- The paper introduces a large-scale dataset with over 1.2M action steps across diverse Windows applications and a novel hybrid GUI+API action space.
- It presents a robust, automated data collection pipeline, TrajAgent, leveraging LLM-guided query mapping and quality filtering to generate realistic desktop trajectories.
- Benchmark evaluations show that specialized models dramatically outperform general VLMs in GUI grounding, screen parsing, and action prediction tasks.
GUI-360: A Large-Scale Dataset and Benchmark for Computer-Using Agents
Motivation and Scope
With the increasing sophistication of desktop automation, reliable and realistic data are pivotal for training, evaluating, and benchmarking computer-using agents (CUAs). The GUI-360datasetaddressesthreerecurringgapsinthefield:(i)ascarcityofreal−world,diversedesktoptasks,(ii)limitedscalableannotationpipelinesforcollectingmultimodaltrajectoriesindesktopenvironments,and(iii)theabsenceofunifiedbenchmarksassessingGUIgrounding,screenparsing,andactionprediction.</p><p>GUI−360^ advances the state-of-the-art by comprising over 1.2M executed action steps across thousands of trajectories in widely-used Windows applications (Word, Excel, PowerPoint), paired with full-resolution screenshots, rich accessibility metadata, goals, reasoning traces, and both successful and failed execution records. Crucially, it introduces a hybrid GUI+API action space to mirror modern agent architectures.
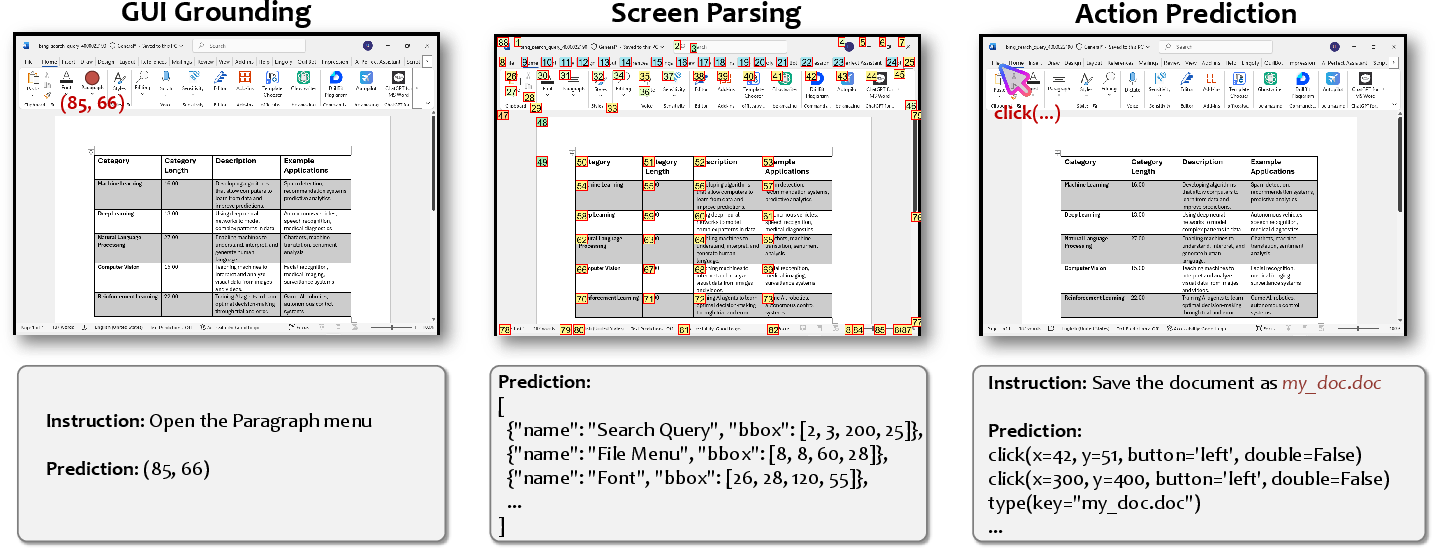
Figure 1: GUI-360coversGUIGrounding,ScreenParsing,andActionPredictionfordesktopautomation.</p></p><h2class=′paper−heading′id=′dataset−construction−pipeline′>DatasetConstructionPipeline</h2><h3class=′paper−heading′id=′multi−stage−automated−collection′>Multi−StageAutomatedCollection</h3><p>TheGUI−360^ data collection pipeline is built for scale and minimal human input:
- Query Acquisition: Aggregates authentic user intents and usage patterns from three principal sources—search logs, forums, and in-app help—yielding a diverse and high-frequency query distribution. These queries are mapped to environment templates constructed via LLM-guided clustering and abstraction, maximizing contextual reusability and reducing overhead.
- Task Instantiation: Queries are matched to templates and reformulated for direct execution, ensuring each trajectory is executable and contextually grounded.
- Quality Filtering: An LLM-based filtering mechanism enforces strict constraints, discarding tasks with ambiguities, cross-app dependencies, template mismatches, or non-executable requirements.
The overall post-filtering process retains approximately 75% of candidate tasks, producing a collection representative of true user operations in office productivity workflows.
Automated Trajectory Generation: TrajAgent
Data acquisition is fully automated through TrajAgent, an orchestrated agent framework designed to execute instantiated tasks, log comprehensive multimodal records, and handle post-processing. TrajAgent decomposes each task into subtasks, selects and executes GUI or API actions, collects screenshots and accessibility metadata, and logs intermediate reasoning and execution outcomes.
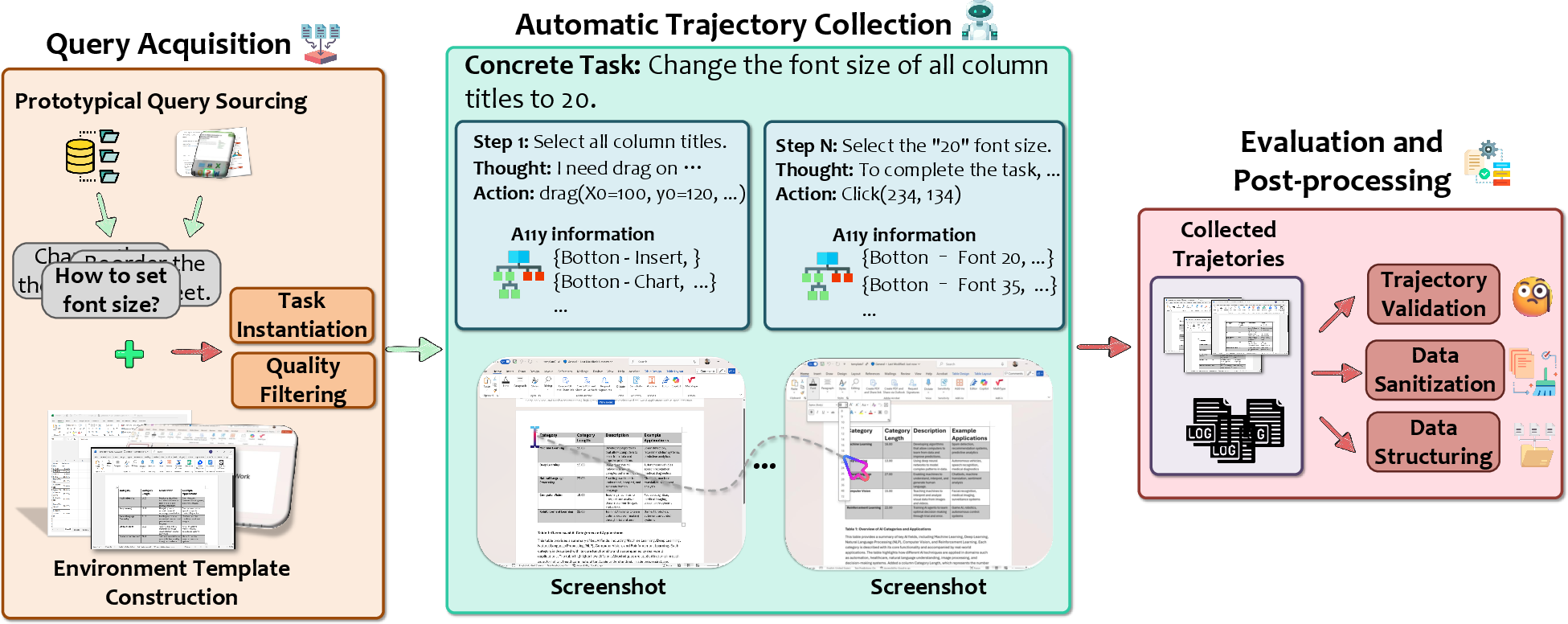
Figure 2: Overview of the GUI-360datacollectionpipelineformulti−modaldesktopagenttrajectories.</p><imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2511−04307/trajagent.png"alt="Figure3"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure3:ArchitectureofTrajAgent,enablingscalablebatchexecutionandmultimodaldatalogging.</p></p><p>TrajAgentincorporatesatwo−stageexecutionstrategy(GPT−4o→GPT−4.1fallback)tomaximizesuccessratesandreducesingle−modeldependency.Allexecutedstepsarerecordedinastandardizedschema,supportingreal−timeevaluationanddownstreamtraining.</p><h2class=′paper−heading′id=′benchmark−tasks−and−evaluation′>BenchmarkTasksandEvaluation</h2><p>GUI−360^ defines three canonical tasks for desktop agents:
- GUI Grounding: Given a stepwise plan, predict the interaction location or element.
- Screen Parsing: From a screenshot, enumerate actionable UI elements with semantic attributes and locations.
- Action Prediction: Given current context and user intent, output the next executable action with all required arguments (coordinates, element identification, etc.).
Benchmark splits cover 13,750 training trajectories (105k steps) and 3,439 test trajectories (26k steps), paired with 17.7M annotated UI elements and extensive multimodal assets.
Experimental Results
GUI Grounding
General-purpose VLMs (GPT-4o, GPT-4.1, o3, GPT-5) yield low accuracy (<12%), struggling with heterogeneous desktop layouts and visual ambiguity. Grounding-specialized models and those fine-tuned on GUI-360$^ (UI-TARS-1.5 7B-SFT, Qwen-VL-2.5 7B-SFT) achieve >82% accuracy, demonstrating the strong training signal of the dataset and highlighting deficiencies in off-the-shelf approaches.</p>
<h3 class='paper-heading' id='screen-parsing'>Screen Parsing</h3>
<p>Screen parsing is evaluated via element detection F1, mean <a href="https://www.emergentmind.com/topics/semantic-intersection-over-union-iou" title="" rel="nofollow" data-turbo="false" class="assistant-link" x-data x-tooltip.raw="">IoU</a>, and semantic similarity. General-purpose VLMs show limited performance (F1 < 0.13, mean IoU < 0.58), while specialized architectures (OmniParser v1/v2) consistently reach F1 > 0.40, mean IoU > 0.73. The dense and diverse layouts in Excel and PowerPoint remain challenging, yet task-specific training substantially improves element recovery and semantic <a href="https://www.emergentmind.com/topics/fidelity-alpha-precision" title="" rel="nofollow" data-turbo="false" class="assistant-link" x-data x-tooltip.raw="">fidelity</a>.</p>
<h3 class='paper-heading' id='action-prediction'>Action Prediction</h3>
<p>Action prediction is the most complex task, requiring mapping user commands to correct functions, arguments, and status. Without accessibility metadata (visual-only), all models are below 20% accuracy. Provision of structured a11y signals boosts performance substantially (e.g., GPT-4o: 3% → 36%). Fine-tuned models further improve function and argument prediction, though argument mismatch and coordinate errors persist as bottlenecks. Accessibility information is indispensable for reliable reasoning and grounding.</p>
<h2 class='paper-heading' id='practical-implications-and-limitations'>Practical Implications and Limitations</h2>
<p>The empirical gaps between general-purpose and task-adapted agents confirm the necessity of realistic, large-scale datasets for advancing desktop CUAs. GUI-360$, with its multimodal breadth and scalable collection framework, supports both horizontal scaling (more applications/domains) and vertical expansion (longer-horizon, multi-step workflows, failure handling).
While fine-tuning and RL on GUI-360deliversubstantialgains,theydonotbridgethegaptohuman−levelreliabilityorrobustnessagainstout−of−distributionlayouts,rareaffordances,oradversarialsituations.Theinterplaybetweenstructuredsemanticinput(a11ydata),high−fidelityvisualcontext,andactionplanningremainsanactiveareaforfurtherresearch.</p><p>Thereleaseoffailurecasesandreasoningtracesopensavenuesforreinforcementlearning,bootstrapping,anddiagnosticsinagentdevelopment.<ahref="https://www.emergentmind.com/topics/hg−tnet−hybrid"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">Hybrid</a>actionspacesfurtherenableevaluationofperception−drivenvs.API−augmentedstrategiesandfacilitate<ahref="https://www.emergentmind.com/topics/compositional−generalization"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">compositionalgeneralization</a>.</p><h2class=′paper−heading′id=′future−directions′>FutureDirections</h2><p>GUI−360^ establishes a blueprint for dataset design and benchmarking in desktop CUA research:
- Extensibility: The template-based instantiation and pipeline automation support rapid expansion to additional applications and domains, including scientific software, creative tools, and browser environments.
- Multi-Agent and Collaborative Scenarios: With standardized logging and reasoning traces, studying coordination, delegation, and collaborative execution becomes feasible.
- Sim2Real Transfer: Combined GUI/API action spaces and comprehensive failure handling form a basis for transfer learning between desktop, mobile, and cloud interfaces.
- Learning from Failure: With explicit failed trajectories and intermediate reasoning, agents can be optimized via RL from human/LLM feedback and counterfactual error analysis.
Conclusion
GUI-360deliversacomprehensive,scalable,andrealisticdatasetforthedesktopagentresearchcommunity,bridginggapsinscreenunderstanding,actionplanning,andmultimodalreasoning.BenchmarkingonGUI−360^ exposes persistent weaknesses in even the strongest contemporary VLMs, drives progress through supervised and RL adaptation, and sets a new standard for reproducible, extensible CUA development. The resources, code, and benchmarks released are poised to accelerate systematic advances toward practical, robust computer-using agents.

