Flash-KMeans: Fast and Memory-Efficient Exact K-Means
Abstract: $k$-means has historically been positioned primarily as an offline processing primitive, typically used for dataset organization or embedding preprocessing rather than as a first-class component in online systems. In this work, we revisit this classical algorithm under the lens of modern AI system design and enable $k$-means as an online primitive. We point out that existing GPU implementations of $k$-means remain fundamentally bottlenecked by low-level system constraints rather than theoretical algorithmic complexity. Specifically, the assignment stage suffers from a severe IO bottleneck due to the massive explicit materialization of the $N \times K$ distance matrix in High Bandwidth Memory (HBM). Simultaneously, the centroid update stage is heavily penalized by hardware-level atomic write contention caused by irregular, scatter-style token aggregations. To bridge this performance gap, we propose flash-kmeans, an IO-aware and contention-free $k$-means implementation for modern GPU workloads. Flash-kmeans introduces two core kernel-level innovations: (1) FlashAssign, which fuses distance computation with an online argmin to completely bypass intermediate memory materialization; (2) sort-inverse update, which explicitly constructs an inverse mapping to transform high-contention atomic scatters into high-bandwidth, segment-level localized reductions. Furthermore, we integrate algorithm-system co-designs, including chunked-stream overlap and cache-aware compile heuristics, to ensure practical deployability. Extensive evaluations on NVIDIA H200 GPUs demonstrate that flash-kmeans achieves up to 17.9$\times$ end-to-end speedup over best baselines, while outperforming industry-standard libraries like cuML and FAISS by 33$\times$ and over 200$\times$, respectively.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making a classic computer method called K‑Means clustering run much faster and use less memory on modern graphics cards (GPUs). K‑Means is a way to group similar things together—like sorting photos by who’s in them or grouping words by meaning. The authors redesign how K‑Means runs on GPUs so it works quickly enough to be used “online” (during live model training or inference), not just as a slow, offline step.
What questions are the authors trying to answer?
The authors focus on three simple questions:
- How can we stop K‑Means from wasting time writing and reading a giant table of numbers (distances) that we only need briefly?
- How can we avoid lots of different GPU threads fighting to write to the same place in memory when updating cluster centers?
- How can we make K‑Means practical for real systems where the data is huge (doesn’t fit in GPU memory) and the problem size changes all the time?
How did they do it? (Methods explained with analogies)
The authors keep the math of K‑Means exactly the same (no approximations). They change how the work is done inside the GPU to avoid memory traffic jams and writing conflicts.
Here’s what they changed:
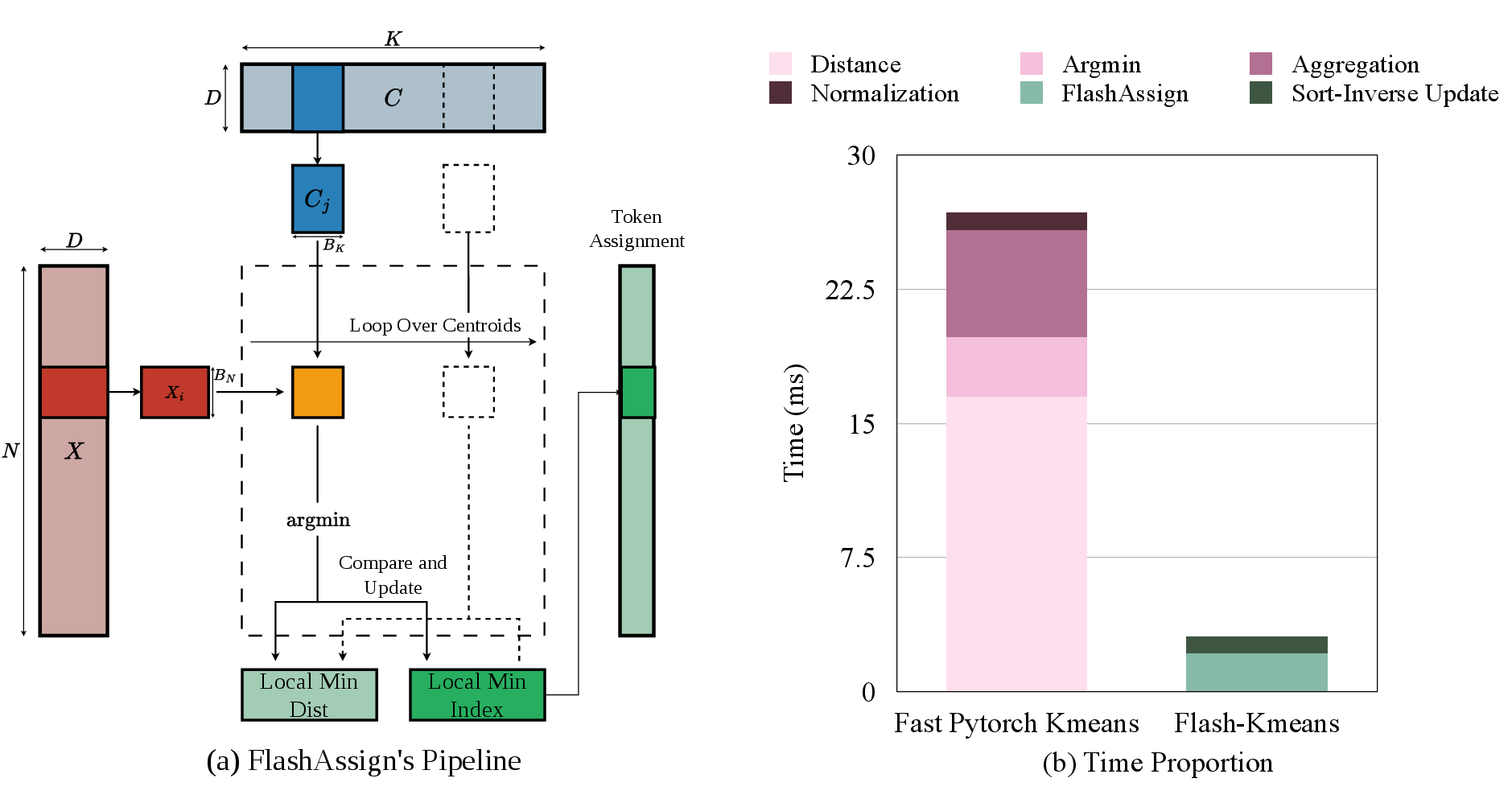
FlashAssign: Find the nearest cluster without writing a giant table
- Usual way: For N data points and K clusters, the computer makes an N×K “distance table” that says how far each point is from each cluster. This is like writing a huge score sheet, then looking for the smallest score in each row.
- Problem: Writing and reading this huge table is slow and memory-heavy on a GPU.
- FlashAssign idea: Don’t write the table at all. Instead, as you go through the clusters for a point, keep only the “best so far” (the smallest distance and its cluster). It’s like checking shops one by one and remembering the cheapest price you’ve seen, without writing down every price.
- Extra trick: Split points and clusters into small tiles (chunks) and “prefetch” the next tile while computing on the current one, so the GPU is always busy.
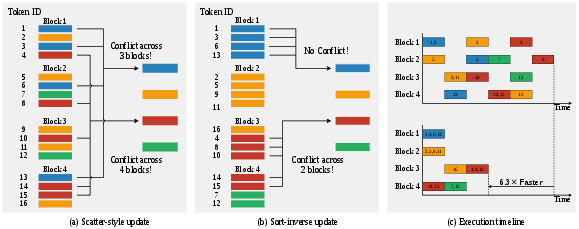
Sort-Inverse Update: Update clusters without everyone writing at once
- Usual way: After assigning points to clusters, each point tries to add itself to its cluster’s total—thousands of threads updating the same few cluster “buckets” at the same time. That’s like hundreds of people trying to share a few pens to fill out the same forms—slow and full of waiting.
- Problem: These “atomic” updates cause heavy contention (everyone queues up to write).
- Sort-Inverse idea: First sort the assignment list by cluster ID (like sorting mail by the destination address). Now all points for the same cluster are next to each other. Then, for each cluster segment, add up points locally (on fast on-chip memory) and write the result once. It turns “many tiny updates” into “few big updates,” which GPUs handle much faster.
System co-design: Make it work on real, large, and changing workloads
- Chunked stream overlap: If your data doesn’t fit in GPU memory, process it in chunks and overlap copying the next chunk from the CPU with computing the current chunk—like bringing the next tray into the kitchen while you’re still cooking the current one.
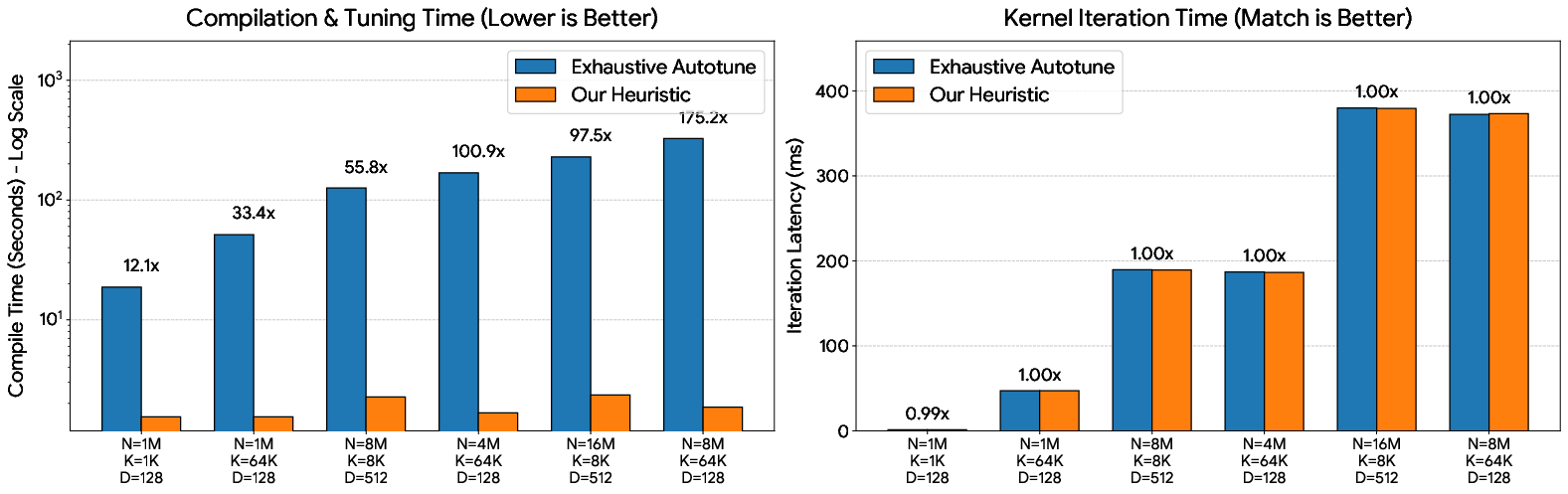
- Cache‑aware compile heuristic: Instead of spending minutes auto‑tuning every time the data size changes, pick good kernel settings quickly using the GPU’s cache sizes and the problem shape—like choosing the right pan size from a simple guide instead of trial‑and‑error every time.
What did they find, and why is it important?
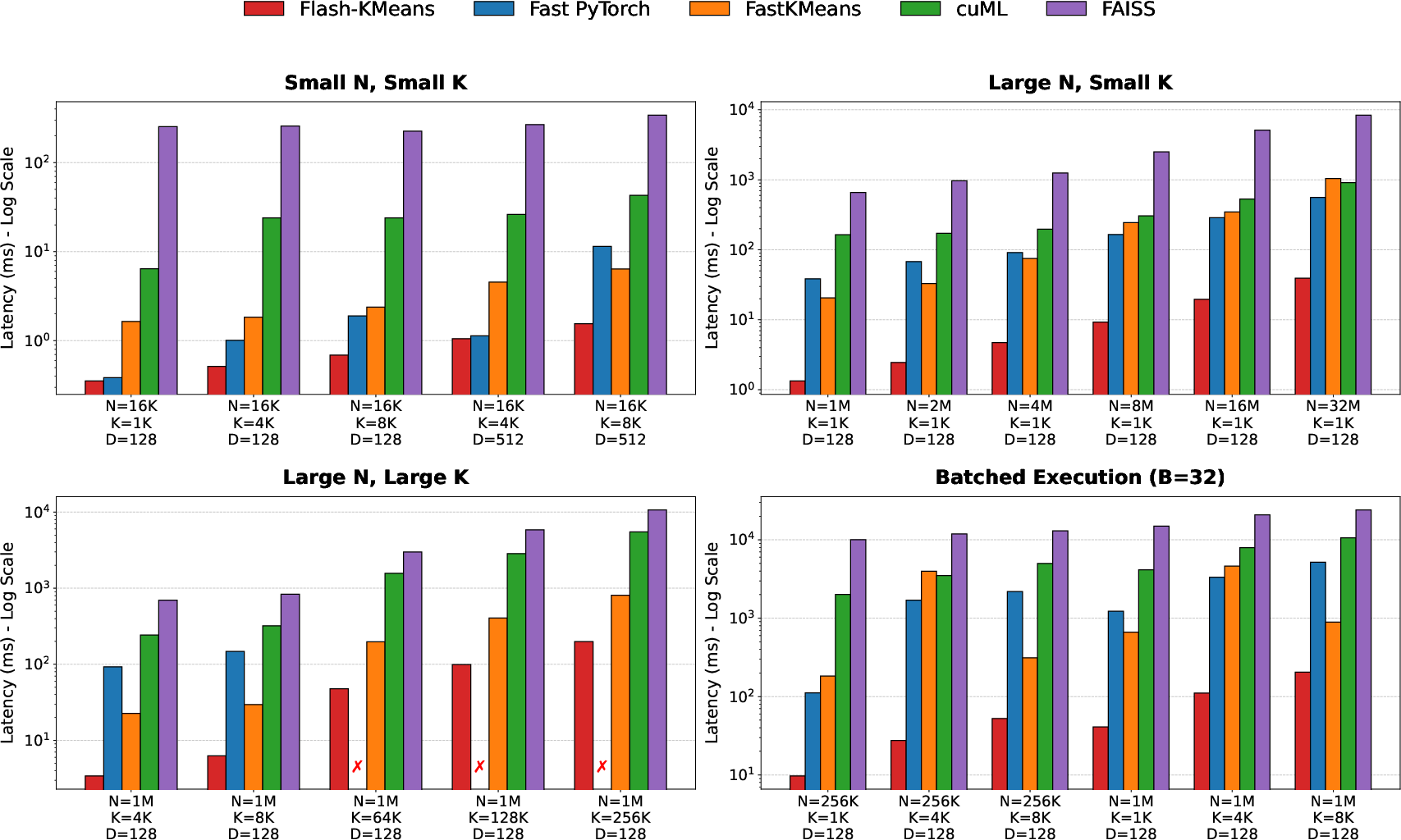
The authors tested their approach on NVIDIA H200 GPUs and found big speedups:
- End-to-end speed: Up to 17.9× faster than the best competing baseline they tested. Compared to common libraries, up to 33× faster than NVIDIA cuML and over 200× faster than FAISS in some settings.
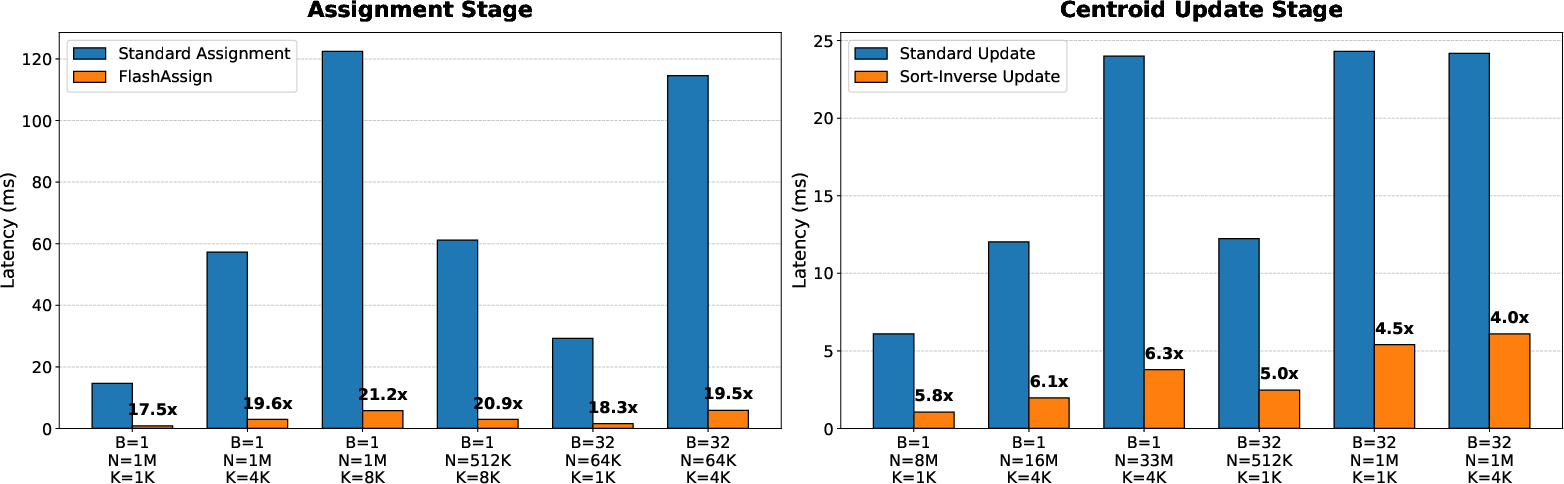
- Kernel (inner loop) speedups:
- FlashAssign (assignment step): up to 21.2× faster by not writing the giant distance table.
- Sort‑Inverse Update (centroid update): up to 6.3× faster by reducing write conflicts.
- Huge datasets: Works out-of-core (data bigger than GPU memory), scaling to one billion points, with up to a 10.5× speedup by overlapping data transfers with computation.
- Fast startup: Their compile heuristic cuts tuning time by up to 175× with about 0.3% or less performance loss compared to exhaustive tuning.
Why this matters: Many modern AI systems secretly rely on K‑Means inside (for things like compressing model memory, routing tokens in big LLMs, organizing embeddings, and deduplicating data). Making K‑Means both fast and memory‑efficient means these systems can run faster and handle larger jobs without changing the math or the final clustering result.
What does this mean for the future?
Because Flash‑KMeans is mathematically exact and redesigned around how GPUs really work, it can serve as a dependable, high‑speed building block inside AI training and inference. That means:
- Lower latency for models that use clustering during inference (e.g., routing or compression in LLMs).
- Better throughput for huge datasets without needing massive GPU memory.
- Easier deployment in dynamic pipelines (changing batch sizes, number of clusters, or dimensions) without long tuning delays.
In short, the paper shows that by respecting the GPU’s memory and data movement limits—and reorganizing work to fit them—you can make a classic algorithm like K‑Means fast enough to be a first‑class part of modern AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- Hardware generality: Results are only reported on NVIDIA H200 (CUDA 12.8). It is unclear how performance and heuristics transfer to A100/H100, consumer GPUs, AMD GPUs/ROCm, or different memory hierarchies and interconnects (NVLink vs PCIe vs CXL).
- Multi-GPU and distributed scaling: The design and evaluation are single-GPU. How to partition centroids/points, construct a global inverse mapping, and perform low-contention updates across GPUs (e.g., NCCL all-reduce) is not addressed.
- Arg-sort scalability and algorithm choice: The update stage relies on argsort over N assignments each iteration. The paper does not quantify the sort’s absolute cost, algorithmic choice (e.g., radix vs comparison sort), memory footprint, or asymptotic behavior for very large N (up to 1e9) and many Lloyd iterations.
- External/streaming sort for out-of-core: For out-of-core runs, how to perform argsort when assignments do not fit in HBM (or even GPU memory) is not specified. The design and cost of external or chunked/global sort and its impact on correctness and performance remain open.
- Memory footprint of indices: For N up to 1e9, storing
aandsorted_idxcan consume multiple GB. The paper does not state index bitwidths, memory layouts, or compression schemes to bound peak memory, especially when centroids and feature data coexist. - Load balance after sorting: Sorting by cluster ID can create extremely long segments for “hot” clusters, risking CTA load imbalance and latency spikes. Work partitioning or segment splitting strategies to avoid stragglers are not explored.
- Worst-case atomic behavior: Although atomics are reduced to segment boundaries, the worst case (e.g., many segments split across chunks/CTAs) and the resulting contention are not characterized analytically or empirically.
- Numerical determinism and “exactness”: Floating-point reductions can be non-associative; different reduction orders (due to sorting/tiling) may alter centroid updates. The paper claims exactness but does not analyze determinism across runs/hardware or bound numeric drift in objective values.
- Precision modes and Tensor Core usage: It is unclear what precisions are used for distances and updates (FP32/BF16/FP16) and how mixed precision affects correctness, convergence, and speed. Guidance on safely exploiting Tensor Cores without degrading clustering quality is missing.
- Empty clusters and stability: Handling of (empty clusters), re-seeding strategies, and their impact on performance and determinism are not discussed.
- Initialization strategies: Integration with k-means++ or GPU-friendly seeding, and their costs relative to the accelerated iteration loop, are not evaluated.
- Convergence behavior over iterations: The paper focuses on per-iteration speed. The number of iterations to convergence, objective descent curves, and any effect of numerical strategies on convergence are not reported.
- Alternative distance metrics: The method is specialized to squared Euclidean distance. Support and performance for cosine, L1, Mahalanobis, or learned metrics—and how FlashAssign and sort-inverse update adapt—are unaddressed.
- Compatibility with pruning/bounding accelerations: How to fuse IO-aware kernels with algorithmic accelerations (e.g., Elkan/Yinyang bounds, triangle inequality pruning) without reintroducing memory bottlenecks is an open design question.
- Extreme shapes and high dimensionality: Most kernel studies use moderate D (e.g., 128/512). Scaling to very high dimensions (e.g., D ≫ 1k) and its effects on register pressure, tiling, and occupancy are not evaluated.
- Heuristic generality and robustness: The cache-aware compile heuristic is validated on a limited set of shapes/hardware. Formal guarantees or broader stress-testing against a wider shape distribution and other GPUs are not provided.
- Tail latency and jitter: For online invocation, tail percentiles (P95/P99) under multi-tenant contention, dynamic shape changes, and concurrent operators are not reported.
- Energy efficiency and cost: Power draw, energy per iteration, and performance-per-watt comparisons versus baselines are unmeasured.
- Real workload integration: Claims of benefits to LLMs/retrieval/video pipelines are not validated end-to-end. Downstream metrics (e.g., serving throughput, latency, memory footprint) and integration overheads (data layout, preprocessing) are unknown.
- Interconnect dependence: Chunked stream overlap is shown for PCIe; scaling on NVLink/NVSwitch/CXL and sensitivity to host memory bandwidth and pinned-memory constraints are not characterized.
- I/O pipeline completeness: Overlapping with disk/network input (beyond host-to-device) and the effect of storage bandwidth/latency on end-to-end throughput remain unexplored.
- API and framework portability: The extent of integration with PyTorch/JAX/Triton, autograd/torch.compile compatibility, and ease of adoption in production stacks is unclear.
- Robustness to distribution skew and nonstationarity: Performance and stability on highly imbalanced or evolving cluster distributions (common in online systems) are not systematically analyzed.
- Small-batch/microbatch regimes: For tiny N/K, kernel launch and sorting overheads may dominate. Automatic fallback strategies to simpler kernels and crossover thresholds are not provided.
- Very large K regimes: Memory and throughput implications when K is extremely large (e.g., ≥ 106) are not discussed, including centroid tiling limits and centroid-update storage pressure.
- Fault tolerance and resilience: Behavior under GPU preemption, kernel failures, or partial chunk failures in out-of-core execution, and mechanisms for checkpointing/restart, are not addressed.
- Security/memory safety: No discussion of bounds checking or robustness to adversarial or malformed inputs (e.g., NaNs/Infs), which can appear in pipeline integrations.
These gaps suggest concrete avenues: multi-GPU designs, external-memory sorting, mixed-precision and determinism studies, integration with pruning algorithms and real applications, comprehensive hardware/energy/tail-latency evaluations, and enhanced robustness and portability tooling.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can leverage Flash-KMeans today, given that it is an exact Lloyd’s K-Means with an open-source implementation and validated on modern NVIDIA GPUs.
- GPU-accelerated embedding de-duplication and dataset curation
- What: Speed up large-scale semantic de-duplication (e.g., SemDeDup-style pipelines) and clustering-based dataset filtering for training corpora and retrieval corpora.
- Potential tools/products/workflows:
- Drop-in replacement for K-Means stages in existing PyTorch/cuML/FAISS-based data curation jobs.
- Nightly/weekly data-cleaning jobs in data lakes (Spark + GPU executors with Flash-KMeans kernels).
- Assumptions/dependencies:
- Access to modern NVIDIA GPUs (H100/H200-class) and CUDA 12+.
- Euclidean metric assumed; embeddings typically normalized or compatible with L2.
- Integration work if currently tied to CPU-only K-Means or FAISS internals.
- Faster IVF/PQ codebook and coarse-quantizer training for vector databases and search engines
- What: Accelerate index building (e.g., IVF coarse quantizer, PQ codebook training) and periodic re-clustering of embeddings for retrieval systems.
- Potential tools/products/workflows:
- Vector DBs (Milvus, Weaviate, Pinecone) adopt Flash-KMeans for index build/update.
- Search/recommendation platforms shorten index refresh windows from hours to minutes.
- Assumptions/dependencies:
- Requires integration as a training backend; inference/search pipelines remain unchanged.
- GPU availability for index build stages; data transfer pipelines tuned for out-of-core streaming.
- Online LLM operators: sparse routing and KV-cache compression
- What: Use K-Means during inference/training for token routing (sparse attention, MoE-like behaviors) and semantic KV-cache clustering/merging to reduce memory and latency.
- Potential tools/products/workflows:
- Plugins for vLLM/TensorRT-LLM/serving stacks that invoke Flash-KMeans inside forward passes.
- RAG systems with online embedding clustering for dynamic context selection.
- Assumptions/dependencies:
- Latency-sensitive deployments need GPU-resident invocation and minimal H2D/D2H transfers.
- Exact L2 K-Means fits the intended routing/compression logic; adaptation needed for cosine-only pipelines.
- High-throughput recommendation system candidate generation and segmentation
- What: Re-cluster user/item embeddings at higher frequency for cohorting, candidate pools, and A/B experiments.
- Potential tools/products/workflows:
- GPU-accelerated offline jobs or micro-batches that update cohorts multiple times per day.
- MLOps pipelines with automated re-indexing using Flash-KMeans kernels.
- Assumptions/dependencies:
- Stable GPU scheduling in production; data pipelines supply pinned memory and overlap I/O.
- Clusters used for downstream ranking must be validated for business metrics.
- Video and vision model pipelines (token permutation and quantization)
- What: Repeated K-Means calls inside Diffusion Transformers or ViT pipelines for semantic-aware token permutation and low-bit KV-cache quantization during training/inference.
- Potential tools/products/workflows:
- Training scripts swap baseline K-Means kernels for Flash-KMeans to reduce wall-clock time.
- Inference graphs with on-the-fly token clustering to cut memory use.
- Assumptions/dependencies:
- Model graphs must support CUDA streams and kernel fusion without disrupting scheduling.
- GPU memory must be managed to exploit chunked stream overlap for large batches.
- Massive-scale analytics and ETL (out-of-core, billion-point clustering)
- What: Run K-Means on datasets far exceeding VRAM via chunked stream overlap and pipeline parallelism.
- Potential tools/products/workflows:
- GPU-accelerated Spark/Flink stages that hand off partitions to Flash-KMeans for clustering.
- “K-Means-at-scale” internal platform jobs for customer segmentation or geospatial tiling.
- Assumptions/dependencies:
- High-throughput PCIe/NVLink and pinned-memory buffers to hide transfer latency.
- Sufficient host memory and storage bandwidth to feed the GPU.
- Healthcare and scientific cohorting at interactive speeds
- What: Cluster patient or molecular embeddings to support cohort discovery, trial recruitment, or phenotype subtyping with faster turnaround.
- Potential tools/products/workflows:
- Hospital research clusters accelerate periodic cohort updates.
- Bioinformatics workflows (e.g., omics embeddings clustering) shorten exploratory loops.
- Assumptions/dependencies:
- Regulatory approval and data governance remain unchanged; exactness helps reproducibility.
- GPU clusters in secure environments; pipelines export embeddings suitable for L2 clustering.
- Faster experimentation/teaching in academia and industry R&D
- What: Reduce time-to-first-run and per-iteration latency for K-Means-heavy experiments.
- Potential tools/products/workflows:
- Course labs and research notebooks use the cache-aware compile heuristic to avoid long auto-tuning.
- Benchmark suites comparing algorithms at billion-scale.
- Assumptions/dependencies:
- Access to compatible GPUs; minimal code changes if using PyTorch-based kernels.
Long-Term Applications
These opportunities require additional engineering, broader hardware support, or further research before widespread deployment.
- Extensions to other clustering and distance metrics
- What: Apply IO-aware streaming and sort-inverse reductions to k-medoids, GMM/EM, spectral clustering, or to non-Euclidean metrics (cosine, Mahalanobis).
- Potential tools/products/workflows:
- A general “Flash-Clustering” suite with pluggable metrics and algorithms.
- Assumptions/dependencies:
- Kernel redesigns for metric-specific math and stability; careful tiling for new compute patterns.
- Validation on diverse GPUs and larger multi-GPU setups.
- Integration as managed cloud services and vector DB primitives
- What: “Flash-KMeans as a Service” and first-class index-build operators in vector DBs.
- Potential tools/products/workflows:
- Cloud APIs for clustering/index building with SLAs; autoscaling GPU backends.
- Assumptions/dependencies:
- Multi-tenant scheduling, billing, and isolation; standardized APIs for index build/update.
- Database engines and GPU SQL: generalizing sort-inverse to group-by/aggregate
- What: Adopt the sort-then-segment pattern to reduce atomic contention in GPU group-by and reduce/merge operators at scale.
- Potential tools/products/workflows:
- GPU-accelerated OLAP engines integrating contention-free segmented reductions.
- Assumptions/dependencies:
- Query planner support for reordering and cost models; robustness to data skew.
- Edge and robotics real-time clustering
- What: Real-time clustering of point clouds/features for SLAM, scene segmentation, or on-robot perception.
- Potential tools/products/workflows:
- Jetson-class deployments with adapted kernels and reduced-memory tiling.
- Assumptions/dependencies:
- Porting from HBM-centric design to embedded GPUs with lower bandwidth; real-time schedulability guarantees.
- Energy- and cost-aware data center optimization
- What: Lower compute-hours and energy per clustering job; enable greener pipelines for index builds and data curation.
- Potential tools/products/workflows:
- Scheduler policies that route K-Means jobs to Flash-KMeans-enabled GPU pools to minimize energy/cost.
- Assumptions/dependencies:
- Telemetry to quantify energy savings; organizational incentives for carbon-aware scheduling.
- Privacy and policy-aligned data governance via rapid de-duplication
- What: Faster removal of redundant or near-duplicate records to reduce inadvertent exposure and simplify audit trails.
- Potential tools/products/workflows:
- “Governance pipelines” that run frequent clustering-based audits across data estates.
- Assumptions/dependencies:
- Strong linkage with hashing/embedding pipelines; clear governance frameworks; secure GPU access.
- Interactive billion-scale analytics and BI
- What: Near-real-time embedding clustering for exploratory segmentation and drill-down in dashboards.
- Potential tools/products/workflows:
- GPU-backed BI tools exposing clustering as an interactive widget on massive datasets.
- Assumptions/dependencies:
- Tight integration with columnar stores/vector stores; latency budgets under interactive thresholds.
- Cross-vendor and multi-accelerator portability
- What: Ports to AMD ROCm, Intel GPUs, and future accelerators with equivalent IO-aware kernels.
- Potential tools/products/workflows:
- Vendor-neutral “flash” primitives library used across accelerators.
- Assumptions/dependencies:
- Re-implementation of low-level tiling, async copy, and reduction strategies on new runtimes; performance re-validation.
Glossary
- argmin: The operation that returns the index of the minimum value of a function or array. "Compute "
- argsort: An operation that returns the indices that would sort an array. "We first apply an argsort operation to the assignment vector "
- asynchronous prefetch: Fetching data into faster memory ahead of use in parallel with computation to hide latency. "double buffer and asynchronous prefetch"
- bandwidth-limited: Performance constrained primarily by memory bandwidth rather than computation. "fundamentally bandwidth-limited by the HBM round trips"
- cache-aware compile heuristic: A strategy that chooses kernel configurations based on hardware cache characteristics to avoid expensive auto-tuning. "a cache-aware compile heuristic to reliably match near-optimal configurations"
- chunked stream overlap: Overlapping data transfers and computation across chunks to hide communication latency. "including chunked stream overlap and cache-aware compile heuristic"
- Cooperative Thread Array (CTA): A CUDA execution unit (thread block) that cooperates via shared resources like shared memory and synchronization. "Each Cooperative Thread Array (CTA) processes a contiguous block of tokens"
- CUDA streams: CUDA constructs that enable concurrent kernel execution and asynchronous memory transfers. "use CUDA streams to coordinate asynchronous host-to-device transfers"
- double buffer: Using two buffers so one is filled while the other is processed, enabling overlap of IO and compute. "implement double buffer and asynchronous prefetch"
- FLOPs: Floating point operations; a measure of arithmetic work. "Although these algorithmic improvements successfully reduce theoretical FLOPs,"
- gather: A memory access pattern that reads elements from non-contiguous locations into a contiguous buffer. "uses sorted_idx to gather the corresponding token features from the original matrix."
- High Bandwidth Memory (HBM): A high-throughput memory technology attached to GPUs, offering much greater bandwidth than traditional DRAM. "explicit materialization of the distance matrix in High Bandwidth Memory (HBM)."
- inverse mapping: A mapping from targets back to sources (e.g., from clusters to tokens) enabling reorganized dataflow. "explicitly constructs an inverse mapping"
- IO-aware: Designed to reduce input/output and memory traffic as a first-class optimization objective. "Inspired by IO-aware attention mechanisms"
- IO-bound: A workload whose performance is dominated by input/output (memory or data movement) rather than computation. "IO-bound assignment in assignment stage:"
- Lloyd's iteration: The classic two-step k-means iteration consisting of assignment and update phases. "A standard Lloyd's iteration consists of two distinct stages:"
- materialization: Explicitly constructing and storing an intermediate data structure in memory. "explicit materialization of the distance matrix ."
- memory wall: The growing disparity between processor speed and memory bandwidth/latency that limits performance. "limited by two low-level bottlenecks: the memory wall in the assignment stage"
- on-chip memory: Fast memory resources located on the GPU chip (e.g., registers and shared memory). "fast on-chip memory (registers or shared memory)"
- online argmin: Incrementally updating the current minimum and its index as new data tiles are processed, avoiding full materialization. "FlashAssign relies on an online argmin update."
- out-of-core execution: Processing data that do not fully fit in device memory by streaming chunks in and out. "seamless out-of-core execution on up to one billion points"
- PCIe: The peripheral interconnect used between host and GPU; often a communication bottleneck. "overlapping PCIe communication with computation."
- registers: The fastest storage on the GPU, private to each thread. "we maintain two running states in registers: the current minimum distance and the corresponding centroid index ."
- scatter-style updates: Writing to memory locations determined by data indices (e.g., cluster IDs), often causing contention. "Standard implementations typically perform scatter-style updates,"
- segment-level localized reductions: Reductions performed over contiguous segments of sorted data to maximize locality and throughput. "segment-level localized reductions."
- shared memory: Fast on-chip memory shared by threads within a CTA for cooperation and reduced global memory traffic. "fast on-chip memory (registers or shared memory)"
- sort-inverse update: An update strategy that sorts assignments and uses the inverse mapping to turn scattered atomics into localized reductions. "sort-inverse update, which explicitly constructs an inverse mapping"
- SRAM: Fast on-chip static RAM used in GPU memory hierarchies (e.g., shared memory/L1). "FlashAssign streams data blocks from HBM to SRAM,"
- Tensor Cores: Specialized GPU units optimized for high-throughput matrix multiply-accumulate operations. "matrix multiplications via Tensor Cores"
- tiling: Partitioning data into tiles to improve cache reuse and reduce memory traffic. "two-dimensional tiling over both the points and the centroids."
- time-to-first-run: The latency before the first execution, including compilation and tuning overheads. "drastically increasing the time-to-first-run"
- VRAM: Video RAM; the GPU’s on-device memory used to store models and data during execution. "exceed the GPU's VRAM capacity."
- write-path serialization: Performance loss due to writes being serialized (e.g., by contended atomics), limiting throughput. "kernel-level dataflow and write-path serialization."
Collections
Sign up for free to add this paper to one or more collections.

