- The paper presents a novel dataset that captures dense, high-fidelity video trajectories of professional desktop applications with human-verified annotations.
- Its methodology leverages expert-designed workflows across 87 applications, recording 55 hours of 30fps video with sub-second precision for every UI interaction.
- The dataset enables improved spatial-temporal reasoning, action planning, and reward modeling, driving advances in training next-generation computer-use agents.
CUA-Suite: Scaling Computer-Use Agents With High-Fidelity Human Video and Dense Annotation
Motivation and Problem Context
The CUA-Suite project (2603.24440) directly addresses persistent bottlenecks in the training of general-purpose Computer-Use Agents (CUAs) for professional desktop environments. While recent advances in Vision-Language-Action Models (VLAMs) and GUI automation datasets have propelled progress in web and mobile settings, the desktop domain—especially professional-grade applications—remains underserved. Existing datasets are either restricted to sparse screenshots, suffer from noisy automated annotations, or rely on action discretization that removes the temporal dynamics essential for high-fidelity agent learning. The largest existing open dataset, ScaleCUA, offers only about 2 million screenshots (less than 20 hours of video-equivalent data), limiting the training of agents capable of fine-grained spatial and temporal reasoning. CUA-Suite systematically addresses these limitations with an emphasis on dense, human-verified video trajectories and comprehensive annotation.
Data Collection and Suite Composition
CUA-Suite is an ecosystem comprising three principal resources: VideoCUA, GroundCUA, and UI-Vision. The curation pipeline centers on human experts conducting naturalistic workflows within 87 diverse, primarily open-source desktop applications spanning 12 software categories (e.g., development, productivity, scientific, graphics, finance). Expert task design replaces procedural synthesis, ensuring that demonstrated workflows are contextually rich, goal-oriented, and representative of complex real-world use cases.
Human annotators record continuous 30 frames-per-second desktop video (amounting to approximately 55 hours across ∼10,000 tasks) while simultaneously capturing dense kinematic cursor traces and logging every mouse and keyboard action with sub-second precision. Keyframes extracted proximate to user events are then exhaustively labeled: every visible UI element receives a bounding box, a semantically meaningful text label, and categorical annotation where feasible; OCR is applied for elements with extended text. Approximately 50% of elements are further categorized into one of eight high-level semantic types to augment geometric ground truth. This annotation protocol yields more than 3.6 million element labels across 56,000 screenshots.
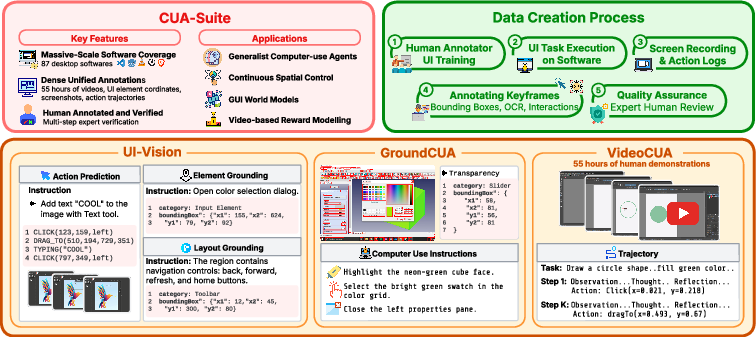
Figure 1: CUA-Suite’s ecosystem, comprising UI-Vision, GroundCUA, and VideoCUA, yields dense multimodal resources for perception, grounding, and planning in desktop computer-use agents.
Dataset Details: VideoCUA, GroundCUA, and UI-Vision
VideoCUA
VideoCUA constitutes the largest and most temporally continuous dataset of its kind, with 55 hours of human-demonstrated task execution in professional desktop applications (over 6 million video frames). Each trajectory integrates screen recordings, normalized kinematic cursor logs, and fine-grained, multi-layered reasoning annotation (averaging nearly 500 words per step). This format not only preserves all spatial and temporal cues but is also directly compatible with prevailing agent training pipelines (screenshot-action pairs, (st,at,st+1) world model data, or continuous trajectory learning frameworks).
GroundCUA
GroundCUA is constructed from human-verified bounding box annotations densely labeling all interactable UI elements in 56,000 desktop screenshots. This forms the empirical basis for training robust UI grounding models: high annotation density, pixel-level bounding boxes even for non-rectilinear and canvas-drawn widgets, functional captions, and broad coverage of application categories distinguish GroundCUA from mobile/web resources reliant on accessibility trees or DOM-based metadata.
UI-Vision
UI-Vision serves as a rigorous, desktop-centric benchmark for evaluating perception, layout reasoning, and action prediction in CUAs. It includes 450 expertly-annotated demonstration tasks, with three metrics: 1) Element Grounding (localizing UI elements from text queries), 2) Layout Grounding (structural grouping), and 3) Action Prediction (planning and execution). The benchmark reveals both substantial recent progress in grounding accuracy (top models now achieving ∼60% on basic/functional categories, up from ∼25% previously) and persistent failure in spatial reasoning splits (e.g., only ∼27% accuracy) across leading architectures.
Evaluation and Empirical Findings
Task-level action prediction via VideoCUA surfaces the persistent limitations of current action models such as OpenCUA-7B and -32B. In a 256-task evaluation spanning all 87 applications (nearly 2,000 action predictions), OpenCUA-32B achieves only 37.7% prediction accuracy within a 50-pixel threshold, while the 7B variant achieves 16.5%. Human evaluation (N=576 steps) exposes a further gap: action intent is correct in 85.9% of steps, but grounding to the correct UI element is less than 53%, with application-level stepwise accuracy highly variable (ranging from 3.6% to 73.3% across domains).
Qualitative Failure Analysis
Complex desktop GUIs, especially creative or scientific tools with non-standard interaction paradigms (e.g., Krita, FreeCAD, Inkscape, OBS Studio), provoke systematic prediction errors. The most common failures include cross-panel confusion, context-inappropriate tool selection, and inability to disambiguate visually similar elements distributed across spatially separated regions.
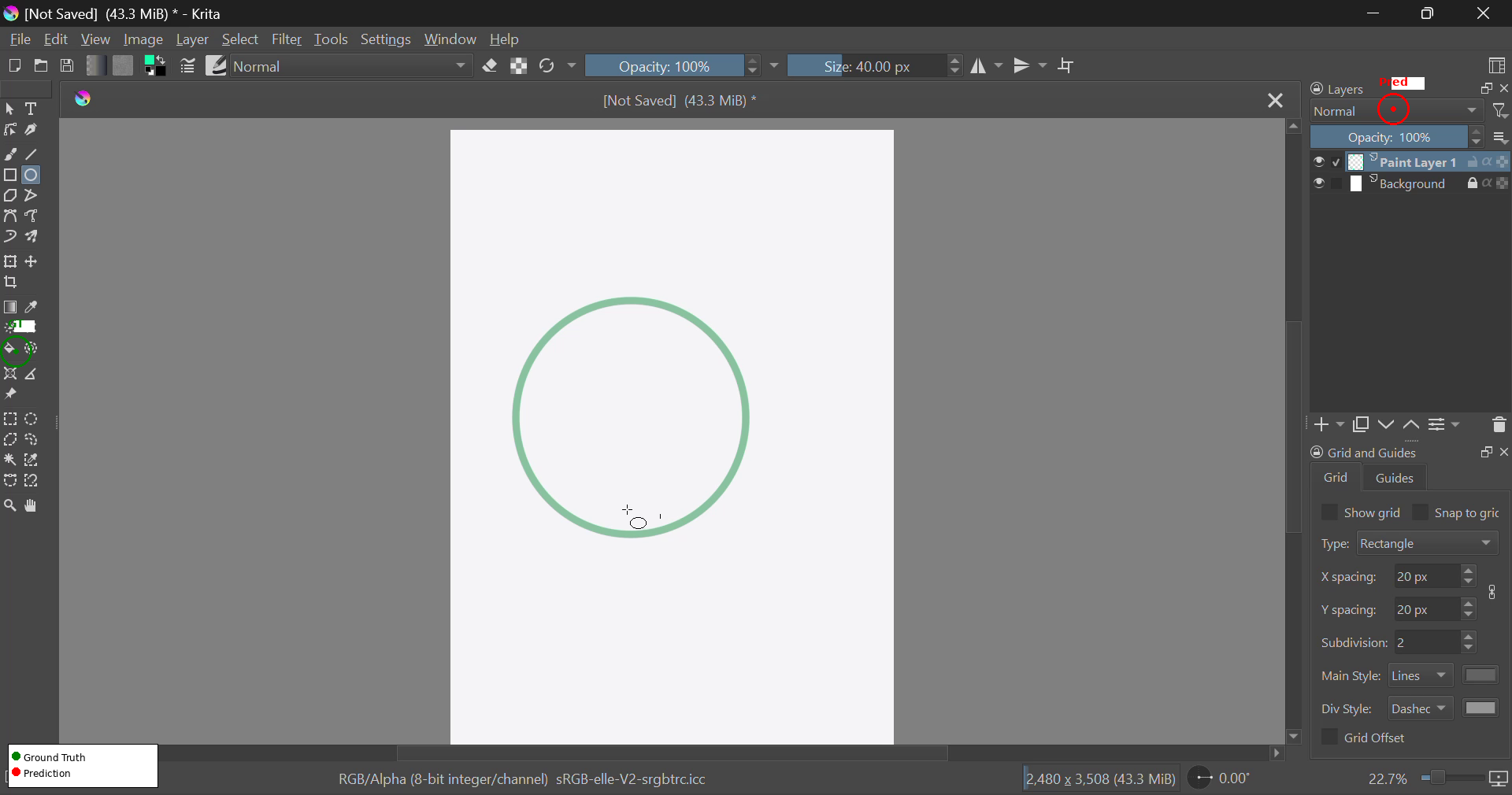
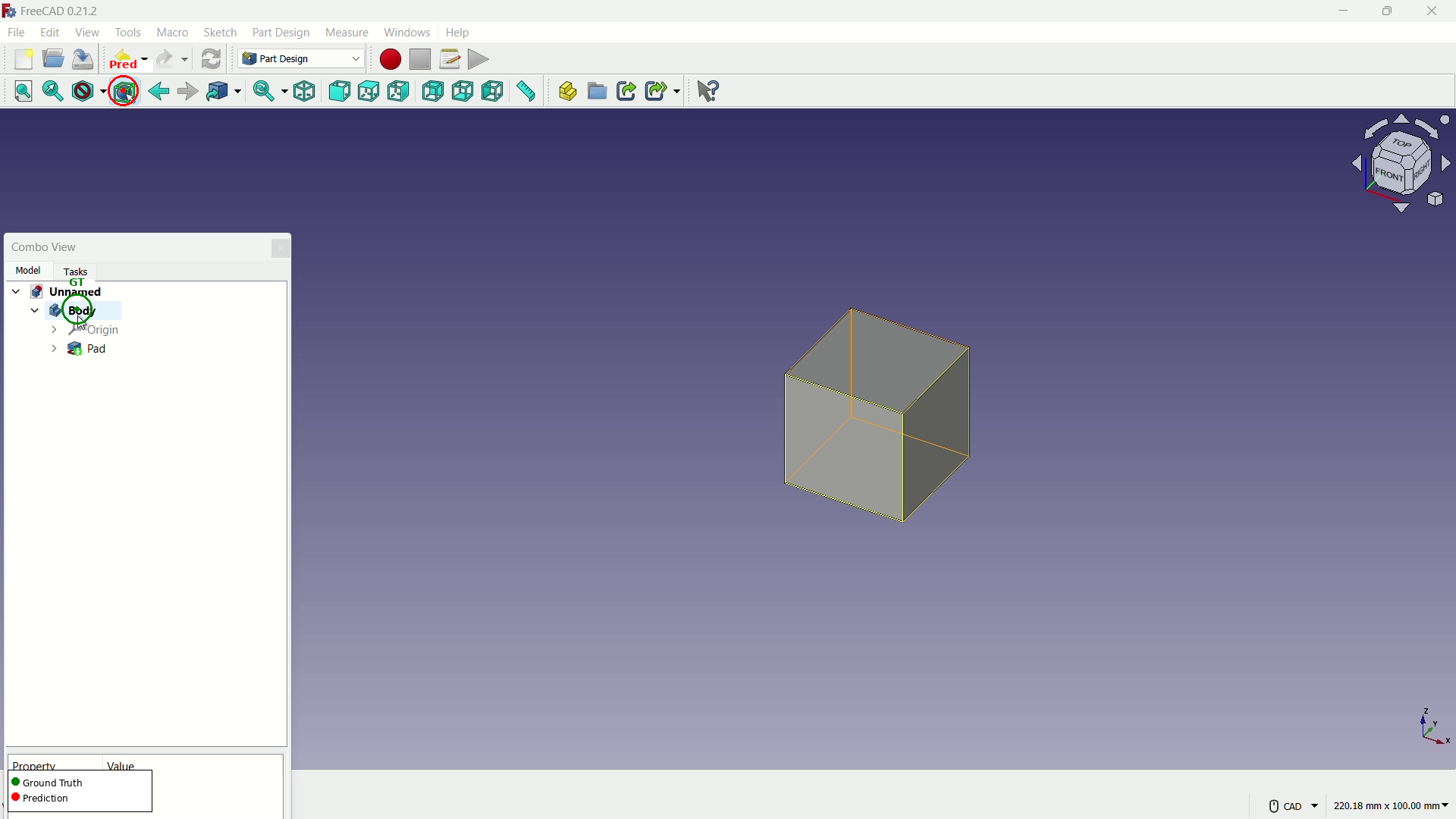
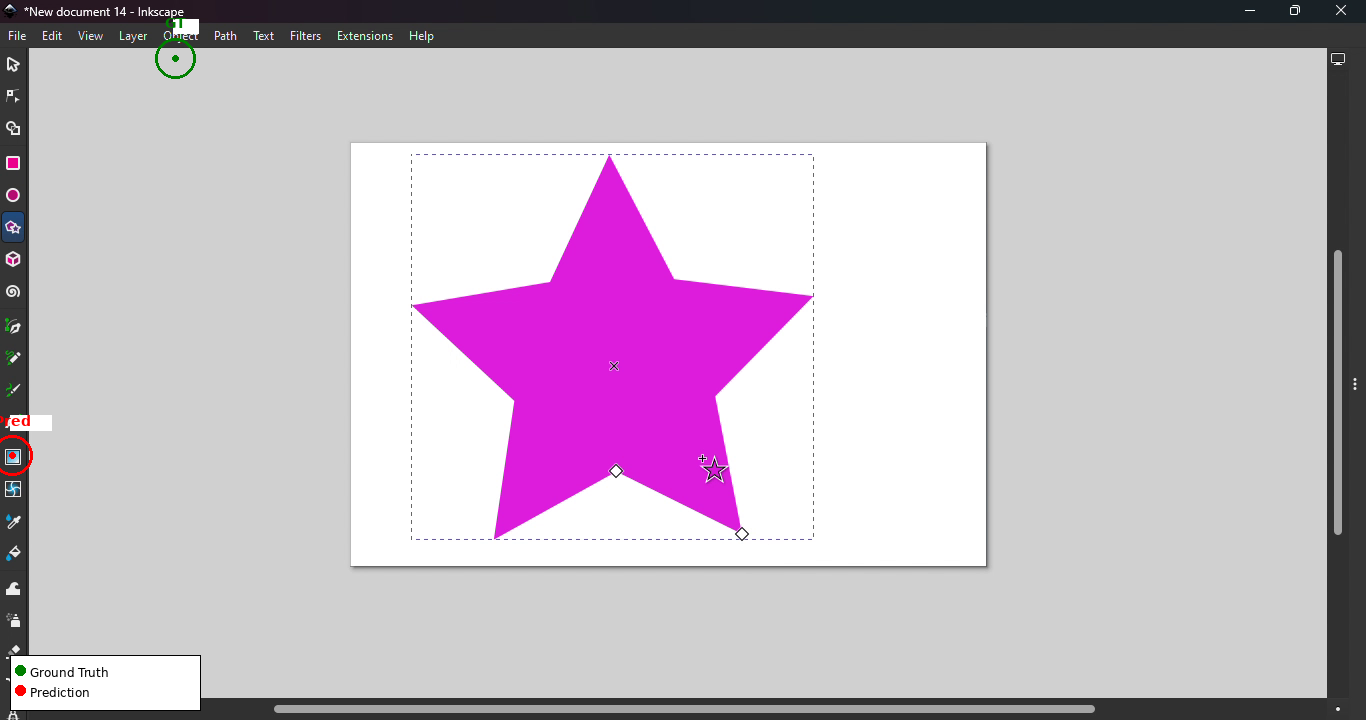
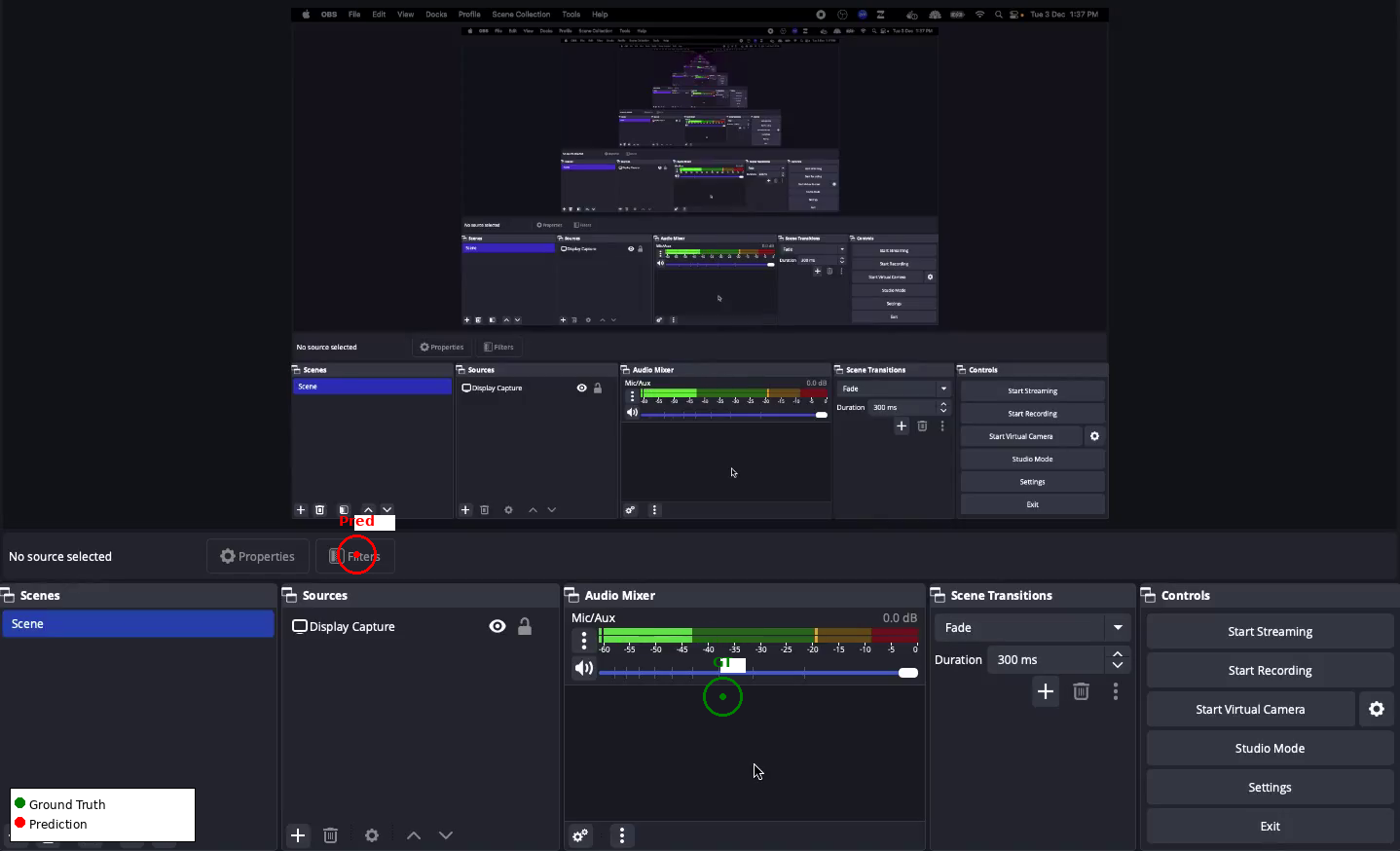
Figure 2: Illustration of cross-panel confusion in Krita; model predicts the Layers panel rather than the intended tool icon—a canonical error case in dense desktop UIs.
Causal Signal, Annotation Density, and Reasoning
Multi-layered reasoning annotations—derived using LLMs such as Claude-Sonnet-4.5—enrich each action trajectory with stepwise chain-of-thought (CoT) rationales, direct action descriptions, observations, and post-hoc reflections. This supports both supervised action prediction and enables trajectory-level reward modeling, self-correction, and instruction-tuning datasets (700K instances for applications such as GroundNext).
Practical and Theoretical Implications
CUA-Suite’s dense, temporally continuous corpus enables progress along several axes:
- Generalist screen parsing: Densely labeled, canvas-resolved screenshots provide supervision for vision-based parsers robust to custom widgetry absent in HTML/DOM-derived resources.
- Continuous spatial control: Kinematic cursor traces and frame-dense video enable training of feedback-driven imitation or RL models for smooth, human-like GUI navigation—not just coordinate prediction.
- Action-conditioned visual world models: Dense (st,at,st+1) triplets from high-fidelity video support the nascent field of action-conditional GUI simulators and lookahead planning.
- Video-based reward modeling: Confirmed expert trajectories and CoT annotation supply positive and fine-grained supervision for learning reward functions that generalize across desktop domains without task-specific engineering.
By maximizing data generality and annotation exhaustiveness, the resource remains future-proof to as-of-yet unanticipated agent architectures and training regimes.
Future Research Directions
CUA-Suite unlocks a spectrum of research directions currently limited by data sparsity, including but not restricted to:
- Training and evaluating large multimodal models (MLLMs) capable of true generalization to arbitrary desktop software
- Robust world modeling for rapid model-based planning in open-ended GUI environments
- Development of reliable, actionable, and explainable reward models for RL in computer-use contexts
- Fine-grained error analysis of grounding and planning in complex panel-based UIs, linking model failures to concrete annotation artifacts
Conclusion
CUA-Suite (2603.24440) establishes a new data-centric paradigm for the development, evaluation, and diagnosis of professional desktop computer-use agents. By unifying high-fidelity human video demonstrations, exhaustive UI annotation, and rigorous task benchmarks within a fully open-source ecosystem, this resource exposes the limits of current foundation models and provides the foundation for next-generation agents capable of robust perception, grounding, and planning across the full spectrum of desktop software. Its application potential spans not only benchmarking and training but also drives emerging lines of research in generalist parsing, continuous control, simulation-based planning, and reward learning.