Collective Communication for 100k+ GPUs (2510.20171v1)
Abstract: The increasing scale of LLMs necessitates highly efficient collective communication frameworks, particularly as training workloads extend to hundreds of thousands of GPUs. Traditional communication methods face significant throughput and latency limitations at this scale, hindering both the development and deployment of state-of-the-art models. This paper presents the NCCLX collective communication framework, developed at Meta, engineered to optimize performance across the full LLM lifecycle, from the synchronous demands of large-scale training to the low-latency requirements of inference. The framework is designed to support complex workloads on clusters exceeding 100,000 GPUs, ensuring reliable, high-throughput, and low-latency data exchange. Empirical evaluation on the Llama4 model demonstrates substantial improvements in communication efficiency. This research contributes a robust solution for enabling the next generation of LLMs to operate at unprecedented scales.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper explains how Meta built a new communication system, called NCCLX, to help huge numbers of GPUs “talk” to each other quickly and reliably when training and running very large AI models like Llama 4. Think of thousands of powerful computers (GPUs) working together; they constantly need to share pieces of data. If that sharing is slow or clumsy, the whole job slows down. NCCLX is designed to keep data moving fast across more than 100,000 GPUs, both during training (which needs high throughput and reliability) and during inference (which needs very low delay).
What the researchers wanted to figure out
In simple terms, they asked:
- How can we make communication between 100k+ GPUs fast, reliable, and easy to customize for different AI model needs?
- How do we reduce delays and avoid network “traffic jams” when messages travel long distances across buildings and data centers?
- Can we keep communication fast without wasting GPU computing power or memory?
- Can one system work well for both training (big, steady data flows) and inference (many small, quick messages)?
How they did it
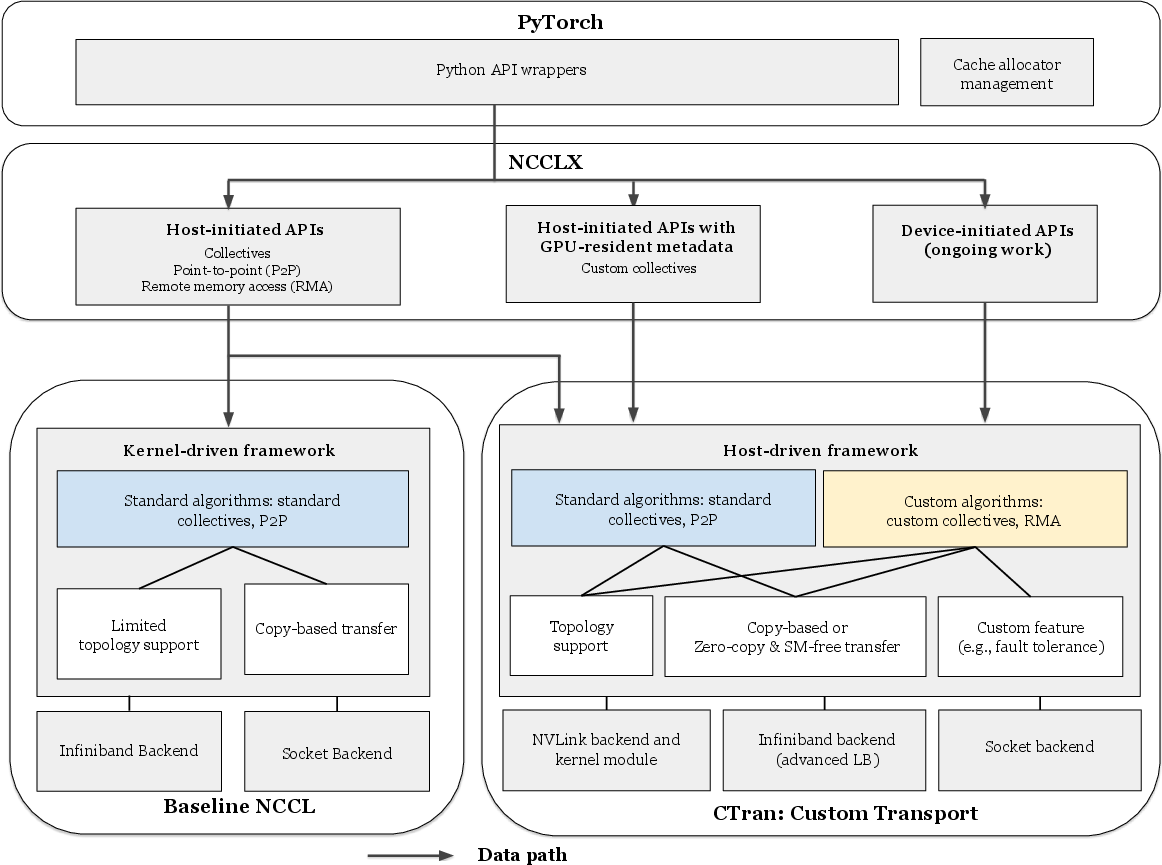
They built NCCLX on top of an existing library called NCCL (a common tool for GPU communication), then added a new transport engine called CTran. Here are the key ideas, explained with everyday analogies:
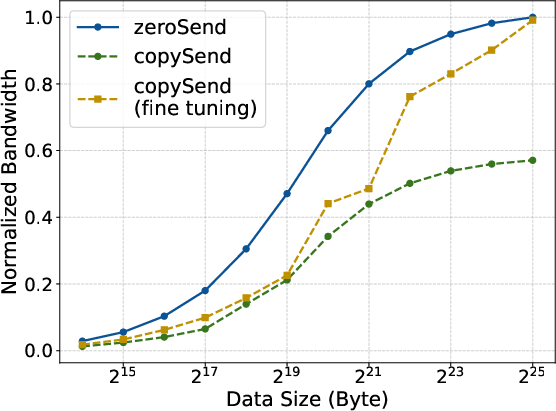
- Zero-copy, SM-free transfers: Usually, sending data is like putting it in a locker, then someone moves it from locker to locker before it reaches the final person. That wastes time and energy. “Zero-copy” is like handing the note directly from sender to receiver—no lockers in between. “SM-free” means the GPU’s main “brain cells” (its compute units) aren’t tied up just shuffling data; they stay focused on math.
- Host-driven customization (CPU-guided algorithms): Instead of packing all logic into GPU kernels, NCCLX lets a lightweight CPU thread plan and schedule the communication while respecting GPU stream order. This makes it easier to plug in custom algorithms and optimize for different parts of a model (like pipeline parallel, tensor parallel, mixture-of-experts, and data parallel training).
- Multiple API styles for flexibility:
- Host-initiated APIs (simple, fast setup)
- Host-initiated with GPU-held metadata (useful when the GPU decides details on the fly, like routing in mixture-of-experts)
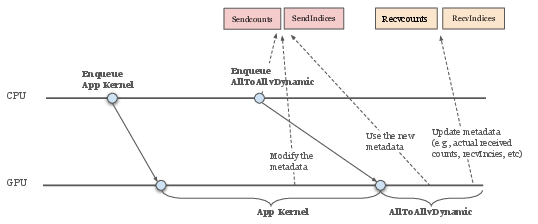
- Device-initiated APIs (in progress), where the GPU can trigger communication directly for ultra-low-latency patterns
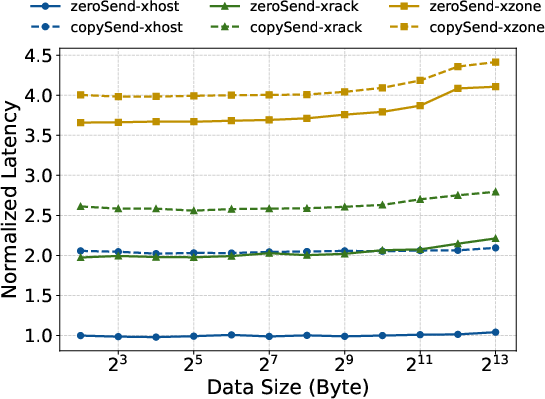
- Traffic control for big networks (DQPLB): The data center network is like a multi-city highway system. If you dump one giant truckload at once, you can cause traffic jams. CTran breaks messages into right-sized chunks and carefully limits how many are “on the road” at the same time, depending on how far they have to travel (same rack, same room, across zones, or to another building). This keeps the network flowing smoothly and avoids huge queues at switches.
- Co-design with PyTorch memory (tensor registration):
- Automatically track and lazily register buffers when first used
- Use a pre-allocated memory pool for communication to avoid repeated registration costs under heavy memory churn
- These tricks keep registration overhead low without making developers rewrite their code.
- Works across different hardware links: CTran supports NVLink (fast in-server GPU-to-GPU links), high-speed network (RoCE/InfiniBand) between servers, and sockets, and can choose the best path and algorithm for each job.
- Built-in tooling: NCCLX adds scalable initialization (so 100k+ GPUs can start fast and in sync), monitoring, fault tolerance (so a single hiccup doesn’t break a giant job), and resource controls to keep memory and network handles in check.
What they found
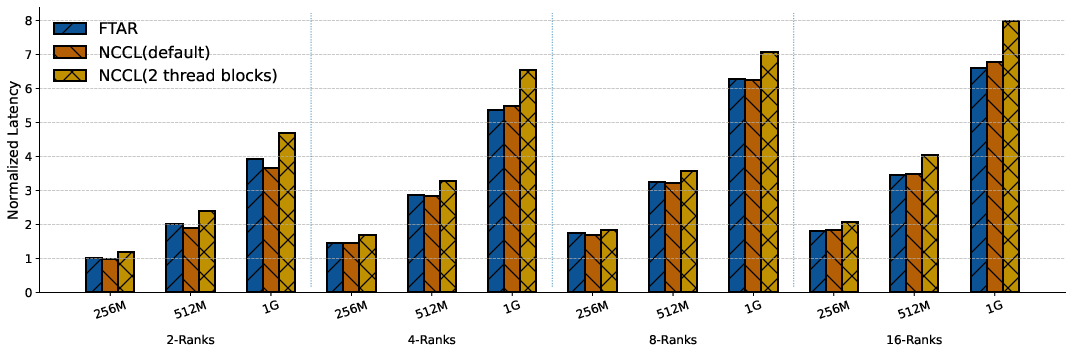
On real Llama 4 workloads at Meta scale, NCCLX improved performance notably:
- Training:
- Up to 12% lower latency per steady training step
- Up to 11× faster startup time at 96,000 GPUs (so massive jobs get going much sooner)
- Inference:
- 15% to 80% lower end-to-end decoding latency across different multi-node setups (snappier responses for users)
- Technical wins that make these gains possible:
- Zero-copy reduced extra GPU work and delays caused by intermediate buffers
- Smart traffic control (DQPLB) kept the network from clogging, especially across long-distance paths between buildings
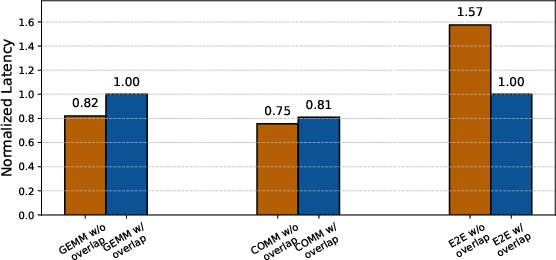
- Host-driven algorithms made it easier to add classic fast patterns (like tree or doubling algorithms) and custom features (like fault-tolerant all-reduce), and to overlap compute with communication effectively
Why this matters: At 100k+ GPUs, distances and switch layers add delay. NCCLX keeps message sizes, pacing, and routing tuned to the “bandwidth-delay product” of each path, so the network stays full but not overwhelmed. It also avoids wasting GPU compute time on memory copies, so more of the chip is spent on model math.
What this means going forward
- Faster, cheaper large models: Better communication means we can train and serve bigger models faster and with fewer stalls, which can reduce costs and make new features (like larger context windows or more experts) practical.
- One stack for diverse needs: By supporting host-initiated, hybrid, and device-initiated styles in one place, teams don’t have to juggle multiple libraries for different parts of the model. That simplifies development and operations.
- Scales to future sizes: With careful network load balancing and zero-copy design, NCCLX is built to handle even larger clusters and more complex topologies across multiple data center buildings.
- More robust operations: Faster startup, fault tolerance, and good monitoring make it easier to run giant jobs in the real world, find problems quickly, and keep performance high.
In short: NCCLX helps huge fleets of GPUs communicate like a well-orchestrated team—passing the right-sized messages at the right time, using the best routes, without getting in each other’s way—so the biggest AI models can train and serve faster and more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and missing details that future work could address to strengthen the paper’s claims and broaden the applicability of NCCLX and CTran.
- Device-initiated APIs: The paper states device-initiated support is “ongoing” but does not specify API semantics, resource models, interaction with CUDA Graphs, or empirical comparison to NVSHMEM in LLM workloads; portability risks and migration paths from NVSHMEM remain unclear.
- GPU-resident collectives for inference: Design and implementation details are sparse; there is no breakdown of end-to-end latency (p50/p99), CPU cycle profiles, or how GPU-resident metadata avoids padding and integrates with CUDA Graphs in realistic MoE inference pipelines.
- Zero-copy buffer registration instability: The paper observes sporadic 100 ms registration spikes and notes ongoing collaboration with NVIDIA, but provides no mitigation guarantees, detection mechanisms, or operational guardrails to ensure predictable latency at 100k+ scale.
- Memory allocator interaction and policy: Auto-registration effectiveness depends on PyTorch CCA segment reuse; frequent remapping (e.g., in PP) can cause registration churn. The MemPool solution requires explicit tensor labeling. Open questions: automated identification of “communication tensors,” dynamic policy switching between auto-registration and MemPool, and fragmentation/efficiency impacts under tight memory budgets.
- Overlap and resource contention: While zero-copy is SM-free, NIC DMA still consumes HBM bandwidth; there is no quantitative analysis of HBM bandwidth contention with GEMM, or of throughput/latency trade-offs under heavy compute-memory pressure.
- DQPLB adaptivity and fairness: Per-connection outstanding-message limits appear static; there is no runtime adaptation to BDP changes, congestion, or failures, nor analysis of fairness across concurrent jobs/collectives or coexistence with non-LLM traffic on shared fabrics.
- DQPLB correctness/robustness: The 24-bit sequence number, wrap-around handling, CQ overflow risk at scale, memory overhead of out-of-order tracking, and CPU cost per peer under high fan-out are not analyzed; portability of
IBV_WR_RDMA_WRITE_WITH_IMMand immediate-data semantics across NICs/IB/RoCE is not addressed. - Congestion control posture: The design explicitly avoids DCQCN/ECN and relies on deep-buffer switches plus receiver-driven flow control, but provides no stability analysis, tail-latency characterization, or guidance for deployments lacking deep buffers; impacts under adversarial or bursty patterns are unknown.
- Large-scale validation depth: Claims of 100k+ GPU readiness lack comprehensive end-to-end evaluations across topological tiers (rack/zone/DC), multiple collectives (MoE AllToAll, DP AllReduce, PP send/recv), tail distributions, and failure injections.
- Scalable initialization details: The “11×” improvement at 96k lacks protocol description, scalability analysis under control-plane churn, authentication/security considerations, and integration details with cluster schedulers.
- Fault tolerance specifics: “Fault tolerant AllReduce” is referenced without describing algorithms (e.g., redundancy, coding, or reconfiguration), guarantees under partial failures/stragglers/link flaps, or performance overheads during recovery.
- CPU-side host-driven model overheads: A background thread per communicator raises questions about CPU core consumption, NUMA locality, OS scheduling jitter, preemption sensitivity, and power efficiency at cluster scale; no measurements are provided.
- Stall kernel/stream semantics: The sub-microsecond synchronization claim is not validated under heavy stream concurrency or mixed workloads; deadlock avoidance, CUDA Graph interactions, and cross-library stream ordering are not discussed.
- NVLink zero-copy prerequisites: The CopyEngine/NVLink approach is presented for H100-class nodes with full NVLink connectivity; there is no fallback design or performance characterization for PCIe-only or partially connected topologies (e.g., A100 variants).
- Security and isolation: RDMA zero-copy exposes GPU memory regions; multi-tenant isolation, registration lifetime management, and cleanup on failures are not discussed; OS/IOMMU limits and safety checks are unspecified.
- Portability beyond NVIDIA/RoCE: AMD GPUs, alternative NICs, and IB fabrics are acknowledged but not evaluated; vendor-specific dependencies (e.g., immediate data fields, GPUDirect RDMA behavior) may limit portability.
- Algorithm selection and autotuning: “Offline auto-tuning” lacks methodology, search space, and stability guarantees; there is no runtime adaptation or sensitivity analysis across model phases, message-size mixes, or topology changes.
- Handshake overhead: Microbenchmarks exclude the address-exchange phase; for frequent p2p in PP, handshake costs could dominate; buffer reuse strategies and CUDA Graph caching effectiveness are not quantified.
- Monitoring and tooling: Resource management and fault localization tools are claimed but not described (APIs, overheads, examples); integration with observability stacks (e.g., tracing, metrics, logs) and operator workflows is unclear.
- Reproducibility: Reported improvements often use percentages/normalized plots without absolute times, tail metrics, network details, software versions, NCCL baselines (e.g., exact tunables), or model hyperparameters; the public repo reference lacks a pinned commit/configuration to reproduce results.
- RDMA/QP resource scaling: Multiple data QPs per connection at scale may hit NIC QP/CQ limits; there is no analysis of QP/CQE memory overhead, completion processing load, or strategies when per-GPU peer counts are very high.
- Host–kernel coordination heuristics: The scheduling rules that decide when to let the kernel perform NVLink copies versus CPU-driven RDMA are not formalized; suboptimal overlap risks and sensitivity to message sizes/topology are unaddressed.
- Topology discovery and churn: The system depends on topology-aware configuration, but discovery methods, resilience to misconfiguration/stale views, and dynamic adaptation to link/node changes are unspecified.
- NCCL coexistence: The paper allows mixing baseline NCCL and CTran via environment variables, yet gives no guidance on safe combinations, interference on shared NIC/streams, or a compatibility matrix for collectives.
- Error handling semantics: Behavior on RDMA errors, CQ timeouts, sequence gaps, or stuck peers is unspecified; upper-layer guarantees (abort, retry, idempotence) and observability for such events are missing.
- Memory footprint accounting: While NCCL’s FIFO-based memory use is critiqued, NCCLX’s own overheads (registration caches, out-of-order maps, MemPool reserves) are not quantified across collectives and scales.
- Tail behavior under contention: Average latency/bandwidth improvements are shown, but p95/p99 behaviors—critical for inference SLOs and training step stragglers—are not provided.
- Network feature dependencies: The approach assumes specific switch VOQ tuning and deep-buffer behavior; the sensitivity to switch silicon, ECMP hashing, and cloud-network policies (e.g., PFC/ECN knobs) is not studied.
Practical Applications
Immediate Applications
Below is a curated list of practical uses that can be deployed now, organized across sectors. Each bullet notes potential tools/workflows and key assumptions or dependencies that affect feasibility.
- Large-scale LLM training acceleration (software/AI infrastructure)
- What: Reduce per-step latency (up to 12%) and training startup time (up to 11× at ~96k GPUs) for models like Llama4.
- How: Adopt NCCLX as the PyTorch communication backend; use CTran’s host-driven collectives, zero-copy transfers, scalable initialization, and DQPLB for topology-aware load balancing.
- Tools/Workflows: torchcomms ncclx backend; environment-based algorithm selection; offline auto-tuning; scalable init service.
- Assumptions/Dependencies: H100-class GPUs with NVLink; RoCE/InfiniBand network; deep-buffer switches; RDMA driver stability; access to NCCLX build/integration.
- Low-latency distributed inference (consumer products, enterprise software)
- What: Improve end-to-end decoding latency by 15–80% in multi-node inference (e.g., MoE AllToAll).
- How: Use GPU-resident collectives and low-latency host-initiated APIs with GPU-resident metadata; reduce CPU overhead; leverage CUDA Graphs where applicable.
- Tools/Workflows: NCCLX inference mode, MoE-aware collectives, CUDA Graph-friendly routines.
- Assumptions/Dependencies: NVLink connectivity; RDMA-capable NICs; CUDA Graph integration; consistent kernel shapes for graph capture.
- Pipeline Parallelism speed-up via zero-copy send/recv (software/HPC)
- What: Lower latency over cross-rack and cross-zone paths while minimizing SM/HBM contention to improve compute–communication overlap.
- How: Employ zero-copy and SM-free point-to-point operations for PP microbatches.
- Tools/Workflows: NCCLX zero-copy P2P; memory-pool mode for predictable registration; PP microbatch scheduling tuned for DQPLB.
- Assumptions/Dependencies: Memory pool configured; tensor registration managed by NCCLX’s PyTorch co-design; RDMA driver behavior predictable.
- Fine-grained TP overlap with RMA Put (software/AI infrastructure)
- What: Achieve tight compute–communication overlap for Tensor Parallelism.
- How: Use NCCLX’s remote memory access semantics to push data directly during kernel progress.
- Tools/Workflows: CTran RMA Put primitives; TP kernels co-designed with communication.
- Assumptions/Dependencies: Stable RMA primitives on the target NIC/driver; precise stream ordering.
- Elastic, fault-tolerant AllReduce for Hybrid Sharding DP (software/AI infrastructure)
- What: Enable no-hang operation, elasticity, and flexible restarts in data-parallel domains.
- How: Deploy fault-tolerant custom collectives in NCCLX; integrate with checkpoint/restart logic.
- Tools/Workflows: Fault-tolerant AllReduce; control-plane orchestration; recovery workflows.
- Assumptions/Dependencies: Application-level checkpointing; control-plane reliability; cluster scheduler integration.
- Scalable initialization service for massive jobs (cloud operations)
- What: Reliable, fast collective setup across tens of thousands of hosts.
- How: Use NCCLX’s scalable init workflows before high-speed RoCE/IB communications.
- Tools/Workflows: Initialization fan-out, host-side coordination, communicator lifecycle management.
- Assumptions/Dependencies: Orchestrator (e.g., Kubernetes/Slurm) hooks; service discovery; robust host CPU threads.
- Congestion reduction via DQPLB (network engineering)
- What: Reduce switch buffer build-up and improve completion time with bandwidth-delay product–aware posting across QPs.
- How: Apply per-topology limits on outstanding data; round-robin distribution; immediate-data sequence tracking; fast-path QP.
- Tools/Workflows: DQPLB tuner; topology classification (in-rack/cross-rack/cross-zone/cross-DC); VOQ tuning.
- Assumptions/Dependencies: NIC support for RDMA Write with Immediate; deep-buffer switches; prior VOQ tuning; telemetry to guide limits.
- Operational telemetry, resource management, and fault localization (devops/observability)
- What: Maintain high communication performance while minimizing GPU memory/SM and network resources; rapid hardware and user-fault diagnosis.
- How: Use NCCLX’s resource manager, fault analyzer, and debug tooling.
- Tools/Workflows: Fault localization dashboard; resource quotas for QPs/SM/memory; alerts on misconfiguration.
- Assumptions/Dependencies: Integration with existing logging/metrics pipelines; operator runbooks.
- Academic and lab-scale reproducible collectives (academia/education)
- What: Teach and test classical HPC algorithms (Brucks, Recursive Doubling, Tree Broadcast) in modern GPU contexts.
- How: Use NCCLX’s host-driven design to port/evaluate latency-optimized collectives; explore hierarchical topology impacts.
- Tools/Workflows: Small-cluster experiments; algorithm toggling via environment variables; PyTorch-based benchmarks.
- Assumptions/Dependencies: Access to IB/RoCE or NVLink-equipped clusters; instrumentation for latency/path analysis.
- Sector-specific LLM training cost/time reduction (finance, healthcare, media)
- What: Faster training cycles and lower operational overhead for domain models.
- How: Replace baseline NCCL with NCCLX in PyTorch stacks; tune DQPLB and zero-copy for the organization’s topology.
- Tools/Workflows: NCCLX auto-tuning runs; training orchestration integration; monitoring for congestion.
- Assumptions/Dependencies: Compliance and security reviews; hardware parity with tested configurations; migration playbooks.
- Carbon and energy efficiency reporting improvements (policy/ESG)
- What: Use measurable communication efficiency gains to refine energy/CO2 accounting for AI workloads.
- How: Track reduced time-to-train and network buffer occupancy as inputs to energy models; update procurement criteria.
- Tools/Workflows: Energy telemetry collection; reporting templates linking NCCLX adoption to energy savings.
- Assumptions/Dependencies: Access to reliable power/telemetry data; cooperation between infra and sustainability teams.
- Better user experiences via faster AI responses (daily life/consumer apps)
- What: More responsive chat assistants and generative features at scale.
- How: Deploy NCCLX-backed multi-node inference for production services running large MoE or TP/PP models.
- Tools/Workflows: Inference serving pipelines; CUDA Graph capture; low-latency collectives.
- Assumptions/Dependencies: Service readiness for NCCLX stack; model compatibility with GPU-resident metadata paths.
Long-Term Applications
The following applications need further research, development, scaling, or ecosystem changes before broad deployment.
- Unified device-initiated APIs in NCCLX (software/AI infrastructure)
- What: Integrate NVSHMEM-like device-initiated semantics to support highly dynamic, fine-grained communication from kernels.
- Value: Lower latency and better compute–communication overlap for small/medium message patterns.
- Dependencies: Completion of NCCLX device-initiated mode; symmetric memory strategies; CUDA Graph robustness; GPU driver performance.
- Cross-vendor accelerator support (hardware/software)
- What: Extend CTran backends to AMD GPUs and emerging AI accelerators/ASICs.
- Value: Broader portability; avoids dual-runtime maintenance across heterogeneous fleets.
- Dependencies: Vendor RDMA stacks, equivalent NVLink/PCIe/NIC offloads, kernel/driver maturity.
- Autonomous topology-aware auto-tuning (AI infrastructure)
- What: Continuous, data-driven selection of collectives and DQPLB parameters per topology and workload phase.
- Value: Remove manual tuning; adapt to dynamic congestion and job placement.
- Dependencies: High-fidelity telemetry, performance models, safe online optimization policies.
- Geo-distributed multi-DC training and serving (cloud networking)
- What: Seamless collectives across buildings/regions using BDP-aware posting and congestion-aware routing.
- Value: Flexibility in capacity placement; resilience to regional constraints.
- Dependencies: Inter-DC mesh expansion, latency/jitter engineering, regulatory/data locality compliance.
- Standardized zero-copy buffer registration in PyTorch/CUDA (open-source ecosystem)
- What: Make memory-pool/auto-registration modes first-class, predictable, and efficient across drivers.
- Value: Lower overhead, fewer edge-case stalls (e.g., 100 ms registration spikes), broader adoption.
- Dependencies: NVIDIA/AMD driver fixes; PyTorch CCA enhancements; community consensus and testing.
- NIC/DPU offload for collective control plane (networking/hardware co-design)
- What: Move address exchange, sequencing, and notification logic closer to NIC/DPUs.
- Value: Lower CPU overhead, higher throughput, better isolation; unlock more fast-path operations.
- Dependencies: Programmable NIC/DPUs; RDMA firmware features (e.g., immediate data handling, sequence tracking).
- Energy-aware scheduling and congestion-aware job placement (energy/cloud ops)
- What: Use NCCLX/DQPLB telemetry to place jobs and throttle collectives for energy/performance balance.
- Value: Lower peak power; greener training; predictable performance under multi-tenant load.
- Dependencies: Scheduler integration; policy knobs for energy targets; reliable congestion/BDP metrics.
- Robust elasticity for preemptible capacity and spot GPUs (cloud economics)
- What: Generalize fault-tolerant AllReduce for frequent preemption; fast recovery and reconfiguration.
- Value: Reduce cost via spot/preemptible instances; maintain high training efficiency.
- Dependencies: Advanced checkpointing; rapid communicator reformation; topology-aware recovery.
- Managed NCCLX services and tooling products (cloud/provider offerings)
- What: Offer NCCLX-enabled distributed training as a managed service; ship “DQPLB Tuner”, “Fault Analyzer”, “Network Congestion Guard”.
- Value: Simplify adoption for enterprises; reduce ops burden; standard SLAs.
- Dependencies: Productization, support pipelines, multi-tenant isolation features.
- Policy and standards for AI interconnects (policy/industry consortia)
- What: Define best practices on deep-buffer vs DCQCN, QP limits, interconnect oversubscription, and carbon reporting for large-scale AI.
- Value: Safer, more efficient AI infrastructure; transparency in energy and performance claims.
- Dependencies: Multi-stakeholder engagement; empirical benchmarks; alignment with regulatory bodies.
- Distributed inference at the edge (robotics/embedded systems)
- What: Bring GPU-resident collectives and low-latency paths to multi-GPU edge clusters for real-time robotics and AR/VR.
- Value: Faster local decision-making; reduced cloud dependency.
- Dependencies: RDMA/NVLink alternatives at the edge; optimized socket backend; ruggedized NICs.
- New research on hierarchical-latency collectives (academia)
- What: Design algorithms that exploit sequence-numbered multi-QP posting, immediate data, and sliding-window ordering under extreme hierarchy.
- Value: Advance theory and practice of collectives at 100k+ scales; unify HPC and ML communication paradigms.
- Dependencies: Access to large testbeds or realistic simulators; collaboration with hardware vendors.
Glossary
- AI Zone: A logical grouping of racks within a datacenter used to structure large-scale AI networks and topology. Example: "Each DC is partitioned into multiple AI Zones."
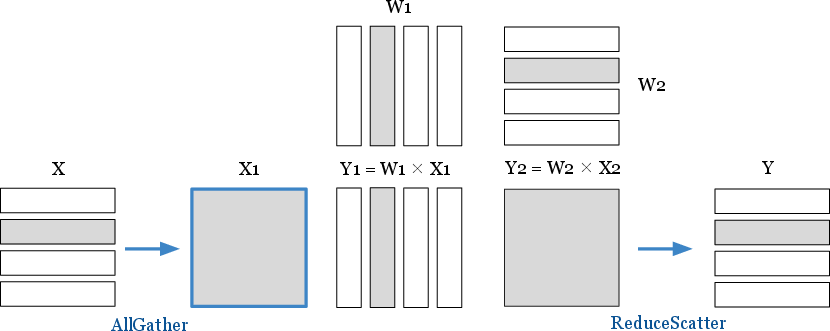
- AllGather: A collective operation that gathers data from all processes and distributes the combined result back to all of them. Example: "Collectives like AllReduce, AllGather and ReduceScatter, are commonly used in various model domains (e.g., Data Parallelism, Tensor Parallelism)."
- AllReduce: A collective operation that reduces data across processes (e.g., sum) and shares the result with all participants. Example: "Collectives like AllReduce, AllGather and ReduceScatter, are commonly used in various model domains (e.g., Data Parallelism, Tensor Parallelism)."
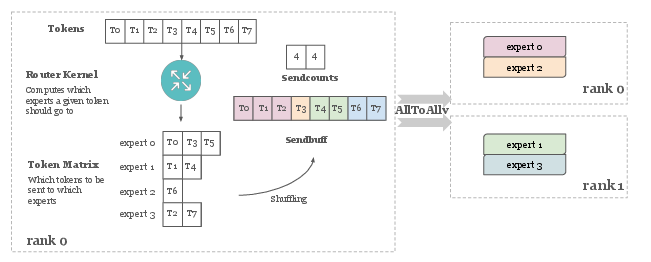
- AllToAll: A collective where each participant sends distinct data to every other participant. Example: "AllToAll in Mixture of Experts falls into such a pattern"
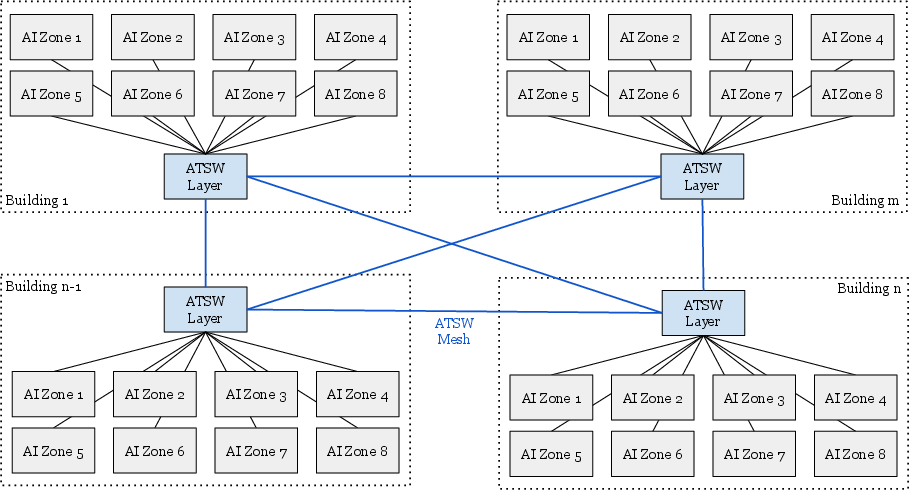
- ATSW (Aggregator Training Switch): A network switch layer that connects cluster training switches across a datacenter to extend the RoCE fabric. Example: "Aggregator Training Switches (ATSW) connect CTSWs across the DC"
- Bandwidth-delay product (BDP): The amount of data that can be in flight on a network link; product of bandwidth and round-trip time, guiding message sizing. Example: "bandwidth delay product (BDP)"
- Brucks: A latency-optimized algorithm for AllGather used in large-scale collectives. Example: "we ported the latency-optimized Brucks and Recursive Doubling algorithms for AllGather"
- CCA (CUDA cache allocator): PyTorch’s GPU memory allocator; extended here to integrate buffer registration for zero-copy networking. Example: "we carefully extended the CUDA cache allocator (CCA) in Pytorch"
- Clos architecture: A multi-stage network topology providing scalable, non-blocking connectivity. Example: "The network within a DC adopts a 3-layer Clos architecture"
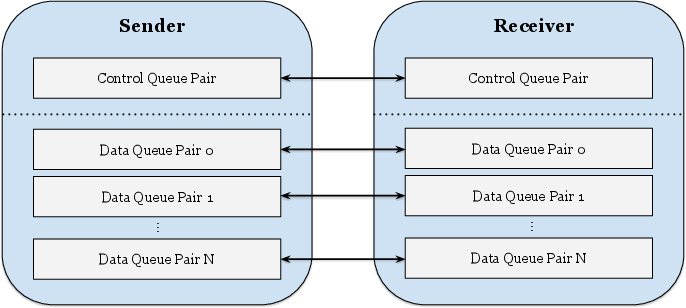
- Completion Queue (CQ): An RDMA structure where completion notifications for work requests are posted. Example: "corresponding completion queue (CQ)"
- Completion Queue Element (CQE): An entry posted to a completion queue indicating that a work request has completed. Example: "completion queue element (CQE)"
- CopyEngine: A GPU hardware engine for direct memory copy operations without SM involvement. Example: "we utilize the CopyEngine where possible through custom user-facing APIs."
- CTran: A host-driven custom transport layer within NCCLX providing zero-copy, SM-free transfers and topology-aware optimizations. Example: "we developed a host-driven custom transport layer called CTran."
- CTSW (Cluster Training Switch): A switch layer connecting racks within an AI Zone. Example: "Cluster Training Switches (CTSW) connect all racks within an AI Zone."
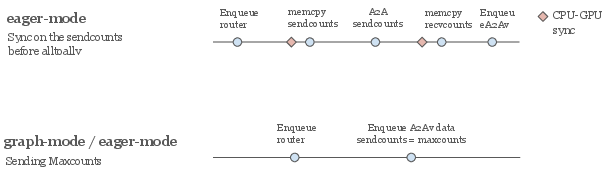
- CUDA graphs: A CUDA feature to capture and replay sequences of GPU operations; sensitive to host-device synchronization and argument passing. Example: "proves incompatible with CUDA graphs"
- Data Parallelism (DP): A parallel training method where model replicas process different data shards and synchronize parameters. Example: "Data Parallelism (DP)"
- DCQCN: A congestion control mechanism for RDMA over Ethernet; noted here as not used in favor of other strategies. Example: "we do not employ traditional congestion control mechanisms such as DCQCN"
- Device-initiated APIs: Communication APIs invoked from GPU kernels with device-side arguments for low-latency, fine-grained operations. Example: "Device-initiated APIs"
- DQPLB (Dynamic Queue Pair Load Balancing): A technique to partition and rate-limit zero-copy traffic across multiple QPs based on topology to control congestion. Example: "Dynamic Queue Pair Load Balancing (DQPLB) technique"
- EP (Expert Parallelism): A model-parallel strategy where different “experts” (sub-networks) handle different tokens or inputs. Example: "expert parallelism (EP)"
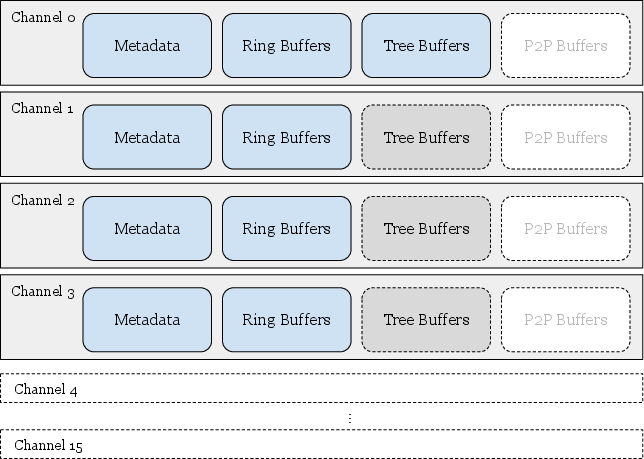
- FIFO buffer: An internal staging buffer used by copy-based collectives to pipeline data transfers. Example: "the sender rank copies data from the user buffer into an NCCL-internal 'FIFO buffer' that is pre-registered with the network."
- FSDP (Fully Sharded Data Parallelism): A method that shards model parameters, gradients, and optimizer state across data-parallel ranks to save memory. Example: "fully sharded data parallelism, FSDP, and data parallelism, DP"
- GEMM: General Matrix-Matrix Multiply; a core compute kernel in deep learning workloads. Example: "such as GEMM."
- HBM (High Bandwidth Memory): On-package memory providing very high throughput for GPU workloads. Example: "Streaming Multiprocessors (SMs) and utilize High Bandwidth Memory (HBM) bandwidth."
- Host-pinned memory: Host memory pages pinned to avoid paging, enabling fast DMA and GPU/CPU synchronization. Example: "allocated from host-pinned memory."
- IB (InfiniBand): A high-performance networking technology commonly used in HPC and GPU clusters. Example: "Infiniband/RoCE (IB)"
- IBV_WR_RDMA_WRITE_WITH_IMM: An RDMA verb opcode that writes remote memory and carries 32-bit immediate data for inline signaling. Example: "the sender utilizes the IBV_WR_RDMA_WRITE_WITH_IMM opcode"
- Immediate data: A small inline metadata field carried with RDMA operations for lightweight signaling and ordering. Example: "the 32-bit immediate data field"
- Mixture of Experts (MoE): A model architecture that routes inputs to specialized sub-networks (experts) to improve efficiency and capacity. Example: "in MoE training and inference systems,"
- NCCL (NVIDIA Collective Communication Library): A GPU collective communication library optimized for bandwidth and regular collective patterns. Example: "NVIDIA offers NCCL"
- NCCLX: Meta’s collective communication framework unifying host- and device-initiated semantics with zero-copy and customization. Example: "we developed NCCLX, a collective communication framework"
- NIC (Network Interface Card): Hardware that connects a host to the network and performs DMA for RDMA operations. Example: "PCIe transfer from send buffer to sender side NIC"
- NVLink: NVIDIA’s high-speed GPU interconnect enabling fast peer-to-peer transfers within a node. Example: "CTran contains NVLink, Infiniband/RoCE (IB) and socket backends"
- NVSHMEM: A device-initiated, GPU-centric PGAS-style communication library suited for fine-grained, low-latency operations. Example: "In contrast, NVSHMEM utilizes device-initiated communication semantics."
- Over-subscription ratio: The ratio of downstream to upstream bandwidth, indicating potential contention in network tiers. Example: "over-subscription ratio from 1:7 to 1:2.8"
- PAT algorithm: A recent latency-optimized collective algorithm added to NCCL for large scale. Example: "the recent 2.23 release introduced the PAT algorithm"
- Pipeline Parallelism (PP): A model-parallel training method that assigns different layers to different devices and pipelines microbatches through them. Example: "Pipeline parallelism (PP) is a distributed training approach"
- QP (Queue Pair): The RDMA endpoint abstraction (send and receive queues) used to post work requests. Example: "The number of data QPs is configurable"
- RDMA (Remote Direct Memory Access): A networking capability allowing direct memory reads/writes between hosts without CPU involvement. Example: "RDMA network transfer is driven by the CPU thread."
- ReduceScatter: A collective that reduces data across all participants and scatters disjoint reduced segments to each one. Example: "AllGather and ReduceScatter, are commonly used"
- Recursive Doubling: A logarithmic-step collective algorithm used for operations like AllGather to minimize latency. Example: "Brucks and Recursive Doubling algorithms for AllGather"
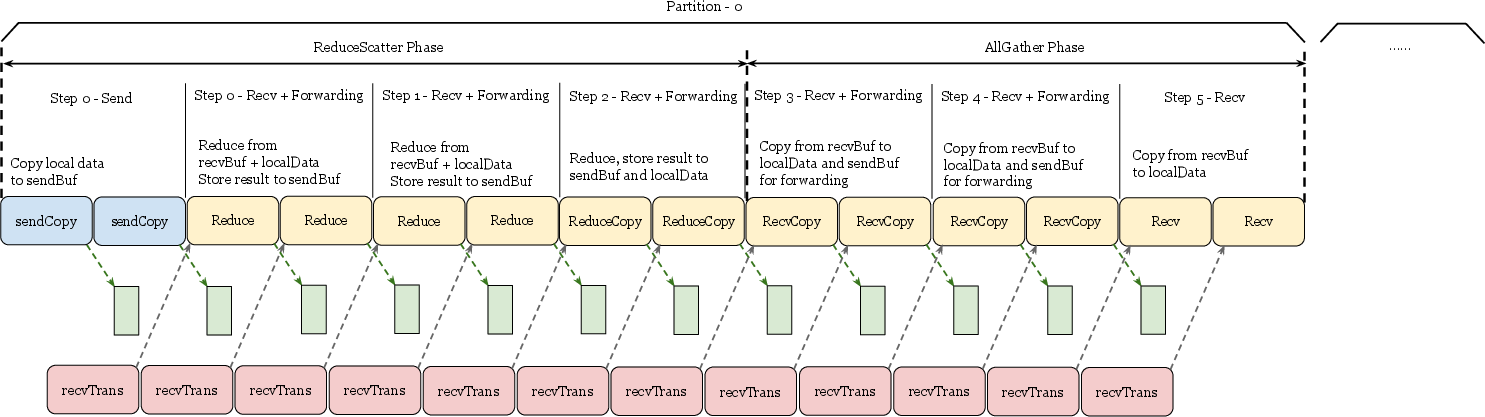
- Recursive Vector-Halving Distance-doubling: A classic algorithm for scalable ReduceScatter using halving/doubling communication patterns. Example: "Recursive Vector-Halving Distance-doubling algorithm for ReduceScatter"
- Rendezvous protocol: A two-phase transfer method where endpoints exchange buffer metadata before sending data. Example: "following the classical rendezvous protocol."
- Ring algorithm: A bandwidth-efficient collective algorithm where data circulates around ranks in a ring. Example: "NCCL only had the Ring algorithm till the recent 2.23 release introduced the PAT algorithm"
- RoCE (RDMA over Converged Ethernet): RDMA transport over Ethernet networks used in AI clusters. Example: "RoCE network"
- RMA (Remote Memory Access): Communication semantics enabling direct reads/writes to remote memory without active participation by the remote CPU. Example: "remote memory access (RMA) semantics."
- RTSW (Rack Training Switch): A switch connecting GPUs within the same rack. Example: "Rack Training Switch (RTSW) connects GPUs within a rack"
- SM (Streaming Multiprocessor): The GPU’s compute unit responsible for executing CUDA kernels. Example: "Streaming Multiprocessors (SMs)"
- SM-free: Communication that avoids using GPU SMs, reducing contention with compute kernels. Example: "SM-free communication"
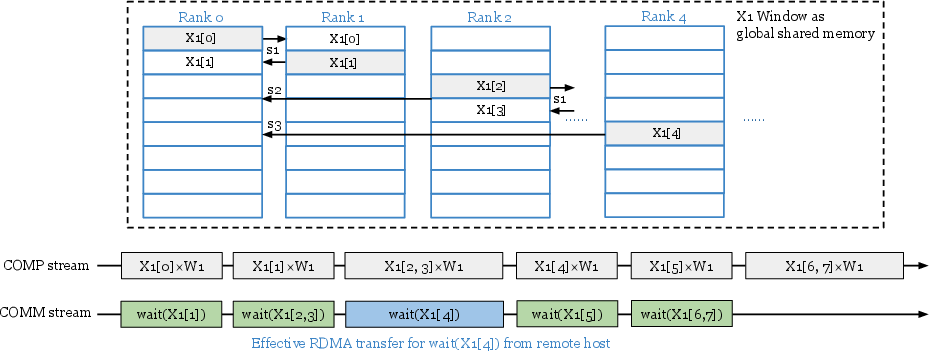
- Stall kernel: A lightweight CUDA kernel launched to enforce stream ordering while a CPU thread drives communication. Example: "while launching a stall kernel on the user-specified stream."
- Tensor Parallelism (TP): A model-parallel approach splitting individual layers (e.g., matrix multiplications) across multiple GPUs. Example: "tensor parallelism (TP)"
- Virtual Output Queuing (VOQ): A switch queuing mechanism to avoid head-of-line blocking by separating queues per output port. Example: "Virtual Output Queuing (VOQ) tuning"
- WQE (Work Queue Element): An RDMA work request descriptor posted to a QP’s send/receive queue. Example: "work queue elements (WQEs)"
- Zero-copy: A transfer method that sends data directly from source to destination buffers without intermediate copies. Example: "zero-copy and SM-free communication"
Collections
Sign up for free to add this paper to one or more collections.