VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos (2510.19488v1)
Abstract: Training computer-use agents requires massive amounts of GUI interaction data, but manually annotating action trajectories at scale is prohibitively expensive. We present VideoAgentTrek, a scalable pipeline that automatically mines training data from publicly available screen-recorded videos at web scale, eliminating the need for manual annotation. Our approach addresses a key challenge: raw videos contain implicit demonstrations but lack explicit action labels. To solve this, we develop Video2Action, an inverse dynamics module (IDM) with two components: (1) a video grounding model that detects and localizes GUI actions with precise temporal boundaries and context, and (2) an action-content recognizer that extracts structured parameters like click coordinates and typed text with high fidelity. Applied to 39,000 YouTube tutorial videos, our pipeline generates 1.52 million interaction steps automatically. We leverage this data through continued pretraining followed by supervised fine-tuning. On OSWorld-Verified, our approach improves task success rates from 9.3% (SFT-only baseline) to 15.8%, a 70% relative improvement. On AgentNetBench, step accuracy increases from 64.1% to 69.3%. Our results demonstrate that passive internet videos can be transformed into high-quality supervision for computer-use agents, providing a scalable alternative to expensive manual annotation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to teach AI “computer-use agents” how to use a computer—things like clicking buttons, typing in boxes, scrolling pages, and navigating apps—by simply watching screen-recorded tutorial videos from the internet. The big idea is to turn regular YouTube how-to videos into training data, without hiring people to label every click and keystroke.
What questions does the paper try to answer?
The research focuses on three simple questions:
- Can we automatically find and learn the exact actions people do in screen-recorded videos (like where they clicked or what they typed)?
- Can we turn those videos into clean, step-by-step instructions that an AI can learn from?
- Will training on these video-derived steps actually make computer-use agents better at solving tasks on real computers?
How does it work? (Methods explained simply)
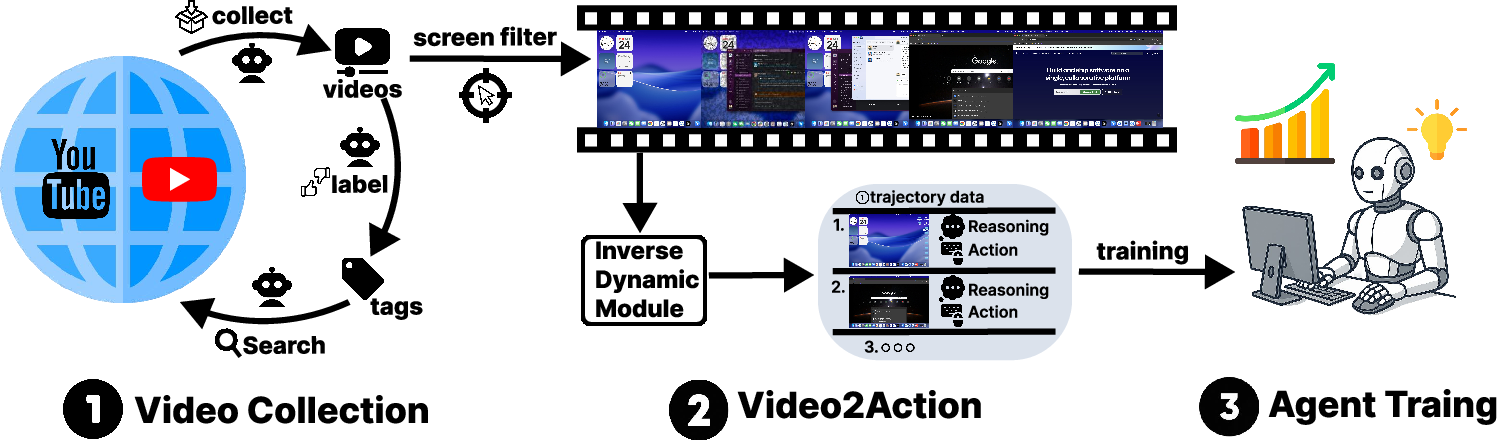
Think of the system like a careful observer watching a tutorial and writing down a recipe of everything that happens. The pipeline is called VideoAgentTrek, and it has three main parts:
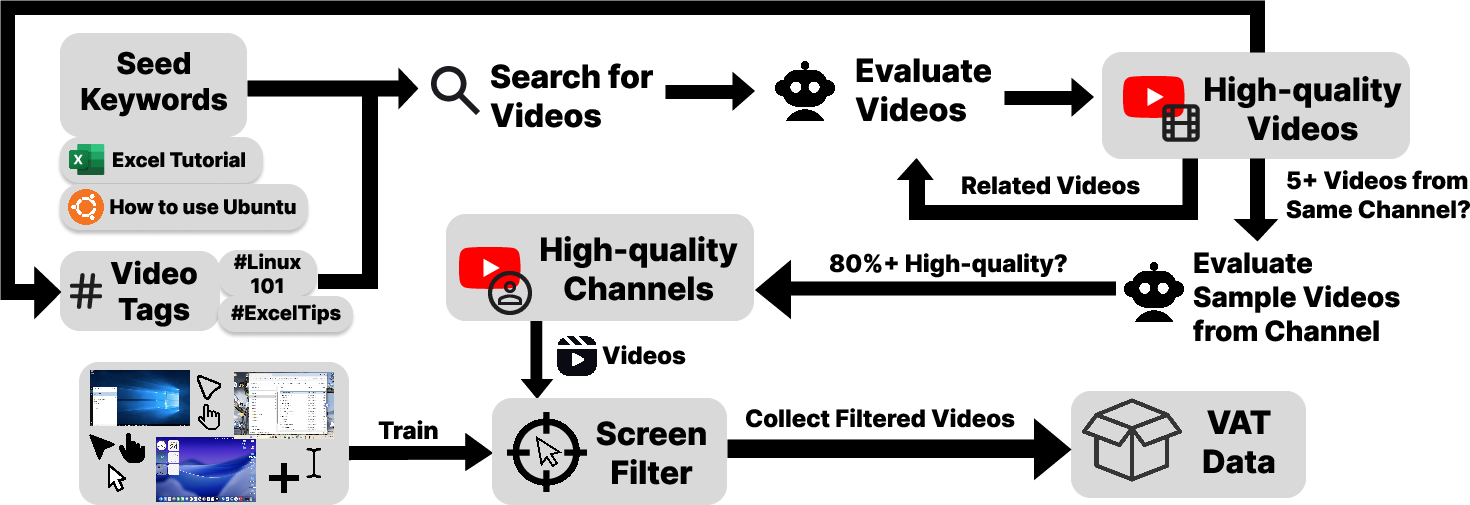
1) Collect and filter videos The team gathers lots of YouTube tutorials (like “How to use Excel” or “Windows tips”). Then they use a tool called ScreenFilter to keep only the parts of each video where you can see a mouse cursor on the screen. This helps focus on real computer actions, not just talking or slides.
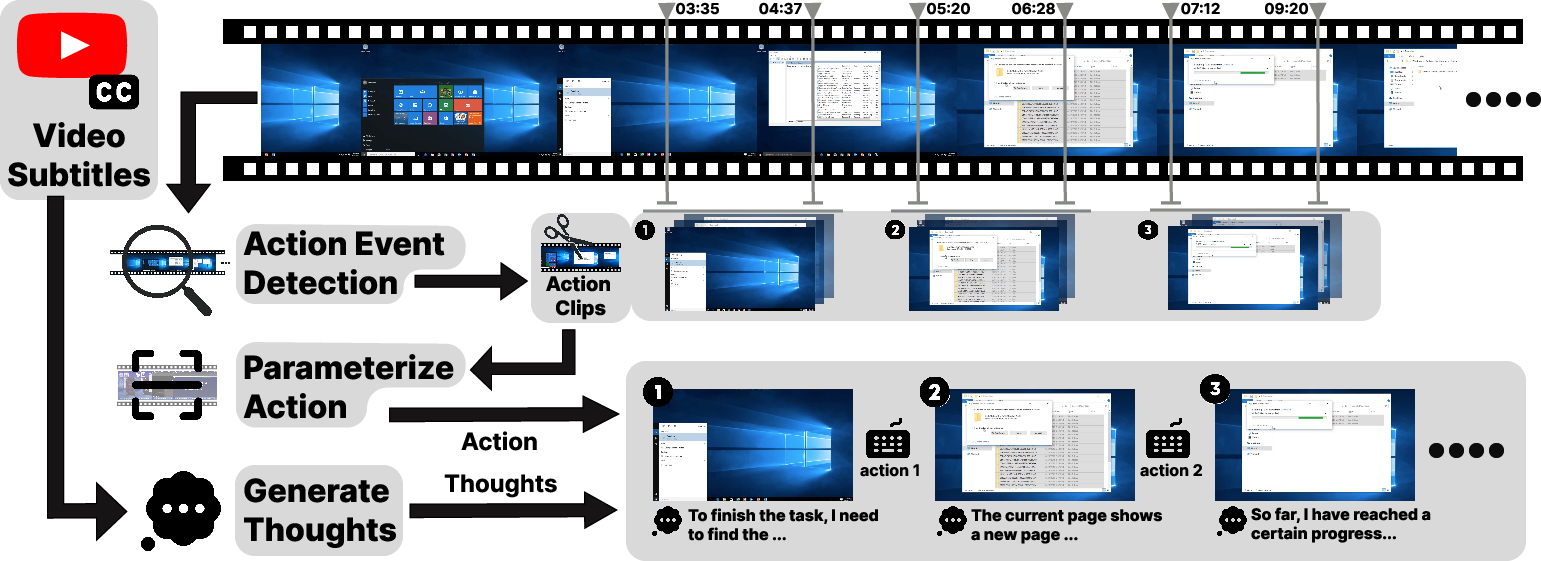
2) Turn video into actions (Video2Action) This is the clever part. It works like watching over someone’s shoulder and figuring out exactly what they did and when:
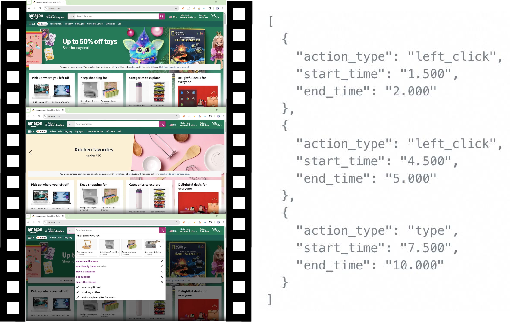
- Action event detection: The model scans the video and finds the exact time ranges where actions happen, for example “a click happened between 1.5s and 2.0s” or “typing happened from 3.5s to 5.5s.”
- Action parameterization: For each detected action, it extracts the details needed to reproduce it, like the (x, y) screen coordinates of a click or the literal text that was typed.
In short, it converts “implicit demonstrations” (just video) into “explicit instructions” (a step with a screenshot, action type, and precise action details).
3) Train the agent The team uses the mined steps to teach a vision-LLM in two stages:
- Stage 1: Continued pretraining on the big pile of auto-extracted video steps to learn general UI patterns.
- Stage 2: Supervised fine-tuning on a smaller, clean dataset of human-annotated examples to sharpen accuracy.
A few helpful terms in everyday language:
- GUI (Graphical User Interface): The visual stuff you click and type into—buttons, menus, search boxes.
- Inverse dynamics: Imagine seeing the “before” and “after” of a screen and asking, “What action caused that change?” It’s inference from effects back to actions.
- Parameters: The exact ingredients of an action—like the exact point you clicked or the exact text you typed.
What did they find and why does it matter?
Key results:
- Scale: From 39,000 YouTube videos, the system automatically created about 1.52 million usable action steps. That’s a huge, diverse dataset spanning many apps and operating systems.
- Better performance:
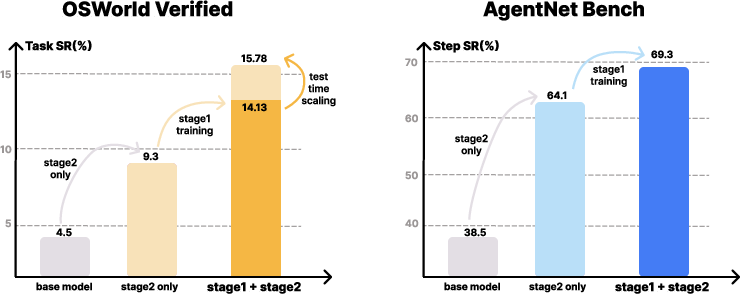
- On OSWorld-Verified (an online, real-computer benchmark), success rate rose from 9.3% to 15.8% after using their video-based pretraining—about a 70% relative improvement.
- On AgentNetBench (an offline benchmark), step accuracy increased from 64.1% to 69.3%.
- Longer plans help: Models trained on long, multi-step video trajectories improved further when given more steps to act (from 20 to 50), showing they learned to plan better over longer tasks.
Why it matters:
- It proves that “passive” internet videos can become “active” training data.
- It reduces the need for expensive, manual labeling of clicks and keystrokes.
- It helps agents handle messy, real-world computer screens more robustly.
What’s the bigger impact?
This approach could make it much easier and cheaper to build AI assistants that can actually use computers—opening files, filling forms, configuring settings, and completing multi-step workflows across many apps. Because the method scales with public videos, it can cover a wide range of software and interfaces. The team also released tools (ScreenFilter and Video2Action) so other researchers can build on this work. Over time, this could lead to more capable, trustworthy computer-use agents that help with everyday tasks, office work, and professional workflows without needing massive hand-crafted datasets.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, structured to guide future research.
- Temporal precision metrics for event detection are under-specified: no reporting of temporal IoU, boundary error (ms), or latency tolerance per action type; evaluation uses “any overlap,” which does not reflect millisecond-level localization the paper claims.
- Action parameter accuracy is only assessed via small-scale manual review (n=500) without quantitative pixel-error for clicks, path error for drags, scroll magnitude/direction, or character-level accuracy for typed text; a rigorous, ground-truthed benchmark is missing.
- Poor performance on keystroke-only and drag actions (low recall/accuracy) is acknowledged but not addressed; methods to recover keypress sequences (modifiers, shortcuts), drag paths, selection ranges, and window management actions remain open.
- Scroll parameterization lacks magnitude/direction extraction; click parameterization ignores double/right-click and long-press semantics; hover and focus changes are not modeled; composite actions (e.g., select-then-type) are not supported.
- End-to-end trajectory correctness (does the predicted action sequence reproduce the observed UI transition when executed?) is not evaluated; automated replay validation or execution-in-simulator checks are absent.
- ScreenFilter may bias data toward mouse-visible segments and exclude valuable keyboard-centric interactions; its precision/recall, false-positive/negative rates, and impact on downstream distribution shifts are not quantified.
- Cursor detection robustness across OS themes, cursor styles, DPI/scaling, multi-monitor setups, small UI elements, and cursor occlusions is not evaluated; failure modes and mitigation strategies are unclear.
- Dataset composition skews toward OS-level operations; coverage gaps across application categories, professional tools, and web workflows are not analyzed for their effect on generalization.
- Language and locale diversity (e.g., non-English tutorials, non-Latin scripts, RTL layouts) are not reported; typed text recognition fidelity across languages and fonts remains unexplored.
- Legal/ethical considerations of mining YouTube content (copyright, consent, privacy) and safeguards against extracting sensitive information (e.g., passwords, emails) are not addressed.
- The inner-monologue component uses GPT-5 Medium, but there is no ablation quantifying its contribution to performance, error recovery, or long-horizon planning; reproducibility and cost/access constraints are not discussed.
- No comparison against specialized temporal localization baselines (e.g., BMN, Grounding-MD, Video-GroundingDINO) to justify the choice of a VLM-based detector for millisecond precision.
- Training data for Video2Action is sourced from OpenCUA logs (instrumented domain) while evaluation targets web tutorials (un-instrumented domain); domain gap analysis and adaptation methods are missing.
- Noise in mined trajectories is acknowledged, but there is no systematic measurement of label noise rates, nor robust training strategies (e.g., curriculum, confidence weighting, denoising via consistency checks) to mitigate it.
- The pipeline does not enforce or check GUI element semantics (widget identity, role, affordances); mapping coordinates to UI elements (via accessibility APIs or layout parsing) and learning element-centric policies remain open.
- Typed text extraction approach (OCR vs. text-field focus inference) is unspecified; character-level accuracy and error types (confusions, insertions, deletions) are not measured; post-processing corrections are absent.
- Screenshot selection for each step (how “representative” frames are chosen) is under-defined; the effect of frame selection policy on grounding and policy learning is untested.
- Deduplication of videos/steps (near-duplicate tutorials, repeated workflows) is not described; potential overfitting to common patterns and its impact on benchmark diversity is unexplored.
- Scaling laws beyond the reported token counts (e.g., 26B → 100B+) and diminishing returns or saturation points are unstudied; optimal mix ratios between mined, human, and grounding data are not explored.
- Test-time scaling benefits are shown only up to 50 steps on OSWorld-Verified; extended budgets, curriculum planning, and dynamic budget allocation policies are open questions.
- Failure-mode analysis on OSWorld-Verified and AgentNetBench is missing (e.g., which task categories benefit/hurt from video pretraining? typical error chains? recovery behaviors?).
- Cross-OS generalization (Windows/macOS-heavy training vs. Ubuntu evaluation) is not analyzed; targeted domain adaptation techniques (style transfer, layout normalization, OS-specific affordance learning) remain unexplored.
- Pipeline efficiency, throughput, and cost (video processing time per hour, detector/recognizer inference latency, GPU-hours) are not reported; practical scaling bottlenecks and optimization levers are unclear.
- Dataset release constraints are not discussed; if raw videos cannot be shared, guidance on reproducible crawling protocols, metadata, and synthetic labels to enable replication is needed.
- Integrating reinforcement learning, preference optimization, or interactive self-play to refine policies from mined trajectories is left unexplored; the paper focuses on supervised pretraining/finetuning only.
- Use of audio and transcripts is limited to monologue generation; leveraging audio cues (click sounds, narration alignment) for event detection/parameterization and intent grounding remains untapped.
- Automated quality control (e.g., verifying that predicted actions cause consistent UI changes via replay/vision checks) is not implemented; a scalable validation and filtering framework would reduce noise.
- Safety and reliability in real deployments (misclick avoidance, guardrails against destructive actions, confirmatory steps) are not studied; risk-aware policy learning from noisy web data is an open area.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be implemented now, leveraging the paper’s released tools (ScreenFilter and Video2Action), training recipe (video-driven pretraining + supervised fine-tuning), and demonstrated performance gains.
- Video-to-dataset mining for GUI agents
- Sectors: software, AI tooling, education
- What: Use ScreenFilter to extract GUI segments and Video2Action to auto-label clicks, scrolls, and typed text from screen-recorded tutorials, producing large-scale training corpora without manual annotation.
- Products/workflows: “Data factory” pipelines for continuous ingestion of public/enterprise tutorial videos; turnkey dataset generation for model vendors.
- Assumptions/dependencies: Content licensing and data rights for scraping/processing; adequate video quality (≥720p increases accuracy); compute for pretraining; action parameterization works best for pointer-centric actions (click/scroll) and moderate for typing, weaker for drag/press.
- Performance boosting of existing computer-use agents via continued pretraining
- Sectors: software automation, enterprise RPA
- What: Apply the two-stage recipe (video pretraining + SFT) to existing VLM-based agents to improve robustness and task success (e.g., OSWorld-Verified +70% relative gain reported).
- Products/workflows: Vendor upgrade paths where customer-specific RPA agents are periodically pretrained on curated video corpora, then SFT on company SOP demos.
- Assumptions/dependencies: Domain match between training videos and deployment environments; consistent windowing/resolution; sufficient GPU budget.
- Video-to-macro/RPA script generation for repetitive workflows
- Sectors: enterprise IT, operations, daily life
- What: Convert a single tutorial video into executable step sequences (coordinates + typed content) to automate routine tasks across web/desktop apps.
- Products/workflows: “Watch & replicate” assistants that mirror tutorial steps in target environments; macro libraries generated from how-to videos.
- Assumptions/dependencies: UI alignment between source video and user environment (OS/app version, layout scaling); element robustness beyond raw coordinates; guardrails for safe execution.
- Fine-grained tutorial indexing and “jump-to-step” navigation
- Sectors: education, media platforms
- What: Use the event detector to timestamp actions (e.g., “click Settings,” “type query”) enabling users to jump directly to relevant steps.
- Products/workflows: Tutorial platforms offering action-aware search; learning management systems with step-level navigation.
- Assumptions/dependencies: Accurate temporal event detection; ASR quality to pair rationale/intent; stable UI cues in videos.
- Automated step-by-step documentation from videos
- Sectors: developer tooling, customer success, technical writing
- What: Generate structured guides with screenshots, action parameters, and inner monologues summarizing intent and expected state changes.
- Products/workflows: Doc generators for release notes, onboarding guides, and help center articles produced from internal demo recordings.
- Assumptions/dependencies: Reliable ASR/transcripts; correctness of inferred parameters; human-in-the-loop review for compliance and clarity.
- Software QA: Derive test cases from internal demo videos
- Sectors: software engineering, QA
- What: Convert product demo videos to reproducible test sequences for regression testing, smoke tests, or UI change detection.
- Products/workflows: CI pipelines that auto-generate GUI test suites; differential analysis across releases.
- Assumptions/dependencies: Mapping coordinates to elements (DOM/Accessibility APIs) to reduce flakiness; environment-contingent selectors; version-controlled recording.
- Helpdesk and IT ops assistants that execute documented procedures
- Sectors: IT services, customer support
- What: Train agents on support/tutorial videos to automatically perform frequent tasks (e.g., OS settings, software installs).
- Products/workflows: Triage bots that follow verified playbooks; semi-autonomous “runbook executors.”
- Assumptions/dependencies: Strong guardrails, sandboxing, and audit logs; environment parity; role-based access controls.
- Accessibility aids for motor-impaired users
- Sectors: healthcare, assistive tech, daily life
- What: Agents that reproduce tutorial steps as assistive actions (clicks/typing) under user voice or intent prompts.
- Products/workflows: Voice-driven desktop assistants that execute UI interactions for users.
- Assumptions/dependencies: High reliability and safe execution; privacy protections; user override mechanisms; regulatory compliance.
- Academic dataset augmentation for GUI grounding and temporal event detection
- Sectors: academia (CV/ML/HCI)
- What: Use open-source tools to produce structured datasets for research on UI grounding, inverse dynamics, and long-horizon planning.
- Products/workflows: Public benchmarks built from curated tutorial corpora; reproducible pipelines shared across labs.
- Assumptions/dependencies: Rigorous curation; bias analysis (OS/app skew); annotation QA for evaluation subsets.
- Cybersecurity training: Simulate risky UI workflows to harden agents
- Sectors: security
- What: Create adversarial or “unsafe” action sequences from real-world videos (e.g., phishing flows) to train agents to avoid or flag risky behavior.
- Products/workflows: Red-team corpora for safe agent alignment; policy checks embedded in action planners.
- Assumptions/dependencies: Safe sandbox environments; clear policies on restricted actions; continuous monitoring.
Long-Term Applications
Below are more ambitious use cases that would benefit from further research, scaling, and productization, including improved parameter extraction, cross-platform generalization, and governance frameworks.
- General-purpose, cross-platform computer-use agents
- Sectors: software, productivity
- What: Unified agents that reliably operate across OS (Windows/macOS/Linux/Android/iOS) and hundreds of apps, with long-horizon planning skills learned from web-scale videos.
- Products/workflows: “Universal desktop copilots” for knowledge workers; AI IT admins for routine maintenance.
- Assumptions/dependencies: Larger, more diverse corpora (including mobile); better element-level grounding; advanced safety/alignment layers.
- Continuous learning systems that ingest new videos to update skills
- Sectors: enterprise, SaaS
- What: Always-on “skill refresh” pipelines that watch newly published tutorials, incrementally improving agents’ competence.
- Products/workflows: Managed services providing skill updates and capability catalogs; enterprise skill registries.
- Assumptions/dependencies: Content licensing and opt-in mechanisms; governance for model drift; reproducibility and versioning.
- Low-code/no-code RPA from videos with resilient element binding
- Sectors: RPA, business operations
- What: Business users supply screen recordings or public tutorials; system compiles robust, element-based scripts rather than raw coordinates.
- Products/workflows: Video-to-RPA compilers integrated with DOM/accessibility APIs; action graphs with fallback policies.
- Assumptions/dependencies: Reliable target-element detection and cross-version matching; semantic UI models; error recovery strategies.
- Organization-specific onboarding copilots
- Sectors: HR, operations, IT
- What: Agents that learn company SOPs from internal training videos and automate onboarding tasks (e.g., account setup, app configuration).
- Products/workflows: Private skill libraries; policy-aware executors; compliance logging.
- Assumptions/dependencies: Access control, data privacy; standardized recording practices; strong audit trails.
- Policy and governance frameworks for video-mined supervision
- Sectors: policy, legal, platform governance
- What: Standards for consent, licensing, attribution, revocation, and fair use when converting public videos into training data.
- Products/workflows: Platform-level opt-in/out flags; creator monetization programs; provenance tracking for datasets and models.
- Assumptions/dependencies: Stakeholder alignment (platforms, creators, researchers, enterprises); enforcement tools and independent audits.
- Cross-device mobile agent training (smartphones/tablets)
- Sectors: mobile, consumer software
- What: Extend Video2Action to touch gestures (tap, pinch, swipe), notifications, and device settings from mobile tutorial videos.
- Products/workflows: Mobile copilots performing user-taught tasks; app-agnostic assistants for mobile productivity.
- Assumptions/dependencies: High-quality mobile recordings; gesture parameterization; handling device-specific overlays and permissions.
- Accessibility at scale for complex workflows
- Sectors: healthcare, public sector
- What: Agents that handle multi-step tasks for motor-impaired users (tax filing, medical portals), trained from step-rich tutorials and professional demos.
- Products/workflows: Certified assistive services; personal “digital aides.”
- Assumptions/dependencies: Robust fail-safes; legal and ethical safeguards; user trust and control.
- Agent-centric software QA and UI regression analytics
- Sectors: software engineering
- What: Agents trained from usage videos detect UI regressions and produce developer-ready reports (action-level diffs, broken paths).
- Products/workflows: Analytics dashboards for UI health; automated bug repro sequences from user-submitted recordings.
- Assumptions/dependencies: Stable element mapping across versions; scalable diffing and summarization; developer tooling integration.
- Finance back-office automation with strong guardrails
- Sectors: finance, compliance
- What: Agents that learn repetitive back-office workflows from recorded SOPs (reconciliation, reporting) and execute them under policy constraints.
- Products/workflows: Compliance-aware action planners; approval workflows; immutable logs.
- Assumptions/dependencies: Robust identity/access management; formal policy encoding; high-precision parameterization.
- Educational copilots that perform, explain, and assess software tasks
- Sectors: education, EdTech
- What: Agents that not only replicate tutorial steps but also adaptively guide students, detect errors, and provide feedback.
- Products/workflows: Interactive labs; step-wise tutors with “why-this-step” rationales using inner monologues.
- Assumptions/dependencies: Accurate task intent modeling; curriculum alignment; student data privacy and analytics ethics.
- Marketplace and monetization for skills distilled from videos
- Sectors: platforms, creator economy
- What: Skill-pack ecosystems where creators license workflows distilled into agent capabilities (with revenue sharing).
- Products/workflows: Skill catalogs, provenance tracking, licensing dashboards.
- Assumptions/dependencies: Platform support; standardized capability packaging; robust attribution and payout mechanisms.
Notes on Assumptions and Dependencies Across Applications
- Legal and policy: Rights to process and train on public videos vary by jurisdiction and platform ToS; creator consent, opt-in/out, and licensing are critical for scaled deployment.
- Technical: Action parameter extraction is more reliable for pointer-centric actions (click/scroll) than drag/press; typed text extraction depends on OCR/ASR quality; mapping raw coordinates to robust element selectors improves reliability.
- Operational: Environment parity (OS/app versions, resolutions) affects reproducibility; safety guardrails (sandboxing, RBAC, audit logs) are essential for enterprise use.
- Data quality and coverage: Broader OS/app diversity and mobile content will improve generalization; curated evaluation subsets remain necessary for measuring real-world readiness.
- Compute and scaling: Web-scale ingestion and pretraining require sustained compute and storage; continuous learning pipelines need rigorous governance to manage drift and provenance.
Glossary
- Action-content recognizer: A model that extracts the specific parameters of an action (e.g., click coordinates, typed text) from a localized video segment. "an action-content recognizer that extracts structured parameters like click coordinates and typed text with high fidelity."
- Action event detection: The task of finding and typing GUI interactions in video with precise start and end times. "First, an action event detection model performs dense event detection, identifying action types and their precise temporal boundaries"
- Action parameterization: Inferring the concrete arguments of a detected action, such as pointer coordinates or the literal text typed. "the action parameterization model, an action-content recognizer, analyzes these localized segments to extract structured parameters"
- AgentNetBench: An offline benchmark evaluating step-by-step correctness of computer-use agents across apps and websites. "On AgentNetBench, step accuracy increases from 64.1% to 69.3%."
- Agentic supervision: Training data that directly supervises an agent’s actions and reasoning steps extracted from demonstrations. "convert them into agentic supervision."
- ASR: Automatic Speech Recognition; transcripts used as context for generating rationales around actions. "short ASR transcripts spanning a 1-minute window before the action"
- Behavior cloning: Imitation learning by directly mimicking expert action sequences. "via inverse-dynamics auto-labeling followed by behavior cloning"
- Continued pretraining: Further pretraining a base model on new large-scale domain-specific data before fine-tuning. "We leverage this data through continued pretraining followed by supervised fine-tuning."
- Dense event detection: Detecting many temporally localized events within a video without prompts or queries. "perform prompt-free, dense event detection"
- GUI grounding: Aligning pointers and actions to the correct user interface targets and layout. "GUI grounding pairs"
- Headless browsers: Browser environments without a graphical interface, used for scripted data generation. "Programmatic synthesis inside headless browsers"
- Inner monologue: A brief, explicit rationale generated for each action to capture intent, plan, and expected state change. "We therefore generate a brief inner monologue before each action"
- Instrumented environments: Systems that log precise interaction signals (e.g., mouse/keyboard events) during data collection. "programmatic synthesis in instrumented environments"
- Inverse dynamics module (IDM): A model that infers the actions (and their parameters) that caused observed state changes in video. "We develop Video2Action, an inverse dynamics module (IDM) that extracts structured action supervision from unlabeled GUI videos."
- Long-horizon: Referring to tasks or trajectories that span many steps and require extended planning. "improve robustness on long-horizon tasks via better error detection and recovery."
- Moment retrieval: Locating the temporal segment in a video that corresponds to a described event. "Temporal grounding approaches such as temporal action localization, moment retrieval, keyframe detection, and dense video captioning"
- OCR: Optical Character Recognition; reading on-screen text, with potential noise affecting typed-text recognition. "typing shows moderate accuracy despite OCR noise"
- OpenCUA: An open-source platform/dataset for computer-use agents providing synchronized videos and interaction logs. "the annotation tool provided by OpenCUA"
- OSWorld-G: A dataset of GUI grounding pairs to improve pointer–target alignment and layout perception. "from the OSWorld-G dataset"
- OSWorld-Verified: An online benchmark of real desktop tasks used to measure end-to-end agent performance. "On OSWorld-Verified, our approach improves task success rates from 9.3% (SFT-only baseline) to 15.8%, a 70% relative improvement."
- Programmatic synthesis: Automatically generating labeled trajectories through scripts or APIs rather than manual annotation. "Programmatic synthesis inside headless browsers or scripted desktop flows can generate large volumes with exact parameters"
- Prompt-free: Performing a task without explicit natural-language prompts or queries. "perform prompt-free, dense event detection"
- Qwen2.5-VL: A multimodal vision-LLM used as the base for video grounding and action recognition. "We leverage Qwen2.5-VL~\citep{bai2025qwen25vltechnicalreport} as the base model, benefiting from its multimodal understanding and fine-grained spatiotemporal capabilities."
- ReAct tuples: Data format pairing observations with reasoning (thoughts) and actions for training agents. "Assembling these per-clip steps yields ReAct tuples for training"
- ReAct-style trajectories: Sequences that interleave reasoning steps (“thoughts”) with actions for improved planning and grounding. "motivating our inclusion of in ReAct-style trajectories"
- ScreenFilter: A cursor-based filtering tool to extract GUI-interaction segments from raw videos. "we developed ScreenFilter, a lightweight cursor detection model upon YOLOv8x"
- Supervised fine-tuning (SFT): Training a model on labeled instruction/response or action data to specialize it for tasks. "followed by supervised fine-tuning."
- System-2 reasoning: Deliberative, step-by-step reasoning used to improve grounding and execution in agents. "step-level “thoughts” or System-2 reasoning"
- Temporal boundaries: The precise start and end timestamps that localize an event within a video. "identifying action types and their precise temporal boundaries"
- Temporal event detection: Predicting typed events along with their start/end times across a video timeline. "multi-class temporal event detection"
- Temporal-grounding supervision: Labels linking events to their exact times in video for training precise detectors. "create temporal-grounding supervision"
- Test-time scaling: Increasing performance by allowing more steps or budget at inference time. "test-time scaling providing additional performance gains"
- Video grounding: Conditioning a model to detect and localize events/actions within video segments. "We equip a VLM with video grounding"
- Video2Action: The paper’s inverse dynamics module that detects actions and recovers their parameters from video. "We develop Video2Action, an inverse dynamics module (IDM) that extracts structured action supervision from unlabeled GUI videos."
- VideoAgentTrek: The proposed pipeline that converts unlabeled screen-recorded videos into training data for computer-use agents. "We present VideoAgentTrek, a scalable pipeline that automatically mines training data from publicly available screen-recorded videos at web scale"
- Vision-LLM (VLM): A model that processes both visual and textual inputs for multimodal understanding. "We equip a VLM with video grounding"
- VPT: Video PreTraining; learning to act from unlabeled videos via inverse dynamics and imitation. "VPT demonstrated that large-scale unlabeled videos can be converted into effective training signals"
- YOLOv8x: A high-capacity object detection backbone used here for efficient cursor detection. "a lightweight cursor detection model upon YOLOv8x"
Collections
Sign up for free to add this paper to one or more collections.