Training Proactive and Personalized LLM Agents
Abstract: While existing work focuses primarily on task success, we argue that effective real-world agents require optimizing three dimensions: productivity (task completion), proactivity (asking essential questions), and personalization (adapting to diverse user preferences). We introduce UserVille, an interactive environment with LLM-based user simulators enabling diverse, configurable user preferences. Leveraging UserVille, we introduce PPP, a multi-objective reinforcement learning approach that jointly optimizes all three dimensions: Productivity, Proactivity, and Personalization. Experiments on software engineering and deep research tasks show that agents trained with PPP achieve substantial improvements over strong baselines such as GPT-5 (+21.6 on average), demonstrating the ability to ask strategic clarifying questions, adapt to unseen user preferences, and improve task success through better interaction. This work demonstrates that explicitly optimizing for user-centered interaction is critical for building practical and effective AI agents.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI helpers (called “LLM agents”) to be better at working with people. Instead of only focusing on finishing tasks, the authors say great agents should also:
- be productive (actually solve the problem),
- be proactive (ask smart, necessary questions when instructions are unclear),
- be personalized (change how they talk and ask based on the user’s preferences).
To do this, they build a training playground called UserVille and create a training method called PPP that improves all three skills at once.
What questions did the researchers ask?
The paper explores simple, people-centered questions:
- If users give vague instructions, can agents succeed by asking clarifying questions?
- Can we train agents to balance task-solving with good communication?
- Will these agents learn to ask only when needed and adapt to different user styles?
- Do these skills generalize to new kinds of users and harder tasks?
How did they study it?
The researchers used three main ideas, each with everyday analogies to make them easy to understand:
1) Making tasks feel like the real world
In many datasets, prompts are crystal-clear. Real people aren’t always that precise. So the team rewrote precise prompts into “vague” versions to mimic real-life uncertainty. Think of it like getting a homework assignment with missing details—you need to ask questions to fill the gaps.
2) UserVille: a world of different “users”
They built an environment where “users” are simulated with different preferences. Imagine classmates with different styles:
- Some like short questions,
- some want detailed context,
- some prefer one question at a time,
- some only answer in a certain format (like multiple-choice or JSON),
- some even prefer specific languages or jokes.
These simulated users allow the agent to practice adapting to different communication styles and give feedback on how helpful the questions were.
3) PPP training: practice with a balanced scoreboard
They trained agents using reinforcement learning (RL), which is like practice where you get points for good behavior. Here, the “scoreboard” combines three rewards:
- Productivity: Did the agent solve the task?
- Proactivity: Did it ask useful, easy-to-answer questions and avoid annoying, hard-to-answer ones?
- Personalization: Did it follow the user’s preferences (like asking briefly or in a certain format)?
The agent learns to balance all three, so it doesn’t just chase the answer—it also interacts well with people.
They tested this on two kinds of tasks:
- Software engineering problems (from SWE-Bench), like fixing code issues.
- Deep research tasks (from BrowseComp-Plus), which involve searching and reasoning across web pages.
What did they find and why it matters?
Here are the main findings reported in the paper:
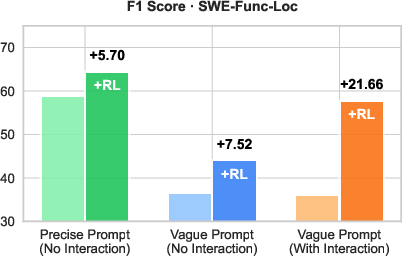
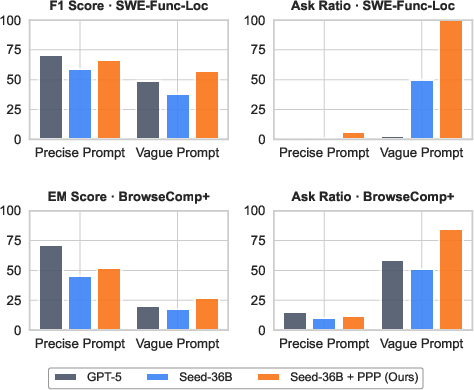
- Interaction helps a lot when prompts are vague. Agents that ask clarifying questions solve more tasks. Without good training, agents might ask poor questions or not ask at all.
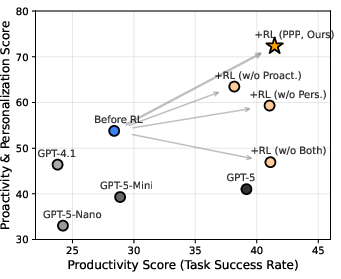
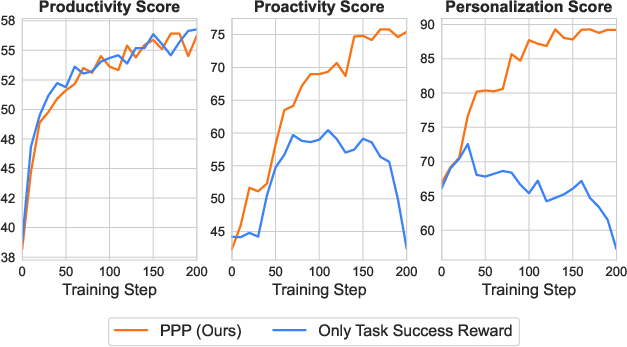
- PPP training improves all three skills at once. Compared to strong models (like GPT-5), PPP-trained agents did substantially better on productivity, proactivity, and personalization in their tests.
- The agents learned to be strategic:
- They asked more when prompts were vague and less when prompts were precise.
- Over training, they first asked more questions, then asked better-targeted ones that were easy for the user to answer.
- The skills transfer:
- They adapted to new user preferences they hadn’t seen before.
- They worked with different user simulators (different LLMs playing the “user” role).
- Skills learned on a subtask (like finding which functions in code need editing) helped on the full, more complex task.
Why it matters: In real life, people don’t always provide perfect instructions, and they have different ways they like to communicate. Agents that can ask the right questions and match the user’s style are more helpful, less frustrating, and more successful.
What is the impact of this research?
This work suggests a shift in how we train AI helpers. Instead of only rewarding “getting the right answer,” we should also reward good communication and adaptation to the user. If widely adopted:
- Everyday AI assistants could become more considerate and effective,
- Teams using AI for coding or research might finish tasks faster with fewer misunderstandings,
- New training environments like UserVille could help create agents that are truly user-centered.
The authors also note limitations and ethics:
- The “users” are simulated, not real people; future work should involve real user studies.
- Personalization must be done carefully to avoid manipulation, protect privacy, and be fair to different groups.
In short, this paper shows that optimizing for how an agent interacts—not just whether it solves the task—can make AI feel more like a helpful collaborator and less like a black box.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work.
- Real-human validation: The study relies on LLM-based user simulators; conduct controlled user studies to validate that PPP’s proactivity and personalization improvements translate to higher real user satisfaction, task success, and perceived agent quality.
- Ground-truthing user effort: The low/medium/high effort classification is heuristic; create a human-labeled dataset with measured response time, keystrokes, and cognitive-load instruments (e.g., NASA-TLX) to calibrate and validate effort categories and thresholds.
- LLM-as-judge reliability: Personalization scoring uses LLM judges; quantify inter-LLM agreement, bias, and variance, and benchmark against human judgments to assess accuracy, robustness, and susceptibility to prompt sensitivity or reward hacking.
- Reward design sensitivity: The composite reward uses fixed scalar weights (e.g., +0.05, −0.1, −0.5); perform sensitivity analyses to understand how weights impact trade-offs and convergence, and explore principled multi-objective methods (e.g., Pareto RL, Lagrangian/constraint-based optimization, hypervolume maximization) instead of simple scalarization.
- Dynamic, user-specific weighting: Investigate adaptive weighting of productivity, proactivity, and personalization per user/persona and per session stage (early vs. late turns), rather than a single global weighting scheme.
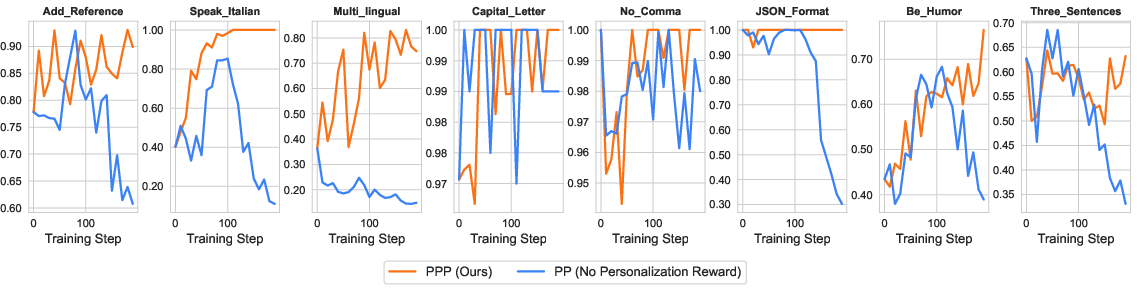
- Preference taxonomy validity: The 20 preferences are manually crafted and include atypical constraints (e.g., “no commas”, “English only and all caps”); derive a realistic preference taxonomy from large-scale real interaction logs and qualitative studies, and evaluate PPP on that distribution.
- Preference learning: Move beyond rule-following to learning user preference embeddings from interaction traces (few-shot, online, or meta-learning), including cold-start inference when preferences are implicit or underspecified.
- Preference drift and conflict: Study adaptation when preferences change mid-session, are inconsistent, or conflict (e.g., brevity vs. detail), and design strategies for negotiation, clarification, and resolution.
- Vague prompt realism: Validate the LLM-based “prompt vaguenization” against real-world vague requests (distributional similarity, topic coverage, ambiguity types), and quantify how differences affect interaction and task outcomes.
- Ask timing and value-of-information: Formalize “when to ask” via a decision-theoretic policy (expected utility/value of information) that balances clarification benefit against user effort costs; compare against heuristic ask ratios.
- Binary scoring granularity: Proactivity and personalization are evaluated with binary outcomes; develop continuous, multi-dimensional metrics (e.g., question relevance, specificity, answerability, politeness, brevity adherence) and correlate with human satisfaction.
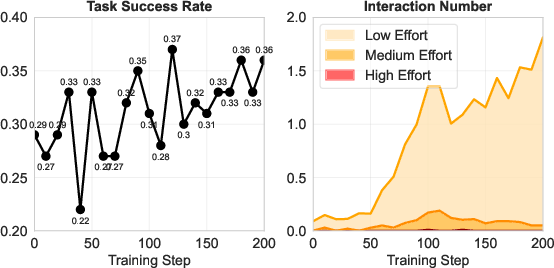
- Negative transfer on precise prompts: PPP-trained models decreased success on precise SWE-Full prompts; analyze why (e.g., over-asking, distribution shift, forgetting), and test mitigations (gating policies, regularization, curriculum mixing of precise/vague prompts).
- Full-task training: The agent is trained on SWE-Func-Loc (a subtask); evaluate PPP trained end-to-end on SWE-Full and other complex tasks to assess scalability, tool orchestration, and generalization.
- Domain and modality coverage: Extend beyond SWE and deep research to diverse domains (customer support, creative writing, medical/legal QA) and modalities (speech, GUI agents), and measure cross-domain robustness.
- Simulator robustness and adversarial users: Evaluate PPP against adversarial, inconsistent, or low-knowledge user simulators; test resilience to misleading answers, preference injection attacks, and noisy or multilingual inputs.
- Cross-lingual personalization: Current language-related preferences are limited; systematically evaluate cross-lingual performance (dialects, code-switching, noisy text), fairness across languages, and multilingual preference compliance.
- Interaction cost budgets: Incorporate explicit user effort/time budgets and optimize interaction under constraints (e.g., limited number of questions), including budget-aware RL or constrained optimization.
- Long-context and compute scaling: PPP uses very large output lengths (32K–65K tokens); quantify compute costs, memory footprint, latency, and scalability, and evaluate lightweight variants or distillation approaches.
- Statistical rigor: Report confidence intervals, significance tests, and effect sizes for key metrics to substantiate claims and ensure reliability across seeds and datasets.
- Reward hacking and overfitting: Investigate whether agents exploit LLM judges or handcrafted rules (e.g., formatting preferences) without genuinely improving interaction quality; design adversarial tests and detection/penalty mechanisms.
- Multi-objective RL algorithm choice: Compare GRPO+DAPO to alternative algorithms (PPO, A2C, SAC, distributional RL, Pareto front methods) for stability, sample efficiency, and trade-off control.
- Uncertainty calibration: Measure and improve agent confidence calibration (e.g., selective asking when confidence is low), and evaluate how uncertainty estimates predict the utility of asking.
- Memory and privacy for personalization: Specify how user preferences are stored, updated, and forgotten across sessions, with privacy safeguards, consent mechanisms, and compliance (e.g., GDPR-like requirements).
- Tool ecosystem coverage: Expand toolsets (IDE actions, test runners, debugging aids, richer browsing) and study how tool availability interacts with proactivity (e.g., asking vs. self-discovery via tools).
- Multi-user scenarios: Examine agents interacting with teams (conflicting preferences across multiple stakeholders), including role-aware adaptation and aggregation of preferences.
- Fairness auditing: Assess differential performance and satisfaction across demographics, language groups, and communication styles; add fairness metrics and mitigation strategies to PPP’s objectives.
- Reproducibility and transparency: Release complete reward functions, vaguenization prompts, user-judging rubrics, and detailed simulator settings; document seeds and hyperparameters to enable faithful replication.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with existing capabilities described in the paper. Each item notes the sector, potential tools/products/workflows, and feasibility assumptions or dependencies.
- Proactive issue triage and localization for software teams
- Sector: software engineering
- Tools/products/workflows: integrate a PPP-trained agent into GitHub/GitLab issue workflows or IDEs to (a) ask targeted reproduction questions, (b) localize buggy functions (
SWE-Func-Loc), and (c) hand off precise context to humans or downstream auto-fix agents. UseOpenHandsscaffolds,ask_usertools, and the paper’s proactivity/personalization scoring to monitor interaction quality. - Assumptions/dependencies: access to repos and CI, task-verifiable metrics (F1/unit tests), sufficient context window and tool permissions; simulated-user training generalizes to real developer behavior.
- Clarifying, preference-aware code review and PR grooming
- Sector: software engineering
- Tools/products/workflows: review bots that proactively query missing decisions (versions, constraints, docs), comply with team-specific formatting preferences (e.g., valid JSON, language constraints), and minimize developer effort using a “user effort” classifier.
- Assumptions/dependencies: repository access, preference templates configured per team; reward functions tuned to internal review rubrics.
- Customer support chat that minimizes user effort
- Sector: customer service, retail, telco, SaaS
- Tools/products/workflows: PPP-tuned agents that ask only “low-effort” clarifying questions and adapt tone, brevity, and language. Use proactivity penalties to avoid unnecessary queries; deploy “interaction scorecards” based on the paper’s metrics for QA and A/B tests.
- Assumptions/dependencies: accurate domain-specific productivity metrics (resolution/EM), privacy-compliant logging to estimate effort; escalation workflows for high-effort cases.
- Requirements elicitation assistants for PMs/BAs
- Sector: product management, enterprise IT
- Tools/products/workflows: agents that turn underspecified feature requests into clarified specs by asking strategic questions aligned with stakeholder preferences (e.g., “one question per turn”, “all questions upfront”). Use Prompt Vaguenization to stress-test requirement capture.
- Assumptions/dependencies: stakeholders accept agent-led elicitation; integration with ticketing tools (Jira/Linear).
- Deep-research assistants with adaptive questioning
- Sector: R&D, knowledge management, education
- Tools/products/workflows: browsing agents that clarify scope (timeframe, sources, format) and adapt to user preference templates (e.g., brevity, language). Integrate with enterprise search using retrievers (e.g., Qwen3-Embed-8B) and log proactivity/personalization scores to ensure effective collaboration.
- Assumptions/dependencies: reliable retrieval, content compliance (copyright); domain-specific answer judgers for productivity.
- Documentation and developer relations copilot
- Sector: software, technical writing
- Tools/products/workflows: writing assistants that proactively ask for missing configuration details or API versions, and honor strict formatting preferences (e.g., JSON-only, code snippets with explicit file/URL references).
- Assumptions/dependencies: access to source docs/repos; formatting validators to automate personalization rewards.
- Agent QA, evaluation, and pre-deployment gating
- Sector: AI/ML platform engineering
- Tools/products/workflows: adopt
UserVilleas a test harness to simulate diverse user personas, generate ambiguous prompts, and compute proactivity/personalization metrics before production rollout. Use composite PPP rewards to tune agents. - Assumptions/dependencies: suitable simulators (LLMs) and task verifiers; MLOps integration (e.g., Verl).
- Contact center “ask-ratio” calibration playbooks
- Sector: customer service operations
- Tools/products/workflows: operational dashboards tracking ask ratio, user effort distribution (low/medium/high), and preference adherence to reduce customer annoyance and handle underspecified tickets efficiently.
- Assumptions/dependencies: reliable effort classification from transcripts; agents exposed to preference templates.
- Accessibility and localization in conversational UX
- Sector: public services, global products
- Tools/products/workflows: enforce communication constraints (e.g., specific languages, all-caps) per user preference; proactively clarify missing data while minimizing cognitive load.
- Assumptions/dependencies: inclusive preference catalogs; language detection/translation pipelines.
- Brand voice and compliance enforcement
- Sector: marketing, communications
- Tools/products/workflows: define “preference policies” (tone, format, humor inclusion) and use personalization rewards to ensure adherence across agents in copy generation or customer interactions.
- Assumptions/dependencies: organization-specific rubrics; governance for safe personalization (avoid manipulation).
- Adaptive tutoring with minimal-disruption clarifications
- Sector: education
- Tools/products/workflows: tutors that ask essential questions aligned with student preferences (e.g., one question per turn, simple/common-sense only), and personalize tone/format to reduce frustration.
- Assumptions/dependencies: domain scoring for productivity (learning outcomes); classroom data privacy.
Long-Term Applications
Below are applications that require further research, scaling, domain adaptation, or validation with real users before broad deployment.
- Clinical intake triage with effort-aware clarification
- Sector: healthcare
- Tools/products/workflows: triage agents that ask only low-effort medical history questions, personalize language, and escalate high-effort queries to clinicians. Use PPP rewards tied to clinical productivity metrics (accuracy, time-to-triage).
- Assumptions/dependencies: rigorous safety, HIPAA/GDPR compliance, clinical validation, bias auditing.
- Legal and financial advisory intake assistants
- Sector: law, finance
- Tools/products/workflows: effort-minimizing intake that clarifies goals/constraints while complying with jurisdictional formatting and tone preferences; integrate with case/portfolio systems.
- Assumptions/dependencies: regulation-compliant logging; verified productivity metrics; supervision by licensed professionals.
- Robotics/home assistants with clarifying dialogue
- Sector: robotics, smart home
- Tools/products/workflows: agents that ask targeted questions before executing physical tasks, tuned to household preferences (minimal interruptions, language, humor). Extend PPP to multimodal (speech/gesture) interaction.
- Assumptions/dependencies: robust perception/action safety; real-time multimodal RL; user acceptance studies.
- Persistent, privacy-preserving “agent-of-me” preference memory
- Sector: consumer software, enterprise productivity
- Tools/products/workflows: cross-app agents that learn and retain user preferences over time, apply them across tasks (coding, research, writing), and optimize PPP objectives longitudinally.
- Assumptions/dependencies: consented preference storage, privacy controls, federated/edge learning to mitigate data risks.
- Standardization of user-centric interaction metrics
- Sector: academia, industry consortia
- Tools/products/workflows: formalize proactivity and personalization metrics as industry benchmarks; publish “interaction quality” leaderboards alongside task success.
- Assumptions/dependencies: community buy-in; domain-specific measurement definitions; reference user simulators.
- Real-human preference learning and reward modeling
- Sector: AI research
- Tools/products/workflows: replace manual preference pools with learned, hierarchical preference models from real logs; extend proactivity rewards with human-validated effort scales.
- Assumptions/dependencies: large-scale, consented interaction datasets; robust causal analyses to avoid reward hacking.
- Enterprise-scale simulation farms and MLOps integration
- Sector: AI platform engineering
- Tools/products/workflows: managed
UserVilleservices that generate realistic ambiguity, orchestrate multi-objective RL (GRPO/DAPO), and produce deployment readiness gates based on PPP metrics. - Assumptions/dependencies: scalable compute; simulator diversity; seamless pipeline integration.
- Full-stack IDE copilots that transition from localization to auto-fix
- Sector: software engineering
- Tools/products/workflows: extend PPP-trained localization skills to safe auto-patching with tests and rollback; agents clarify blockers only when necessary to reduce developer effort.
- Assumptions/dependencies: robust test coverage; risk-aware change management; human-in-the-loop approvals.
- Government digital services with effort-minimizing form completion
- Sector: public sector
- Tools/products/workflows: conversational assistants that clarify missing items proactively, adapt to accessibility preferences, and reduce submission errors.
- Assumptions/dependencies: accessibility standards, fairness audits, citizen data protections.
- Safety and ethics frameworks for personalized agents
- Sector: policy, governance
- Tools/products/workflows: guidelines for non-manipulative personalization, transparency of adaptation mechanisms, and user control over preferences; audit processes for equitable interaction across populations.
- Assumptions/dependencies: multidisciplinary collaboration, regulatory alignment, standardized reporting.
- Preference template marketplaces and certification
- Sector: enterprise software, marketplaces
- Tools/products/workflows: curated preference bundles (e.g., “legal intake JSON-only,” “support short-answers”) with certification that agents meet PPP thresholds.
- Assumptions/dependencies: interoperable preference schemas; third-party certifiers; continuous monitoring.
- Interaction analytics products
- Sector: CX/EX analytics
- Tools/products/workflows: dashboards exposing ask ratio, effort distribution, and preference adherence; root-cause analysis for high-effort sessions; tooling to auto-tune agent policies.
- Assumptions/dependencies: consistent logging; cross-channel data integrations; meaningful KPI mapping to PPP metrics.
- Multimodal PPP (text + voice + vision) for field operations
- Sector: energy, logistics, manufacturing
- Tools/products/workflows: agents that clarify with minimal disruption via voice/AR overlays, optimize PPP while on the job (e.g., equipment repair), and adapt to operator preferences.
- Assumptions/dependencies: reliable multimodal capture, latency controls, domain verification signals for productivity.
- Cross-language, low-latency personalization at global scale
- Sector: global platforms
- Tools/products/workflows: agents enforcing language-specific constraints and cultural tone preferences while maintaining low ask ratios; deploy at scale with streaming RL updates.
- Assumptions/dependencies: high-quality multilingual models, content safety filters, regional compliance.
Glossary
- Ablations: Controlled removal of components or objectives to assess their impact on performance. "with ablations confirming each objective's necessity"
- Ask Ratio: The proportion of instances where the agent asks at least one question. "Ask Ratio (the percentage of instances where the model asks any question)"
- ask_user tool: A tool-call interface that lets the agent ask questions to the user simulator during an interaction. "We formulate the interaction between agent and user as an ask_user tool, and thereby the task can be modeled as a multi-turn tool call agent."
- BrowseComp-Plus: A benchmark for evaluating deep-research agents with fair and transparent criteria. "we use BrowseComp-Plus, splitting the data into 450 training instances and 100 test instances."
- Clip-Higher strategy: An RL training heuristic that clips policy updates more permissively for higher advantages to stabilize training. "adopt the Clip-Higher strategy and Token-Level Policy Gradient Loss from DAPO"
- Composite reward signal: A combined reward that integrates multiple objectives (e.g., task success, interaction quality, preference alignment). "using a composite reward signal derived from three sources"
- DAPO: A training framework providing techniques like token-level policy gradient loss for RL fine-tuning of LLMs. "Token-Level Policy Gradient Loss from DAPO"
- Deep-Research: A task domain focused on complex information gathering and synthesis via browsing tools. "and the Deep-Research task from BrowseComp-Plus"
- EM score: Exact Match metric that measures whether the predicted answer matches the ground-truth exactly. "For Deep-Research, we use the official answer judger to calculate the EM score."
- F1 score: The harmonic mean of precision and recall, used here to evaluate function localization accuracy. "F1 score on SWE-Bench-Verified (SWE-Func-Loc), comparing precise vs. vague initial user prompts and agents with vs. without user interaction."
- GRPO: Group Relative Policy Optimization, an RL algorithm variant used for training the agent. "We employ a GRPO-based reinforcement learning algorithm"
- Group Relative Advantage Estimator: An estimator that normalizes advantages relative to a group of trajectories for stable RL updates. "where the importance sampling ratio and the group relative advantage estimator \citep{Shao2024DeepSeekMathPT} are given by"
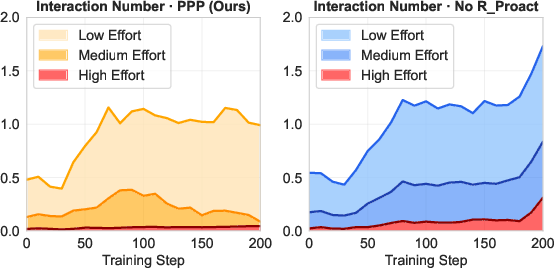
- High-effort: A category of user effort indicating that answering the agent’s question requires significant additional work beyond the original prompt. "High-effort: This applies when the user simulator provides an answer using information that exists beyond the original precise user prompt."
- Importance sampling ratio: The ratio between new and old policy probabilities used to correct off-policy updates in RL. "where the importance sampling ratio and the group relative advantage estimator \citep{Shao2024DeepSeekMathPT} are given by"
- Information asymmetry: A condition where the user simulator has access to precise information that the agent lacks, enabling targeted clarifications. "we can establish information asymmetry between the user simulator and the agent"
- LLM-as-a-judge: Using an LLM to evaluate outputs according to a rubric, acting as an automated judge. "by prompting the user simulator to act as an LLM-as-a-judge using a preference-specific evaluation rubric."
- LLM-simulated users: Artificial users implemented with LLMs to provide feedback and preferences in multi-turn interactions. "researchers have used LLM-simulated users in multi-turn settings"
- Low-effort: A user-effort category where questions can be answered directly from the precise prompt without extra work. "Low-effort: This applies when the agent's question can be answered directly using information from the original, precise user prompt."
- Medium-effort: A user-effort category reflecting unnecessary or poorly posed questions that the user cannot answer. "Medium-effort: This applies when the user simulator cannot or refuses to answer the question (e.g., replying, ``I don't know'')."
- Multi-objective reinforcement learning: RL that optimizes multiple goals simultaneously (e.g., productivity, proactivity, personalization). "We employ a multi-objective reinforcement learning (RL) algorithm"
- OpenHands: An agentic framework used as a scaffold for SWE tasks and environments. "For SWE tasks, we implement our scaffold based on OpenHands"
- open_page tool: A browsing tool-call that opens web pages during deep-research tasks. "the agent is equipped with a search tool and an open_page tool."
- PPP: Productive, Proactive, and Personalized; an optimization framework jointly training agents on the three interaction dimensions. "Leveraging UserVille, we introduce PPP, a multi-objective reinforcement learning approach that jointly optimizes all three dimensions"
- Preference generalization: The ability of the agent to follow unseen user preferences after training. "verifying the preference generalization ability of our approach."
- Preference-Aware User Simulation: Simulation of users parameterized by configurable interaction preferences for personalized training and evaluation. "Preference-Aware User Simulation: We design an LLM-based user simulator whose behavior is driven by diverse configurable user preferences, enabling personalized interactions and reward calculation."
- Preference-specific reward function: A scoring function tailored to a particular user preference to assess compliance. "based on the preference-specific reward function"
- Proactivity: The agent’s skill in asking essential clarifying questions while avoiding unnecessary queries. "We evaluate the agent's proactivity using a user effort estimation approach."
- Proactivity Reward: The RL reward component penalizing medium/high-effort queries and rewarding low-effort interactions. "The proactivity reward $R_{\text{Proact}$ is derived from the user-centric evaluations"
- Productivity: Task completion effectiveness (e.g., solving the problem correctly). "productivity (task completion)"
- Productivity Reward: The task-oriented, verifiable reward component that measures successful completion. "The productivity reward $R_{\text{Prod}$ is a task-oriented, verifiable reward"
- Prompt Vaguenization: The process of rewriting precise prompts into under-specified forms to simulate real-world ambiguity. "The Prompt Vaguenization stage uses an LLM to rewrite the prompt into a vague form."
- ReAct-style agent: An agent pattern that interleaves reasoning and acting (tool calls) during multi-turn interaction. "We follow a ReAct-style agent~\citep{Yao2022ReActSR} to model the interaction as following,"
- Retriever: A component that fetches relevant information (e.g., documents) to support answering. "We use Qwen3-Embed-8B as the retriever."
- Search tool: A tool-call interface allowing the agent to perform web searches during tasks. "the agent is equipped with a search tool and an open_page tool."
- Seed-OSS-36B-Instruct: The base LLM used for experiments prior to RL fine-tuning. "We conduct experiments using Seed-OSS-36B-Instruct as the base model."
- Session-level user effort: The maximum effort category experienced within a full interaction session. "the overall session-level user effort, which we define as the maximum effort recorded in any single turn within that session."
- SWE-Bench Verified: A benchmark of real-world GitHub issues with verification via tests. "SWE-Bench Verified~\citep{Jimenez2023SWEbenchCL} as the test data."
- SWE-Full: The full SWE task where agents make real edits and are evaluated by unit tests. "We also evaluate on the SWE-Full task"
- SWE-Func-Loc: The SWE subtask focused on localizing the issue to functions that need editing. "we train the model only on the SWE-Func-Loc task"
- SWE-Gym: A training dataset/environment for software engineering agent tasks. "we use SWE-Gym~\citep{Pan2024TrainingSE} as the training data"
- Token-Level Policy Gradient Loss: An RL objective that applies policy gradient updates at the token level in sequence generation. "adopt the Clip-Higher strategy and Token-Level Policy Gradient Loss from DAPO"
- Trajectory: The full sequence of agent actions and observations in a multi-turn interaction. "an agent generates a multi-turn interaction trajectory denoted as"
- User-Centric Evaluation: Metrics and feedback focusing on interaction quality and preference adherence from the user’s perspective. "User-Centric Evaluation: After task completion, the user simulator produces user-centric feedback metrics"
- UserVille: An interactive environment with diverse LLM-based user simulators and user-centric metrics. "We introduce UserVille, an interactive environment with LLM-based user simulators enabling diverse, configurable user preferences."
- Verl: A reinforcement learning runtime/framework used to implement the training environment. "Our training environment is implemented with Verl"
- Verifiable reward: A reward component that can be checked objectively against task success criteria. "The productivity reward $R_{\text{Prod}$ is a task-oriented, verifiable reward"
Collections
Sign up for free to add this paper to one or more collections.

