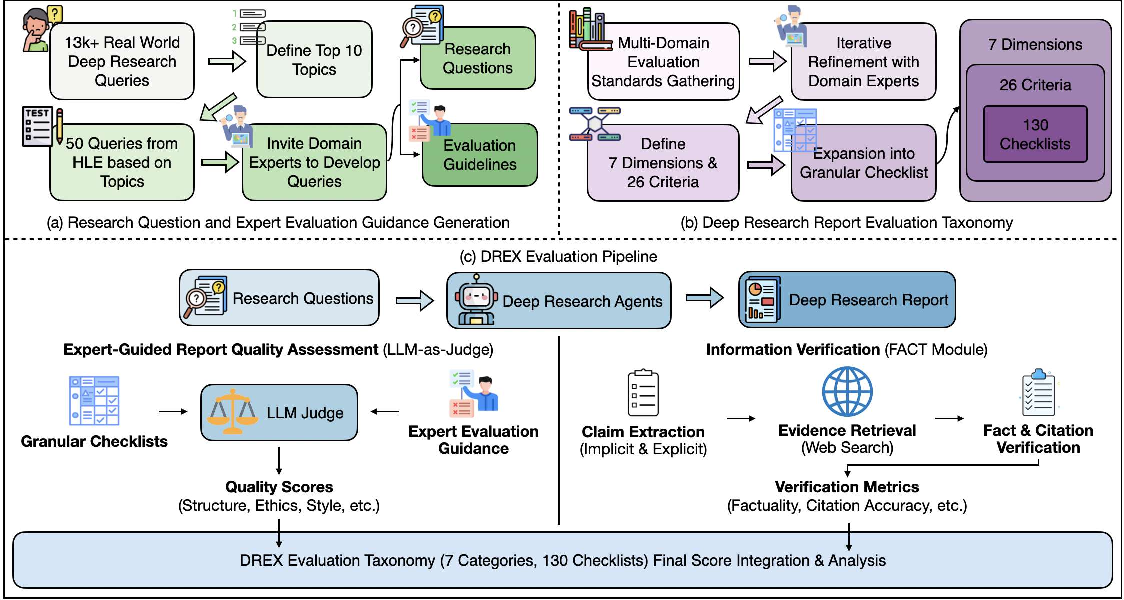
- Deep Research Report Evaluation Taxonomy: A structured framework of dimensions and criteria for evaluating deep research reports. "we construct a Deep Research Report Evaluation Taxonomy with 7 major dimensions (\S~\ref{sec:taxonomy}), which we group into 5 report-quality dimensions and 2 external-information dimensions."
- DeepResearchBench: A benchmark focused on deep research report-centric evaluations. "Additionally, DeepResearchBench~\cite{deepbench} and WebThinker Eval~\cite{webthinker} present Deep Research report-centric evaluations that assess literature-based report generation and multi-document reasoning"
- Document-level fact-checking architecture: A pipeline that verifies all claims across a report, including uncited ones. "we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality."
- Ethics Compliance: An evaluation dimension assessing handling of sensitive issues, safety, and balanced perspectives. "The evaluation is conducted across 5 dimensions: Request Completeness, Evidence Validity, Structure Consistency, Narration Style, and Ethics Compliance"
- Evidence Validity: An evaluation dimension measuring quantitative accuracy and logical support of arguments. "The evaluation is conducted across 5 dimensions: Request Completeness, Evidence Validity, Structure Consistency, Narration Style, and Ethics Compliance"
- Expert Evaluation Guidance: Task-specific guidance authored by domain experts to improve LLM-judge consistency and catch subtle errors. "DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently."
- Fair Use: A legal doctrine permitting limited use of copyrighted material under certain conditions. "fail to address issues such as implicit evidence, contextual citation inheritance, and Fair Use that appear in long-form reports."
- FRAMES: A high-difficulty QA benchmark testing long-context reasoning and synthesis. "High-difficulty QA benchmarks such as HLE~\cite{hle}, GPQA~\cite{gpqa}, and FRAMES~\cite{frames} reveal the limitations of existing models by requiring long-context reasoning, expert-level thinking, and information synthesis skills."
- GPQA: A graduate-level problem answering benchmark designed to assess expert reasoning. "High-difficulty QA benchmarks such as HLE~\cite{hle}, GPQA~\cite{gpqa}, and FRAMES~\cite{frames} reveal the limitations of existing models by requiring long-context reasoning, expert-level thinking, and information synthesis skills."
- Grouped Claim Verification: A technique bundling claims that cite the same source to verify them together efficiently. "First, we apply Grouped Claim Verification, which bundles multiple claims citing the same source into a single input for verification."
- Humanity's Last Exam (HLE): An expert-written, multi-disciplinary, high-difficulty benchmark used to seed report topics. "We use Humanity's Last Exam (HLE) \cite{hle} as a source of seed questions"
- ICC (Intraclass Correlation Coefficient): A reliability statistic for measuring consistency across evaluators or models. "We measured the agreement between models using Krippendorff's and ICC (Intraclass Correlation Coefficient)."
- Inter-evaluator Agreement (IEA): The degree of agreement among different evaluation models or judges. "Inter-evaluator Agreement (IEA)"
- Information Integrity: An evaluation dimension focusing on claim factuality, citation validity, and reference quality. "Information Integrity and Information Sufficiency are evaluated through a separate verification pipeline, the Information Verification Module."
- Information Sufficiency: An evaluation dimension assessing the adequacy and diversity of sources and citations. "Information Integrity and Information Sufficiency are evaluated through a separate verification pipeline, the Information Verification Module."
- Krippendorff's alpha: A statistical coefficient measuring inter-rater reliability for qualitative judgments. "We measured the agreement between models using Krippendorff's and ICC (Intraclass Correlation Coefficient)."
- Lost-in-the-Middle problem: An LLM limitation where information in the middle of long inputs is overlooked. "When processing long documents as a single input, LLMs suffer from the Lost-in-the-Middle problem, which leads to the omission of important claims~\cite{liu2023lostmiddlelanguagemodels}."
- LLM-as-a-Judge: Using LLMs directly as evaluators of generated content. "Most notably, the LLM-as-a-Judge method, which directly uses LLMs as evaluators, has been widely researched."
- MAPLE: A method for few-shot claim verification via micro analysis of pairwise language evolution. "Additionally, MAPLE~\cite{zeng2024maple}, FactDetect~\cite{jafari2024robustclaimverificationfact}, and ClaimCheck~\cite{putta-etal-2025-claimcheck} implemented sophisticated claim-level fact-checking"
- ManuSearch: A deep research evaluation setting employing multi-agent web browsing. "Furthermore, ManuSearch~\cite{manusearch} and Mind2Web-2~\cite{mind2web2} employ multi-agent web browsing and agent-as-a-judge architectures"
- Mind2Web-2: A dataset/system for evaluating agents’ web interaction and research capabilities. "Furthermore, ManuSearch~\cite{manusearch} and Mind2Web-2~\cite{mind2web2} employ multi-agent web browsing and agent-as-a-judge architectures"
- Narration Style: An evaluation dimension covering report form, writing quality, and reader friendliness. "The evaluation is conducted across 5 dimensions: Request Completeness, Evidence Validity, Structure Consistency, Narration Style, and Ethics Compliance"
- Pairwise agreement: A metric indicating how often an evaluator matches human preference when comparing two items. "Pairwise agreement is a metric that measures the proportion of cases in which our evaluator chose the same priority as the human expert when comparing two reports"
- Pearson correlation coefficient: A measure of linear correlation between two sets of scores. "we used the Pearson correlation coefficient, the Spearman rank correlation coefficient, and pairwise agreement \cite{deepbench}."
- Request Completeness: An evaluation dimension assessing whether the report fully addresses the query’s scope and requirements. "The evaluation is conducted across 5 dimensions: Request Completeness, Evidence Validity, Structure Consistency, Narration Style, and Ethics Compliance"
- Retrieval-augmented generation (RAG): A technique that augments model outputs with retrieved documents to improve factuality. "TrustGPT~\cite{huang2023trustgpt} attempted to improve factuality based on RAG"
- Retrieval-induced drift: The tendency for a report’s focus to shift away from the original query due to injected external material. "inducing a kind of retrieval-induced drift in which information rather than blurs the problem definition and argumentation structure."
- Rubric items: Fine-grained checklist elements used to score report quality consistently. "operationalized into 130 fine-grained rubric items."
- Spearman rank correlation coefficient: A nonparametric measure of rank correlation between two rankings. "we used the Pearson correlation coefficient, the Spearman rank correlation coefficient, and pairwise agreement \cite{deepbench}."
- Structure Consistency: An evaluation dimension ensuring coherent organization (intro, body, conclusion, sections). "The evaluation is conducted across 5 dimensions: Request Completeness, Evidence Validity, Structure Consistency, Narration Style, and Ethics Compliance"
- TrustGPT: A research effort/benchmark aimed at trustworthy LLMs and improving factuality. "TrustGPT~\cite{huang2023trustgpt} attempted to improve factuality based on RAG"
- WebThinker Eval: An evaluation framework for deep research report generation and reasoning. "Additionally, DeepResearchBench~\cite{deepbench} and WebThinker Eval~\cite{webthinker} present Deep Research report-centric evaluations that assess literature-based report generation and multi-document reasoning"
Collections
Sign up for free to add this paper to one or more collections.