Optimizing 3D Gaussian Splattering for Mobile GPUs
Abstract: Image-based 3D scene reconstruction, which transforms multi-view images into a structured 3D representation of the surrounding environment, is a common task across many modern applications. 3D Gaussian Splatting (3DGS) is a new paradigm to address this problem and offers considerable efficiency as compared to the previous methods. Motivated by this, and considering various benefits of mobile device deployment (data privacy, operating without internet connectivity, and potentially faster responses), this paper develops Texture3dgs, an optimized mapping of 3DGS for a mobile GPU. A critical challenge in this area turns out to be optimizing for the two-dimensional (2D) texture cache, which needs to be exploited for faster executions on mobile GPUs. As a sorting method dominates the computations in 3DGS on mobile platforms, the core of Texture3dgs is a novel sorting algorithm where the processing, data movement, and placement are highly optimized for 2D memory. The properties of this algorithm are analyzed in view of a cost model for the texture cache. In addition, we accelerate other steps of the 3DGS algorithm through improved variable layout design and other optimizations. End-to-end evaluation shows that Texture3dgs delivers up to 4.1$\times$ and 1.7$\times$ speedup for the sorting and overall 3D scene reconstruction, respectively -- while also reducing memory usage by up to 1.6$\times$ -- demonstrating the effectiveness of our design for efficient mobile 3D scene reconstruction.

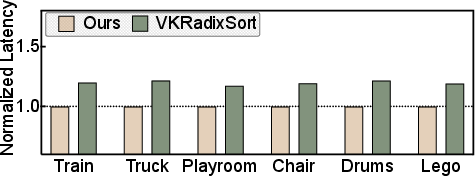
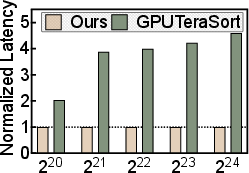
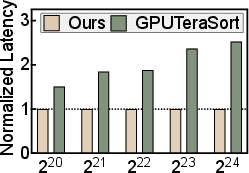
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making a new 3D graphics technique, called 3D Gaussian Splatting (3DGS), run fast on phones and tablets. 3DGS turns multiple photos of a place into a realistic 3D scene you can look around in. The authors focus on speeding it up on mobile GPUs (the graphics chips inside phones), so apps like augmented reality, drone navigation, or robot vision can work quickly, privately, and without needing the internet.
What questions the paper tries to answer
The paper asks simple but important questions:
- How can we make 3DGS run fast on mobile GPUs, which are different from big desktop GPUs?
- Can we redesign the slow parts of 3DGS (especially sorting) to work better with the special 2D “texture caches” on mobile chips?
- If we do that, how much faster and more memory‑efficient can the whole 3DGS pipeline become on real phones?
How the researchers approached the problem
Think of 3DGS as painting a 3D scene using many soft, blurry dots (Gaussians) that act like tiny, colored “paint splashes.” To show the scene from a camera view, 3DGS:
- Projects those 3D splashes onto a 2D image.
- Splits the image into small squares (tiles), like a chessboard.
- Sorts the splashes so the ones closer to the camera are blended correctly over the ones behind.
- Combines colors and transparency to produce the final picture.
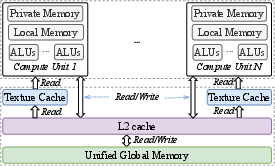
On mobile GPUs, the memory system is built around 2D texture caches. A cache is like a tiny, super‑fast pantry that works best if you grab items sitting next to each other in rows and columns. If your program keeps looking up data that’s far apart, you miss the pantry and have to go back to the slower main kitchen—this wastes time.
The researchers found that sorting the splashes was the biggest time sink. Traditional GPU sorting compares items that can be far apart in memory, which causes lots of cache misses on mobile GPUs.
So they did three key things:
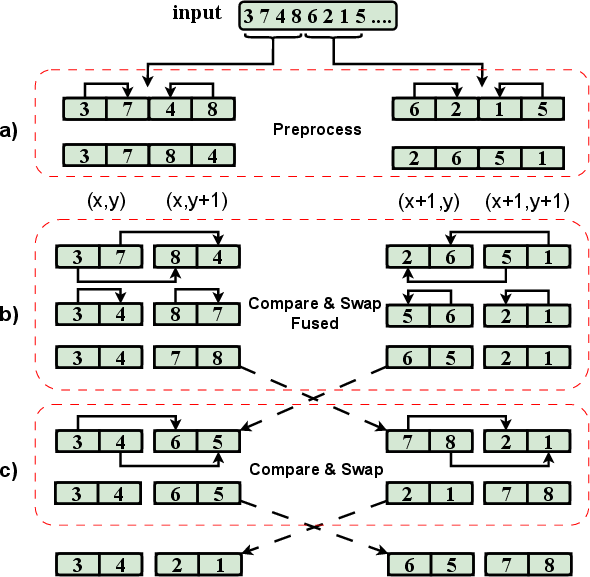
- A texture‑cache‑friendly sorting algorithm: They rearranged (“transformed the layout”) so that each pair of items that needs to be compared sits next to each other in the 2D texture, like putting students who need to work together at adjacent desks. This way, the GPU fetches them in one quick grab from the cache. They also “fused” the last steps of sorting to reduce extra memory trips.
- Smart data packing: They grouped and laid out variables (like position, color, and opacity) so they fit naturally into the 2D texture and its 4‑value “pixels,” minimizing wasted reads and making index math simple and fast.
- Faster tile rendering: Inside each 16×16 tile, they used SIMD (do the same math on multiple pixels at once) and unrolled small loops, so each thread computes more pixels efficiently when all those pixels need the same splash info.
To guide these choices, they built a simple performance model of the texture cache using micro‑benchmarks. In everyday terms, they measured how slow things get when their data “steps out of the pantry’s shelves” and trained a small regression model to predict the effect. This helped them choose layouts and strides that stay “in‑pantry” more often.
What they found and why it matters
Their approach led to solid, measurable wins on real mobile devices:
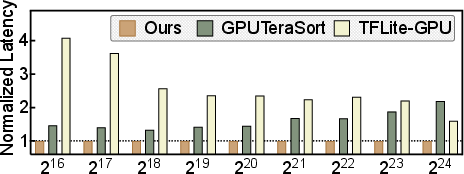
- Sorting speedups up to 4.1× compared to prior GPU sorting methods.
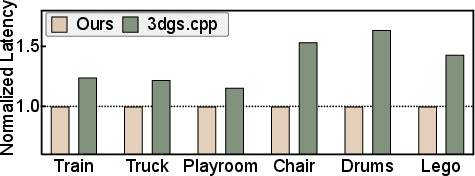
- End‑to‑end 3DGS pipeline speedups up to 1.7×.
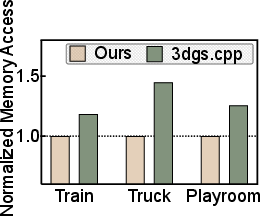
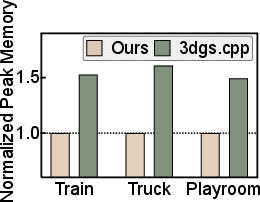
- Memory usage reduced by up to 1.6×.
These improvements come from turning many far‑apart memory accesses into nearby ones, which the 2D texture cache can serve quickly. That means smoother, faster rendering without needing a desktop GPU or a cloud server.
Why this research is important
If you want phones and drones to understand and display the 3D world in real time—think AR filters that stick perfectly to objects, robots that dodge obstacles, or handheld apps that explore rooms—speed and privacy matter. Running 3DGS fully on the device:
- Protects data (no need to send camera views to the cloud).
- Works even without internet.
- Responds quickly enough for interactive experiences.
By redesigning sorting and data layout for the way mobile GPUs actually work, this paper shows a practical path to real‑time 3D scene reconstruction on everyday devices. It’s a step toward more capable, responsive AR/VR, robotics, and autonomous systems right in your pocket.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, focusing on concrete issues future researchers could address:
- Device generality and portability
- How robust is the approach across diverse mobile GPUs (Adreno, Mali, PowerVR/IMG, Apple) with different texture tiling/swizzling, cache sizes, and replacement policies?
- Can the method automatically adapt (auto-tune) to unknown or changing cache block sizes and texture layouts without per-device offline profiling?
- Texture-cache cost model validity
- The cross-block stride–based ML model is trained on microbenchmarks; does it generalize to different kernels, access patterns, and devices beyond the tested ones?
- Lack of validation against ground-truth hardware counters or hardware disclosures; how accurate is the assumed block size b and the “minimum miss” bound in practice?
- No reported overhead and methodology for per-device calibration (data volume, time, required tooling).
- 32-bit key normalization correctness and limits
- Formal guarantees are missing for the 64-bit→32-bit key conversion (e.g., stability, absence of collisions, ordering correctness) when packing 20-bit tile IDs and normalized depth.
- What are the failure modes for extreme cases (e.g., very large tile counts, high scene depth dynamic range, or pathological distributions)?
- Reproducibility: how are ties handled (bitonic networks are not stable), and does float-based ordering introduce nondeterminism across devices or drivers?
- Algorithmic scope and alternatives
- Only bitonic-network–style sorting was explored; how do domain-specific designs (e.g., two-phase “bucket by tile, then per-tile segmented sort” using local memory) or hybrid/radix approaches compare on mobile GPUs?
- Could more aggressive stage fusion (beyond the last two steps) or per-tile/shared-memory sorting reduce kernel-launch and memory-traffic overheads further?
- No evaluation of incremental/temporal reuse (exploiting inter-frame coherence) to avoid full resorting every frame.
- Kernel launch and scheduling overheads
- The number of kernels is O(log2 n); launch overheads and synchronization costs on mobile GPUs are not profiled or optimized beyond limited fusion.
- Pipeline overlap (asynchronous compute/raster passes) and concurrent stage scheduling remain unexplored.
- Data layout and precision choices
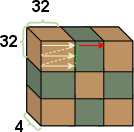
- The chosen 32×32 sorted-data block and 3×4 SH block layouts are empirically motivated; no sensitivity study across devices, scenes, or cache block sizes.
- The impact of using FP16/INT formats for SH, covariance, and intermediate buffers (bandwidth/energy vs. accuracy) is not evaluated.
- Quantization trade-offs and error propagation (e.g., from packing/grouping) on final image quality are not measured.
- End-to-end latency and real-time guarantees
- Absolute latencies vs. application-level budgets (e.g., 20 ms for AR/robotics) are not reported; it is unclear under which scene sizes and device classes real-time is achieved.
- Sustained-performance behavior (thermal throttling over long sessions) and responsiveness under mobile power/thermal constraints are unmeasured.
- Energy and thermal characterization
- No energy-per-frame, power draw, or thermal analysis; speedups may not translate to acceptable battery life and sustained performance on mobile devices.
- Memory usage and scalability
- While variable packing saves up to 1.6× memory, worst-case duplication (large anisotropic Gaussians crossing many tiles) and overall memory blow-up are not bounded or mitigated.
- Out-of-core/streaming strategies for scenes exceeding available unified memory are not discussed.
- Allocation, fragmentation, and buffer reuse policies under tight memory budgets are unspecified.
- Rendering quality and correctness
- Effects of reordering (due to key normalization or non-stable sort) on alpha compositing, transparency, and occlusion are not quantitatively assessed.
- No analysis of visual artifacts in challenging scenes (high overlap, deep layers, or very shallow depth differences).
- Tile size and tiling policy
- Tile size is fixed at 16×16; the trade-off between tile size, duplication rate, locality, and sorting cost is not explored. Is there a device- or scene-adaptive tile size that performs better?
- SIMD restructuring in rendering
- The four-pixels-per-thread design assumes beneficial SIMD width and coherence; portability to devices with different vector widths and impacts on divergence, occupancy, and register pressure are not analyzed.
- No ablation isolating the gains and potential downsides (e.g., load imbalance for sparsely covered tiles).
- API and implementation details
- The specific GPU API (Vulkan/GL ES/Metal/Compute) and its implications for barriers, memory visibility, and texture cache behavior are not detailed; portability across APIs remains unclear.
- Framebuffer-to-texture copies and render-pass transitions can be costly on tile-based GPUs; these overheads are not quantified or optimized.
- Integration with broader 3DGS/AR pipelines
- On-device 3DGS training/optimization (not just rendering) is out of scope; feasibility and bottlenecks for full on-device pipelines are unknown.
- Integration with tracking/SLAM and camera pose estimation for real-time AR is not evaluated; dataflow and latency budgets across modules are missing.
- Robustness under extreme scene statistics
- Performance and correctness under extreme overlap, highly non-uniform Gaussian sizes, or adversarial depth distributions are not characterized.
- Error handling and fallback strategies (e.g., when tile counts exceed 20-bit packing or memory budgets) are not described.
- Reproducibility and baselines
- GPUTeraSort re-implementation details and potential deviations from the original are not fully disclosed; baseline fairness and completeness are uncertain.
- Code, microbenchmark generator, and auto-tuning artifacts are not explicitly released, hindering independent verification.
- Theoretical analysis vs. measured behavior
- The memory-access count formulas and “near-minimum miss” claims are not corroborated with instruction-level traces or hardware events; the compute overhead of index transformations and its impact on occupancy is not quantified.
- Compatibility with texture compression/tiling schemes
- Mobile GPUs often employ proprietary texture tiling and compression (e.g., AFBC); interactions with these schemes and their effect on access patterns are not studied.
- Stability and determinism
- Deterministic rendering across runs and devices (important for testing and safety-critical applications) is not addressed given the float-based keys and non-stable sorting network.
These gaps suggest concrete avenues for future work, including per-device auto-tuning and validation, formal correctness analysis of key normalization, exploration of alternative sorting paradigms and per-tile strategies, energy/thermal profiling, adaptive tiling, and end-to-end integration and validation in real-time AR/robotics scenarios.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s texture-cache–optimized sorting, variable packing/layout, and mobile-optimized 3D Gaussian Splatting (3DGS) pipeline. Each item includes sector alignment and feasibility notes.
- Mobile AR scene reconstruction SDK for app developers (software, AR/VR)
- What: A drop-in SDK that replaces existing mobile 3DGS sort/render stages with the paper’s texture-cache–aware pipeline to get 1.7× end-to-end speedups and up to 1.6× memory savings on Adreno/Mali devices.
- Where: Integrate with ARCore/ARKit pipelines to accelerate mapping and occlusion, improve latency in AR shopping, home design, and museum guides.
- Assumptions/Dependencies: Access to mobile GPU compute APIs (Vulkan/OpenGL ES/Metal), devices with 2D texture caches; key normalization is acceptable (32-bit float format); multi-view images or precomputed Gaussian primitives available.
- On-device 3D capture in consumer apps with reduced cloud reliance (software, e-commerce, daily life)
- What: Faster, privacy-preserving 3D scans of rooms or objects on phones (e.g., listing properties, insurance claims, furniture placement) using the optimized 3DGS pipeline.
- Where: Real estate virtual tours, product visualization, DIY home planning apps.
- Assumptions/Dependencies: Sufficient device GPU; acceptable reconstruction quality with optimized sorting and data packing; device storage for Gaussian primitives.
- Real-time drone navigation and obstacle avoidance with local 3D reconstruction (robotics)
- What: Lower-latency scene reconstruction on edge (on-board phones/tablets/controllers) using the proposed pipeline to meet ~20 ms latency budgets for critical path tasks.
- Where: Autonomous drones in warehouses, agriculture, inspection.
- Assumptions/Dependencies: Stable camera calibration and synchronized frames; controlled scene complexity to fit device memory; texture-cache behavior comparable to profiled devices.
- Mobile game engines with dynamic occlusion and photorealistic environments (software, gaming)
- What: Plug the optimized sorting/rendering stages into game engines to enable fast compositing and transparency handling via 3DGS for dynamic scenes on mobile GPUs.
- Where: AR games, mixed-reality experiences, mobile titles needing high-fidelity occlusion.
- Assumptions/Dependencies: Engine support for custom render passes; scenes represented by Gaussian primitives; 2.5D texture cache benefits on target GPUs.
- Field inspection and emergency response mapping without connectivity (public sector, policy, daily life)
- What: On-device 3D scene capture and reconstruction for first responders and inspectors, reducing data transmission and enabling offline operation.
- Where: Disaster assessment, building inspections, cultural heritage documentation.
- Assumptions/Dependencies: Trained operators; device battery and thermal constraints; acceptance of on-device processing for sensitive environments; compatibility with agency data retention policies.
- Academic benchmarking and teaching: mobile texture-cache–aware GPU algorithms (academia)
- What: Use the pipeline as a teaching case and benchmark suite to study parallel sorting, 2D cache layouts, and GPU memory locality on mobile devices.
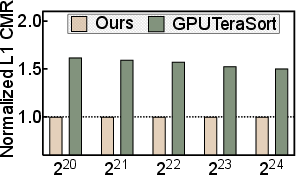
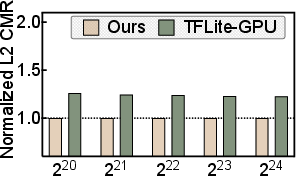
- Where: Courses in parallel computing, graphics, mobile systems; lab assignments measuring L1/L2 miss rates and latency effects.
- Assumptions/Dependencies: Access to profiling tools and supported mobile GPUs; reproducible workloads; permissions to run micro-benchmarks.
- Texture-cache–aware sorting library for mobile GPUs (software infrastructure)
- What: A standalone, general-purpose GPU sort module that replaces radix/bitonic in mobile frameworks (e.g., MNN, NCNN, TFLite backends) when keys/values fit the paper’s format.
- Where: Data-parallel workloads needing sort/group-by on mobile devices.
- Assumptions/Dependencies: Availability of 2D texture memory; key normalization constraints; integration effort with existing framework kernels.
- Energy-sensitive deployments: reduce memory traffic to extend battery life (energy, mobile platforms)
- What: Adopt variable packing and stage fusion to cut texture reads/writes and cache misses in mobile pipelines, lowering energy per frame for 3D reconstruction tasks.
- Where: Consumer apps, industrial handhelds.
- Assumptions/Dependencies: Energy gains map proportionally to reduced memory traffic; workload fits the paper’s block-wise layouts.
Long-Term Applications
These use cases require additional research, engineering, or ecosystem support to scale, generalize, or standardize the techniques.
- Full on-device 3DGS training and incremental mapping (robotics, AR/VR, software)
- What: Extend the pipeline from fast rendering/reconstruction to on-device training/updating of Gaussians for dynamic scenes (SLAM-like updates), minimizing cloud use.
- Why: Enables continuous, privacy-preserving mapping for AR cloud alternatives and robotic autonomy.
- Dependencies: Efficient on-device optimization routines; memory/thermal management; robust key normalization across dynamic depth ranges; cross-scene generalization.
- Cross-vendor, cross-API standardization of texture-cache–aware kernels (software, hardware co-design)
- What: Define portable abstractions and compiler/runtime support for 2D-blocked memory layouts and cache-friendly index transformations across Adreno/Mali/Apple GPUs.
- Why: Make these optimizations accessible in mainstream mobile frameworks and engines with predictable performance.
- Dependencies: Vendor cooperation; profiling-guided compilers; API extensions; validation on diverse cache organizations.
- Generalization beyond sorting: texture-cache–aware primitives (software infrastructure)
- What: Apply layout and stage fusion concepts to prefix sums, merges, group-by, and rasterization steps (e.g., alpha blending) for end-to-end acceleration.
- Why: Build a coherent mobile GPU library where all hot kernels exploit 2D locality.
- Dependencies: Formal cost models validated across devices; kernel-by-kernel redesign; support for different data types and precision.
- Multi-user, large-scale AR with shared on-device maps (AR/VR, networking)
- What: Combine fast local reconstruction with peer-to-peer synchronization to host shared AR experiences without cloud services.
- Why: Reduce latency and privacy risks while scaling scene complexity via distributed devices.
- Dependencies: Efficient map merging; consistency protocols; device-to-device networking; conflict resolution and security.
- Privacy-first policies for edge 3D perception (policy)
- What: Draft guidelines and compliance frameworks encouraging on-device 3D reconstruction for sensitive spaces (healthcare facilities, schools) to limit data exfiltration.
- Why: Align with GDPR/CCPA goals while maintaining functionality.
- Dependencies: Standardized audit trails; device certification; lifecycle management of local 3D data.
- Insurance and claims automation with mobile 3D reconstruction (finance, insurance)
- What: Use on-device 3D capture to document incidents (home/car damage) and auto-generate claim models with reduced adjuster site visits.
- Why: Speed, cost savings, improved customer experience.
- Dependencies: Integration with insurer workflows; accuracy thresholds; fraud detection; regulatory approval.
- Digital twins on mobile for facilities and smart cities (energy, infrastructure)
- What: Maintain lightweight, frequently updated 3D models of buildings or public spaces via mobile teams using the optimized pipeline.
- Why: Support maintenance, energy audits, crowd management, and accessibility planning.
- Dependencies: Scalable scene management; versioning; interoperability with BIM systems; training for operators.
- Texture-cache profiling tools and predictive scheduling (academia, tooling)
- What: Develop general micro-benchmark–based profilers and ML models to predict cache behavior, guide kernel scheduling and layout choices automatically.
- Why: Reduce developer burden; optimize per-device deployments.
- Dependencies: Standardized data collection; on-device ML inference for scheduling; integration into build systems and runtimes.
- Hardware/driver co-design for 3DGS (hardware vendors, software)
- What: Work with GPU vendors to expose texture-cache metadata and specialized instructions for frequent 3DGS patterns (compare-and-swap, index transforms).
- Why: Improve determinism and throughput beyond software-only optimization.
- Dependencies: Vendor APIs; backward compatibility; security implications; ecosystem buy-in.
- Healthcare fittings and orthotics via mobile 3D capture (healthcare)
- What: Capture patient-specific 3D geometry in clinics using phones/tablets to design orthotics or prosthetics with minimal cloud processing.
- Why: Faster turnarounds and better privacy.
- Dependencies: Clinical validation; device sterilization protocols; integration with CAD/CAM; quality control across diverse anatomies.
Notes on feasibility across applications:
- Gains depend on mobile GPU texture-cache behavior (2.5D blocks and read-only caches). Results may vary across vendors and models.
- The pipeline assumes multi-view input and accurate camera parameters; dynamic scenes and poor lighting degrade results without additional modeling.
- Key normalization (32-bit float with tile-depth packing) must preserve ordering and precision ranges for specific workloads; extreme depth ranges may require tuning.
- Thermal throttling and battery constraints on mobile devices can limit sustained performance; workload management and frame scheduling are necessary for long sessions.
- Memory reductions (up to 1.6×) and sorting speedups (up to 4.1×) are empirically validated on tested devices; careful validation is needed before broad deployment.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example from the text.
- 2.5D texture memory: A texture memory model on mobile GPUs with 2D spatial locality where each texel is a 4-component vector, accessed via a read-only cache. "mobile GPUs primarily employ a 2.5D texture memory, with a corresponding read-only cache"
- 2D texture cache: A cache optimized for two-dimensional spatial locality of texture fetches on GPUs. "optimizing for the two-dimensional (2D) texture cache"
- 3D Gaussian Splatting (3DGS): A scene representation that uses learnable 3D Gaussian primitives projected to 2D for efficient, parallel rendering. "3D Gaussian Splatting (3DGS) represents a paradigm shift in scene representation."
- Alpha blending: A compositing method that combines colors based on per-pixel opacity. "through a step called {\em alpha blending}"
- Anisotropic spread: Direction-dependent variance of a Gaussian’s extent, encoded by its covariance. "covariance (defining anisotropic spread)"
- Axis-aligned bounding box (AABB): A rectangle aligned with the axes that bounds a projected primitive. "Each projected 2D Gaussian ellipse is represented by an axis-aligned bounding box (AABB)."
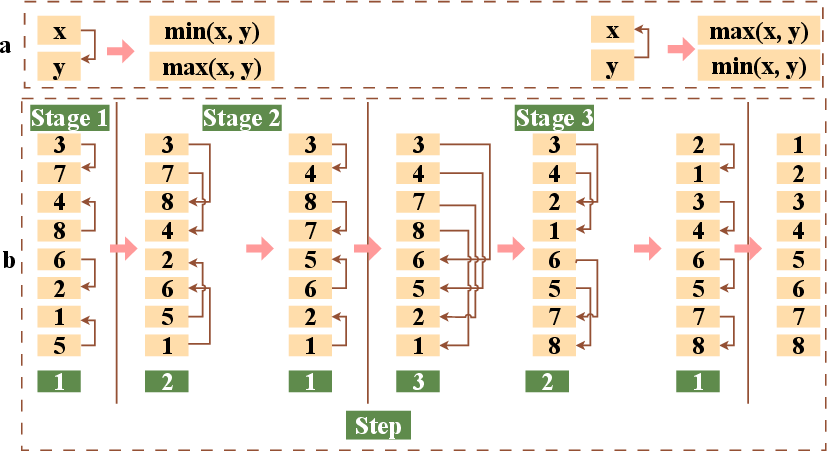
- Bitonic sorting network: A parallel sorting network that merges bitonic sequences through structured compare-and-swap stages. "Bitonic sorting network illustration"
- Compare-and-swap (in sorting networks): An operation that compares two elements and swaps them if out of order. "Compare and swap within the Quads of size "
- Cost model (for the texture cache): An analytical or empirical model to predict performance based on cache-aware access patterns. "a cost model for the texture cache."
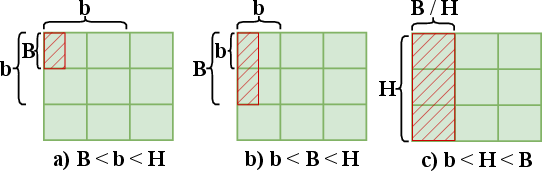
- Cross-block stride: A 2D access stride that crosses cache block boundaries, affecting miss rate. "The concept of {\em cross-block stride} is introduced --"
- Differentiable affine transformations: Linear transformations with translation that are differentiable, enabling learning-based projection. "project Gaussian kernels onto the image plane through differentiable affine transformations."
- Frustum culling: Removing objects outside the camera frustum before rendering to save computation. "A step called {\em Frustum culling} eliminates Gaussians outside the camera view."
- GPUTeraSort: A GPU-based sorting approach leveraging texture memory and PBSN for large key-value datasets. "GPUTeraSort leveraged Dowdâs Periodic Balanced Sorting Network (PBSN)~\cite{pbsn} to achieve improved memory usage while sorting large key-value datasets."
- Hilbert (space-filling curve order): A spatial storage order that preserves locality for 2D textures. "storage order (e.g., row-major, column-major, zigzag, or Hilbert)."
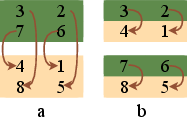
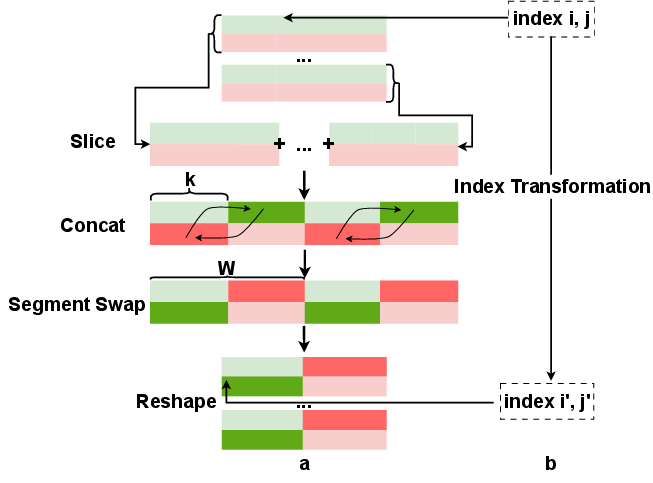
- Index transformation: Recomputing indices to achieve a desired memory layout without extra data movement. "we apply an index transformation at every sorting step."
- Kernel (GPU kernel): A GPU function executed by many threads in parallel. "Each of these quads is processed in a separate kernel to achieve parallelism."
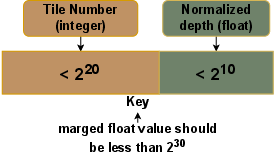
- Key normalization: Mapping wide (e.g., 64-bit) sort keys into a narrower representation (e.g., 32-bit float) while preserving order semantics. "we implement {\em key normalization}, which converts the 64-bit integer key for 3DGS to a 32-bit floating point number."
- L1 texture cache: The first-level cache backing texture fetches, optimized for 2D spatial locality. "align with the 2D spatial locality of the L1 texture cache."
- LPDDR5/X: A low-power mobile DRAM standard with limited bandwidth compared to desktop memory systems. "narrow LPDDR5/X buses (< 50 GB/s bandwidth)"
- Layout transformation: Reorganizing data in memory to place comparison partners adjacently for cache efficiency. "Layout Transformation."
- Local work group: A set of GPU threads that cooperate on a subproblem (e.g., a tile) in parallel compute. "each local work group processes a tile"
- Multi-view stereo (MVS): A class of methods that reconstruct 3D geometry from multiple images. "multi-view stereo (MVS)~\cite{furukawa2015multi,kar2017learning,yao2018mvsnet,chen2019point}"
- Neural Radiance Fields (NeRF): An implicit neural representation that models view-dependent color and density for 3D scenes. "particularly the Neural Radiance Fields (NeRF) introduced by Mildenhall et al. \cite{mildenhall2020nerf}."
- Novel view synthesis (NVS): Generating unseen views of a scene from a set of input images. "novel view synthesis (NVS) models"
- Occlusion: The blocking of objects by others closer to the camera, requiring correct depth ordering. "ensure correct rendering order for transparency and occlusion."
- Periodic Balanced Sorting Network (PBSN): A sorting network variant used to improve memory behavior on GPUs. "Dowdâs Periodic Balanced Sorting Network (PBSN)"
- Pointer-chasing benchmarking: A latency-measurement method using dependent memory accesses to emulate random access patterns. "inspired by pointer-chasing benchmarking~\cite{volkov2008benchmarking}"
- Quad size (sorting network mapping): The logical block size used to pair elements for compare-and-swap in a texture-mapped sorting stage. "The key concept here is the {\em quad size}--specifically, in {\em compare and swap} using a quad of size "
- Radix sorting: A non-comparative sorting algorithm that organizes keys by digits/bits. "featuring efficient radix sorting and rendering."
- Rasterization (GPU rasterization): Converting scene geometry or splats into pixel values on the image plane. "leverages GPU rasterization for efficient, high-quality, real-time rendering of complex scenes."
- SIMD: Single Instruction, Multiple Data; executing the same operation over multiple data elements in parallel. "utilizing SIMD operations."
- Spherical harmonics: Orthogonal basis functions on the sphere used to model view-dependent color properties. "spherical harmonics"
- Splatting operations: Rendering technique that projects and blends primitive footprints (e.g., Gaussians) onto the image plane. "Splatting operations such as sorting are inherently memory-intensive"
- Stage fusion: Combining multiple sorting stages or steps into a single kernel to reduce memory traffic. "Stage Fusion."
- Texture point (texel vector): A texture element treated as a vector of fixed length (often 4 channels) in texture memory. "each {\em texture element} (also called a {\em texture point}) is actually a vector of length 4."
- Texture representation: The data-unit, layout, and storage order used to store 2D texture data in memory. "Texture representation refers to how 2D texture data is stored in memory"
- Tile-based rendering: A rendering approach that partitions the image into tiles to improve locality. "Mobile GPUs are better suited for tile-based rendering"
- Tile identifier: A unique index for a tile used to group and sort per-tile primitives. "indexed by a combination of the tile identifier and Gaussian depth"
- Unified memory hierarchy: A shared memory system for CPU/GPU that lacks discrete on-chip shared memory tiers typical of desktop GPUs. "the limited unified memory hierarchy in mobile GPUs intensifies contention during rasterization of overlapping Gaussians."
- View-dependent spherical harmonic color coefficients: SH coefficients that model how color changes with viewing direction. "view-dependent spherical harmonic color coefficients"
Collections
Sign up for free to add this paper to one or more collections.