MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
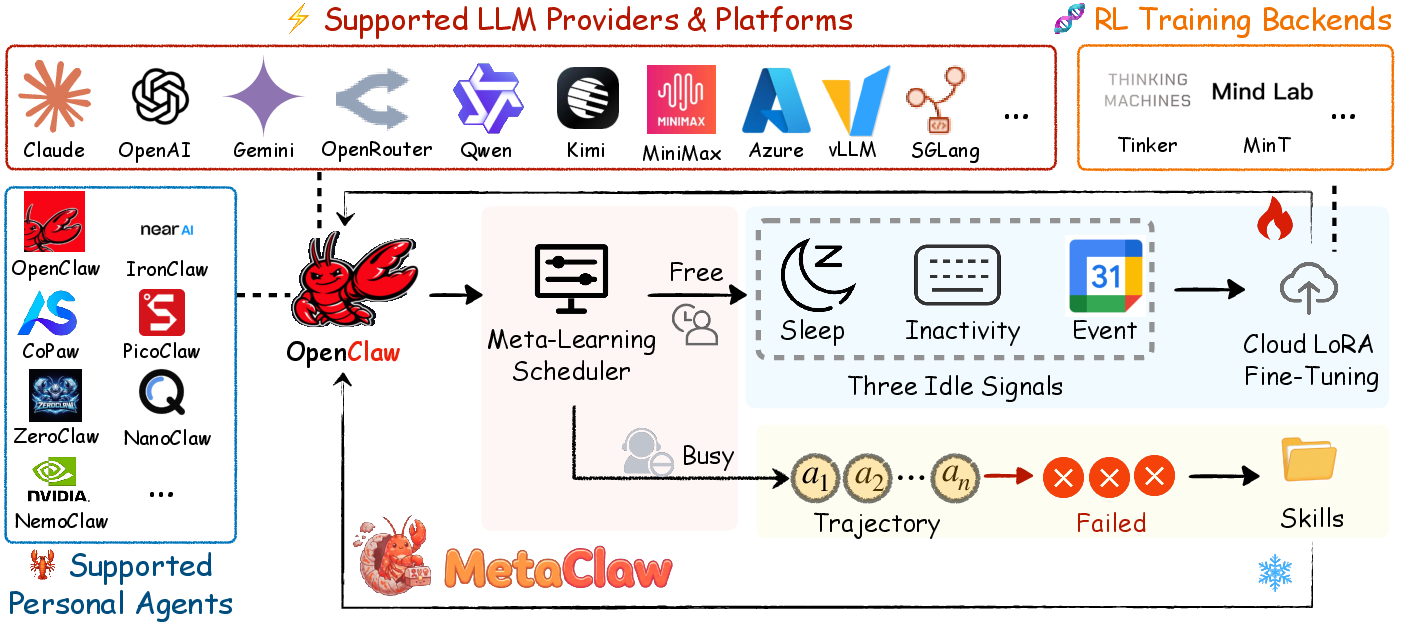
Abstract: LLM agents are increasingly used for complex tasks, yet deployed agents often remain static, failing to adapt as user needs evolve. This creates a tension between the need for continuous service and the necessity of updating capabilities to match shifting task distributions. On platforms like OpenClaw, which handle diverse workloads across 20+ channels, existing methods either store raw trajectories without distilling knowledge, maintain static skill libraries, or require disruptive downtime for retraining. We present MetaClaw, a continual meta-learning framework that jointly evolves a base LLM policy and a library of reusable behavioral skills. MetaClaw employs two complementary mechanisms. Skill-driven fast adaptation analyzes failure trajectories via an LLM evolver to synthesize new skills, enabling immediate improvement with zero downtime. Opportunistic policy optimization performs gradient-based updates via cloud LoRA fine-tuning and Reinforcement Learning with a Process Reward Model (RL-PRM). This is triggered during user-inactive windows by the Opportunistic Meta-Learning Scheduler (OMLS), which monitors system inactivity and calendar data. These mechanisms are mutually reinforcing: a refined policy generates better trajectories for skill synthesis, while richer skills provide higher-quality data for policy optimization. To prevent data contamination, a versioning mechanism separates support and query data. Built on a proxy-based architecture, MetaClaw scales to production-size LLMs without local GPUs. Experiments on MetaClaw-Bench and AutoResearchClaw show that skill-driven adaptation improves accuracy by up to 32% relative. The full pipeline advances Kimi-K2.5 accuracy from 21.4% to 40.6% and increases composite robustness by 18.3%. Code is available at https://github.com/aiming-lab/MetaClaw.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine you have a helpful AI that lives on your computer and does lots of different chores—editing files, running commands, organizing notes—day after day. The problem is: real life changes fast, but most AIs don’t keep learning once they’re released. This paper introduces MetaClaw, a way for an always-on AI assistant to keep getting better while you use it, without shutting down.
MetaClaw does this in two ways:
- It quickly turns mistakes into simple, reusable tips (skills) that take effect right away.
- It waits for your downtime (like when you’re asleep) to do deeper training that updates the AI’s “brain” for bigger improvements.
Together, these two loops help the AI learn from the real world as it goes.
What questions the paper tries to answer
The authors focus on a few practical questions:
- How can an AI keep improving while it’s actively helping you, without pausing service?
- Can we turn everyday mistakes into simple rules that help right away?
- When is it safe to do heavier training so we don’t interrupt the user?
- How do we make sure we train on the right data (after changes) and not on old, misleading information?
How the approach works (in plain language)
Think of MetaClaw as a team with two roles: a fast “coach” and a slow “trainer.”
- Fast coach (instant skill updates): When the AI messes up (like editing the wrong file or using the wrong date format), MetaClaw writes a short, clear rule such as “Always make a backup before changing a file” or “Use ISO date format with timezone.” These rules are saved in a “skill library.” The next time a similar task comes up, the AI reads the relevant rules first. This is like putting helpful sticky notes in the AI’s notebook—no heavy training needed.
- Slow trainer (deeper learning during your downtime): When you’re not using your computer (sleep hours, no keyboard/mouse movement, or you’re in a calendar event), MetaClaw uses those moments to fine-tune the AI’s underlying abilities in the cloud. This is like sending the AI to the gym at night. It uses feedback from how well the AI performed after new skills were added to steadily improve its “brain” (model weights).
A few important safety/quality ideas make this work well:
- Versioning (don’t train on stale info): Every conversation or task is stamped with which “skill library version” the AI was using. If a new skill is added, the system throws out old training data that no longer reflects the AI’s current behavior. That way, it doesn’t learn from outdated mistakes.
- Smart scheduling (don’t interrupt): A background scheduler only runs deeper training when you’re inactive, so the AI stays responsive when you need it.
- No special hardware needed: The heavy training happens in the cloud, so you don’t need a fancy GPU locally.
Simple analogy:
- Skills = quick, written rules added to the AI’s playbook right after a mistake.
- Policy training = workouts that build long-term strength, done when the “player” isn’t in a game.
- Versioning = keeping score only after the newest rules are in place, so training uses the right results.
What the researchers found
The team tested MetaClaw in two main ways:
- MetaClaw-Bench (simulated “workdays” with real command-line tasks)
- 934 tasks spread across 44 “days,” mixing file edits and multiple-choice questions.
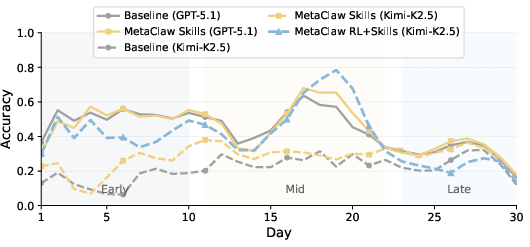
- Just adding skills (the fast coach) made a noticeable difference. For one model, accuracy improved by up to 32% (relative improvement).
- Using both skills and the deeper training (the full system) made the biggest jump:
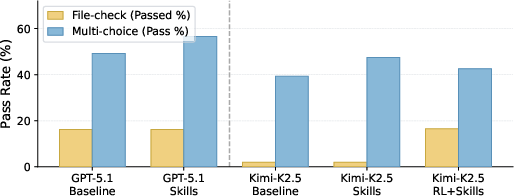
- A mid-tier model (“Kimi-K2.5”) went from 21.4% to 40.6% accuracy.
- End-to-end task completion (strict checks) improved more than 8× on one part of the benchmark.
- File-check pass rates on another part rose by 185%.
- AutoResearchClaw (a long, 23-stage “from idea to paper” research pipeline)
- Even with only skills (no heavy training), the AI:
- Reduced retries by about 25%.
- Cut “refine” loops by 40%.
- Completed more stages and was overall 18% more robust.
Why this matters:
- Quick rule updates helped stop repeat mistakes immediately.
- Deeper training later made the AI more reliable at finishing complex tasks.
- A weaker model combined with MetaClaw nearly matched the starting accuracy of a stronger model—showing that smart learning can partly make up for smaller “brains.”
Why these results are important
- Always-on improvement: The AI keeps learning from daily use without shutting down.
- Fewer repeated mistakes: Turning failures into simple rules helps right away.
- Respecting your time: Big training runs happen when you’re not using the computer.
- Cost-effective: You can get strong performance from a mid-level model by letting it learn continuously.
- Flexible and general: The same approach helped both command-line tasks and a long research workflow.
Final takeaway
MetaClaw shows a practical path for everyday AI helpers to grow smarter in the real world. It combines:
- Fast, low-cost learning from mistakes (skills you can use immediately), and
- Slower, stronger upgrades during idle time (deeper training in the cloud).
This two-speed learning system means your AI can evolve alongside your needs—like a student who adds tips to their notes during class and studies more deeply after school—leading to fewer errors, more finished tasks, and better performance over time.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. These items are intended to guide follow-on research and engineering work.
- Real-world deployment validation: Results are shown on an authored simulation (MetaClaw-Bench) and one pipeline (AutoResearchClaw); there is no evaluation on live user traffic with naturally occurring task distributions, noise, and long-horizon drift.
- Generalization breadth: Adaptation is demonstrated on CLI-centric tasks and a single research pipeline; it remains unclear how MetaClaw performs on other modalities (web agents, GUI automation, APIs, robotics), or multi-step tool use beyond shells.
- Reward modeling details: The process reward model (PRM) is treated as a black box; its training data, calibration, domain coverage, and robustness to distribution shift are unspecified, raising questions about reward misspecification and gaming.
- PRM drift and co-evolution: As skills and policies evolve, the reward function itself may become stale; no mechanism is provided to detect or adapt PRM drift, or to jointly update PRM with the agent while avoiding feedback loops.
- Failure detection reliability: The framework assumes accurate failure identification (to drive skill evolution) and process rewards; how to handle ambiguous outcomes, partial credit, or noisy/incorrect checker signals is not addressed.
- Support–query separation side effects: Flushing all pre-generation trajectories may discard valuable data and reduce sample efficiency; alternatives (e.g., importance weighting, off-policy corrections) are not explored.
- Data scarcity during frequent skill updates: If skills evolve rapidly, the query buffer may remain small, impeding stable RL; the paper does not quantify the minimal data needed per training window or strategies to amortize this.
- RL-only vs skills-only ablations: There is no condition evaluating RL without skills or memory baselines; the individual and combined contributions of each component (and versioning) are not fully disentangled.
- Task-type trade-offs: RL improved execution-heavy file-checks but decreased multi-choice accuracy; multi-objective or Pareto optimization to avoid such regressions is not investigated.
- Catastrophic interference: How weight updates interact with previously effective skills (e.g., degrading their utility) is not measured; methods to preserve skill efficacy under RL updates are absent.
- Skill evolver reliability: The LLM-based evolver may synthesize incorrect, redundant, or conflicting skills; criteria for acceptance, automated validation, deduplication, and conflict resolution are not specified.
- Skill quality measurement: There is no metric for skill causal impact (e.g., counterfactual evaluation) or for ranking/pruning based on utility across tasks.
- Skill library scaling: Prompt budgets and retrieval complexity with a growing skill set are not addressed; compression, summarization, or hierarchical indexing strategies are left unexplored.
- Retrieval robustness: The embedding-based retrieval’s sensitivity to domain shift, lexical variation, and skill collisions is not analyzed; adaptive retrieval or learned selectors could be needed.
- Negative transfer and guardrails: Mechanisms to detect and prevent harmful or task-inappropriate skill application (e.g., over-conservative “always back up” rules in time-critical tasks) are not included.
- Safety and security: Evolving skills may be vulnerable to prompt injection or adversarial trajectories that seed harmful behaviors; there is no adversarial evaluation or safety vetting pipeline for new skills.
- Privacy and compliance: Trajectory storage, file-system context, and calendar data are used for training and scheduling; privacy safeguards, on-device alternatives, and enterprise compliance (PII/PHI) are not detailed.
- OMLS practicality and portability: Idle-window detection depends on user configuration, OS APIs, and Google Calendar; robustness in headless servers, shared workstations, or enterprise environments is unclear.
- Training interruption and latency: Weight hot-swaps “briefly interrupt inference,” but the downtime magnitude and user-perceived impact are not measured or bounded.
- Cloud LoRA constraints: Cost, throughput, and latency of frequent cloud fine-tunes—especially under tight idle windows—are not quantified; fallback strategies when cloud endpoints are unavailable are missing.
- Multi-tenant scaling: The framework targets a single user/agent; extensions to multi-user, multi-tenant settings (shared skills, per-user specialization, interference) are not studied.
- Model generality: Full pipeline results are shown only for Kimi-K2.5 due to available LoRA endpoints; portability to other providers/models and behavior on stronger/weaker LLMs remain open.
- Hyperparameter sensitivity: Thresholds for triggering skill evolution, retrieval top-k, RL batch sizes, and scheduler parameters are not systematically ablated, limiting reproducibility and deployment tuning.
- Theoretical framing: The claim of “continual meta-learning” lacks a formal objective or convergence analysis; sample efficiency and stability guarantees under non-stationary streams are not provided.
- Long-horizon longevity: Behavior over months of evolution (skill library growth, model drift, forgetting) is unreported; maintenance strategies (retirement of stale skills, periodic consolidation) are unaddressed.
- Reward hacking risk: Agents may learn to satisfy PRM/checkers without truly solving tasks (e.g., schema gaming); diagnostics and defenses against spec–implementation gaps are not included.
- Evolver–policy coupling: Using the same (or similar) LLM family for skill synthesis and policy may induce self-reinforcing errors; diversity, cross-model checks, or human-in-the-loop gating are not examined.
- Cross-domain transfer claims: Only one non-CLI domain (AutoResearchClaw) is tested; broader tests across heterogeneous pipelines are needed to substantiate claims of general-purpose adaptability.
- Cost accounting: Token, compute, and financial costs of continual prompting, retrieval, and periodic fine-tuning are not reported; cost–benefit analysis for production viability is missing.
- Rollback and version control: Safe rollback of skills and model weights after regressions, and governance over versions (auditing, reproducibility), are not described.
- Robustness to extreme drift: Benchmarks increase difficulty, but abrupt tool/API changes, unseen file systems, or policy ruleset changes are not simulated; resilience strategies remain open.
- Human oversight and UX: Interfaces for reviewing/editing skills, overriding evolver decisions, and resolving conflicts with organizational policies are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging MetaClaw’s skill-driven fast adaptation, opportunistic scheduling, and support–query versioning without requiring model retraining downtime.
- Evolving DevOps and IT Ops CLI assistants for incident response and release operations
- Sectors: software engineering, IT operations, SRE
- How it works: inject distilled skills from failed runs (e.g., “create .bak before modifying,” “validate JSON schema,” “confirm before destructive commands”); trigger LoRA fine-tunes during idle windows via OMLS; separate support vs. query data to avoid stale gradients.
- Tools/products/workflows: OMLS daemon for sleep/inactivity/calendar scheduling; skill library packs for CI/CD; “Process Reward Model (PRM) from CI checks” pipeline; hot-swap LoRA manager.
- Assumptions/dependencies: reliable PRMs from test/linters/deploy gates; cloud fine-tuning endpoint; org approval to monitor system idle and calendar; robust rollback/blue–green deployment.
- Data engineering and analytics ETL validators that stop repeated breakages
- Sectors: data platforms, analytics, finance, healthcare
- How it works: distill skills from pipeline failures (schema mismatches, timestamp formats, naming conventions); enforce transform rules via skill retrieval; run opportunistic LoRA updates overnight.
- Tools/products/workflows: “ETL SkillOps” (skill linter + dedup + retrieval); PRM from data quality checks; Airflow/Dagster adapters to stamp generation versions on runs.
- Assumptions/dependencies: accessible validation logs; embedding store/retrieval quality; data governance for trajectory storage.
- Knowledgeable customer support and helpdesk agents that learn new procedures without retraining
- Sectors: customer support, telecom, retail, SaaS
- How it works: convert escalations and failed conversations into succinct skills (policy clarifications, escalation rules, PII handling); immediate prompt injection prevents repeated mistakes.
- Tools/products/workflows: “Lesson-to-Skill” evolver from ticket CRM; skill packs per product/version; skill versioning across channels.
- Assumptions/dependencies: safe handling of customer data; domain approval of synthesized skills; guardrails for policy conformance.
- Developer productivity assistants that adapt to repo-specific rules and tests
- Sectors: software, open-source tooling
- How it works: distill skills from failing unit/integration tests and code review feedback; opportunistic LoRA with PRM derived from pass/fail tests and lint policies.
- Tools/products/workflows: GitHub/GitLab app to stamp skill generation; “PRM Studio” to convert CI signals into process rewards; IDE extensions that retrieve repo skills.
- Assumptions/dependencies: stable test signals; permission for code telemetry; cost controls for fine-tunes.
- Research automation pipelines with fewer retries and refinements (AutoResearchClaw-style)
- Sectors: academia, R&D, pharma, industrial research
- How it works: capture stage-level failures (e.g., citation formatting, data validation) as reusable skills; inject across pipeline stages to cut retry/refine cycles (as shown: −24.8% retries, −40% refines).
- Tools/products/workflows: pipeline executor plugin for skill injection; “Stage-skill mapper” to route skills to 18+ LLM-driven stages; runbooks distilled into skills.
- Assumptions/dependencies: fine-grained pipeline telemetry; QA checks as PRM; reproducible sandbox.
- Compliance-by-construction assistants for regulated content and workflows
- Sectors: finance, healthcare, legal, HR
- How it works: convert compliance violations and audit findings into skills (PII redaction, retention rules, naming/format standards) that apply preemptively; version skills to match current rulesets.
- Tools/products/workflows: “Compliance Skill Packs” curated by risk teams; policy-aware retrieval; audit logs with generation stamps.
- Assumptions/dependencies: regulator-approved skill reviews; provenance tracking; safe prompt injection policies.
- Cybersecurity analyst co-pilots that refine playbooks from incidents
- Sectors: cybersecurity, MSSP, SOC
- How it works: distill skills from alert triage errors and post-incident reviews (e.g., “verify path hash before quarantine,” “escalate if IOC matches watchlist”); inject to reduce false negatives/positives.
- Tools/products/workflows: SIEM/SOAR connectors to build PRMs from triage outcomes; skill retrieval during response workflows.
- Assumptions/dependencies: strict data security; human-in-the-loop approval for new skills; incident taxonomy alignment.
- RPA-style back-office task automators that get safer and more reliable over time
- Sectors: operations, supply chain, finance ops
- How it works: skills encode guardrails for spreadsheets, ERP updates, invoice formatting, and reconciliation; LoRA updates run during off-hours with OMLS.
- Tools/products/workflows: RPA connectors (SAP, Oracle, Sheets); skill deduplication and priority; rollback on schema drift.
- Assumptions/dependencies: stable tool access; PRM signals from business rule validators; access controls.
- LLMOps pattern: support–query versioning and data hygiene for continual training
- Sectors: MLOps/LLMOps across industries
- How it works: adopt the paper’s versioning protocol to exclude pre-adaptation failures from RL buffers; maintain clean, post-adaptation datasets for online fine-tunes.
- Tools/products/workflows: “Support/Query Data Lake” with generation stamps and buffer flushing; pipeline hooks in training jobs.
- Assumptions/dependencies: accurate failure detection; consistent generation counters across services; observability.
- Calendar- and idle-aware fine-tuning in enterprise agent platforms
- Sectors: enterprise IT, productivity software
- How it works: OMLS coordinates LoRA training during sleep hours, keyboard inactivity, or meetings; pauses/resumes with mid-batch checkpointing.
- Tools/products/workflows: cross-platform OMLS daemon; IT policy templates; change windows integration (CAB).
- Assumptions/dependencies: user consent for signal monitoring; cloud fine-tune infrastructure; change management approvals.
- Education: auto-grading and tutoring agents that internalize procedural rubrics
- Sectors: education technology
- How it works: distill rubric violations and formatting errors into skills; ensure consistent grading and tutoring feedback without full retrains.
- Tools/products/workflows: LMS connectors; rubric-to-skill evolver; PRM from rubric checks.
- Assumptions/dependencies: fairness audits; de-biasing for student subgroups; privacy compliance (FERPA/GDPR).
- Agent CI for safe updates using MetaClaw-Bench-like suites
- Sectors: software, agent platforms
- How it works: integrate MetaClaw-Bench or similar multi-day simulations into CI to validate that new skills/weights improve end-to-end completion without regressions.
- Tools/products/workflows: “Agent CI Harness” with day-by-day checks; release gates tied to PRM scores.
- Assumptions/dependencies: representative tasks; cost budgeting for CI runs.
Long-Term Applications
These applications require further research, scaling, tooling maturity, or policy development before broad deployment.
- Federated skill sharing and privacy-preserving continual learning across teams/tenants
- Sectors: enterprise software, healthcare, finance
- Vision: share anonymized, vetted skills across departments or organizations while keeping sensitive trajectories private; converge on “best-practice” skills.
- Tools/products/workflows: differential privacy for skill texts; federation/consortia governance; skill provenance and licensing.
- Assumptions/dependencies: legal frameworks for knowledge sharing; robust de-identification; incentive mechanisms.
- Cross-vendor standardized “SkillOps” ecosystem and marketplaces
- Sectors: software platforms, marketplaces, standards bodies
- Vision: common schemas for skill definition, priority, scope, and evaluation; marketplaces of audited skill packs (e.g., SOC2, HIPAA, PCI).
- Tools/products/workflows: skill linter/validator; skill impact analyzer; versioned dependency graphs between skills.
- Assumptions/dependencies: consensus on standards; liability and certification models.
- Production-safe online RL for agents with formal guardrails
- Sectors: all safety-critical domains
- Vision: continuous RL updates under safety constraints, with rollback, counterfactual evaluation, and change auditing; PRMs that capture process-level safety and compliance.
- Tools/products/workflows: shadow deployment and canary RL; formal safety monitors; counterfactual simulators for process rewards.
- Assumptions/dependencies: mature PRMs; robust off-policy evaluation; regulatory acceptance of self-updating systems.
- Domain-general process reward models and reward engineering toolkits
- Sectors: software, education, healthcare, finance
- Vision: reusable PRMs trained from logs, checkers, and human feedback that score stepwise processes (not just final outputs).
- Tools/products/workflows: “PRM Studio” for data collection, weak supervision, and evaluation; domain adapters (CI, LMS, EHR, ERP).
- Assumptions/dependencies: labeled or proxy-labeled process data; agreement on reward taxonomies.
- On-device or edge continual adaptation with LoRA hot-swaps
- Sectors: mobile, robotics, IoT
- Vision: run skill injection locally; schedule compact LoRA updates on-device or near-edge to reduce latency and protect privacy.
- Tools/products/workflows: low-footprint training runtimes; energy-aware OMLS; secure model artifact delivery.
- Assumptions/dependencies: hardware acceleration; thermal/energy constraints; secure storage.
- Multi-modal, tool-rich agents (software + robotics) with unified meta-learning
- Sectors: robotics, manufacturing, warehouse automation
- Vision: distill natural-language “operational heuristics” that span both software and physical tasks; RL updates respect safety envelopes.
- Tools/products/workflows: multi-modal skill schema; sim-to-real PRM validation; safety interlocks.
- Assumptions/dependencies: high-fidelity simulators; robust tooluse safety; human oversight.
- Regulatory frameworks for adaptive AI systems that change post-deployment
- Sectors: public policy, compliance
- Vision: certification regimes for versioned skills and online RL; audit trails for skill generation and buffer flushing; reporting of adaptation events.
- Tools/products/workflows: “Adaptation Ledger” with cryptographic provenance; periodic conformance audits; incident reporting standards.
- Assumptions/dependencies: harmonized regulations; third-party auditors; legal definitions of “material model change.”
- Cost-optimized deployment of smaller models made competitive via MetaClaw
- Sectors: startups, cost-sensitive enterprises
- Vision: deploy mid-tier LLMs with MetaClaw to approach larger-model performance (as shown by Kimi-K2.5 nearly closing the GPT gap), reducing inference cost.
- Tools/products/workflows: “Capability Gap Analyzer” to target skill/RL investments; dynamic routing to stronger models only when needed.
- Assumptions/dependencies: stable gains across domains; guardrails against capability overclaims.
- Automated curriculum and skill lifecycle management at scale
- Sectors: LLMOps, platform engineering
- Vision: auto-cluster failures, propose consolidated skills, detect redundancy/conflicts, retire obsolete skills, and measure marginal utility.
- Tools/products/workflows: skill graph maintenance; A/B skill ablations; automated skill deprecation with safety checks.
- Assumptions/dependencies: robust evaluation signals; explainability for skill decisions.
- Benchmarking and conformance testing for continual agents in the wild
- Sectors: academia, consortia, platform vendors
- Vision: community benchmarks like MetaClaw-Bench that reflect non-stationary workloads, with standardized metrics for file-check completion, process robustness, and data hygiene.
- Tools/products/workflows: reproducible multi-day task suites; reference PRMs; leaderboard protocols that penalize stale-reward contamination.
- Assumptions/dependencies: shared datasets and simulators; cost-sharing for long-horizon evaluations.
Notes on common assumptions and dependencies across applications:
- Reward modeling quality is pivotal; weak or misaligned PRMs can mis-train policies.
- Access to cloud LoRA fine-tuning (or equivalent) and safe hot-swapping infrastructure is required for weight updates.
- OMLS relies on user consent and enterprise policy for monitoring sleep, inactivity, and calendar signals.
- Reliable detection of failures and precise skill generation/versioning are necessary to prevent data leakage and stale-reward contamination.
- Data governance, privacy, and security controls must be in place for storing trajectories and skills.
- Embedding-based retrieval quality and prompt budget constraints impact how many and which skills can be used effectively.
- Cost, latency, and provider API stability influence feasibility at production scale.
Glossary
- Cloud LoRA fine-tuning: Low-Rank Adaptation performed on remote/cloud infrastructure to update model weights efficiently with small parameter ranks. "Opportunistic policy optimization performs gradient-based weight updates via cloud LoRA fine-tuning using RL with a process reward model"
- Composite robustness score: A single metric combining multiple pipeline-level measures into a weighted average to assess robustness. "and a composite robustness score (weighted average of stage completion rate at 40\%, retry reduction at 30\%, and refine cycle efficiency at 30\%)"
- Continual meta-learning: A learning paradigm where a system continuously improves both its performance and its ability to adapt across a stream of evolving tasks. "We present MetaClaw, a continual meta-learning framework that jointly maintains a base LLM policy and an evolving skill library of reusable behavioral instructions"
- Embedding-based retrieval: Selecting relevant items (e.g., skills) based on similarity in a learned vector space. "Retrieve(\mathcal{S}, \tau) \subseteq \mathcal{S} selects the most relevant skills for the current task via embedding-based retrieval."
- Experience distillation: Converting raw trajectory experience into concise, reusable guidance or rules rather than retaining full logs. "Skill-driven adaptation evolves the skill library via a gradient-free experience distillation process:"
- GRPO: An online policy gradient method used to fine-tune LLMs for reasoning/agentic tasks. "In practice, policy optimization is realized via cloud LoRA fine-tuning using GRPO, deferred to idle windows by the Opportunistic Meta-Learning Scheduler (OMLS)."
- Hot-swap model weights: Replacing the currently served model parameters with updated ones without lengthy service interruption. "Hot-swap model weights"
- ISO 8601: An international standard for date and time representations, often including timezone offsets. "temporal format compliance, normalizing natural-language time expressions to ISO~8601 format with timezone offsets"
- LLM agents: LLM-driven systems that perceive context and take actions to accomplish multi-step tasks. "LLM agents have demonstrated remarkable capabilities across complex tasks"
- MAML: Model-Agnostic Meta-Learning, an algorithm that optimizes for rapid adaptation via inner- and outer-loop updates. "This learning trajectory mirrors the MAML inner-loop update structure"
- Meta-model: The combined state of a system’s core policy parameters and its higher-level adaptation artifacts (e.g., skill library). "The agent's behavior at any point in time is fully determined by a meta-model:"
- Meta-parameter: A parameter governing how a model adapts (rather than the model’s immediate behavior), such as a skill library used at inference. "As a meta-parameter, accumulates behavioral knowledge across the entire task stream"
- Non-stationary distribution: A task distribution that changes over time, requiring continual adaptation. "drawn from a non-stationary distribution ."
- Opportunistic Meta-Learning Scheduler (OMLS): A component that detects user idle periods and schedules training to avoid disrupting service. "triggered only during user-inactive windows by the Opportunistic Meta-Learning Scheduler (OMLS)"
- Opportunistic policy optimization: Deferring gradient-based policy updates to idle periods, using data collected after recent adaptations. "Opportunistic policy optimization uses RL with a process reward model (PRM) to update model weights via cloud LoRA fine-tuning"
- PEARL: An off-policy meta-RL algorithm that learns probabilistic context variables for fast task adaptation. "PEARL infers a probabilistic context variable for off-policy adaptation"
- PRM (Process Reward Model): A reward function that scores intermediate steps or processes, enabling more granular RL feedback. "using RL with a process reward model (PRM)"
- ProMP: A meta-RL method that incorporates proximal/trust-region constraints during meta-policy search. "ProMP applies trust-region constraints at the meta-level."
- Proxy-based architecture: A deployment pattern where a lightweight local proxy coordinates with remote services to run large models without local GPUs. "Built on a proxy-based architecture, MetaClaw scales to production-size LLMs without a local GPU."
- Query data: Post-adaptation trajectories that reflect current capabilities and are valid for training policy updates. "Query data consists of trajectories collected after adaptation has taken effect;"
- RL buffer: A storage of trajectories used to compute gradient updates during reinforcement learning. "The RL buffer accumulates query trajectories across all post-adaptation generations,"
- RLHF: Reinforcement Learning from Human Feedback, a paradigm for aligning models using human-provided reward signals. "RLHF and its variants establish the use of reward signals to fine-tune LLM behavior,"
- RL2: A meta-RL approach where a recurrent policy learns to adapt by using its hidden state to encode task information. "RL\textsuperscript{2} trains a recurrent policy whose hidden state implicitly encodes task context,"
- Skill-driven fast adaptation: Immediate, gradient-free update to the agent’s behavior by injecting distilled skills into prompts. "Skill-driven fast adaptation analyzes failure trajectories and synthesizes new skill instructions that are immediately injected into the agent's prompt"
- Skill evolver: An LLM component that analyzes failures and synthesizes new behavioral instructions (skills). "where is a skill evolver, an LLM that analyzes failure trajectories and synthesizes new behavioral instructions."
- Skill generation versioning: A mechanism to tag data with the current skill library version to prevent mixing pre- and post-adaptation data during training. "To prevent stale reward contamination, a skill generation versioning mechanism strictly separates support data (failure trajectories consumed by skill evolution) from query data (post-adaptation trajectories used for RL updates)."
- Skill library: A set of reusable, natural-language behavioral instructions injected at inference time to guide the agent. "an evolving skill library of reusable behavioral instructions"
- Stale reward contamination: Using rewards from trajectories collected under outdated conditions, leading to misaligned gradient updates. "To prevent stale reward contamination, a skill generation versioning mechanism strictly separates support data ... from query data ..."
- Support data: Pre-adaptation failure trajectories used to induce new skills but excluded from RL updates. "Support data consists of trajectories whose failures drive adaptation of the skill library ;"
- Task distribution drift: The phenomenon where the types of tasks encountered change over time, reducing performance of a static model. "As the task distribution drifts, a frozen model becomes increasingly misaligned with actual usage patterns"
- Top-k retrieval: Selecting the top k most similar items according to a similarity metric during retrieval. "with top- retrieval via cosine similarity over sentence embeddings."
- Zero service downtime: Ensuring that adaptations take effect without interrupting the agent’s availability to users. "taking effect immediately with zero service downtime."
Collections
Sign up for free to add this paper to one or more collections.