- The paper introduces a live, automated benchmark for generative research synthesis that continuously updates using recent high-quality ArXiv papers.
- It outlines a holistic evaluation framework that measures synthesis, retrieval quality, and citation verifiability through LLM-based metrics and semantic operators.
- Experimental results reveal that no system exceeds 19% across all metrics, emphasizing significant room for improvements in current generative research synthesis models.
DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
The paper introduces DeepScholar-Bench (-Bench), a live benchmark and automated evaluation framework for generative research synthesis systems. These systems aim to automate the process of retrieving, synthesizing, and citing prior research to generate long-form, cited summaries—specifically, related work sections for academic papers. Existing benchmarks are inadequate for this task: question-answering datasets focus on short-form factual responses, while expert-curated datasets are prone to staleness and contamination. -Bench addresses these limitations by providing a continuously updated, automated pipeline that sources queries from recent, high-quality ArXiv papers across diverse domains.
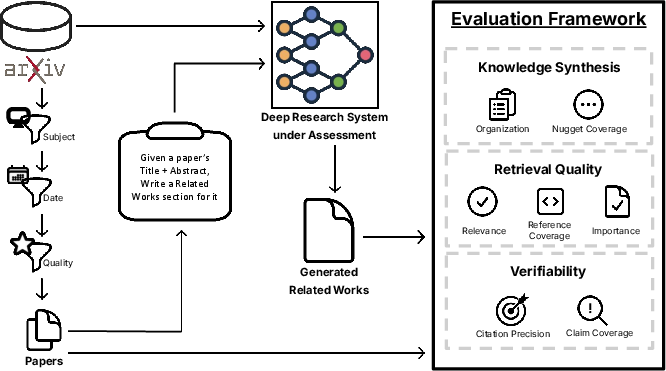
Figure 1: DeepScholarBench pipeline: automated extraction of paper metadata and related works, with holistic evaluation across synthesis, retrieval, and verifiability.
Dataset Construction and Task Definition
The benchmark task is to generate a related work section for a given paper, using only its title and abstract as input. The dataset is constructed by scraping recent ArXiv papers, filtering for quality (e.g., accepted at conferences, presence of related works section, well-formatted bibliography), and extracting all relevant metadata and citations. The pipeline is designed for continual updates, ensuring queries remain current and minimizing contamination from model training data.

Figure 2: -Bench dataset schema, detailing the structure of queries, references, and evaluation targets.
Holistic Evaluation Framework
Evaluating generative research synthesis requires metrics that capture the complexity of long-form synthesis, retrieval, and citation. The framework assesses system outputs along three dimensions:
- Knowledge Synthesis: Organization (LLM-based pairwise comparison to human exemplars) and Nugget Coverage (fraction of essential facts present, using automated nuggetization).
- Retrieval Quality: Relevance Rate (graded relevance via LLM judge), Document Importance (median citation count of references, normalized to human exemplars), and Reference Coverage (fraction of important references recovered).
- Verifiability: Citation Precision (percent of citations supporting their claims) and Claim Coverage (percent of claims fully supported by cited sources, with a sliding window for context).
The evaluation pipeline leverages LLM-as-a-judge methodology, validated by strong agreement with human annotators (>70% across metrics).
Reference Pipeline: DeepScholar-base
DeepScholar-base (-base) is a reference implementation for generative research synthesis, built atop the LOTUS API for efficient LLM-based data processing. The pipeline iteratively generates search queries, retrieves results, applies semantic filtering and top-k ranking, and aggregates the most relevant sources into a final report. Semantic operators (sem_filter, sem_topk, sem_agg) are used to optimize filtering, ranking, and summarization, providing accuracy guarantees and cost reductions.
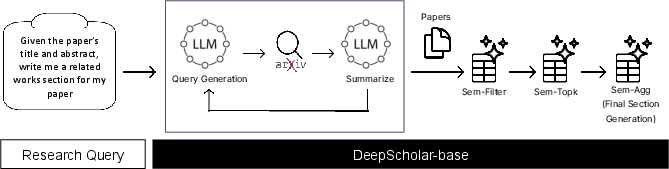
Figure 3: -base system architecture: iterative search, semantic filtering, ranking, and aggregation via LOTUS semantic operators.
Experimental Results and Analysis
A comprehensive evaluation is conducted across open-source systems (DeepResearcher, STORM, OpenScholar), search AIs (Llama-4, GPT-4.1, o3, Claude, Gemini), commercial systems (OpenAI DeepResearch), and -base. All systems are restricted to ArXiv search to control for retrieval corpus and avoid leakage.
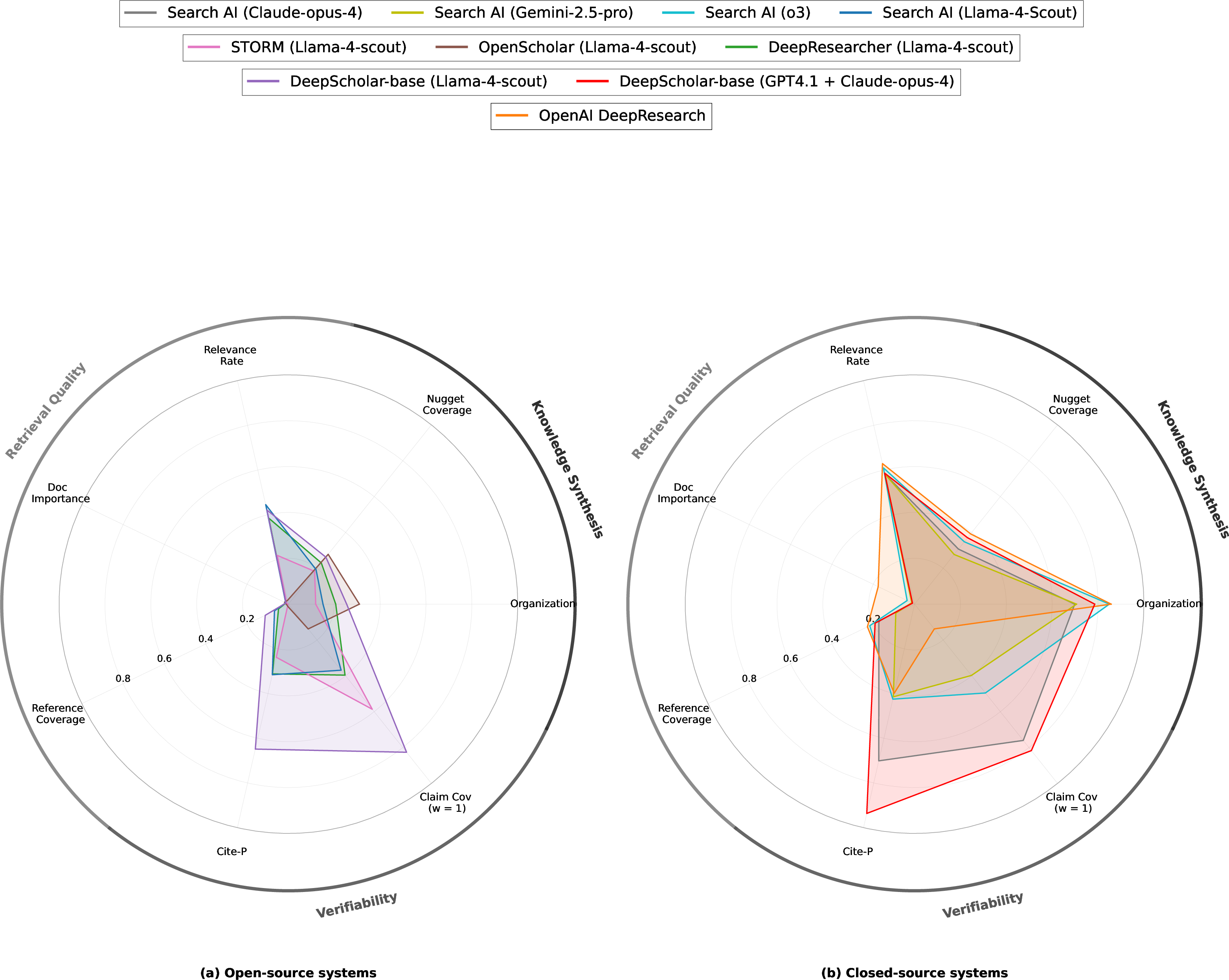
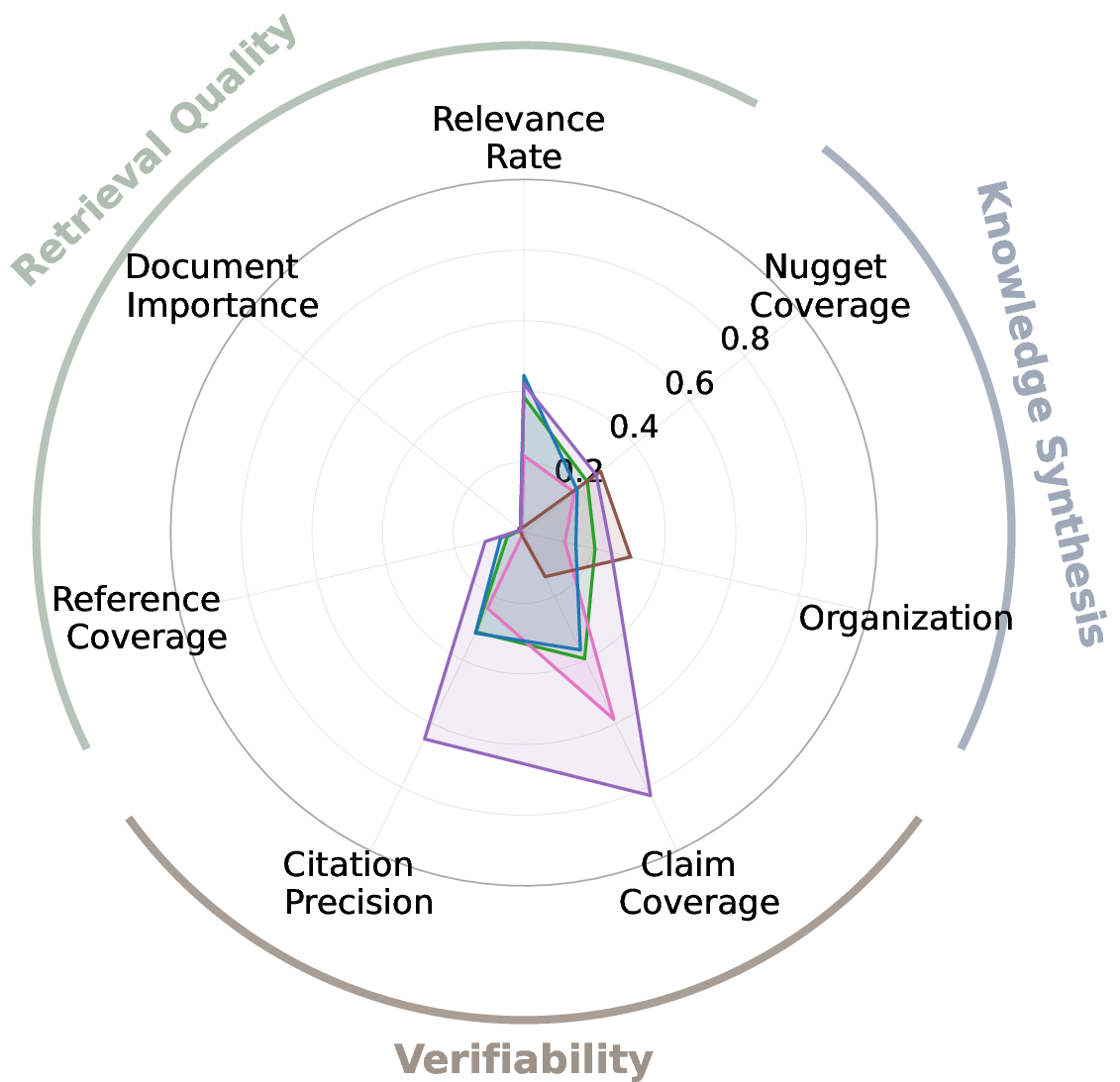
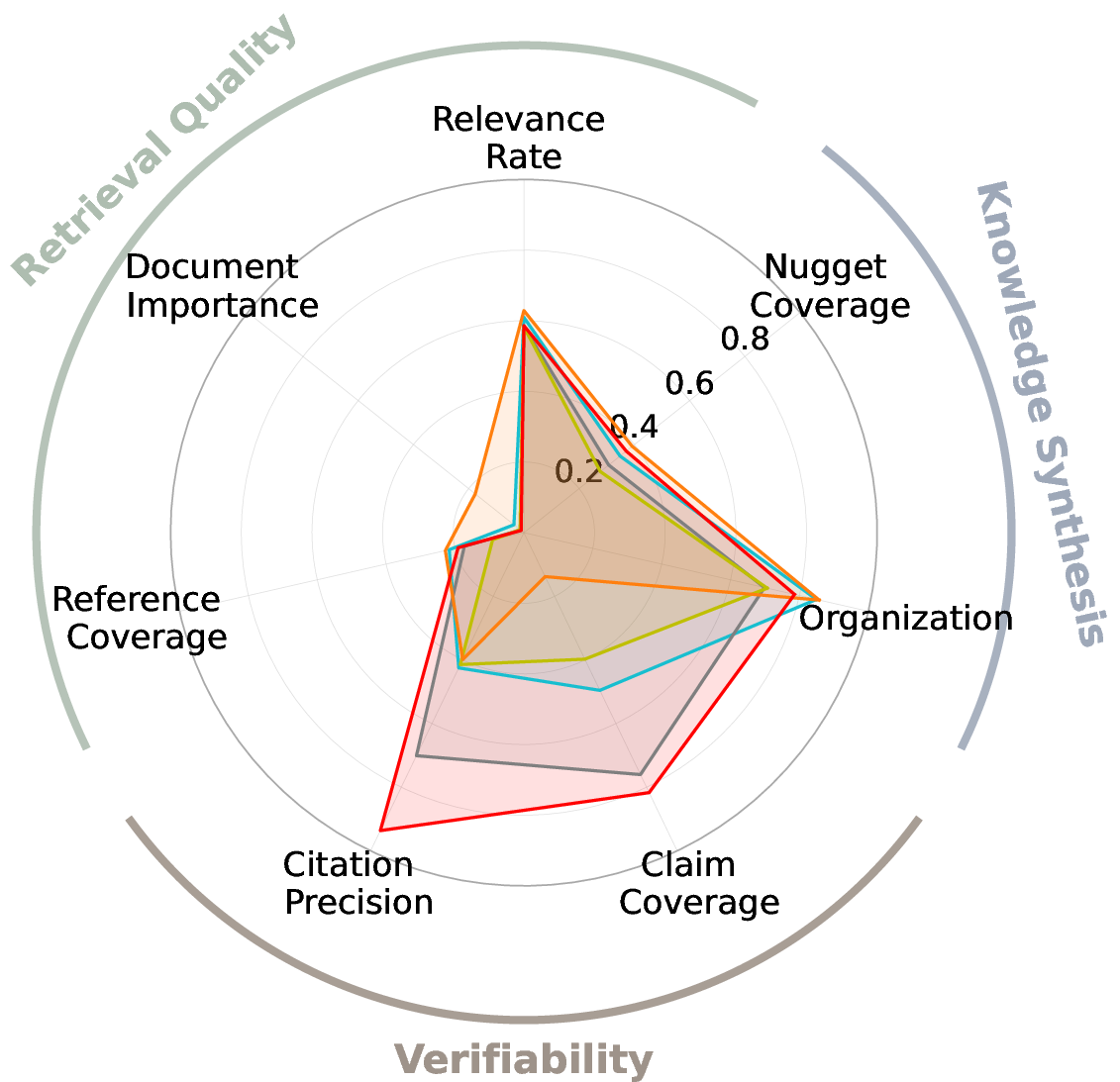
Figure 4: Comparative performance of generative research synthesis systems on -Bench, showing both open-source and proprietary models.
Key findings:
- No system exceeds 19% across all metrics, indicating substantial headroom for improvement.
- OpenAI DeepResearch achieves the highest Organization (.857) and Nugget Coverage (.392) among prior methods, but struggles with verifiability.
- -base consistently outperforms prior open-source systems and search AIs, and achieves up to 6.3× higher verifiability than DeepResearch.
- Document Importance and Reference Coverage remain low for all systems, highlighting challenges in retrieving notable sources.
- Oracle retrieval ablations show that synthesis quality improves with perfect retrieval, but Nugget Coverage remains unsaturated, indicating limitations in LLM synthesis even with ideal inputs.
Citation and Reference Analysis
The paper provides a detailed breakdown of citation importance in human-written exemplars, distinguishing between essential and non-essential references, and between ArXiv and non-ArXiv sources.
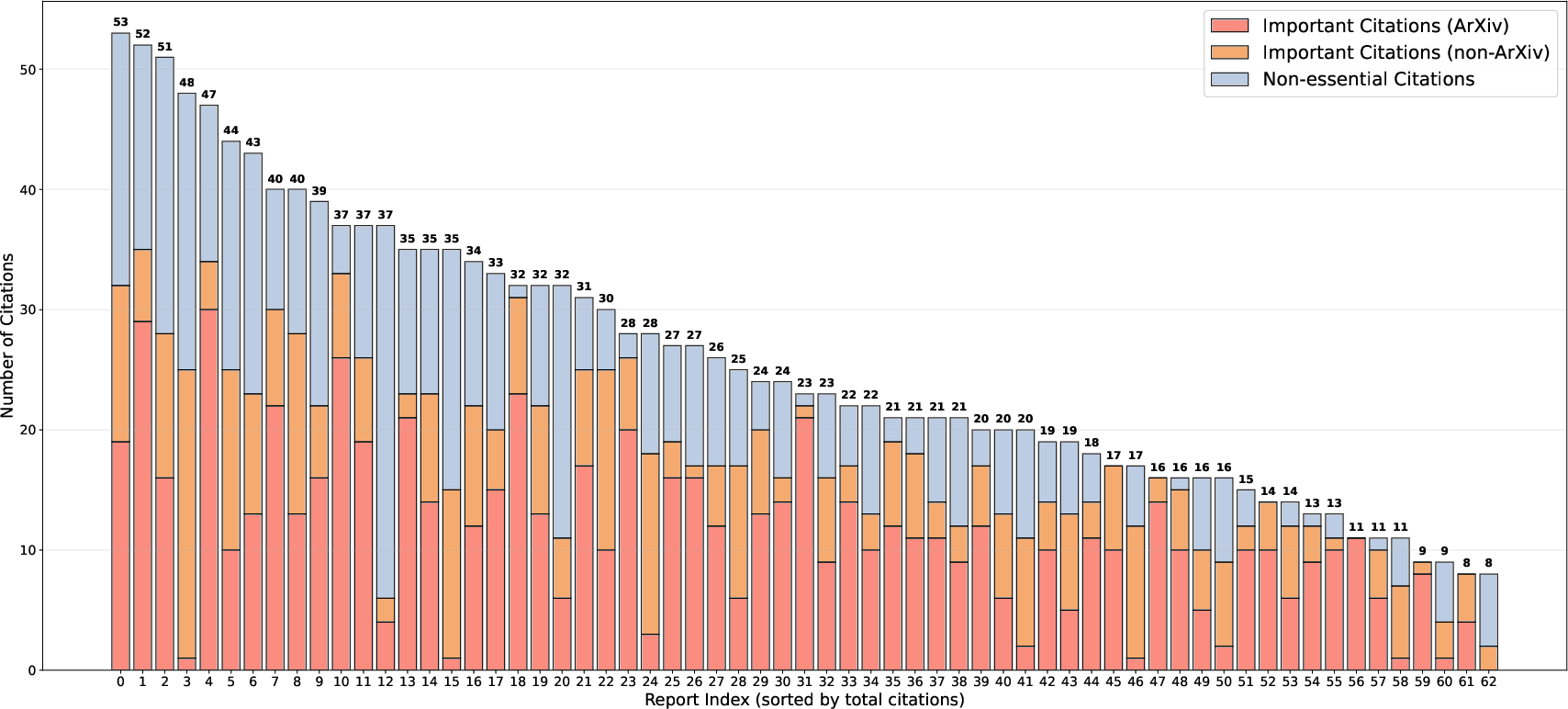
Figure 5: Citation importance breakdown in -Bench, color-coded by reference type and essentiality.
Document importance is further analyzed via citation count distributions, revealing a highly skewed landscape with a few highly-cited outliers.
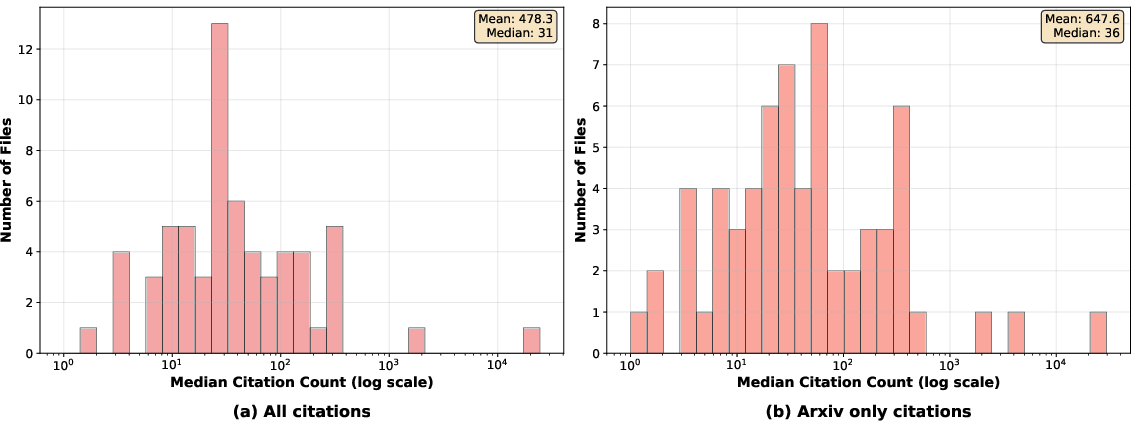
Figure 6: Log-scale distribution of citation counts for references in human-written exemplars, highlighting the skew toward highly-cited works.
Ablation Studies and Human Agreement
Ablation studies on retrieval APIs and oracle settings demonstrate that retrieval quality is a major bottleneck, but synthesis remains challenging even with perfect inputs. Human agreement studies confirm that LLM-based evaluation metrics are robust proxies for expert judgment.
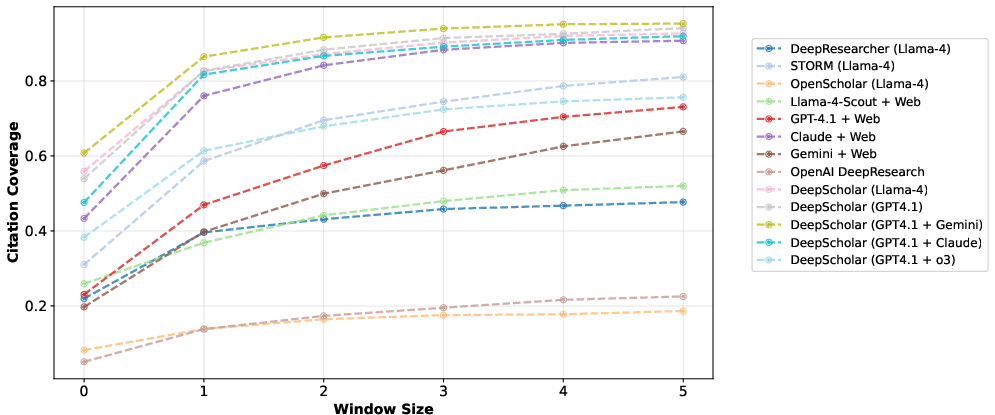
Figure 7: Ablation study on citation coverage with varying window sizes, illustrating the trade-off between strictness and recall.
Implications and Future Directions
DeepScholar-Bench establishes a rigorous, scalable foundation for benchmarking generative research synthesis. The persistent gap between system and human performance across all dimensions underscores the complexity of the task and the limitations of current LLMs in both retrieval and synthesis. The modular evaluation framework and reference pipeline facilitate reproducible, automated assessment and provide strong baselines for future research.
Practical implications include:
- Benchmarking agentic research systems: -Bench enables systematic comparison of agentic LLM pipelines, multi-agent frameworks, and retrieval-augmented generation architectures.
- Automated evaluation for long-form synthesis: The LLM-as-a-judge paradigm, validated by human agreement, supports scalable, cost-effective evaluation for complex tasks.
- Dataset extensibility: The automated pipeline allows for continual updates, supporting live benchmarking and minimizing contamination.
- Semantic operator optimization: The LOTUS-based approach demonstrates the utility of declarative, cost-optimized LLM data processing for retrieval, ranking, and summarization.
Theoretical implications include the need for improved compositional generalization, robust retrieval over dynamic corpora, and enhanced verifiability in LLM outputs. Future work should focus on integrating more sophisticated retrieval models, optimizing synthesis for coverage and factuality, and developing agentic systems capable of reasoning over diverse, evolving knowledge bases.
Conclusion
DeepScholar-Bench provides a live, automated benchmark and evaluation framework for generative research synthesis, addressing critical gaps in existing benchmarks. The reference pipeline, modular evaluation metrics, and systematic analysis reveal substantial opportunities for progress in retrieval, synthesis, and verifiability. The benchmark remains far from saturated, and its adoption will be instrumental in advancing the capabilities of AI systems for complex research tasks.