RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
Abstract: We propose RLAnything, a reinforcement learning framework that dynamically forges environment, policy, and reward models through closed-loop optimization, amplifying learning signals and strengthening the overall RL system for any LLM or agentic scenarios. Specifically, the policy is trained with integrated feedback from step-wise and outcome signals, while the reward model is jointly optimized via consistency feedback, which in turn further improves policy training. Moreover, our theory-motivated automatic environment adaptation improves training for both the reward and policy models by leveraging critic feedback from each, enabling learning from experience. Empirically, each added component consistently improves the overall system, and RLAnything yields substantial gains across various representative LLM and agentic tasks, boosting Qwen3-VL-8B-Thinking by 9.1% on OSWorld and Qwen2.5-7B-Instruct by 18.7% and 11.9% on AlfWorld and LiveBench, respectively. We also that optimized reward-model signals outperform outcomes that rely on human labels. Code: https://github.com/Gen-Verse/Open-AgentRL

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RLAnything, a way to train AI systems (especially LLMs, or LLMs) that act like agents in the world. Think of an agent as a player in a game: it looks at the world, decides what to do, and tries to reach a goal. RLAnything helps this “player” learn better by improving three parts at the same time:
- the policy (the agent’s decision-maker),
- the environment (the tasks or “levels” the agent plays), and
- the reward model (the “referee” that judges each move and the final result).
Instead of training only the agent, RLAnything makes all three parts work in a loop, giving feedback to each other and getting stronger together.
What questions did the researchers ask?
The paper asks simple, practical questions:
- Can we give the agent richer, step-by-step feedback (not just a final “win or lose”) so it learns faster on long tasks?
- Can we train the reward model (the judge) to become more reliable by checking its own consistency and the actual outcomes?
- Can we automatically adjust task difficulty (the environment) based on how the agent is doing, so training stays challenging but not impossible?
- If we train these three parts together in a closed loop, do agents perform better on real tasks like using a computer, playing text-based games, or writing code?
How did they do it?
The team built a “closed-loop” training system where the policy, reward model, and environment keep improving each other. Here’s the idea in everyday terms:
The three parts (with analogies)
- Policy (the decision-maker): This is the agent that chooses actions. Imagine a player making moves in a game.
- Reward model (the judge/referee): This model reads what the agent did at each step and decides if that step helped or hurt the final goal. It also looks at the final outcome (success or failure). Think of a referee who both scores each play and also knows who won the match.
- Environment (the tasks/levels): These are the challenges presented to the agent (like missions in a game). The difficulty can be changed to be easier or harder.
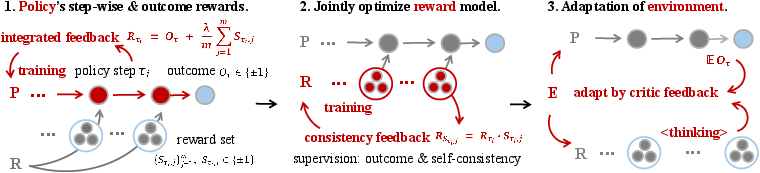
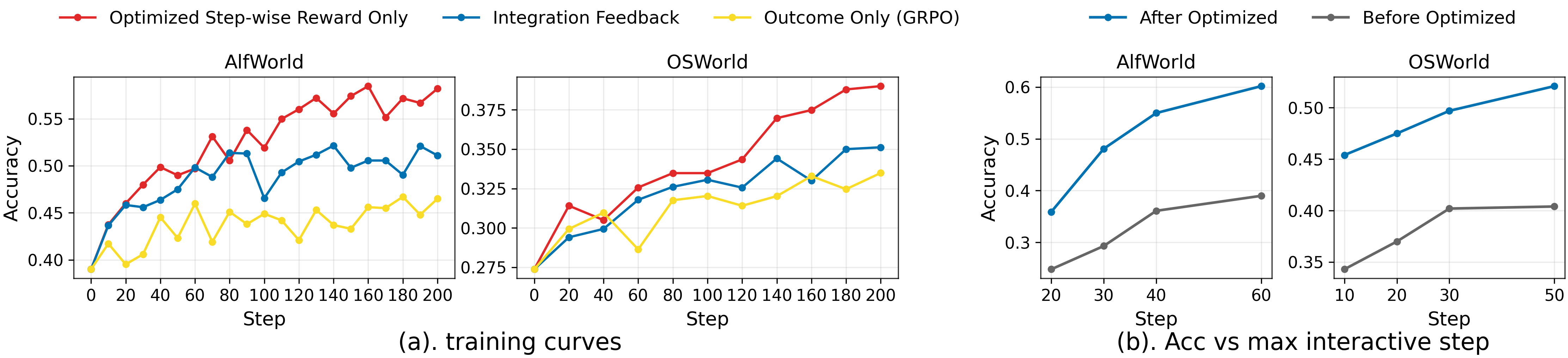
Integrated feedback (step-wise + outcome)
Long tasks are hard to learn from if you only get feedback at the end (“win” or “lose”). RLAnything combines two signals:
- Outcome reward: Did the agent finish the task? This is the final win/lose.
- Step-wise reward: Was each step helpful or harmful? The reward model gives +1 or −1 per step after reasoning.
Together, the agent gets both overall supervision and detailed hints along the way—like a scoreboard plus coaching tips after every move.
Teaching the reward model to be consistent
The reward model itself is trained too. It looks at:
- Whether its step judgments agree with the final outcome,
- Whether multiple independent evaluations agree with each other (self-consistency).
This “consistency feedback” helps the judge become more reliable over time, which in turn helps train the policy better.
Adapting the environment automatically
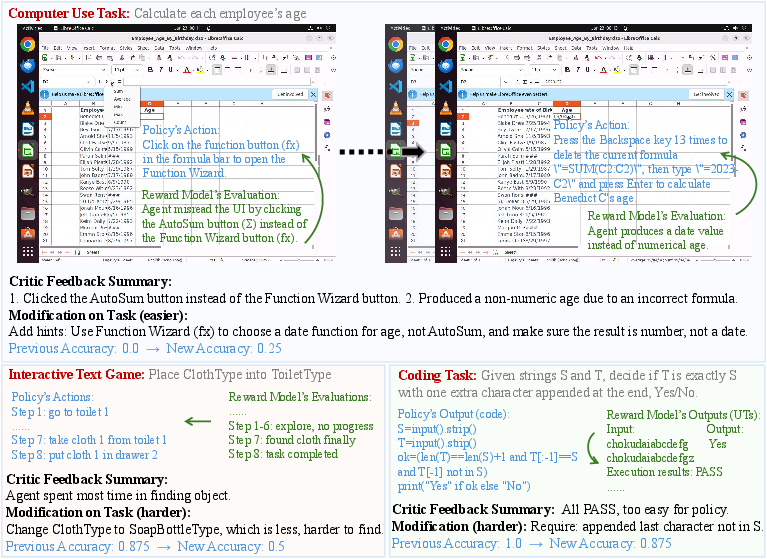
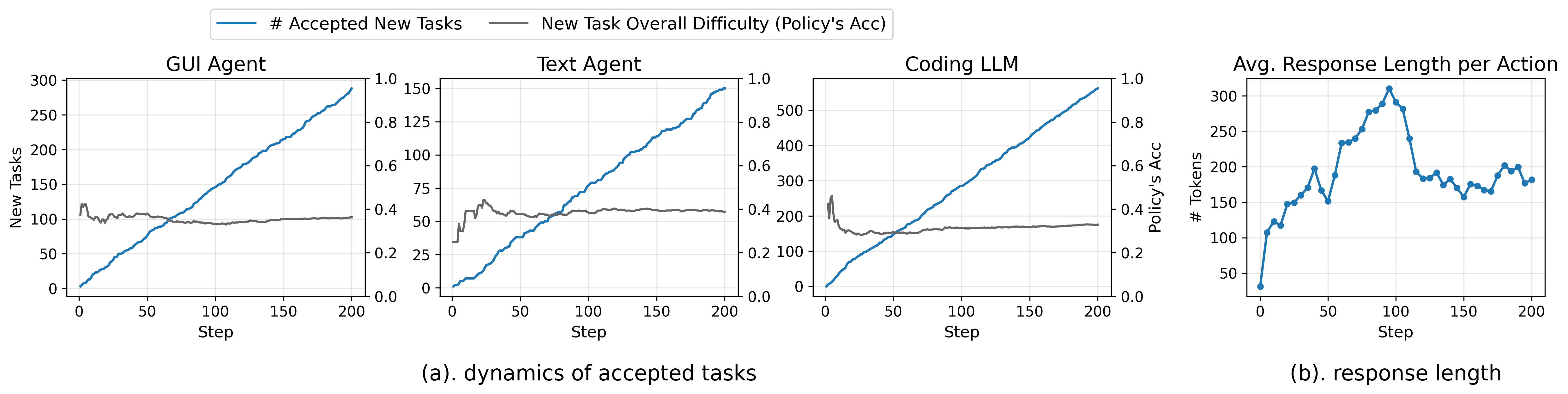
RLAnything adjusts task difficulty using “critic feedback” (summaries of mistakes from the reward model’s reasoning). If a task is too easy, it’s made harder; if too hard, it’s made easier. Think of a game that raises or lowers the level based on how the player is performing, but with smart hints about what to change (e.g., remove a shortcut, add a step, or change the object to search for).
A key theory insight (in simple terms)
The paper shows that the reward model learns best when it sees a balanced mix of successes and failures. If tasks are too easy or too hard, the judge mostly sees one kind of result (all wins or all losses), which makes it harder to learn accurate step scores. That’s why adapting difficulty isn’t just good for the agent—it also trains a better judge.
What did they find?
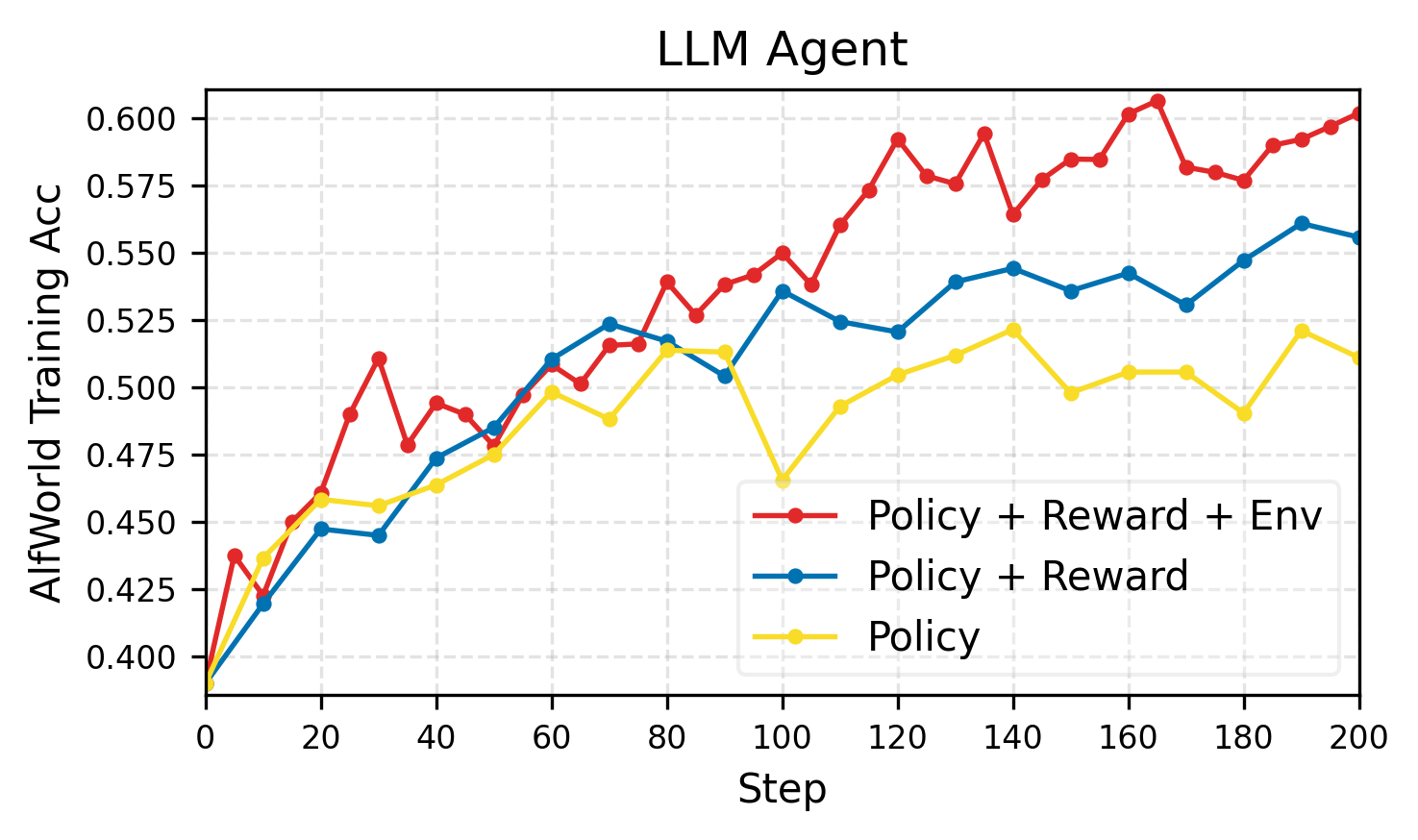
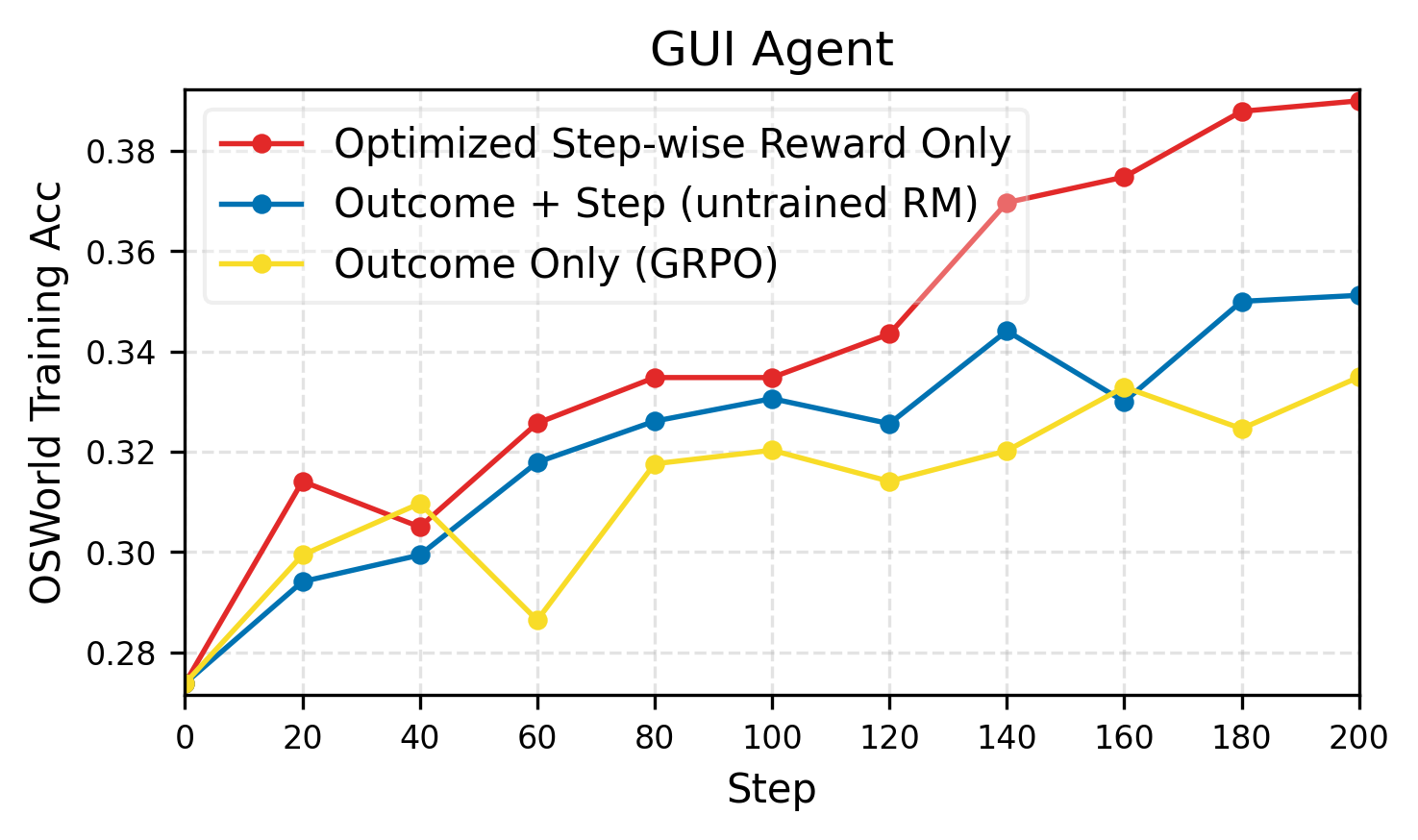
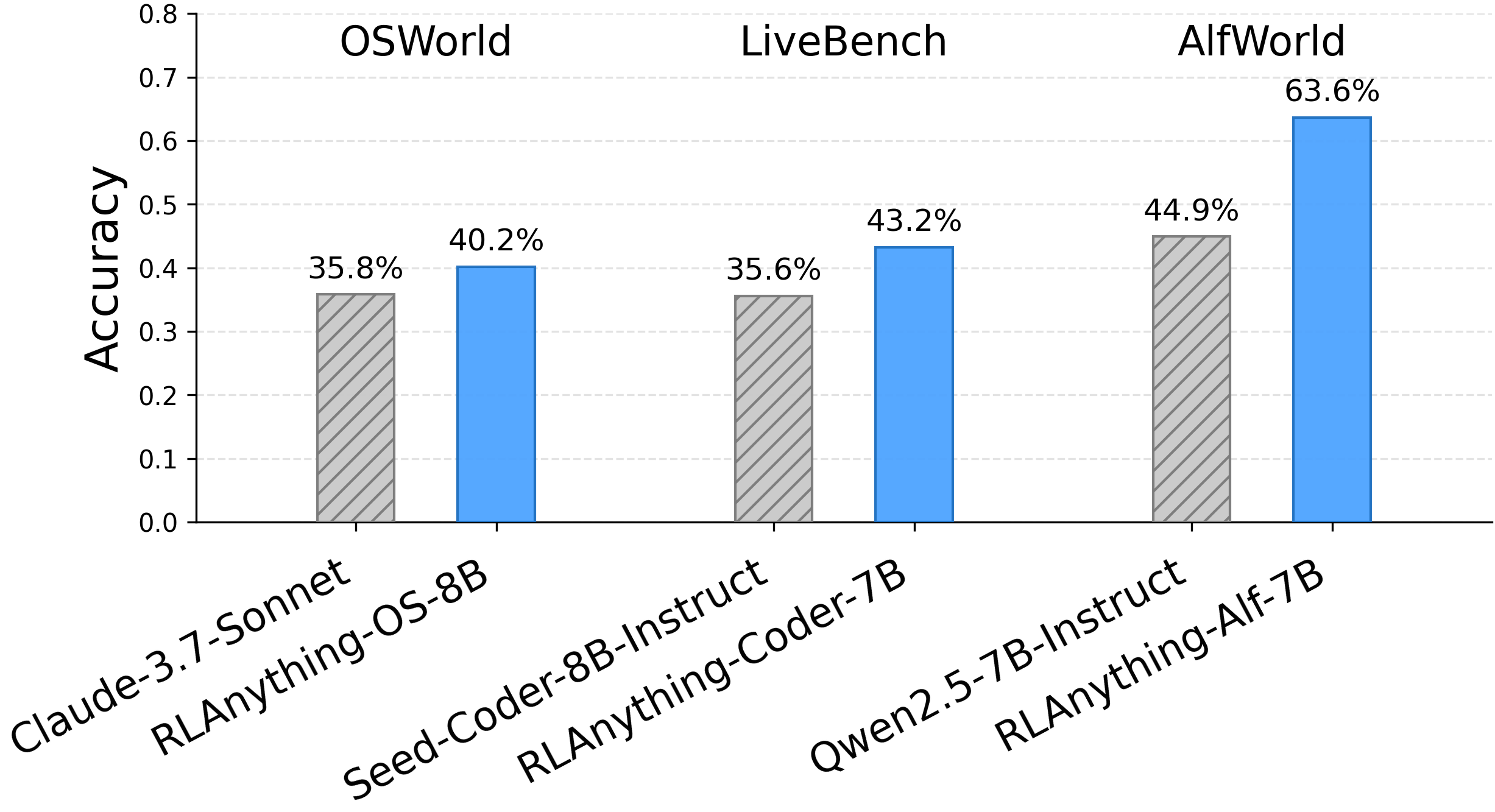
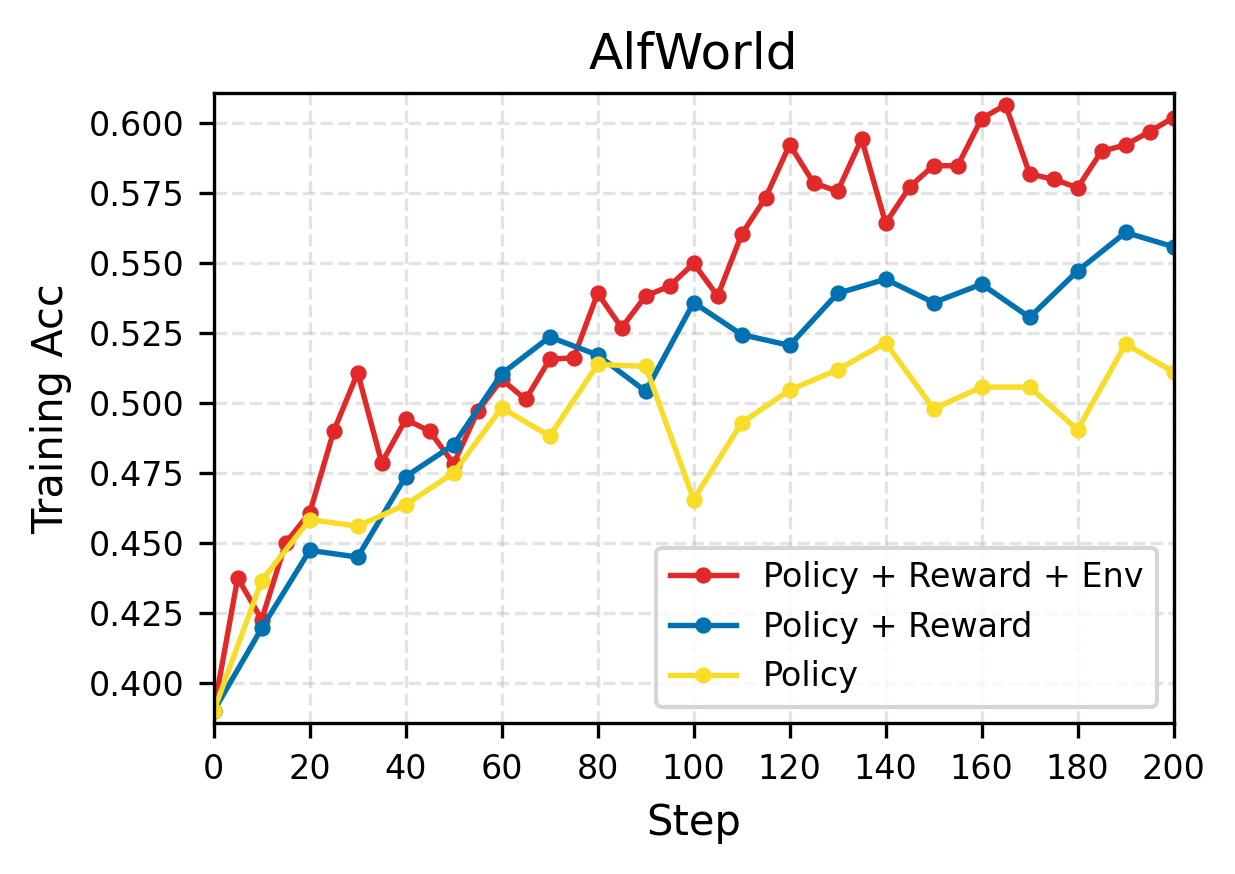
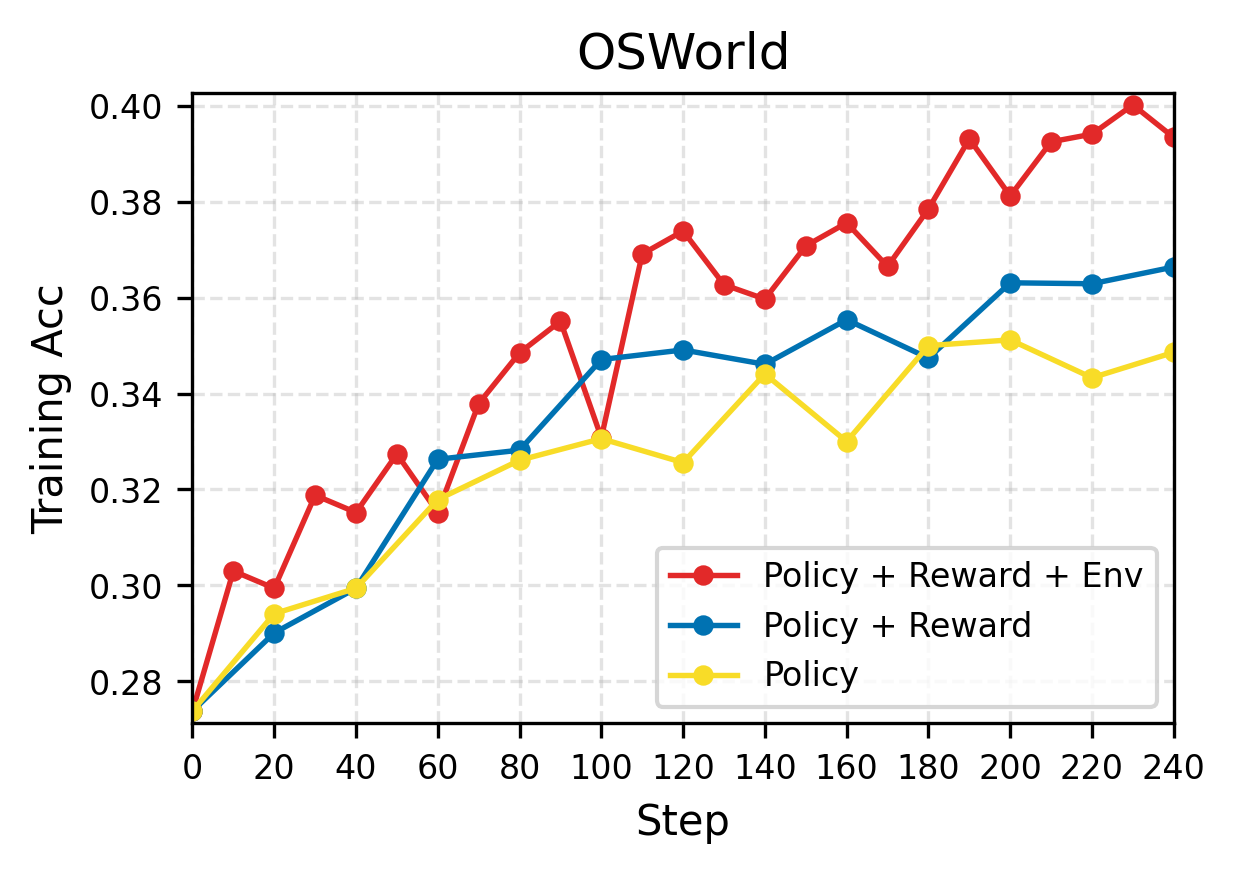
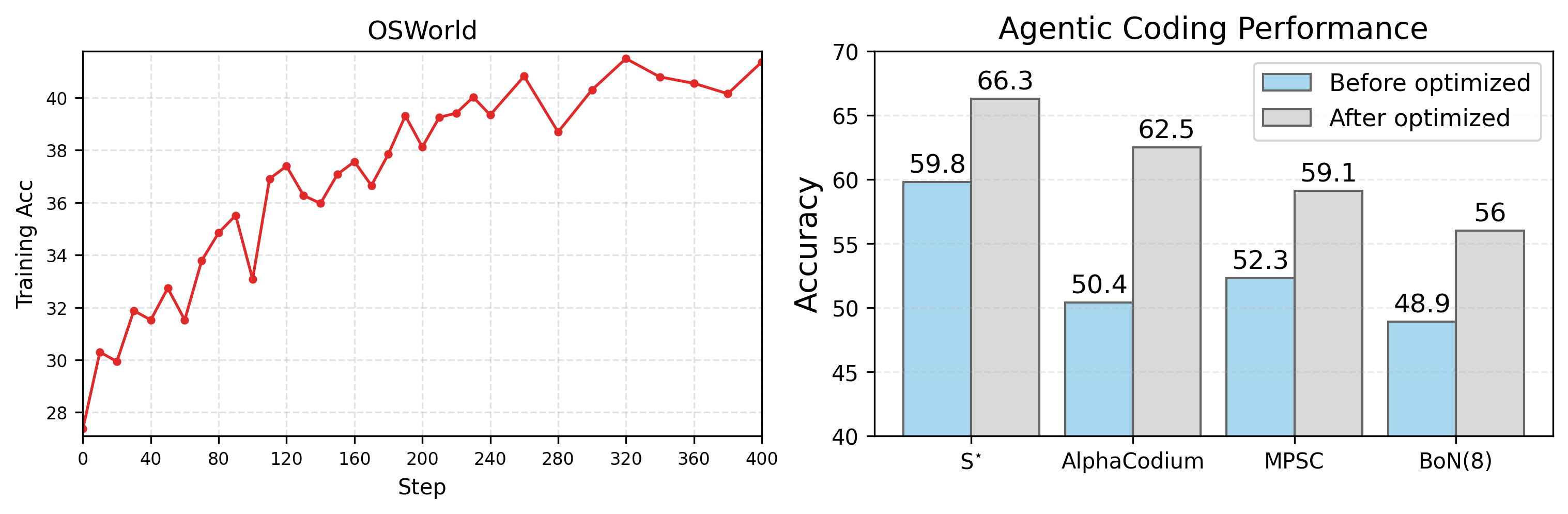
Across three kinds of tasks—using a computer (OSWorld), playing text-based games (AlfWorld), and coding—adding each dynamic component (policy, reward, environment) improved performance. The full RLAnything system helped the most.
Highlights:
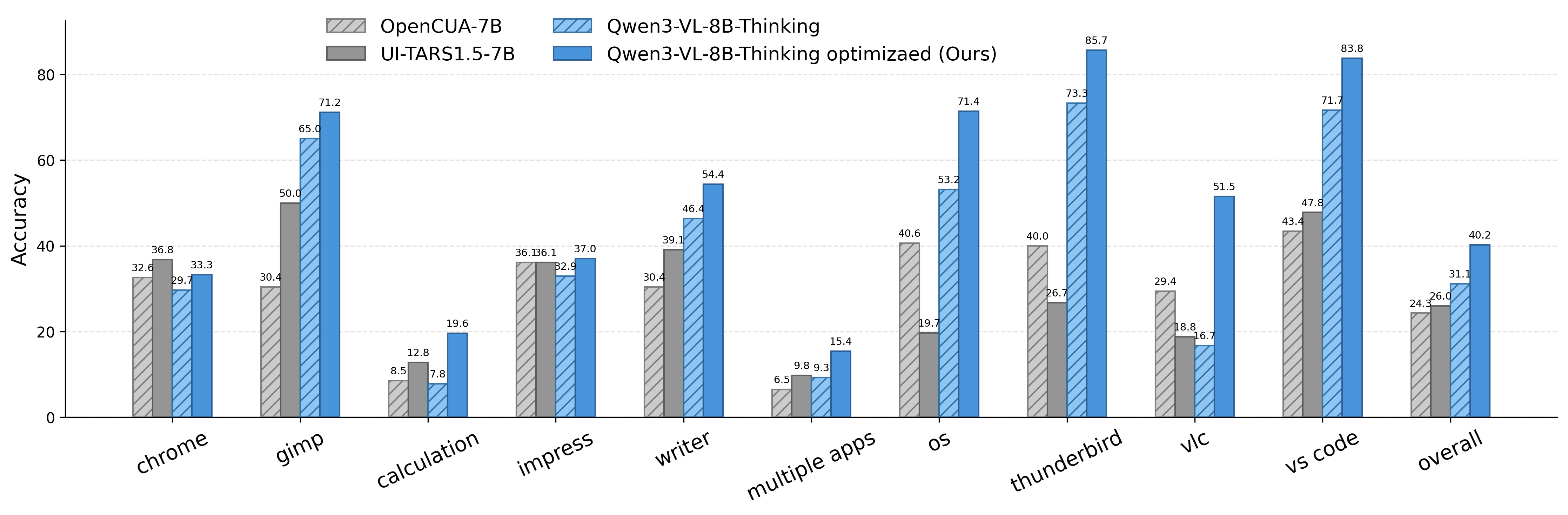
- Computer-use agent (Qwen3-VL-8B-Thinking) improved by about 9.1% on OSWorld overall, and about 5.2% on out-of-distribution tasks (new/unseen types).
- Text-game agent (Qwen2.5-7B-Instruct) improved by 18.7% on AlfWorld and by 11.9% on LiveBench coding tasks.
- The reward model’s “step scoring” and its ability to predict future outcomes both got better when trained with consistency feedback and environment adaptation.
- Integrated rewards (step-wise + outcome) were clearly better than outcome-only rewards, especially on long tasks where final results are sparse.
- In some cases, using the optimized reward model’s step-wise signals alone beat training with human-labeled outcome scripts. That means you can rely less on costly human labels.
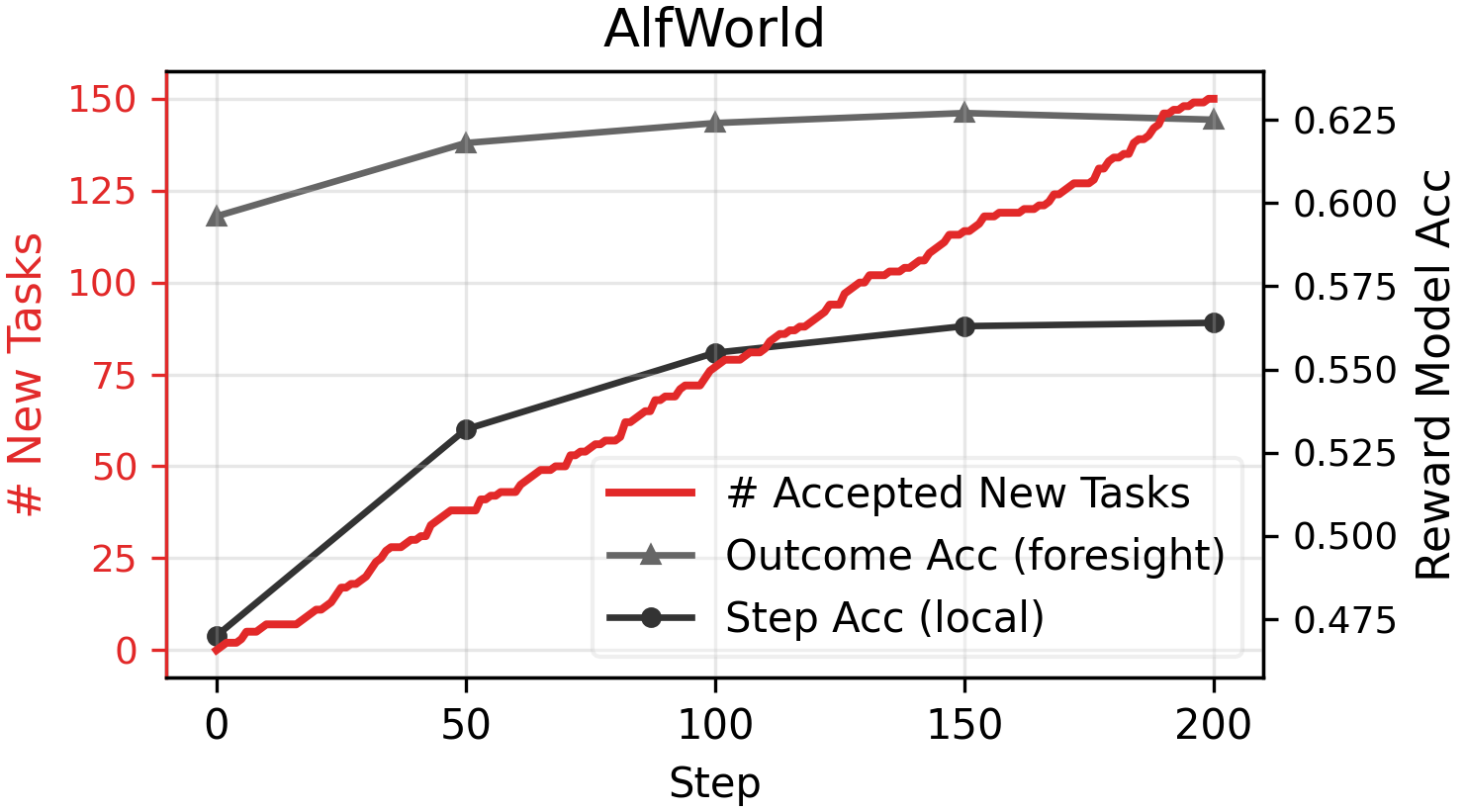
- Environment adaptation accepted new tasks at a roughly linear rate, hinting that you can scale up training data automatically.
- In coding, the system improved both the agent’s coding accuracy and the quality of generated unit tests (which act as a reward model that checks the code).
Why does this matter?
RLAnything shows a practical way to build smarter, more self-improving AI agents:
- It reduces the need for human-labeled outcomes by training strong reward models that can judge steps and predict final influence.
- It keeps training challenging but fair by automatically adjusting task difficulty using detailed “critic feedback.”
- It boosts generalization to new, unseen tasks (out-of-distribution), which is crucial for real-world deployment.
- It works across different domains—computer control, text games, and coding—suggesting broad usefulness.
In simple terms: instead of teaching only the player, RLAnything teaches the player, the referee, and the game levels—all at once. That teamwork makes the whole system learn faster, more reliably, and with less human effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed to guide concrete follow‑up research.
- Theoretical assumptions vs. practice: Theorems hinge on binary step labels, independence across reward-model evaluations, and asymptotics as , yet experiments use small (e.g., 3) and correlated LLM outputs; the finite‑ regime and correlated judges are not analyzed.
- Generalizing beyond binary step labels: The framework reduces step-wise signals to ; how to extend theory and practice to ordinal, continuous, or calibrated probabilistic scores remains open.
- Stability of triadic co-optimization: The closed-loop updates of policy, reward model, and environment introduce strong non-stationarity; convergence, oscillation, and stability properties (and mitigation strategies) are not characterized.
- Credit assignment with outcome mixing: Adding the final outcome to every step’s reward can mis-credit early correct steps in ultimately failing trajectories (and vice versa); no analysis or alternative credit schedules (e.g., decay by step index, delayed bootstrapping) are studied.
- Sensitivity to key hyperparameters: Only a narrow ablation on is provided; systematic sensitivity to m (number of RM votes), rollout count, step limits, acceptance thresholds (), and task sampling is missing.
- Reward-model calibration and reliability: No calibration or robustness diagnostics (e.g., Brier scores, ECE, adversarial inputs) are reported for the generative reward model; susceptibility to hallucinations or deceptive policy rationales is unaddressed.
- Circularity in reward-model evaluation: Step-wise “process accuracy” is measured by majority vote of a stronger LLM rather than human-labeled ground truth, risking model‑to‑model bias; a benchmark with human step‑level annotations is needed.
- Over-optimization to the reward model: Showing that RM-only supervision can outperform human-labeled outcomes raises Goodhart/MESA alignment concerns; there is no auditing for reward hacking, specification gaming, or unintended behaviors.
- Task adaptation quality and safety: LM-written task modifications are accepted mainly via policy accuracy bands; failure modes (logical inconsistencies, ambiguous goals, security risks) lack human vetting, formal checks, or automatic constraint enforcement.
- GUI environment scalability: Truly automatic generation of verifiers/evaluators is not solved; only 47/230 tasks had pre-created perturbed versions with new evaluators, limiting claims of end‑to‑end automatic environment evolution.
- Acceptance criterion reliability: Acceptance of new tasks based on accuracy from few rollouts may admit flawed tasks; confidence estimation, Bayesian criteria, or cross‑model validation are not explored.
- Distribution shift management: Frequent task rewriting creates non-stationary data; no off-policy corrections, replay strategies, or importance weighting are used for policy learning to mitigate drift.
- Generality across modalities and domains: Results are limited to GUI, text games, and single‑turn coding; applicability to robotics/continuous control, multi-agent settings, multilingual environments, and longer-horizon workflows is untested.
- Compute and cost trade-offs: The framework requires multiple rollouts, multiple RM evaluations per step, and LM-driven task rewrites; computation, energy, and latency budgets, and their trade-offs with performance, are not reported.
- OOD characterization: OOD splits (e.g., withheld OSWorld categories) may not reflect real-world distribution shifts; broader and stronger OOD and cross-benchmark generalization tests are absent.
- Robustness to reward-model bias: How biased or systematically wrong reward models affect policy and environment adaptation (error propagation, feedback loops) is not quantified; debiasing or ensembling is not studied.
- Finite-horizon vs. long-horizon scaling: While step limits are increased modestly, how integrated rewards and RM supervision scale to very long trajectories (hundreds/thousands of steps) is unexamined.
- Alternative integration of step-wise and outcome rewards: Only a simple linear combination is used; adaptive weighting, learned mixing, or return-to-go formulations are not compared.
- Task diversity vs. difficulty: Adaptation focuses on difficulty bands, not on systematically increasing diversity/coverage; mechanisms to avoid curriculum overfitting or narrow task distributions are not developed.
- Safety and ethics of synthesized tasks: Automatically generated tasks (coding and GUI) could introduce harmful content or system manipulations; safety policies, red-teaming, or filters are not described.
- Coding setting ground-truth circularity: “gt code” and “gt UT” definitions can be mutually dependent and dataset-limited; risk of admitting buggy tests or codes is real without human-verified or oracle baselines.
- Verifiability of unit tests: In coding, correctness of generated tests is assessed via model- and dataset-based criteria; absence of human audit or differential testing beyond provided suites leaves logical coverage and soundness uncertain.
- Baselines for environment adaptation: The framework is not compared against simpler curricula (e.g., random difficulty jitter, heuristic leveling) or alternative adaptation signals (e.g., uncertainty, learning progress).
- Transfer and reuse: Whether optimized reward models and adapted environments transfer across policy backbones or sizes (e.g., to smaller or different architectures) is not explored.
- Reproducibility details: Prompts and task adaptation rules are referenced but not fully specified for all settings; release of adapted tasks/verifiers and seeds for exact replication is unclear.
- Guardrails against policy–reward co-adaptation: No mechanisms (e.g., holdout evaluation tasks, frozen sentinel RMs, or adversarial RMs) are used to detect mutual overfitting between policy and reward model.
- Theoretical guarantees under environment adaptation: Theorems analyze reward precision but not the learning dynamics under actively changing task distributions; finite-sample bounds or regret analyses are absent.
- Effect of correlated RM votes: Multiple RM evaluations per step likely share model and prompt; how correlation degrades the theoretical gains from ensembling is not analyzed or measured.
- Failure analysis: Limited qualitative or quantitative analysis of where the system fails (e.g., types of tasks, error taxonomies) and how environment adaptation addresses (or fails to address) these cases.
Glossary
- Active learning from experience: An approach where the system adapts tasks based on observed errors and successes to improve learning efficiency and scale. "enabling active learning from experience and potential environment scaling."
- Advantage: A baseline-adjusted measure of a step’s reward used in policy gradient updates to reduce variance. "Finally, we compute advantages by standardizing rewards across trajectories at the same step index , i.e., over the set ."
- Agentic: Refers to settings involving autonomous agents that perform multi-step, interactive tasks. "We demonstrate effectiveness of RLAnything across diverse real-world applications, including computer control, coding, and text-based games." (context: “agentic tasks”)
- AlfWorld: A text-based interactive environment benchmark for evaluating LLM agents. "For the LLM agent on AlfWorld \citep{shridhar2020alfworld, cote2018textworld}, we use Qwen2.5-7B-Instruct as the policy model and Qwen2.5-14B-Instruct as the reward model"
- Chain-of-thought (CoT): The explicit reasoning sequence produced by an LLM before taking actions. "its chain-of-thought length increases rapidly"
- Closed-loop optimization: An optimization process where components (policy, reward, environment) iteratively provide feedback to each other. "reward models through closed-loop optimization"
- Consistency feedback: A training signal for the reward model that encourages agreement between step-level labels and aggregated quality signals. "the reward model is jointly optimized via consistency feedback"
- Critic feedback: Evaluative feedback used to adjust environment tasks, summarized from the reward model and policy performance. "Environment tasks leverage critic feedback from both the policy and the reward model to drive automatic, targeted adaptation"
- Evaluator scripts: Human-written programs that verify whether GUI tasks are successfully completed. "GUI evaluators are typically implemented as human-written evaluation scripts"
- Environment adaptation: Automatic modification of task difficulty or structure based on policy performance and reward-model diagnostics. "our theory-motivated automatic environment adaptation improves training for both the reward and policy models"
- Generative reward model: An LLM-based reward model that produces step-wise judgments via reasoning instead of simple scalar scores. "Step-wise signals are typically provided by generative reward models"
- GRPO: A reinforcement learning algorithm (Group Relative Policy Optimization) commonly used for LLM training. "outcome supervision (the standard GRPO \citep{deepseekmath} setting)"
- Importance-weight functions: Weighting functions applied to samples to correct for imbalanced sampling in expectations. "on the right-hand side, and are importance-weight functions of "
- L2 inner product: The inner product defined over square-integrable functions, used for theoretical analysis of objectives. "and denotes the inner product over ."
- L2 norm: The norm induced by the L2 space (square root of the integral of the square), used to measure function magnitude. " is constant irrelevant to , and is norm."
- LiveBench: A benchmark suite used to evaluate LLM capabilities, including coding tasks. "We use LiveCodeBench-V2 \citep{jain2024livecodebench}, CodeContests \citep{li2022alphacode}, and LiveBench \citep{white2024livebench} for evaluation"
- LiveCodeBench: A benchmark dataset focused on evaluating code generation and testing capabilities of LLMs. "We use LiveCodeBench-V2 \citep{jain2024livecodebench}, CodeContests \citep{li2022alphacode}, and LiveBench \citep{white2024livebench} for evaluation"
- OSWorld: A GUI-based benchmark environment for testing computer-use agents. "For GUI agents on OSWorld \citep{xie2024osworld}, we use Qwen3-VL-8B-Thinking as both the policy and reward model."
- Out-of-distribution (OOD): Data or tasks that differ from the training distribution, used to assess generalization. "“OOD” denotes accuracy on out-of-distribution tasks."
- Outcome accuracy: A metric for how well step-wise rewards predict final task outcomes. "“Outcome Acc” denotes the accuracy of predicting outcomes using step-wise rewards."
- Outcome reward: The verifiable signal associated with the final success or failure of a trajectory. "reinforcement learning benefits from integrating step-wise rewards with outcome rewards."
- Outcome supervision: Training based solely on final outcome labels rather than intermediate signals. "provides a stronger learning signal than outcome supervision (the standard GRPO \citep{deepseekmath} setting)."
- Pass-at-least-one rate: The fraction of tasks with at least one successful run among multiple trials. "obtaining pass-at-least-one rates of , , and , respectively."
- Process accuracy: The reward model’s accuracy in assessing correctness at the step level. "“Process Acc” denotes the accuracy of reward model in evaluating step-wise correctness"
- Process reward: A step-wise signal estimating the quality or progress at each step in a trajectory. "where is the mean process reward assigned by ."
- Reinforcement learning with verifiable rewards (RLVR): An RL paradigm where rewards are derived from automatically verifiable outcomes. "Reinforcement learning with verifiable rewards (RLVR) is an effective approach"
- Rollout: Executing a policy to generate trajectories for training or evaluation. "At each RL step, we sample 12 tasks, each with 8 independent rollout trajectories."
- Self-consistency: Agreement across multiple independent evaluations or reasoning samples, used to stabilize supervision. "based on outcome and self-consistency"
- Step-wise signals: Per-step feedback used to guide learning in long-horizon tasks. "Step-wise signals are typically provided by generative reward models"
- Trajectory-level outcome signal: The final reward or label associated with the entire trajectory, not individual steps. "which combines step-wise signals from reward model with the trajectory-level outcome signal."
- Unit test (UT): Automatically checkable tests used to evaluate code correctness in coding tasks. "“UT” denotes the accuracy of generated unit tests."
- Verifiable outcomes: Task outcomes that can be deterministically checked by scripts or rules. "The ground truth for outcome accuracy comes from verifiable outcomes"
- Verifier files: Files/scripts that implement verification logic for GUI tasks and objectives. "adapting to a different objective requires creating new verifier files."
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed with today’s tools (the paper links code and models), along with target sectors, likely workflows/tools, and key dependencies.
- Bold Application: Upgrading GUI/RPA agents with dynamic RL
- Sectors: software, enterprise IT, operations, productivity
- What: Fine-tune computer-use agents (e.g., Qwen3-VL-based) with integrated step-wise + outcome rewards and automatic task adaptation (OSWorld-like tasks). Expect higher success rates, better generalization to new apps/web UIs, and reduced manual reward engineering.
- Tools/workflows: Open-AgentRL (GitHub repo); Reward model prompting for step grading; EnvAdapter prompts to make tasks harder/easier; acceptance gating with αlow/αhigh; screen capture and action logging; evaluator scripts where available.
- Assumptions/dependencies: Access to frontier or suitable open LLMs (e.g., Qwen3-VL-8B); GUI instrumentation (screenshots, OCR, coordinates); evaluator/verifier scripts for some tasks or strong GRMs; compute budget; monitoring for reward hacking.
- Bold Application: Jointly training code generators and unit-test generators
- Sectors: software engineering, DevOps, QA
- What: Co-optimize coding LLMs with a unit-test generator as the reward model; use step-wise unit-test feedback to guide coding policy; integrate into CI to increase pass@k and defect detection.
- Tools/workflows: UT-as-reward model; sandboxed runners (e.g., Docker); pass/fail aggregation per step; integrated GRPO-style training; datasets like CodeContests and LiveCodeBench; CI hooks for nightly model updates.
- Assumptions/dependencies: Reliable deterministic test harnesses; flakiness control; security sandboxing; sufficient training data; compute for multi-sample evaluations.
- Bold Application: Cheaper supervision by replacing outcome scripts with optimized reward-model signals
- Sectors: software, automation, research labs
- What: Where outcome evaluators are expensive (e.g., GUI scripts), train policies using only optimized step-wise generative reward models (GRMs). The paper shows this can outperform outcome-only supervision.
- Tools/workflows: GRM prompting templates for per-step grading; consistency-feedback training for the GRM; quality dashboards to track process and outcome accuracy.
- Assumptions/dependencies: High GRM accuracy; bias/variance monitoring; human-in-the-loop review for critical tasks; guardrails to prevent reward model drift.
- Bold Application: Curriculum generation for multi-turn conversational or task agents
- Sectors: customer support, BPO, HR, sales enablement
- What: Use critic feedback to synthesize harder/easier conversation tasks, balancing difficulty to improve training and reduce sparse rewards in long dialogues.
- Tools/workflows: Conversation simulators or historical logs; GRM to grade step quality (e.g., grounding, policy adherence); environment adapter LLM to perturb scenarios; acceptance thresholds for curriculum gating.
- Assumptions/dependencies: Conversation quality heuristics and/or verifiable outcomes (e.g., resolution/CSAT proxies); privacy controls; domain-specific prompts.
- Bold Application: Adaptive practice problem generation in EdTech
- Sectors: education, training, upskilling
- What: Generate math/coding exercises that adapt to learner performance using critic feedback; provide step-wise guidance to learners and tune difficulty automatically.
- Tools/workflows: GRM for process evaluation of learners’ steps; task rewriter to vary constraints/hints; acceptance gating to maintain correctness; LMS integration.
- Assumptions/dependencies: Reliable correctness checks; content safety; pedagogy-aligned difficulty scaling.
- Bold Application: Automated QA and regression detection
- Sectors: DevOps, QA
- What: Use the reward-model unit-test generator to synthesize tests that detect failures in candidate code variants (including A/B releases), increasing coverage without manual test authoring.
- Tools/workflows: Test generator trained with consistency feedback; “detect” metrics as in the paper; CI/CD pipelines; triage dashboards for flaky tests.
- Assumptions/dependencies: Test determinism; code sandboxing; version pinning; governance for generated tests.
- Bold Application: Research pipelines for long-horizon RL with process rewards
- Sectors: academia, corporate research
- What: Immediate reproduction of joint policy–reward–environment optimization on OSWorld, AlfWorld, and coding benchmarks; ablation of λ and evaluation of reward precision μ goals.
- Tools/workflows: Open-AgentRL repo and HF models; plug-in new environments; reward prompts; difficulty thresholds; evaluation on in-domain/OOD splits.
- Assumptions/dependencies: Compute; environment compatibility; unified logging for step-level analytics.
- Bold Application: Web automation and data collection agents with robust exploration
- Sectors: data/AI platforms, growth engineering
- What: Train web agents (e.g., WebArena-style) with integrated rewards and dynamic task difficulties to stabilize learning in sparse-reward browsing tasks.
- Tools/workflows: DOM instrumentation; GRM prompts for step quality (clicks, form fills); environment adapter to mutate goals/hints; acceptance gating.
- Assumptions/dependencies: Stable page structures or resilient selectors; content policy compliance; captcha mitigation.
Long-Term Applications
The following require further research, scaling, or domain-specific development and oversight.
- Bold Application: Self-evolving enterprise agents for RPA/IT Ops
- Sectors: enterprise IT, operations, back-office
- What: Agents that continuously mine operational failures (critic feedback), generate new tasks, and improve policies and reward models in a closed loop to cover growing app landscapes.
- Tools/workflows: Continuous EnvAdapter service; failure mining; online RL; change management integration.
- Assumptions/dependencies: Strong safety/rollback; privacy; observability; budget for continual compute; guardrails against reward hacking.
- Bold Application: Robotics with co-optimized policy, reward, and environment
- Sectors: robotics, logistics, assistive tech
- What: Use multimodal GRMs to provide step-wise signal in manipulation/navigation; adapt sim tasks (curriculum) based on failures; translate to real via sim2real.
- Tools/workflows: Photorealistic simulators; vision-language reward models; automatic scenario scaling; domain randomization.
- Assumptions/dependencies: Accurate sensor models; sim2real gap; safety certifications; high data requirements.
- Bold Application: Clinical decision support and workflow optimization
- Sectors: healthcare
- What: Train CDS agents with step-wise GRMs that evaluate intermediate reasoning (guideline adherence) and outcomes; adapt case difficulty (comorbidities, missing data) by critic feedback.
- Tools/workflows: Retrospective EHR simulators; expert-in-the-loop evaluation; audit trails.
- Assumptions/dependencies: Regulated data access; robust validation; medical liability; strict oversight (not deployable without trials).
- Bold Application: Finance agents with process-aware risk controls
- Sectors: finance, trading, risk management
- What: Use GRMs to reward step-wise risk management and compliance; adapt environments by simulating regime changes and stress scenarios.
- Tools/workflows: High-fidelity market simulators; risk-aware reward components; compliance checks.
- Assumptions/dependencies: Model risk controls; backtest–live gap; regulatory approval; adversarial market conditions.
- Bold Application: Scientific lab automation and experiment planning
- Sectors: R&D, biotech, materials science
- What: Reward models grade step-wise plausibility and safety; environment adaptation proposes new experimental conditions informed by failures; closed-loop hypothesis testing.
- Tools/workflows: Lab simulators or robotic labs; data management; provenance tracking.
- Assumptions/dependencies: Reliable simulators; costly wet-lab iterations; safety constraints.
- Bold Application: AI safety red-teaming and adversarial curriculum generation
- Sectors: AI governance, policy, safety teams
- What: Use consistency-trained reward models as critics to identify risky steps, then auto-generate harder adversarial tasks; apply acceptance gating to curate evaluation suites.
- Tools/workflows: Red-team task generator; risk taxonomies; scorecards for process/outcome accuracy.
- Assumptions/dependencies: Evolving policy standards; expert oversight; avoiding overfitting to evaluator artifacts.
- Bold Application: Open-ended learning platforms and generalist agents
- Sectors: AI platforms, foundation models
- What: Scale accepted tasks linearly to continuously broaden capabilities across domains, using dynamic balancing of difficulty to maintain informative gradients.
- Tools/workflows: Large-scale task markets; automated acceptance; multi-domain reward models.
- Assumptions/dependencies: Significant compute; cross-domain safety; catastrophic forgetting mitigation.
- Bold Application: Personalized digital companions that learn from user behavior
- Sectors: consumer software, accessibility
- What: Personal agents adapt tasks and evaluate intermediate steps to learn user-specific workflows (email triage, file management), improving with daily use.
- Tools/workflows: On-device or privacy-preserving learning; UI instrumentation; user-in-the-loop correction.
- Assumptions/dependencies: Privacy and consent frameworks; device resources; robust rollback.
- Bold Application: Industrial control and energy systems with fault-adaptive training
- Sectors: energy, manufacturing
- What: Train controllers with GRMs that assess step-wise stability/safety; adapt environments with fault injection and scenario perturbations for better robustness.
- Tools/workflows: Digital twins; safety envelopes; human-in-the-loop evaluation.
- Assumptions/dependencies: High-fidelity models; safety-critical certification; strict guardrails.
- Bold Application: Secure coding assistants with auto-generated exploit tests
- Sectors: cybersecurity, software
- What: Extend unit-test generators to produce adversarial security tests; train code policies to pass these tests and reduce vulnerabilities.
- Tools/workflows: Vulnerability corpora; SAST/DAST integration; secure sandboxes.
- Assumptions/dependencies: Coverage gaps for zero-days; test flakiness; governance of generated exploits.
Notes on Feasibility, Assumptions, and Dependencies
- Model access and compute: Many applications assume access to capable multimodal/text LLMs (e.g., Qwen families) and sufficient compute for multi-sample GRM evaluations.
- Environment instrumentation: Step-wise signals require logging fine-grained state transitions (screenshots/DOM, action traces, unit-test outcomes).
- Evaluators and acceptance gating: When outcome evaluators are absent, GRMs must be validated and monitored; acceptance thresholds (αlow/αhigh) need tuning per domain.
- Safety and governance: Automated task generation can drift; adopt guardrails, audits, and human-in-the-loop reviews in regulated or high-risk domains.
- Reliability of GRMs: Bias, reward hacking, and non-stationarity are risks; use consistency feedback, OOD checks, and evaluation on strong supervisor models.
- Data/privacy: For enterprise and consumer uses, ensure data minimization, consent, and secure storage; prefer on-device or federated approaches where feasible.
- Generalization: Gains on OSWorld/AlfWorld/coding suggest transferability, but domain adaptation (prompts, interfaces) is required for new sectors.
Collections
Sign up for free to add this paper to one or more collections.