FlashMem: Supporting Modern DNN Workloads on Mobile with GPU Memory Hierarchy Optimizations
Abstract: The increasing size and complexity of modern deep neural networks (DNNs) pose significant challenges for on-device inference on mobile GPUs, with limited memory and computational resources. Existing DNN acceleration frameworks primarily deploy a weight preloading strategy, where all model parameters are loaded into memory before execution on mobile GPUs. We posit that this approach is not adequate for modern DNN workloads that comprise very large model(s) and possibly execution of several distinct models in succession. In this work, we introduce FlashMem, a memory streaming framework designed to efficiently execute large-scale modern DNNs and multi-DNN workloads while minimizing memory consumption and reducing inference latency. Instead of fully preloading weights, FlashMem statically determines model loading schedules and dynamically streams them on demand, leveraging 2.5D texture memory to minimize data transformations and improve execution efficiency. Experimental results on 11 models demonstrate that FlashMem achieves 2.0x to 8.4x memory reduction and 1.7x to 75.0x speedup compared to existing frameworks, enabling efficient execution of large-scale models and multi-DNN support on resource-constrained mobile GPUs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making big AI models (like those used for image, speech, and text) run well on phones and tablets. Phones don’t have a lot of memory, and their graphics chips (mobile GPUs) work differently from laptop/desktop GPUs. The authors built a system called FlashMem that lets a phone run large or multiple AI models quickly without running out of memory.
Think of it like this: instead of trying to fit an entire library of books into a small backpack (preloading a whole model), FlashMem brings only the pages you need right when you need them (streaming parts of the model), and it organizes them so they’re easy to read fast.
What questions were the researchers trying to answer?
They focused on a few simple questions:
- How can we run very large AI models on phones without using too much memory?
- How can we run several different models one after another (like a pipeline) without wasting time loading and reformatting data each time?
- Can we load model data in small pieces while the GPU is still computing, so there’s less waiting?
- How can we use the phone GPU’s special “texture memory” (a kind of 2D-friendly memory) to work faster and avoid extra conversions?
How did they do it? (Methods explained simply)
To make this work, the authors combined smart scheduling, memory-aware planning, and GPU-friendly code. Here’s the big picture in everyday terms:
- Streaming instead of preloading:
- Most mobile AI frameworks load the entire model into memory first (“preload”), which is fast later but uses a lot of memory.
- FlashMem “streams” only the parts (weights) needed for the next steps, like bringing ingredients to the kitchen just in time for each recipe step.
- Use the GPU’s favorite shelf (texture memory):
- Mobile GPUs have a special memory area that likes 2D tiled data (called “2.5D texture memory”)—it lets the GPU read data quickly.
- FlashMem rearranges weights into small tiles that fit this shelf well, so the GPU needs fewer conversions and runs faster.
- Plan when to bring each piece (Overlap Plan Generation, OPG):
- The system splits each big weight into small chunks and makes a plan for when each chunk should be loaded.
- They use a solver (Google OR-Tools CP-SAT) to find a good plan that:
- Keeps memory use under limits.
- Ensures chunks arrive before they’re needed.
- Avoids overloading any step with too much extra loading.
- Think of this solver like a puzzle-solver that schedules who carries which pages of a book to class and when, so no one is overloaded and the teacher always has the right page on time.
- Know each step’s “load capacity”:
- Not all operations (layers) are equal. Some can handle extra loading while they compute; others slow down a lot if you do that.
- The authors measured and learned how much extra loading each type of layer can tolerate (their “load capacity”). For example:
- Simple operations (like ReLU or Add) can usually handle a lot.
- Big matrix multiplies (like MatMul or Conv) can handle a fair amount.
- Steps like LayerNorm or Softmax don’t like extra loading much.
- They trained a small predictive model to estimate this, so the plan stays fast.
- Adjust “fusion” when needed:
- Frameworks often “fuse” several steps into one to go faster. But if you fuse too much, you lose places where loading and computing can overlap.
- FlashMem can “unfuse” certain parts when necessary to create more chances to load in the background without slowing things down.
- Rewrite GPU code to pipeline cleanly:
- They rewrite kernels (the small GPU programs) so that each loop does:
- 1) Prefetch the next chunk of data,
- 2) Compute with the current chunk,
- 3) Repeat—without messy “if” checks that split the GPU’s attention.
- This keeps all GPU threads doing the same thing, avoiding slowdowns.
- Do the heavy planning offline:
- The scheduling plan is computed before the app runs (offline), so during actual use the phone just follows the plan with no extra planning cost.
What did they find, and why does it matter?
The team tested FlashMem on 11 popular models (covering text, images, audio) and found:
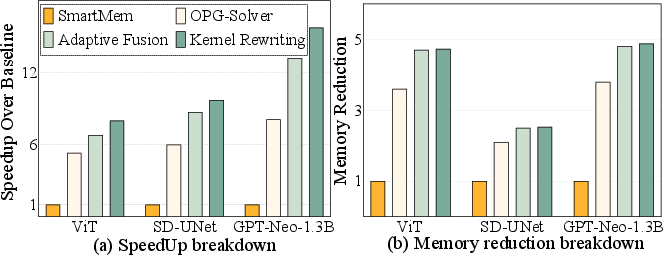
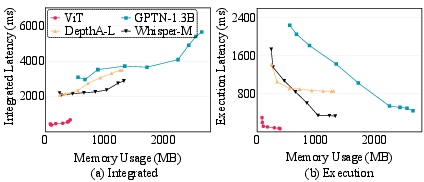
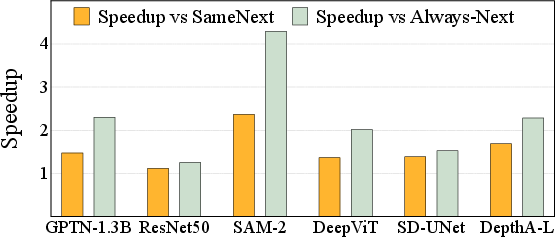
- Much lower memory use: 2.0× to 8.4× less memory on average (and up to about 10× for some models).
- Big speedups: 1.7× to 75× faster compared to several existing mobile frameworks.
- Compared to a strong recent system (SmartMem), FlashMem was on average 8.6× faster on the tested cases, with even larger gains for some big models (like GPT-Neo 1.3B and Stable Diffusion’s UNet).
Why this matters:
- It becomes possible to run bigger AI models on phones without crashing or slowing down.
- Apps that chain multiple AI models (like speech-to-text → image generation) can run more smoothly on the device.
- Less time is wasted converting and reloading data between models.
What’s the impact?
- Better on-device AI: Apps can keep your data private (no cloud needed), respond faster, and run more advanced features.
- More complex tasks on phones: Developers can use larger models and connect multiple models in a pipeline without blowing past memory limits.
- Energy and user experience: Faster processing and less memory pressure can improve battery life and overall responsiveness.
In short, FlashMem gives phones a “smart packing and delivery system” for AI model data—bringing the right pieces at the right time, in the right shape—so modern AI can run efficiently on small devices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item identifies a concrete direction future researchers could pursue.
- Scope limited to FIFO-style, sequential multi-DNN execution; no support or evaluation for preemptive scheduling, co-running models, or concurrent multi-tenant workloads on mobile GPUs.
- No cross-model caching strategy: transformed (2.5D) weights are not reused across models or across sessions; feasibility, storage overhead, eviction, and consistency of a cross-model texture cache remain unexplored.
- Portability constraints: design and optimizations target Adreno/Mali texture-memory GPUs; compatibility with Apple (Metal), PowerVR, older GPUs, or heterogeneous accelerators (DSPs/NPUs) is unaddressed.
- CP-SAT solver scalability and optimality: solutions often “feasible” under a 150s limit without optimality guarantees; no bounds on suboptimality, worst-case runtime, or mechanisms for online re-optimization under runtime variability.
- Dynamic neural networks left for future work: handling runtime-dependent control flow, variable sequence lengths (e.g., LLMs), and dynamic attention spans remains unresolved.
- Load capacity prediction (XGBoost) lacks validation: dataset composition, device/operator generalization, prediction accuracy, and calibration across driver versions and kernels are not reported.
- Heuristic thresholds (0%/20%/300% added load tolerance) are ad hoc; a principled method to derive, validate, and adapt these thresholds per device/operator is missing.
- Uniform chunk size S is assumed; no method to select or adapt S per operator/model/device, nor analysis of its impact on cache behavior, bandwidth, and scheduling flexibility.
- Fusion splitting policy is heuristic: criteria to choose α, guarantees of numerical equivalence, impact on vendor-tuned fused kernels, and automated detection of safe fusion boundaries are not formalized.
- Template-based kernel rewriting coverage: unclear whether all operator types and fused variants are supported across APIs (OpenCL/Vulkan/Metal) and driver versions; portability, maintenance cost, and correctness testing are not detailed.
- Offline 2.5D pre-tiling on disk: integration with standard model formats (ONNX/TFLite), conversion time, storage overhead, and deployment tooling changes (including backward compatibility and versioning) are not evaluated.
- Compression/encryption pipeline: how streaming interacts with compressed or encrypted model weights (decompression, integrity checks, secure storage) and its overhead is not studied.
- Precision/quantization support: behavior with INT8/FP16/BF16, mixed precision, and calibration accuracy under texture layout transformations remains unexplored.
- Energy and thermal behavior: methodology, device states, and sustained performance under thermal throttling and battery constraints are not reported despite energy claims in evaluation goals.
- I/O path assumptions: feasibility and effectiveness of overlapping flash storage I/O with GPU compute under mobile OS scheduling, filesystem encryption, and contention from other apps is not quantified.
- OS-level memory management: robustness under memory pressure, fragmentation, texture object limits, frequent image creation/destruction, and allocator behavior is not characterized.
- Cross-model pipeline scheduling: opportunities to prefetch the next model, share intermediate buffers, or overlap end-of-model compute with next-model loads to minimize pipeline latency are not explored.
- Evaluation coverage gaps: no experiments on repeated inferences of the same model (where full preloading could amortize costs), small models, varying batch sizes, or LLM sequence-length sensitivity.
- Correctness verification: numerical parity across fused/unfused graphs and rewritten kernels (tolerances, determinism) lacks a systematic validation framework.
- Fail-safe behavior: guarantees when solver/heuristics cannot meet constraints (deadline misses, graceful degradation), and bounds on additional latency under overload are not provided.
- Vendor-specific interactions: effects of pipeline barriers, cache policies, tiling differences (Adreno vs Mali), and automatic GWS/LWS tuning at runtime are not systematically studied.
- Heterogeneous scheduling: strategies to partition operators across GPU/NPU/CPU to optimize overlap and memory footprint are not addressed.
- Persistent caching across sessions: policies for keeping transformed weights on disk/texture across app runs (eviction, versioning, space management, model updates) are not defined.
- Formal analysis missing: no theoretical bounds connecting memory reduction to latency overhead, no convergence guarantees for fallback strategies, and no sensitivity analysis for key hyperparameters (λ, M_peak, α).
Practical Applications
Immediate Applications
These applications can be built or integrated today by leveraging FlashMem’s weight streaming, CP-SAT–based overlap planning, 2.5D texture-memory layouts, and branch-free, pipelined kernels on current mobile GPUs (e.g., Adreno, Mali).
- On-device multimodal assistants (LLM + vision + ASR) with tight memory budgets
- Sectors: software, consumer mobile, education, accessibility
- What to deploy: offline chat/summarization (e.g., GPT-Neo–class), speech recognition (Whisper), and image tasks (e.g., ViT/SD-UNet) chained in one session without exceeding RAM
- Workflow/tools: model converter that tiles weights into 2.5D; offline OR-Tools LC-OPG solver to generate schedules; integration as a backend for ExecuTorch/TFLite/MNN; kernel templates with pipelined weight loading
- Assumptions/dependencies: Android/Vulkan/OpenCL access to texture memory; per-model offline planning; storage bandwidth sufficient for streaming; developer ability to adopt FlashMem kernels/runtime
- Camera and AR pipelines that co-run multiple DNNs sequentially (encoder → detector → segmenter)
- Sectors: mobile imaging, AR/VR, social media
- What to deploy: FIFO multi-model execution that streams weights on demand to minimize peak memory and hide load/transformation latency
- Workflow/tools: pipeline-aware scheduler using LC-OPG output; per-operator capacity profiles (XGBoost predictor) to decide load overlap; adaptive fusion/unfusion of fused ops where needed
- Assumptions/dependencies: predictable FIFO-style invocation (non-preemptive); model graphs available for lowering and kernel templating
- Privacy-preserving on-device translation (ASR → NMT → TTS) without cloud round-trips
- Sectors: healthcare, government, travel, accessibility
- What to deploy: chained speech-to-text and text-to-speech with reduced init/transform overhead between models
- Workflow/tools: integrated runtime that treats init+exec holistically; 2.5D-optimized weight storage; branch-free kernels to overlap streaming and compute
- Assumptions/dependencies: adequate flash I/O; app permissions for sustained background compute; per-model schedules generated offline
- Mobile photo/video editing with multi-stage AI filters (denoise → relight → segment → stylize)
- Sectors: creator tools, social apps, imaging
- What to deploy: multi-DNN effects with lower latency spikes and 2–8× lower memory use during edits/exports
- Workflow/tools: FlashMem backend for effect chains; tiled-weight packages per model; per-layer capacity thresholds to preserve interactivity
- Assumptions/dependencies: device GPU supports 2D textures and concurrent queues; careful QoS to preserve UI responsiveness
- Edge robotics and drones with sequential perception stacks on phones/tablets (or phone-class SoCs)
- Sectors: robotics, drones, industrial inspection
- What to deploy: object detection → tracking → depth/SLAM with streaming weights to fit complex stacks on limited RAM
- Workflow/tools: ROS2 nodes using FlashMem kernels; LC-OPG schedules embedded in model artifacts; per-device capacity profiles
- Assumptions/dependencies: stable power/thermal envelope; model graphs amenable to kernel templating
- Wearables/AR glasses running on-device segmentation and detection with lower battery drain
- Sectors: wearables, AR, fitness
- What to deploy: memory-aware inference that reduces texture-transform overhead and peak usage, improving responsiveness and battery life
- Workflow/tools: pre-tiled weights; small-chunk streaming plans; branch-free kernels to avoid divergence on small GPUs
- Assumptions/dependencies: strict thermal constraints; storage bandwidth variability across SKUs
- Mobile KYC/fintech flows: multimodel ID verification (OCR → face match → liveness) on device
- Sectors: finance, eKYC, payments
- What to deploy: faster, more private, multi-step verification without large memory spikes
- Workflow/tools: per-model 2.5D packages; LC-OPG scheduler embedded in the app; adaptive unfusion to recover overlap capacity if fused graphs block streaming
- Assumptions/dependencies: compliance with on-device processing policies; secure model packaging
- OEM/system AI services that host multiple app models sequentially (system keyboard, camera, gallery)
- Sectors: mobile OEMs, OS vendors
- What to deploy: system-wide inference service with FlashMem backend to reduce memory pressure and init latency across app-invoked models
- Workflow/tools: OS service integrating FIFO queues and LC-OPG plans; dev tooling to convert app models to 2.5D tiled artifacts
- Assumptions/dependencies: platform APIs for texture access; cross-app scheduling policies; device-specific profiling
- Academic reproduction and research on memory-aware scheduling and kernel codegen
- Sectors: academia (systems, ML compilers)
- What to deploy: experiments on LC-OPG (CP-SAT via OR-Tools), per-operator capacity modeling (XGBoost), and adaptive fusion strategies on standard mobile benchmarks
- Workflow/tools: open-source planner and kernel templates; datasets of operator profiles; integration with TVM/MLC-LLM/ExecuTorch
- Assumptions/dependencies: access to target devices (Adreno/Mali), profiling harnesses, solver time budget (~seconds–minutes per model)
- Developer CI/CD for memory-optimized mobile AI deployments
- Sectors: software engineering, DevOps
- What to deploy: build-step that tiles weights, profiles per-operator capacity, generates LC-OPG schedules, and validates peak memory budgets before release
- Workflow/tools: converter + profiler + OR-Tools planner + kernel templater; device-farm checks across vendor GPUs
- Assumptions/dependencies: reproducible device profiling; per-ABI kernel builds; versioning of schedules per model variant
Long-Term Applications
These opportunities require further research, hardware/OS support, or broader ecosystem adoption before wide deployment.
- Preemptive, multi-tenant mobile AI scheduling with overlap-aware interruption/resume
- Sectors: OS vendors, mobile platforms, productivity suites
- What to build: runtime that can preempt and resume weight streaming and compute with QoS targets across many apps
- Dependencies: OS/kernel support (timeline semaphores, GPU scheduling), persistent state checkpoints for streaming plans, fairness policies
- Dynamic/conditional model support (mixture-of-experts, runtime control flow) in overlap planning
- Sectors: LLMs, advanced vision, research platforms
- What to build: LC-OPG extensions that account for branching graphs and runtime-dependent operator activation
- Dependencies: online capacity estimation, fast re-planning, hardware counters for feedback; hybrid CP-SAT/heuristic solvers
- Standardized 2.5D texture-aware weight formats for model distribution
- Sectors: model hubs, toolchains (PyTorch/TVM/ONNX), app stores
- What to build: cross-vendor, texture-aware serialized formats to avoid repeated on-device layout conversion
- Dependencies: buy-in from framework maintainers and GPU vendors; backward compatibility tooling; format versioning
- Hardware/OS co-design for direct flash-to-texture DMA and decompression-in-texture
- Sectors: semiconductor, mobile SoC vendors
- What to build: SoC support for bypassing unified memory copies and hardware units to decode/transpose into 2.5D texture layouts
- Dependencies: driver/runtime changes; security/permission models for DMA; coordination with Vulkan/OpenCL/Metal APIs
- Heterogeneous acceleration: extend streaming and overlap to NPUs/ISPs with unified scheduling
- Sectors: mobile silicon, edge AI
- What to build: cross-accelerator memory and schedule planner that targets GPU+NPU pipelines with consistent overlap semantics
- Dependencies: vendor NPU APIs exposing memory hierarchy and transfer queues; unified IR and kernel templates
- Adaptive, learning-based capacity prediction and schedule optimization
- Sectors: compilers, AutoML/auto-tuning
- What to build: online models (RL/BO) to continuously refine per-operator load capacity and chunking for each device and OS version
- Dependencies: low-overhead telemetry; safe exploration; configuration caching; integration with CI for periodic retraining
- Secure streaming of protected models (DRM, TEE integration)
- Sectors: media/DRM, enterprise, premium app vendors
- What to build: encrypted, chunked weight streaming directly into GPU/TEE with attestations and anti-tamper checks
- Dependencies: TEE↔GPU secure channels; driver support for protected textures/buffers; model rights management
- Compression-aware streaming (quantization/pruning/sparsity) with variable chunk sizing
- Sectors: model optimization, edge AI
- What to build: scheduler and kernels that exploit per-layer compression ratios and sparse layouts to minimize streamed bytes and peak memory
- Dependencies: compressed/tiled format standards; sparse-friendly kernel templates; accuracy retention studies
- Cloud-edge partitioning with overlap-aware offloading
- Sectors: telecom, cloud gaming/AI services
- What to build: split inference where edge streams only needed layers/weights while overlapping transfers with on-device compute
- Dependencies: stable low-latency connectivity; privacy policies for selective offload; partitioning compilers
- Policy and standards for privacy-by-default, energy-efficient on-device AI
- Sectors: regulators, standards bodies, OEMs
- What to build: guidance and certification that reward on-device inference with documented memory/energy savings and reduced data transfer
- Dependencies: transparent energy/memory reporting APIs; reproducible measurement protocols; OEM cooperation
- Benchmarks and competitions for multi-DNN mobile workloads with memory/latency KPIs
- Sectors: academia, industry consortia
- What to build: standardized suites that reflect FIFO multi-model patterns and report init+exec holistically
- Dependencies: shared datasets; open runtimes; cross-device baselines
Cross-cutting Assumptions and Dependencies
- Hardware/software: mobile GPUs with 2D texture memory and concurrent command queues (e.g., Adreno, Mali); access via Vulkan/OpenCL/Metal; driver stability and permissions for high-throughput transfers.
- Tooling: offline solver (Google OR-Tools CP-SAT) and profiling (XGBoost-based capacity predictor); kernel templates or codegen integrated into existing frameworks (TVM, ExecuTorch, TFLite, MNN, SmartMem).
- Model prep: per-model conversion to 2.5D tiled weight files; per-device capacity profiling; versioning of schedules per model and device class.
- Workload pattern: best-fit today for FIFO-style multi-model pipelines; preemptive and dynamic-control-flow models require further research.
- Performance variability: benefits depend on storage bandwidth, SoC memory bandwidth, thermal headroom, and driver behavior; results may vary across devices and OS versions.
Glossary
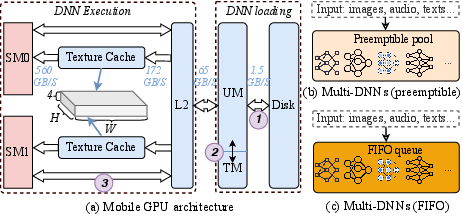
- 2.5D texture memory: A specialized GPU memory organization that arranges data into 2D tiles with limited depth to exploit spatial locality and caching. "This specialized memory organization is known as 2.5D texture memory."
- Adaptive fusion: A strategy that adjusts operator fusion to balance load capacity, memory usage, and performance. "an adaptive fusion mechanism to balance memory and performance."
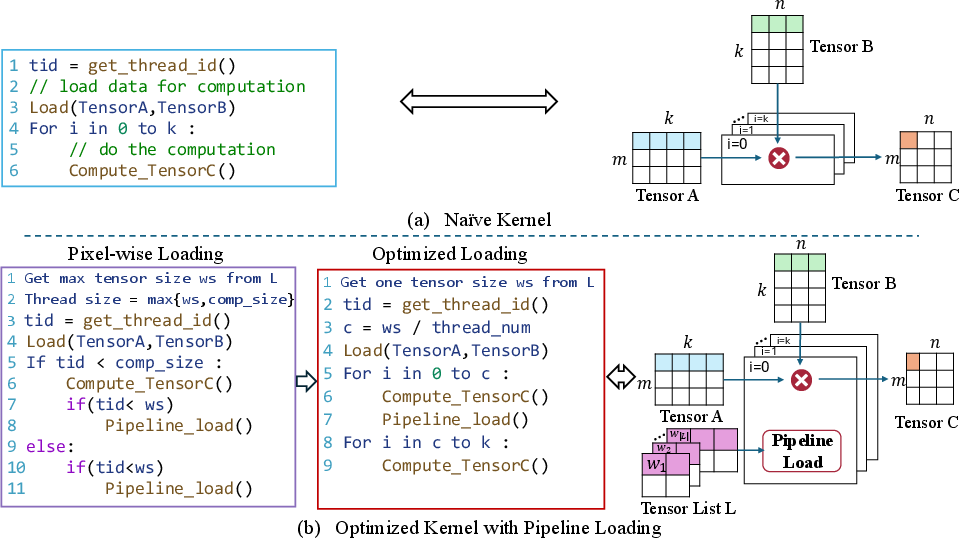
- Branch divergence: The performance penalty caused when threads in a warp follow different control-flow paths. "warp-level branch divergence"
- Command queues: GPU submission paths that allow overlapping of computation with memory transfers. "using independent command queues."
- Constraint Programming Satisfiability (CP-SAT): A constraint-based optimization formulation used for scheduling and allocation problems. "reduce it to the Constraint Programming Satisfiability (CP-SAT)~\cite{cpsatlp} problem"
- Directed acyclic graph (DAG): A graph with directed edges and no cycles, used to represent DNN operator dependencies. "A Deep Neural Network (DNN) is represented by a directed acyclic graph (DAG) "
- FIFO scheduling: A sequential scheduling approach where queued models execute one after another. "FIFO scheduling employs a sequential design where multiple models are queued and executed sequentially until all requests are fulfilled."
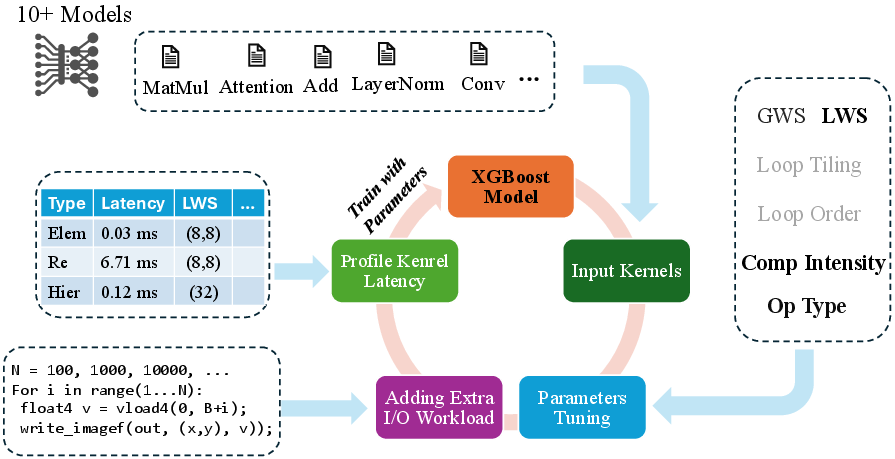
- Global Work Size (GWS): The total number of work-items launched for a GPU kernel. "Global Work Size (GWS) and Local Work Size (LWS) determine workload distribution and thread partition, respectively."
- Google OR-Tools: An open-source optimization suite used to implement the CP-SAT solver. "we integrate Google OR-Tools~\cite{cpsatlp} -- an open-source software suite for combinatorial optimization, to solve our overlap planning problem."
- Hybrid execution mode: A runtime strategy that switches between exact optimization and heuristics based on workload conditions. "Lastly, we introduce a {hybrid execution mode} that seamlessly switches between CP-SAT and heuristic scheduling based on workload conditions."
- In-flight memory: The portion of memory concurrently occupied by data being transferred and transformed during execution. "the total in-flight memory (spanning weights in both unified and texture memory) allowed during execution;"
- Load Capacity (): The maximum amount of data a layer can transform concurrently without significant slowdown. " represents the maximum number of byte chunks that layer can concurrently transform from unified memory to texture memory without incurring significant overhead."
- Local Work Size (LWS): The number of work-items per work-group, controlling thread partitioning. "Global Work Size (GWS) and Local Work Size (LWS) determine workload distribution and thread partition, respectively."
- Multiply-accumulate (MAC): A fundamental arithmetic operation in DNNs that multiplies inputs and accumulates the result. "compute MAC (multiply-accumulate) outputs."
- Multi-DNN: Workloads consisting of multiple distinct deep neural networks executed in succession. "multi-DNN workloads"
- Operator fusion: Combining multiple operators into a single kernel to reduce overhead and intermediate memory. "operator fusion is often a key optimization"
- Overlap Plan Generation (OPG): The scheduling problem of when and where to load and transform weights relative to computation. "We first formalize the Overlap Plan Generation (OPG) problem"
- Pipelined execution: An execution strategy that interleaves data loading with computation to hide latency. "a branch-free, pipelined execution strategy that interleaves computation with weight loading"
- Preemptive scheduling: A policy allowing a high-priority model to interrupt a lower-priority one during execution. "Preemptive solutions permit a high-priority model to interrupt or replace a lower-priority model during execution"
- Profile-guided adjustments: Solver adaptations based on observed runtime behavior and available memory. "the solver incorporates {profile-guided adjustments}, dynamically updating based on real-time profiling of execution behavior and available memory."
- SIMT efficiency: Efficiency of Single Instruction, Multiple Threads execution on GPUs, reduced by divergent control flow. "reduce SIMT efficiency"
- Streaming multiprocessor (SM): The GPU compute unit that executes kernels and manages thread blocks. "executing on SM (streaming multiprocessor\circled{3})."
- Texture memory (TM): A GPU memory space optimized for 2D access patterns with a dedicated cache. "texture memory (TM)"
- Unified memory (UM): A shared memory space accessible by both CPU and GPU on mobile platforms. "unified memory (UM)"
- Unified memory architecture: A mobile GPU design where CPU and GPU share system memory rather than using dedicated VRAM. "mobile GPUs present additional performance bottlenecks due to their unified memory architecture"
- VRAM: Dedicated GPU memory used in desktop-class GPUs, contrasted with mobile unified memory. "Unlike desktop-class GPUs with dedicated VRAM"
- Weight preloading: Loading all model parameters into memory before inference begins. "Existing DNN acceleration frameworks primarily deploy a {\em weight preloading} strategy"
- XGBoost regression model: A gradient-boosted tree-based model used to predict latency under varying load. "We train an XGBoost regression model \cite{chen2016xgboost} to predict execution latency under varying additional loads"
Collections
Sign up for free to add this paper to one or more collections.